当前位置:网站首页>seata 1.3.0 四种模式解决分布式事务(AT、TCC、SAGA、XA)
seata 1.3.0 四种模式解决分布式事务(AT、TCC、SAGA、XA)
2022-07-07 08:44:00 【铛铛响】
前言
1、seata版本 1.3.0
2、基础项目结构,大家只需要关注 设备模块 device和工单模块 order即可。 -
-
| 项目 | 说明 |
|---|---|
| api-gateway | 网关模块 |
| common | 基础模块 |
| device | 设备模块 |
| order | 工单模块 |
| user | 用户模块 |
3、数据库说明, 设备模块 device链接gxm-301数据库,工单模块 order链接 gxm-300数据库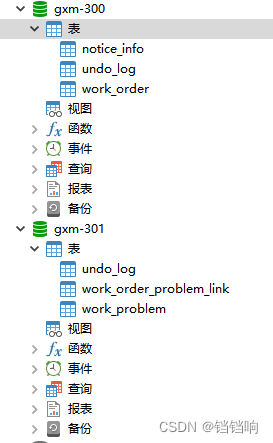
4、主要业务说明,在生成工单的时候,我们使用order服务向 gxm-300数据库的表work-order和notice_info插入数据库,并且远程调用device服务插入gxm-301数据库的表 work-problem 和表work_order_problem_link
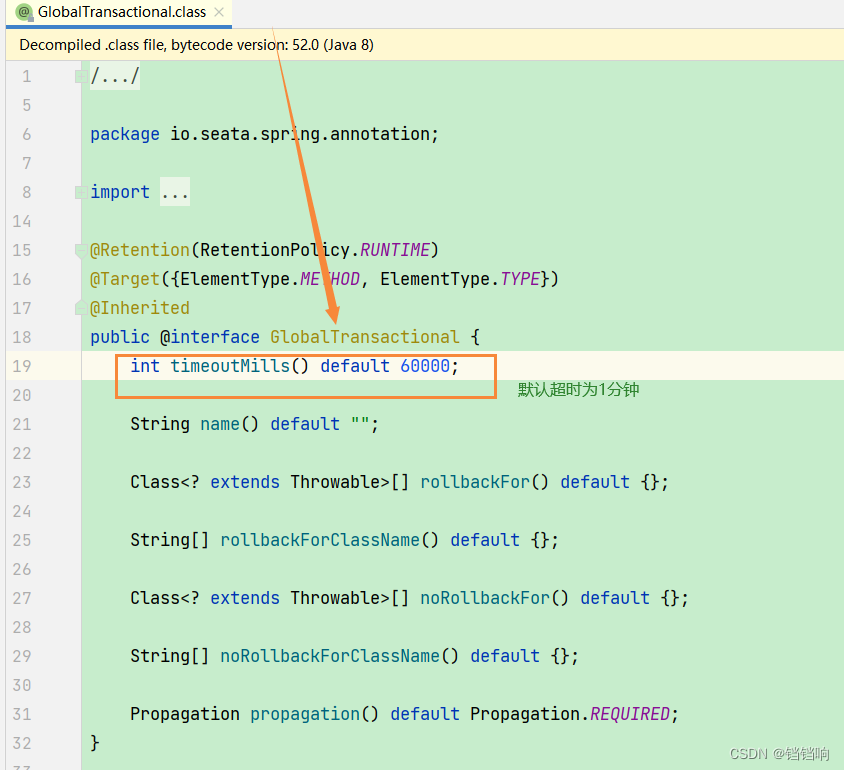
5、调试说明,我们在使用@GlobalTransactional注解的时候,seata的控制事务是有时间限制的默认为1分钟,所以在我们debug的时候如果时间过长,seata就默认回滚了,为了方便大家调试,可以修改这个参数。
6、官方的==新人文档 是一定要看的==
一、AT 模式
1、对于seata 来说默认开启的就是 AT模式,而且如果你依赖 seata-spring-boot-starter 时,自动代理数据源,无需额外处理
2、对于AT模式在回滚的时候会找到 undo_log 中的前镜像与后镜像,来进行恢复。
但是在恢复的时候,会比较后镜像是否有没有被修改过,即进行数据进行比较,如果有不同,说明数据被当前全局事务之外的动作进行了修改,这个时候
AT模式做数据校验的时候,会回滚失败,因为校验不通过,我们也可以通过配置参数关闭这个前后镜像的校验过程,不过这个是非常不建议的,因为,被其他线程修改了导致不能还原现场这种情况,确实还是需要人为去处理的
3、这是官方的的AT模式的使用说明,这都是必须要注意的点偶。
4、其中官方的 新人文档 是一定要看的,其中在老版本中,我们是要代理数据源的,如下,具体的模式选择不同的数据源来代理即可,比如我们现在模拟的是AT,那就是return new DataSourceProxy(druidDataSource);。
@Primary
@Bean("dataSource")
public DataSource dataSource(DataSource druidDataSource) {
//AT 代理 二选一
return new DataSourceProxy(druidDataSource);
//XA 代理
return new DataSourceProxyXA(druidDataSource)
}
5、但是如何你使用的是高版本的或者使用的是 seata-starter,就不用手动配置,因为我使用的是 seata-starter,而且我现在演示的是AT模式,所以不用改什么(后续在XA模式的时候会去修改)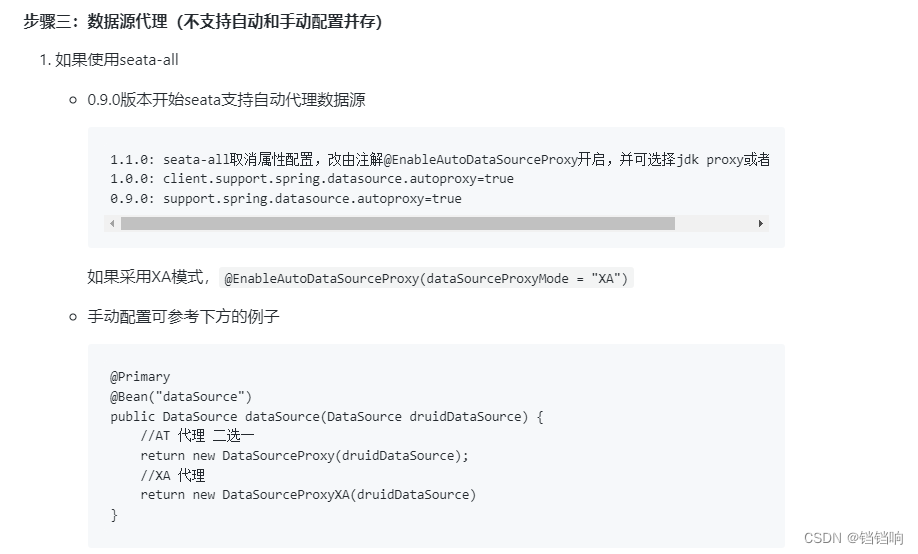
6、常见的问题,官方已经有了说明和回答 常见问题,在用于生产之前,这些最好都看一遍。
1.1、使用说明
1.1.1、使用
1、我们使用注解 @GlobalTransactional开启seata的AT模式的事务管理,而且因为是使用的是seata-starter,那这个注解会自动代理AT模式的数据源,具体代码如下,可以看到代码主要分为两部分,第一部分是调用自己order服务的2个表的mapper 插入数据到gxm-300,第二部分是远程调用device的两个mapper来进行插入数据到gxm-301
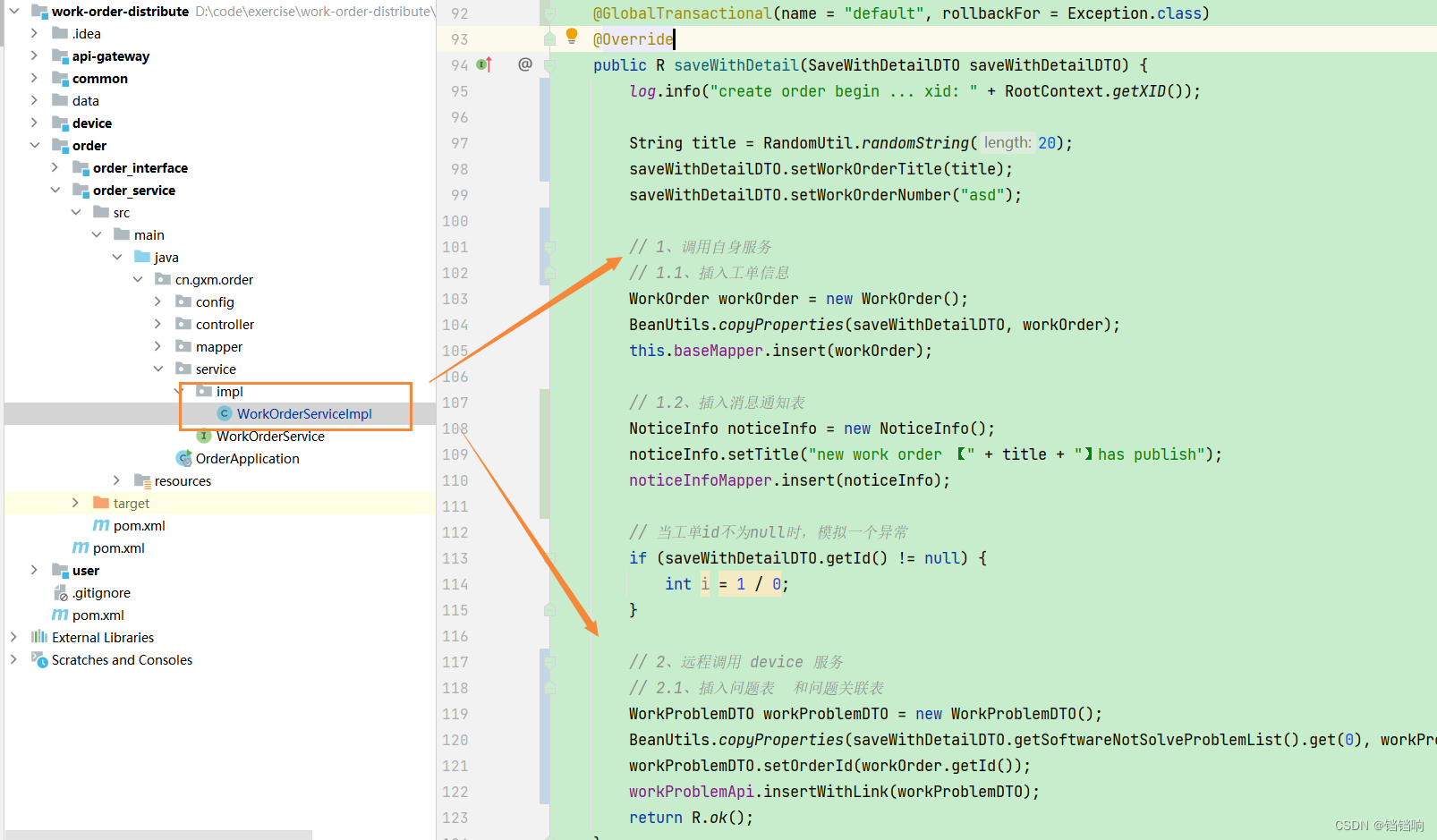
@GlobalTransactional(name = "default", rollbackFor = Exception.class)
@Override
public R saveWithDetail(SaveWithDetailDTO saveWithDetailDTO) {
log.info("create order begin ... xid: " + RootContext.getXID());
String title = RandomUtil.randomString(20);
saveWithDetailDTO.setWorkOrderTitle(title);
saveWithDetailDTO.setWorkOrderNumber("asd");
// 1、调用自身服务
// 1.1、插入工单信息
WorkOrder workOrder = new WorkOrder();
BeanUtils.copyProperties(saveWithDetailDTO, workOrder);
this.baseMapper.insert(workOrder);
// 1.2、插入消息通知表
NoticeInfo noticeInfo = new NoticeInfo();
noticeInfo.setTitle("new work order 【" + title + "】has publish");
noticeInfoMapper.insert(noticeInfo);
// 当工单id不为null时,模拟一个异常
if (saveWithDetailDTO.getId() != null) {
int i = 1 / 0;
}
// 2、远程调用 device 服务
// 2.1、插入问题表 和问题关联表
WorkProblemDTO workProblemDTO = new WorkProblemDTO();
BeanUtils.copyProperties(saveWithDetailDTO.getSoftwareNotSolveProblemList().get(0), workProblemDTO);
workProblemDTO.setOrderId(workOrder.getId());
workProblemApi.insertWithLink(workProblemDTO);
return R.ok();
}
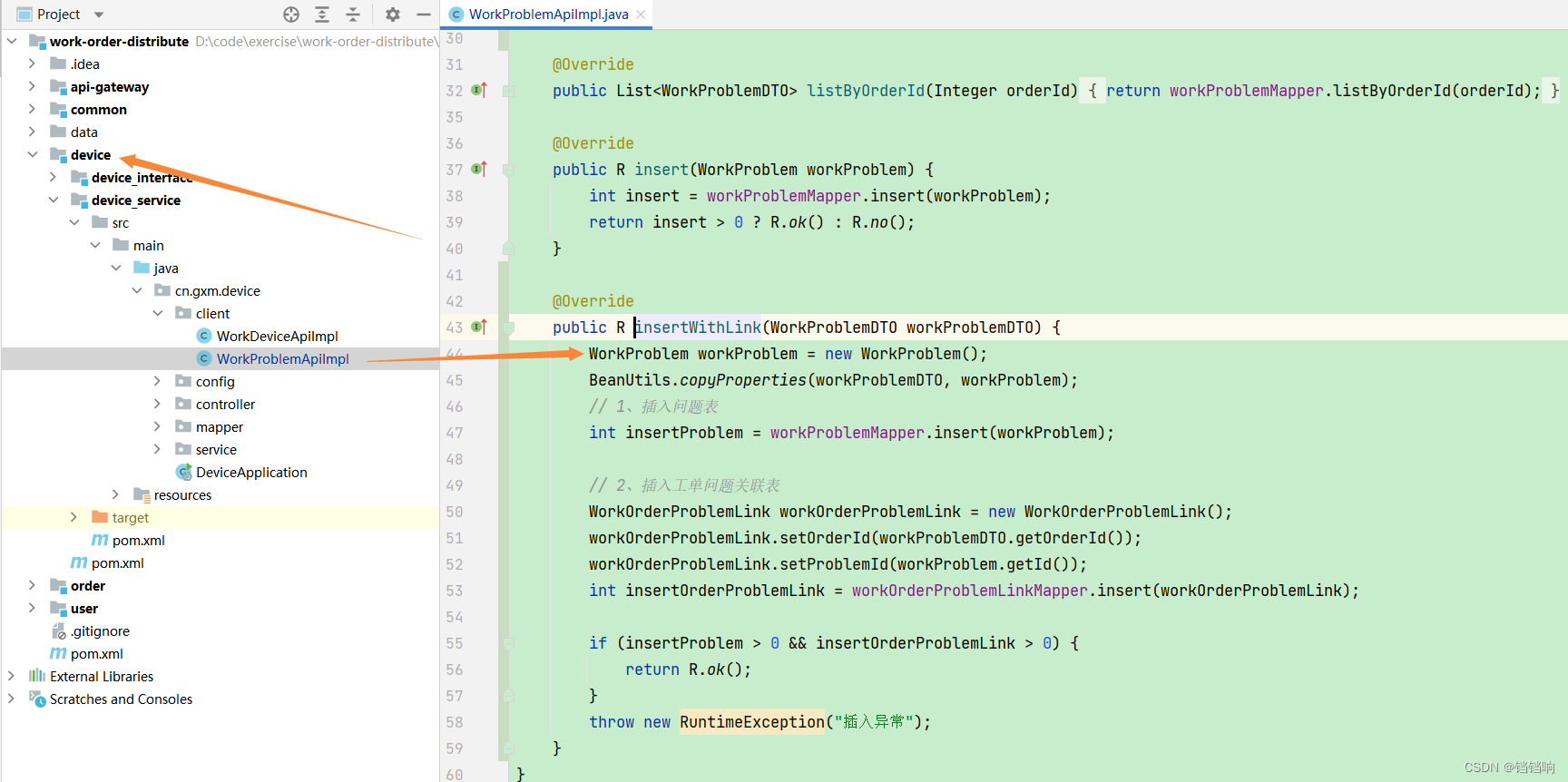
@Override
public R insertWithLink(WorkProblemDTO workProblemDTO) {
WorkProblem workProblem = new WorkProblem();
BeanUtils.copyProperties(workProblemDTO, workProblem);
// 1、插入问题表
int insertProblem = workProblemMapper.insert(workProblem);
// 2、插入工单问题关联表
WorkOrderProblemLink workOrderProblemLink = new WorkOrderProblemLink();
workOrderProblemLink.setOrderId(workProblemDTO.getOrderId());
workOrderProblemLink.setProblemId(workProblem.getId());
int insertOrderProblemLink = workOrderProblemLinkMapper.insert(workOrderProblemLink);
if (insertProblem > 0 && insertOrderProblemLink > 0) {
return R.ok();
}
throw new RuntimeException("插入异常");
}
2、先测试成功的方式,即传参的时候id为空,则2个数据库的4张表都没有问题,都插入成功,说明没有问题
3、再测试不成功,即传参的时候id不为空,则seata数据全局事务就会生效,2个数据库4张表都没有数据库,说明seata的AT模式生效了,
1.1.2、刨析
1、我们打个断点,可以就可以发现AT模式的秘密所在了,我们直接在调用链的最后的位置打上断点,这个位置是4个mapper都已经插入成功了,但是device服务没有返回,所以整个链路没有结束,并且此时我加长了事务的时间,足够我们调试了。
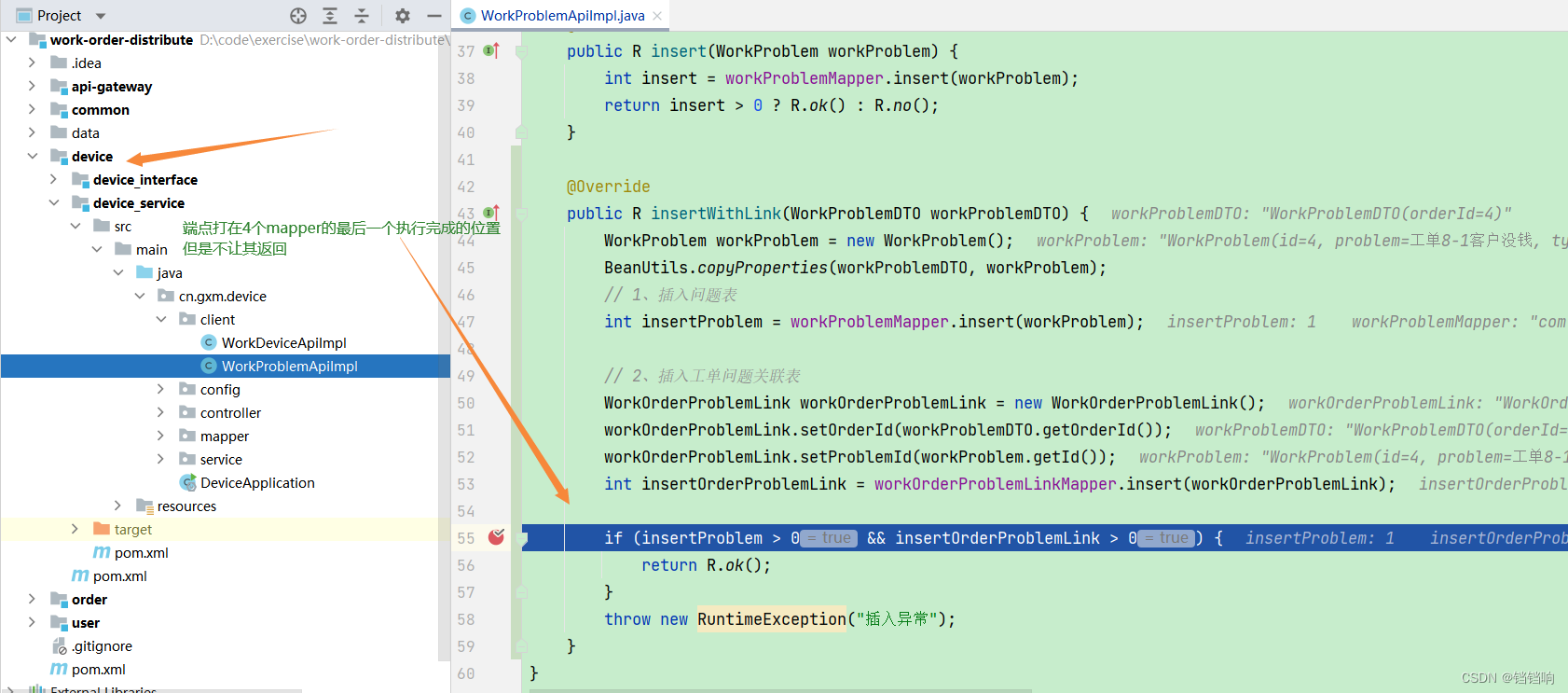
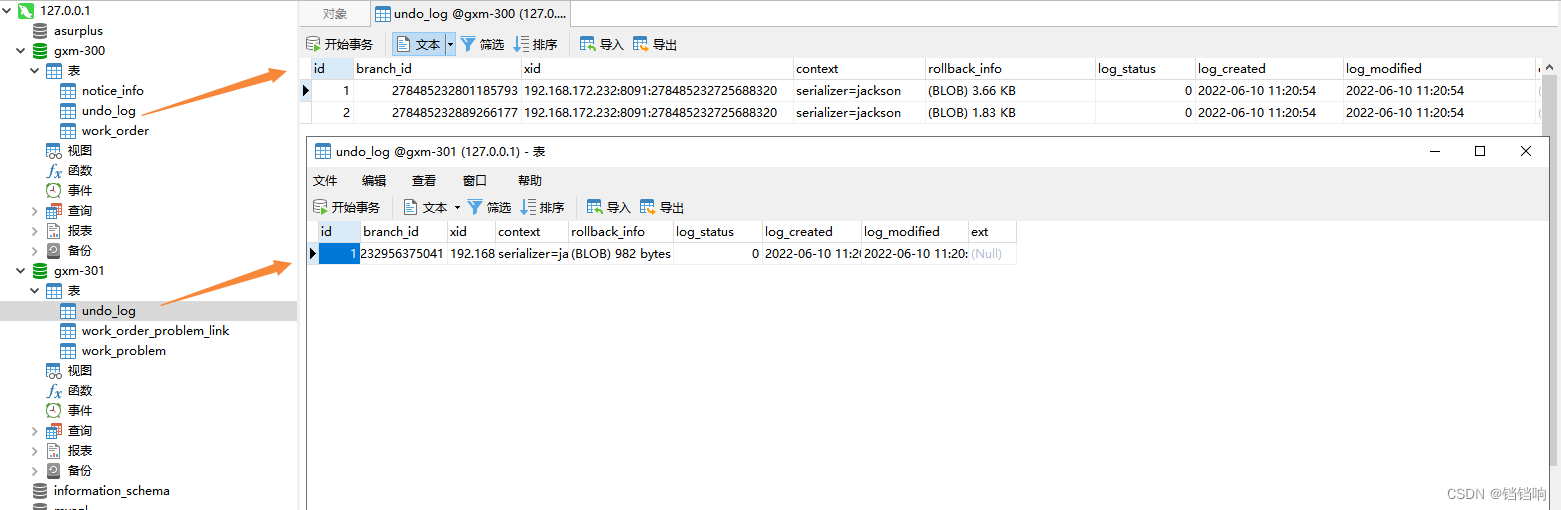
2、在端点处停止的时候,我们观察gxm-300数据库和gxm-301数据库,你会发现,4个mapper的插入数据都已经插入到数据库了,并且一个mapper会在对应的undo_log表中插入一条数据,其中会有前置镜像数据和后置镜像数据,以及分支id branch_id
3、gxm-300 的 undo_log表
id branch_id xid context rollback_info log_status log_created log_modified ext
7 278197152412237825 192.168.172.232:8091:278197152336740352 serializer=jackson (BLOB) 3.66 KB 0 2022-06-09 16:16:10 2022-06-09 16:16:10
8 278197152475152385 192.168.172.232:8091:278197152336740352 serializer=jackson (BLOB) 2.27 KB 0 2022-06-09 16:16:10 2022-06-09 16:16:10
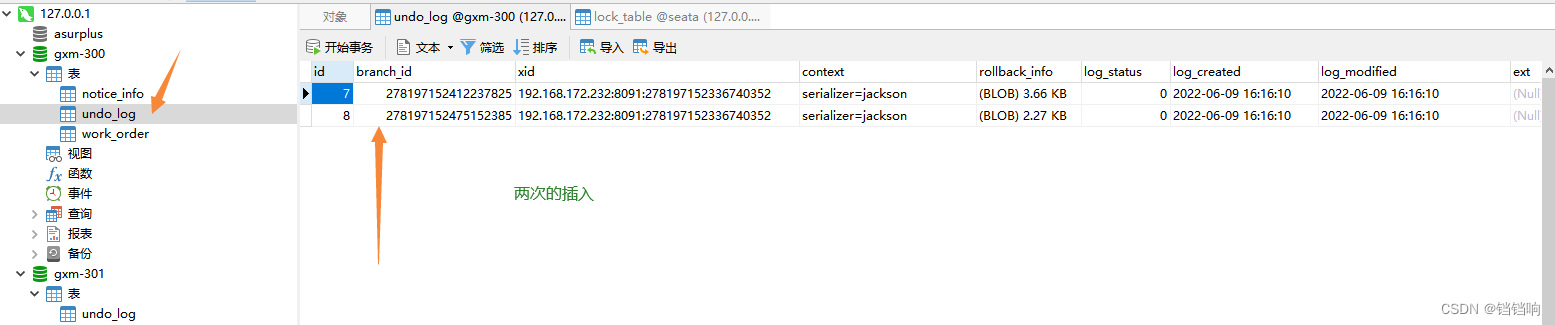
4、 gxm-301 的 undo_log表
id branch_id xid context rollback_info log_status log_created log_modified ext
7 278197152550649857 192.168.172.232:8091:278197152336740352 serializer=jackson (BLOB) 982 bytes 0 2022-06-09 16:16:10 2022-06-09 16:16:10
8 278197152600981505 192.168.172.232:8091:278197152336740352 serializer=jackson (BLOB) 999 bytes 0 2022-06-09 16:16:10 2022-06-09 16:16:10
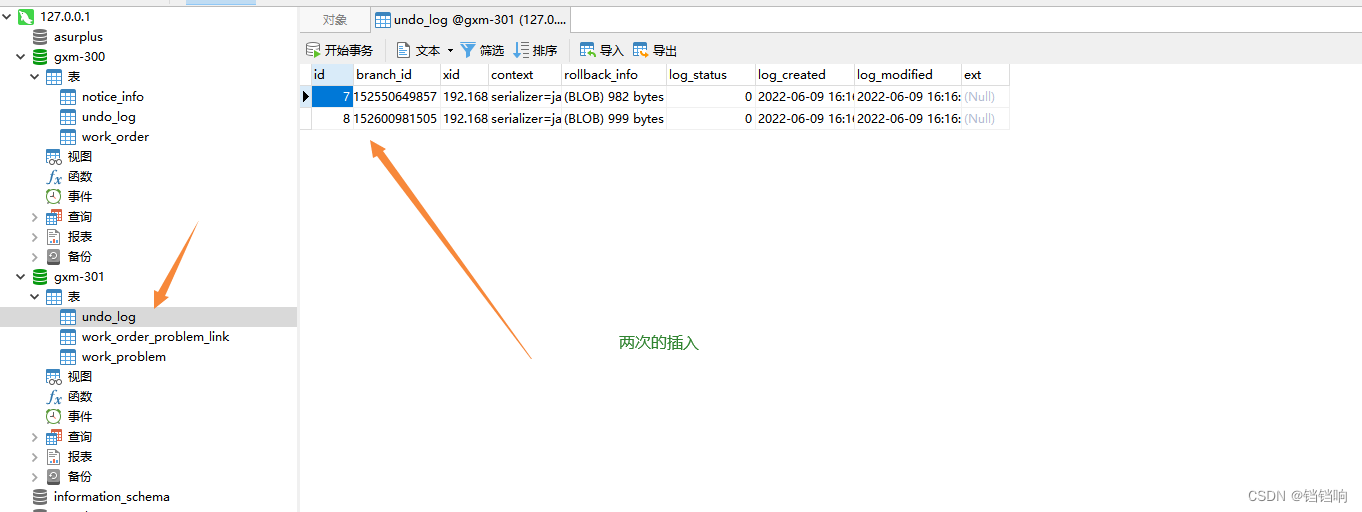
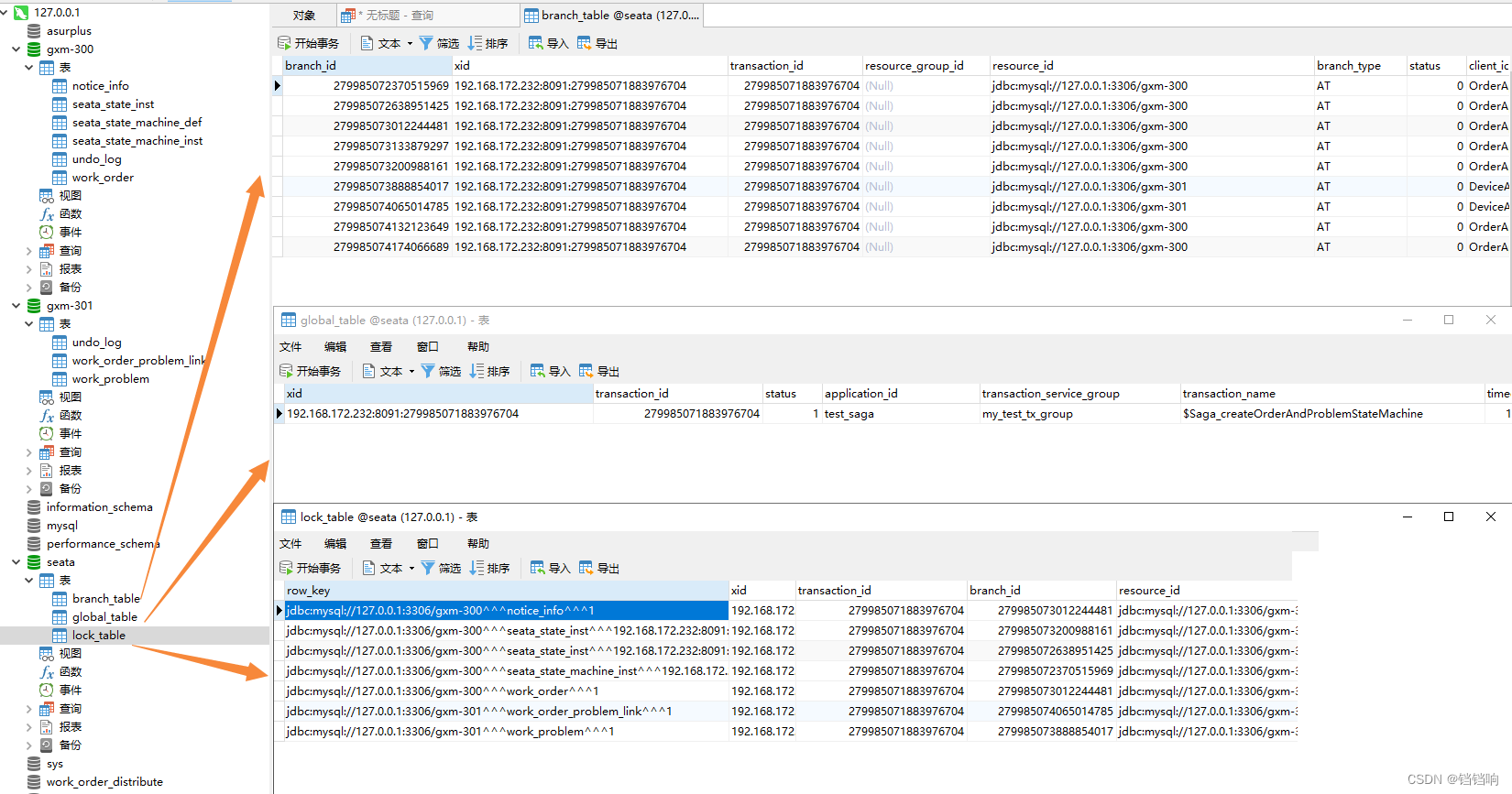
5、seata 的 branch_table表
branch_id xid transaction_id resource_group_id resource_id branch_type status client_id application_data gmt_create gmt_modified
278197152412237825 192.168.172.232:8091:278197152336740352 278197152336740352 jdbc:mysql://127.0.0.1:3306/gxm-300 AT 0 OrderApplication-seata-id:192.168.172.232:56035 2022-06-09 16:16:09.791745 2022-06-09 16:16:09.791745
278197152475152385 192.168.172.232:8091:278197152336740352 278197152336740352 jdbc:mysql://127.0.0.1:3306/gxm-300 AT 0 OrderApplication-seata-id:192.168.172.232:56035 2022-06-09 16:16:09.806598 2022-06-09 16:16:09.806598
278197152550649857 192.168.172.232:8091:278197152336740352 278197152336740352 jdbc:mysql://127.0.0.1:3306/gxm-301 AT 0 DeviceApplication-seata-id:192.168.172.232:56409 2022-06-09 16:16:09.824506 2022-06-09 16:16:09.824506
278197152600981505 192.168.172.232:8091:278197152336740352 278197152336740352 jdbc:mysql://127.0.0.1:3306/gxm-301 AT 0 DeviceApplication-seata-id:192.168.172.232:56409 2022-06-09 16:16:09.837013 2022-06-09 16:16:09.837013
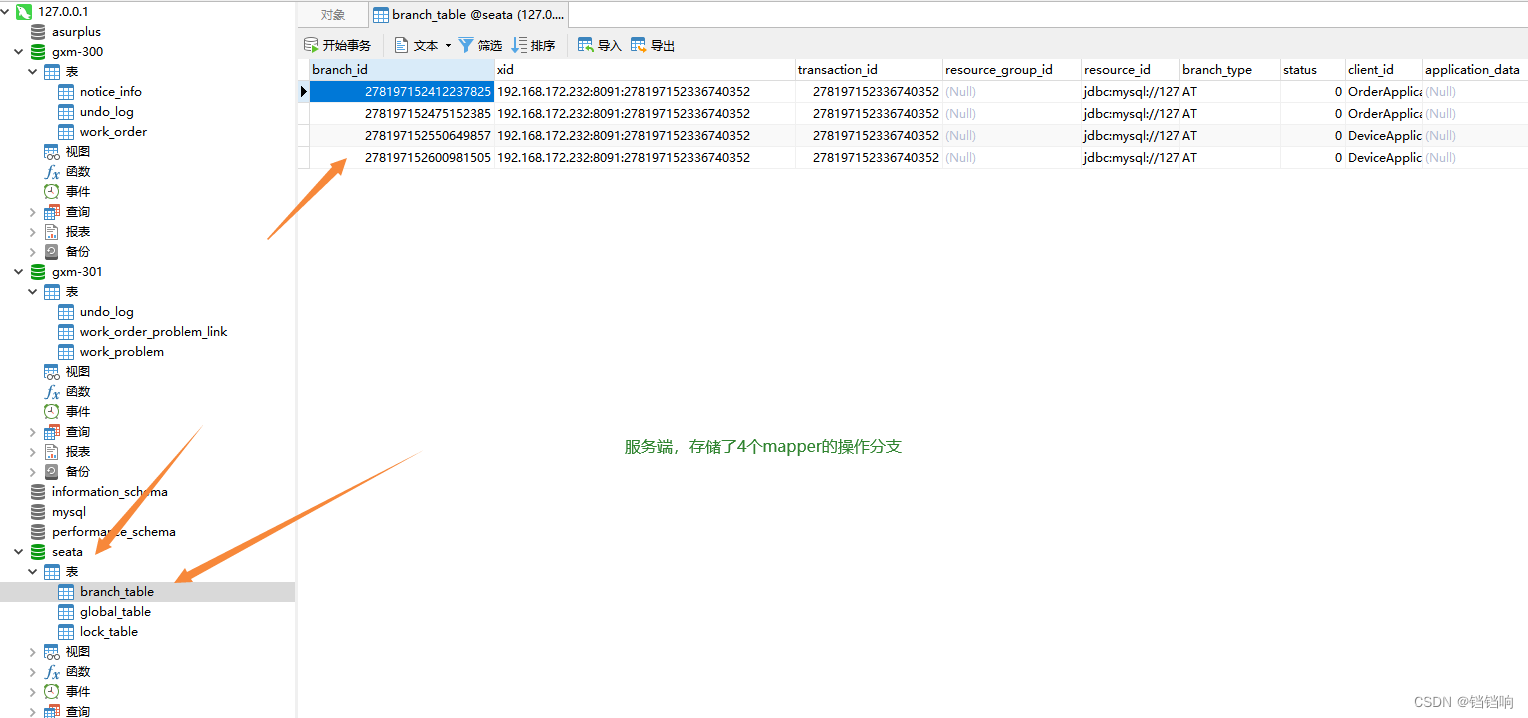
6、 seata 的 global_table表
xid transaction_id status application_id transaction_service_group transaction_name timeout begin_time application_data gmt_create gmt_modified
192.168.172.232:8091:278197152336740352 278197152336740352 5 OrderApplication-seata-id my_test_tx_group default 600000 1654762569770 2022-06-09 16:16:09 2022-06-09 16:16:42
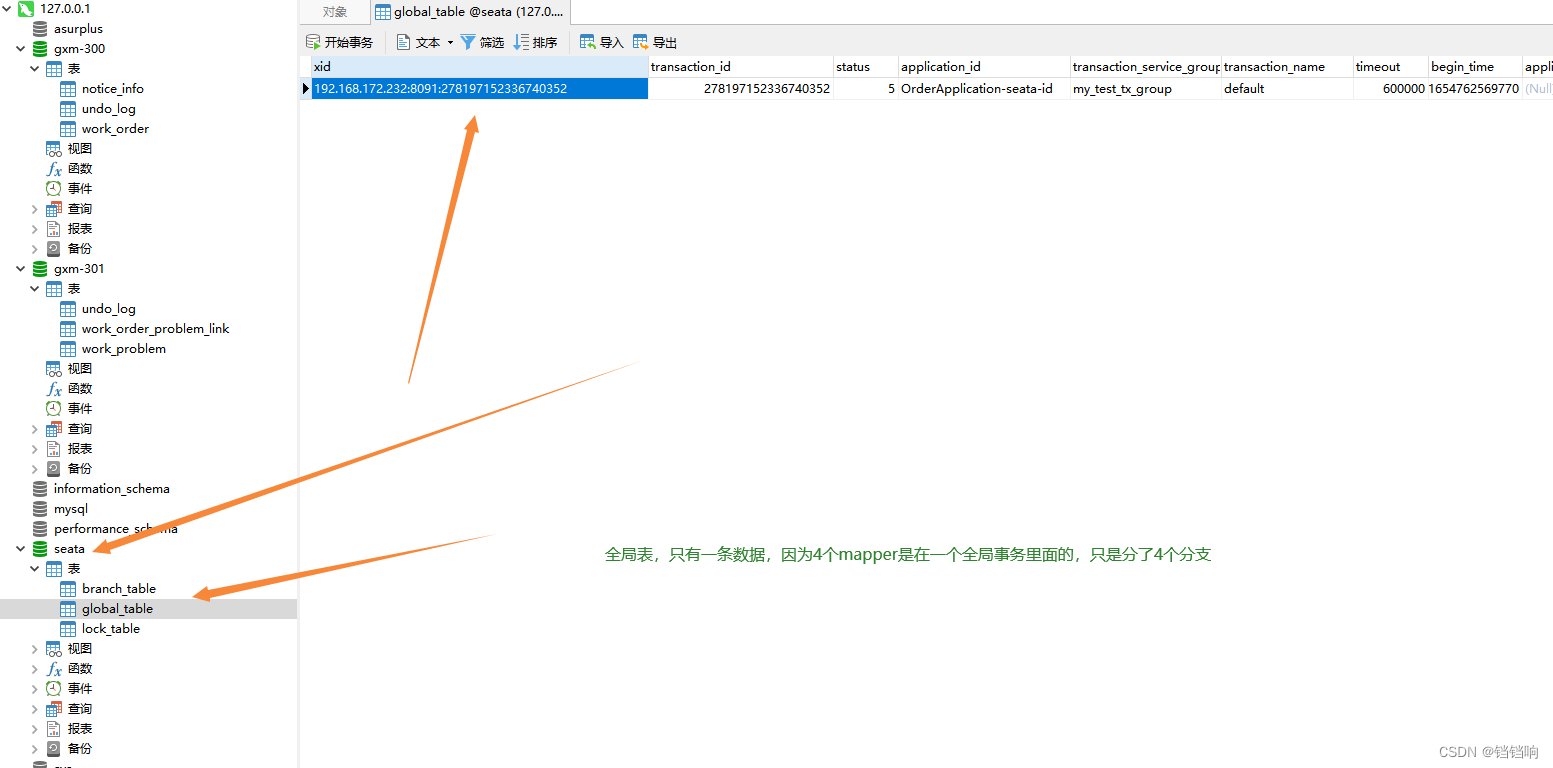
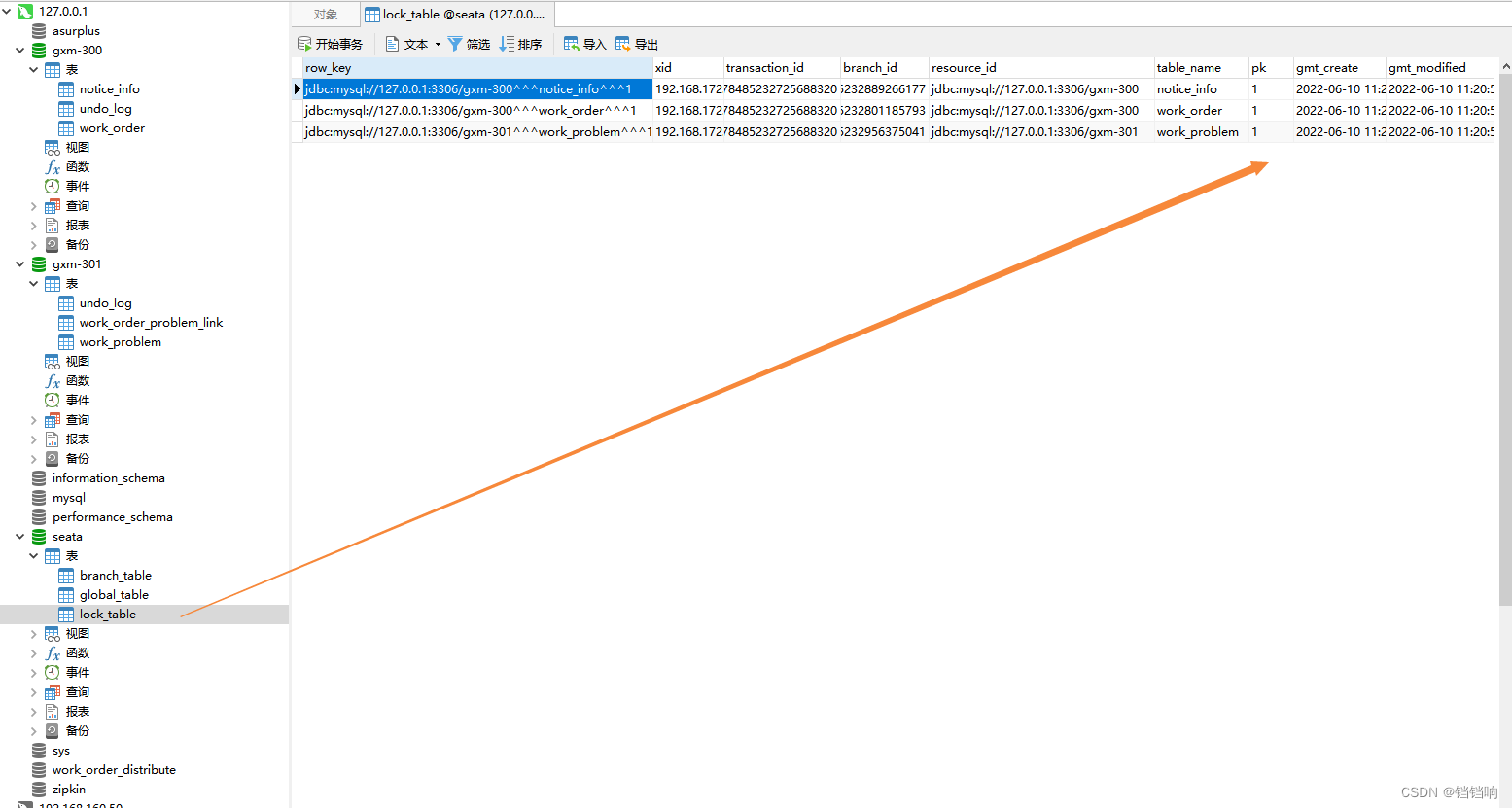
7、seata 的 lock_table表
row_key xid transaction_id branch_id resource_id table_name pk gmt_create gmt_modified
jdbc:mysql://127.0.0.1:3306/gxm-300^^^notice_info^^^4 192.168.172.232:8091:278197152336740352 278197152336740352 278197152475152385 jdbc:mysql://127.0.0.1:3306/gxm-300 notice_info 4 2022-06-09 16:16:09 2022-06-09 16:16:09
