当前位置:网站首页>超标量处理器设计 姚永斌 第8章 指令发射 摘录
超标量处理器设计 姚永斌 第8章 指令发射 摘录
2022-07-07 09:51:00 【岐岇】
8.1 概述
何为发射?它就是将符合一定条件的指令从发射队列issue queue中选出来,并送到FU中执行的过程。发射队列页可以叫做保留站reservation station。
发射队列会按照一定的规则,选择那些源操作数都已经准备好的指令,将其送到FU中执行,这个过程称为发射。
但是对于乱序执行的超标量处理器来说,只有少数指令,例如store指令和分支指令,才会使用这种顺序执行的方法,而对于大多数的指令,都是按照乱序的方式进行发射,设计难度比较大。
指令到了发射队列之后,就不会再按照程序中指定的顺序在处理器中流动,只要发射队列中的一条指令的操作数都准备好了,且满足了发射的条件,就可以送到相应的FU中去执行。
发射队列的作用就是使用硬件保存一定数量的指令,然后从这些指令找出可以执行的指令,而不管指令之间原始的顺序,这就是指令的乱序执行。
在超标量处理器的流水线中,发射阶段的硬件比较复杂,一般它的时序都处于处理器当中的关键路径上,直接影响着处理器的周期时间。
在发射阶段之后,所有指令都是乱序执行的,直到流水线最后的提交commit阶段,才利用重排序ROB将这些指令又拉回到程序中指定的原始顺序。
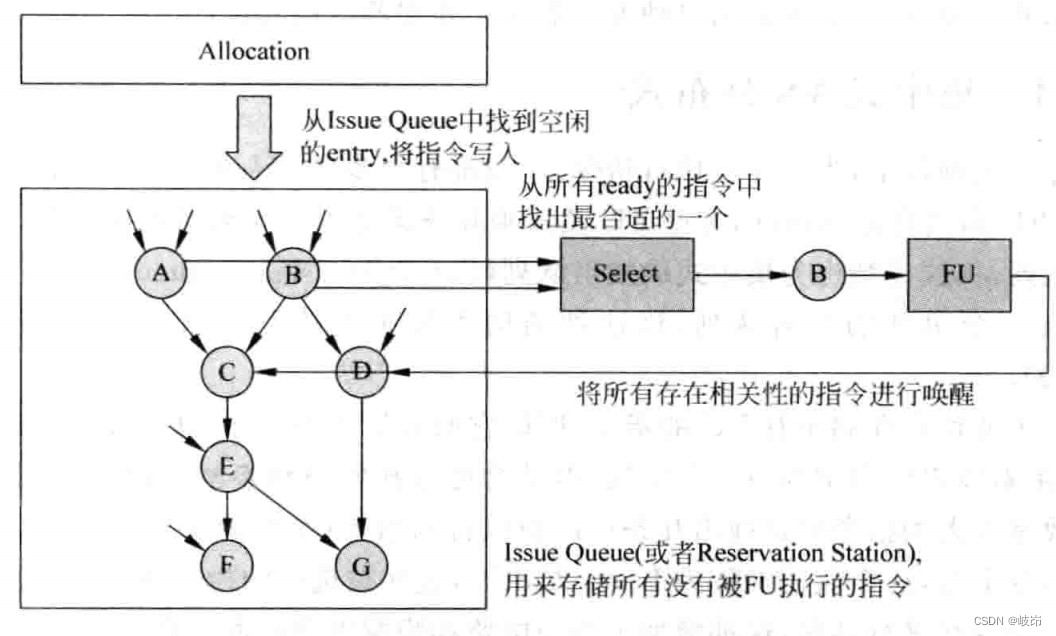
流水线发射阶段的执行过程,涉及到的一些重要部件:
(1)发射队列,用来存储已经被寄存器重命名,但是没有被送到FU执行的指令,通常也被称为保留站。
(2)分配电路,用来从发射队列中找到空闲的空间,将寄存器重命名之后的指令存储到其中,不同的发射队列的设计方法,会直接影响到这部分电路的实现。
(3)选择电路,也称仲裁arbiter电路,如果发射队列中存在多条指令的操作数都已经准备好了,那么这个电路会按照一定的规则,从其中找出最适合的指令,送到FU中去执行,这部分是电路是发射阶段比较关键部分,会直接影响整个处理器的执行效率。
(4)唤醒电路,当一条指令经过FU执行而得到结果操作数时,会将其通知给发射队列中所有等待这个数据的指令,这些指令中对应的源寄存器就会被设置为有效的状态,这个过程即使唤醒。如果发射队列中一条指令的所有源操作数都有效了,则这个指令处于准备好的状态,可以向选择电路发出申请。
发射队列中存储A-G这七条指令,指令A和指令B都已经处于准备好的状态,经过选择电路的仲裁,选择指令B送到FU中进行运算,它运算完成后,会将发射队列中和B指令的结果寄存器相同的所有源寄存器(位于指令C和D)也置为有效,这样就将相关的指令进行唤醒。
发射阶段的实现有很多种方式,而位于这个阶段中心位置的发射队列,它的实现方式直接决定了整个发射阶段的实现方式,它可以设计成集成式centralized,也可以设计成分布式distribute;可以设置成压缩的方式compressing,或者非压缩式non-compressing;可以设计成数据捕捉式data-capture,也可以设计成非数据捕捉式non-data-capture。这些结构都正交的,之间可以互相组合。
8.1.1 集中式 VS 分布式
在超标量处理器中,为了并行执行指令,一般都会有很多的FU,例如有些FU负责整数加减,有些负责存储器访问,有些负责乘除法运算。如果所有的这些FU都共用一个发射队列,称这种结构为集中式发射队列CIQ;而如果每个FU都有一个单独地发射队列,则为分布式发射队列DIQ。
CIQ因为要负责存储所有FU的指令,所以它的容量需要很大,设计有着很大的利用效率,不浪费发射队列中的每一个空间,但是会使选择电路和唤醒电路变得比较复杂,因为需要从数量庞大的指令中选择几条可以被执行的指令(个数选择取决于每周期最多可以同时执行的指令个数,这个值通常称为issue width),这些被选中的指令还需要将发射队列中所有相关的指令都进行唤醒,这都增加了选择电路和唤醒电路的面积和延迟。
DIQ为每一个FU都配备一个发射队列,所以每个发射队列的容量可以很少,这样就大大简化了选择电路的设计。但是当一个发射队列已经满了的时候,即使其他的发射队列中还有空间,也不能继续向其写入新的指令,此时就需要将发射阶段之前的所有流水线都暂停,直到这个发射队列还有空闲的空闲为止。造成了发射队列的利用效率低下,而且由于它的分布比较分散,进行唤醒操作时所需要的布线复杂度也随之上升。
