当前位置:网站首页>【系统设计】指标监控和告警系统
【系统设计】指标监控和告警系统
2022-07-07 09:35:00 【dotNET跨平台】
在本文中,我们将探讨如何设计一个可扩展的指标监控和告警系统。一个好的监控和告警系统,对基础设施的可观察性,高可用性,可靠性方面发挥着关键作用。
下图显示了市面上一些流行的指标监控和告警服务。

接下来,我们会设计一个类似的服务,可以供大公司内部使用。
设计要求
从一个小明去面试的故事开始。

面试官:如果让你设计一个指标监控和告警系统,你会怎么做?
小明:好的,这个系统是为公司内部使用的,还是设计像 Datadog 这种 SaaS 服务?
面试官:很好的问题,目前这个系统只是公司内部使用。
小明:我们想收集哪些指标信息?
面试官:包括操作系统的指标信息,中间件的指标,以及运行的应用服务的 qps 这些指标。
小明:我们用这个系统监控的基础设施的规模是多大的?
面试官:1亿日活跃用户,1000个服务器池,每个池 100 台机器。
小明:指标数据要保存多长时间呢?
面试官:我们想保留一年。
小明:好吧,为了较长时间的存储,可以降低指标数据的分辨率吗?
面试官:很好的问题,对于最新的数据,会保存 7 天,7天之后可以降低到1分钟的分辨率,而到 30 天之后,可以按照 1 小时的分辨率做进一步的汇总。
小明:支持的告警渠道有哪些?
面试官:邮件,电 钉钉,企业微信,Http Endpoint。
小明:我们需要收集日志吗?还有是否需要支持分布式系统的链路追踪?
面试官:目前专注于指标,其他的暂时不考虑。
小明:好的,大概都了解了。
总结一下,被监控的基础设施是大规模的,以及需要支持各种维度的指标。另外,整体的系统也有较高的要求,要考虑到可扩展性,低延迟,可靠性和灵活性。
基础知识
一个指标监控和告警系统通常包含五个组件,如下图所示

1. 数据收集:从不同的数据源收集指标数据。
2. 数据传输:把指标数据发送到指标监控系统。
3. 数据存储:存储指标数据。
4. 告警:分析接收到的数据,检测到异常时可以发出告警通知。
5. 可视化:可视化页面,以图形,图表的形式呈现数据。
数据模式
指标数据通常会保存为一个时间序列,其中包含一组值及其相关的时间戳。
序列本身可以通过名称进行唯一标识,也可以通过一组标签进行标识。
让我们看两个例子。
示例1:生产服务器 i631 在 20:00 的 CPU 负载是多少?

上图标记的数据点可以用下面的格式表示

在上面的示例中,时间序列由指标名称,标签(host:i631,env:prod),时间戳以及对应的值构成。
示例2:过去 10 分钟内上海地区所有 Web 服务器的平均 CPU 负载是多少?
从概念上来讲,我们会查询出和下面类似的内容
CPU.load host=webserver01,region=shanghai 1613707265 50
CPU.load host=webserver01,region=shanghai 1613707270 62
CPU.load host=webserver02,region=shanghai 1613707275 43我们可以通过上面每行末尾的值计算平均 CPU 负载,上面的数据格式也称为行协议。是市面上很多监控软件比较常用的输入格式,Prometheus 和 OpenTSDB 就是两个例子。
每个时间序列都包含以下内容:
• 指标名称,字符串类型的 metric name 。
• 一个键值对的数组,表示指标的标签,List<key,value>
• 一个包含时间戳和对应值的的数组,List <value, timestamp>
数据存储
数据存储是设计的核心部分,不建议构建自己的存储系统,也不建议使用常规的存储系统(比如 MySQL)来完成这项工作。
理论下,常规数据库可以支持时间序列数据, 但是需要数据库专家级别的调优后,才能满足数据量比较大的场景需求。
具体点说,关系型数据库没有对时间序列数据进行优化,有以下几点原因
• 在滚动时间窗口中计算平均值,需要编写复杂且难以阅读的 SQL。
• 为了支持标签(tag/label)数据,我们需要给每个标签加一个索引。
• 相比之下,关系型数据库在持续的高并发写入操作时表现不佳。
那 NoSQL 怎么样呢?理论上,市面上的少数 NoSQL 数据库可以有效地处理时间序列数据。比如 Cassandra 和 Bigtable 都可以。但是,想要满足高效存储和查询数据的需求,以及构建可扩展的系统,需要深入了解每个 NoSQL 的内部工作原理。
相比之下,专门对时间序列数据优化的时序数据库,更适合这种场景。
OpenTSDB 是一个分布式时序数据库,但由于它基于 Hadoop 和 HBase,运行 Hadoop/HBase 集群也会带来复杂性。Twitter 使用了 MetricsDB 时序数据库存储指标数据,而亚马逊提供了 Timestream 时序数据库服务。
根据 DB-engines 的报告,两个最流行的时序数据库是 InfluxDB 和 Prometheus ,它们可以存储大量时序数据,并支持快速地对这些数据进行实时分析。
如下图所示,8 核 CPU 和 32 GB RAM 的 InfluxDB 每秒可以处理超过 250,000 次写入。