jdbc:mysql://127.0.0.1:3306/gxm-300^^^work_order^^^4 192.168.172.232:8091:278197152336740352 278197152336740352 278197152412237825 jdbc:mysql://127.0.0.1:3306/gxm-300 work_order 4 2022-06-09 16:16:09 2022-06-09 16:16:09
jdbc:mysql://127.0.0.1:3306/gxm-301^^^work_order_problem_link^^^4 192.168.172.232:8091:278197152336740352 278197152336740352 278197152600981505 jdbc:mysql://127.0.0.1:3306/gxm-301 work_order_problem_link 4 2022-06-09 16:16:09 2022-06-09 16:16:09
jdbc:mysql://127.0.0.1:3306/gxm-301^^^work_problem^^^4 192.168.172.232:8091:278197152336740352 278197152336740352 278197152550649857 jdbc:mysql://127.0.0.1:3306/gxm-301 work_problem 4 2022-06-09 16:16:09 2022-06-09 16:16:09
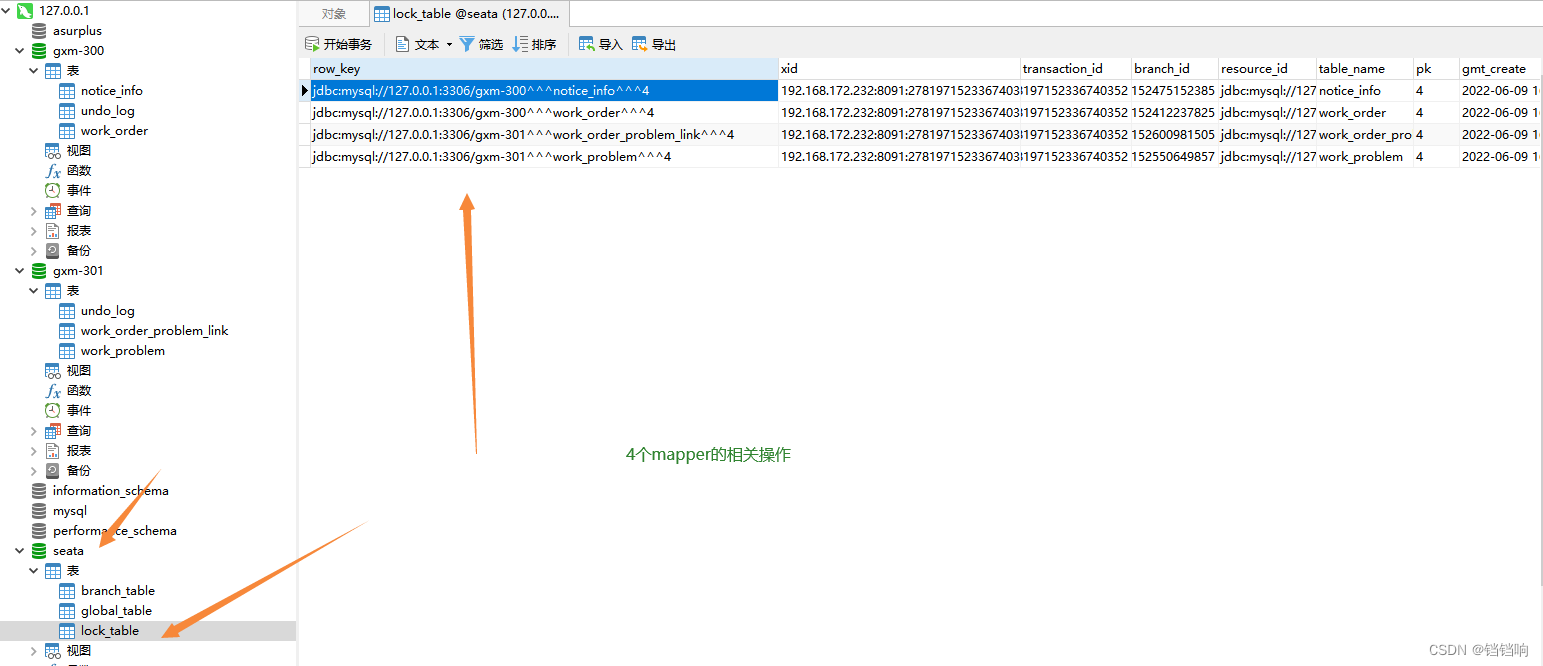
8、关联关系就是branch_id和 transaction_id,一个 transaction_id 表示一次全局事务的开始,旗下会有多个branch_id分支事务
9、如果我们的业务最后没有问题(指的是业务正常插入成功,或者有异常但是seata的AT模式帮你回滚了,而且回滚的时候没有任何问题),那么这些表都不会有数据,因为我们的全局事务结束了,保证的当次业务的流程了,即使是失败了,但是帮你回滚了。一旦我们的表有数据,就说明,业务执行发生了异常而seata回滚的时候发现有问题,这个时候,seata就会把相关信息的表数据存储起来,不删除,我们看到就要去处理了。
比如一种情况,我们在异常流程中,第一个线程执行一半的时候,即
work_order表数据插入成功了,但是我们在数据库手动修改,或者其他线程事务修改了这条刚生产的数据,但第一个现场执行到后面,即准备插入work_problem发生了异常,那么这个时候,seata的at模式会根据相关日志来进行回滚,但是回滚的时候,它会检查,在这期间`work_order``那条刚插入的数据,有没有被修改,一旦和它当初记录的不一致,那么它iu没法帮你处理了。这个时候,相关表的数据就存储下来了,我们就要根据这些信息来手动处理了。
1.1.3、AT模式回滚失败,处理
1、对于前面的1.1.2节的调试,我这里出现了问题,可能是因为我断点停留时间太长了,会发现相关表有数据,说seata的at模式回滚失败了。接下来我们就要去处理了。
2、看到了全局事务id278197152336740352
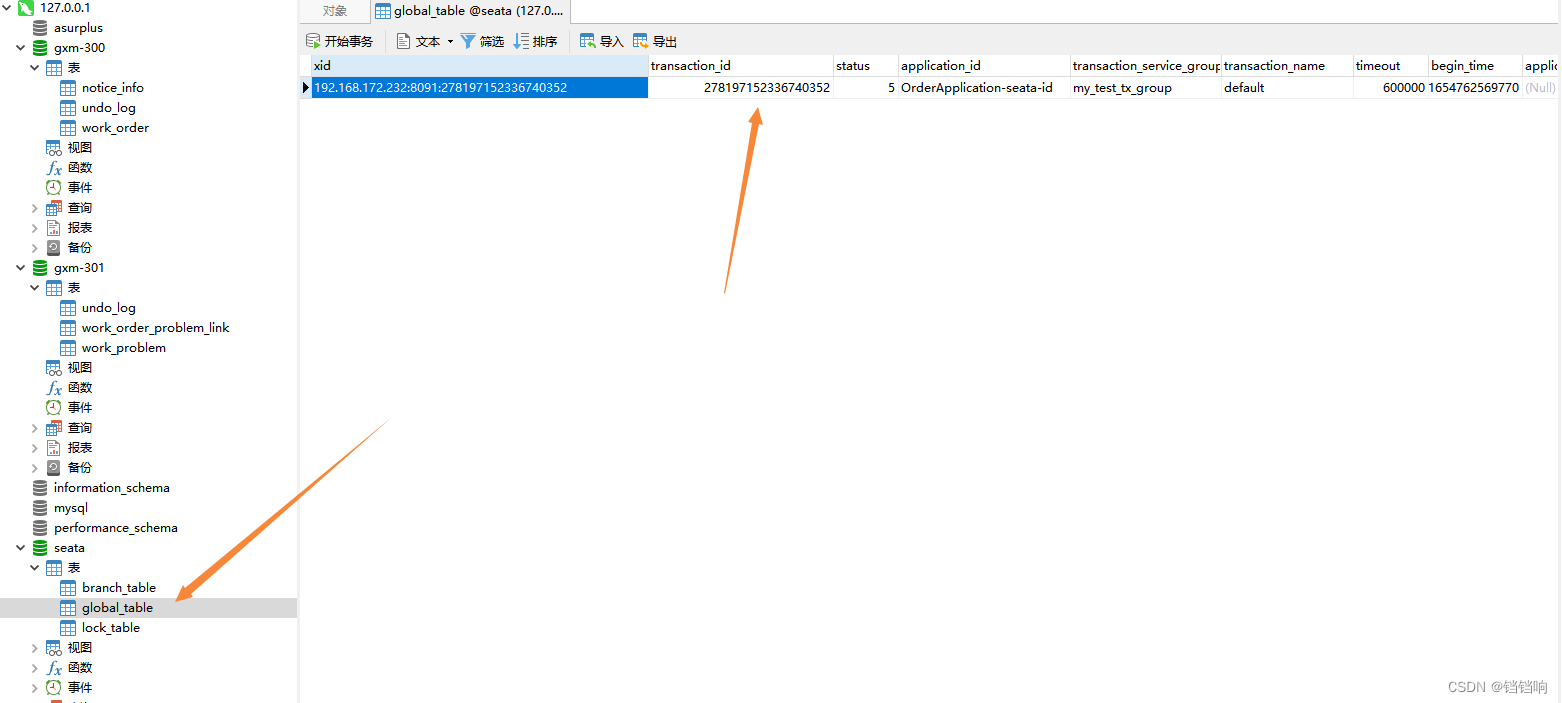
3、找当前全局事务下有那些事务分支遗留了下来,可以看到是gxm-300的业务有问题,而且pk字段是4,说明是这两种表的主键为4的有问题。
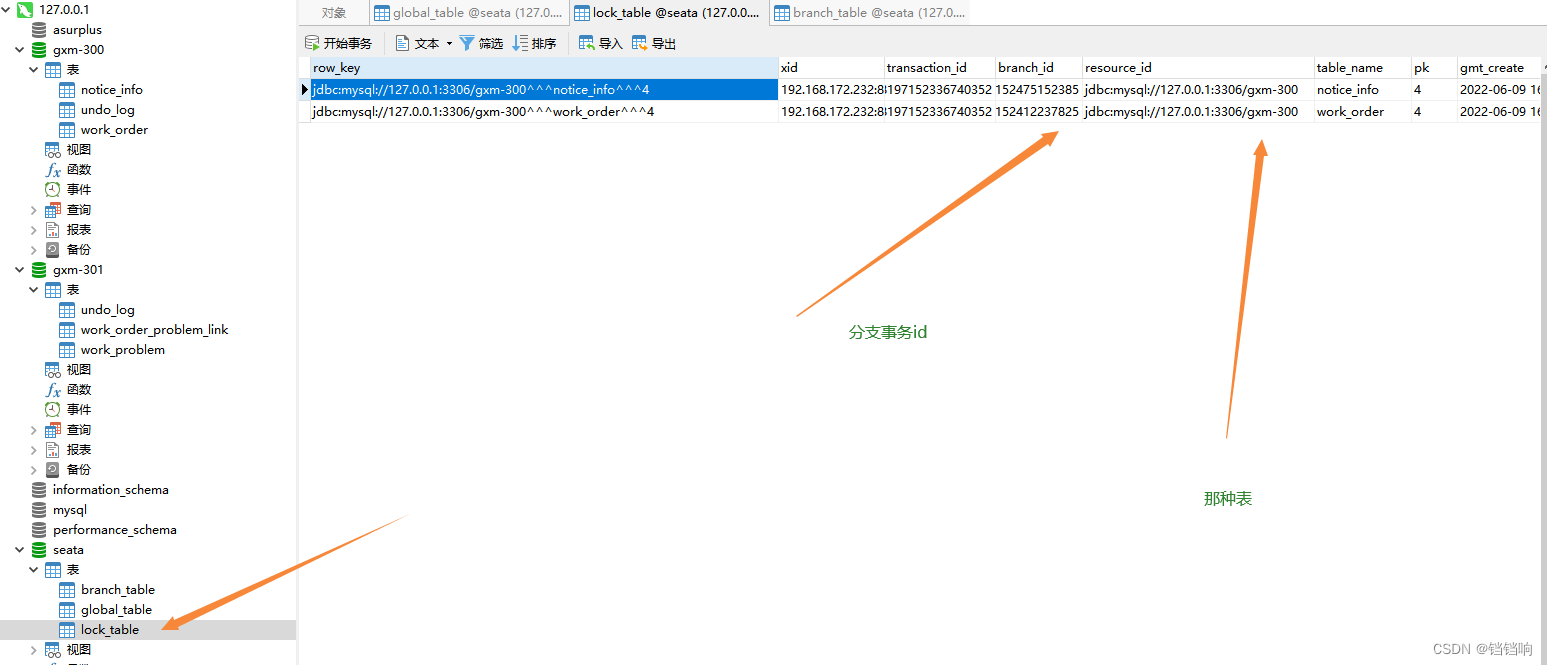
4、于是我们到对应的数据中找到它的undo_log,可以看到对应的分支id也是和前面的对应的上的,其中rollback_info字段记录的就是前置镜像的数据和后置镜像的数据
5、我们点击rollback_info字段,然后保存数据为 xxx.json文件,打开如下
{
"@class":"io.seata.rm.datasource.undo.BranchUndoLog",
"xid":"192.168.172.232:8091:278197152336740352",
"branchId":278197152412237825,
"sqlUndoLogs":[
"java.util.ArrayList",
[
{
"@class":"io.seata.rm.datasource.undo.SQLUndoLog",
"sqlType":"INSERT",
"tableName":"work_order",
"beforeImage":{
"@class":"io.seata.rm.datasource.sql.struct.TableRecords$EmptyTableRecords",
"tableName":"work_order",
"rows":[
"java.util.ArrayList",
[
]
]
},
"afterImage":{
"@class":"io.seata.rm.datasource.sql.struct.TableRecords",
"tableName":"work_order",
"rows":[
"java.util.ArrayList",
[
{
"@class":"io.seata.rm.datasource.sql.struct.Row",
"fields":[
"java.util.ArrayList",
[
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"id",
"keyType":"PRIMARY_KEY",
"type":4,
"value":4
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"work_order_number",
"keyType":"NULL",
"type":12,
"value":"asd"
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"work_order_title",
"keyType":"NULL",
"type":12,
"value":"bfkzc4oganhbirygfd87"
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"client_name",
"keyType":"NULL",
"type":12,
"value":"袁玉环2"
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"client_contact",
"keyType":"NULL",
"type":12,
"value":"腾讯333"
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"client_phone",
"keyType":"NULL",
"type":12,
"value":"181562383652"
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"order_service_type",
"keyType":"NULL",
"type":4,
"value":1
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"order_type",
"keyType":"NULL",
"type":4,
"value":1
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"service_type",
"keyType":"NULL",
"type":4,
"value":3
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"deal_user_id",
"keyType":"NULL",
"type":4,
"value":20
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"order_content",
"keyType":"NULL",
"type":-1,
"value":"周末晚上聚会2"
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"create_user_id",
"keyType":"NULL",
"type":4,
"value":null
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"create_time",
"keyType":"NULL",
"type":93,
"value":null
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"specify_processing_day",
"keyType":"NULL",
"type":91,
"value":[
"java.sql.Date",
1653321600000
]
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"receive_time",
"keyType":"NULL",
"type":93,
"value":null
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"receiver_submit_time",
"keyType":"NULL",
"type":93,
"value":null
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"end_time",
"keyType":"NULL",
"type":93,
"value":null
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"order_status",
"keyType":"NULL",
"type":4,
"value":null
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"receiver_refuse_content",
"keyType":"NULL",
"type":-1,
"value":null
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"receiver_deal_content",
"keyType":"NULL",
"type":-1,
"value":null
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"receiver_result_status",
"keyType":"NULL",
"type":4,
"value":null
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"send_refuse_content",
"keyType":"NULL",
"type":12,
"value":null
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"device_model",
"keyType":"NULL",
"type":12,
"value":null
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"device_number",
"keyType":"NULL",
"type":12,
"value":null
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"service_report_images",
"keyType":"NULL",
"type":-1,
"value":"http://gxm-tensquare.oss-cn-beijing.aliyuncs.com/2022-04/25/e214ba1b-6541-4756-8a2b-fdb1c29111e4.jpg"
}
]
]
}
]
]
}
}
]
]
}
6、根据上述的json文件内容,直接操作是insert,而device没有插入成功,但是它插入成功了,我们把相关的数据删除即可,后续如果是其他情况,比如update这种,根据前后镜像数据,按照需求处理。
1.2、测试相应方法上不放置spring的事务注解,多个业务是否正常回滚
1、对于上述的方法,我们知道每个order服务调用了本地的2个mapper,插入到他链接的数据库(gxm-300)中,然后远程调用deivce服务的方法,而device的方法里面是调用device本地的2个mapper,插入到他链接的数据库(gxm-301)中,所以,我们不在每个方法上面加上spring的事务注解,即不在order服务的saveWithDetail方法和device服务的insertWithLink方法上使用spring的事务注解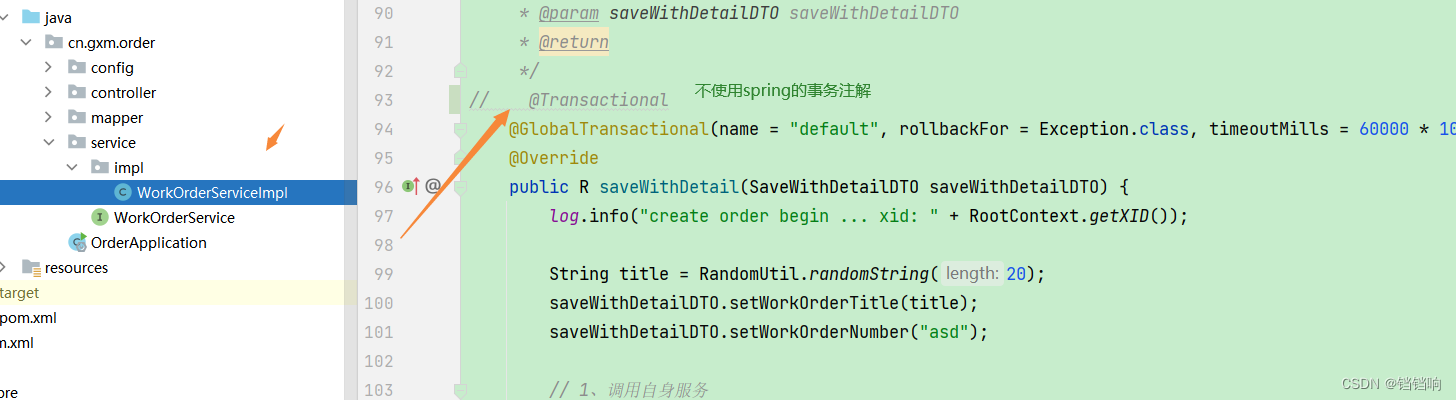
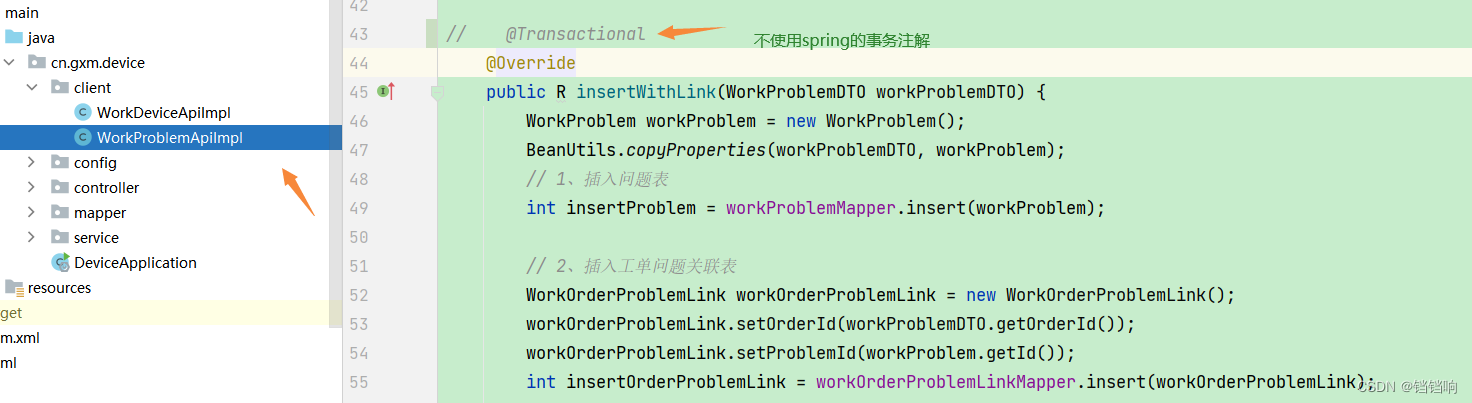
2、这个结果其实在我们的第一节中简单的使用中就已经证明了,是可以的,我们不需要再加上对应的spring的事务注解了,seata 会保证的。
3、当然有人可能会说,对于下面这个方法,也许device本身的业务需要用到,用的不是分布式事务,那需要spring 来管理,我需要加上spring的事务处理注解,这个说法呢,你当然可以加上spring的事务注解,seata不会影响,但是我不建议,因为这个类下的api就是提供给外部调用的,如果是内部本服务的业务应该在其他类中去处理,不应该放在这里,被其内部调用是不合适的。
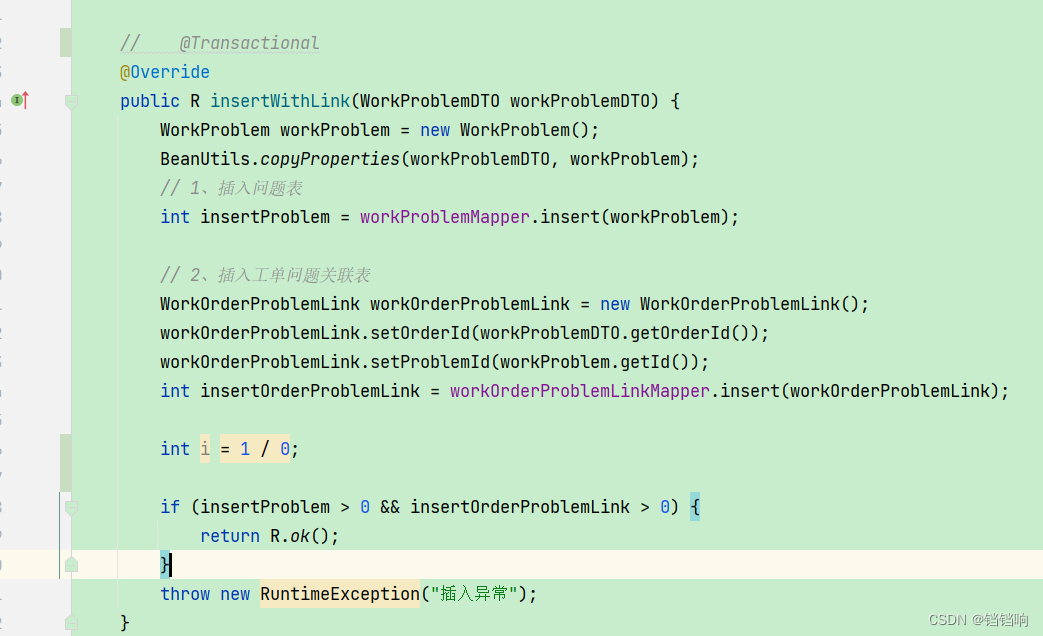
1.3、测试seata回滚时,镜像数据被其他事务修改后,无法回滚成功的情况
1、首先大家要了解seata的AT模式流程,官方文档:Seata AT 模式
2、看完这个流程之后,大家就能脑补出一个问题,就是如下在全局事务未提交的情况下,镜像数据被其他现场修改了,如下,这种情况下seata是没有办法处理,除非你关闭前后镜像检查,强制数据更新,这太不稳妥了。
订单服务和库存服务。
开启全局事务后,库存服务已提交本地事务,50库存修改为49,全局事务未提交。
另外一个线程开启本地事务,修改库存从49到48。
然而订单服务报错,全局事务需要回滚,这时会全局事务会回滚失败,出现脏数据。
有什么好的方案去处理这种情况吗?或者避免这种情况的发生
3、这种问题,github的issue已经提出了 脏写导致数据回滚失败?,这种情况,分两种处理方式
4、这篇官方文章也说的很好 详解 Seata AT 模式事务隔离级别与全局锁设计,也说到了脏写的情况和处理。
1.3.1、模拟这种情况
1、还是之前的接口,我们修改seata的全局控制时间,因为等下测试时间会很长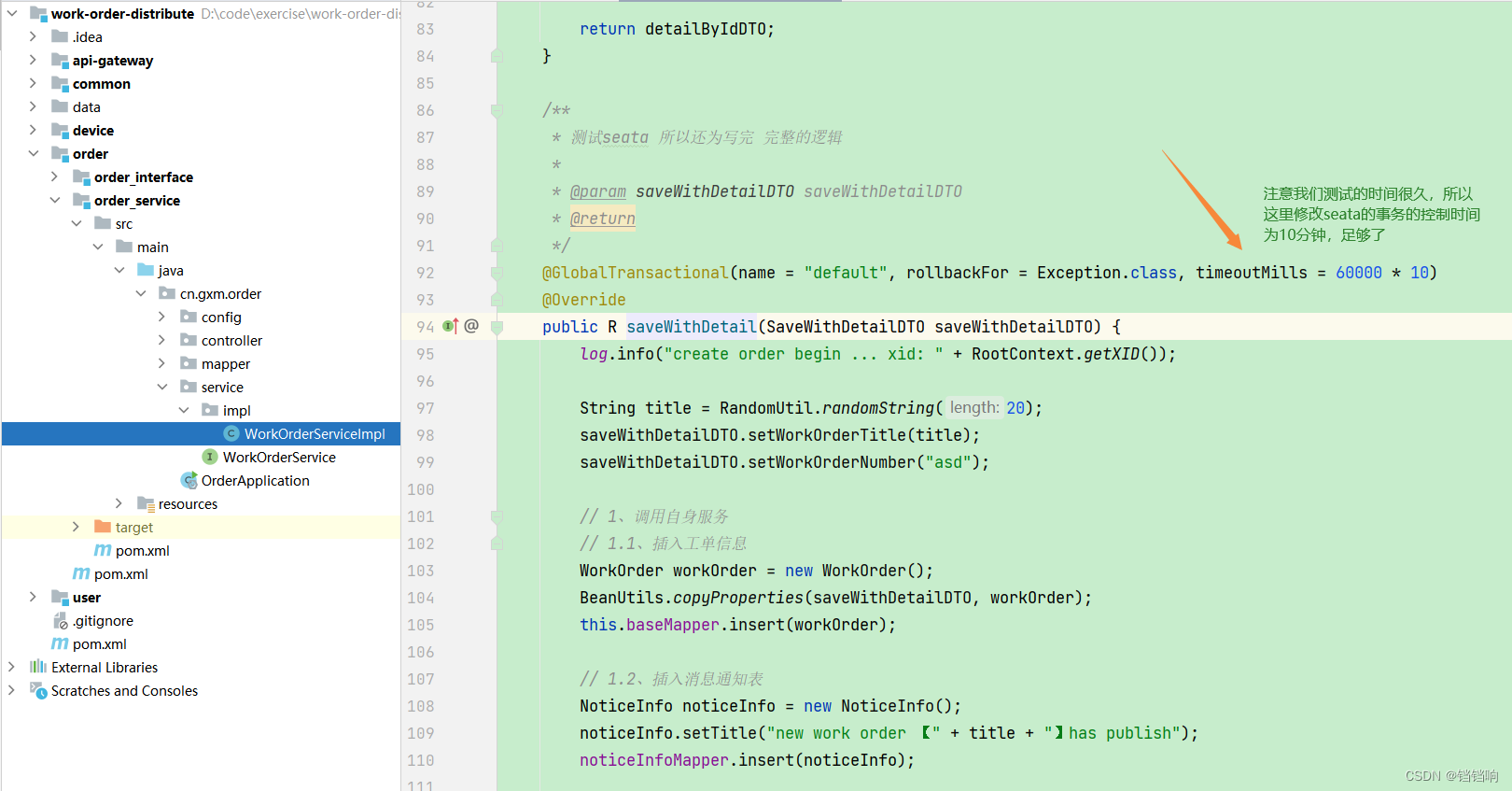
2、我们在device服务中在执行玩所有的mapper后停顿20秒,此时数据库就已经有2个数据库的4个表的数据了,如下
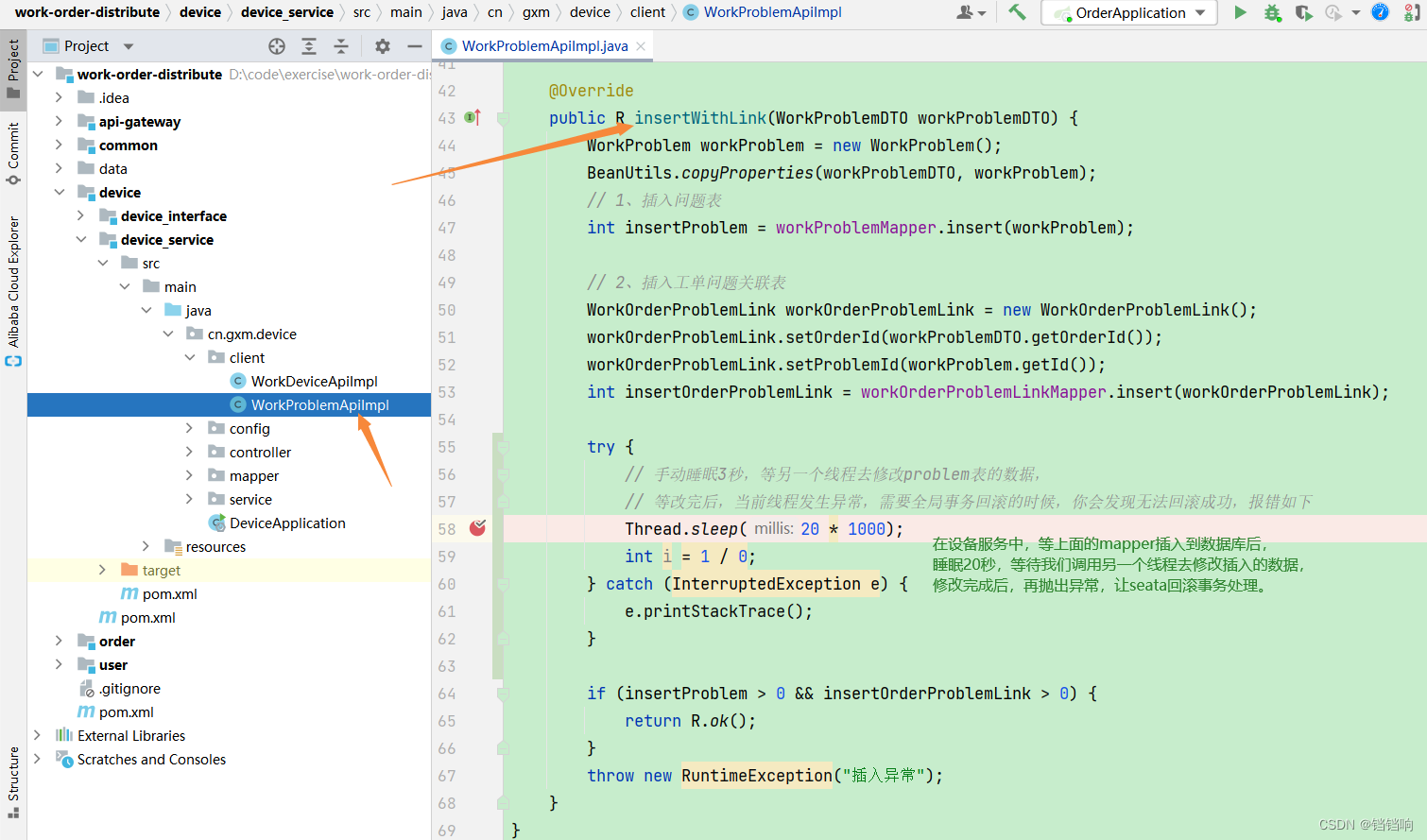
