当前位置:网站首页>对比学习之 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
对比学习之 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
2022-07-07 09:09:00 【InfoQ】

- 诸神黄昏时代的对比学习
- “军备竞赛”时期的对比学习好。
- 将整个imagenet做成字典,从中抽取一个mini batch作为正样本。再从中随机抽取4096条作为负样本。
- 从数据集中抽取一个mini batch对其增广,使用一个孪生网络,将原图放进一个网络,将增强之后的图放进另一个网络,二者同时进行训练,对二者使用一个NCE loss或者infoNCE loss。一张图片和它的增广作为正样本,剩余的图片及其增广作为负样本。
- 从数据集中抽取一个mini batch对其进行两次增广,使用一个孪生网络,将一组图片增强放进一个网络,将另一组图片增强放进另一个网络,二者同时进行训练,对二者使用一个NCE loss或者infoNCE loss。
- 它可能会重复的抽取到同一数据。虽然你数据集有很多图片,但是你从中抽可能会抽到相同的图片。极端的情况下,如果你抽到一组图片作为正样本,然后你又抽到同样重复的一组图片作为负样本。那这样就会对训练造成影响。
- 也可能不具有整个数据集的代表性。比如这个数据其实有很多很多种动物,但是你抽到的都是狗,这样数据就是没有代表性的。
- 当然这样的选取的越全面效果越好,但是如果你选取的过多的负样本又会造成计算资源的浪费。
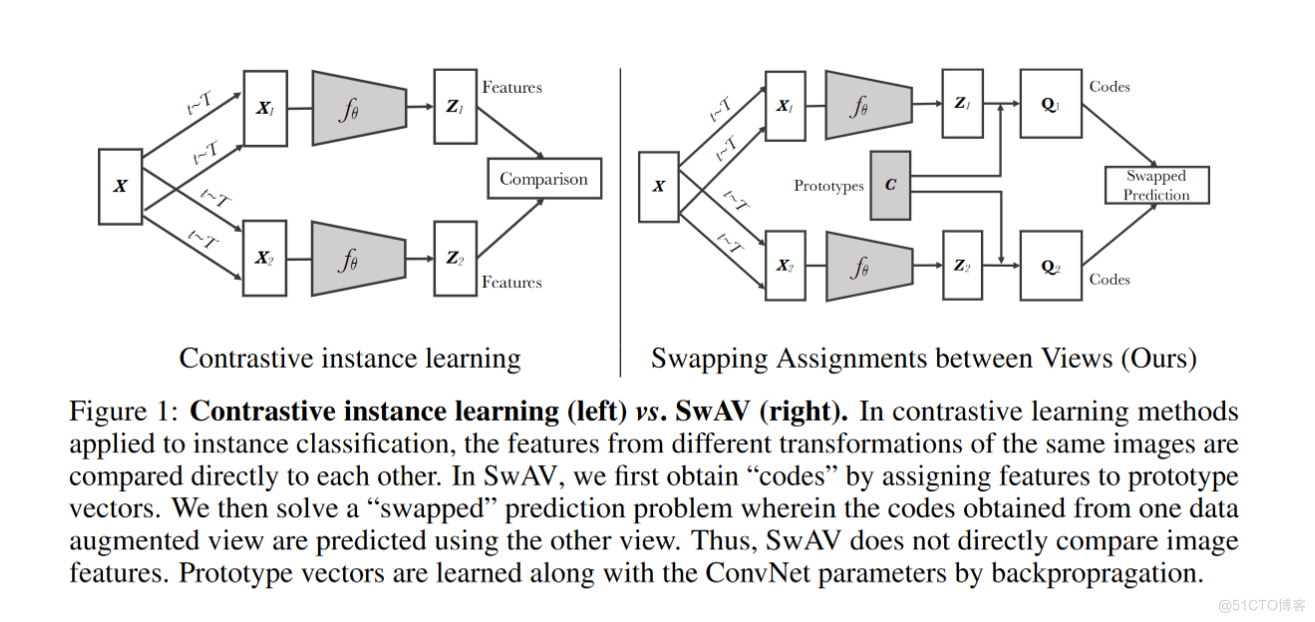
- 先说重复问题:因为你使用的是聚类中心进行比较。虽然是不同的聚类中心,那么他肯定不可能出现重复的情况。
- 再说一下没有代表性的问题:聚类就是将众多的图片聚成不同的类别。与每一个类别的中心进行对比,是绝对具有代表性的。
- 再说一下过去有过多负样本造成资源浪费的问题。如果要跟很多的负样本去做类比,可能就需要成千上万的负样本,而且即使如此也只是一个近似,而如果只是跟聚类中心做对比,则可以用几百或者最多3,000个聚类中心,就足以表示了。大大减少了计算资源消耗。
边栏推荐
- [untitled]
- Une fois que l'uniapp a sauté de la page dans onlaunch, cliquez sur Event Failure resolution
- verilog设计抢答器【附源码】
- Hash / (understanding, implementation and application)
- 2021-04-23
- 网络协议 概念
- The difference between monotonicity constraint and anti monotonicity constraint
- SQL Server knowledge collection 11: Constraints
- Network foundation (1)
- [pyqt] the cellwidget in tablewidget uses signal and slot mechanism
猜你喜欢

Arduino board description
关于在云服务器上(这里用腾讯云)安装mysql8.0并使本地可以远程连接的方法
2021-05-21
![[machine learning 03] Lagrange multiplier method](/img/14/7d4eb5679606e272f137ddbda4938c.png)
[machine learning 03] Lagrange multiplier method
![[STM32] actual combat 3.1 - drive 42 stepper motors with STM32 and tb6600 drivers (I)](/img/cd/7cd8e2e77419c65d633a2a235b2362.png)
[STM32] actual combat 3.1 - drive 42 stepper motors with STM32 and tb6600 drivers (I)
seata 1.3.0 四種模式解决分布式事務(AT、TCC、SAGA、XA)

Interprocess communication (IPC)

July 10, 2022 "five heart public welfare" activity notice + registration entry (two-dimensional code)
2021-04-23
![[untitled]](/img/c2/d70d052b7e9587dc81c622f62f8566.jpg)
[untitled]
随机推荐
After the uniapp jumps to the page in onlaunch, click the event failure solution
【pyqt】tableWidget里的cellWidget使用信号与槽机制
Différences entre les contraintes monotones et anti - monotones
2021 summary and 2022 outlook
Typescript interface inheritance
Using ENSP to do MPLS pseudo wire test
Use of dotween
关于jmeter中编写shell脚本json的应用
Wallhaven壁纸桌面版
Vuthink正确安装过程
Unity websocket client
Typescript interface inheritance
RationalDMIS2022 高级编程宏程序
Ffmpeg record a video command from RTSP
uniapp 在onLaunch中跳轉頁面後,點擊事件失效解决方法
面试被问到了解哪些开发模型?看这一篇就够了
Go Slice 比较
The eighth training assignment
[untitled]
Unity script visualization about layout code