高层次设计

• Metrics Source 指标来源,应用服务,数据库,消息队列等。
• Metrics Collector 指标收集器。
• Time series DB 时序数据库,存储指标数据。
• Query Service 查询服务,向外提供指标查询接口。
• Alerting System 告警系统,检测到异常时,发送告警通知。
• Visualization System 可视化,以图表的形式展示指标。
深入设计

现在,让我们聚焦于数据收集流程。主要有推和拉两种方式。
拉模式

上图显示了使用了拉模式的数据收集,单独设置了数据收集器,定期从运行的应用中拉取指标数据。
这里有一个问题,数据收集器如何知道每个数据源的地址? 一个比较好的方案是引入服务注册发现组件,比如 etcd,ZooKeeper,如下

下图展示了我们现在的数据拉取流程。

1. 指标收集器从服务发现组件中获取元数据,包括拉取间隔,IP 地址,超时,重试参数等。
2. 指标收集器通过设定的 HTTP 端点获取指标数据。
在数据量比较大的场景下,单个指标收集器是独木难支的,我们必须使用一组指标收集器。但是多个收集器和多个数据源之间应该如何协调,才能正常工作不发生冲突呢?
一致性哈希很适合这种场景,我们可以把数据源映射到哈希环上,如下

这样可以保证每个指标收集器都有对应的数据源,相互工作且不会发生冲突。
推模式
如下图所示,在推模式中,各种指标数据源(Web 应用,数据库,消息队列)直接发送到指标收集器。

在推模式中,需要在每个被监控的服务器上安装收集器代理,它可以收集服务器的指标数据,然后定期的发送给指标收集器。
推和拉两种模式哪种更好?没有固定的答案,这两个方案都是可行的,甚至在一些复杂场景中,需要同时支持推和拉。
扩展数据传输

现在,让我们主要关注指标收集器和时序数据库。不管使用推还是拉模式,在需要接收大量数据的场景下,指标收集器通常是一个服务集群。
但是,当时序数据库不可用时,就会存在数据丢失的风险,所以,我们引入了 Kafka 消息队列组件, 如下图

指标收集器把指标数据发送到 Kafka 消息队列,然后消费者或者流处理服务进行数据处理,比如 Apache Storm、Flink 和 Spark, 最后再推送到时序数据库。
指标计算
指标在多个地方都可以聚合计算,看看它们都有什么不一样。
• 客户端代理:客户端安装的收集代理只支持简单的聚合逻辑。
• 传输管道:在数据写入时序数据库之前,我们可以用 Flink 流处理服务进行聚合计算,然后只写入汇总后的数据,这样写入量会大大减少。但是由于我们没有存储原始数据,所以丢失了数据精度。
• 查询端:我们可以在查询端对原始数据进行实时聚合查询,但是这样方式查询效率不太高。
时序数据库查询语言
大多数流行的指标监控系统,比如 Prometheus 和 InfluxDB 都不使用 SQL,而是有自己的查询语言。一个主要原因是很难通过 SQL 来查询时序数据, 并且难以阅读,比如下面的SQL 你能看出来在查询什么数据吗?
select id,
temp,
avg(temp) over (partition by group_nr order by time_read) as rolling_avg
from (
select id,
temp,
time_read,
interval_group,
id - row_number() over (partition by interval_group order by time_read) as group_nr
from (
select id,
time_read,
"epoch"::timestamp + "900 seconds"::interval * (extract(epoch from time_read)::int4 / 900) as interval_group,
temp
from readings
) t1
) t2
order by time_read;相比之下, InfluxDB 使用的针对于时序数据的 Flux 查询语言会更简单更好理解,如下
from(db:"telegraf")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "foo")
|> exponentialMovingAverage(size:-10s)数据编码和压缩
数据编码和压缩可以很大程度上减小数据的大小,特别是在时序数据库中,下面是一个简单的例子。

