当前位置:网站首页>【神经网络】卷积神经网络CNN【含Matlab源码 1932期】
【神经网络】卷积神经网络CNN【含Matlab源码 1932期】
2022-07-07 09:46:00 【海神之光】
一、获取代码方式
获取代码方式1:
完整代码已上传我的资源:【神经网络】卷积神经网络CNN【含Matlab源码 1932期】
获取代码方式2:
通过订阅紫极神光博客付费专栏,凭支付凭证,私信博主,可获得此代码。
备注:
订阅紫极神光博客付费专栏,可免费获得1份代码(有效期为订阅日起,三天内有效);
二、卷积神经网络CNN简介
1 神经元
神经元是人工神经网络的基本处理单元, 一般是多输入单输出的单元, 其结构模型如图1所示.其中:xi表示输入信号;n个输入信号同时输入神经元j.wij表示输入信号xi与神经元j连接的权重值, bj表示神经元的内部状态即偏置值, yj为神经元的输出.输入与输出之间的对应关系可用下式表示: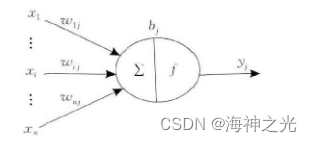
图1 神经元模型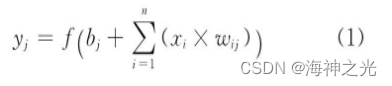
f (·) 为激励函数, 其可以有很多种选择, 可以是线性纠正函数 (Rectified Linear Unit, ReLU) [25], sigmoid函数、tanh (x) 函数、径向基函数等。
2 多层感知器
多层感知器 (Multilayer Perceptron, MLP) 是由输入层、隐含层 (一层或者多层) 及输出层构成的神经网络模型, 它可以解决单层感知器不能解决的线性不可分问题.图2是含有2个隐含层的多层感知器网络拓扑结构图.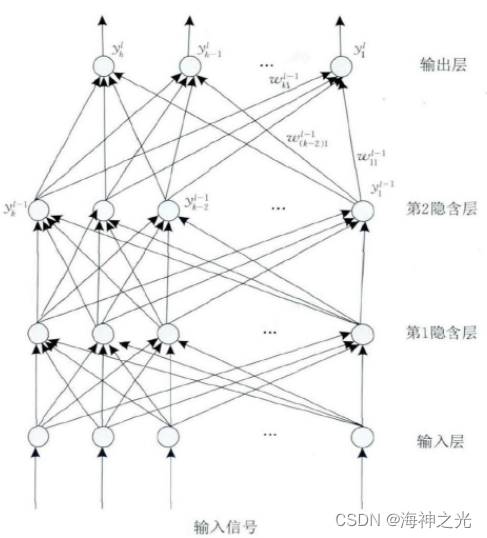
图2 多层感知器结构图
输入层神经元接收输入信号, 隐含层和输出层的每一个神经元与之相邻层的所有神经元连接, 即全连接, 同一层的神经元间不相连.图2中, 有箭头的线段表示神经元间的连接和信号传输的方向, 且每个连接都有一个连接权值.隐含层和输出层中每一个神经元的输入为前一层所有神经元输出值的加权和.假设xml是MLP中第l层第m个神经元的输入值, yml和bml分别为该神经元输出值和偏置值, wiml-1为该神经元与第l-1层第i个神经元的连接权值, 则有: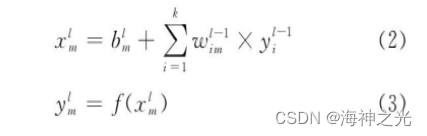
当多层感知器用于分类时, 其输入神经元个数为输入信号的维数, 输出神经元个数为类别数, 隐含层个数及隐层神经元个数视具体情况而定.但在实际应用中, 由于受到参数学习效率影响, 一般使用不超过3层的浅层模型.BP算法可分为两个阶段:前向传播和后向传播, 其后向传播始于MLP的输出层.以图2为例, 则损失函数为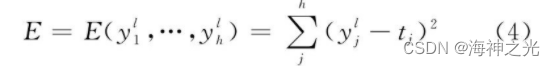
其中第l层为输出层, tj为输出层第j个神经元的期望输出, 对损失函数求一阶偏导, 则网络权值更新公式为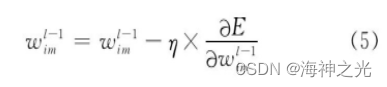
其中, η为学习率.