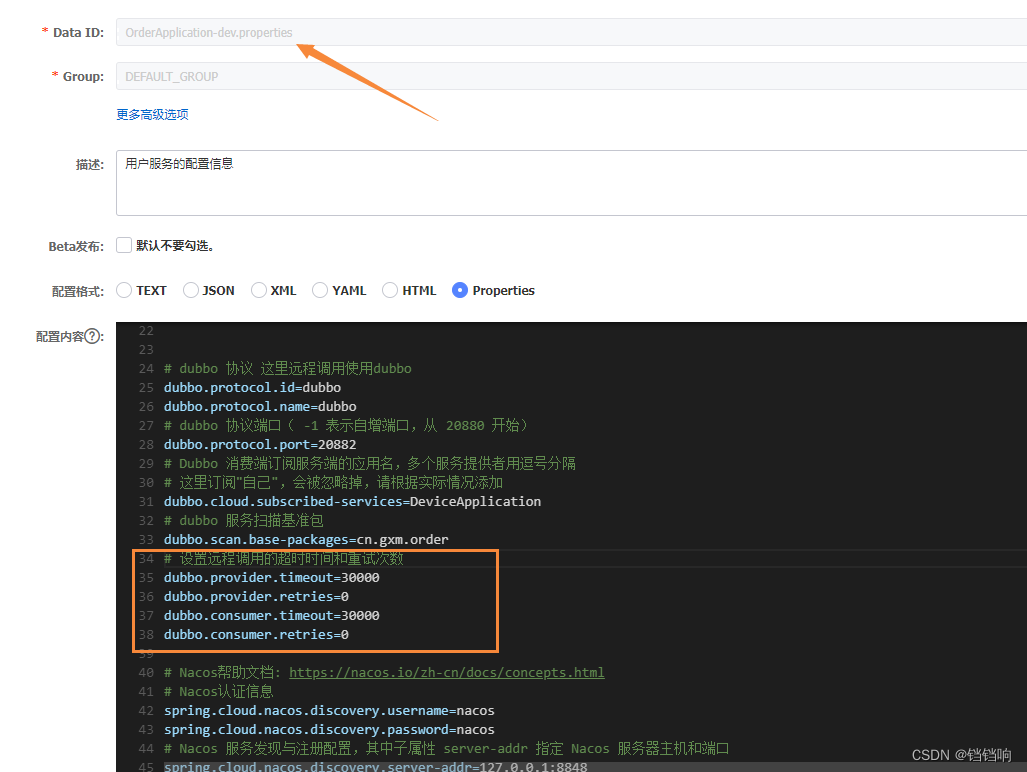
3、注意这里我们设置的时间很长,所以远程调用可能会出现超时了,直接导致seata回滚,我们还未来得急调用修改的线程呢,所以,我们需要修改远程调用的组件的超时时间,我这里用的是dubbo,所以我设置消费者order的dubbo的调用超时时间即可,修改为30秒,足够了。 springBoot集成dubbo的超时时间设置
# 设置远程调用的超时时间和重试次数
dubbo.provider.timeout=30000
dubbo.provider.retries=0
dubbo.consumer.timeout=30000
dubbo.consumer.retries=0
4、增加一个线程去修改未提交的数据,在前面停顿的在20秒的时候,我们去调用如下接口,把为提交事务的数据修改掉。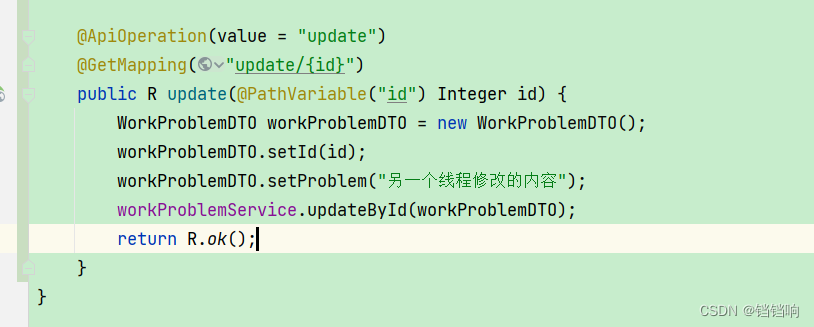
5、我们另一个线程修改的是device服务的数据,所以,可以看到控制台日志如下,而且rm此时会一直尝试,可以看后面的那张图,一直尝试一直失败,控制台一直打印尝试失败的信息。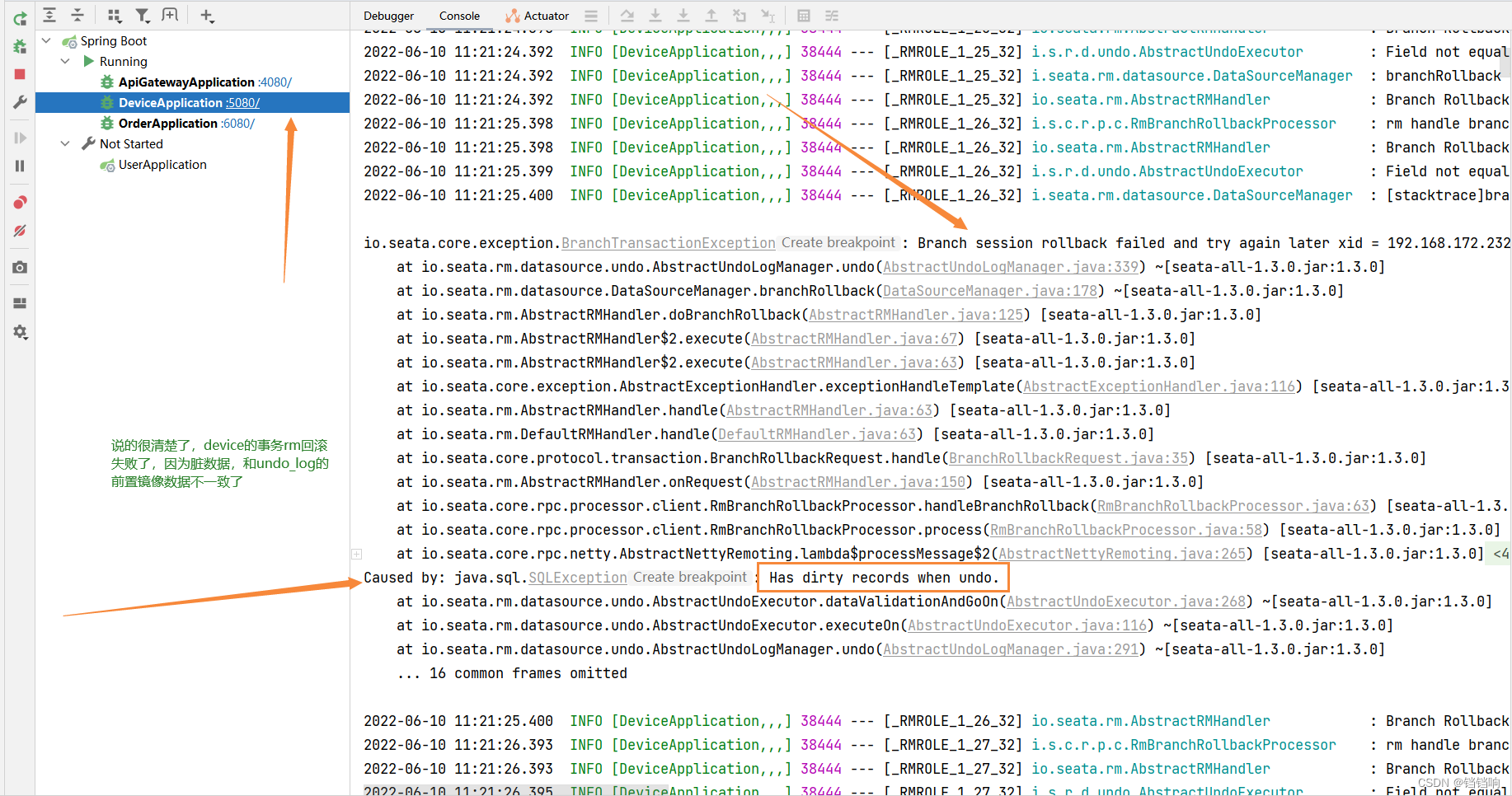

6、数据层面如下,所以数据库gxm-300和gxm-301的undo_log的数据条数加起来一共一定是3条。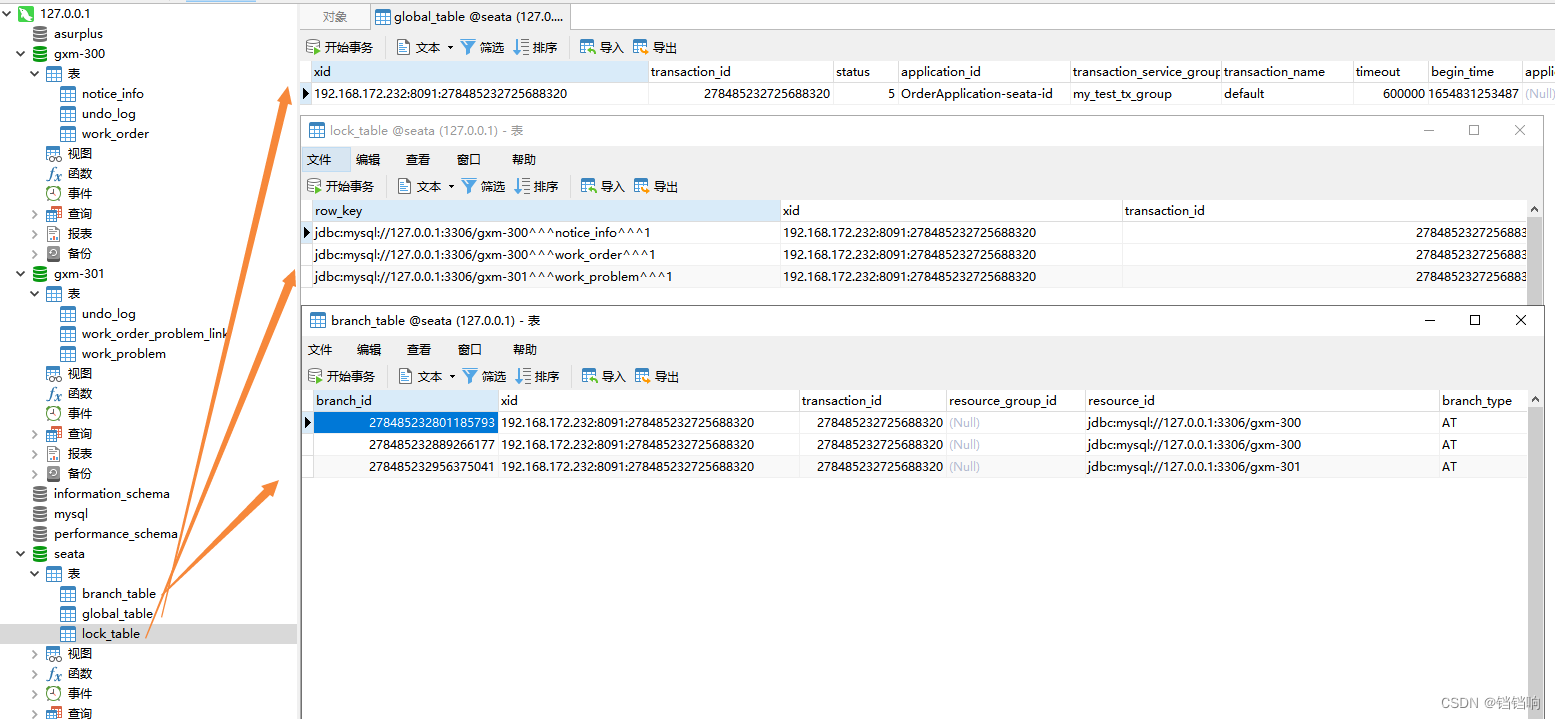
1.3.2、第一种处理方式(手动处理,根据业务挽救)
7、我们可以根据上述的表情况数据,来手动根据业务处理,比如通过lock_table的字段pk,和当前业务知道,多插入了这三个表的三条数据,主键都是为1的,所以根据我们的业务我们直接删除相关数据即可。然后记得seata数据库的相关表的数据也得删除偶,以及对应的undo_log表数据也需要删除。
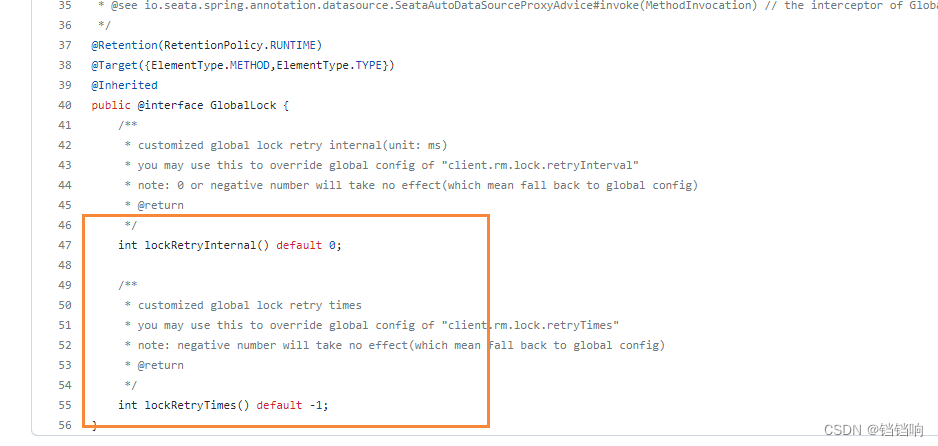
1.3.3、第二种处理方式(@GlobalLock)
1、在本地修改的事务上加上@GlobalLock
- 其中参数
lockRetryTimes尝试间隔时间,lockRetryTimes尝试次数,说明在多少秒内间隔多少次会不断重试获取全局锁,如果该记录在全局事务中,则会失败- 这两个参数是在1.4.0和其以上版本才出现的,1.3.0m还没有。
2、可以参考 Seata入门系列(22)[email protected]注解使用场景及源码分析,说的很好
3、另一个修改的线程发现修改的数据在全局事务中,所以不支持修改。
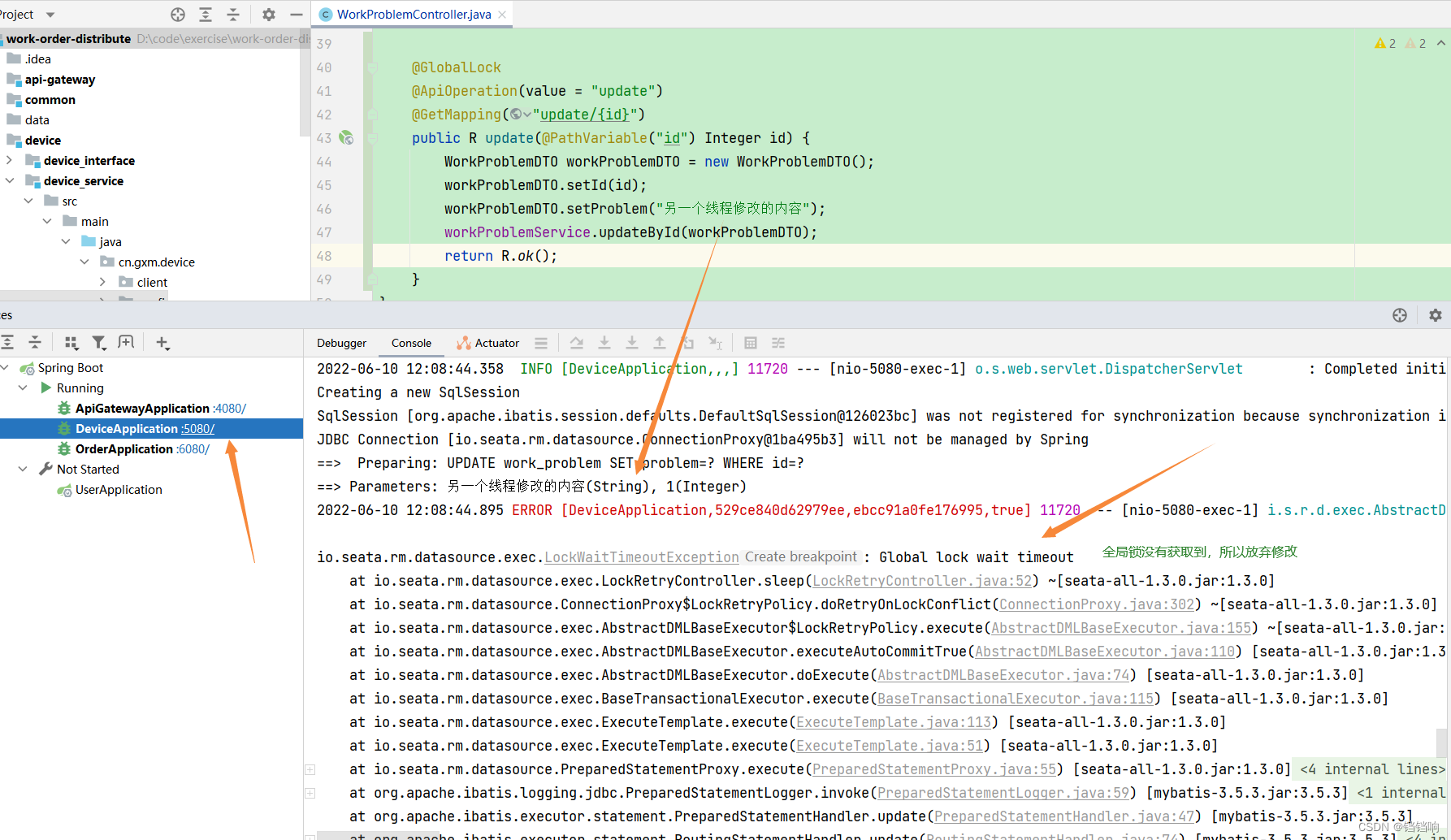
4、事务回滚成功,undo_log 的前置镜像数据和数据库的数据保持一致,说明没有被之前的那个线程修改掉。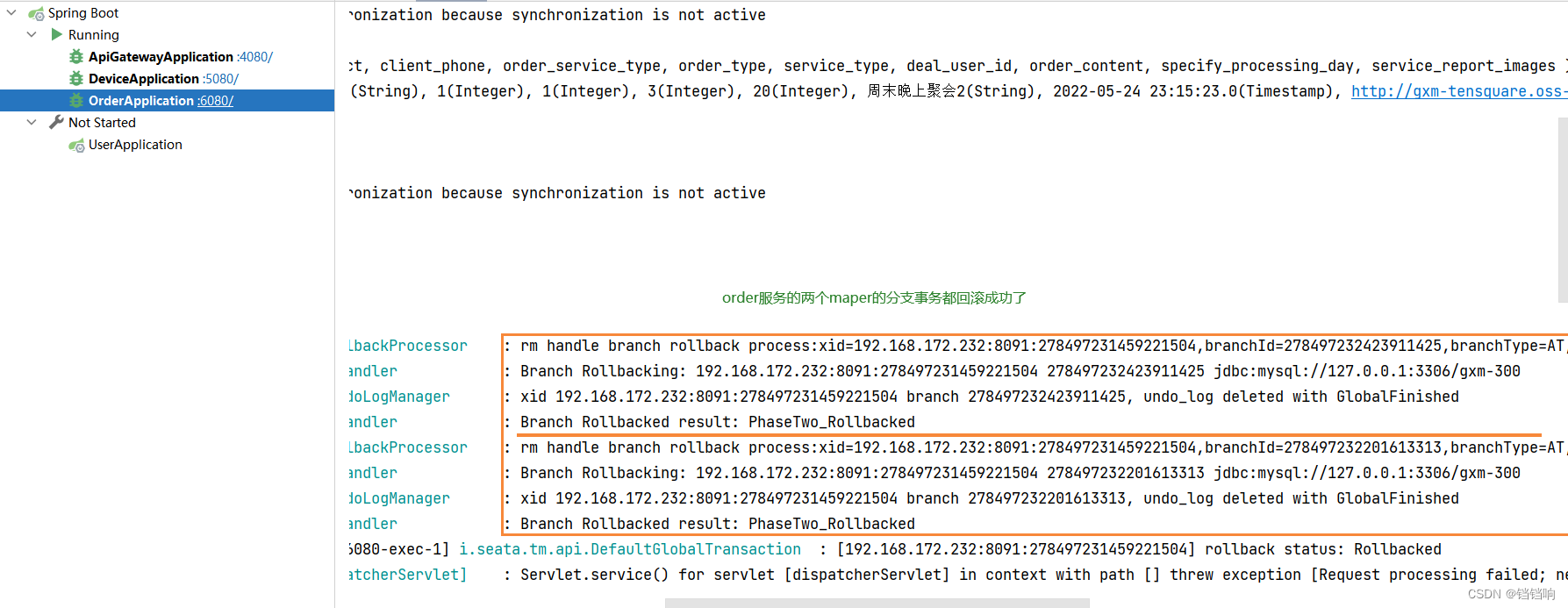
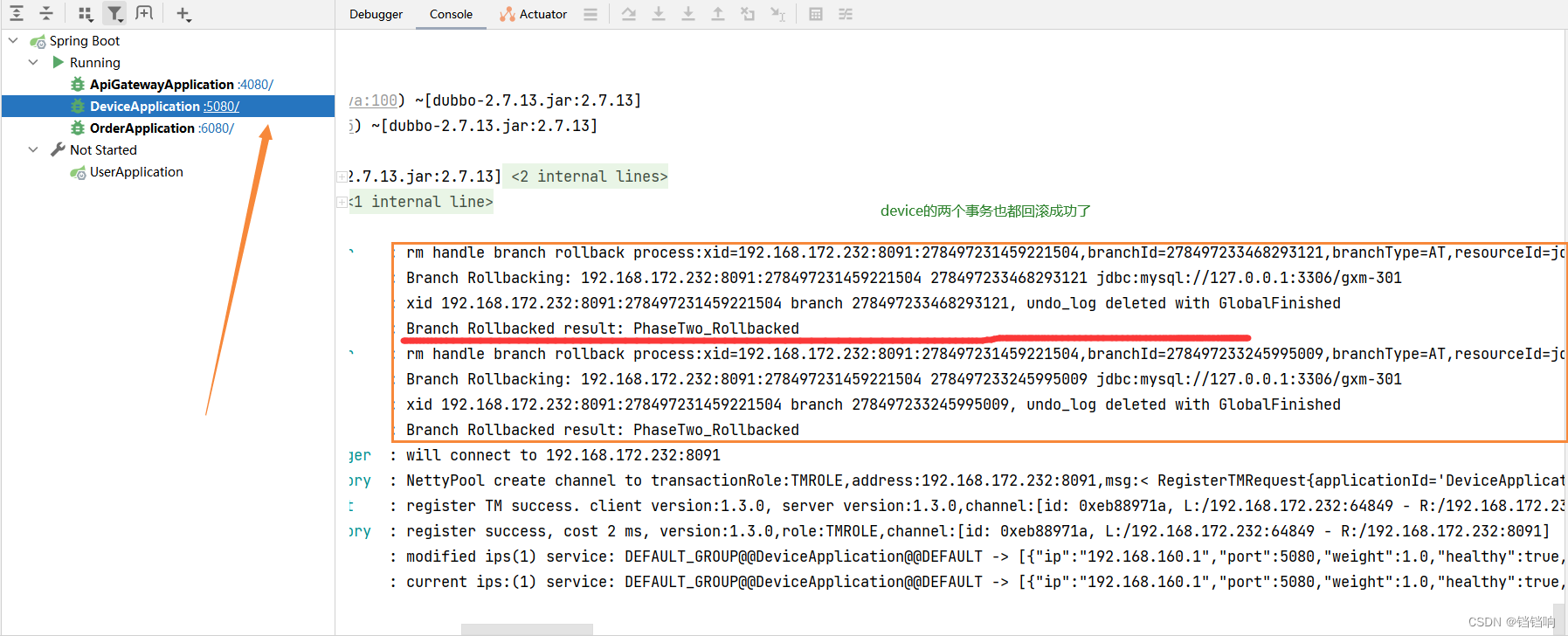
二、TCC 模式
1、其实TCC模式和AT流程上来说是一样的,只是AT是自动根据undo_log来进行事务回滚和补偿,而TCC则需要我们提供相应的接口,官方也都表明了 Seata TCC 模式,可以看到TCC的第一阶段和第二阶段都是自定义的逻辑,seata只管在特定情况下调用。而AT就是全靠undo_log,然后seata判断来帮你处理。

2、这里需要介绍几个后面需要用到的基础注解和参数
@LocalTCC适用于SpringCloud+Feign模式下的TCC,但是当我实验的时候,调用使用的是dubbo,理论上是不用这个注解的(官方的demo中用dubbo的也没有加这个注解),但是我试了一下,不加就会出现 tcc BusinessActionContext get null ,官方到现在还未处理,不知道是什么问题,我在下面也回复了。
@TwoPhaseBusinessAction注解try方法,其中name为当前tcc方法的bean名称,写方法名便可(记得全局唯一),commitMethod指向提交方法,rollbackMethod指向事务回滚方法。指定好三个方法之后,seata会根据全局事务的成功或失败,去帮我们自动调用提交方法或者回滚方法。@BusinessActionContextParameter注解可以将参数传递到二阶段(commitMethod/rollbackMethod)的方法,这个也是下面提到的问题,第二阶段获取的参数只能是第一阶段的一开始通过注解定义的参数值,即使你在第一阶段修改,添加,也没法在第二阶段获取到最新的参数值。BusinessActionContext 便是指TCC事务上下文,可以通过该参数获取
xid、branchId、actionName,以及一些参数,注意,这里有个问题就是 于prepare阶段,也就是try阶段代码的数据添加参数,或者修改参数,在confrim和cancel阶段的方法里面是接受不到你修改后的数据的。
3、TCC 参与者需要实现三个方法,分别是一阶段 Try 方法、二阶段 Confirm 方法以及二阶段 Cancel 方法。在 TCC 参与者的接口中需要先加上 @TwoPhaseBusinessAction 注解,并声明这个三个方法,如下所示
public interface TccAction {
@TwoPhaseBusinessAction(name = "yourTccActionName", commitMethod = "confirm", rollbackMethod = "cancel")
public boolean try(
BusinessActionContext businessActionContext, int a, int b);
public boolean confirm(BusinessActionContext businessActionContext);
public boolean cancel(BusinessActionContext businessActionContext);
}
@TwoPhaseBusinessAction 注解属性说明:
name:TCC参与者的名称,可自定义,但必须全局唯一。commitMethod:指定二阶段 Confirm 方法的名称,可自定义。rollbackMethod:指定二阶段 Cancel 方法的名称,可自定义。
4、TCC 方法参数说明:
Try:第一个参数类型必须是BusinessActionContext,后续参数的个数和类型可以自定义。Confirm:有且仅有一个参数,参数类型必须是 BusinessActionContext,后续为相应的参数名(businessActionContext)。Cancel:有且仅有一个参数,参数类型必须是
BusinessActionContext,后续为相应的参数名(businessActionContext)。
5、TCC 方法返回类型说明:
一阶段的
Try方法可以为 boolean 类型,也可以自定义返回值。二阶段的
Confirm和 Cancel 方法的返回类型必须为 boolean 类型。
6、各接口作用:(下面的demo实际上并没有严格按照这个方式来执行,建议生产环境按照如下步骤保证,要建立一张资源预留表用于锁住资源,可以参考这篇文章,原生TCC实现)
可以参考demo,原生TCC实现 https://github.com/prontera/spring-cloud-rest-tcc/tree/readme-img,里面就建立了一张资源表,用于try阶段,预留资源。
Try:初步操作。完成所有业务检查,预留必须的业务资源。(比如select for update 锁住某条记录,预留指定资源)Confirm:确认操作。真正执行的业务逻辑(比如根据try的数据,更新库存之类的操作),不作任何业务检查,只使用 Try 阶段预留的业务资源。因此,只要Try操作成功,Confirm必定能成功。另外,Confirm 操作需满足幂等性,保证一笔分布式事务能且只能成功一次。Cancel:取消操作。释放Try阶段预留的业务资源。同样的,Cancel操作也需要满足幂等性
2.1、代码模拟
2.1.1、业务service
1、还是上面的基础项目,不过需要稍微改动一下,我们抽取一个专门处理复杂业务的service类出来,里面分别调用order服务和device服务,这样看着清楚一些,如下,在调用的时候,BusinessActionContext 参数,我们传null即可,seata会为其赋值的。
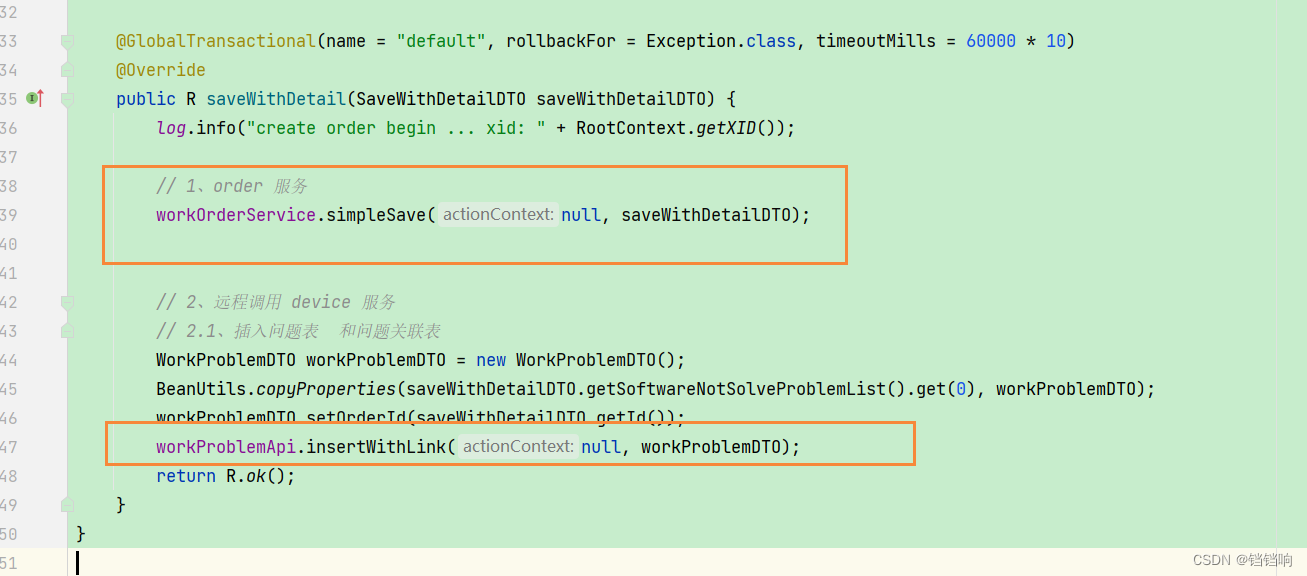
@GlobalTransactional(name = "default", rollbackFor = Exception.class, timeoutMills = 60000 * 10)
@Override
public R saveWithDetail(SaveWithDetailDTO saveWithDetailDTO) {
log.info("create order begin ... xid: " + RootContext.getXID());
// 1、order 服务
workOrderService.simpleSave(null, saveWithDetailDTO);
// 2、远程调用 device 服务
// 2.1、插入问题表 和问题关联表
WorkProblemDTO workProblemDTO = new WorkProblemDTO();
BeanUtils.copyProperties(saveWithDetailDTO.getSoftwareNotSolveProblemList().get(0), workProblemDTO);
workProblemDTO.setOrderId(saveWithDetailDTO.getId());
workProblemApi.insertWithLink(null, workProblemDTO);
return R.ok();
}
2、异常模拟我们放在device服务中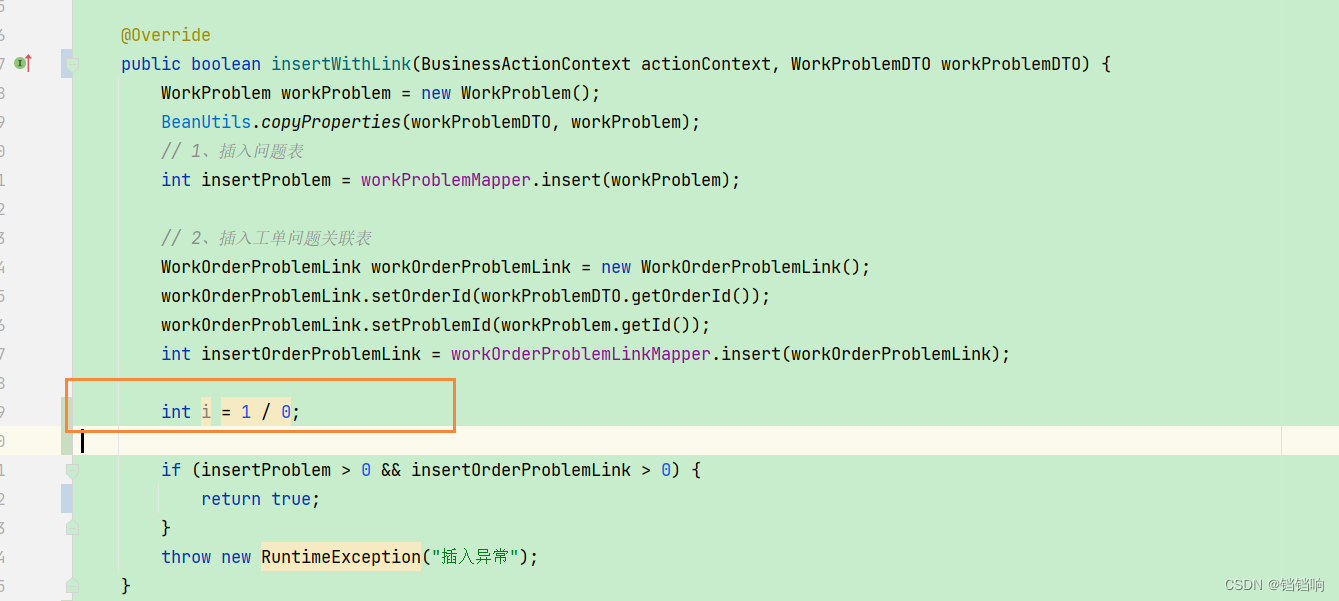
2.1.2、order服务
1、注意我们要在接口上加上注解@LocalTCC,开启tcc事务,并在第一阶段的方法上加上注解@TwoPhaseBusinessAction,并赋值注解的值,表明第二阶段的commit和rollback方法分别是什么,以及三个方法的返回值得是boolean
@LocalTCC
public interface WorkOrderService extends IService<WorkOrder> {
String simpleSave_BusinessActionContextParameter = "saveWithDetailDTO";
/** * 增加工单 * * @param saveWithDetailDTO saveWithDetailDTO */
@TwoPhaseBusinessAction(name = "DubboTccSimpleSaveActionOne", commitMethod = "simpleSaveCommit", rollbackMethod = "simpleSaveRollback")
boolean simpleSave(BusinessActionContext actionContext,
@BusinessActionContextParameter(paramName = simpleSave_BusinessActionContextParameter) SaveWithDetailDTO saveWithDetailDTO);
/** * Commit boolean. * 这个方法需要保持幂等和防悬挂 * * @param actionContext the action context * @return the boolean */
public boolean simpleSaveCommit(BusinessActionContext actionContext);
/** * Rollback boolean. * 这个方法需要保持幂等和防悬挂 * * @param actionContext the action context * @return the boolean */
public boolean simpleSaveRollback(BusinessActionContext actionContext);
}
2、实现类,因为我模拟的这个业务是插入,而二阶段回滚的时候,补偿肯定就是更具新增的id删除它,但是我试了一下,在第一阶段的actionContext#map里面增加参数,或者修改saveWithDetailDTO参数,都不行,在第二阶段只能获取到初始传参的saveWithDetailDTO值,这也就是我前面提到的,如果有和我一样的业务需求,可以考虑放到redis里面拿id,等等。
@Slf4j
@Service
public class WorkOrderServiceImpl implements WorkOrderService {
@DubboReference
private WorkDeviceApi workDeviceApi;
@DubboReference
private WorkProblemApi workProblemApi;
@Autowired
private NoticeInfoMapper noticeInfoMapper;
private static final String INSERT_ORDER_ID_KEY = "INSERT_ORDER_ID_KEY";
private static final String INSERT_NOTICE_INFO_ID_KEY = "INSERT_NOTICE_INFO_ID_KEY";
/** * * @param saveWithDetailDTO saveWithDetailDTO * @return */
// @Transactional 当然这个方法也可以加上spring 的 Transactional 注解
@Override
public boolean simpleSave(BusinessActionContext actionContext, SaveWithDetailDTO saveWithDetailDTO) {
// 属性 BusinessActionContext 不需要我们注入,seata会为我们注入的
String actionName = actionContext.getActionName();
String xid = actionContext.getXid();
long branchId = actionContext.getBranchId();
String title = RandomUtil.randomString(20);
saveWithDetailDTO.setWorkOrderTitle(title);
saveWithDetailDTO.setWorkOrderNumber("asd");
// 1、调用自身服务
// 1.1、插入工单信息
WorkOrder workOrder = new WorkOrder();
BeanUtils.copyProperties(saveWithDetailDTO, workOrder);
this.baseMapper.insert(workOrder);