因为一般数据收集的时间间隔是固定的,所以我们可以把一个基础值和增量一起存储,比如 1610087371, 10, 10, 9, 11 这样,可以占用更少的空间。
下采样
下采样是把高分辨率的数据转换为低分辨率的过程,这样可以减少磁盘使用。由于我们的数据保留期是1年,我们可以对旧数据进行下采样,这是一个例子:
• 7天数据,不进行采样。
• 30天数据,下采样到1分钟的分辨率
• 1年数据,下采样到1小时的分辨率。
我们看另外一个具体的例子,它把 10 秒分辨率的数据聚合为 30 秒分辨率。
原始数据

下采样之后

告警服务
让我们看看告警服务的设计图,以及工作流程。

1. 加载 YAML 格式的告警配置文件到缓存。
- name: instance_down
rules:
# 服务不可用时间超过 5 分钟触发告警.
- alert: instance_down
expr: up == 0
for: 5m
labels:
severity: page2. 警报管理器从缓存中读取配置。
3. 根据告警规则,按照设定的时间和条件查询指标,如果超过阈值,则触发告警。
4. Alert Store 保存着所有告警的状态(挂起,触发,已解决)。
5. 符合条件的告警会添加到 Kafka 中。
6. 消费队列,根据告警规则,发送警报信息到不同的通知渠道。
可视化
可视化建立在数据层之上,指标数据可以在指标仪表板上显示,告警信息可以在告警仪表板上显示。下图显示了一些指标,服务器的请求数量、内存/CPU 利用率、页面加载时间、流量和登录信息。

Grafana 可以是一个非常好的可视化系统,我们可以直接拿来使用。
总结
在本文中,我们介绍了指标监控和告警系统的设计。在高层次上,我们讨论了数据收集、时序数据库、告警和可视化,下图是我们最终的设计:

Reference
[0] System Design Interview Volume 2: https://www.amazon.com/System-Design-Interview-Insiders-Guide/dp/1736049119
[1] Datadog: https://www.datadoghq.com/
[2] Splunk: https://www.splunk.com/
[3] Elastic stack: https://www.elastic.co/elastic-stack
[4] Dapper, a Large-Scale Distributed Systems Tracing Infrastructure: https://research.google/pubs/pub36356/
[5] Distributed Systems Tracing with Zipkin: https://blog.twitter.com/engineering/en_us/a/2012/distributed-systems-tracing-with-zipkin.html
[6] Prometheus: https://prometheus.io/docs/introduction/overview/
[7] OpenTSDB - A Distributed, Scalable Monitoring System: http://opentsdb.net/
[8] Data model: : https://prometheus.io/docs/concepts/data_model/
[9] Schema design for time-series data | Cloud Bigtable Documentation https://cloud.google.com/bigtable/docs/schema-design-time-series
[10] MetricsDB: TimeSeries Database for storing metrics at Twitter: https://blog.twitter.com/engineering/en_us/topics/infrastructure/2019/metricsdb.html
[11] Amazon Timestream: https://aws.amazon.com/timestream/
[12] DB-Engines Ranking of time-series DBMS: https://db-engines.com/en/ranking/time+series+dbms
[13] InfluxDB: https://www.influxdata.com/
[14] etcd: https://etcd.io
[15] Service Discovery with Zookeeper https://cloud.spring.io/spring-cloud-zookeeper/1.2.x/multi/multi_spring-cloud-zookeeper-discovery.html
[16] Amazon CloudWatch: https://aws.amazon.com/cloudwatch/
[17] Graphite: https://graphiteapp.org/
[18] Push vs Pull: http://bit.ly/3aJEPxE
[19] Pull doesn’t scale - or does it?: https://prometheus.io/blog/2016/07/23/pull-does-not-scale-or-does-it/
[20] Monitoring Architecture: https://developer.lightbend.com/guides/monitoring-at-scale/monitoring-architecture/architecture.html
[21] Push vs Pull in Monitoring Systems: https://giedrius.blog/2019/05/11/push-vs-pull-in-monitoring-systems/
[22] Pushgateway: https://github.com/prometheus/pushgateway
[23] Building Applications with Serverless Architectures https://aws.amazon.com/lambda/serverless-architectures-learn-more/
[24] Gorilla: A Fast, Scalable, In-Memory Time Series Database: http://www.vldb.org/pvldb/vol8/p1816-teller.pdf
[25] Why We’re Building Flux, a New Data Scripting and Query Language: https://www.influxdata.com/blog/why-were-building-flux-a-new-data-scripting-and-query-language/
[26] InfluxDB storage engine: https://docs.influxdata.com/influxdb/v2.0/reference/internals/storage-engine/
[27] YAML: https://en.wikipedia.org/wiki/YAML
[28] Grafana Demo: https://play.grafana.org/
END
做了一个 .NET 的学习网站,内容涵盖了分布式系统,数据结构与算法,设计模式,操作系统,计算机网络等,以及工作推荐和面试经验分享,欢迎来撩。
回复 dotnet 获取网站地址。
回复 面试题 获取 .NET 面试题。
回复 程序员副业 获取适合程序员的副业指南。

