当前位置:网站首页>Some opinions and code implementation of Siou loss: more powerful learning for bounding box regression zhora gevorgyan
Some opinions and code implementation of Siou loss: more powerful learning for bounding box regression zhora gevorgyan
2022-07-07 11:32:00 【Optimistic, medium】
Recently, many official account are pushing this article , But I have some problems in the process of reading , Because the code is not open source , Understanding may not be correct , So first record , After open source, we can understand it more deeply compared with the code , I also hope that if some big guys see this article , Can you give me some advice on my immature views .
The final loss function of the experiment is calculated as follows :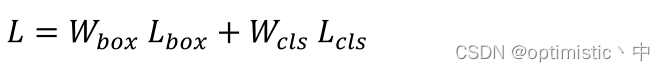
among L c l s L_{cls} Lcls It is used. focal loss, W b o x W_{box} Wbox and W c l s W_{cls} Wcls The weight parameters are calculated according to genetic algorithm , L b o x L_{box} Lbox It is what this article mentions SIoU Loss , The calculation is as follows :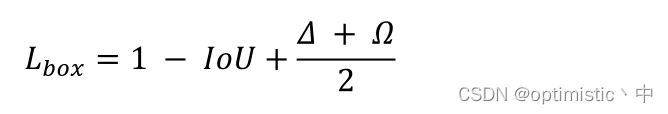
It mainly involves four parts of losses : Angle loss 、 Distance loss 、 Shape loss 、IoU Loss
1. Angle loss 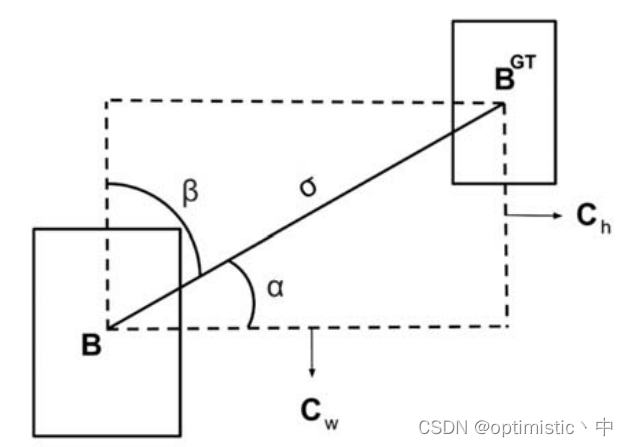
Here the author thinks , Angle factor can be considered , First, make the prediction box return to the same horizontal line or vertical line as the truth box , I agree with that , Can accelerate convergence , The author evaluates the loss through the following formula 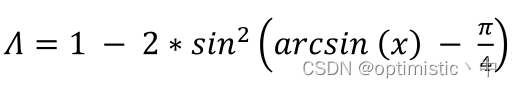
The formula consists of two parts , The first part is 1 − 2 s i n 2 ( x ) 1-2sin^2(x) 1−2sin2(x), In fact, it is c o s ( 2 x ) cos(2x) cos(2x), Make the x > 0 x>0 x>0 The situation of , Its value is only in x x x by π / 4 π/4 π/4 Take the minimum when , obtain 0, And in the x x x by 0 Take the maximum when , obtain 1; The second part is a r c s i n ( x ) − π / 4 arcsin(x)-π/4 arcsin(x)−π/4, among a r c s i n ( x ) arcsin(x) arcsin(x) That is to say α α α, It needs to be done − π / 4 -π/4 −π/4 The operation of is to consider moving the prediction box towards the side with a smaller angle , because β β β be equal to π / 2 − α π/2-α π/2−α, both − π / 4 -π/4 −π/4 The latter numbers are opposite to each other , after c o s cos cos The calculated value of the function is the same , When α α α by 0 When , Its loss is the smallest , But for π / 4 π/4 π/4 It's the biggest when I'm young . Finally, the prediction box moves faster to the horizontal or vertical line where the truth box is located .