3 CNN
1962年, 生物学家Hubel和Wiesel[28]通过对猫脑视觉皮层的研究, 发现在视觉皮层中存在一系列复杂构造的细胞, 这些细胞对视觉输入空间的局部区域很敏感, 它们被称为“感受野”.感受野以某种方式覆盖整个视觉域, 它在输入空间中起局部作用, 因而能够更好地挖掘出存在于自然图像中强烈的局部空间相关性.文献[28]将这些被称为感受野的细胞分为简单细胞和复杂细胞两种类型.根据HubelWiesel的层级模型, 在视觉皮层中的神经网络有一个层级结构:外侧膝状体→简单细胞→复杂细胞→低阶超复杂细胞→高阶超复杂细胞[29].低阶超复杂细胞与高阶超复杂细胞之间的神经网络结构类似于简单细胞和复杂细胞间的神经网络结构.在该层级结构中, 处于较高阶段的细胞通常会有这样一个倾向:选择性地响应刺激模式更复杂的特征;同时还具有一个更大的感受野, 对刺激模式位置的变化更加不敏感[29].1980年, Fukushima根据Huble和Wiesel的层级模型提出了结构与之类似的神经认知机 (Neocognitron) [29].神经认知机采用简单细胞层 (S-layer, S层) 和复杂细胞层 (C-layer, C层) 交替组成, 其中S层与Huble-Wiesel层级模型中的简单细胞层或者低阶超复杂细胞层相对应, C层对应于复杂细胞层或者高阶超复杂细胞层.S层能够最大程度地响应感受野内的特定边缘刺激, 提取其输入层的局部特征, C层对来自确切位置的刺激具有局部不敏感性.尽管在神经认知机中没有像BP算法那样的全局监督学习过程可利用, 但它仍可认为是CNN的第一个工程实现网络, 卷积和池化 (也称作下采样) 分别受启发于Hubel-Wiesel概念的简单细胞和复杂细胞, 它能够准确识别具有位移和轻微形变的输入模式[29,30].随后, LeCun等人基于Fukushima的研究工作使用BP算法设计并训练了CNN (该模型称为LeNet-5) , LeNet-5是经典的CNN结构, 后续有许多工作基于此进行改进, 它在一些模式识别领域中取得了良好的分类效果[19].
CNN的基本结构由输入层、卷积层 (convolutional layer) 、池化层 (pooling layer, 也称为取样层) 、全连接层及输出层构成.卷积层和池化层一般会取若干个, 采用卷积层和池化层交替设置, 即一个卷积层连接一个池化层, 池化层后再连接一个卷积层, 依此类推.由于卷积层中输出特征面的每个神经元与其输入进行局部连接, 并通过对应的连接权值与局部输入进行加权求和再加上偏置值, 得到该神经元输入值, 该过程等同于卷积过程, CNN也由此而得名。
3.1 卷积层
卷积层由多个特征面 (Feature Map) 组成, 每个特征面由多个神经元组成, 它的每一个神经元通过卷积核与上一层特征面的局部区域相连.卷积核是一个权值矩阵 (如对于二维图像而言可为3×3或5×5矩阵) [19,31].CNN的卷积层通过卷积操作提取输入的不同特征, 第1层卷积层提取低级特征如边缘、线条、角落, 更高层的卷积层提取更高级的特征 (1) .为了能够更好地理解CNN, 下面以一维CNN (1D CNN) 为例, 二维和三维CNN可依此进行拓展.图3所示为一维CNN的卷积层和池化层结构示意图, 最顶层为池化层, 中间层为卷积层, 最底层为卷积层的输入层.