saveWithDetailDTO.setId(workOrder.getId());
// 即使你在这个理修改了BusinessActionContext存储的数据,但是你在二阶段(commit/rollback)是拿不到修改后的数据的
// 只能拿到一开始初始化的数据,肯是因为在二阶段的BusinessActionContext对象,是新实例,只有初始的数据
// 没有后面修改的数据
// Map<String, Object> actionContextMap = actionContext.getActionContext();
// actionContextMap.put(INSERT_ORDER_ID_KEY, workOrder.getId());
// 1.2、插入消息通知表
NoticeInfo noticeInfo = new NoticeInfo();
noticeInfo.setTitle("new work order 【" + title + "】has publish");
noticeInfoMapper.insert(noticeInfo);
// actionContextMap.put(INSERT_NOTICE_INFO_ID_KEY, noticeInfo.getId());
return true;
}
@Override
public boolean simpleSaveCommit(BusinessActionContext actionContext) {
// 这里就可以获取 当初在prepare 阶段的加上注解 BusinessActionContextParameter 的值
log.info("simpleSave Commit, params : {}", JSONUtil.toJsonStr(actionContext.getActionContext(simpleSave_BusinessActionContextParameter)));
//todo 若一阶段资源预留,这里则要提交资源
// 表示是否成功
return true;
}
@Override
public boolean simpleSaveRollback(BusinessActionContext actionContext) {
// 这里就可以获取 当初在prepare 阶段的加上注解 BusinessActionContextParameter 的值
JSONObject saveWithDetailDTOJSONObject = (JSONObject) actionContext.getActionContext(simpleSave_BusinessActionContextParameter);
log.info("simpleSave Commit , params : {}", JSONUtil.toJsonStr(saveWithDetailDTOJSONObject));
// 补偿措施,如下
// 1、解决幂等 工单表id 为空,说明第一步都还未执行成功,无需补偿该步骤
// 这里可以换成从redis中获取,这样 Integer orderId = (Integer) actionContext.getActionContext(INSERT_ORDER_ID_KEY);,是获取不到第一节端存入的值的
// 我这里为了方便演示就写成1了,因为的每次演示完后,都会truncate table
Integer orderId = 1;
if (orderId == null) {
return true;
} else {
// 删除插入work_order表的数据
this.baseMapper.deleteById(orderId);
}
// 2、解决幂等 消息通知表 id 为空,说明未插入,无需补偿该步骤
// 这里可以换成从redis中获取,这样 Integer noticeInfoId = (Integer) actionContext.getActionContext(INSERT_NOTICE_INFO_ID_KEY);,是获取不到第一节端存入的值的
// 我这里为了方便演示就写成1了,因为的每次演示完后,都会truncate table
Integer noticeInfoId = 1;
if (noticeInfoId == null) {
return true;
} else {
// 删除插入notice_Info表的数据
noticeInfoMapper.deleteById(noticeInfoId);
}
return true;
}
}
2.1.3、device服务
1、注意我们要在接口上加上注解@LocalTCC,开启tcc事务,并在第一阶段的方法上加上注解@TwoPhaseBusinessAction,并赋值注解的值,表明第二阶段的commit和rollback方法分别是什么,以及三个方法的返回值得是boolean
@LocalTCC
public interface WorkProblemApi {
String insertWithLink_BusinessActionContextParameter = "workProblemDTO";
/** * 插入时,插入对应的工单问题表 * * @param workProblemDTO * @return */
@TwoPhaseBusinessAction(name = "DubboTccInsertWithLinkActionTwo", commitMethod = "insertWithLinkCommit", rollbackMethod = "insertWithLinkRollback")
boolean insertWithLink(BusinessActionContext actionContext,
@BusinessActionContextParameter(paramName = insertWithLink_BusinessActionContextParameter) WorkProblemDTO workProblemDTO);
/** * Commit boolean. * * @param actionContext the action context * @return the boolean */
public boolean insertWithLinkCommit(BusinessActionContext actionContext);
/** * Rollback boolean. * * @param actionContext the action context * @return the boolean */
public boolean insertWithLinkRollback(BusinessActionContext actionContext);
}
2、实现类,因为我模拟的这个业务是插入,而二阶段回滚的时候,补偿肯定就是更具新增的id删除它,但是我试了一下,在第一阶段的actionContext#map里面增加参数,或者修改workProblemDTO参数,都不行,在第二阶段只能获取到初始传参的workProblemDTO值,这也就是我前面提到的,如果有和我一样的业务需求,可以考虑放到redis里面拿id,等等。
@Slf4j
@DubboService
public class WorkProblemApiImpl implements WorkProblemApi {
@Autowired
private WorkProblemMapper workProblemMapper;
@Autowired
private WorkOrderProblemLinkMapper workOrderProblemLinkMapper;
private static final String INSERT_PROBLEM_ID_KEY = "INSERT_PROBLEM_ID_KEY";
private static final String INSERT_ORDER_PROBLEM_LINK_ID_KEY = "INSERT_ORDER_PROBLEM_LINK_ID_KEY";
@Override
public boolean insertWithLink(BusinessActionContext actionContext, WorkProblemDTO workProblemDTO) {
WorkProblem workProblem = new WorkProblem();
BeanUtils.copyProperties(workProblemDTO, workProblem);
// 1、插入问题表
int insertProblem = workProblemMapper.insert(workProblem);
// 2、插入工单问题关联表
WorkOrderProblemLink workOrderProblemLink = new WorkOrderProblemLink();
workOrderProblemLink.setOrderId(workProblemDTO.getOrderId());
workOrderProblemLink.setProblemId(workProblem.getId());
int insertOrderProblemLink = workOrderProblemLinkMapper.insert(workOrderProblemLink);
// 模拟异常
int i = 1 / 0;
if (insertProblem > 0 && insertOrderProblemLink > 0) {
return true;
}
throw new RuntimeException("插入异常");
}
@Override
public boolean insertWithLinkCommit(BusinessActionContext actionContext) {
// 这里就可以获取 当初在prepare 阶段的加上注解 BusinessActionContextParameter 的值
log.info("insertWithLink commit, params : {}", JSONUtil.toJsonStr(actionContext.getActionContext(insertWithLink_BusinessActionContextParameter)));
//todo 若一阶段资源预留,这里则要提交资源
// 表示是否成功
return true;
}
@Override
public boolean insertWithLinkRollback(BusinessActionContext actionContext) {
// 这里就可以获取 当初在prepare 阶段的加上注解 BusinessActionContextParameter 的值
JSONObject workProblemDTOJSONObject = (JSONObject) actionContext.getActionContext(insertWithLink_BusinessActionContextParameter);
log.info("insertWithLink Rollback, params : {}", JSONUtil.toJsonStr(workProblemDTOJSONObject));
// 补偿措施,如下
// 1、解决幂等 问题表id 为空,说明第一步都还未执行成功,无需补偿该步骤
// 这里可以换成从redis中获取,这样 (Integer) actionContext.getActionContext(INSERT_PROBLEM_ID_KEY);,是获取不到第一节端存入的值的
// 我这里为了方便演示就写成1了,因为的每次演示完后,都会truncate table
Integer insertProblemId = 1;
if (insertProblemId == null) {
return true;
} else {
// 删除插入work_order表的数据
this.workProblemMapper.deleteById(insertProblemId);
}
// 2、解决幂等 工单问题关联表 id 为空,说明未插入,无需补偿该步骤
// 这里可以换成从redis中获取,这样 (Integer) actionContext.getActionContext(INSERT_ORDER_PROBLEM_LINK_ID_KEY); 是获取不到第一节端存入的值的
// 我这里为了方便演示就写成1了,因为的每次演示完后,都会truncate table
Integer insertOrderProblemLinkId = 1;
if (insertOrderProblemLinkId == null) {
return true;
} else {
// 删除插入work_order_problem_link表的数据
workOrderProblemLinkMapper.deleteById(insertOrderProblemLinkId);
}
return true;
}
}
2.1.4、测试分析结果
1、我们在4个mapper都执行完成时,且异常还未还发生的地方打一个断点,如下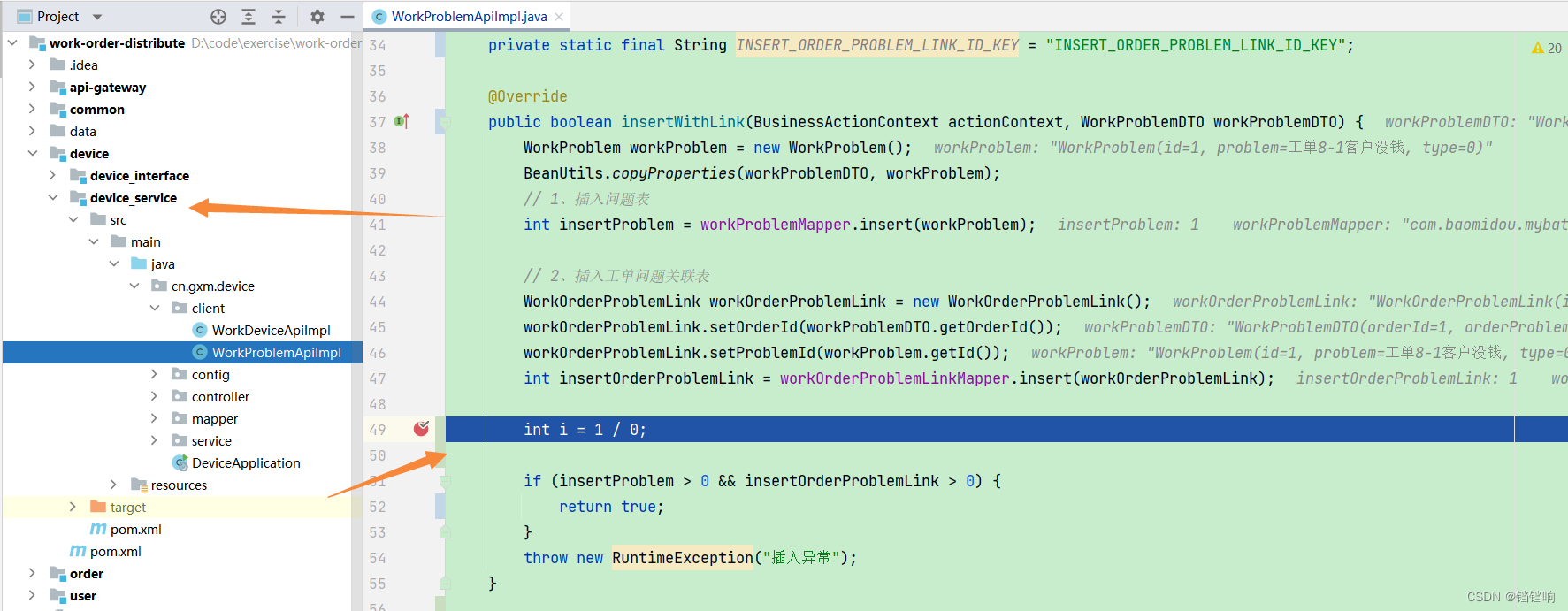
2、4张业务表中都插入了 对于的数据,此时因为我们使用的是tcc模式,rollback的事情需要我们自己去处理,所以undo_log表中是没有数据的,你也可以直接删除这个undo_log表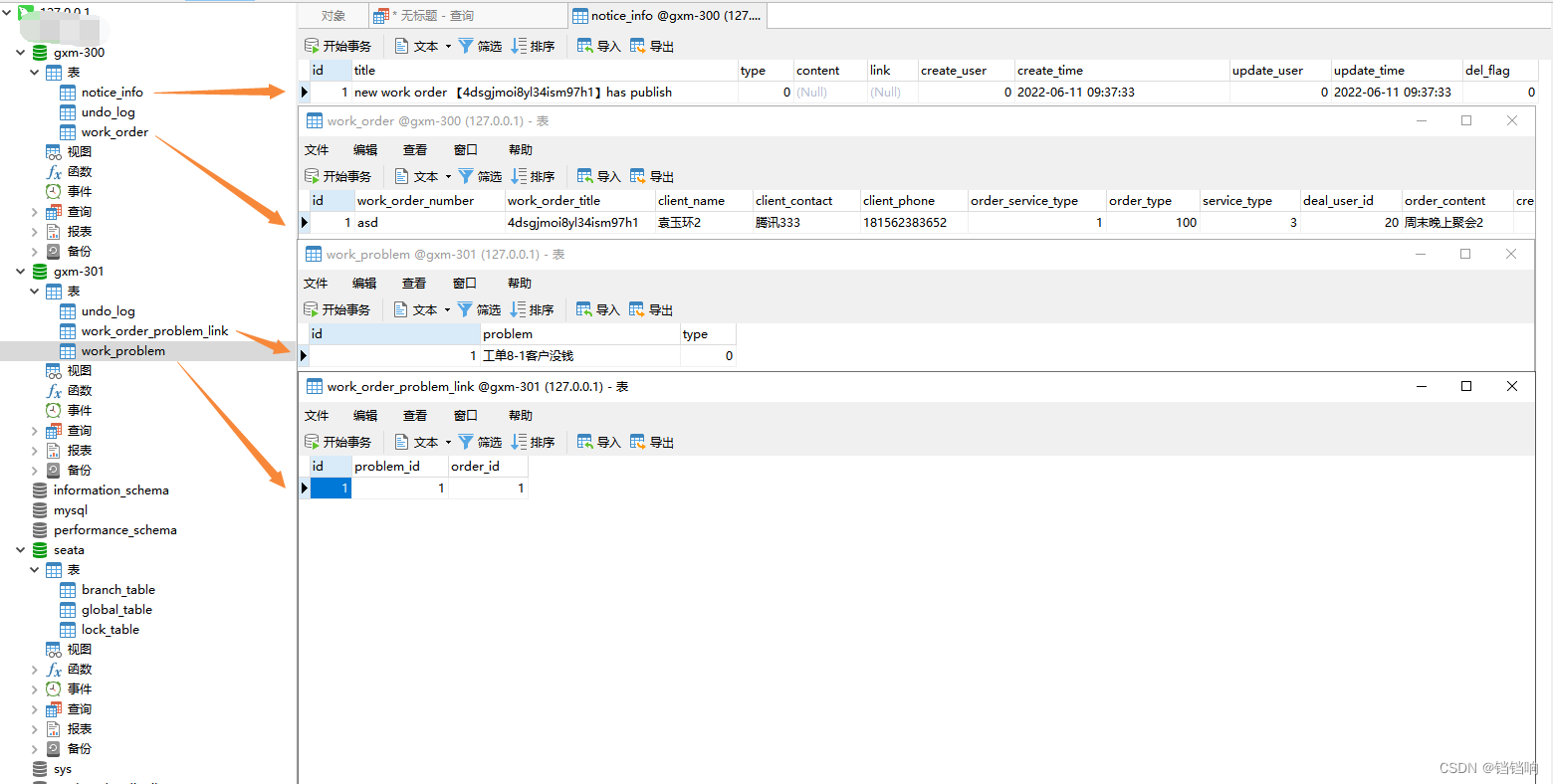
3、seata 服务端3张表,可以看到branch_table表中的分支类型已经换成了TCC模式,一个两个分支,分别是order服务的tcc,和device服务的tcc,表中还有一个字段application-data就是你操作的数据。
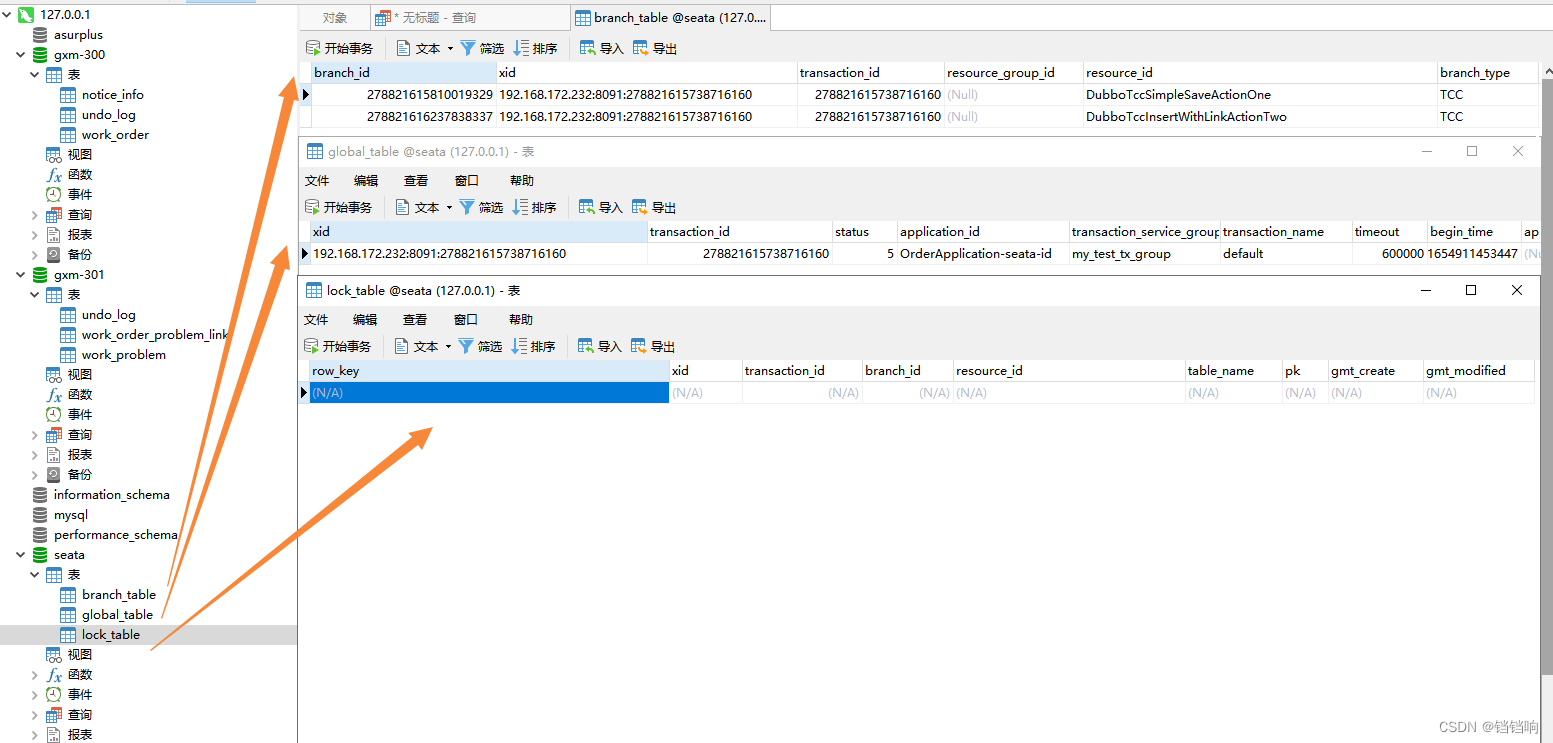
4、放开断点后,可以看到发生了异常,所以2个服务(4个mapper)都要回滚
5、order服务日志分析如下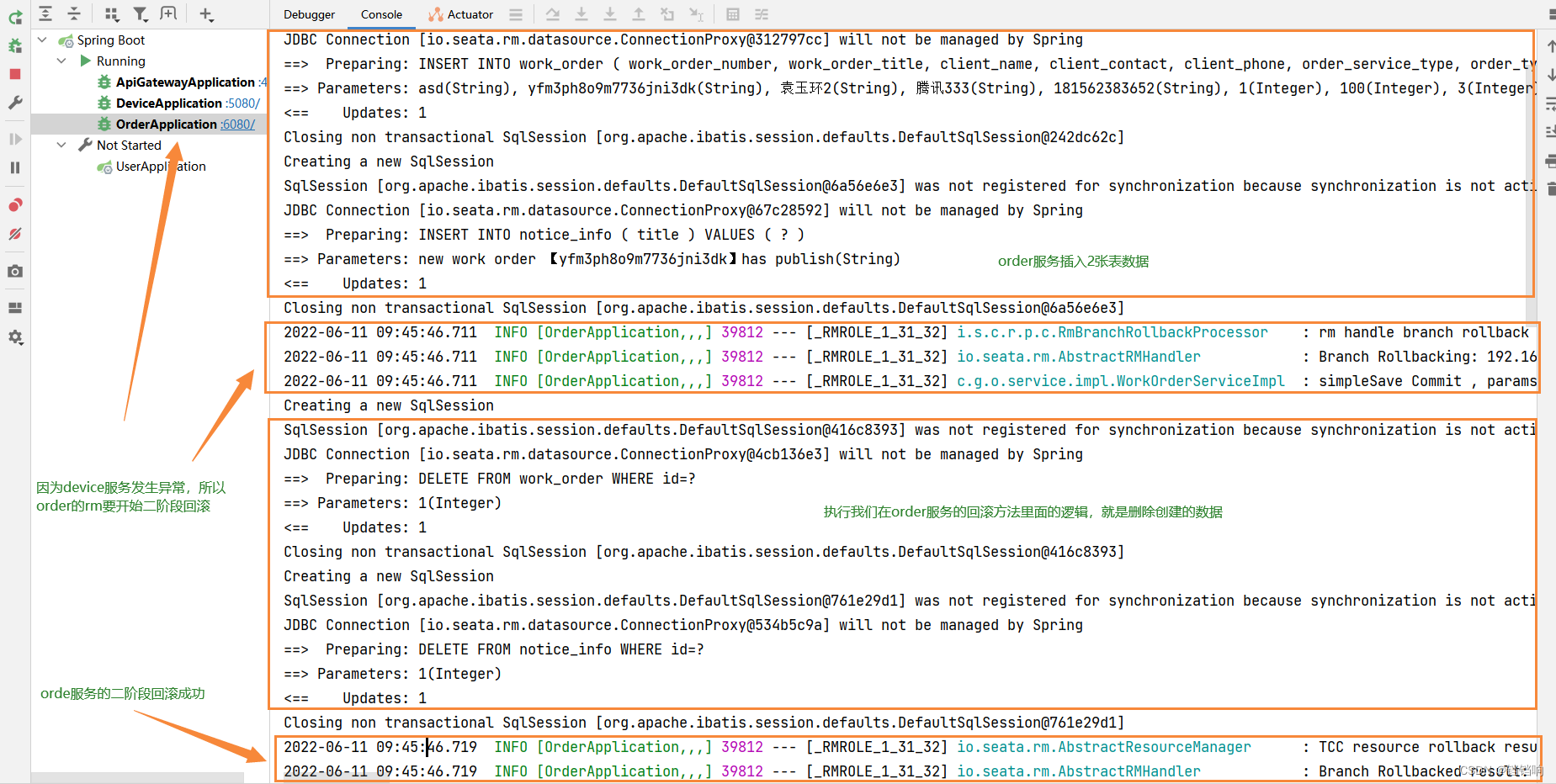
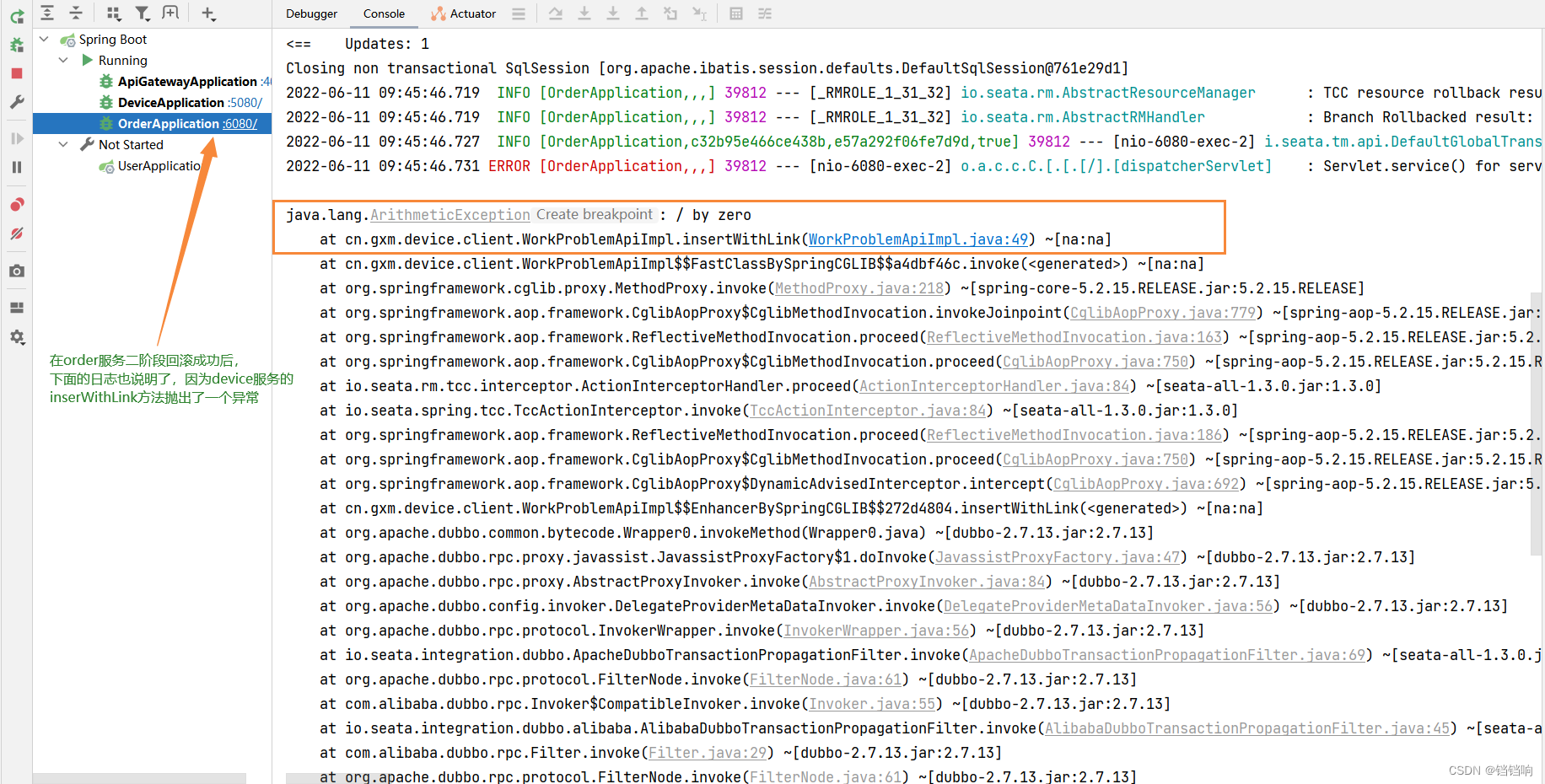
6、device服务日志分析如下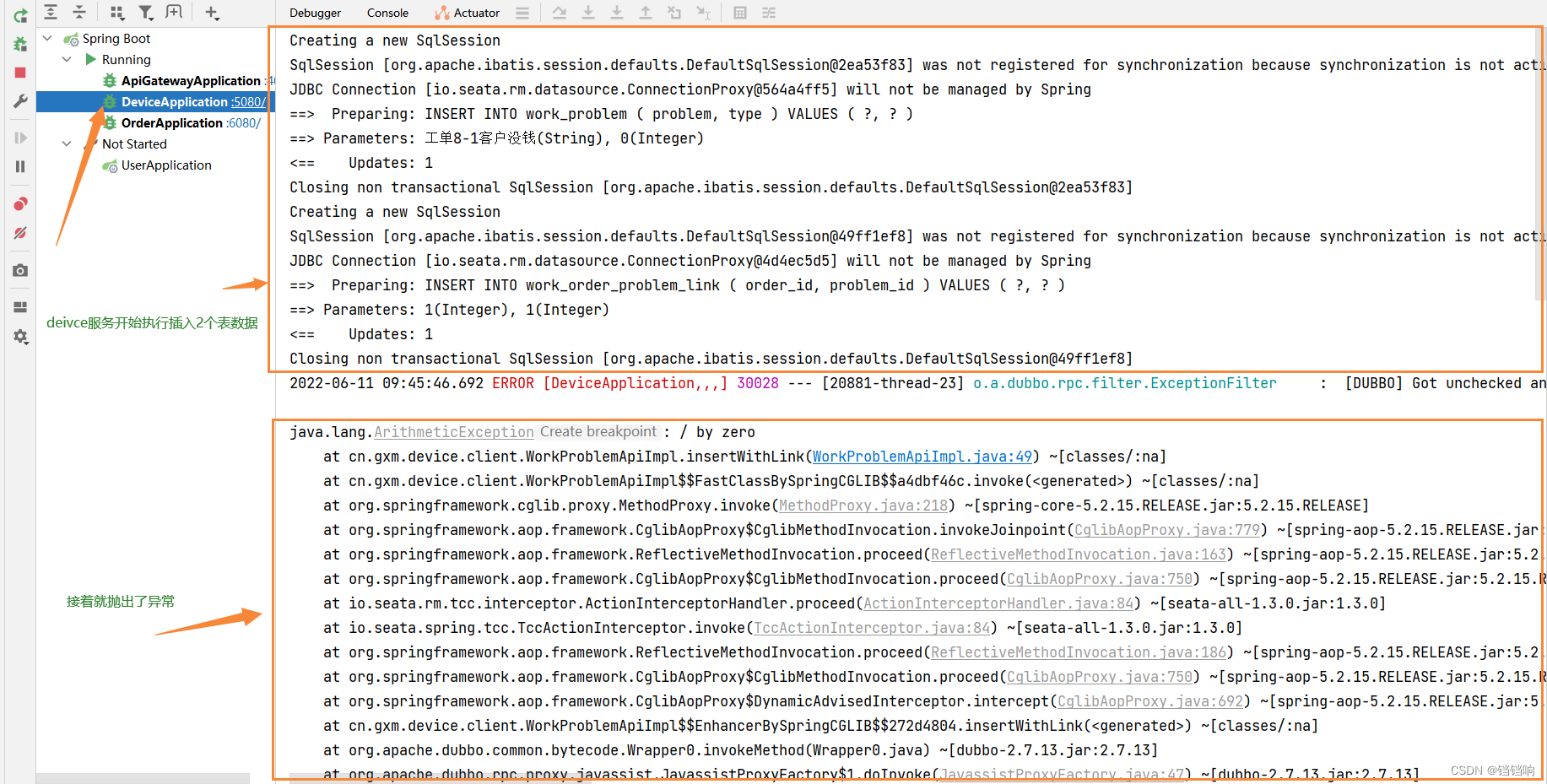
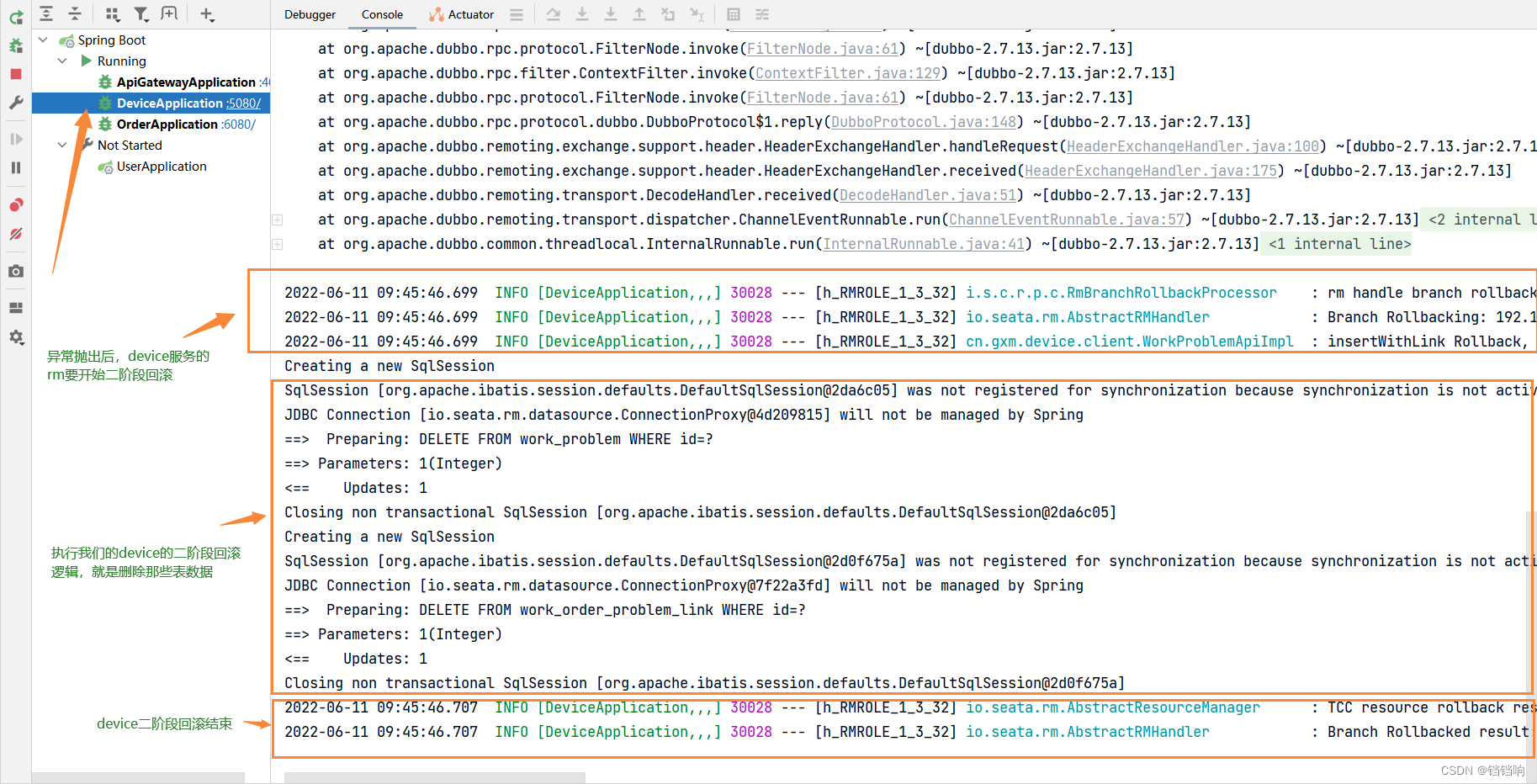
7、查看数据库,当然你也可以看下每个表的自增id,是否已经从2开始了,如果从2开始了,就说明,之前有插入,不过后面回滚删除了。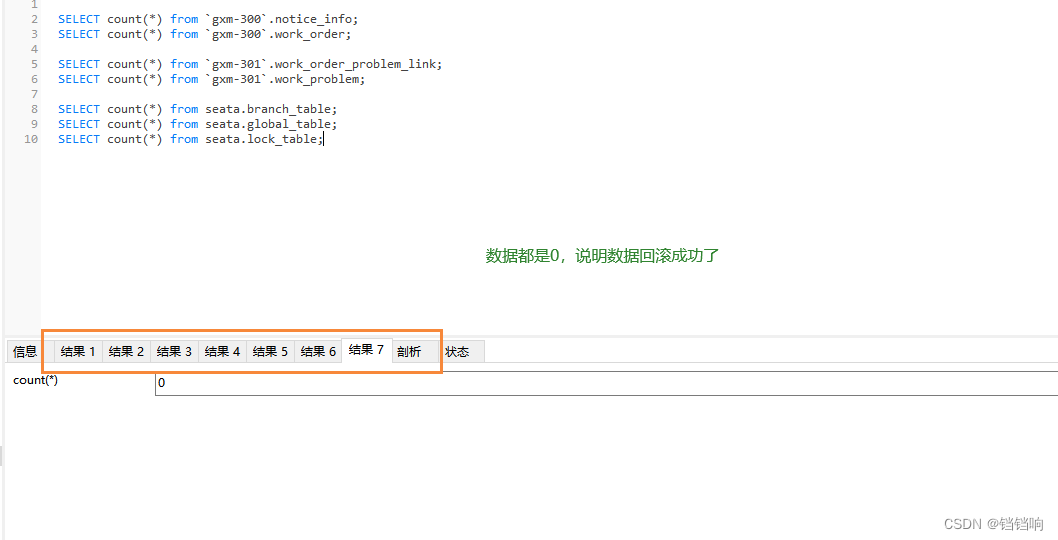
2.2、如何控制异常
1、这部分内容来自于 seata-TCC模式
2、在 TCC 模型执行的过程中,还可能会出现各种异常,其中最为常见的有空回滚、幂等、悬挂等。下面我讲下 Seata 是如何处理这三种异常的
2.2.1、如何处理空回滚
1、什么是空回滚?
空回滚指的是在一个分布式事务中,在没有调用参与方的 Try 方法的情况下,TM 驱动二阶段回滚调用了参与方的 Cancel 方法。
2、那么空回滚是如何产生的呢?