现代处理器一般都结合使用上述两种方法,使某几个FU共同使用一个发射队列,具体将那些FU共用一个发射队列,是和指令集、设计目标等相关的,这属于处理器架构设计的内容。
8.1.2 数据捕捉 VS 非数据捕捉
在流水线的那个阶段读取寄存器的值,它直接决定了处理器中其他一些部件的设计。一般来说,有两个时间点都可以进行寄存器的读取:
(1)在流水线的发射阶段之前读取寄存器,也称为数据捕捉。被寄存器重命名之后的指令首先会读取物理寄存器堆,然后将读取到值随着指令一起写到发射队列。如果有些寄存器的值还没有被计算出来,则会将寄存器的编号写到发射队列中,以供唤醒的过程使用。它会被标记为当前无法获得的状态,这些寄存器都会在之后的时间通过旁路网络得到它们的值,不在需要访问物理寄存器堆。在发射队列中,存储指令操作数的地方称为playload RAM。
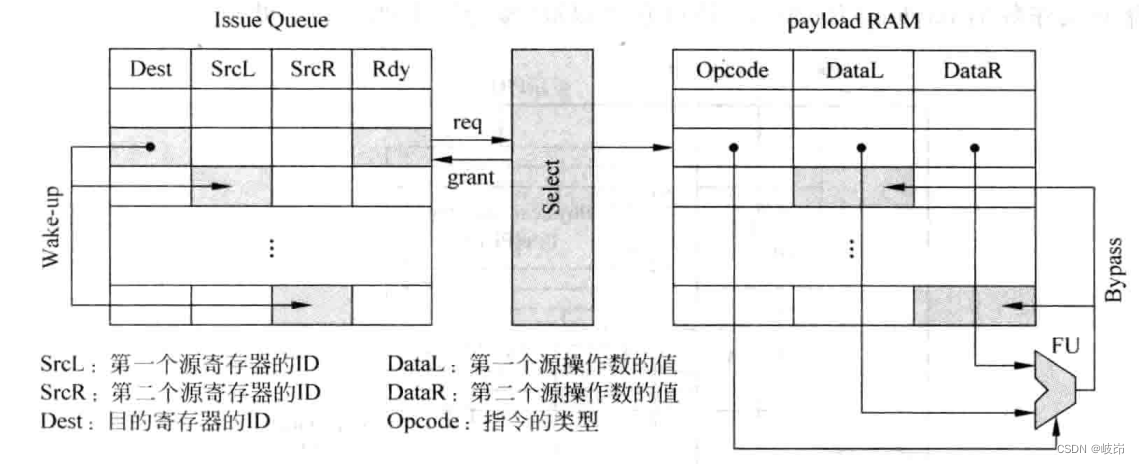
在payload RAM存储了指令源操作数的值,当指令从发射队列中被仲裁电路选中时,就可以直接从payload RAM中对应的地方将源操作数读取出来,并送到FU中执行。
当一条指令从发射队列中被选中的同时,它会将目的寄存器的编号值进行广播,发射队列中其他指令都会将自身的源寄存器编号和这个广播的编号值进行比较,一旦发现相等的情况,则在payload RAM对应的位置进行标记,当那条被选中的指令在FU中计算完毕时,就会将它的结果写到payload RAM这些对应的位置,这是通过旁路网络实现的。这种方式就像是payload在捕捉FU计算的计算,所以称为数据捕捉,发射队列负责比较寄存器编号值是否相等,而payload RAM负责存储源操作数,并捕捉对应FU的结果。
在超标量处理器中,用machine width来标记每周期实际可解码和重命名的指令个数,而用issue width来标记每周期最多可以在FU中并行执行的指令个数。在一般CISC处理器中,在处理器内部将一条CISC指令转换为几条RISC指令,而存储到发射队列中的是RISC指令,只有使issue width大于machine width,才能够使处理器的流水线平衡,避免出现进的多,出的少的情况;而一般在RISC处理器中,一般情况下这两个值都是相等的。但是考虑到由于指令之间存在相关性等原因,在超标量处理器中,即使每周期可以解码和重命名,即使每周期可以解码和重命名4条指令,在很多时候也不能得到每周期4条指令送到FU中执行的这种效果。因此,只有使issue width大于machine width,才能够最大限度地寻找在FU中可以并行执行的指令,所以现代的高性能处理器都会采用多个FU,使每周期可以并行执行的指令个数尽可能多。因此寄存器堆需要的读端口个数是machine width
(2)在流水线发射阶段之后读取物理寄存器堆,被称为非数据捕捉。被重命名之后的指令不会去读取物理寄存器堆,而是直接将源寄存器的编号放到发射队列中,当指令从发射队列被选中时,会使用源寄存器的编号来读取物理寄存器堆,将读取地值送到FU中取执行。由于发射队列不需要存储源操作数payload RAM,所以它可以被瘦身,也就增加了处理的速度。寄存器堆需要的读端口个数是issue width。
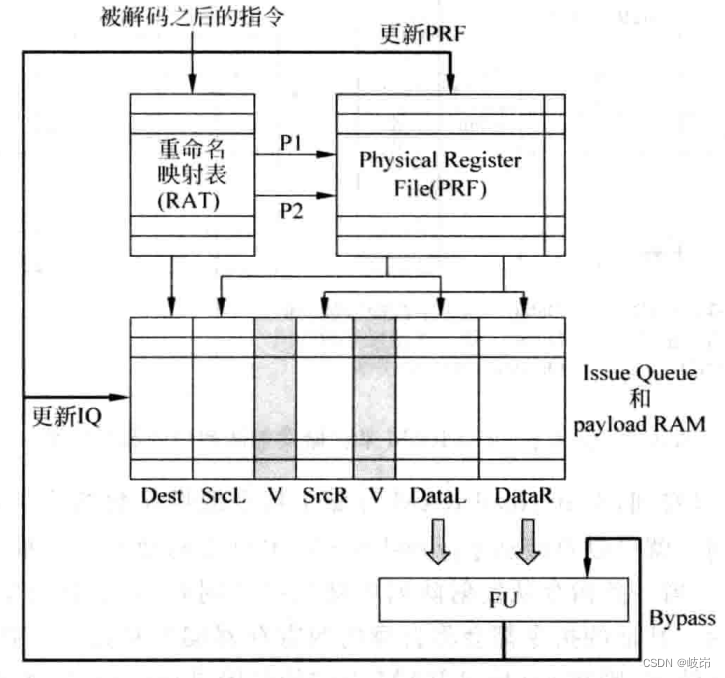
在流水线发射阶段之前读取寄存器,所需存储器堆读端口个数少,发射队列需要更多的面积来存储操作数,以及源操作数需要经历两次读和一次写,即从寄存器中读取出来,写到发射队列中,然后再从发射队列中读取出来送到FU中执行,消耗更多的能量,不利于低功耗处理器。
在发射阶段之后读取寄存器恰好相反。
这两种方法的取舍直接决定了寄存器重命名的实现方式,当使用重排序缓存ROB进行寄存器重命名时,一般都会配合使用数据捕捉的发射形式。因为指令在顺利离开流水线时,需要将它的结果从重排序缓存中搬移到ARF中,采用数据捕捉的方式可以不用关心这种指令的位置变化。
8.1.3 压缩 VS 非压缩
决定了发射阶段的其他部件设计的难易,也影响着处理器的功耗。
(1)压缩
当指令被选中而离开时,在发射队列中就会出现空闲的位置,经过压缩之后,这个空闲的位置会被挤掉,这样所有的指令又靠在一起了。保证空闲的空闲都是处于发射队列的上部,此时只需要将重命名之后的指令写到发射队列的上部即可。