由图3可看出卷积层的神经元被组织到各个特征面中, 每个神经元通过一组权值被连接到上一层特征面的局部区域, 即卷积层中的神经元与其输入层中的特征面进行局部连接.然后将该局部加权和传递给一个非线性函数如ReLU函数即可获得卷积层中每个神经元的输出值.在同一个输入特征面和同一个输出特征面中, CNN的权值共享, 如图3所示, 权值共享发生在同一种颜色当中, 不同颜色权值不共享.通过权值共享可以减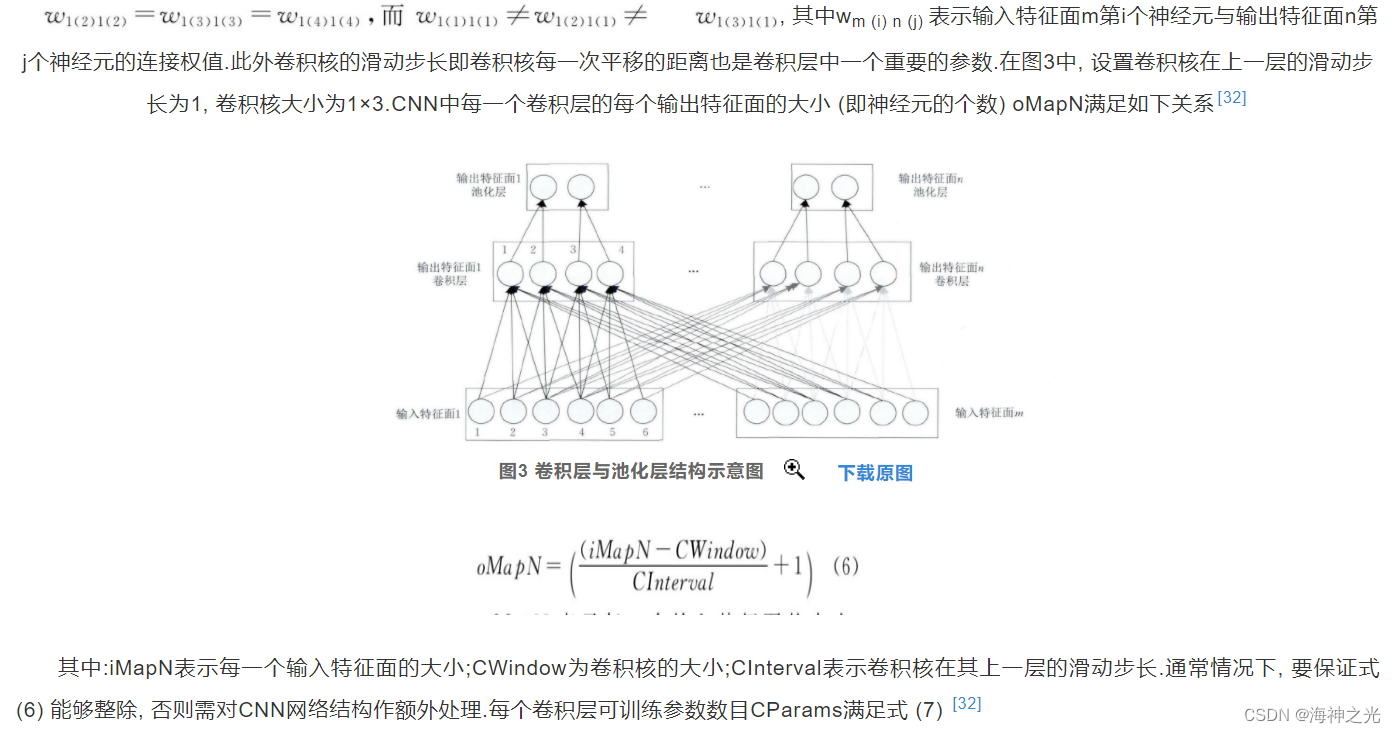
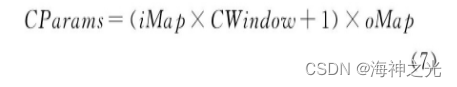
其中:oMap为每个卷积层输出特征面的个数;iMap为输入特征面个数.1表示偏置, 在同一个输出特征面中偏置也共享.假设卷积层中输出特征面n第k个神经元的输出值为xnkout, 而xmhin表示其输入特征面m第h个神经元的输出值, 以图3为例, 则.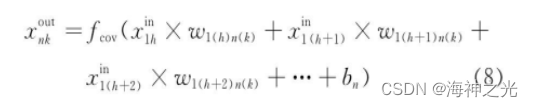
式 (8) 中, bn为输出特征面n的偏置值.fcov (·) 为非线性激励函数.在传统的CNN中, 激励函数一般使用饱和非线性函数 (saturating nonlinearity) 如sigmoid函数、tanh函数等.相比较于饱和非线性函数, 不饱和非线性函数 (non-saturating nonlinearity) 能够解决梯度爆炸/梯度消失问题, 同时也能够加快收敛速度[33].Jarrett等人[34]探讨了卷积网络中不同的纠正非线性函数 (rectified nonlinearity, 包括max (0, x) 非线性函数) , 通过实验发现它们能够显著提升卷积网络的性能, Nair等人[25]也验证了这一结论.因此在目前的CNN结构中常用不饱和非线性函数作为卷积层的激励函数如ReLU函数.ReLU函数的计算公式如下所示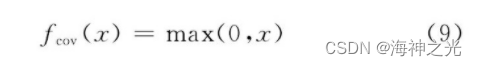
