当前位置:网站首页>Unsupervised learning of visual features by contracting cluster assignments
Unsupervised learning of visual features by contracting cluster assignments
2022-07-07 11:17:00 【InfoQ】

- The comparative study of the gods in the twilight age
- “ The arms race ” The comparative study of the period is good .
- Will the whole imagenet Make a dictionary , Extract one from mini batch As a positive sample . And then randomly extract from it 4096 As a negative sample .
- Extract one from the data set mini batch Expand it , Using a twin network , Put the original image into a network , Put the enhanced graph into another network , Both are trained at the same time , Use one for both NCE loss perhaps infoNCE loss. A picture and its enlargement as a positive sample , The rest of the images and their extensions are taken as negative samples .
- Extract one from the data set mini batch Expand it twice , Using a twin network , Put a set of image enhancements into a network , Put another set of image enhancements into another network , Both are trained at the same time , Use one for both NCE loss perhaps infoNCE loss.
- It may repeatedly extract the same data . Although your data set has many pictures , But you may draw the same picture from it . In extreme cases , If you take a group of pictures as a positive sample , Then you take a group of pictures with the same repetition as the negative sample . That will affect the training .
- It may not be representative of the entire data set . For example, there are many kinds of animals in this data , But all you get is dogs , So the data is not representative .
- Of course, the more comprehensive the selection, the better the effect , But if you choose too many negative samples, it will cause a waste of computing resources .
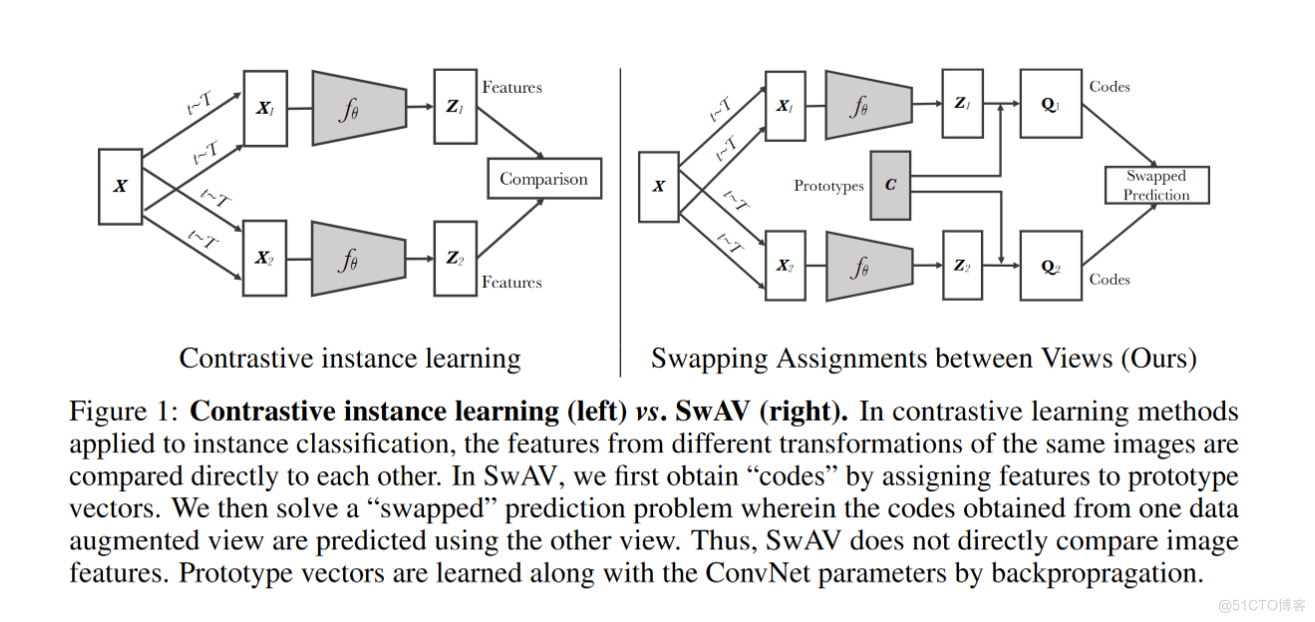
- Let's start with the repeating question : Because you use the cluster center for comparison . Although it is a different cluster center , Then it is certainly impossible for him to repeat .