实现方式是,需要在每个表项中加入多路选择器,用来从其上面的表项(压缩时)或自身(不可压缩时)选择一个。
如果一个发射队列每周期可以压缩两个表项,则每个表项的内容有三个来源,即上上面表项、上面表项以及自身,因此需要更多的布线资源。
还需要对不同表项的多路选择器产生不同的控制信号,增加了设计的复杂度。
压缩的优点在于其选择电路比较简单,为了保证处理器可以最大限度的并行执行指令,一般都从所有准备好的指令中优先选择最旧的指令送到FU中执行,这也称为oldest-first,而这种压缩方式的发射队列已经很自然地按照最新->最旧的顺序将指令排列好了。
如果有任何一条指令在当前周期被选中了,则比它新的所有指令都能够在本周期被选中,这就按照oldest-first原则。
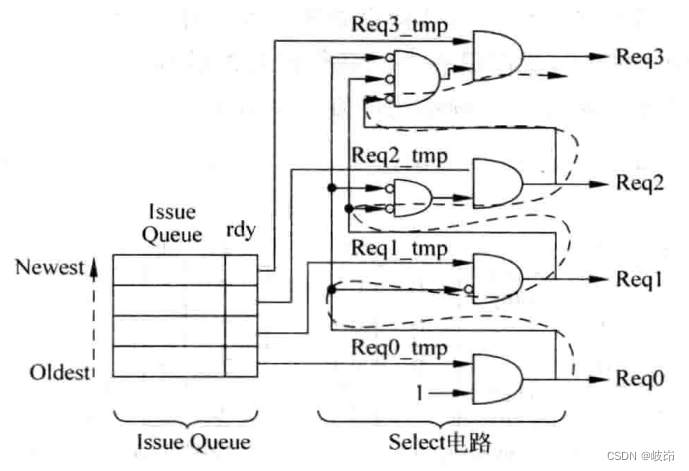
该设计方法的延迟和发射队列的容量成正比,发射队列中可以容纳的指令个数越多,延迟也就越大。
压缩方式的发射队列的优点如下:
(a)分配电路很简单,发射队列中的空闲空间总是处于上部,只需要使用发射队列的写指针,指向当前第一个空闲的空间即可。
(b)选择电路简单,因为这种方法以及使发射队列中的指令从下到上按照“最新”到“最旧”的顺序排列好了。在发射队列中最旧的指令,和它存在RAW相关性指令也是最多的。
缺点:
(a)实现起来比较浪费硅片面积,如一个发射队列对应两个FU时,每周期要从中选择两条指令送到FU中执行,则发射队列需要最多支持两个表项,需要复杂的多路选择器和大量的布线资源,增加了硬件的复杂度。
(b)功耗大,每周期都需要将发射队列当中很多指令进行移动。
(2)非压缩发射队列
每当有指令离开发射队列时,发射队列中其他的指令不会进行移动,而是继续留在原地。优点是大大减少了功耗,减少了多路选择器和布线的面积。缺点是要实现oldest-first功能的选择电路,就需要使用更复杂的逻辑电路,会产生更大的延迟。分配电路也变得比较复杂,无法像压缩办法中那样直接将指令写入发射队列的上部,而是需要扫描发射队列中所有的空间。
8.2 发射过程的流水线
8.2.1 非数据捕捉结构的流水线
进入到发射队列当中的一条指令要被FU执行,必须等到下述几个条件都成立:
(a)这条指令所有的源操作数都准备好了;
(b)这条指令能够从发射队列中被选中,即需要经过仲裁电路的允许才能够发射;
(c)需要能够从寄存器、payload或者旁路网络获得源操作数的值。
上面三个条件是顺序发生的,对于一个源寄存器来说,如果它被写到发射队列中的时候,还处于没准备好的状态,等到之后的某个时间,它变为准备好的状态,这个过程被称为唤醒状态,这需要通过旁路网络才可以通知发射队列中的每个源寄存器。唤醒的过程可以很简单,也可以很复杂,最简单的方法就是当一条指令在FU中得到结果时,将发射队列中使用这条指令计算结果的所有源寄存器都置为准备好的状态。
发射过程被分为唤醒和冲裁两个流水线阶段。在唤醒阶段,发射队列中的所有相关的寄存器会被置为准备好的状态;而在仲裁阶段,会使用仲裁电路从发射队列中选择一条最合适的指令送到FU中。
通过处理器中的旁路网络,能够使唤醒的过程提前。
在同一个周期内执行的仲裁和唤醒这两个操作是串行的。只有当仲裁电路选出可以发射的指令后,才可以对发射队列相关的源寄存器进行唤醒,而只有当这两个不好走在一个周期之内完成时,才可以背靠背地执行RAW相关性指令。
要想使存在RAW相关性的相邻指令可以背靠背地执行,就必须使流水线的仲裁和唤醒两个操作在一个周期内完成,组成一个原子操作。
因为仲裁和唤醒电路都是相对比较复杂的,将它们放在一个周期内执行,肯定会使时钟周期变长,处理器频率变低。而将其分开,减少对时钟周期的负面影响,提高了处理器频率,但是会影响超标量处理器每周期可以并行执行的指令个数。增加了一级流水线,还会有以下负面影响:
(a)分支预测失败时候,惩罚增加;
(b)Cache访问的周期数增加
(c)处理器需要更多的门数,使电容变大,导致功耗增大。
8.2.2 数据捕捉的流水线
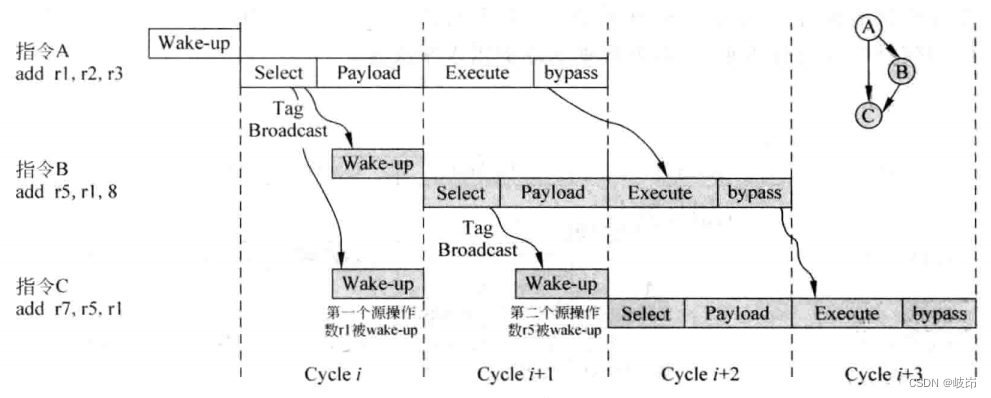
在指令被仲裁电路选中之后,在同一个周期也会对发射队列中其他的指令进行唤醒,同时还回去读取payload RAM,这两个操作时并行执行的,在本周期末尾就可以得到指令的所有源操作数,这样在下个周期就可以送到FU中执行。