2. Distance loss 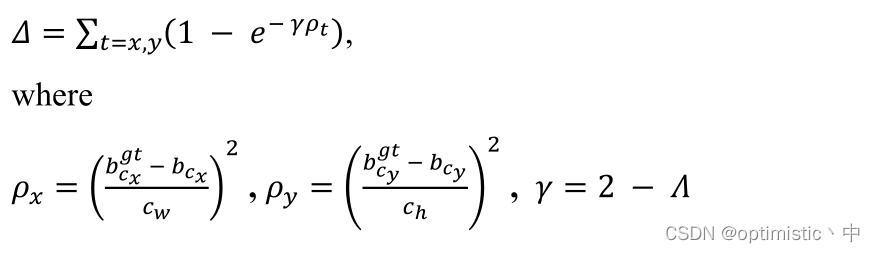
(1) about ρ x ρ_x ρx and ρ y ρ_y ρy The calculation of , I was still thinking that this would not always calculate the identity 1 Do you , Then I found the figure in the paper 3 The diagram is given , there c w c_w cw and c h c_h ch Refers to the length of the smallest external frame .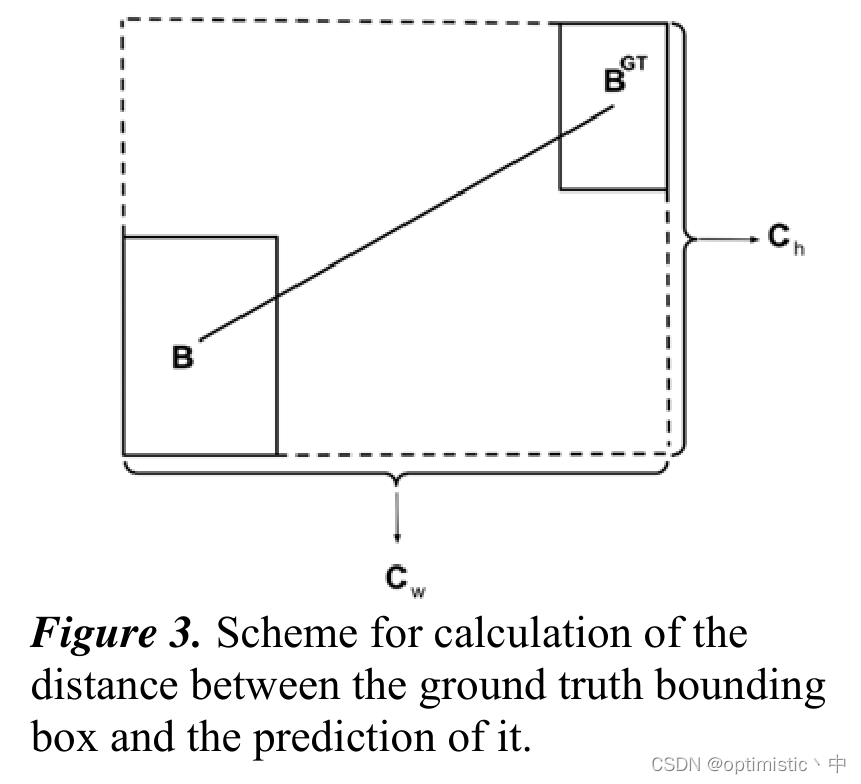
(2) about γ γ γ Calculation method of , My understanding is that first of all, we can get Λ Λ Λ The scope of should be [0,1], Here we pass 2 − Λ 2-Λ 2−Λ, First, prevent γ γ γ by 0 when ρ t ρ_t ρt Failure situation , Secondly, make Λ Λ Λ The smaller it is , ρ t ρ_t ρt The greater the impact of change on losses .
3. Shape loss 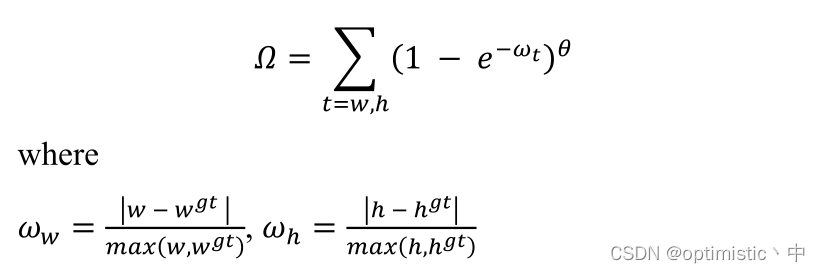
Here and EIOU equally , Both take into account the true aspect ratio between the prediction box and the truth box , But for the ω x ω_x ωx and ω y ω_y ωy The calculation of , And EIOU We also need to calculate that the minimum frame length and width that can surround two frames are different , Only the length and width attributes of the truth box and the prediction box are used here , Less computation , It's supposed to be faster , But the specific effect is not clear . in addition , ω t ω_t ωt The range is [0,1], I don't think it is necessary to pass 1 − e − ω t 1-e^{-ω_t} 1−e−ωt Further calculation , Maybe the effect will be better , Finally, for θ θ θ The introduction of , It's not very understandable here .