边栏推荐
- 【愚公系列】2022年7月 Go教学课程 005-变量
- [untitled]
- [untitled]
- Leetcode - interview question 17.24 maximum submatrix
- MPX plug-in
- Socket socket programming
- 对比学习之 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
- RationalDMIS2022阵列工件测量
- Basic knowledge of process (orphan, zombie process)
- When initializing 'float', what is the difference between converting to 'float' and adding 'f' as a suffix?
猜你喜欢
![[C #] the solution of WinForm operation zoom (blur)](/img/66/b70213c95acd4ad9fe2eb739bd46b5.png)
[C #] the solution of WinForm operation zoom (blur)
![Verilog realizes nixie tube display driver [with source code]](/img/ad/be94912bedc738f4b5f97138db7352.png)
Verilog realizes nixie tube display driver [with source code]
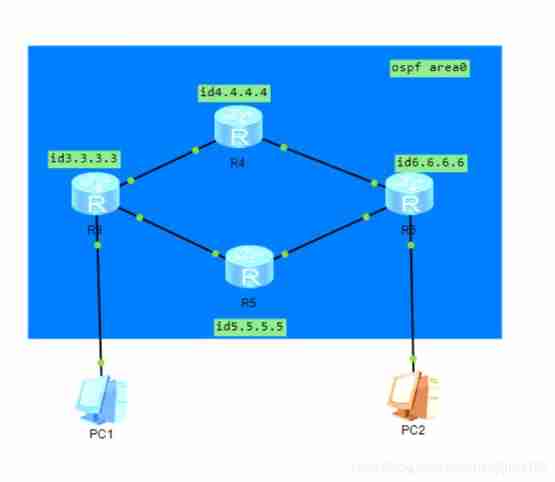
Using ENSP to do MPLS pseudo wire test

Technology sharing | packet capturing analysis TCP protocol
关于测试人生的一站式发展建议

對比學習之 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments

Learning notes | data Xiaobai uses dataease to make a large data screen
MPX plug-in
uniCloud
对比学习之 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
随机推荐
After the uniapp jumps to the page in onlaunch, click the event failure solution
對比學習之 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
解决VSCode只能开两个标签页的问题
网络协议 概念
uniCloud
2021-05-21
Vuthink proper installation process
[untitled]
Array object sorting
普通测试年薪15w,测试开发年薪30w+,二者差距在哪?
LeetCode - 面试题17.24 最大子矩阵
Add a self incrementing sequence number to the antd table component
What if copying is prohibited?
[untitled]
毕业季|与青春作伴,一起向未来!
Verilog design responder [with source code]
MPX plug-in
Two week selection of tdengine community issues | phase II
Qt 实现容器的DELETE的方式
QT implements the delete method of the container