指令的选择和读取payload RAM放到一个流水线,还复杂将FU的计算结果捕捉到payload RAM中,很显然在这个周期做了很多事情,尤其是这个处理器的周期时间变得过大。同时,当FU的个数比较多时,FU结果的旁路网络也会占用不菲的硬件资源和过多的时间,因此可以造成下一步对流水线进行细分。
为了保持相关指令之间可以背靠背地执行,仍然将仲裁和唤醒两个操作放在一个周期内完成,因为多端口的payload RAM占据了过多的时间,因此将其单独放到一个流水段中,指令被仲裁电路选中之后,将发射队列中相关的所有寄存器都进行唤醒,然后在下一个周期进行payload RAM读取。由于将其放在了单独一个流水段,所以它对处理器的周期时间的影响小了很多。源操作数从payload RAM读取出来之后,在下个周期就可以送到FU中执行了,指令的结果时在FU中被计算出来之后,并不会在当前周期马上进行旁路,而是将旁路的过程放到下一个流水段,在流水段的旁路阶段,FU的结果会被送到payload RAM和FU的输入端。
8.3 分配
当采用非压缩的方式来设计发射队列时,需要分配电路能够扫描整个发射队列,找到四个空闲的表项并将4条指令写入。
发射队列的分配电路会扫描发射队列中每个表项的,找到四个空闲的表项并将四条指令写入。
发射队列的分配电路会扫描发射队列中每个表项的空闲标志,从发射队列中并行地找出4个空闲的表项,将重命名之后的指令写入到其中,尽管查找四个空闲表项的过程是并行进行的,但是仍旧需要一段时间才可以完成。其实,整个分配过程所需要的时间是和发射队列的容量,以及每周期写入的指令个数成正比的。
一个简单的方法是可以将发射队列分为4部分,从每部分中找到一个空闲的表项。缺点是很明显的,如果恰好一个段内没有空闲的空间了,此时即使其他的段都是空闲的,这个段也不能接受新的指令,因此一个发射队列也无法在一个周期内写入4条指令了。而且寄存器重命名阶段都是按照程序制定的顺序进行的,指令A无法写入发射队列,会导致后面的指令B、C和D都无法写入到发射队列中。降低了处理器的性能,可以使用缓存将那些不能写入的发射队列的指令缓存起来,使它们不至于阻碍后面指令写发射队列的过程,当然这种做法会增加设计的复杂度。
还需要注意,分配电路从电路严格意义说,是处于流水线的分发阶段的,它并不属于发射阶段的内容。
8.4 仲裁
8.4.1 1-of-M 的仲裁电路
为什么要实现lodest-first功能的仲裁呢?考虑到越是旧的指令,和它存在相关性指令也就越多,因此优先执行最旧的指令,则可以唤醒更多的指令,能够有效地提高处理器执行指令的并行度,而且最旧的指令还占据其他资源,比如ROB和store buffer,越早地执行这些旧的指令,就可以越早地释放这些硬件资源。
要识别发射队列中那些指令是最旧的,就需要知道这些指令的年龄信息,年龄信息即表示指令进入流水线的先后顺序。可以使用指令在ROB中的位置作为这条指令的年龄信息,但是有一个问题是ROB本质是一个FIFO,因此直接使用它的地址是无法表达出年龄的真实信息。
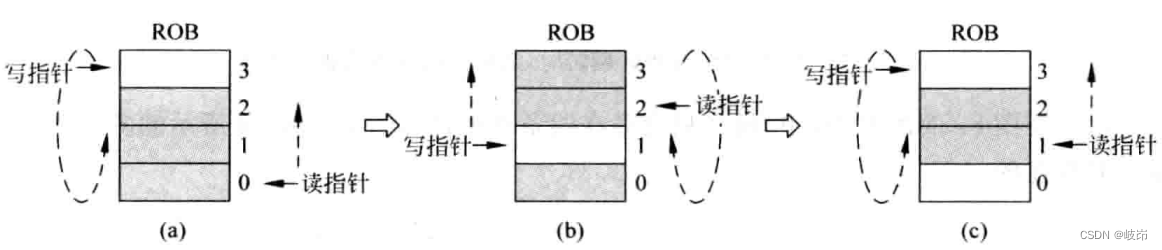
每次写指针翻转时,新的写指针和旧的写指针即出现大小混乱。可以根据指令在ROB中的地址值来判别指令的年龄,而当它们不再一个“面”上时,无法直接通过地址值来确定年龄信息,为了解决这个问题,可以在ROB的地址前面加入一位,称为位置值。这样相当于将写指针和读指针都都增加了一位,每次当它们“翻转”时,最高位的位置值也会随之翻转。

位置值相同时,ROB的地址值越小,对应的指令越旧;
位置值不同时,ROB的地址值越大,对应的指令越旧;
指令在流水线的分发阶段,会将重命名之后的指令写到ROB和发射队列中,为了记录年龄信息,需要将每条指令在ROB中的地址值也一并写到发射队列中,这样在发射队列中的每条指令就有了年龄信息,仲裁电路根据这个信息,从所有准备好的指令中找到最旧的那条指令。如果发射队列有M个表项,这个仲裁电路就称为1-of-M的仲裁电路,它按照oldest-first的原则实现。
所需比较比较电路的级数N和发射队列中的表项的个数M之间存在关系N=log2M,因此发射队列的容量很大时,就需要更多的比较器级数,也就是延迟会更大。
实际当中下面的两个问题:
(a)如何屏蔽掉发射队列中那些还没有准备好的指令,使那些指令的年龄信息不会超过对仲裁电路的结果产生影响?将那些还没有准备好的指令对应的年龄信息置成无穷大。