图4中实线为ReLU曲线, 虚线为tanh曲线.对于ReLU而言, 如果输入大于0, 则输出与输入相等, 否则输出为0.从图4可以看出, 使用ReLU函数, 输出不会随着输入的逐渐增加而趋于饱和.Chen在其报告中分析了影响CNN性能的3个因素:层数、特征面的数目及网络组织 (1) .该报告使用9种结构的CNN进行中文手写体识别实验, 通过统计测试结果得到具有较小卷积核的CNN结构的一些结论: (1) 增加网络的深度能够提升准确率; (2) 增加特征面的数目也可以提升准确率; (3) 增加一个卷积层比增加一个全连接层更能获得一个更高的准确率.Bengio等人[35]指出深度网络结构具有两个优点: (1) 可以促进特征的重复利用; (2) 能够获取高层表达中更抽象的特征, 由于更抽象的概念可根据抽象性更弱的概念来构造, 因此深度结构能够获取更抽象的表达, 例如在CNN中通过池化操作来建立这种抽象, 更抽象的概念通常对输入的大部分局部变化具有不变性.He等人[36]探讨了在限定计算复杂度和时间上如何平衡CNN网络结构中深度、特征面数目、卷积核大小等因素的问题.该文献首先研究了深度 (Depth) 与卷积核大小间的关系, 采用较小的卷积核替代较大的卷积核, 同时增加网络深度来增加复杂度, 通过实验结果表明网络深度比卷积核大小更重要;当时间复杂度大致相同时, 具有更小卷积核且深度更深的CNN结构比具有更大卷积核同时深度更浅的CNN结构能够获得更好的实验结果.其次, 该文献也研究了网络深度和特征面数目间的关系, CNN网络结构设置为:在增加网络深度时适当减少特征面的数目, 同时卷积核的大小保持不变, 实验结果表明, 深度越深, 网络的性能越好;然而随着深度的增加, 网络性能也逐渐达到饱和.此外, 该文献还通过固定网络深度研究了特征面数目和卷积核大小间的关系, 通过实验对比, 发现特征面数目和卷积核大小的优先级差不多, 其发挥的作用均没有网络深度大.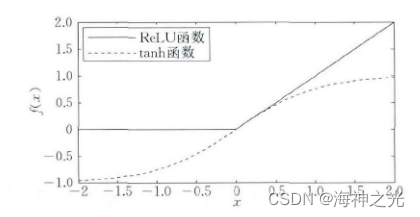
图4 ReLU与tanh函数曲线图
在CNN结构中, 深度越深、特征面数目越多, 则网络能够表示的特征空间也就越大、网络学习能力也越强, 然而也会使网络的计算更复杂, 极易出现过拟合的现象.因而, 在实际应用中应适当选取网络深度、特征面数目、卷积核的大小及卷积时滑动的步长, 以使在训练能够获得一个好的模型的同时还能减少训练时间.
