当前位置:网站首页>对word2vec的一些浅层理解
对word2vec的一些浅层理解
2022-07-07 08:14:00 【strawberry47】
最近有朋友问到word2vec是怎么一回事,于是我又复习了一遍相关知识,记录下自己的一些思考,防止遗忘~
word2vec是获取词向量的手段,它是在NNLM基础上改进的。
训练模型本质上是只具有一个隐含层的神经元网络。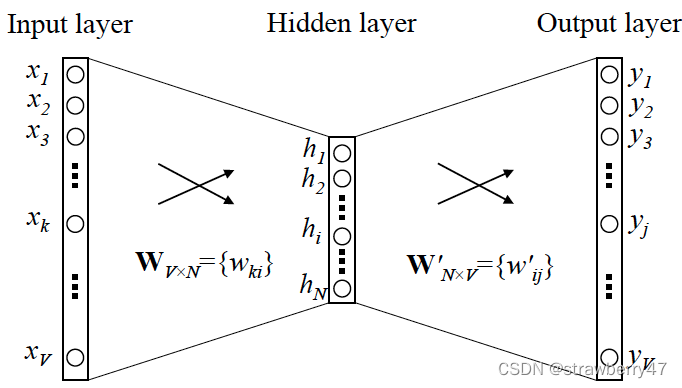
它有两种形式 ① skip-gram:从两边预测中间 ② C-BOW:从中间预测两边;
注意,这两种形式只是代表两种不同的训练方式,最终都是取输入层->隐藏层的权重,作为词向量。
训练时,以CBOW为例,假设语料库是“今天的天气真好”;模型的输入是 "今 天 的 天 真 好"六个单词的one-hot vector,输出是一堆概率,我们希望“气”出现的概率最大。
写代码的时候,通常是调用gensim库,传入语料库就可以训练出词向量了。
一些训练时的小trick:Negative Sampling,哈夫曼树
参考:[NLP] 秒懂词向量Word2vec的本质,总结word2vec(实验室师兄写的博客)
边栏推荐
- Enterprise practice | construction of banking operation and maintenance index system under complex business relations
- Interface test
- Serial communication relay Modbus communication host computer debugging software tool project development case
- 高数_第1章空间解析几何与向量代数_向量的数量积
- Some properties of leetcode139 Yang Hui triangle
- 【acwing】786. Number k
- Study summary of postgraduate entrance examination in September
- 基于HPC场景的集群任务调度系统LSF/SGE/Slurm/PBS
- ArcGIS operation: batch modify attribute table
- Appx代碼簽名指南
猜你喜欢
STM32 ADC和DMA

Experience sharing of software designers preparing for exams
mysql插入数据创建触发器填充uuid字段值
【acwing】786. Number k
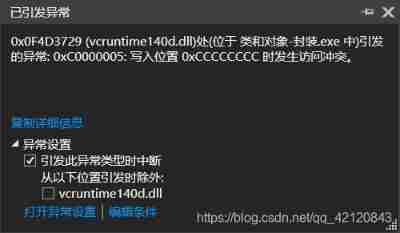
0x0fa23729 (vcruntime140d.dll) (in classes and objects - encapsulation.Exe) exception thrown (resolved)