- Again, there is no representative problem : Clustering is to gather many pictures into different categories . Compare with the center of each category , Is absolutely representative .
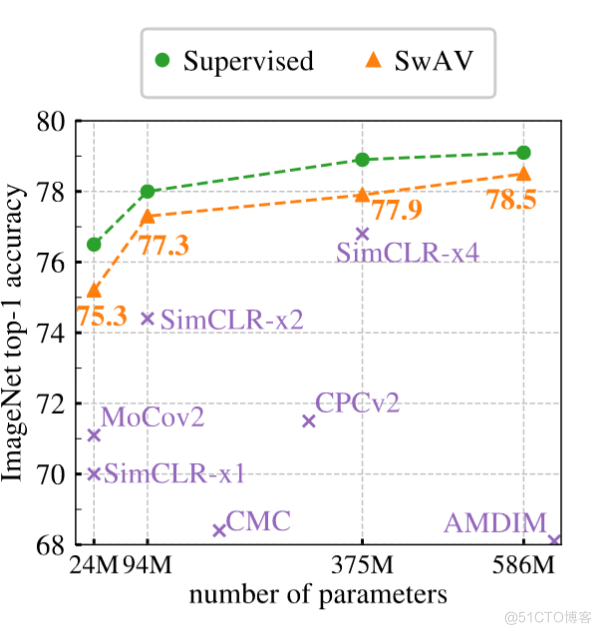
- Let's talk about the waste of resources caused by too many negative samples in the past . If you want to make an analogy with many negative samples , You may need thousands of negative samples , And even so, it is only an approximation , And if you just compare with the cluster center , You can use hundreds or at most 3,000 Cluster centers , That's enough to say . Greatly reduce the consumption of computing resources .
边栏推荐
- 滚动踩坑--UNI_APP(八)
- 数据库同步工具 DBSync 新增对MongoDB、ES的支持
- Graduation season | keep company with youth and look forward to the future together!
- 测试优惠券要怎么写测试用例?
- 毕业季|与青春作伴,一起向未来!
- 科普达人丨一文弄懂什么是云计算?
- [STM32] actual combat 3.1 - drive 42 stepper motors with STM32 and tb6600 drivers (I)
- Poj1821 fence problem solving Report
- JS add spaces to the string
- The seventh training assignment
猜你喜欢

![[untitled]](/img/15/3db921703147afdf58dfffe532a19b.jpg)
![[untitled]](/img/c2/d70d052b7e9587dc81c622f62f8566.jpg)
随机推荐
自动化测试框架
Creative information was surveyed by 2 institutions: greatdb database has been deployed in 9 places
Ping tool ICMP message learning
高考作文,高频提及科技那些事儿……
Ffmpeg record a video command from RTSP
科普达人丨一文弄懂什么是云计算?
從色情直播到直播電商
Go Slice 比较
创意信息获2家机构调研:GreatDB 数据库已在9地部署
0.96 inch IIC LCD driver based on stc8g1k08
在我有限的软件测试经历里,一段专职的自动化测试经验总结
使用MeterSphere让你的测试工作持续高效
LeetCode - 面试题17.24 最大子矩阵
通过 Play Integrity API 的 nonce 字段提高应用安全性
Eth trunk link switching delay is too high
Deeply understand the characteristics of database transaction isolation
[STM32] actual combat 3.1 - drive 42 stepper motors with STM32 and tb6600 drivers (I)
基于STC8G1K08的0.96寸IIC液晶屏驱动程序
electron添加SQLite数据库
90后,辞职创业,说要卷死云数据库