3.2 池化层
池化层紧跟在卷积层之后, 同样由多个特征面组成, 它的每一个特征面唯一对应于其上一层的一个特征面, 不会改变特征面的个数.如图3, 卷积层是池化层的输入层, 卷积层的一个特征面与池化层中的一个特征面唯一对应, 且池化层的神经元也与其输入层的局部接受域相连, 不同神经元局部接受域不重叠.池化层旨在通过降低特征面的分辨率来获得具有空间不变性的特征[37].池化层起到二次提取特征的作用, 它的每个神经元对局部接受域进行池化操作.常用的池化方法有最大池化即取局部接受域中值最大的点、均值池化即对局部接受域中的所有值求均值、随机池化[38,39].Boureau等人[40]给出了关于最大池化和均值池化详细的理论分析, 通过分析得出以下一些预测: (1) 最大池化特别适用于分离非常稀疏的特征; (2) 使用局部区域内所有的采样点去执行池化操作也许不是最优的, 例如均值池化就利用了局部接受域内的所有采样点.Boureau等人[41]比较了最大池化和均值池化两种方法, 通过实验发现:当分类层采用线性分类器如线性SVM时, 最大池化方法比均值池化能够获得一个更好的分类性能.随机池化方法是对局部接受域采样点按照其值大小赋予概率值, 再根据概率值大小随机选择, 该池化方法确保了特征面中不是最大激励的神经元也能够被利用到[37].随机池化具有最大池化的优点, 同时由于随机性它能够避免过拟合.此外, 还有混合池化、空间金字塔池化、频谱池化等池化方法[37].在通常所采用的池化方法中, 池化层的同一个特征面不同神经元与上一层的局部接受域不重叠, 然而也可以采用重叠池化的方法.所谓重叠池化方法就是相邻的池化窗口间有重叠区域.Krizhevsky等采用重叠池化框架使top-1和top-5的错误率分别降低了0.4%和0.3%, 与无重叠池化框架相比, 其泛化能力更强, 更不易产生过拟合.设池化层中第n个输出特征面第l个神经元的输出值为tnlout, 同样以图3为例, 则有: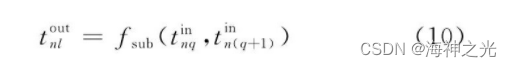
其中:tnqin表示池化层的第n个输入特征面第q个神经元的输出值;fsub (·) 可为取最大值函数、取均值函数等.
池化层在上一层滑动的窗口也称为池化核.事实上, CNN中的卷积核与池化核相当于HubelWiesel模型中感受野在工程上的实现, 卷积层用来模拟Hubel-Wiesel理论的简单细胞, 池化层模拟该理论的复杂细胞.CNN中每个池化层的每一个输出特征面的大小 (神经元个数) DoMapN为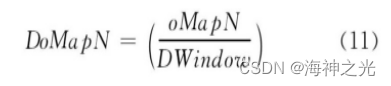
其中, 池化核的大小为DWindow, 在图3中DWindow=2.池化层通过减少卷积层间的连接数量, 即通过池化操作使神经元数量减少, 降低了网络模型的计算量.