在全局事务开启后,参与者 A 分支注册完成之后会执行参与者一阶段 RPC 方法,如果此时参与者 A 所在的机器发生宕机,网络异常,都会造成 RPC 调用失败,即参与者 A 一阶段方法未成功执行,但是此时全局事务已经开启,Seata 必须要推进到终态,在全局事务回滚时会调用参与者 A 的 Cancel 方法,从而造成空回滚。
3、要想防止空回滚,那么必须在 Cancel 方法中识别这是一个空回滚,Seata 是如何做的呢?
Seata 的做法是新增一个 TCC 事务控制表,包含事务的 XID 和 BranchID 信息,在 Try 方法执行时插入一条记录,表示一阶段执行了,执行 Cancel 方法时读取这条记录,如果记录不存在,说明 Try 方法没有执行。
2.2.2、如何处理幂等
1、幂等问题指的是 TC 重复进行二阶段提交,因此 Confirm/Cancel 接口需要支持幂等处理,即不会产生资源重复提交或者重复释放。
2、那么幂等问题是如何产生的呢?
在参与者 A 执行完二阶段之后,由于网络抖动或者宕机问题,会造成 TC 收不到参与者 A 执行二阶段的返回结果,TC 会重复发起调用,直到二阶段执行结果成功。
3、Seata 是如何处理幂等问题的呢?
同样的也是在 TCC 事务控制表中增加一个记录状态的字段 status,该字段有 3 个值,分别为:
- tried:1
- committed:2
- rollbacked:3
二阶段 Confirm/Cancel 方法执行后,将状态改为 committed 或 rollbacked 状态。当重复调用二阶段 Confirm/Cancel 方法时,判断事务状态即可解决幂等问题。
2.2.3、如何处理悬挂
1、悬挂指的是二阶段 Cancel 方法比 一阶段 Try 方法优先执行,由于允许空回滚的原因,在执行完二阶段 Cancel 方法之后直接空回滚返回成功,此时全局事务已结束,但是由于 Try 方法随后执行,这就会造成一阶段 Try 方法预留的资源永远无法提交和释放了。
2、那么悬挂是如何产生的呢?
在执行参与者 A 的一阶段 Try 方法时,出现网路拥堵,由于 Seata 全局事务有超时限制,执行 Try 方法超时后,TM 决议全局回滚,回滚完成后如果此时 RPC 请求才到达参与者 A,执行 Try 方法进行资源预留,从而造成悬挂。
3、Seata 是怎么处理悬挂的呢?
在 TCC 事务控制表记录状态的字段 status 中增加一个状态:
- suspended:4
当执行二阶段 Cancel 方法时,如果发现 TCC 事务控制表有相关记录,说明二阶段 Cancel 方法优先一阶段 Try 方法执行,因此插入一条 status=4 状态的记录,当一阶段 Try 方法后面执行时,判断 status=4 ,则说明有二阶段 Cancel 已执行,并返回 false 以阻止一阶段 Try 方法执行成功。
4、代码中可以增加参数useTCCFence = true,开启seata的放悬挂
@TwoPhaseBusinessAction(name = "beanName", commitMethod = "commit", rollbackMethod = "rollback", useTCCFence = true)
三、SAGA 模式
1、这个saga模式坑的地方是真多啊,主要是官方的文档真是太乱了,但其实源码下的测试用例还是不错的,就是文档太少了,为了找一个可以用于生产的情况,我真是东凑西凑啊。
2、第一点,官方的saga模式的文档是一定要看的,SEATA Saga 模式,看了之后就可以大致了解下了,里面的状态语言的参数的含义大家都是要知道的,不然后面写不了。
3、然后官方代码示例,建议刚入手的小伙伴,一定要先都过一遍,心里有个底
- 源码下的测试用例,
io.seata.saga.engine.StateMachineTests,列举了几乎所有的状态机情况
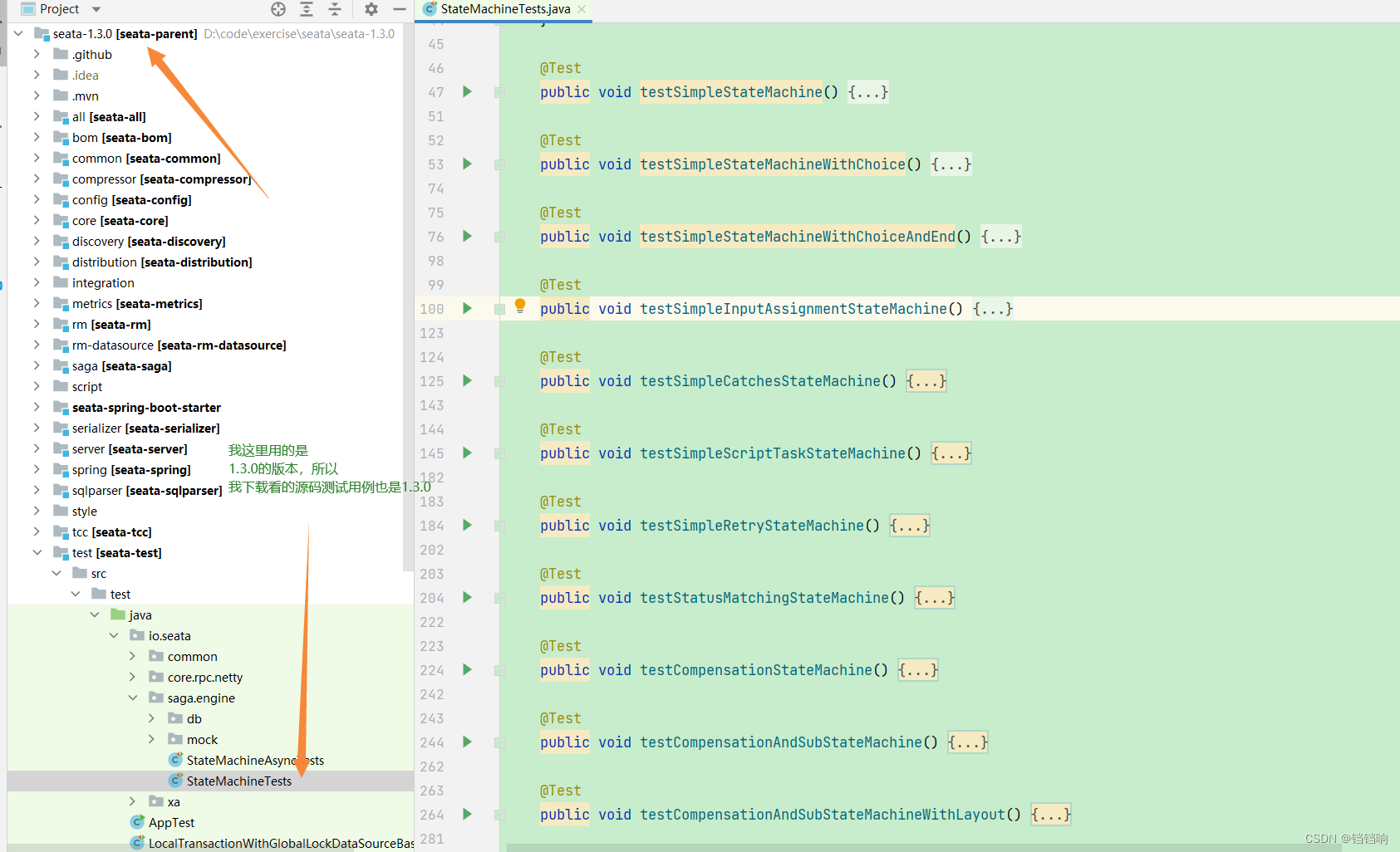
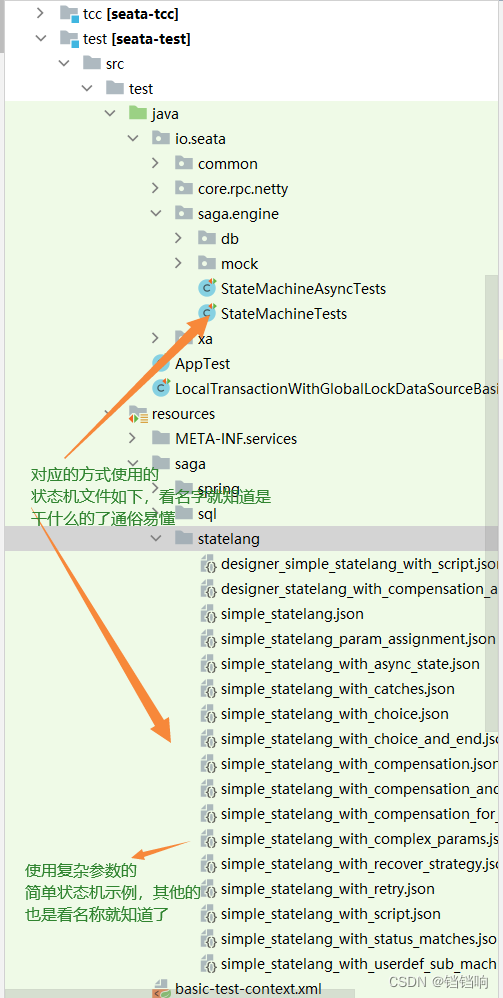
- 还有一个是官方的示例代码,项目地址是 seata-samples,找到你需要的项目情况的示例,当前的
saga模式如下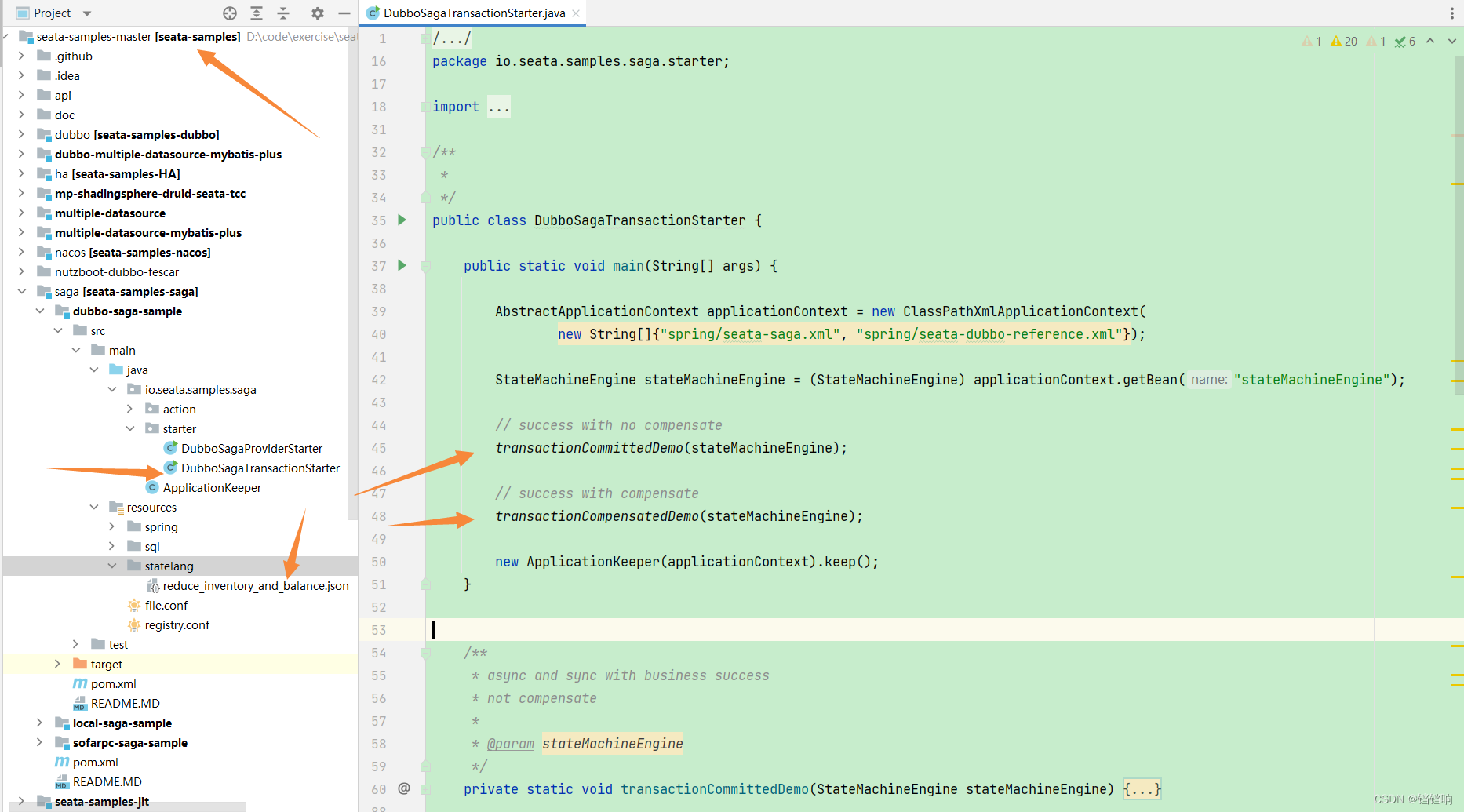
3.1、代码模拟
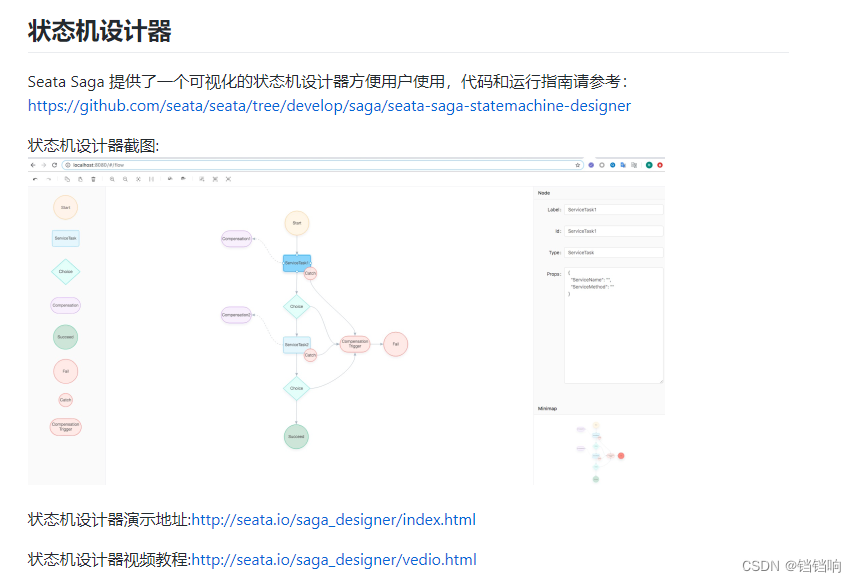
1、根据上面的官方文档和示例项目代码,我们知道,saga目前提供了基于状态机的方式,而状态机的语言官方也给出了一个可视化的界面 状态机设计器演示地址:http://seata.io/saga_designer/index.html
但是这个在线工具,似乎不支持一些老版本
这个没有上面的详细,应该是第一版本
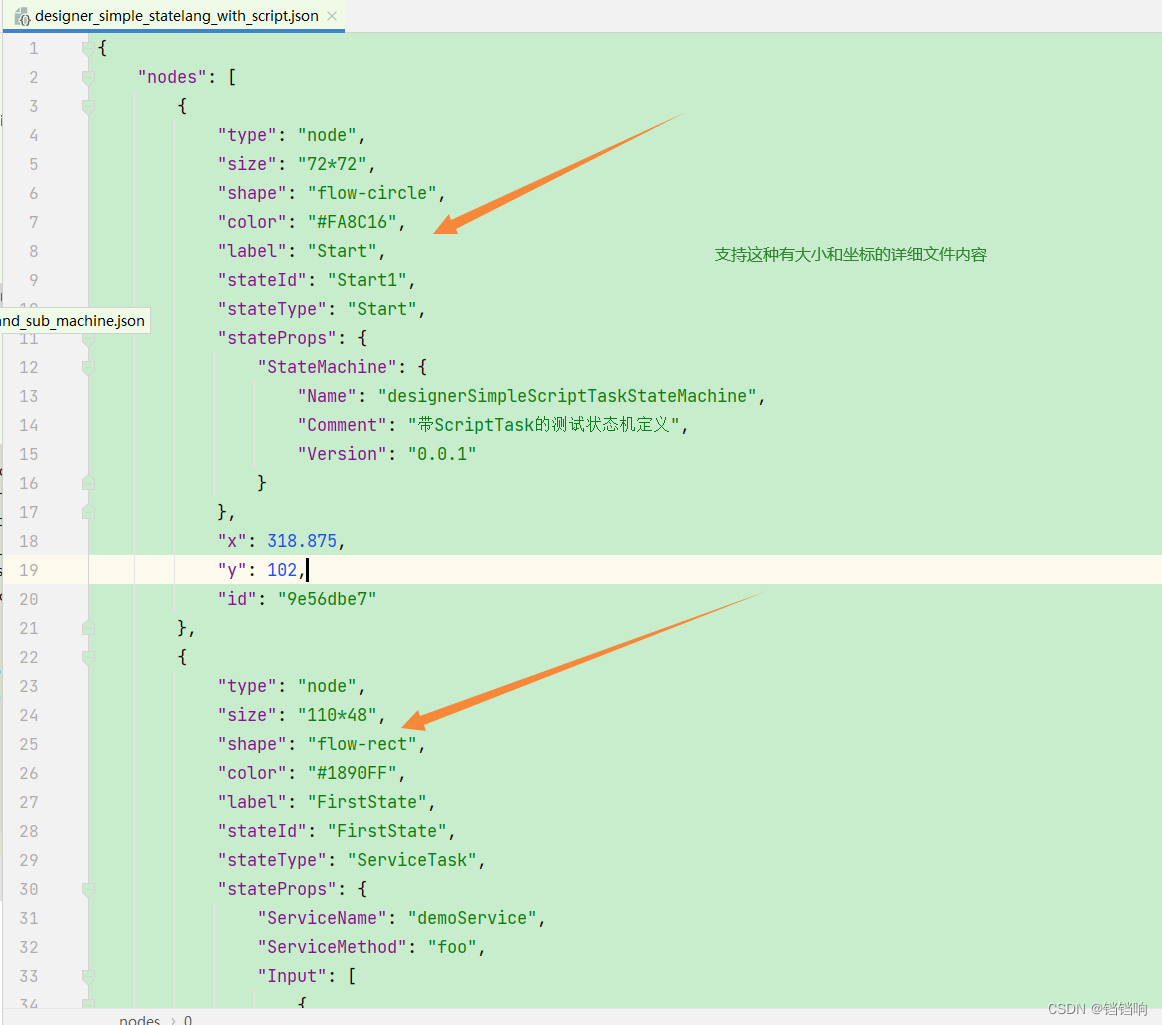
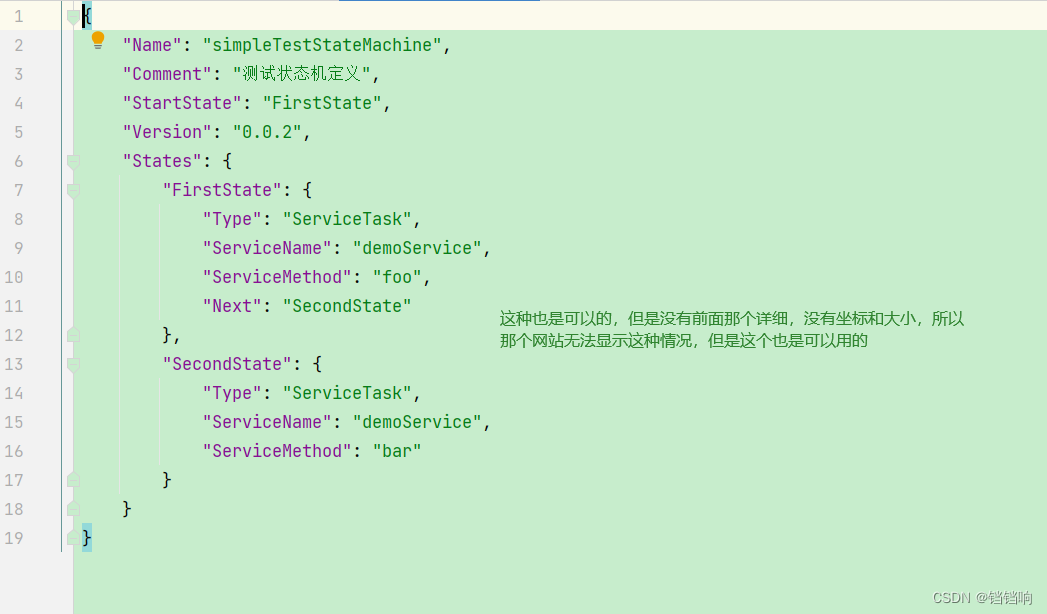
3.1.1 创建数据库
1、saga模式需要在服务发起方的数据库增加一些表,当然saga有提供基于内存数据库(H2)的模式,但是官方不建议你那么做。
2、具体如下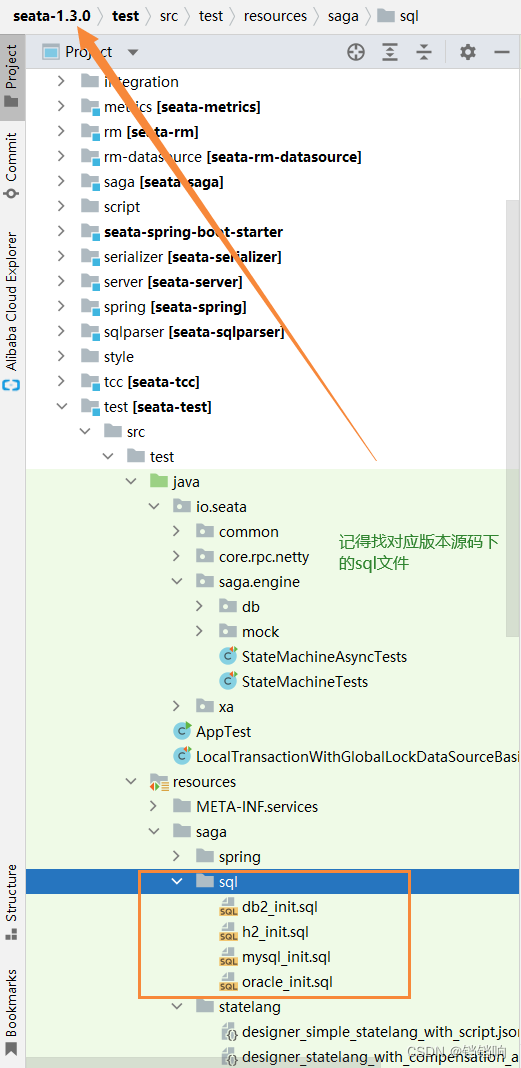
3、执行sql脚本,因为我后续的演示是从order服务发起,用的数据库是gxm-300,所以我这个sql脚本就执行在哪里,如下图新增了三张表。
3.1.2 业务代码
1、很前面一样,我们抽取一个专门处理复杂业务的service类出来,里面分别调用和device服务
order服务(使用gxm-300数据库的work_order表和notice_info表)device服务(使用gxm-301数据库的work_order_problem_link表和work_problem表)
3.1.2.1 order服务
1、WorkOrderService 接口类,一个是业务方法,另一个就是那个业务失败的补偿方法。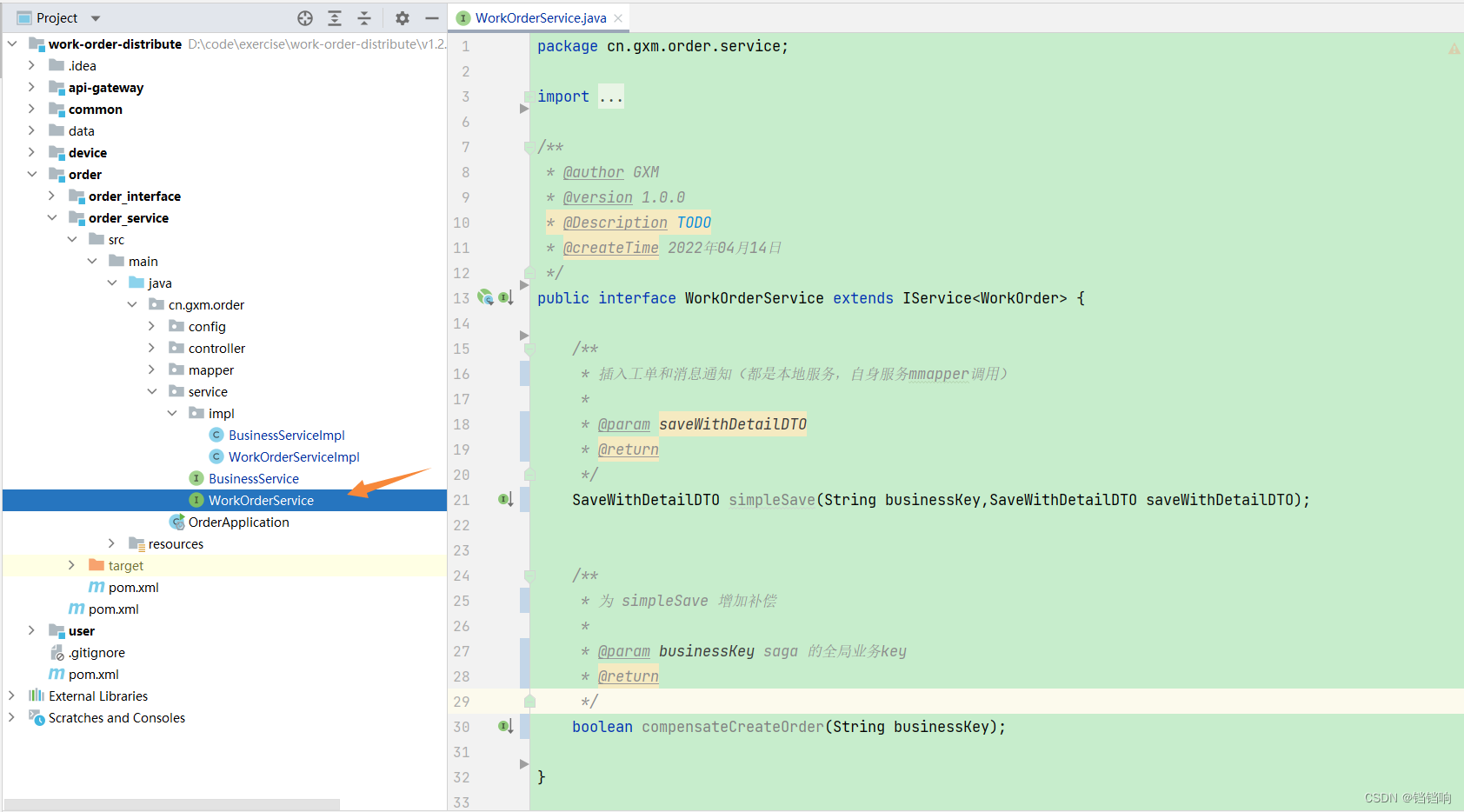
2、WorkOrderServiceImpl 实现类,一个是业务方法,另一个就是那个业务失败的补偿方法。
package cn.gxm.order.service.impl;
import cn.gxm.order.dto.method.service.savewithdetail.SaveWithDetailDTO;
import cn.gxm.order.mapper.NoticeInfoMapper;
import cn.gxm.order.mapper.WorkOrderMapper;
import cn.gxm.order.pojo.NoticeInfo;
import cn.gxm.order.pojo.WorkOrder;
import cn.gxm.order.service.WorkOrderService;
import cn.hutool.core.util.RandomUtil;
import cn.hutool.core.util.StrUtil;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
/** * @author GXM * @version 1.0.0 * @Description TODO * @createTime 2022年04月14日 */
@Slf4j
@Service
public class WorkOrderServiceImpl extends ServiceImpl<WorkOrderMapper, WorkOrder> implements WorkOrderService {
@Autowired
private ApplicationContext applicationContext;
@Autowired
private NoticeInfoMapper noticeInfoMapper;
/** * 测试seata * * @param saveWithDetailDTO saveWithDetailDTO * @return */
@Override
public SaveWithDetailDTO simpleSave(String businessKey, SaveWithDetailDTO saveWithDetailDTO) {
// 可以看到我们的 workProblemApi 在不在spring 里面
// System.out.println(applicationContext.getBeanDefinitionCount());
// for (String beanDefinitionName : applicationContext.getBeanDefinitionNames()) {
// System.out.println(beanDefinitionName);
// }
String title = RandomUtil.randomString(20);
saveWithDetailDTO.setWorkOrderTitle(title);
saveWithDetailDTO.setWorkOrderNumber("asd");
// 1、调用自身服务
// 1.1、插入工单信息
WorkOrder workOrder = new WorkOrder();
BeanUtils.copyProperties(saveWithDetailDTO, workOrder);
workOrder.setBusinessKey(businessKey);
this.baseMapper.insert(workOrder);
saveWithDetailDTO.setId(workOrder.getId());
// 1.2、插入消息通知表
NoticeInfo noticeInfo = new NoticeInfo();
noticeInfo.setTitle("new work order 【" + title + "】has publish");
noticeInfo.setBusinessKey(businessKey);
noticeInfoMapper.insert(noticeInfo);
saveWithDetailDTO.setNoticeInfoId(noticeInfo.getId());
return saveWithDetailDTO;
}
@Override
public boolean compensateCreateOrder(String businessKey) {
log.info("compensateCreateOrder business key : {}", businessKey);
if (StrUtil.isNotBlank(businessKey)) {
// 1、根据 business key 来进行操作 补偿 因为我这里的业务是插入,所以,我直接根据business key 删除相关数据即可
// 1.1、删除 work_order 表数据
LambdaQueryWrapper<WorkOrder> workOrderQueryWrapper = new LambdaQueryWrapper<>();
workOrderQueryWrapper.eq(WorkOrder::getBusinessKey, businessKey);
this.baseMapper.delete(workOrderQueryWrapper);
// 1.2、删除 notice_info 表数据
LambdaQueryWrapper<NoticeInfo> noticeInfoQueryWrapper = new LambdaQueryWrapper<>();
noticeInfoQueryWrapper.eq(NoticeInfo::getBusinessKey, businessKey);
noticeInfoMapper.delete(noticeInfoQueryWrapper);
}
return true;
}
}
3.1.2.1 device服务
1、WorkProblemApi 接口类,一个是业务方法,另一个就是那个业务失败的补偿方法。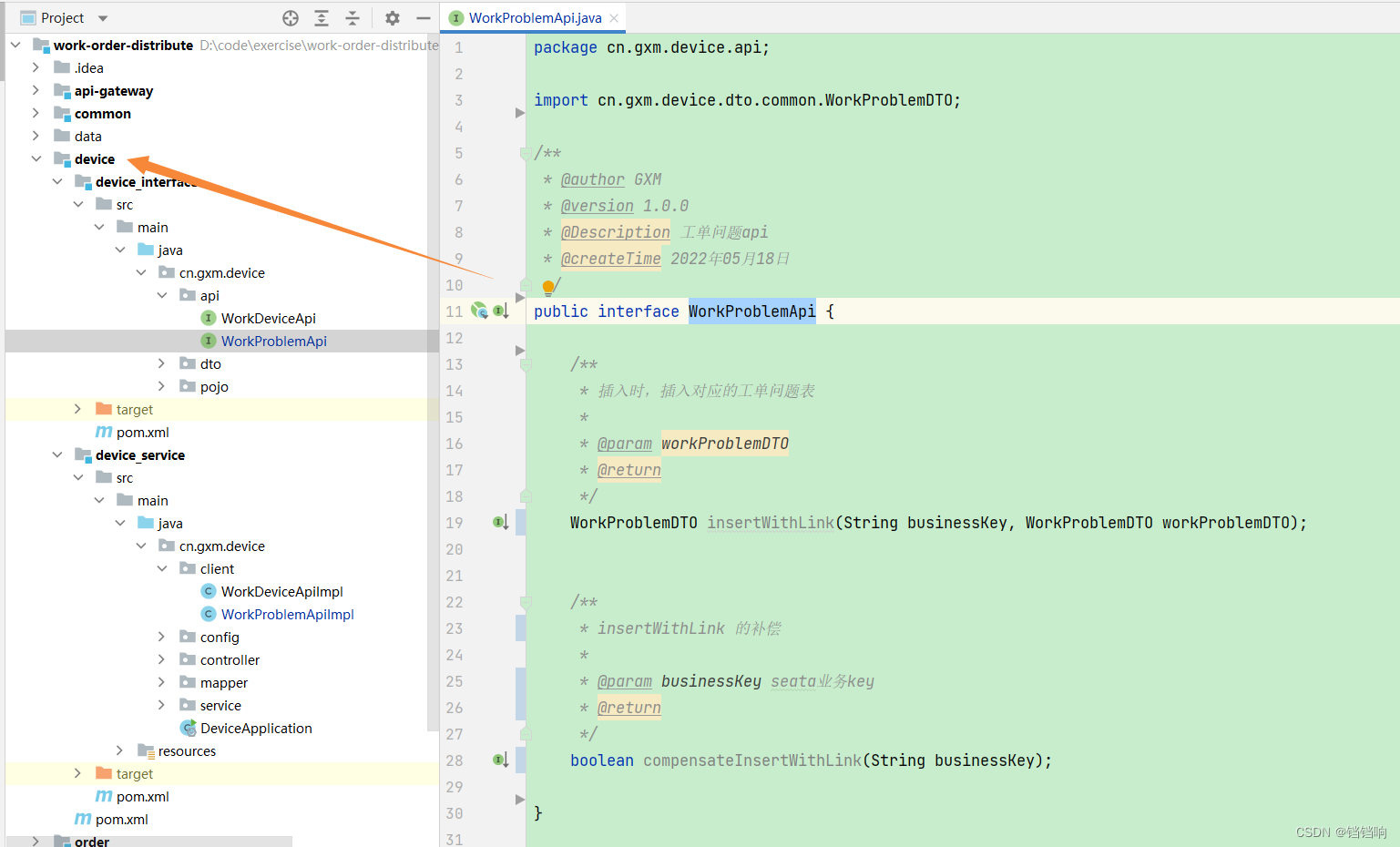
2、WorkProblemApiImpl实现类,一个是业务方法,另一个就是那个业务失败的补偿方法。
package cn.gxm.device.client;
import cn.gxm.device.api.WorkProblemApi;
import cn.gxm.device.dto.common.WorkProblemDTO;
import cn.gxm.device.mapper.WorkOrderProblemLinkMapper;
import cn.gxm.device.mapper.WorkProblemMapper;
import cn.gxm.device.pojo.WorkOrderProblemLink;
import cn.gxm.device.pojo.WorkProblem;
import cn.hutool.core.util.StrUtil;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import lombok.extern.slf4j.Slf4j;
import org.apache.dubbo.config.annotation.DubboService;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
/** * @author GXM * @version 1.0.0 * @Description TODO * @createTime 2022年05月19日 */
@Slf4j
@DubboService
public class WorkProblemApiImpl implements WorkProblemApi {
@Autowired
private WorkProblemMapper workProblemMapper;
@Autowired
private WorkOrderProblemLinkMapper workOrderProblemLinkMapper;
@Override
public WorkProblemDTO insertWithLink(String businessKey, WorkProblemDTO workProblemDTO) {
WorkProblem workProblem = new WorkProblem();
BeanUtils.copyProperties(workProblemDTO, workProblem);
workProblem.setBusinessKey(businessKey);
// 1、插入问题表
workProblemMapper.insert(workProblem);
workProblemDTO.setId(workProblem.getId());
// 2、插入工单问题关联表
WorkOrderProblemLink workOrderProblemLink = new WorkOrderProblemLink();
workOrderProblemLink.setOrderId(workProblemDTO.getOrderId());
workOrderProblemLink.setProblemId(workProblem.getId());