(b)如何根据仲裁电路挑选出的年龄值,在发射队列中找到对应的指令?
最直接的办法就是将仲裁电路得到的这个年龄值和发射队列中所有指令的年龄值进行比较。当时额外引入了CAM电路,增加了处理器的面积和延迟,不是一个很明智的做法。
8.4.2 N-of-M的仲裁电路
若几个FU共用一个发射队列,这个发射队列需要在一个周期内为每个FU都选出一条指令,这样就要求它有一个N-of-M的仲裁电路。
若多个FU共有一个发射队伍,发射队列的容量为M,每个FU都有一个专属的1-of-M的仲裁电路。当指令被写到发射队列中的某个表项时,根据这条指令的类型,将这条指令分配给一个对应的FU,如果存在功能相同的FU,则会按照轮流或者随机的顺序进行分配,这个分配的过程本质可以通过一个多路分配器来实现,它将每个表现的ready信号根据指令的类型分配给不同的仲裁电路,因为发射队列中每个表项都有可能存放不同类型的指令,所以每个FU的仲裁电路都会有M个输入,执行完整的1-of-M的仲裁过程,整个N-of-M的冲裁电路的延迟就只有1-of-M。
引入一个新的问题,一个ALU类型的指令分配给那个ALU呢?可以采用轮换分配,虽然并不能保证严格oldest-first。
对于现代的很多处理器而言,一般最多在每周期执行4~6条指令,典型包括:
加减法、逻辑、移位、乘法、除法、访问存储器、访问协处理器、单指令多数据操作,浮点加减、浮点乘、浮点除法。
一般来说,会将加减法、逻辑运算和移位运算合在一个FU中;将整数乘除法合并在一起;将访问存储器和访问协处理器合并在一起;将所有浮点运算合并在一起;
当更多FU共有一个发射队列时,这个发射队列的容量也需要相应增加,这样就增大了仲裁电路的延迟;如果使更少的FU共用一个发射队列,就需要数量更多的发射队列,这时候唤醒操作就需要更多布线资源和比较器电路,增大了唤醒电路的延迟和功耗。
8.5 唤醒
8.5.1 单周期指令的唤醒
唤醒是指被仲裁电路选中的指令将其目的寄存器的编号和发射队列中所有源寄存器的编号进行比较,并将那些比较结果相等的源寄存器进行标记的过程。
一般情况下,仲裁电路的个数等于issue width。
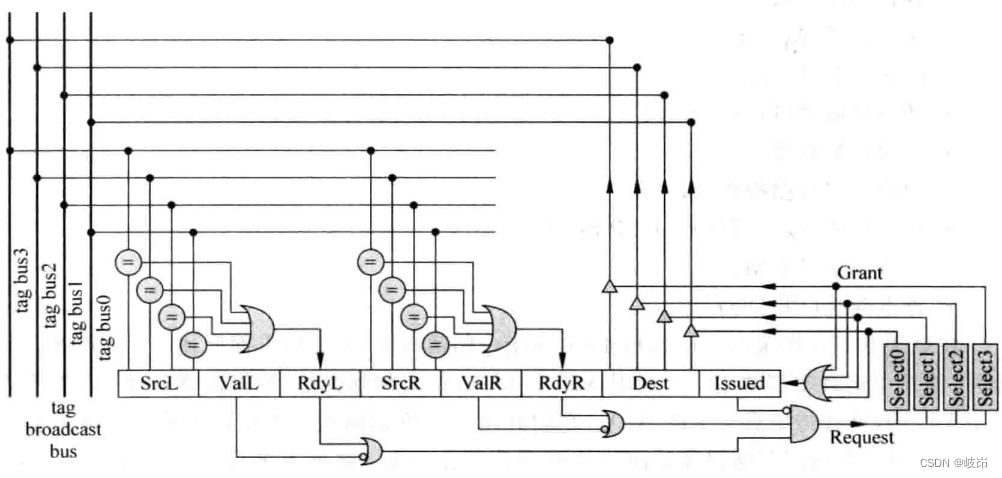
表项内容如下:
(a)ValL:指令中是否存在第一个源寄存器,如果指令中并没有第一个源寄存器,那么也就不需要对这个源寄存器进行唤醒了。
(b)SrcL:指令中的第一个源寄存器的编号;
(c)RdyL:指令中第一个源寄存器是否已经被唤醒而处于准备好的状态;
(d)ValR、SrcR和RdyR:指令中第二个源寄存器的状态;
(e)Dest:目的寄存器的编号;
(f)Issued:一条指令被仲裁电路选中后,可能不会马上离开发射队列,因此需要对其进行标记,这样的指令不会向仲裁电路发出请求信号。
在一个RISC指令集中,大部分的ALU类型的指令都是单周期的,这样的指令在被仲裁电路选中的当前周期就可以对发射队列中的其他指令进行唤醒,被唤醒的指令可以通过旁路网络获得源操作数,从而实现背靠背执行,现在对单周期指令的唤醒过程做一个梳理:
第一步:被仲裁电路选中的指令会将它的目的寄存器的编号送到对应的总线上。
第二步:每一条总线上的值会和发射队列中所有指令的源寄存器的编号进行比较,如果发现相等,则将这个源寄存器标记为准备好的状态。
第三步:当发射队列的某条指令的所有操作数都准备好了,并且还没有被仲裁电路选中过,它就可以向以向相应的仲裁电路发出请求信号了。
第四步:如果仲裁电路发现有更高优先级的指令也发出了请求信号,则当前的这条指令将不会得到有效的响应,这条指令将在下一个周期向仲裁电路发出请求信号,如果其中一个仲裁电路几次都没有给出响应信号的话,可以将这条指令的请求送至另外一个仲裁电路,因为另一个仲裁电路很有可能此时是空闲的。如果从仲裁电路得到了有效的响应信号,则这个响应信号会将这条指令标记为已经被选中的状态,这条指令在下个周期就不会向仲裁电路继续发出请求信号。为什么不直接让这条已经被选中的指令马上离开发射队列呢?因为一条指令如果使用了load指令的结果,即使它被仲裁电路选中,也不可以马上离开发射队列。
第五步:发射队列中这条指令根据收到的响应信号,将它的目的寄存器的编号送到对应的总线,用来唤醒发射队列中所有相关的源寄存器,同时这条指令就可以送到FU中执行了。
8.5.2 多周期指令的唤醒