3.3 全连接层
在CNN结构中, 经多个卷积层和池化层后, 连接着1个或1个以上的全连接层.与MLP类似, 全连接层中的每个神经元与其前一层的所有神经元进行全连接.全连接层可以整合卷积层或者池化层中具有类别区分性的局部信息[42].为了提升CNN网络性能, 全连接层每个神经元的激励函数一般采用ReLU函数[43].最后一层全连接层的输出值被传递给一个输出层, 可以采用softmax逻辑回归 (softmax regression) 进行分类, 该层也可称为softmax层 (softmax layer) .对于一个具体的分类任务, 选择一个合适的损失函数是十分重要的, Gu等人[37]介绍了CNN几种常用的损失函数并分析了它们各自的特点.通常, CNN的全连接层与MLP结构一样, CNN的训练算法也多采用BP算法.
当一个大的前馈神经网络训练一个小的数据集时, 由于它的高容量, 它在留存测试数据 (held-out test data, 也可称为校验集) 上通常表现不佳[30].为了避免训练过拟合, 常在全连接层中采用正则化方法———丢失数据 (dropout) 技术, 即使隐层神经元的输出值以0.5的概率变为0, 通过该技术部分隐层节点失效, 这些节点不参加CNN的前向传播过程, 也不会参加后向传播过程[24,30].对于每次输入到网络中的样本, 由于dropout技术的随机性, 它对应的网络结构不相同, 但是所有的这些结构共享权值[24].由于一个神经元不能依赖于其它特定神经元而存在, 所以这种技术降低了神经元间相互适应的复杂性, 使神经元学习能够得到更鲁棒的特征[24].目前, 关于CNN的研究大都采用ReLU+dropout技术, 并取得了很好的分类性能[24,44,45].
3.4 特征面
特征面数目作为CNN的一个重要参数, 它通常是根据实际应用进行设置的, 如果特征面个数过少, 可能会使一些有利于网络学习的特征被忽略掉, 从而不利于网络的学习;但是如果特征面个数过多, 可训练参数个数及网络训练时间也会增加, 这同样不利于学习网络模型.Chuo等人[46]提出了一种理论方法用于确定最佳的特征面数目, 然而该方法仅对极小的接受域有效, 它不能够推广到任意大小的接受域.该文献通过实验发现:与每层特征面数目均相同的CNN结构相比, 金字塔架构 (该网络结构的特征面数目按倍数增加) 更能有效利用计算资源.目前, 对于CNN网络特征面数目的设定通常采用的是人工设置方法, 然后进行实验并观察所得训练模型的分类性能, 最终根据网络训练时间和分类性能来选取特征面数目.
3.5 CNN结构的进一步说明
CNN的实现过程实际上已经包含了特征提取过程, 以图5、图6为例直观地显示CNN提取的特征.Cao等人[47]采用CNN进行指纹方向场评估, 图5为其模型结构.图5共有3个卷积层 (C1, C3, C5) 、2个池化层 (M2, M4) 、1个全连接层 (F6) 和1个输出层 (O7) .输入的大小为160×160, C1中96×11×11×1 (4) 表示C1层有96个大小为11×11的卷积核, 1为它的输入特征面个数, 4是卷积核在其输入特征面上的滑动步长, 38×38为每个输出特征面的大小.卷积层通过卷积操作提取其前一层的各种不同的局部特征, 由图5可看出, C1层提取输入图像的边缘、轮廓特征, 可看成是边缘检测器.池化层的作用是在语义上把相似的特征合并起来, 池化层通过池化操作使得特征对噪声和变形具有鲁棒性[11].从图上可看出, 各层所提取的特征以增强的方式从不同角度表现原始图像, 并且随着层数的增加, 其表现形式越来越抽象[48].全连接层F6中的每个神经元与其前一层进行全连接, 该层将前期所提取的各种局部特征综合起来, 最后通过输出层得到每个类别的后验概率.从模式分类角度来说, 满足Fisher判别准则的特征最有利于分类, 通过正则化方法 (dropout方法) , 网络参数得到有效调整, 从而使全连接层提取的特征尽量满足Fisher判别准则, 最终有利于分类[48].图6给出了CNN提取心电图 (electrocardiogram, ECG) 特征的过程, 首先通过卷积单元A1、B1、C1 (其中每个卷积单元包括一个卷积层和一个池化层) 提取特征, 最后由全连接层汇总所有局部特征.由图中也可以看出, 层数越高, 特征的表现形式也越抽象.显然, 这些特征并没有临床诊断的物理意义, 仅仅是数理值[48].