workOrderProblemLink.setBusinessKey(businessKey);
workOrderProblemLinkMapper.insert(workOrderProblemLink);
workProblemDTO.setOrderProblemLinkId(workOrderProblemLink.getId());
if (workProblemDTO.getProblem().equals("exception")) {
int i = 1 / 0;
}
return workProblemDTO;
}
/** * 业务补偿 * * @param businessKey seata业务key * @return */
@Override
public boolean compensateInsertWithLink(String businessKey) {
log.info("compensateInsertWithLink business key : {}", businessKey);
if (StrUtil.isNotBlank(businessKey)) {
// 1、根据 business key 来进行操作 补偿 因为我这里的业务是插入,所以,我直接根据business key 删除相关数据即可
// 1.1、删除 work_problem 表数据
LambdaQueryWrapper<WorkProblem> workProblemQueryWrapper = new LambdaQueryWrapper<>();
workProblemQueryWrapper.eq(WorkProblem::getBusinessKey, businessKey);
workProblemMapper.delete(workProblemQueryWrapper);
// 1.2、删除 notice_info 表数据
LambdaQueryWrapper<WorkOrderProblemLink> workOrderProblemLinkQueryWrapper = new LambdaQueryWrapper<>();
workOrderProblemLinkQueryWrapper.eq(WorkOrderProblemLink::getBusinessKey, businessKey);
workOrderProblemLinkMapper.delete(workOrderProblemLinkQueryWrapper);
}
return true;
}
}
3.1.2.3 综合复杂业务类
1、我这边把这个类型直接写到了order服务下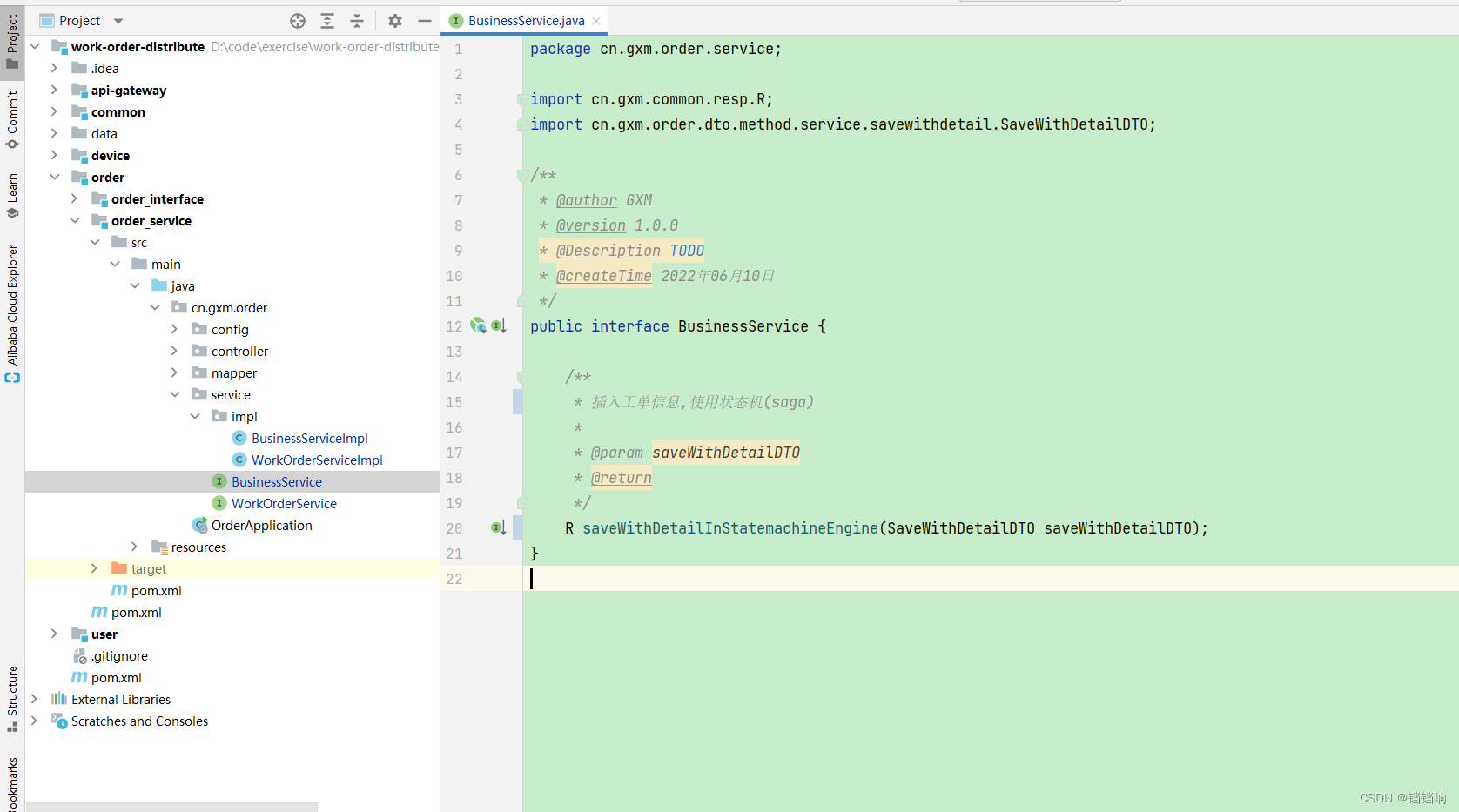
2、实现类
package cn.gxm.order.service.impl;
import cn.gxm.common.resp.R;
import cn.gxm.order.dto.method.service.savewithdetail.SaveWithDetailDTO;
import cn.gxm.order.service.BusinessService;
import io.seata.core.context.RootContext;
import io.seata.saga.engine.StateMachineEngine;
import io.seata.saga.statelang.domain.StateMachineInstance;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.Map;
/** * @author GXM * @version 1.0.0 * @Description TODO * @createTime 2022年06月10日 */
@Service
@Slf4j
public class BusinessServiceImpl implements BusinessService {
@Autowired
private StateMachineEngine stateMachineEngine;
/** * 业务逻辑为 * // 1、order 服务 * workOrderService.simpleSave(saveWithDetailDTO); * // 2、远程调用 device 服务 * // 2.1、插入问题表 和问题关联表 * WorkProblemDTO workProblemDTO = new WorkProblemDTO(); * BeanUtils.copyProperties(saveWithDetailDTO.getSoftwareNotSolveProblemList().get(0), workProblemDTO); * workProblemDTO.setOrderId(saveWithDetailDTO.getId()); * workProblemApi.insertWithLink(workProblemDTO); * * @param saveWithDetailDTO * @return */
@Override
public R saveWithDetailInStatemachineEngine(SaveWithDetailDTO saveWithDetailDTO) {
log.info("create order begin ... xid: " + RootContext.getXID());
String businessKey = String.valueOf(System.currentTimeMillis());
// 1、下面这个状态机描述的就是上面的过程
Map<String, Object> paramMap = new HashMap<>(1);
// 1.1、这个 `saveWithDetailDTOKey`,可以在状态机json文件中通过 $.[saveWithDetailDTOKey] 获取,而且加上`.`可以表示具体的数据
paramMap.put("saveWithDetailDTOKey", saveWithDetailDTO);
paramMap.put("businessKey", businessKey);
String stateMachineName = "createOrderAndProblemStateMachine";
// 1.2、执行状态机json文件,具体业务流程都在json文件中。
// StateMachineInstance instance = stateMachineEngine.start(stateMachineName, null, paramMap);
StateMachineInstance instance = stateMachineEngine.startWithBusinessKey(stateMachineName, null, businessKey, paramMap);
log.info("最总执行结果: {}; xid : {}; businessKey: {}; compensationStatus {}",
instance.getStatus(), instance.getId(), instance.getBusinessKey(), instance.getCompensationStatus());
return R.ok();
}
}
3.1.3 项目配置saga 模式
1、首先我们需要写一个我们的业务的状态语言文件,来表示你的业务情况,以及回滚补偿的情况,你可以使用前面提到过的那个官方提供的在线工具
一些语法我就不再细说了,官方文档拉到底部,就是说这些语义的,不明白可以去看下
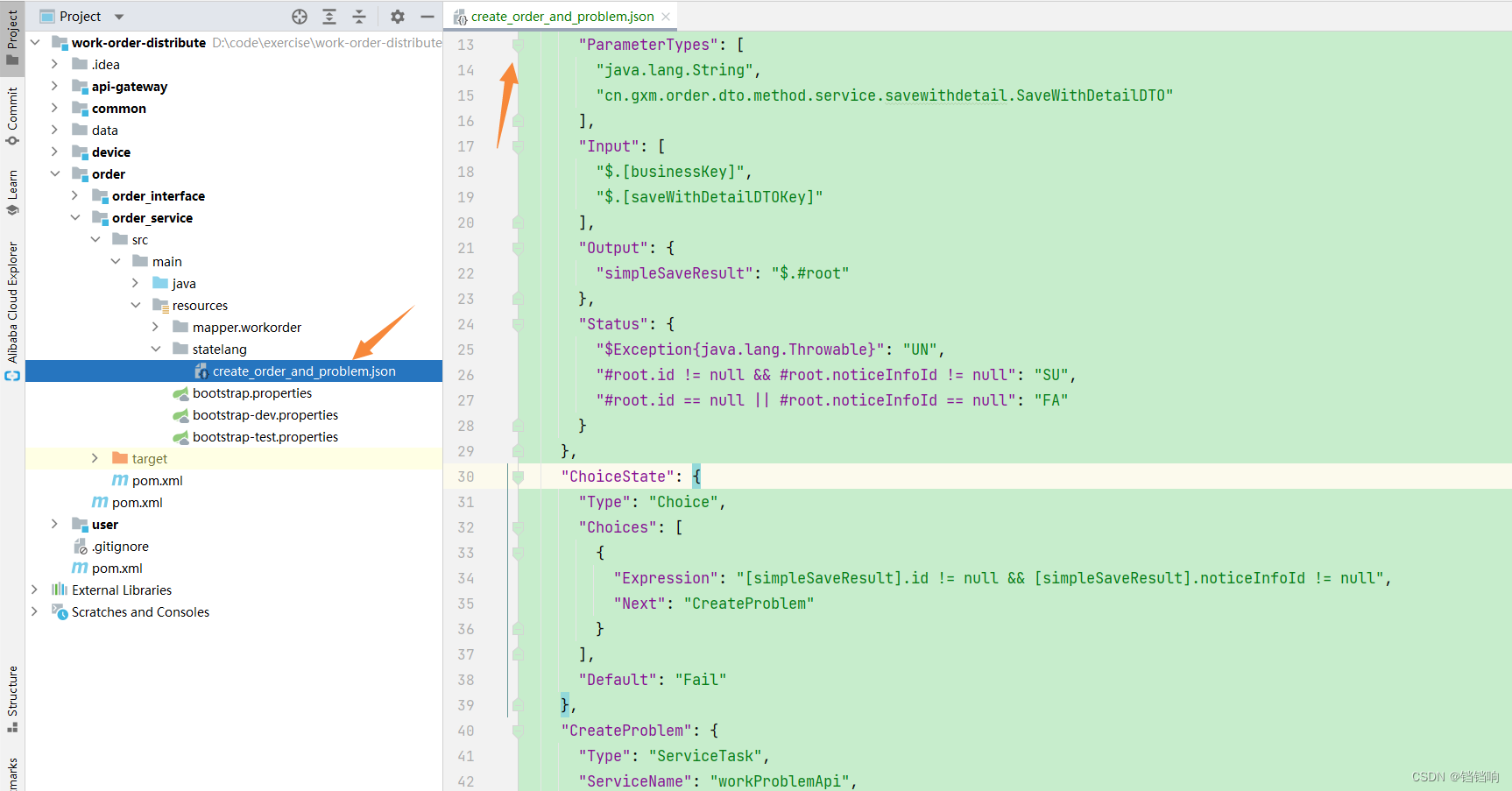
{
"Name": "createOrderAndProblemStateMachine", # 状态机的名称,后续使用的时候要根据这个唯一来找
"Comment": "创建工单状态机", # 简介
"StartState": "CreateOrder", # 初始状态
"Version": "0.0.1", # 当前版本
"States": {
# 状态列表
"CreateOrder": {
# 名为CreateOrder的状态列表
"Type": "ServiceTask", # 类型
"ServiceName": "workOrderServiceImpl", # 对应的服务bean名称,saga会到spring的bean容器中找这个名称的bean。
"ServiceMethod": "simpleSave", # workOrderServiceImpl的名为simpleSave的方法
"Next": "ChoiceState", # 下一个状态
"CompensateState": "CompensateCreateOrder", # 当前服务的补偿状态的名称(下面有定义)
"ParameterTypes": [ # workOrderServiceImpl#simpleSave 的方法参数类型(可以不写,但是如果有泛型,就要写,官方有说明)
"java.lang.String",
"cn.gxm.order.dto.method.service.savewithdetail.SaveWithDetailDTO"
],
"Input": [ # workOrderServiceImpl#simpleSave 的方法的参数值
"$.[businessKey]",
"$.[saveWithDetailDTOKey]"
],
"Output": {
# workOrderServiceImpl#simpleSave 的方法的返回值,存储在状态机上下文中,key是 simpleSaveResult,值是该方法的整个返回结果
"simpleSaveResult": "$.#root"
},
"Status": {
# 当前CreateOrder的的状态 服务执行状态映射,框架定义了三个状态,SU 成功、FA 失败、UN 未知, 我们需要把服务执行的状态映射成这三个状态,帮助框架判断整个事务的一致性,是一个map结构,key是条件表达式,一般是取服务的返回值或抛出的异常进行判断,默认是SpringEL表达式判断服务返回参数,带$Exception{
开头表示判断异常类型。value是当这个条件表达式成立时则将服务执行状态映射成这个值
# 这里要说的一点就是这个异常的判断得放到前面,不然如果你把根据返回值的判断放到前面,一旦发生异常,那么方法是没有返回值的,那这个#root.id就是错误的语法,因为#root是null,当然最总的状态还是"UN"
"$Exception{java.lang.Throwable}": "UN",
"#root.id != null && #root.noticeInfoId != null": "SU",
"#root.id == null || #root.noticeInfoId == null": "FA"
}
},
"ChoiceState": {
"Type": "Choice",
"Choices": [
{
# 只有CreateOrder阶段创建成功了(work_order有id了,并且notice_info也有id,说明插入成功了),才走下一步
"Expression": "[simpleSaveResult].id != null && [simpleSaveResult].noticeInfoId != null",
"Next": "CreateProblem"
}
],
"Default": "Fail" # 否则默认失败(失败状态下面有定义)
},
"CreateProblem": {
"Type": "ServiceTask",
"ServiceName": "workProblemApi",
"ServiceMethod": "insertWithLink",
"CompensateState": "CompensateCreateProblem",
"Input": [
"$.[businessKey]",
{
"problem": "$.[saveWithDetailDTOKey].softwareNotSolveProblemList[0].problem",
"type": "$.[saveWithDetailDTOKey].softwareNotSolveProblemList[0].type",
"orderId": "$.[simpleSaveResult].id"
}
],
"Output": {
"insertWithLinkResult": "$.#root"
},
"Status": {
"$Exception{java.lang.Throwable}": "UN",
"#root.id != null && #root.orderProblemLinkId != null": "SU",
"#root.id == null || #root.orderProblemLinkId == null": "FA"
},
"Catch": [
{
"Exceptions": [
"java.lang.Throwable"
],
"Next": "CompensationTrigger"
}
],
"Next": "Succeed"
},
"CompensateCreateOrder": {
# CreateOrder的补偿措施
"Type": "ServiceTask",
"ServiceName": "workOrderServiceImpl", # 需要 workOrderServiceImpl 的bean
"ServiceMethod": "compensateCreateOrder", # 调用 workOrderServiceImpl#compensateCreateOrder方法里面
"Input": [
"$.[businessKey]"
]
},
"CompensateCreateProblem": {
"Type": "ServiceTask",
"ServiceName": "workProblemApi",
"ServiceMethod": "compensateInsertWithLink",
"Input": [
"$.[businessKey]"
]
},
"CompensationTrigger": {
"Type": "CompensationTrigger",
"Next": "Fail"
},
"Succeed": {
"Type": "Succeed"
},
"Fail": {
"Type": "Fail",
"ErrorCode": "CREATE_FAILED",
"Message": "create order failed"
}
}
}
2、配置saga的状态机的配置信息,比如你的状态机json文件叫什么,在哪里,并注入到spring的容器中,官方的示例,大家看下都能看出来是xml,我这里就改为springboot的配置方式注入就行,大家可以随意选择一个方式
3、我这里改为springboot的@Configuration注入方式,里面内容就是对应上面的xml文件内容,
其中有一个地方需要注意,状态机在执行的时候,会去spring的bean中对应的bean,我们使用dubbo的方式注入的时候,并不会在spring的容器内部,所以会出现找不到对应的bean,但其实我们使用@DubboReference是可以获取的,所以,这里我们手动注入一下。