当一条指令无法在一个周期之内执行完毕是,就不能再被仲裁电路选中的当前周期对发射队列中其他的指令进行唤醒,而需要根据它在FU中执行的周期数,将这个唤醒过程进行延迟。
唤醒过程注意分为两个主要阶段,第一个阶段是将被选中的指令目的寄存器的编号值送到总线上,第二个阶段是将总线上的值和发射队列中所有源寄存器的编号进行比较,因此要将唤醒过程延迟,也就是将这两个阶段进行延迟,这也就产生了两种方法,一种称为延迟广播delayed tag broadcast,另一种称为延迟唤醒delayed waken。
延迟广播的方法是指如果发现被仲裁电路选中的指令执行周期大于1,则在选中的当前周期,并不将这条指令的目的寄存器的编号送到总线上,而是根据这条被选中的指令所需要执行的周期数N,延迟N-1个周期后,才将它送到总线上。
不过当指令操作专用一条总线时,这样做法没有问题,但是当指令和其他操作共用一条总线时,则可能会和其他指令抢用该总线。为了解决这个问题,可以增加这个FU对应的总线个数,但是,当处理中存在很多这样的情况时,会导致大量的总线,这会极大地增加唤醒电路的复杂度,在实际的设计中是无法接受的。如果不增加总线的数量,那么就需要在处理器中记录每条指令的执行周期数。这种方法的优点是没有增加仲裁电路的延迟,但是却造成了性能的损失。
如何解决这个问题?可以让指令向仲裁电路发出请求之前,首先查询表格,如果表格否决了它,那么这条指令就不会向仲裁电路发出有效的请求信号,这样就可以将机会留给其他的指令。但是该做法需要串行访问表格和仲裁电路,所以会增大处理器的周期时间,
延迟广播的方法是对唤醒过程的第一阶段进行延迟,相比之下,延迟唤醒则是对第二阶段进行延迟。延迟唤醒是在发射队列中,每条指令对应的ready状态为加入延迟功能的寄存器。采用移位寄存器的方式来实现延迟唤醒的效果,因为在流水线解码阶段,每条指令需要的执行周期数就可以知道了,将每条指令的执行周期进行编码,编码之后的值简称的DELAY。
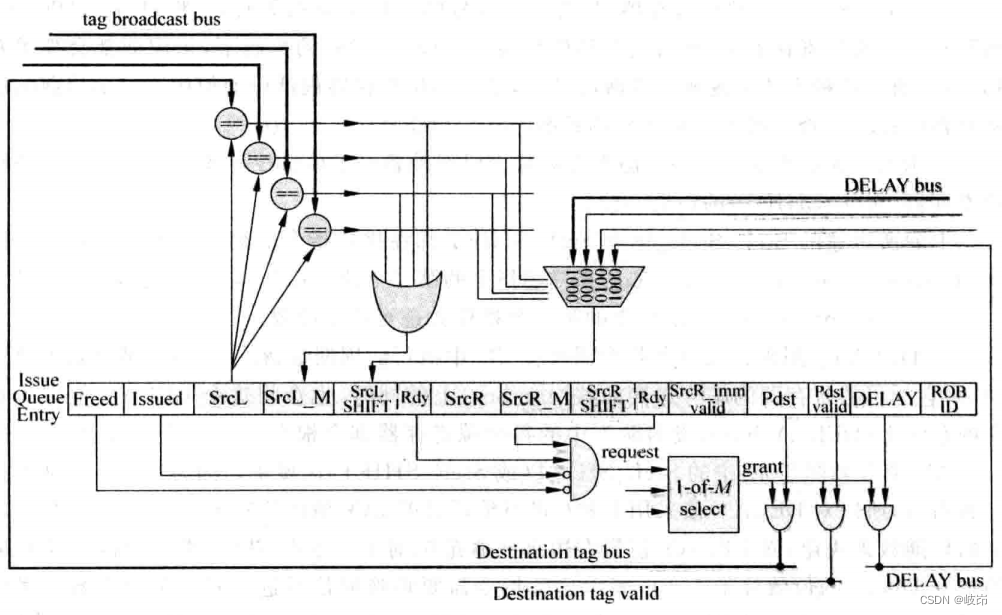
表项内容如下:
(a)Freed:表示这个表项是否是空闲的,当一条指令写入其中时,这个表项就不再是空闲的;而这条指令被仲裁电路选中,并且缺点不会有问题时,这条指令就可以离开发射队列,这个表项就可以变为空闲状态。需要注意的是,一条指令被仲裁电路选中之后,并不一定保证这条指令就一定会得到想要的操作数,当这条指令的操作数来自于load指令时,处理器可能采用推测唤醒。管理发射队列中一个表项是否空闲并不是一件很直接的事情,最容易的方法就是当条指令顺利地离开流水线时,才使它在发射队列中占据的表项变为空闲的状态。但是这会导致很多无效的指令占据着发射队列,使其可用的容量变小,降低了处理器可能获得的并行度。
(b)SrcL_M:当寄存器编号的比较结果相等时,第一位会被置1(M表示match);当这个指令接收到仲裁电路给出的响应信号时,这一位会被清0,它使用移位寄存器进行算术右移的使能信号,当它为1时,移位寄存器每周期都会算术右移一位。
(c)SrcL_SHIFT:移位寄存器,当寄存器编号的比较结果相等时,会将对应的DELAY值写到这个移位寄存器中,然后它在移位使能信号的控制下,每周期都会算术右移一位,通过这样方式实现延迟唤醒的功能。
(d)SrcR_imm_valid:表示指令的第二个操作数是否是立即数;
(e)DELAY:用来记录每条指令需要在FU中执行的周期数,在一条指令被仲裁电路选中,将它的目的寄存器的编号送到总线上的同时,也会将这个DELAY值送到对应的总线上,发射队列中的每个源寄存器都会根据比较的结果,选择合适的DELAY值。对于一条在FU中需要执行L个周期的指令来说,0的位数等于L-1,表示这条指令需要将唤醒信号进行延迟的周期数。
(f)ROB ID:这条指令在ROB中的位置,这个值作为指令的年龄信息,使仲裁电路可以实现oldest-first的指令选择。
8.5.3 推测唤醒
前文所讲述唤醒方法都是建立在一个前提下,即指令在FU中的执行周期数是可以预知的,而对于无法预知的指令如:
(a)Load指令,它在FU中执行的周期数取决于D-Cache是否命中,在一个有着L1,L2,L3 Cache和DRAM的典型处理器,load的延迟不确定。
(b)在某些处理器中,定义了一些特殊情况。
对于这些执行的周期数不确定的指令,可以采用最简单的方式进行处理,当这条指令执行完时,才对其他相关相关的指令进行唤醒操作。