三、部分源代码
%%
X1=rand(100,2048);
X2=20*rand(100,2048); %%%生成两类幅值不同的随机序列,作为两类待分类样本
Xtrain1=[X1;X2];
for i=1:1:200
for j=1:1:2048
Xtrain(1,j,1,i)=Xtrain1(i,j);%%输入数据维度转化
end
end
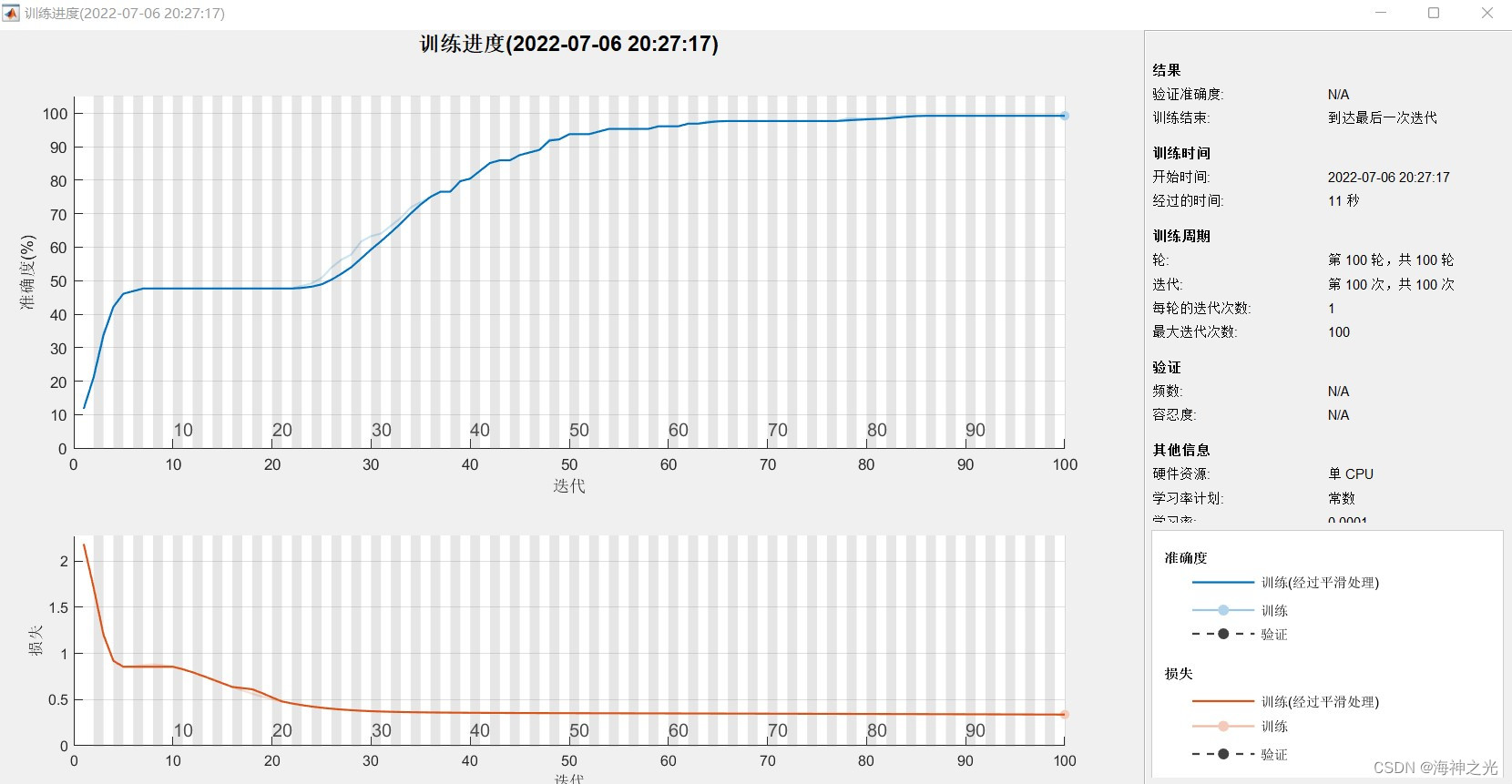
四、运行结果
五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 包子阳,余继周,杨杉.智能优化算法及其MATLAB实例(第2版)[M].电子工业出版社,2016.
[2]张岩,吴水根.MATLAB优化算法源代码[M].清华大学出版社,2017.
[3]周品.MATLAB 神经网络设计与应用[M].清华大学出版社,2013.
[4]陈明.MATLAB神经网络原理与实例精解[M].清华大学出版社,2013.
[5]周飞燕,金林鹏,董军.卷积神经网络研究综述[M].计算机学报. 2017,40(06)
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除
边栏推荐
- Common SQL statement collation: MySQL
- The post-90s resigned and started a business, saying they would kill cloud database
- Apprentissage comparatif non supervisé des caractéristiques visuelles par les assignations de groupes de contrôle
- 大佬们有没有人遇到过 flink oracle cdc,读取一个没有更新操作的表,隔十几秒就重复读取
- What is high cohesion and low coupling?
- electron添加SQLite数据库
- How much do you know about excel formula?
- RationalDMIS2022 高级编程宏程序
- Learning notes | data Xiaobai uses dataease to make a large data screen
- 相机标定(2): 单目相机标定总结
猜你喜欢
How much do you know about excel formula?
千人規模互聯網公司研發效能成功之路
相机标定(2): 单目相机标定总结

【最短路】ACwing 1127. 香甜的黄油(堆优化的dijsktra或spfa)