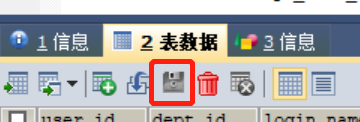
How to cancel automatic saving of changes in sqlyog database
![[ORM framework]](/img/72/13eef38fc14d85978f828584e689a0.png)
[ORM framework]
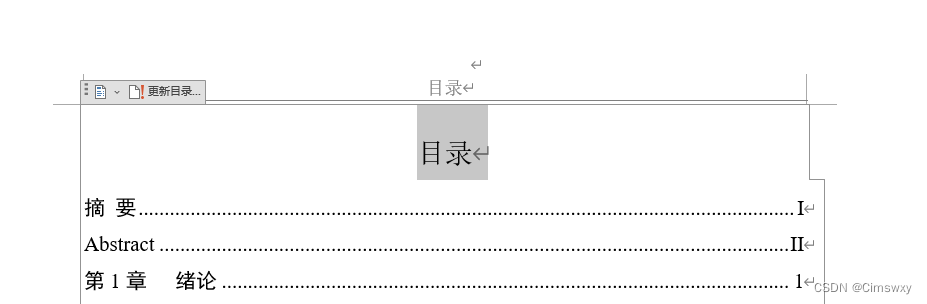
Word自动生成目录的方法
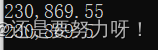
字符串格式化
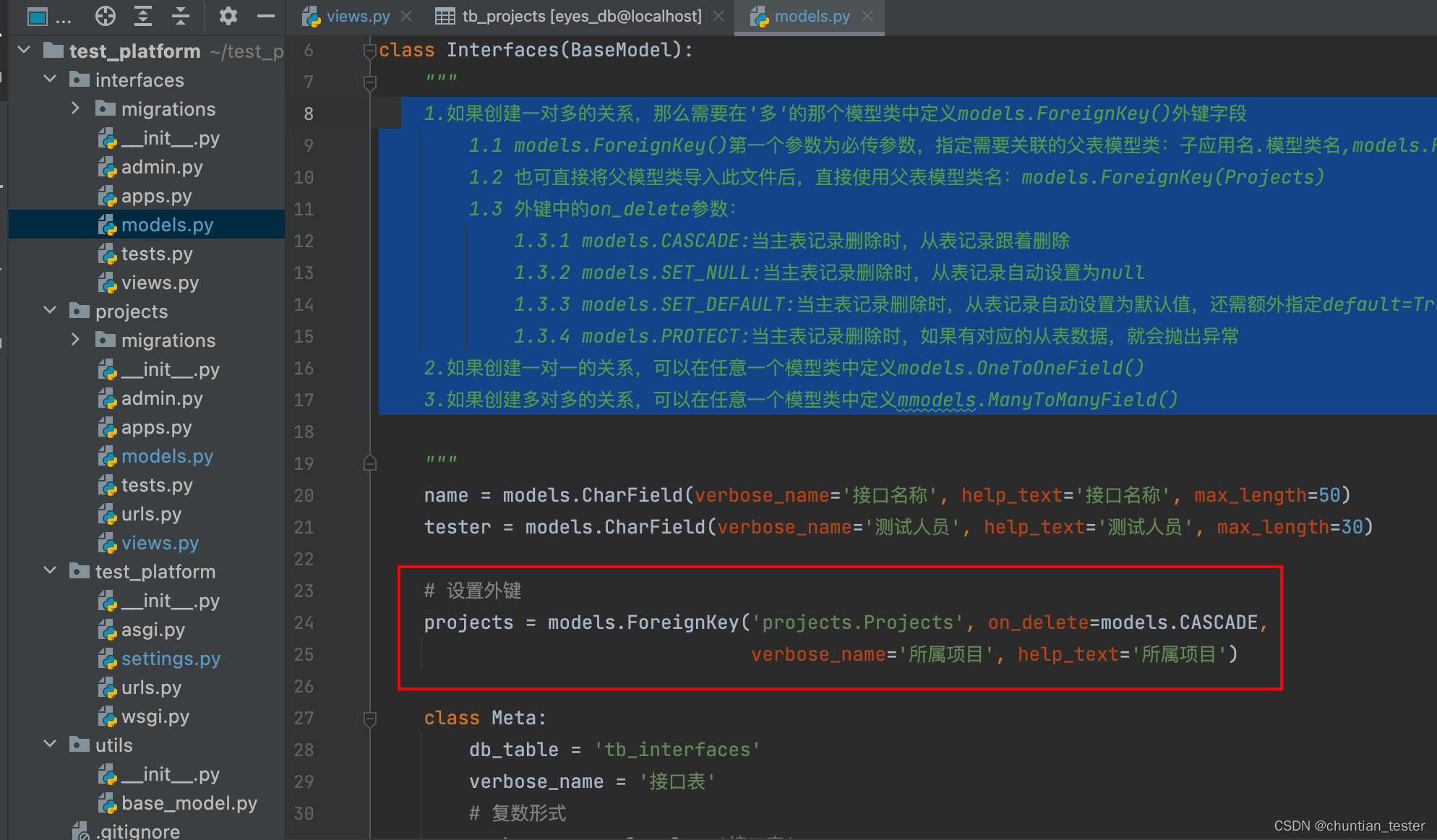
ORM -- query type, association query
随机推荐
Slurm资源管理与作业调度系统安装配置
SQLyog数据库怎么取消自动保存更改
Deadlock caused by non clustered index in SQL Server
Some test points about coupon test
LLVM之父Chris Lattner:为什么我们要重建AI基础设施软件
1324:【例6.6】整数区间
Some thoughts on the testing work in the process of R & D
XML configuration file parsing and modeling
The landing practice of ByteDance kitex in SEMA e-commerce scene
Parameter sniffing (2/2)
IPv4套接字地址结构
JMeter loop controller and CSV data file settings are used together
Use the fetch statement to obtain the repetition of the last row of cursor data
Guid主键
[learning notes - Li Hongyi] Gan (generation of confrontation network) full series (I)
ISP、IAP、ICP、JTAG、SWD的编程特点
Download Text, pictures and ab packages used by unitywebrequest Foundation
Guid primary key
Several schemes of building hardware communication technology of Internet of things
Why is the reflection efficiency low?