例如laod指令,如果L1 D-Cache命中,则当laod指令执行完毕,得到需要的数据时,才将这条指令的目的寄存器的编号送到对应的总线上,对发射队列中相关的寄存器进行唤醒操作。
在设计D-Cache时,Cache是否命中的信息使可以先于数据得到的,例如laod指令执行的第一各周期进行地址的计算,第二个周期访问Tag SRAM进行是否命中的判断,第三个周期将读取到的数据写到load指令的目的寄存器中,在这样设计的D-Cache中,执行第二个周期就可以知道Cache是否命中了。
对于延迟唤醒的情况,只不过对于load指令来说,还需要考到D-Cache缺失情况,则指令不能通过旁路网络获得操作数,也就无法在FU中执行,而且也不能就此停住等待操作数,这样会使FU无法接受其他新的指令,严重影响处理器的性能。最好的办法就是将指令B重新返回发射队列中。
由于读取L1,L2甚至L3 Cache需要的周期数都是确定的,所以可以使用延迟唤醒的方式,但是对于读取时间不确定,例如DRAM的访问,只能等待DRAM中真正得到数据的时候,才对发射队列相关的寄存器进行唤醒。
现代处理器都是在指令被仲裁电路选中的同时,根据这条指令所需要的执行周期数,来对其他相关指令进行唤醒,这样当这条被选中的指令计算出结果的时候,被它唤醒的指令正要进入执行阶段,可以通过旁路网络获得操作数,从而实现背靠背的执行。
load指令多处于相关性的顶端,如果等到它的结果被计算出来才进行唤醒操作,会损失一些潜在的并行执行的机会,从而降低处理器的性能,因此需要使用预测的方法预测指令执行的周期数,在指令得到结果之前,就对相关的指令进行唤醒操作,这种方法就称为推测唤醒。speculative wake up。
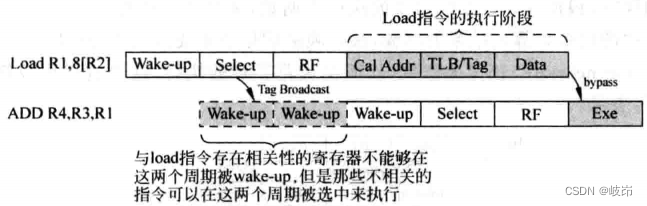
load指令在执行阶段被分为三个流水段,Cal Addr阶段用来计算指令所携带的地址,TLB/Tag阶段会同时访问TLB和D-Cache,在这个周期会得到虚拟地址对应的物理地址,同时会得到D-Cache是否命中的消息,在Data阶段就可以从D-Cache中得到需要的数据,并将其写到目的寄存器中。需要注意预测失败之后的状态恢复。
如果采用软件处理TLB缺失,就需要按照异常的处理方式,等到load指令变为流水线中最旧的指令的时候,将流水线中所有的指令(包括load指令),在对应的异常处理器中对TLB缺失的情况处理,然后重新将load指令和之后的指令取到流水线中。
如果采用硬件处理TLB缺失,那么就不需要将laod指令重新取到流水线中执行,load指令的后面相关指令也只需要重新返回发射队列就可以,因此如果硬件处理TLB缺失的方式,就可以将它恢复过程和D-Cache miss时的恢复过程放到一起来处理,这就节约了硬件资源。
采用不同结构的D-Cache,对于推测唤醒的过程是由影响的。采用虚拟寻址,物理标签,则在访问TLB的同时,也可以使用虚拟地址来访问D-Cache,这种并行地方式会增加执行的效率。如使用物理index,物理tag时候,就必须先访问TLB而得到物理地址,然后才能访问D-Cache,这种将D-Cache的访问过程完全的串行化,因此需要更长的执行时间。如果使用虚拟index,物理tag,则不需要访问TLB,直接使用虚拟地址访问D-Cache就可以了,只有当D-Cache缺失的时候才需要访问TLB(因为L2 Cache都是物理地址来访问的),不需要访问TLB也就意味着这种方面会缩短D-Cache访问的时间。
load指令被仲裁电路选中之后,需要等待两个周期才可以将相关的指令进行唤醒,在这两个周期内,仲裁电路可以选择那些和load不相干的指令,称这两个周期为Independent window。而从load指令开始将相关指令进行唤醒,知道发现它自身是否会D-Cache命中/缺失,中间也间隔两个和走起,称这两个周期为Speculative Window。
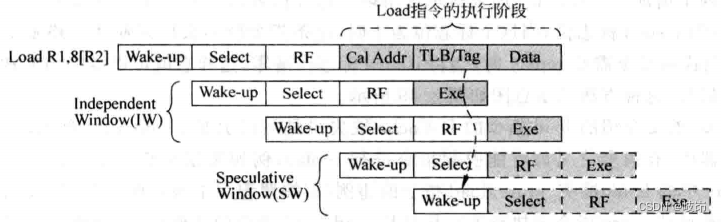
需要注意的是,SW窗口中的指令不一定就和load指令存在相关性,例如那些被load指令唤醒的指令并没有马上被仲裁电路选中,就会使SW窗口中的指令其实并没有使用load指令的结果;而IW窗口中的指令也不一定就和load指令相关,因为它可以和其他load指令的SW窗口是重合的。
边栏推荐