. Net Maui performance improvement

对比学习之 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments

STM32F1与STM32CubeIDE编程实例-MAX7219驱动8位7段数码管(基于SPI)
Unsupervised learning of visual features by contracting cluster assignments
本地navicat连接liunx下的oracle报权限不足
Excel公式知多少?
随机推荐
什么是高内聚、低耦合?
In depth learning autumn recruitment interview questions collection (1)
STM32 entry development uses IIC hardware timing to read and write AT24C08 (EEPROM)
如何在博客中添加Aplayer音乐播放器
Electron adding SQLite database
正在运行的Kubernetes集群想要调整Pod的网段地址
對比學習之 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
STM32 entry development write DS18B20 temperature sensor driver (read ambient temperature, support cascade)
Onedns helps college industry network security
Verilog design responder [with source code]
STM32 entry development NEC infrared protocol decoding (ultra low cost wireless transmission scheme)
Blog moved to Zhihu
What is cloud computing?
一度辍学的数学差生,获得今年菲尔兹奖
0.96 inch IIC LCD driver based on stc8g1k08
【最短路】Acwing1128信使:floyd最短路
Various uses of vim are very practical. I learned and summarized them in my work
技术分享 | 抓包分析 TCP 协议
Half of the people don't know the difference between for and foreach???
相机标定(1): 单目相机标定及张正友标定基本原理