package cn.gxm.order.config;
import cn.gxm.device.api.WorkProblemApi;
import cn.gxm.order.service.impl.WorkOrderServiceImpl;
import com.zaxxer.hikari.HikariDataSource;
import io.seata.saga.engine.StateMachineEngine;
import io.seata.saga.engine.config.DbStateMachineConfig;
import io.seata.saga.engine.impl.ProcessCtrlStateMachineEngine;
import io.seata.saga.rm.StateMachineEngineHolder;
import org.apache.dubbo.config.annotation.DubboReference;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;
import javax.sql.DataSource;
import java.io.File;
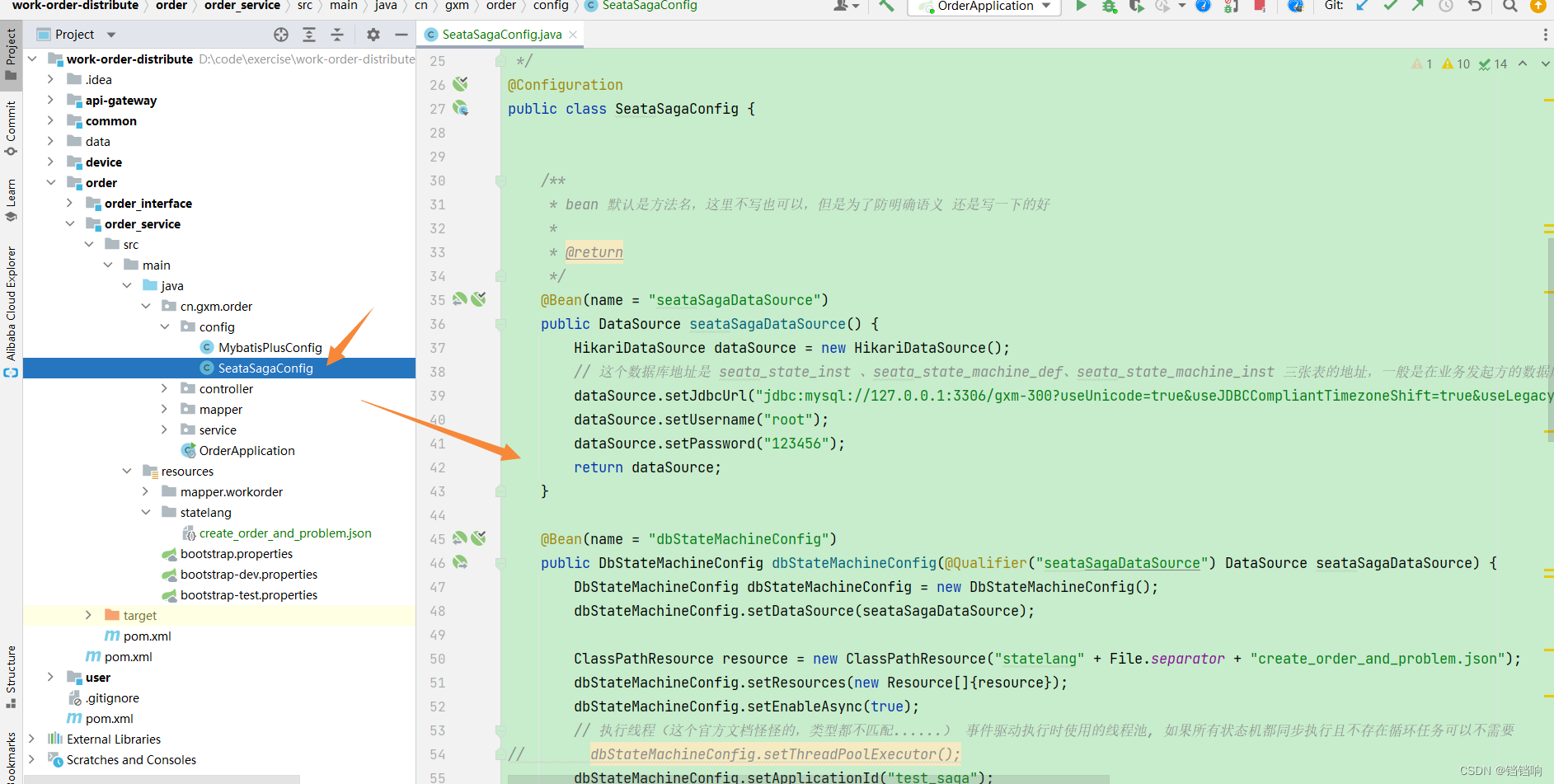
/** * @author GXM * @version 1.0.0 * @Description seata saga模式配置信息 * @createTime 2022年06月13日 */
@Configuration
public class SeataSagaConfig {
/** * bean 默认是方法名,这里不写也可以,但是为了防明确语义 还是写一下的好 * * @return */
@Bean(name = "seataSagaDataSource")
public DataSource seataSagaDataSource() {
HikariDataSource dataSource = new HikariDataSource();
// 这个数据库地址是 seata_state_inst 、seata_state_machine_def、seata_state_machine_inst 三张表的地址,一般是在业务发起方的数据库中
dataSource.setJdbcUrl("jdbc:mysql://127.0.0.1:3306/gxm-300?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai&useSSL=true&characterEncoding=UTF-8");
dataSource.setUsername("root");
dataSource.setPassword("123456");
return dataSource;
}
@Bean(name = "dbStateMachineConfig")
public DbStateMachineConfig dbStateMachineConfig(@Qualifier("seataSagaDataSource") DataSource seataSagaDataSource) {
DbStateMachineConfig dbStateMachineConfig = new DbStateMachineConfig();
dbStateMachineConfig.setDataSource(seataSagaDataSource);
ClassPathResource resource = new ClassPathResource("statelang" + File.separator + "create_order_and_problem.json");
dbStateMachineConfig.setResources(new Resource[]{
resource});
dbStateMachineConfig.setEnableAsync(true);
// 执行线程(这个官方文档怪怪的,类型都不匹配......) 事件驱动执行时使用的线程池, 如果所有状态机都同步执行且不存在循环任务可以不需要
// dbStateMachineConfig.setThreadPoolExecutor();
dbStateMachineConfig.setApplicationId("test_saga");
dbStateMachineConfig.setTxServiceGroup("my_test_tx_group");
return dbStateMachineConfig;
}
/** * saga 状态机 实例 */
@Bean(name = "stateMachineEngine")
public StateMachineEngine stateMachineEngine(@Qualifier("dbStateMachineConfig") DbStateMachineConfig dbStateMachineConfig) {
ProcessCtrlStateMachineEngine processCtrlStateMachineEngine = new ProcessCtrlStateMachineEngine();
processCtrlStateMachineEngine.setStateMachineConfig(dbStateMachineConfig);
return processCtrlStateMachineEngine;
}
/** * Seata Server进行事务恢复时需要通过这个Holder拿到stateMachineEngine实例 * * @param stateMachineEngine * @return */
@Bean
public StateMachineEngineHolder stateMachineEngineHolder(@Qualifier("stateMachineEngine") StateMachineEngine stateMachineEngine) {
StateMachineEngineHolder stateMachineEngineHolder = new StateMachineEngineHolder();
stateMachineEngineHolder.setStateMachineEngine(stateMachineEngine);
return stateMachineEngineHolder;
}
@DubboReference
private WorkProblemApi workProblemApi;
/** * 因为2.x版本的 dubbo 使用 注解 @DubboReference 时,不会注入到spring 中(@DubboReference 并不是 Spring定义的 Bean,所以不会生成 BeanDefinition ,也就是不会主动 createBean ,只能在属性注入的时候触发), * 而saga的状态机在读取的 * 时候要从spring 中获取其他服务的bean,所以这里手动注入一下 * 具体分析可以看 https://heapdump.cn/article/3610812 * @return */
@Bean(name = "workProblemApi")
public WorkProblemApi workProblemApi() {
return workProblemApi;
}
}
3.1.4、说明(重要)
1、其中有一个问题,需要说明一下,就是参数businessKey,我们每次开始一个一个业务都获取当前时时间戳作为businessKey,传入到业务逻辑中去,这是为了,后续补偿的时候,知道怎么补偿,比如说,我们当前这个业务,如果失败,我们肯定要找到对应4张表的4条数据,然后去删除,我们只要把生成的主键id,放到状态机的全局对象中进行流转,即可,但是有一种情况就是,一旦某一个状态发生了异常,那么在状态机中是没有返回数据的,那么就无法将id传入下一步,那后面补偿业务怎么办呢。所以,这里有两种方式
2、第一种,本文做的这种,把业务key传入,而且对应的四张表,都需要一个businessKey字段,对应业务修改的时候,把businessKey填充上去,那么进行补偿的时候,直接根据业务key来操作即可。
3、第二种,还是传入业务key,但是不在对应表中怎加业务key字段,而是保存到redis这种第三方中,比如当前业务,在插入数据库的时候,存入一个 hmap,key就是业务key,filed就是对应的表名,值就是生成的id,那么补偿的时候,根据业务key从redis中取即可。
3.2、情况测试
3.2.1、正常情况
3.2.1.1、状态机对象分析
1、我们先测试没有异常情况的案例,在业务service中,打上断点,查看执行的数据结果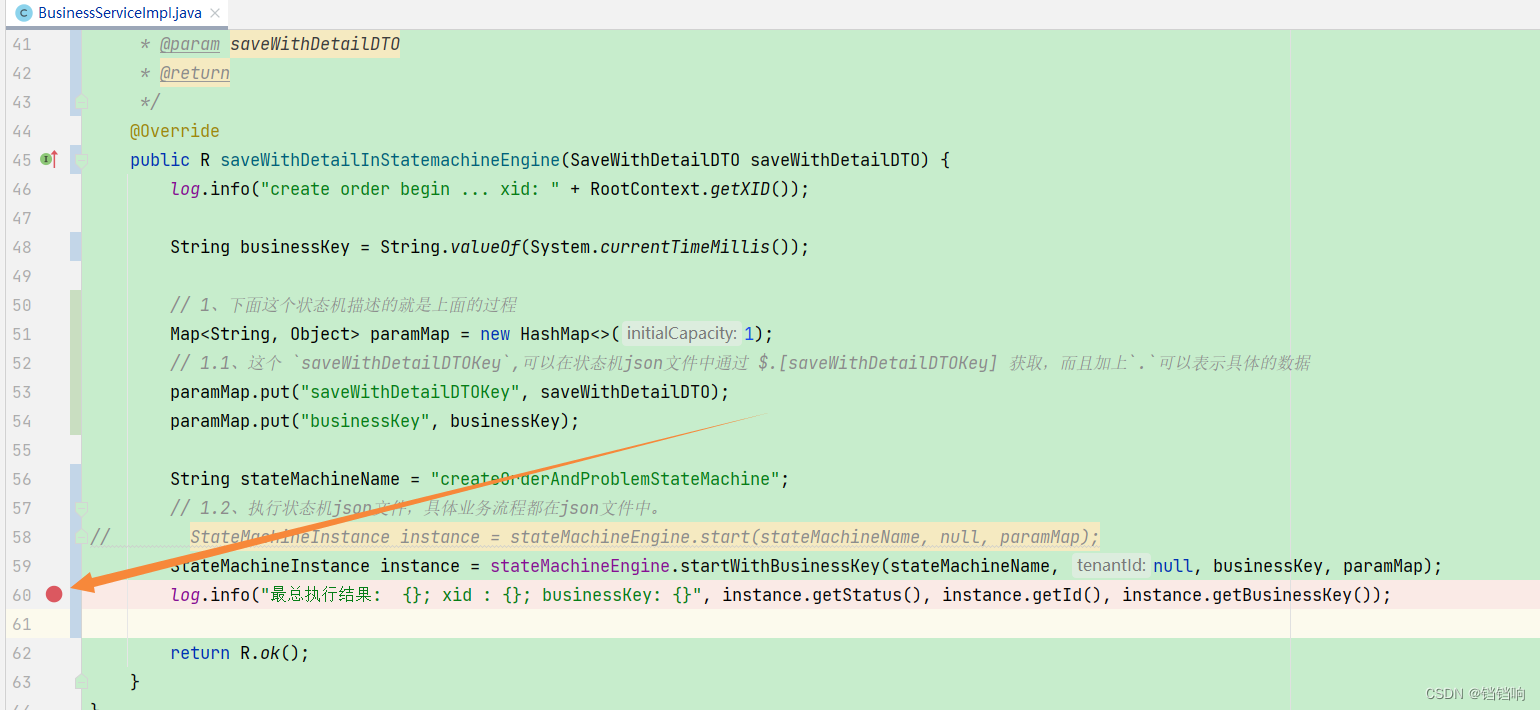
2、初步结果如下: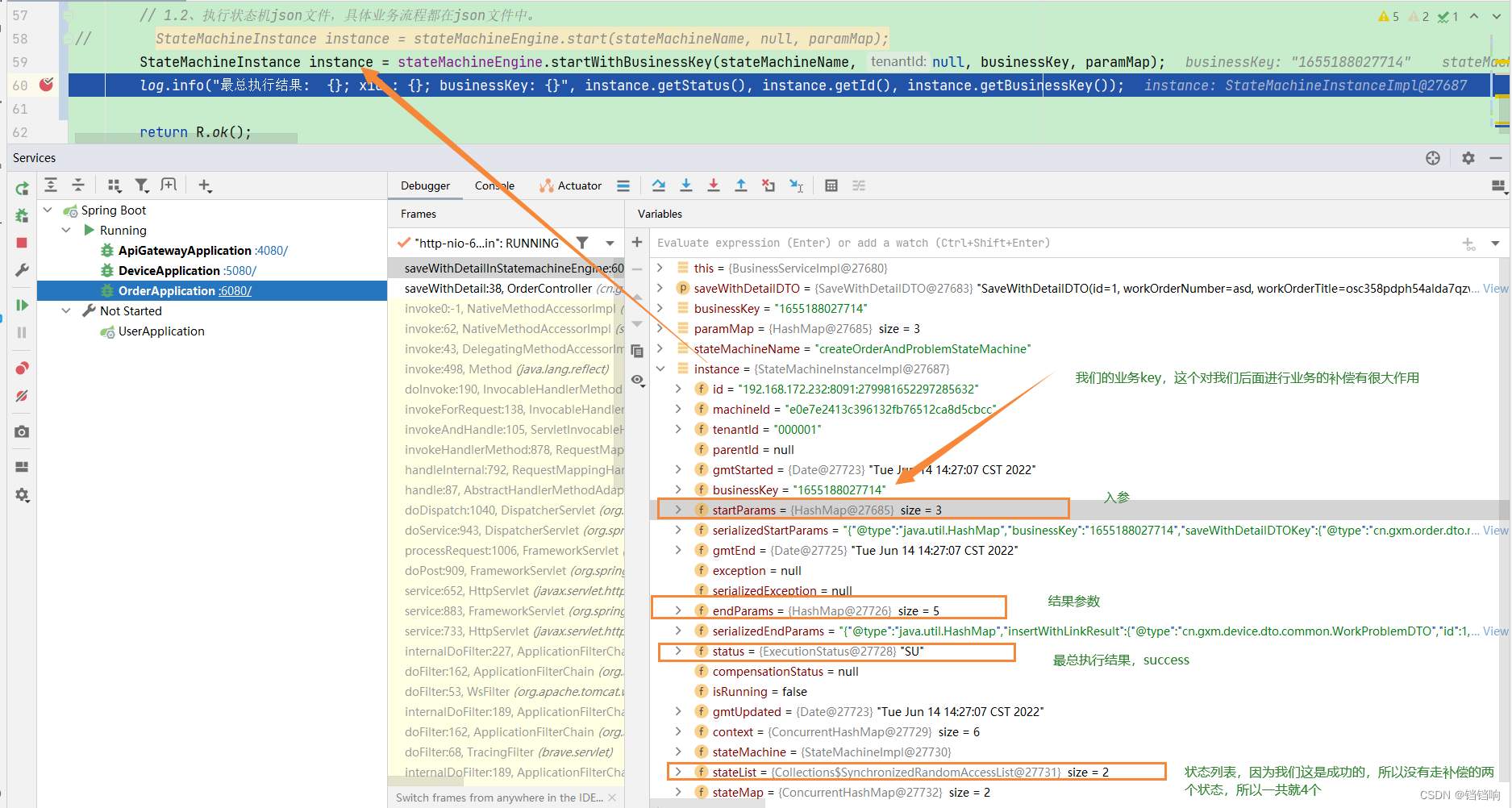
3、传入参数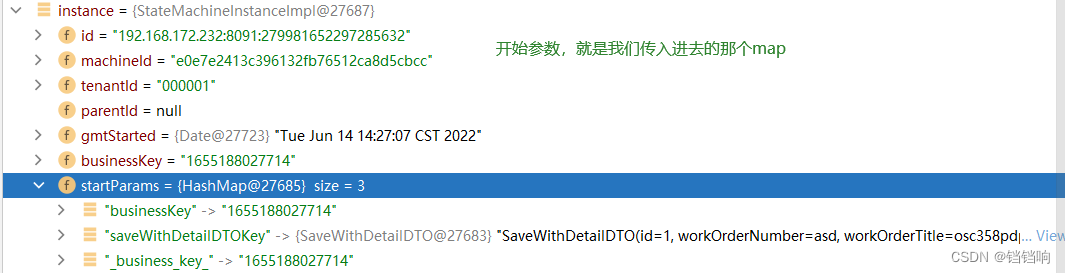
4、结果参数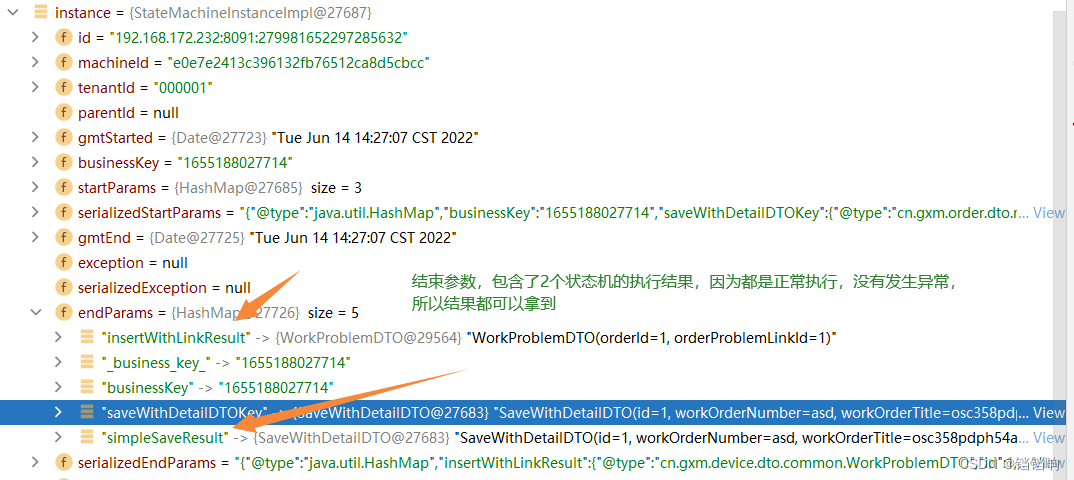
5、最总执行结果
6、状态机对象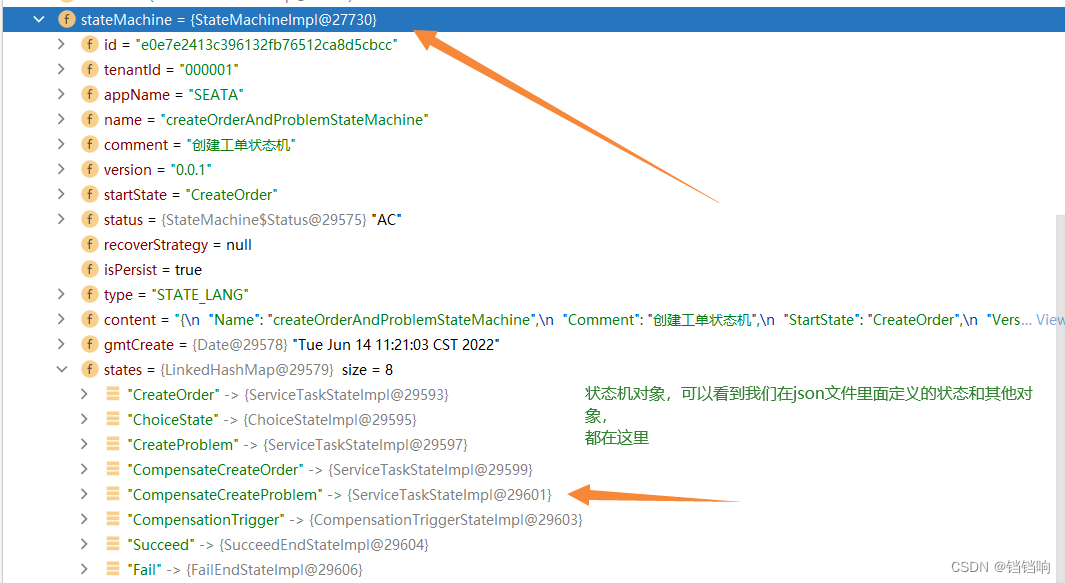
7、 第一个状态机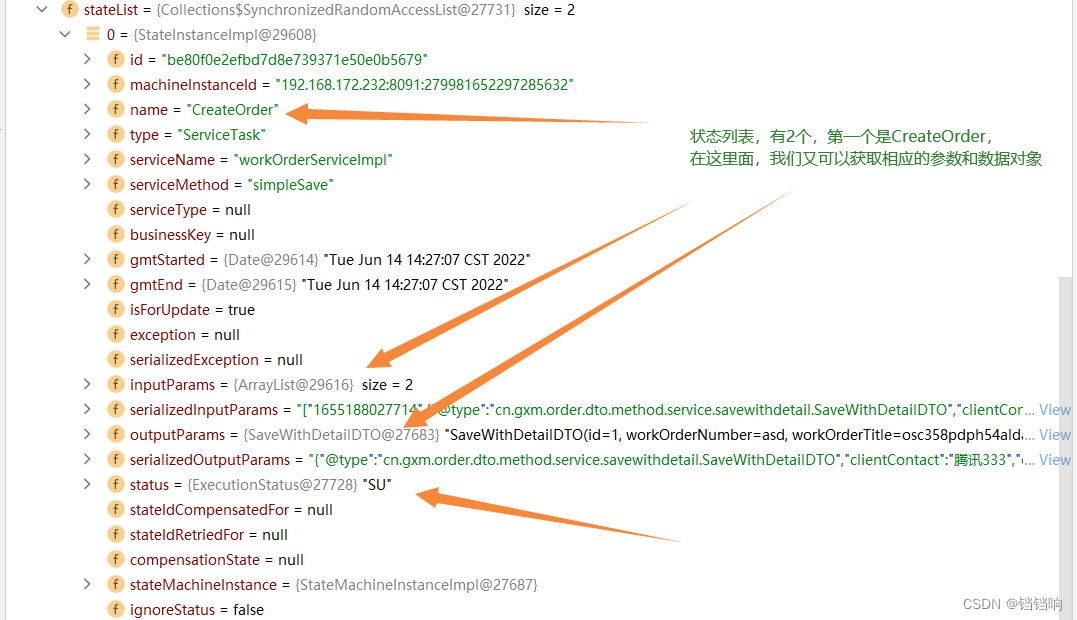
8、 第二个状态机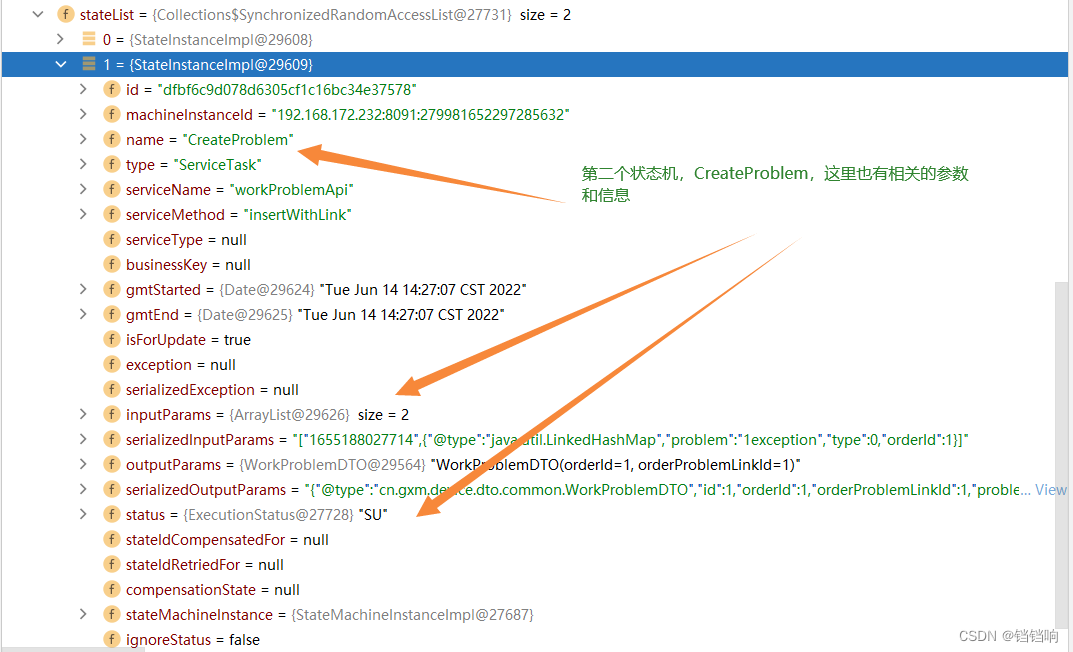
3.2.1.2、控制台日志
1、先执行CreateOrder的状态机,也就是插入order服务的两张表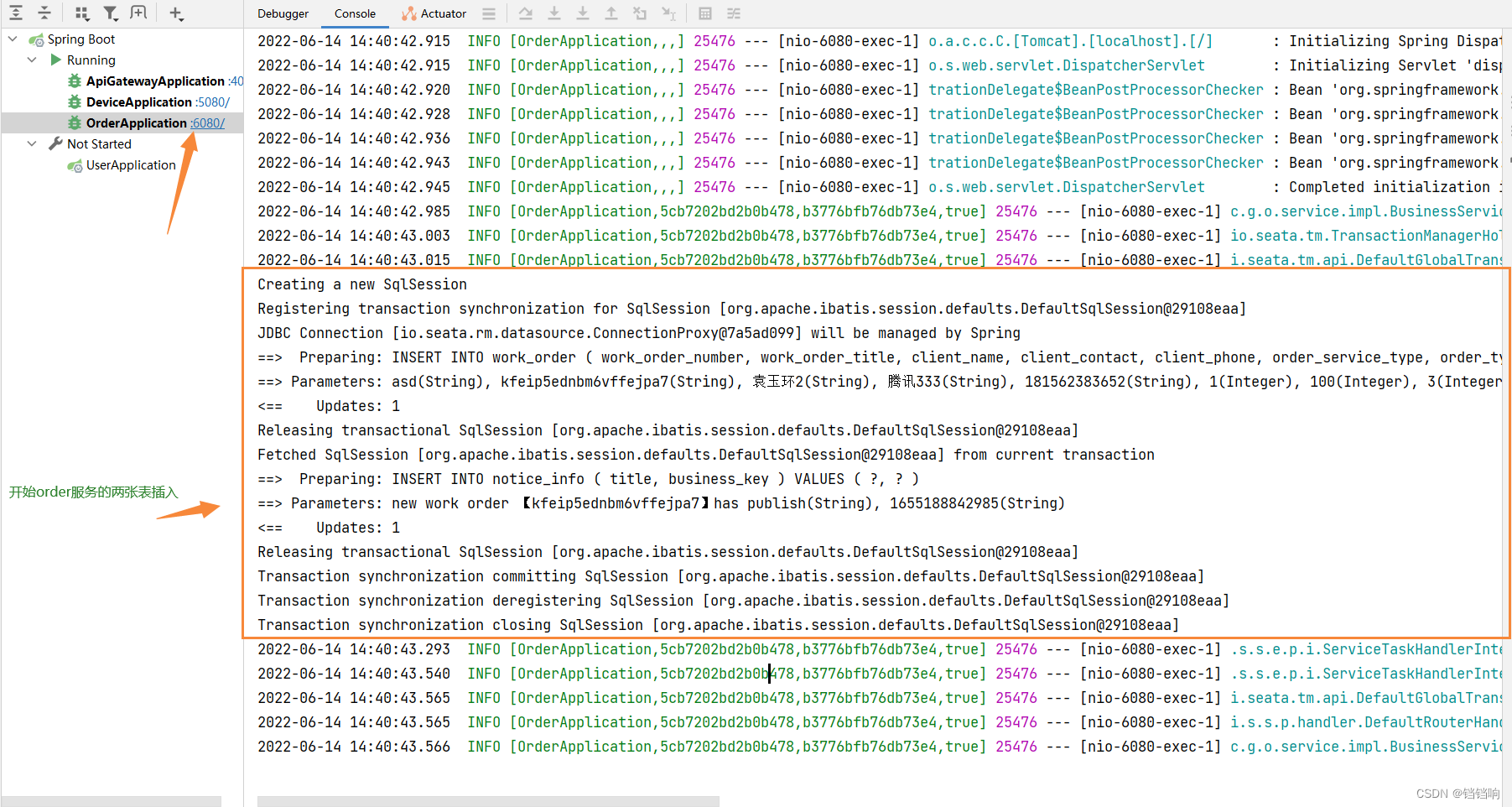
2、再执行CreateProblem的状态机,也就是插入device服务的两张表
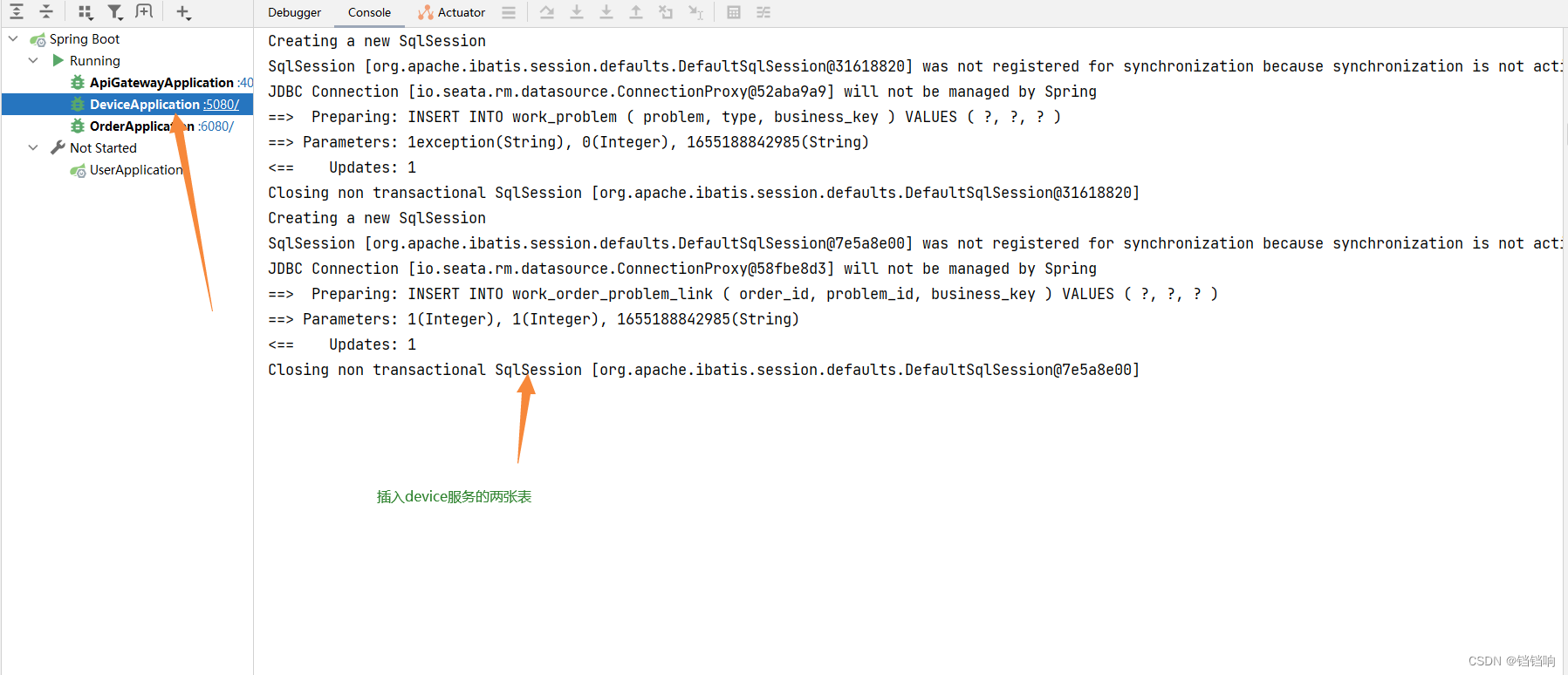
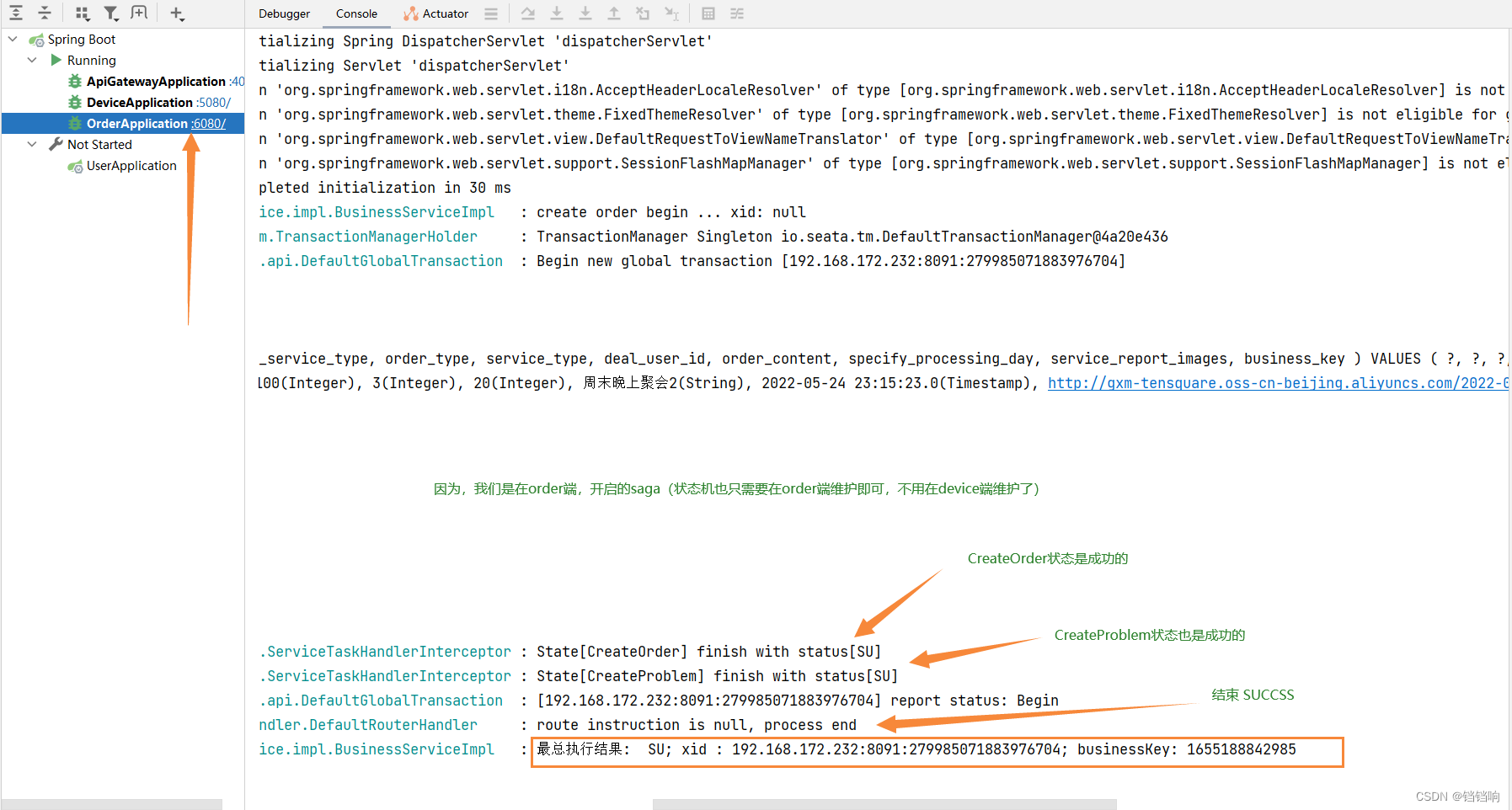
3、最总结果如下,我们关注instance.getStatus()和instance.getCompensationStatus()有没有问题即可。
3.2.1.3、数据库数据(后续有时间把这部分表的含义补上)
1、order服务下的gxm-300数据库情况,当然业务表notice_info和work_order数据是肯定在的,我就不放图了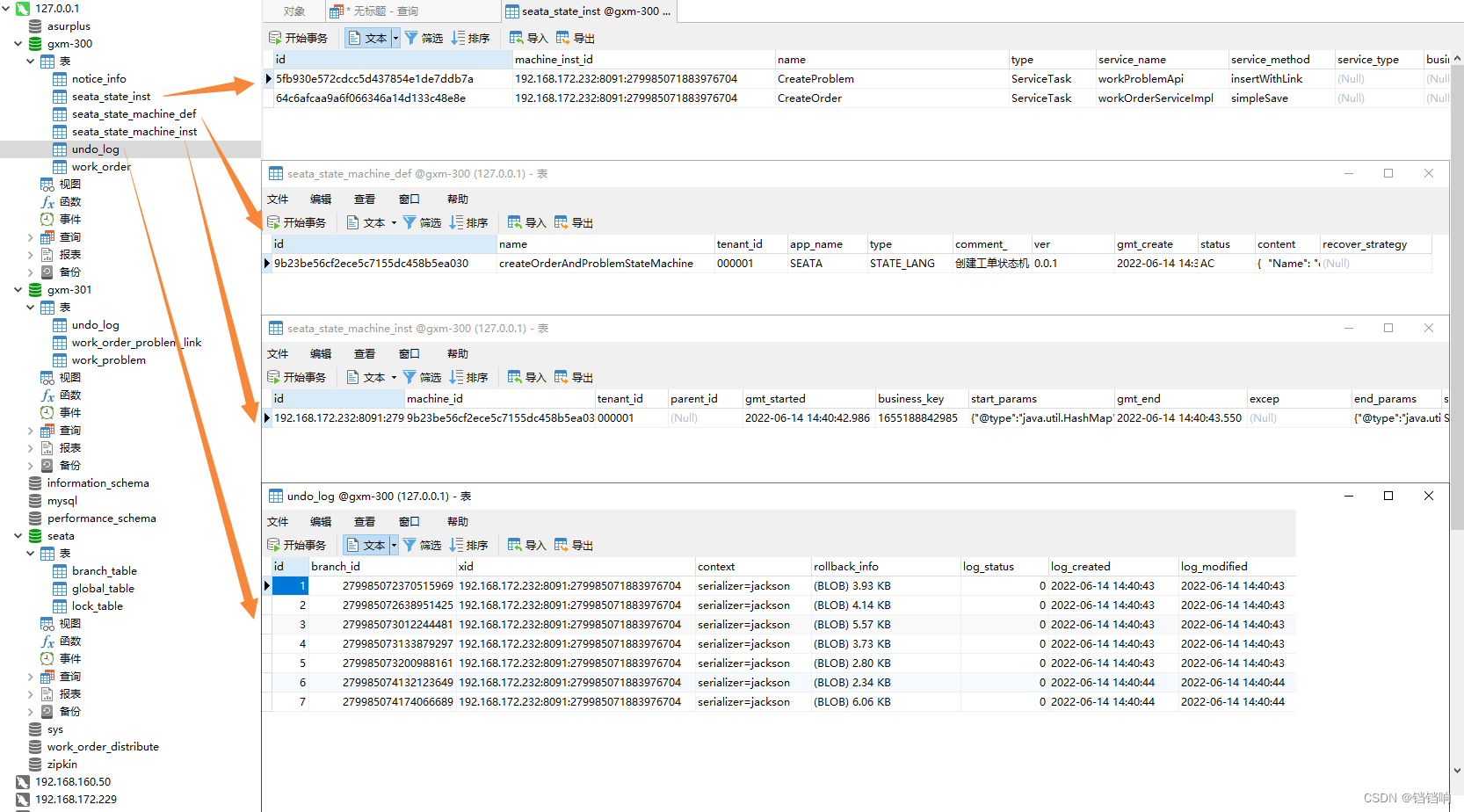
2、device服务下的gxm-301数据库情况,当然业务表work_order_problem_link和work_problem数据是肯定在的,我就不放图了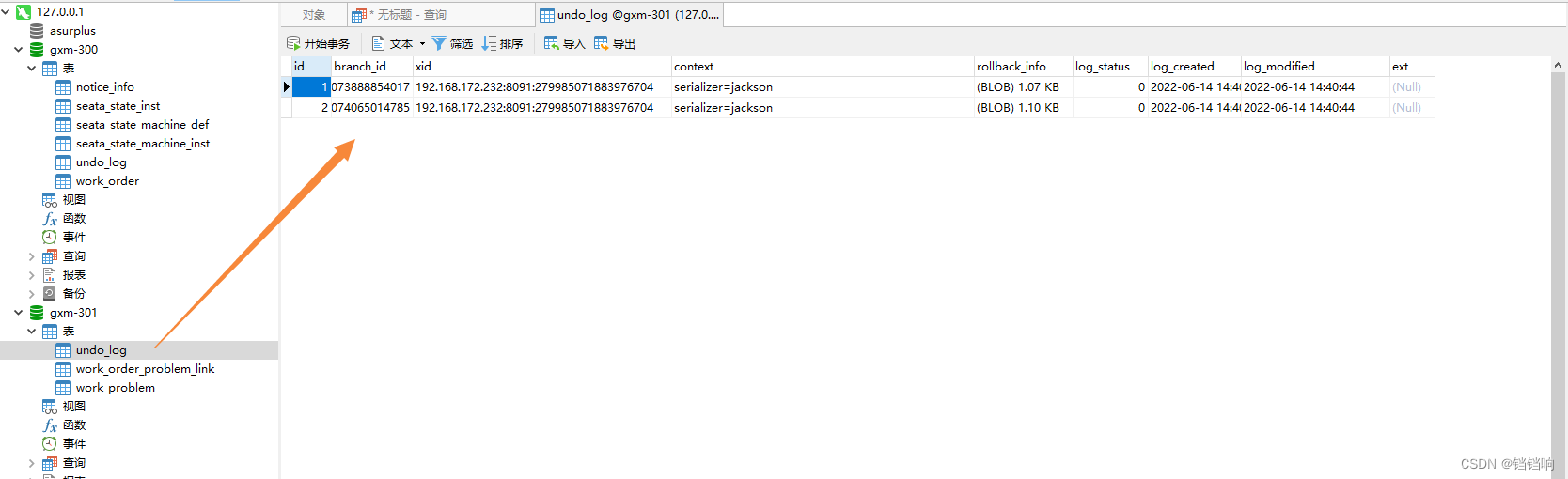
3、seata服务端的三张表数据
3.2.2、异常情况
1、测试该情况之前,把表数据清空一下
truncate table `gxm-300`.notice_info;
truncate table `gxm-300`.undo_log;
truncate table `gxm-300`.work_order;
truncate table `gxm-300`.seata_state_inst;
truncate table `gxm-300`.seata_state_machine_def;
truncate table `gxm-300`.seata_state_machine_inst;
truncate table `gxm-301`.undo_log;
truncate table `gxm-301`.work_order_problem_link;
truncate table `gxm-301`.work_problem;
truncate table `seata`.branch_table;
truncate table `seata`.global_table;
truncate table `seata`.lock_table;
3.2.2.1、状态机对象分析
1、我们在device服务端抛出个异常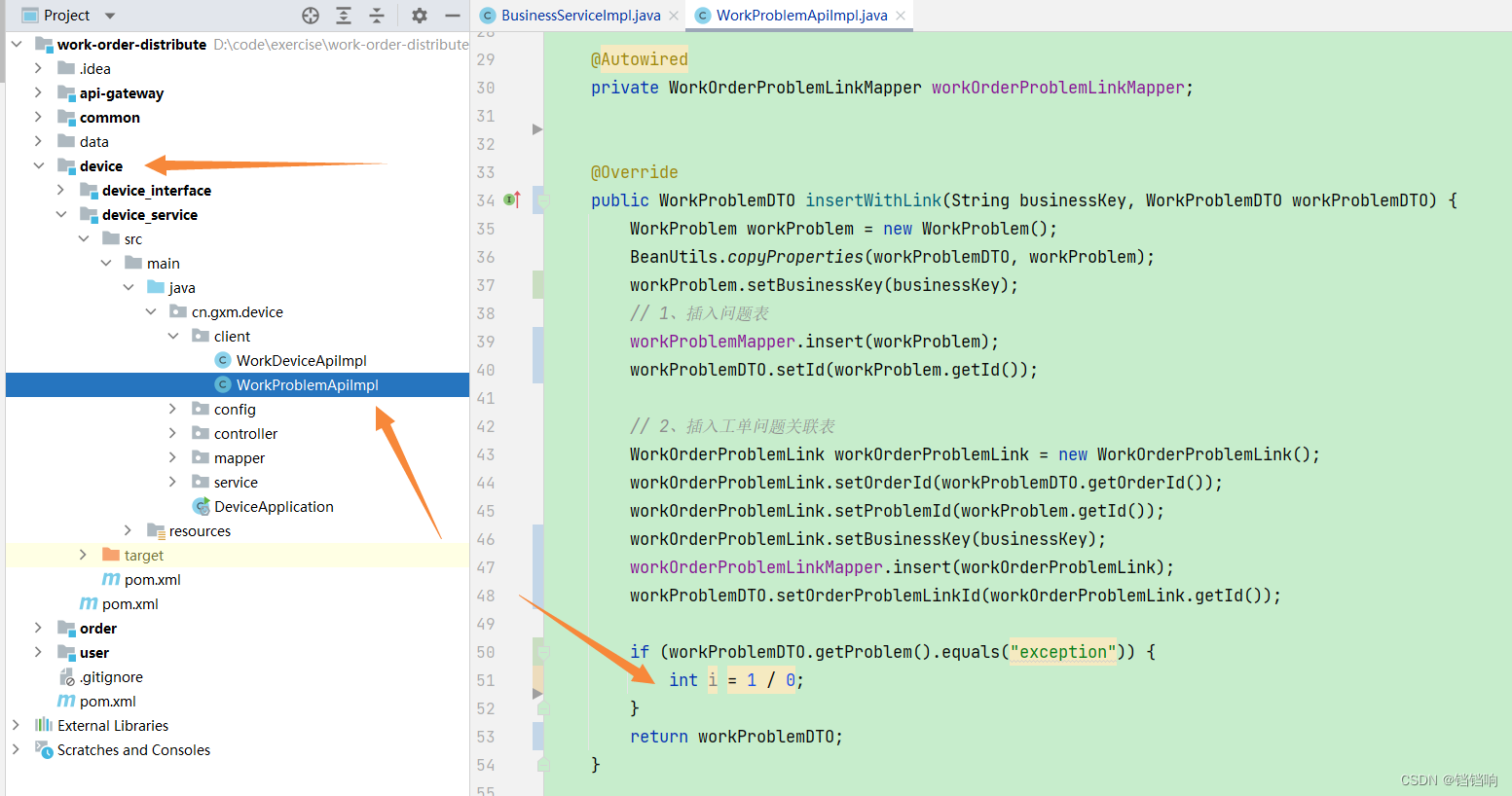
2、接着还在之前的log位置打上断点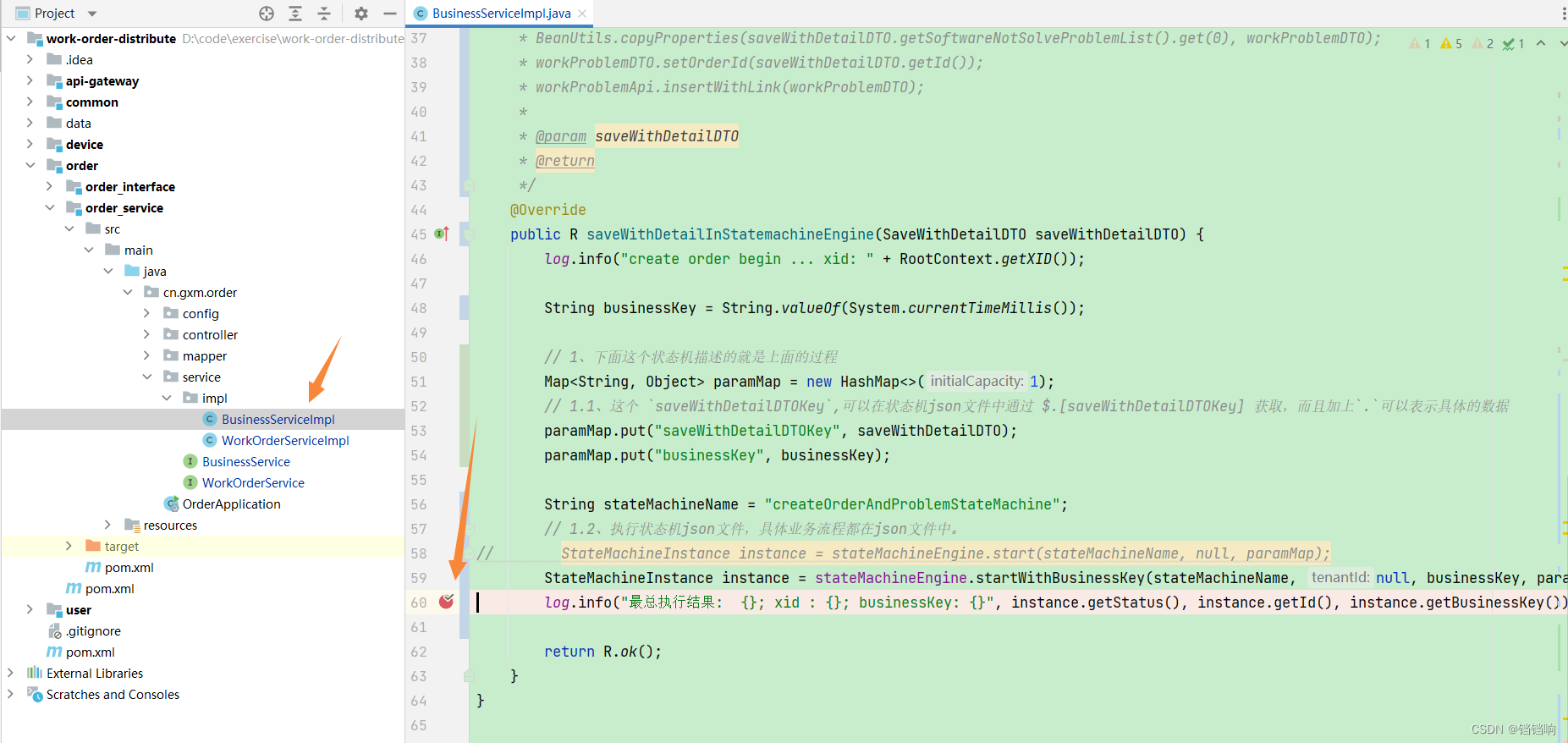
3、状态机对象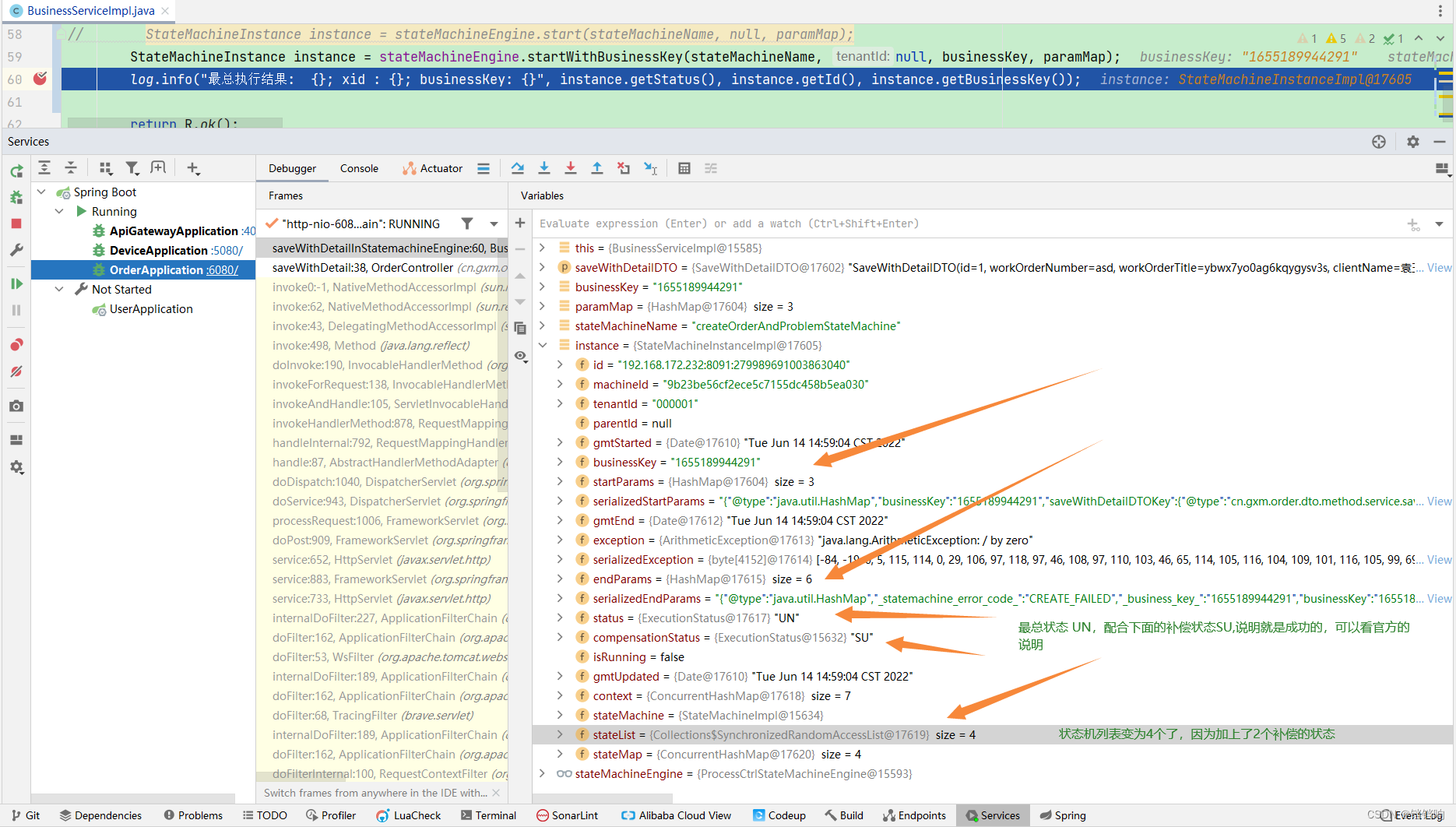
4、这里说一下这个状态,这个状态就是正常的(在有补偿的情况下),可以看官方的说明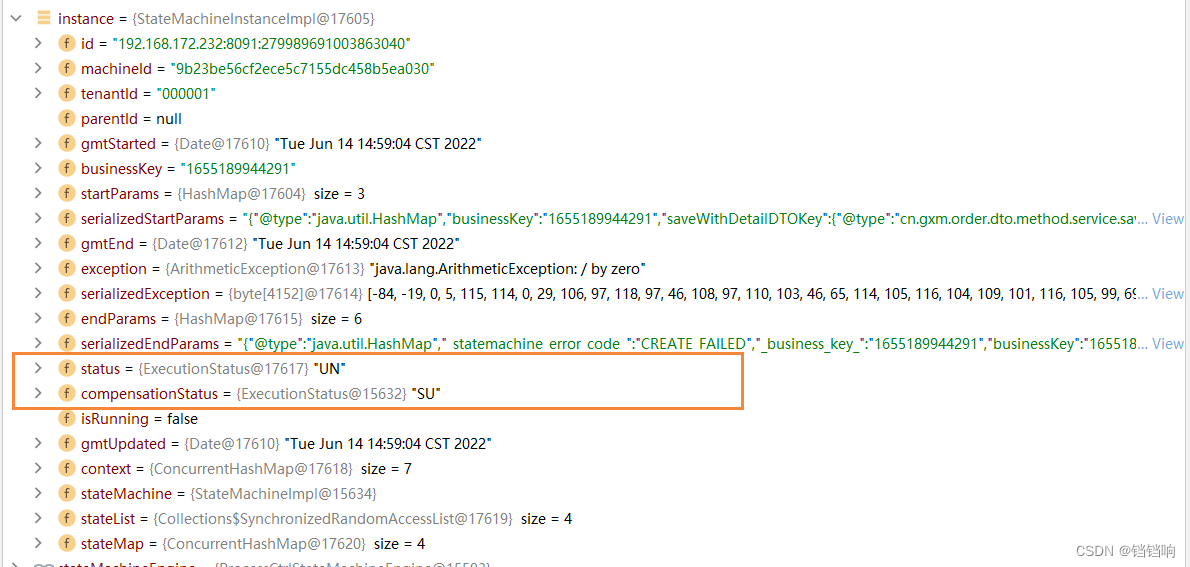
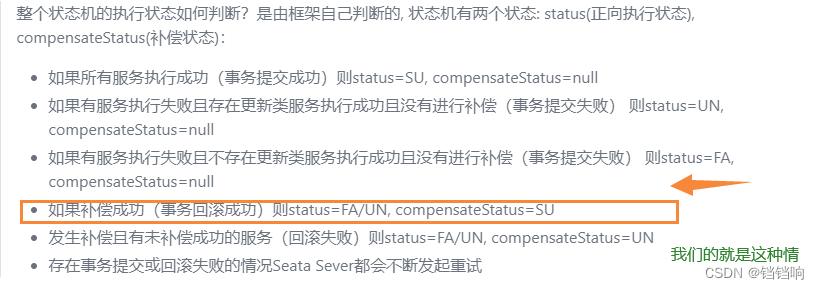
5、状态机列表为4个。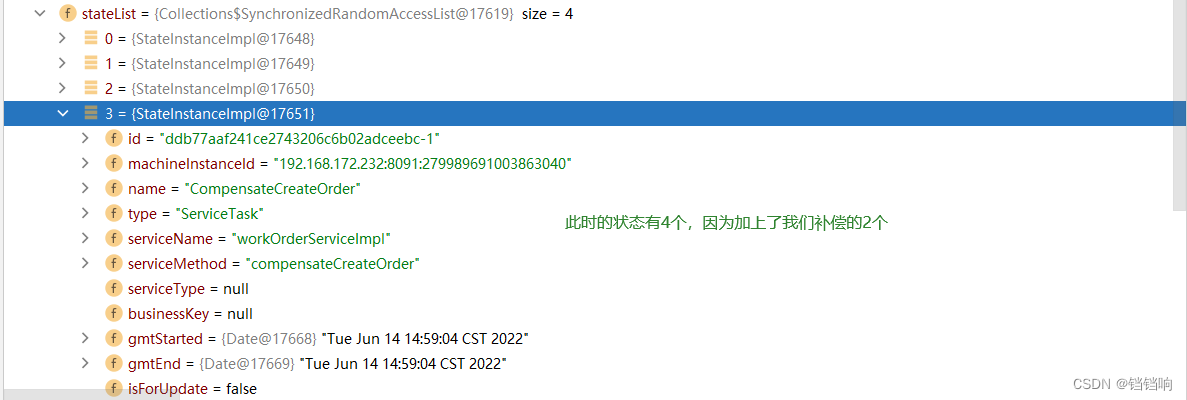
3.2.2.2、控制台日志
1、先执行CreateOrder的状态机,也就是插入order服务的两张表,没有问题,因为此时业务都还是正常的。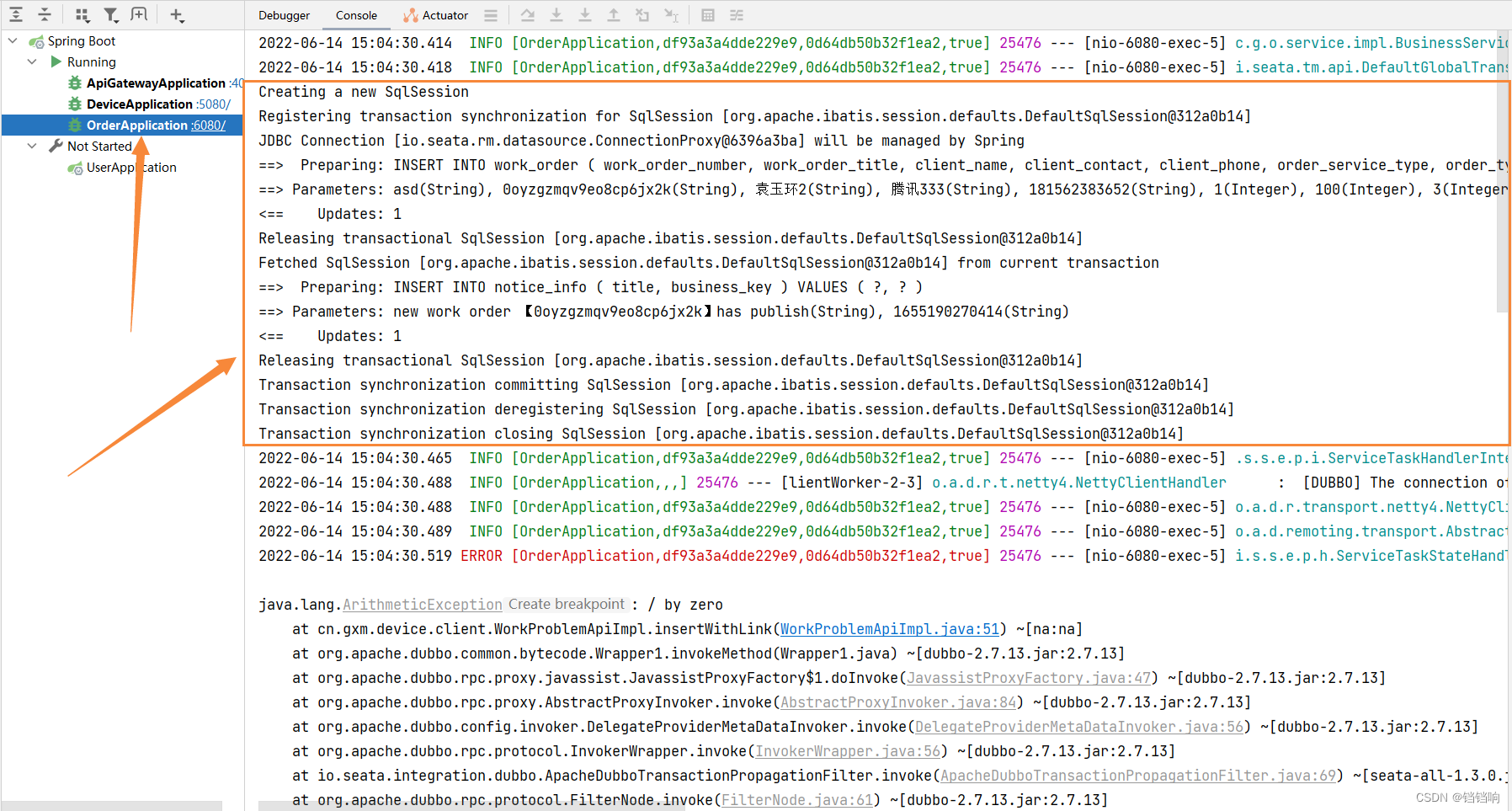
2、再执行CreateProblem的状态机,也就是插入device服务的两张表,然后报错java.lang.ArithmeticException: / by zero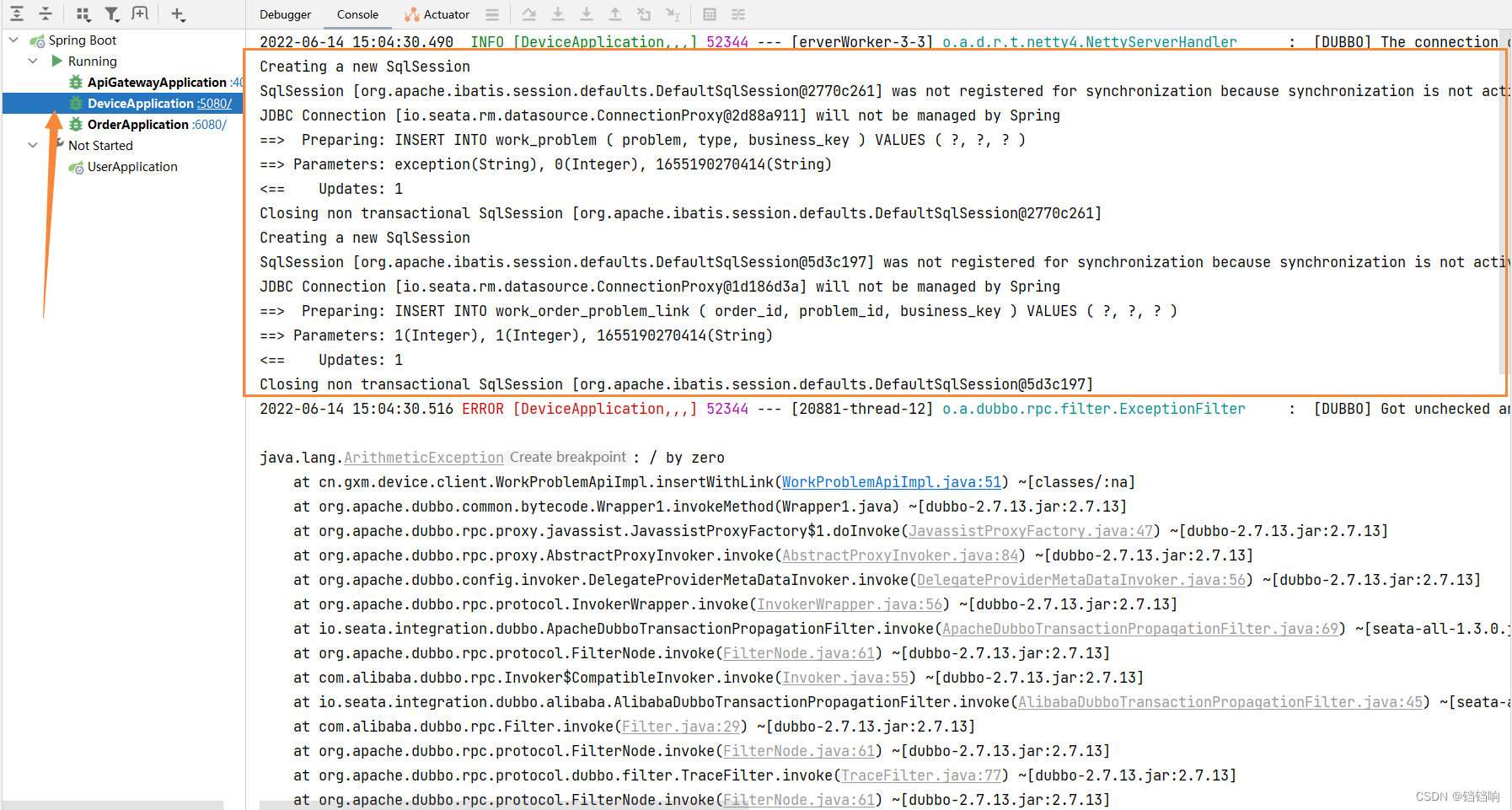
3、order服务收到device的错误信息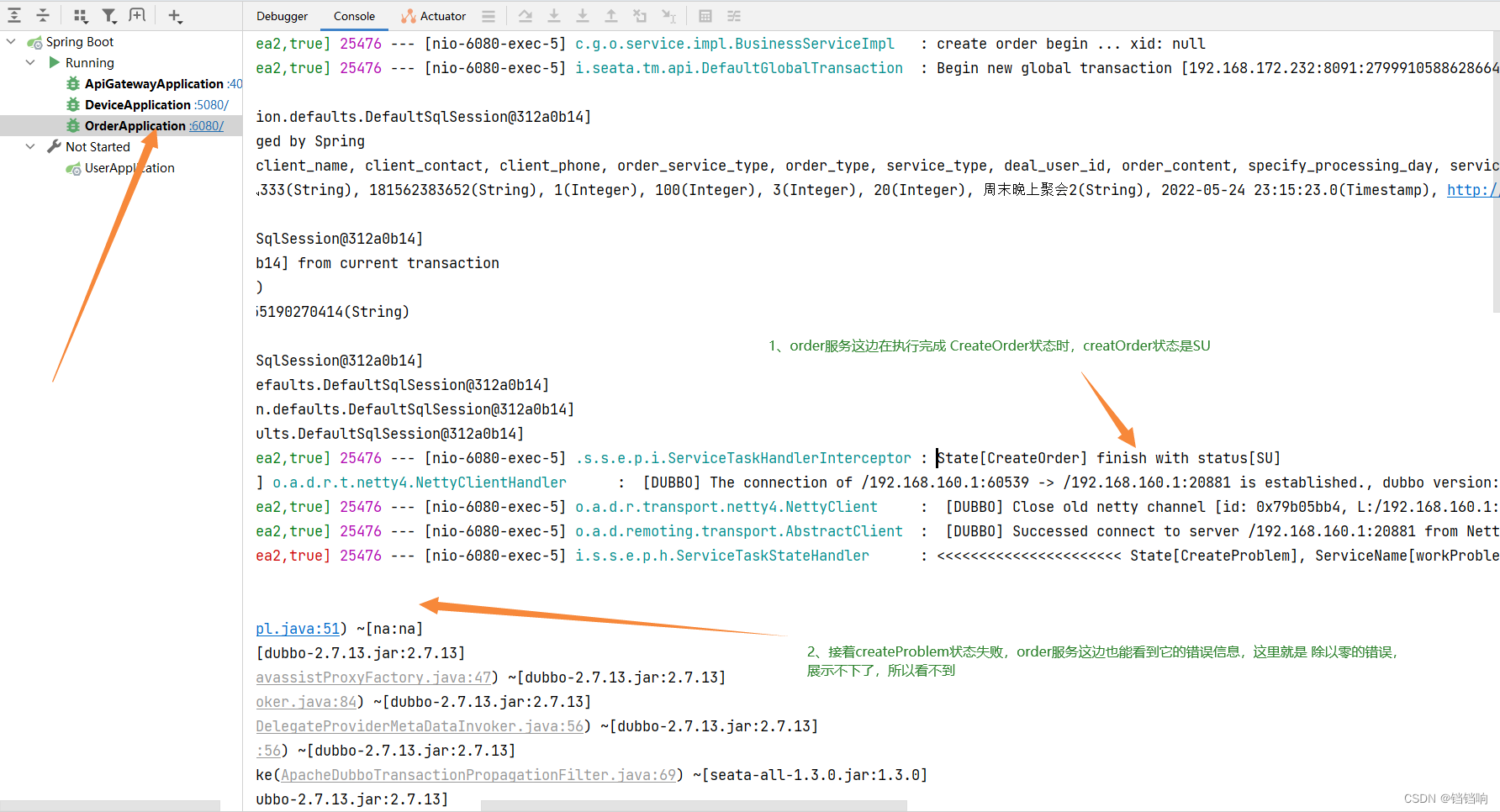
4、开始走补偿状态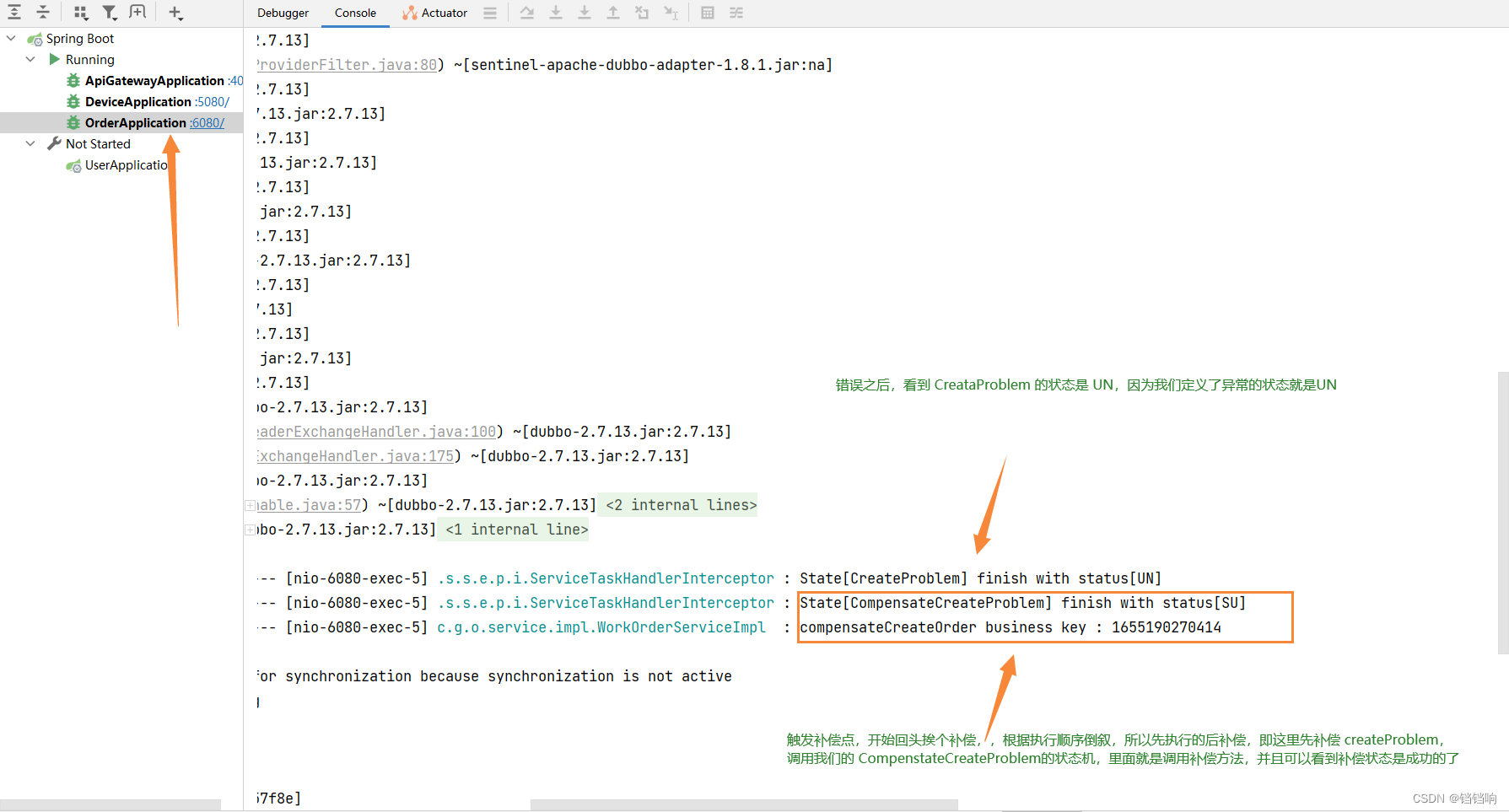
5、先补偿device服务,因为它最后执行 (这张图应该在第4张的中间,执行完成后,你可以看到 State[CompensateCreateProblem] finish with status[SU])
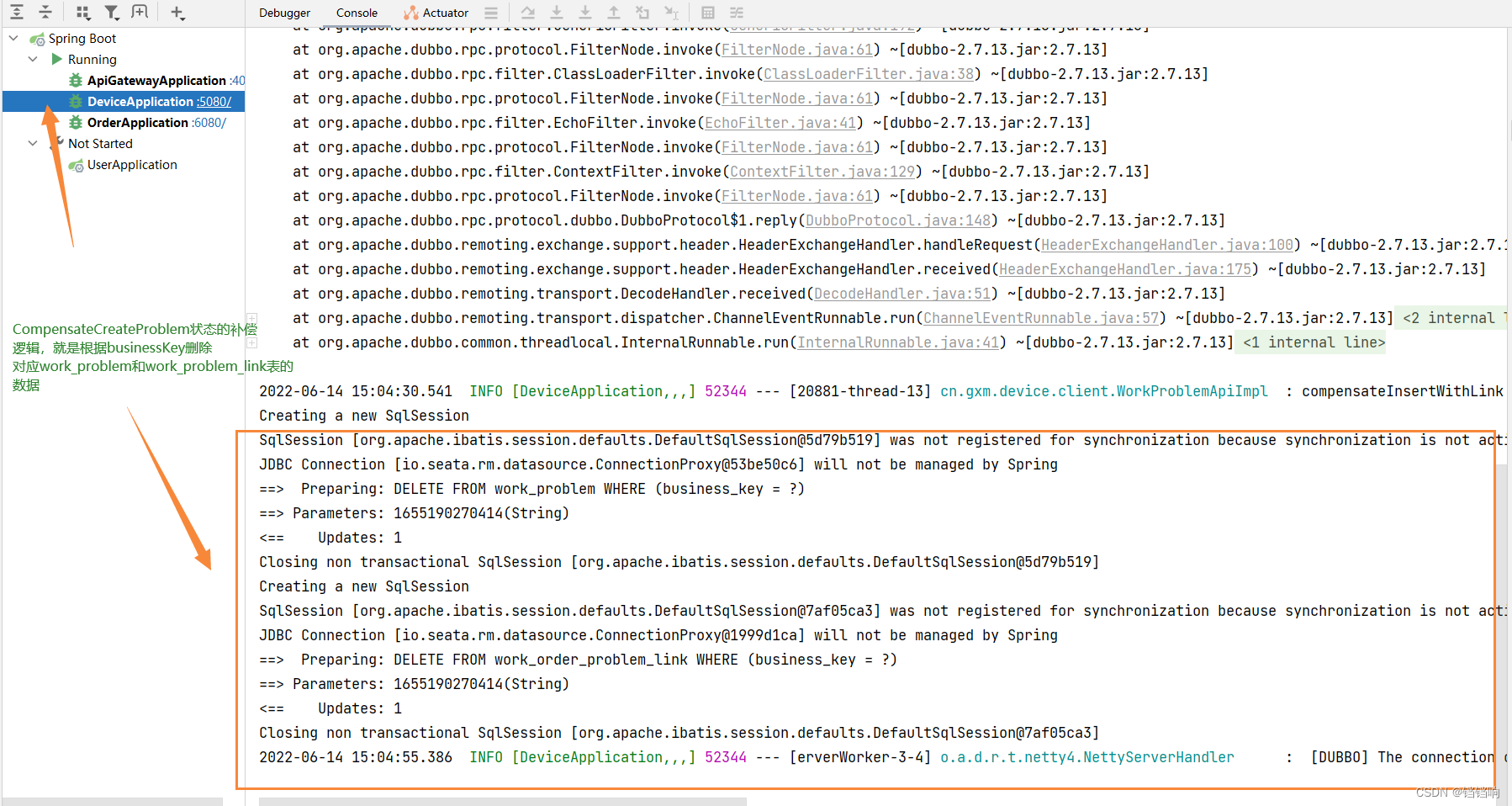
6、再补偿order服务

7、order补偿也成功,最总结果
最总执行结果: UN; xid : 192.168.172.232:8091:279996470823649280; businessKey: 1655191560707; compensationStatus SU
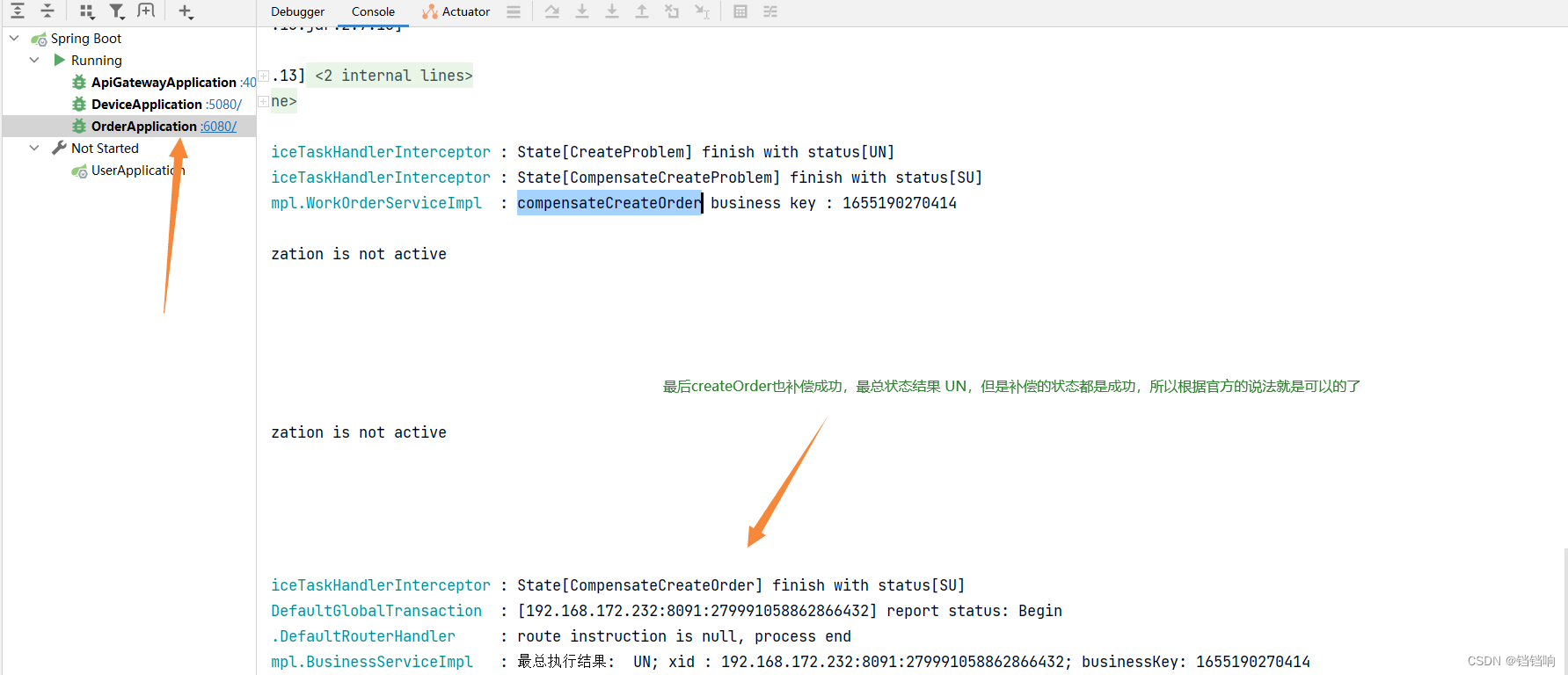
3.2.2.3、数据库数据(后续有时间把这部分表的含义补上)
1、order服务下的gxm-300数据库情况,当然业务表notice_info和work_order数据是肯定不在的,因为回滚了,我就不放图了
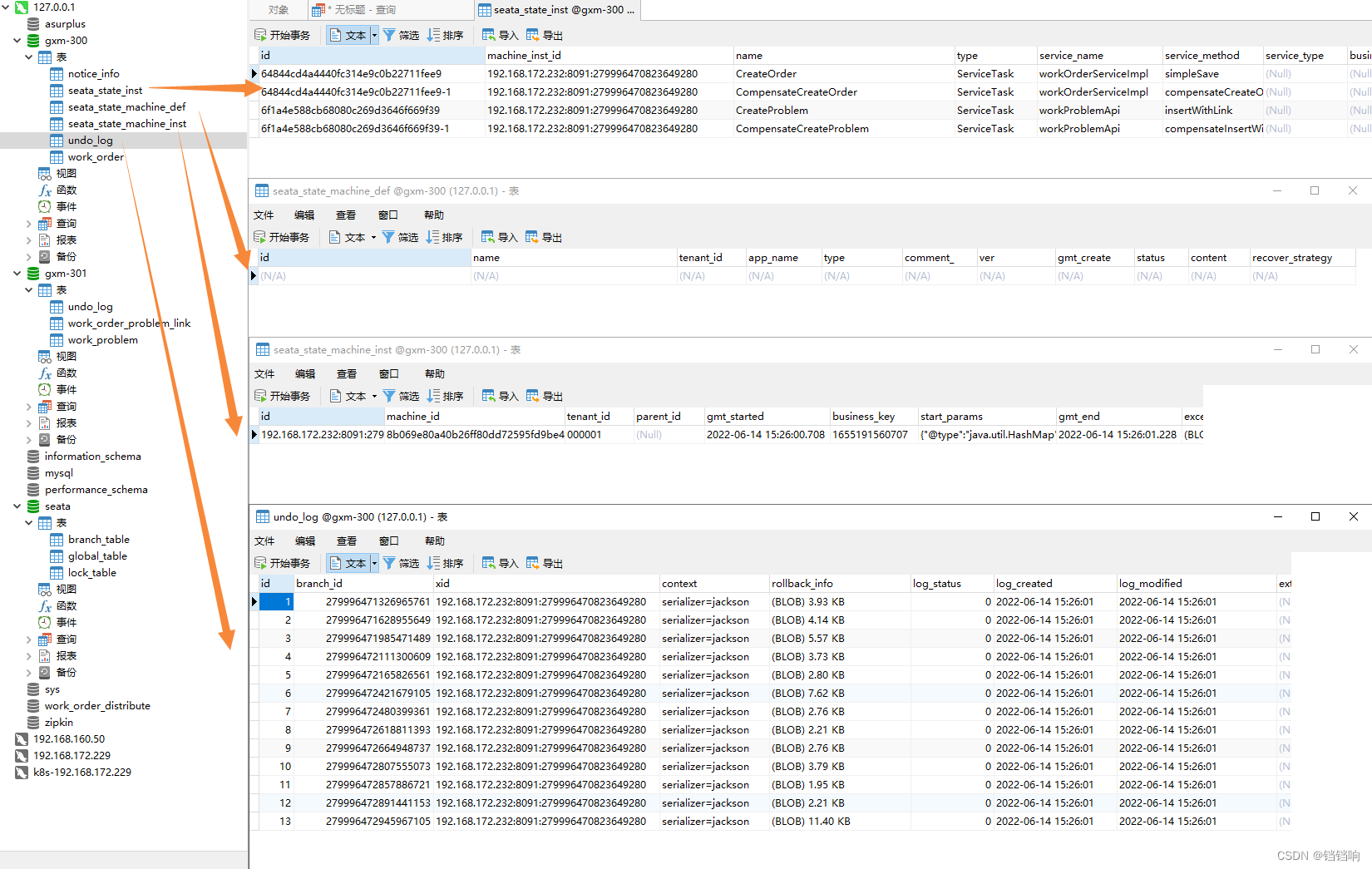
2、device服务下的gxm-301数据库情况,当然业务表work_order_problem_link和work_problem数据是肯定不在的,因为回滚了,我就不放图了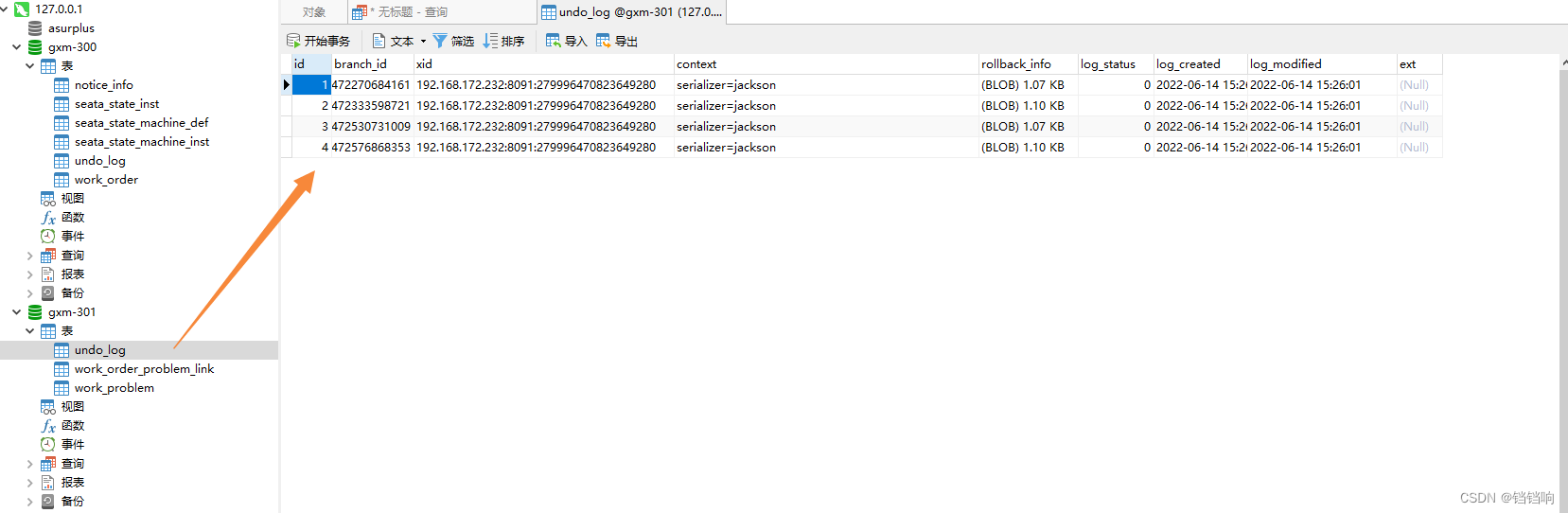
3、seata服务端的三张表数据
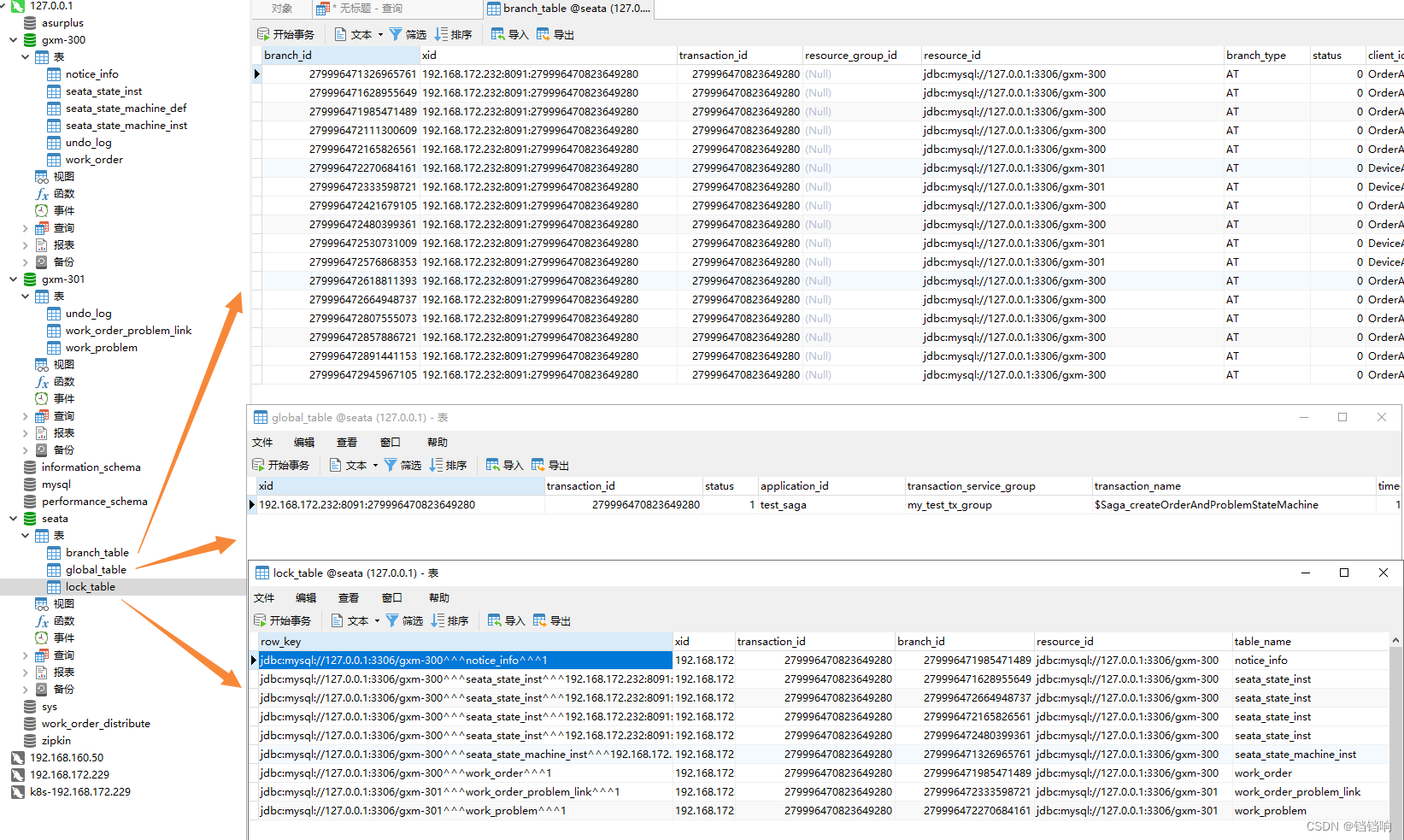
3.2.3、补充说明