- R语言使用quantile函数计算评分值的分位数(20%、40%、60%、80%)、使用逻辑操作符将对应的分位区间(quantile)编码为分类值生成新的字段、strsplit函数将学生的名和姓拆分
- 学习笔记|数据小白使用DataEase制作数据大屏
- STM32入门开发 NEC红外线协议解码(超低成本无线传输方案)
- Flet教程之 16 Tabs 选项卡控件 基础入门(教程含源码)
- The Oracle message permission under the local Navicat connection liunx is insufficient
- Internet Protocol
- 一度辍学的数学差生,获得今年菲尔兹奖
- Cmu15445 (fall 2019) project 2 - hash table details
- What is cloud computing?
- electron 添加 SQLite 数据库
猜你喜欢

学习笔记|数据小白使用DataEase制作数据大屏
分布式数据库主从配置(MySQL)
如何在博客中添加Aplayer音乐播放器
Design intelligent weighing system based on Huawei cloud IOT (STM32)
正在運行的Kubernetes集群想要調整Pod的網段地址

核舟记(一):当“男妈妈”走进现实,生物科技革命能解放女性吗?

Tsinghua Yaoban programmers, online marriage was scolded?

竟然有一半的人不知道 for 与 foreach 的区别???
面试被问到了解哪些开发模型?看这一篇就够了
![Drive HC based on de2115 development board_ SR04 ultrasonic ranging module [source code attached]](/img/ed/29d6bf21f857ec925bf425ad594e36.png)
Drive HC based on de2115 development board_ SR04 ultrasonic ranging module [source code attached]
随机推荐
聊聊SOC启动(六)uboot启动流程二
请查收.NET MAUI 的最新学习资源
Flet教程之 19 VerticalDivider 分隔符组件 基础入门(教程含源码)
Zhou Yajin, a top safety scholar of Zhejiang University, is a curiosity driven activist
Flet教程之 17 Card卡片组件 基础入门(教程含源码)
Technology sharing | packet capturing analysis TCP protocol
Have you ever met flick Oracle CDC, read a table without update operation, and read it repeatedly every ten seconds
简单介绍一下闭包及它的一些应用场景
The Oracle message permission under the local Navicat connection liunx is insufficient
【神经网络】卷积神经网络CNN【含Matlab源码 1932期】
Use metersphere to keep your testing work efficient
Learning notes | data Xiaobai uses dataease to make a large data screen
Onedns helps college industry network security
electron添加SQLite数据库
技术分享 | 抓包分析 TCP 协议
What is high cohesion and low coupling?
一度辍学的数学差生,获得今年菲尔兹奖
Talk about SOC startup (11) kernel initialization
在我有限的软件测试经历里,一段专职的自动化测试经验总结
自动化测试框架