(1) First of all, I don't understand why it would be better to introduce this factor .
(2) Secondly, distance loss can also introduce factors , Why not introduce .
4.IoU Loss
and GIOU The same as mentioned in , Here is the press 1 − I o U 1-IoU 1−IoU To calculate the
For some weights and in the article θ θ θ Parameters are calculated by genetic algorithm on the data set , I don't know the improvement effect of this part , Because the code is not open source , There are also doubts about some of these calculation methods , Therefore, it is impossible to verify the real effect of each improvement point
Here's my comment on SIoU A simple reproduction of , If there is any mistake, please correct it
#(x1,y1) and (x2,y2) They are the central coordinates of the prediction box and the real box
x1 = (b1_x1 + b1_x2) / 2
x2 = (b2_x1 + b2_x2) / 2
y1 = (b1_y1 + b1_y2) / 2
y2 = (b2_y1 + b2_y2) / 2
x_dis = torch.max(x1, x2) - torch.min(x1, x2)
y_dis = torch.max(y1, y2) - torch.min(y1, y2)
sigma = torch.pow(x_dis ** 2 + y_dis ** 2, 0.5) + eps
alpha = y_dis / sigma
beta = x_dis / sigma
threshold = pow(2, 0.5) / 2
sin_alpha = torch.where(alpha > threshold, beta, alpha)
#1 - 2 * sin(x) ** 2 Equate to cos(2x)
angle_cost = torch.cos(torch.arcsin(sin_alpha) * 2 - np.pi / 2)
cw += eps
ch += eps
rho_x = (x_dis / cw) ** 2
rho_y = (y_dis / ch) ** 2
gamma = 2 - angle_cost
distance_cost = 2 - torch.exp(-1 * gamma * rho_x) - torch.exp(-1 * gamma * rho_y)
omiga_w = torch.abs(w1 - w2) / (torch.max(w1, w2) + eps)
omiga_h = torch.abs(h1 - h2) / (torch.max(h1, h2) + eps)
# In the original paper theta stay 4 near , Range 2 To 6
theta = 4
shape_cost = torch.pow(1 - torch.exp(-1 * omiga_w), theta) + torch.pow(1 - torch.exp(-1 * omiga_h), theta)
return iou - 0.5 * (distance_cost + shape_cost)
边栏推荐
- .NET MAUI 性能提升
- electron添加SQLite数据库
- The annual salary of general test is 15W, and the annual salary of test and development is 30w+. What is the difference between the two?
- Easyui学习整理笔记
- 竟然有一半的人不知道 for 与 foreach 的区别???
- 通过环境变量将 Pod 信息呈现给容器
- 常用sql语句整理:mysql
- Android 面试知识点
- TDengine 社区问题双周精选 | 第二期
- 聊聊SOC启动(七) uboot启动流程三
猜你喜欢
Talk about SOC startup (VI) uboot startup process II
基于华为云IOT设计智能称重系统(STM32)

There are so many factors that imprison you

使用MeterSphere让你的测试工作持续高效
About the application of writing shell script JSON in JMeter
在我有限的软件测试经历里,一段专职的自动化测试经验总结
Talk about SOC startup (VII) uboot startup process III
解决VSCode只能开两个标签页的问题
如何在博客中添加Aplayer音乐播放器
正在運行的Kubernetes集群想要調整Pod的網段地址
随机推荐
After the uniapp jumps to the page in onlaunch, click the event failure solution
R語言使用magick包的image_mosaic函數和image_flatten函數把多張圖片堆疊在一起形成堆疊組合圖像(Stack layers on top of each other)
技术分享 | 抓包分析 TCP 协议
Verilog realizes nixie tube display driver [with source code]
Apprentissage comparatif non supervisé des caractéristiques visuelles par les assignations de groupes de contrôle
基于华为云IOT设计智能称重系统(STM32)
sink 消费 到 MySQL, 数据库表里面已经设置了 自增主键, flink 里面,如何 操作?
聊聊SOC启动(十一) 内核初始化
学习笔记|数据小白使用DataEase制作数据大屏
Socket socket programming
The database synchronization tool dbsync adds support for mongodb and es
关于jmeter中编写shell脚本json的应用
Activity生命周期
一度辍学的数学差生,获得今年菲尔兹奖
Blog moved to Zhihu
Automated testing framework
Distributed database master-slave configuration (MySQL)
verilog设计抢答器【附源码】
网络协议 概念
Creative information was surveyed by 2 institutions: greatdb database has been deployed in 9 places