1、根据我们前面写的状态语言json文件知道,补偿触发点CompensationTrigger,是在CreateProblem的时候触发的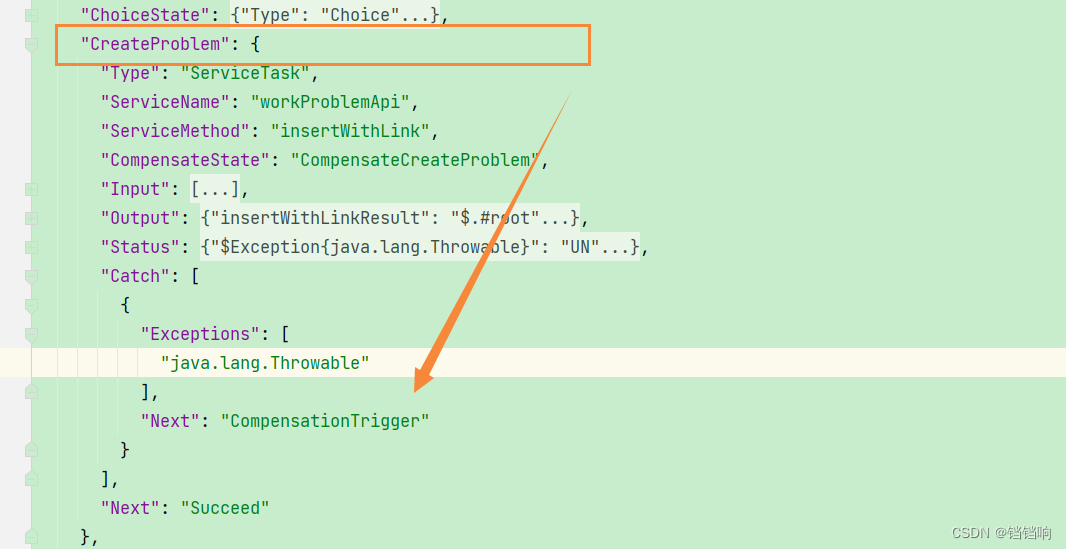
2、那对于开始的状态CreateOrder来说,它内部也有2个本地的mapper,而且它没有设置补偿触发点,一旦直接在CreateOrder失败怎么办呢,所以有两种方式,
- 第一种方式,
CreateOrder阶段失败,也直接触发补偿点,这样也直接执行CompensateCreateOrder而已,因为按照倒叙的方式补偿,它就是第一个。 - 第二种方式,不设置它触发补偿点,直接使用spring的事务回滚它就行,因为它是自己本地项目的的2个mapper。
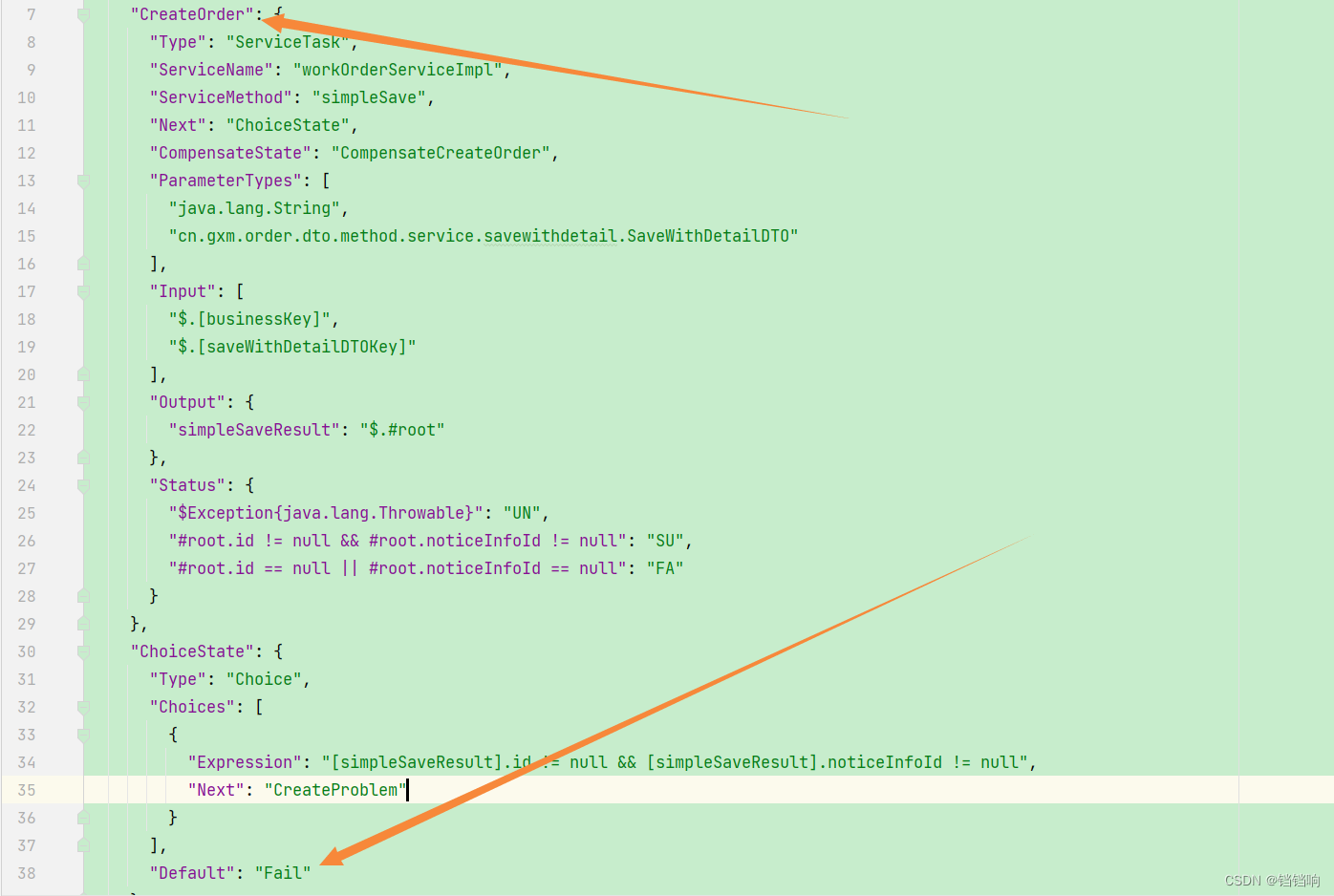
3、这里表示一下第二种方式直接设置spring 事务回滚,如下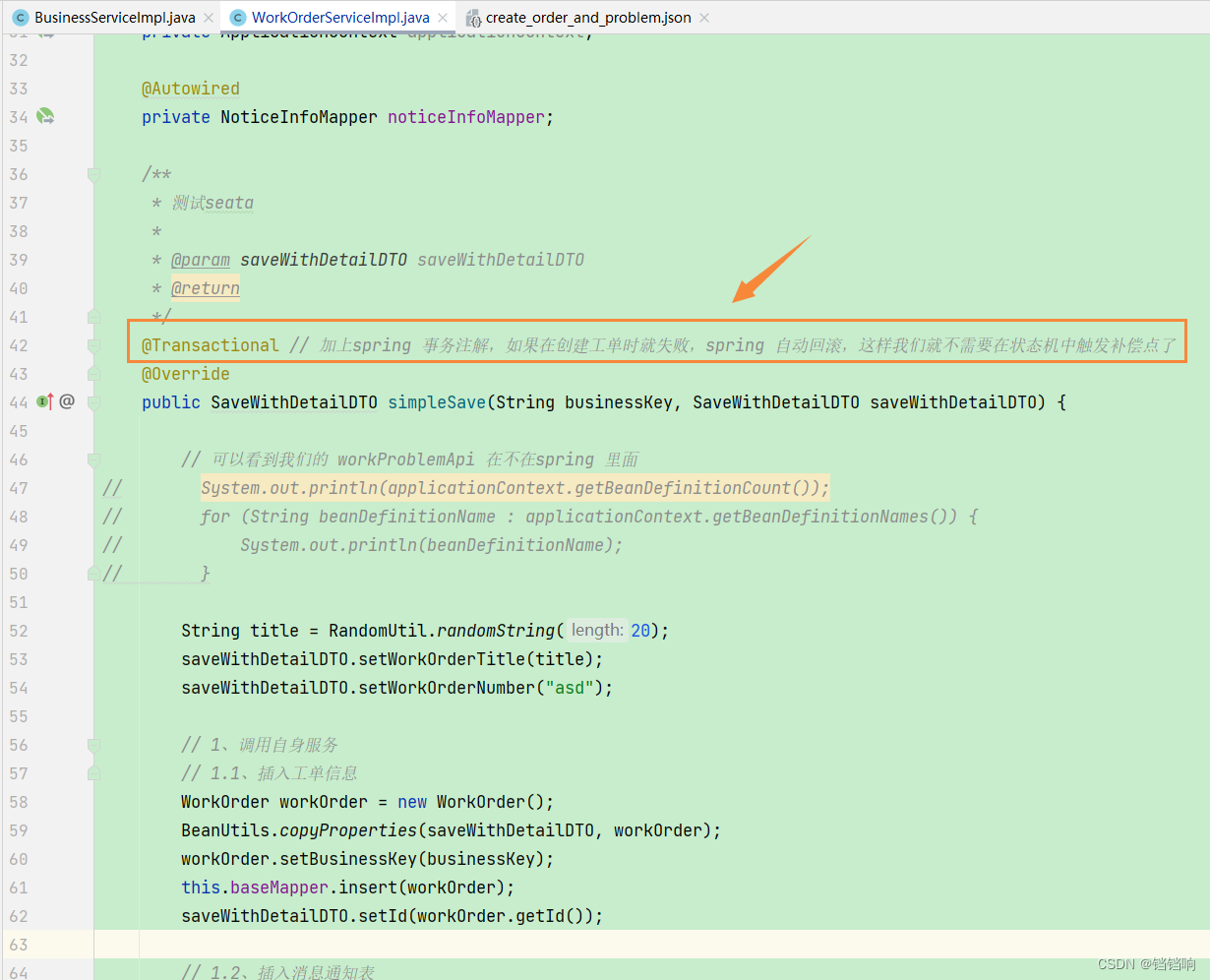
3.3、其他问题
1、注意一旦中间状态发生了异常,那么这个状态的结果你就很难拿到了
3、根据第2点,同理可得,我们在设置ServiceTask的状态时,也是需要把异常判断放在第一位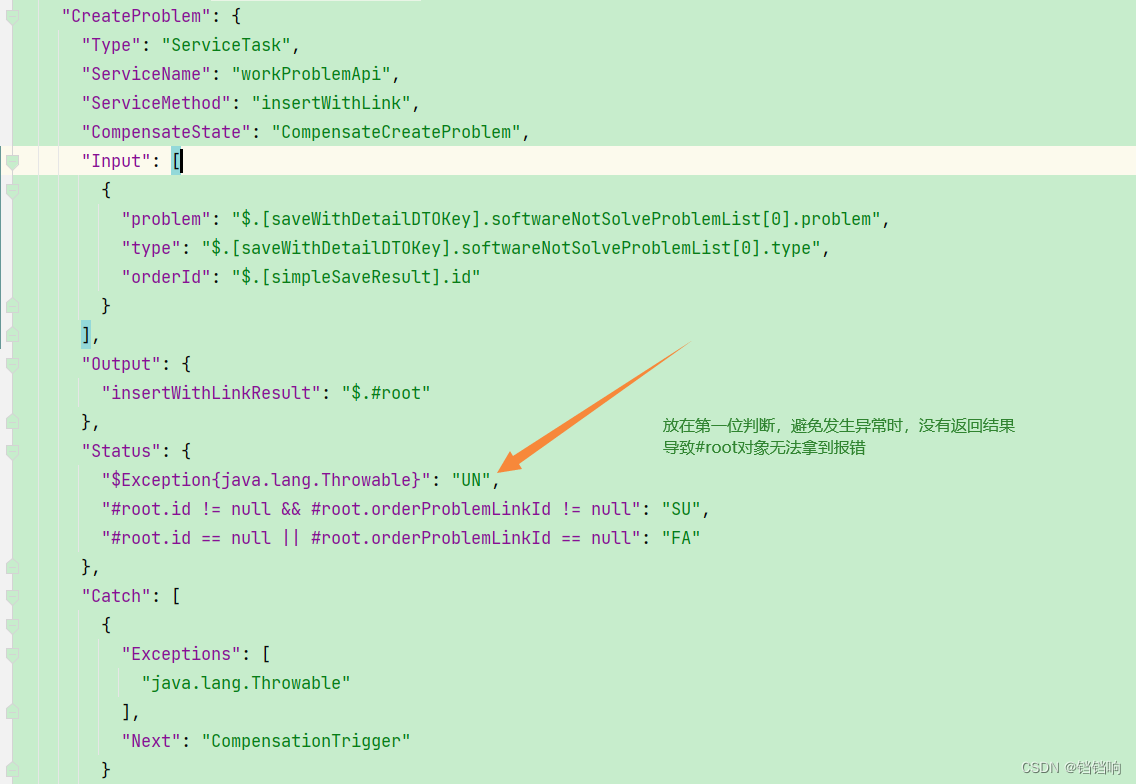
四、XA 模式
4.1、使用说明
1、其实XA和AT差不多,我的意思是代码差不多,所以改动的地方不多,主要的一点是你使用的数据库支持XA,比如MySQL就是可以的,主要点就是开启模式,默认就是AT模式(当然这个参数seata.data-source-proxy-mode是1.4.0开始提供的,之前的版本都只能通过代码修改数据源代理来切换,下面有说)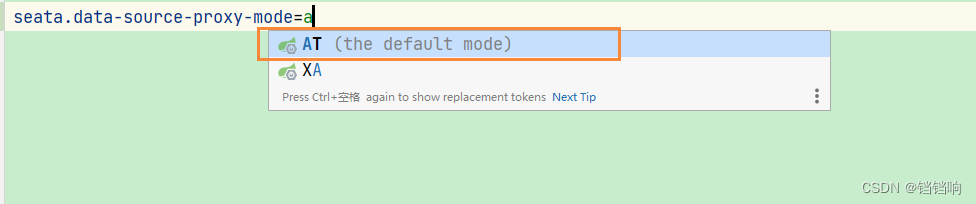
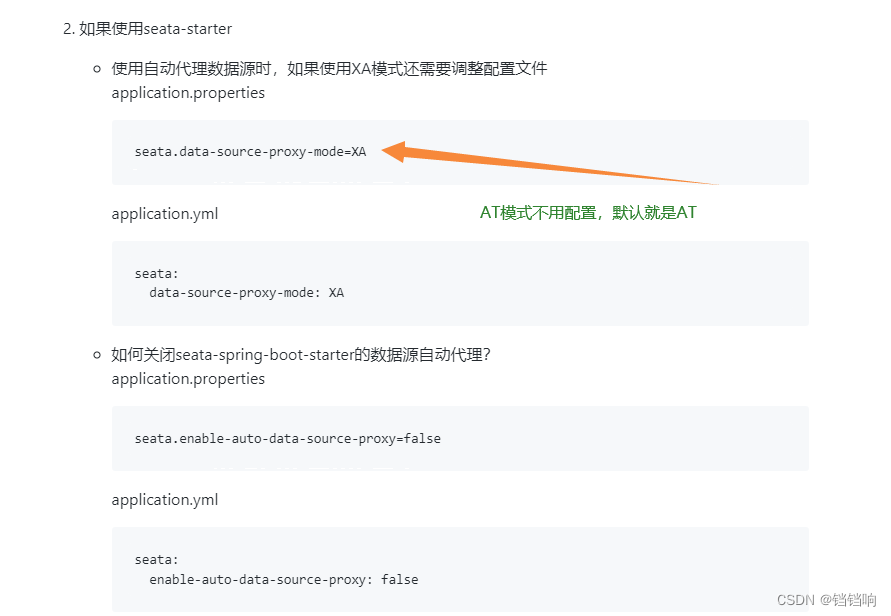
2、第一我们需要修改代理数据源,如果你使用的是seata-starer,并且版本seata的版本 ≥1.4.0 可以直接使用注解的方式来替换,如下图,
之前在
AT模式在,不配置,是因为seata-starer依赖,其内部内置GlobalTransactionScanner自动初始化功能,默认是AT模式,所以不用配置
3、但是如果你的版本没有 ≥ 1.4.0,那么你就只能使用代码的方式去切换了,当然你可以直接选择更新(seata更新,或者单独更新,后面有说)
@Bean("dataSource")
public DataSource dataSource(DruidDataSource druidDataSource) {
// DataSourceProxy for AT mode
// return new DataSourceProxy(druidDataSource);
// DataSourceProxyXA for XA mode
return new DataSourceProxyXA(druidDataSource);
}
4、因为XA模式用不到undo_log表,所以我们可以直接删除,最后gxm-300和gxm-301如下
5、因为我这里使用的是 spring-cloud-starter-alibaba-seata依赖,里面的seata版本还是1.3.0版本,使用不了那个注解直接切换AT和XA模式,如果我要是使用代码改的话,还得从数据源到mapper,全部改一遍,实在有些麻烦,所以,我们可以手动提升seata的版本,当然官网也是有建议的,可以用下面这种方式提示版本,所以我这里就把order服务和device服务的seata手动提升到1.4.0版本。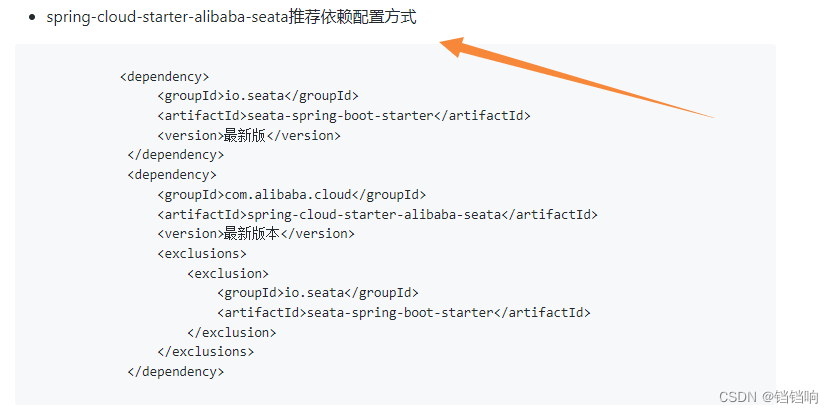
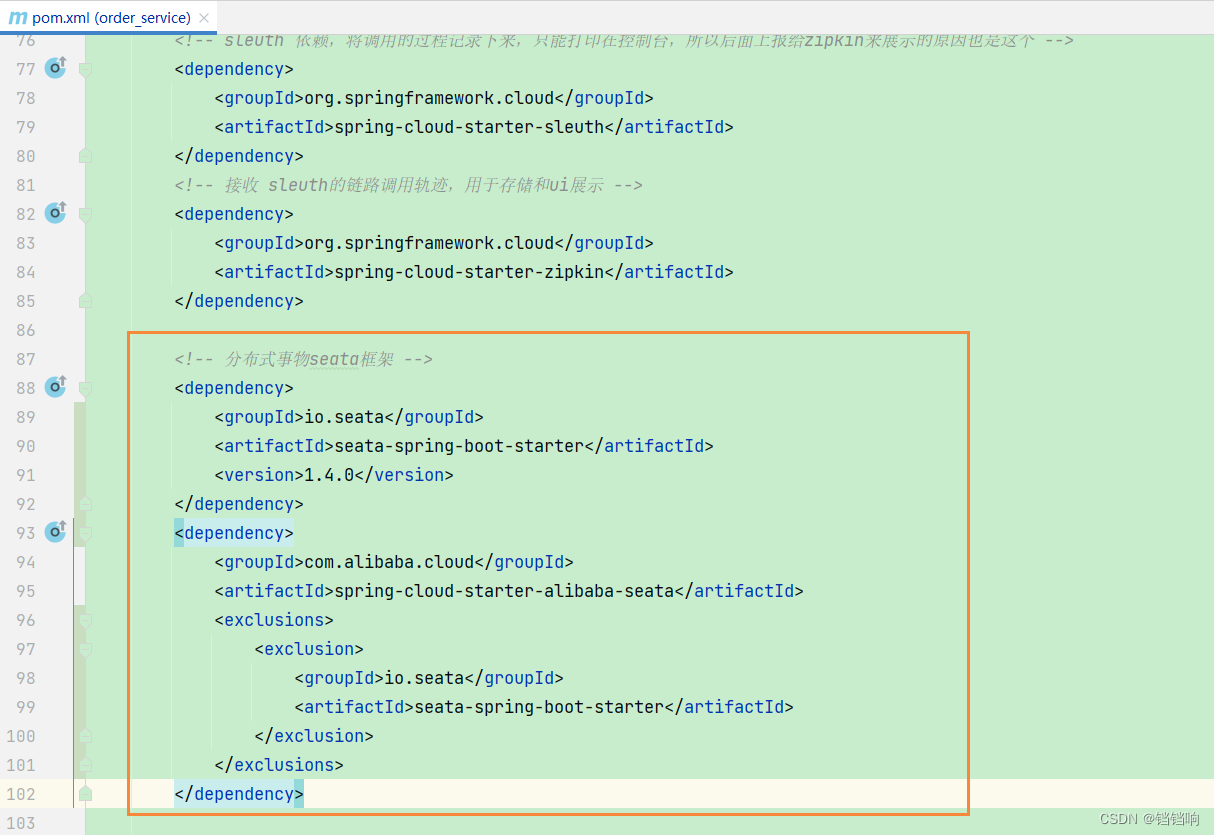
4.2、代码修改
1、在device服务和order服务增加数据源代理配置(使用注解或者代码,看你的版本或者你想用那个)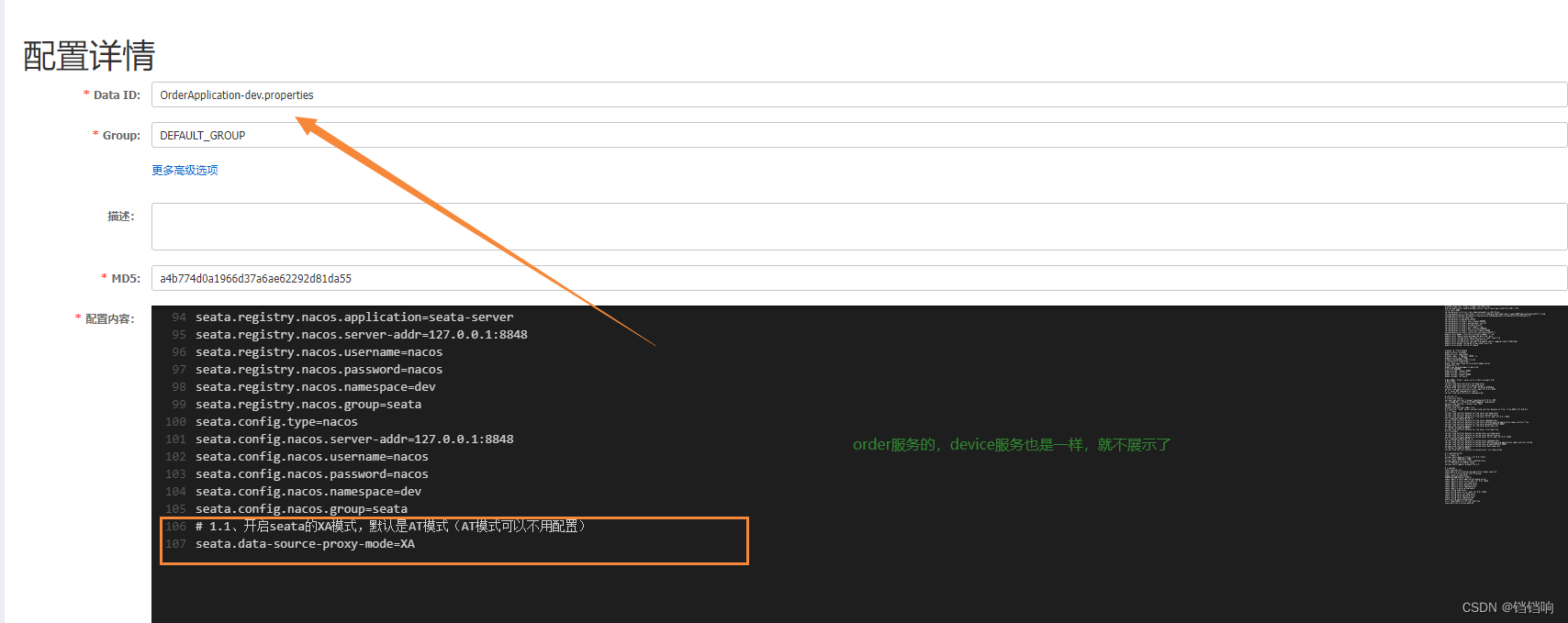
2、其他就和AT模式没有区别了
3、如果项目没有性能的要求我建议使用XA模式,因为,它是强一致性,而AT模式是最总一致性。解释的话,看第五节,如何选择四种模式。
4.3、正常测试(参考AT模式)
省略
4.4、异常测试(参考AT模式)
省略
4.5、测试seata回滚时,镜像数据被其他事务修改后,无法回滚成功的情况(参考AT模式)
1、我们还是和AT模式一样,增加一个接口,修改插入的数据
2、并在device服务休眠
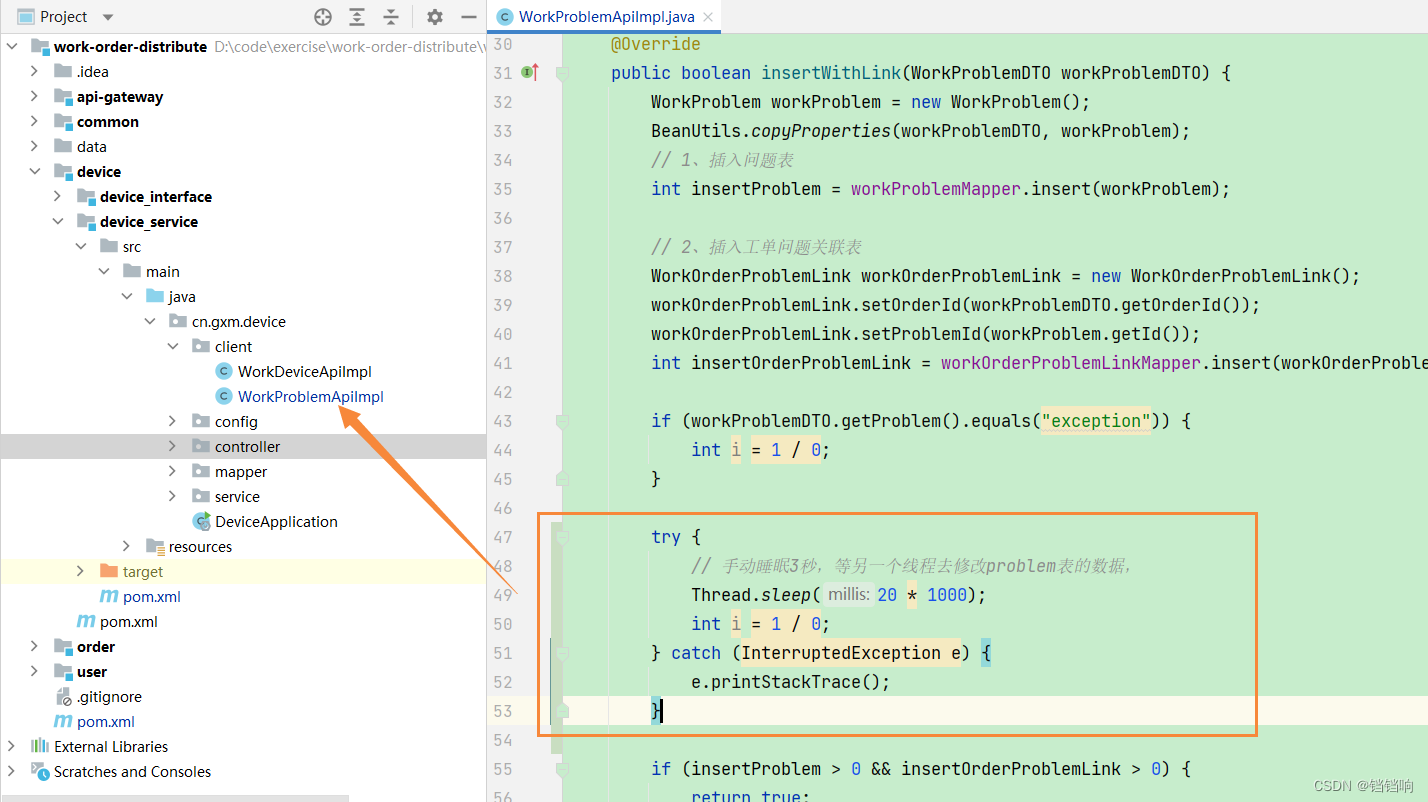
3、记得修改全局事务时间和远程调用组件的超时时间偶,AT模式有,这里就不再多说了
4、在device服务休眠时间,我们调用改动接口,你会发现一直在阻塞,等到插入接口结束了,它也返回了,而且看控制台的数据,发现没有修改到数据,但是看日志插入语句不是先执行的吗。这就是和AT模式的不同之处了。XA 如下
1、因为XA第一阶段不会提交数据,会锁住了那个资源到第二阶段(你在它睡眠期间到数据库看,是看不到那个插入的数据的),我们在第一阶段执行完成后,调用修改接口,是 找不到 那个数据的。
2、而
AT模式是第一阶段直接提交的,所以你能找到那个数据,后续失败回滚是根据undo_log镜像数据来进行回滚的,所以说AT模式是最总一致性,而XA模式是强一致性的。
五、如何选择四种模式(强烈建议看下)
1、四种模式的优缺点和需要我们处理的地方,这篇文章都说了 分布式事务——Seata、XA、TCC、AT、SAGA模式
六、遇到的问题
6.1、Cannot construct instance of java.time.LocalDateTime
1、这个问题很多人都遇到过了,github的issues上面也提出了,主要原因是seata在回滚的时候,用到undo_log的镜像数据,镜像数据默认是fastjson序列化的,然后如果你的业务表有时间字段,并且是datetime类型,那么seata在回滚这类数据的时候,会受到影响。比如,我现在的业务表notice_info就有这个时间字段,一旦涉及到这个业务的回滚,要去undo_log的表中找之前这个表的前后镜像的数据,在反序列化时就会失败。
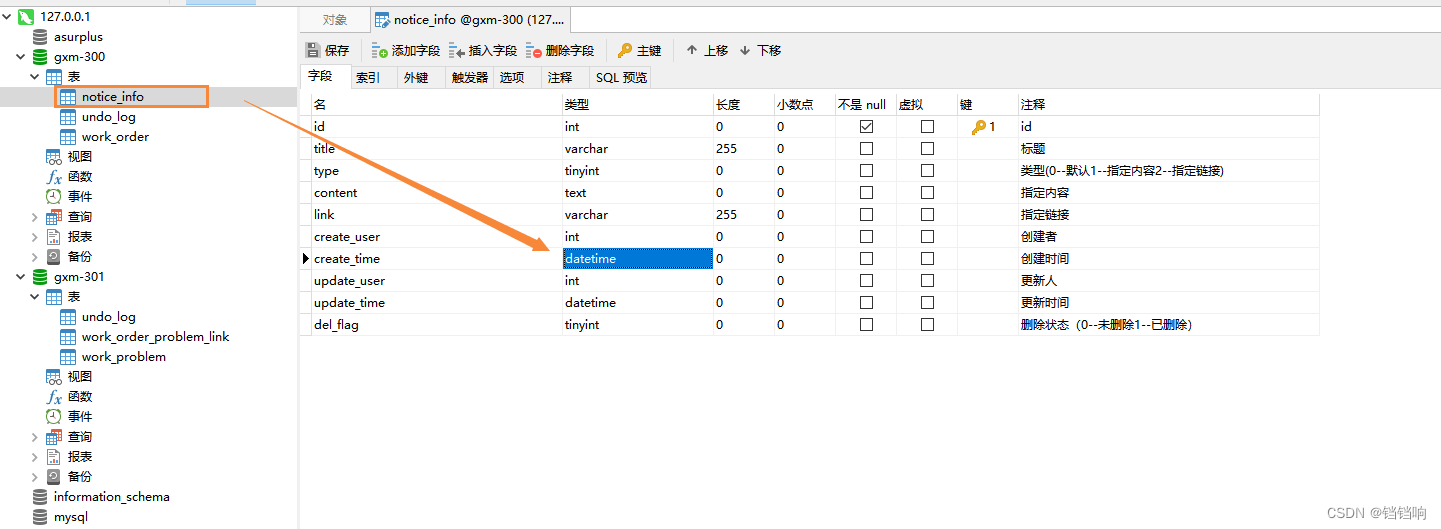
2、这个是那个镜像的内容,可以看到里面确实有这个时间字段。
3、出现这个问题时,会在全局事务发起方,也就是使用了@GlobalTransactional注解的服务中无限的报错,一直不停歇的报错,你可以看到下图,我都把那个服务关掉了,不然一直刷新那个错误。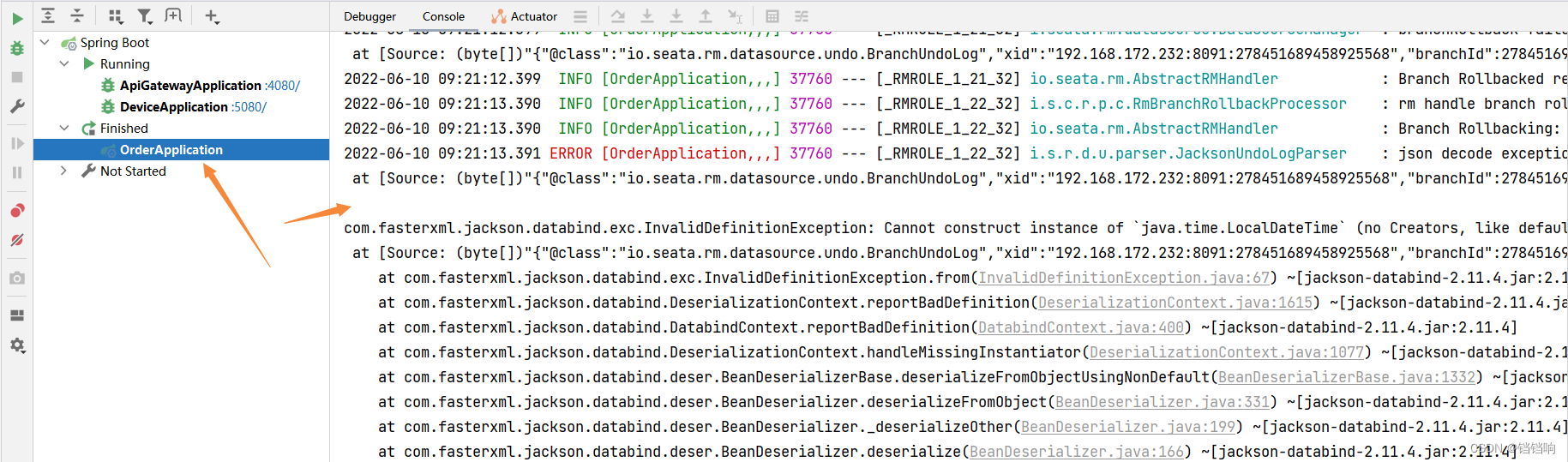
4、解决方案,最后我采用的是降低MySQL版本到8.0.20
seata出现json时间字段序列化错误问题,我不建议修改序列化为其他方式,因为其他方式的可读性,不太好,万一线上出现问题,我们需要及时去查看,还是json方便快速。
官方的github 上面也有这个问题 LocalDateTime转换异常,springboot版本:2.4.4
6.2、io.seata.core.exception.RmTransactionException: Response[ TransactionException[branch register request failed. xid=xx, msg=Data truncation: Data too
1、问题截图如下
2、但是根据上面的日志你看不出来什么,只是说数据大,上网搜索后,会发现说这个是因为lock_table表在插入数据时,字段太长了。
3、所以具体是那个表的那个字段有问题,不要根据网上的乱改,要看服务端日志,因为客户端没有说那个表的那个字段,seata服务端日志如下,但是好像也没有说那张表,只是说PK字段,所以,你如果了解一些seata运行流程的化,就知道这是lock_table表的pk字段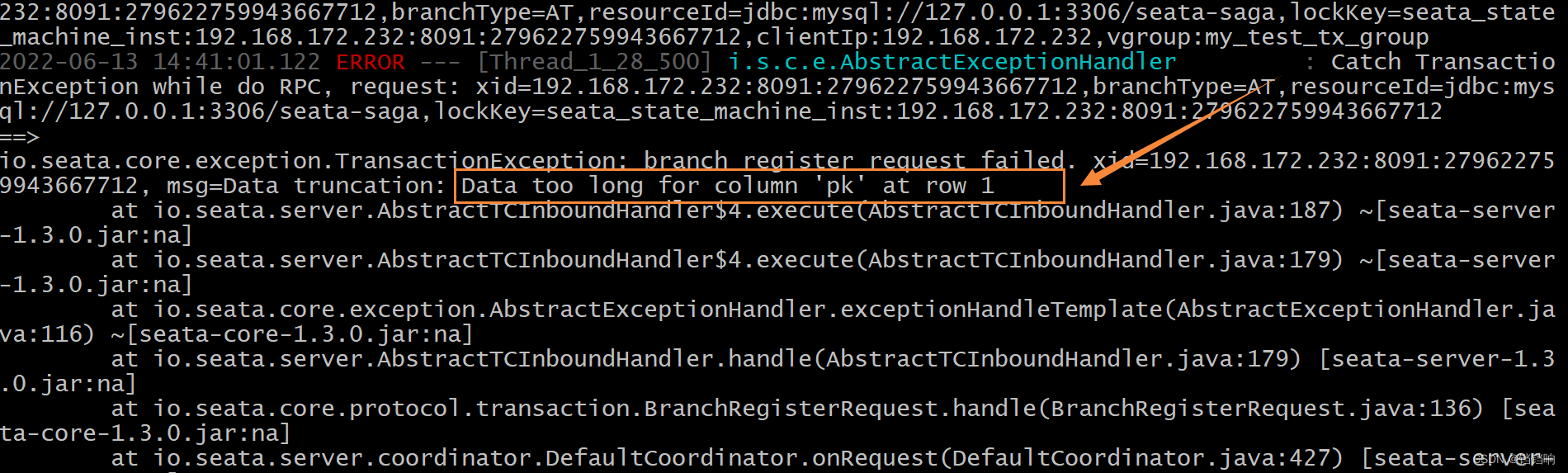
4、所以,我们修改一下lock_table表的pk字段长度即可。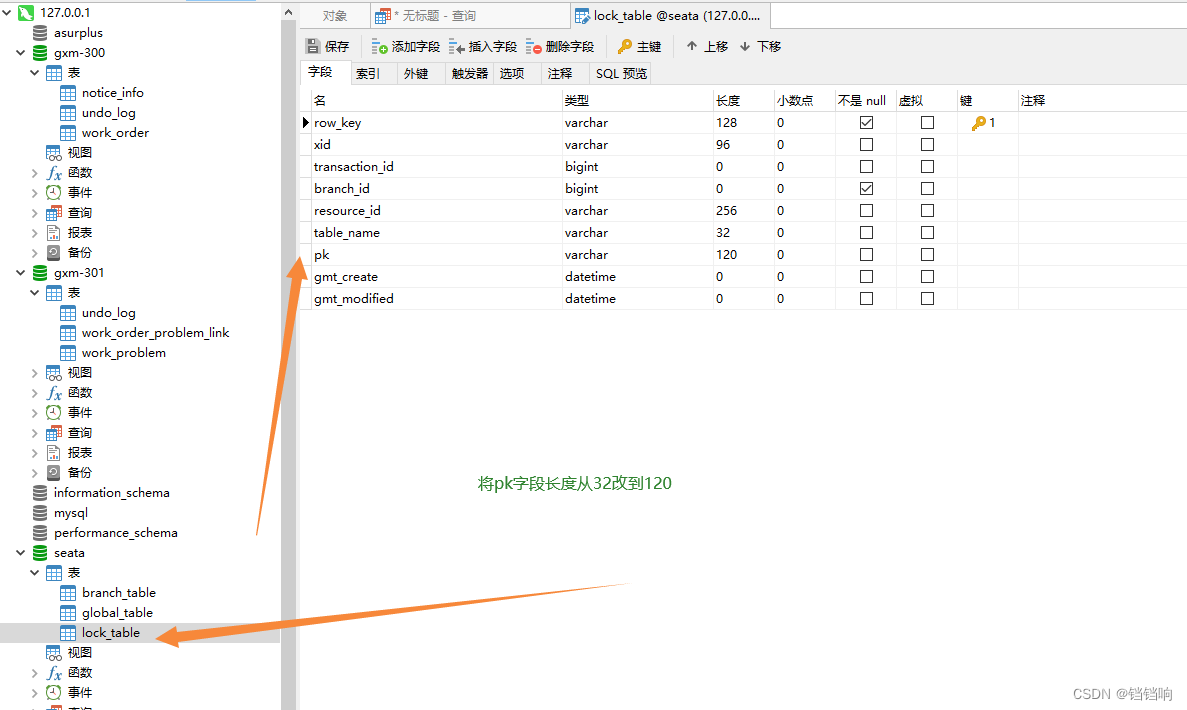
6.3、saga状态机找不到dubbo的bean
1、我们通过 @BubboReference 是可以的,但是状态机执行的时候,找不到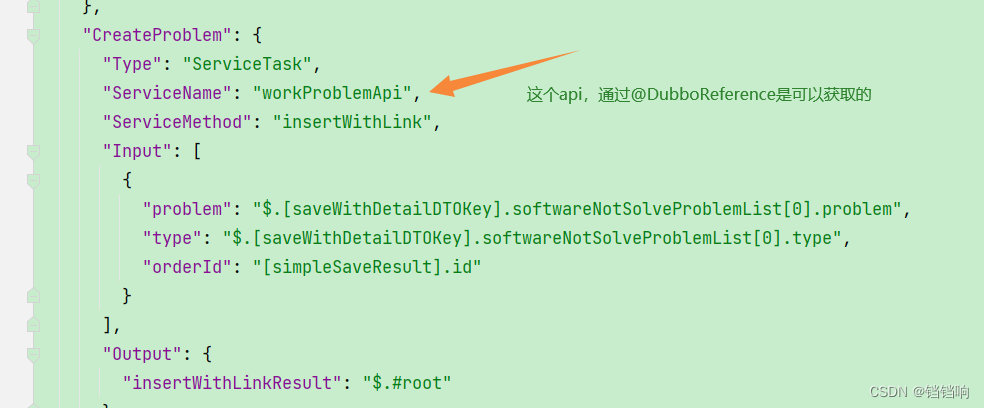
2、原因是因为2.x版本的 dubbo 使用 注解 @DubboReference 时,不会注入到spring 中(@DubboReference 并不是 Spring定义的 Bean,所以不会生成 BeanDefinition ,也就是不会主动 createBean ,只能在属性注入的时候触发),而saga的状态机在读取的 时候要从spring 中获取其他服务的bean,所以这里手动注入一下 具体分析可以看 https://heapdump.cn/article/3610812
3、解决方法就是我们提前手动注入到spring的bean容器中。
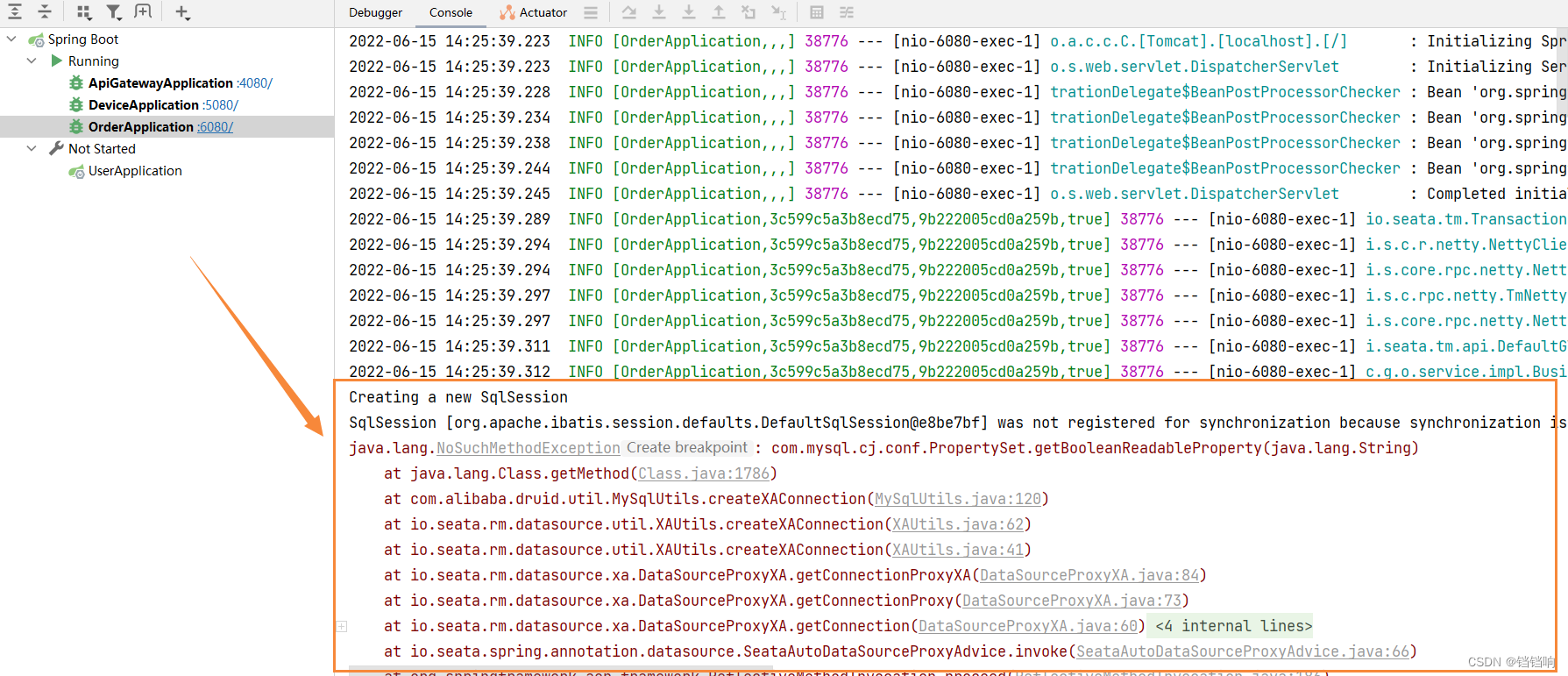
6.4、XA模式下出现 java.lang.NoSuchMethodException: com.mysql.cj.conf.PropertySet.getBooleanReadableProperty(java.lang.String)
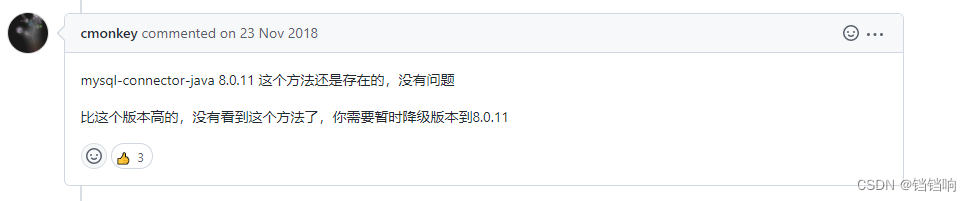
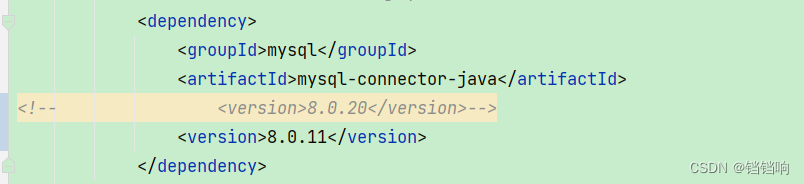
4、这个原因是因为seata默认使用的是DruidDataSource数据库连接池,而DruidDataSource里面的 util 包中的MySqlUtils 类中的createXAConnection 方法,会使用MySQL驱动的getBooleanReadableProperty方法,但是高版本的MySQL驱动中这个方法没有了,所以报错,我这里直接降低MySQL驱动版本即可,将 mysql 驱动包版本切换为8.0.11,在该版本中,getBooleanReadableProperty(String)方法是还存在的。
这个问题,github上面也提出来了,
边栏推荐
- String formatting
- About hzero resource error (groovy.lang.missingpropertyexception: no such property: weight for class)
- Operation method of Orange Pie orangepi 4 lts development board connecting SATA hard disk through mini PCIe
- CAS mechanism
- 1321: [example 6.3] deletion problem (noip1994)
- [detailed explanation of Huawei machine test] tall and short people queue up
- 软考中级,软件设计师考试那些内容,考试大纲什么的?
- 【PyTorch 07】 动手学深度学习——chapter_preliminaries/ndarray 习题动手版
- ThreadLocal会用可不够
- How much review time does it usually take to take the intermediate soft exam?
猜你喜欢
中级软件评测师考什么
![P1031 [noip2002 improvement group] average Solitaire](/img/ba/6303f54d652fa7aa89440e314f8718.png)
P1031 [noip2002 improvement group] average Solitaire
![[daiy5] jz77 print binary tree in zigzag order](/img/ba/b2dfbf121798757c7b9fba4811221b.png)
[daiy5] jz77 print binary tree in zigzag order
Unable to open kernel device '\.\vmcidev\vmx': operation completed successfully. Reboot after installing vmware workstation? Module "devicepoweron" failed to start. Failed to start the virtual machine
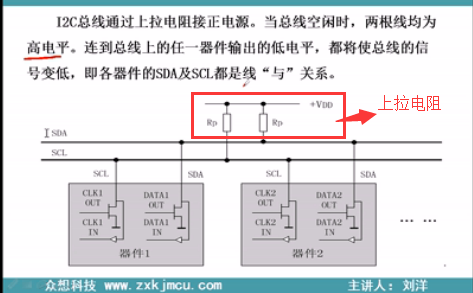
IIC Basics

Simple and easy to modify spring frame components
香橙派OrangePi 4 LTS开发板通过Mini PCIE连接SATA硬盘的操作方法
【STM32】实战3.1—用STM32与TB6600驱动器驱动42步进电机(一)

Multithreaded asynchronous orchestration
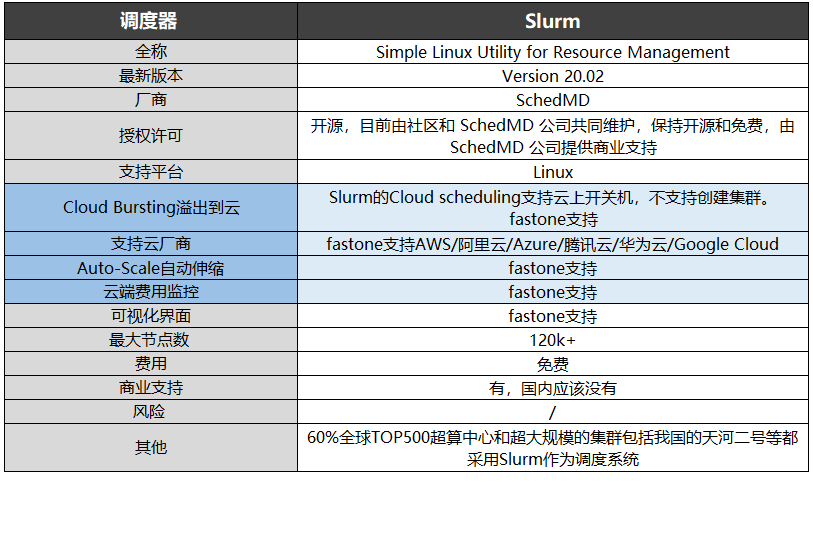
Cluster task scheduling system lsf/sge/slurm/pbs based on HPC scenario
随机推荐
Deep understanding of Apache Hudi asynchronous indexing mechanism
Using tansformer to segment three-dimensional abdominal multiple organs -- actual battle of unetr
ThreadLocal is not enough
软考信息处理技术员有哪些备考资料与方法?
Leetcode-560: subarray with sum K
ThreadLocal会用可不够
Trajectory planning for multi-robot systems: Methods and applications 综述阅读笔记
Typescript interface inheritance
【机器学习 03】拉格朗日乘子法
2022年上半年5月网络工程师试题及答案
Long list performance optimization scheme memo
Five simple and practical daily development functions of chrome are explained in detail. Unlock quickly to improve your efficiency!
[recommendation system 01] rechub
The width of table is 4PX larger than that of tbody
Socket通信原理和实践
施努卡:机器视觉定位技术 机器视觉定位原理
【作业】2022.7.6 写一个自己的cal函数
CAS mechanism
PHP \ newline cannot be output
Hdu-2196 tree DP learning notes