当前位置:网站首页>【HigherHRNet】 HigherHRNet 详解之 HigherHRNet的热图回归代码
【HigherHRNet】 HigherHRNet 详解之 HigherHRNet的热图回归代码
2022-07-07 07:49:00 【大黑山修道】
相关系列链接:
前言:
HigherHRNet 来自于CVPR2020的论文:
HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation。
论文主要是提出了一个自底向上的2D人体姿态估计网络–HigherHRNet。
该论文代码成为自底向上网络一个经典网络,CVPR2021年最先进的自底向上网络DEKR和SWAHR都是基于HigherHRNet的源码上进行的局部改进。
所以搞懂HigherHRNet 对2020~2021的自底向上的人体姿态估计论文研究很有帮助。
相关资料:
HigherHRNet 论文地址:
https://arxiv.org/abs/1908.10357
代码地址:
https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation
HigherHRNet网络代码讲解
主体模型代码:位于项目目录中:
HigherHRNet-Human-Pose-Estimation/lib/models/pose_higher_hrnet.py
目录
1. 主体框架
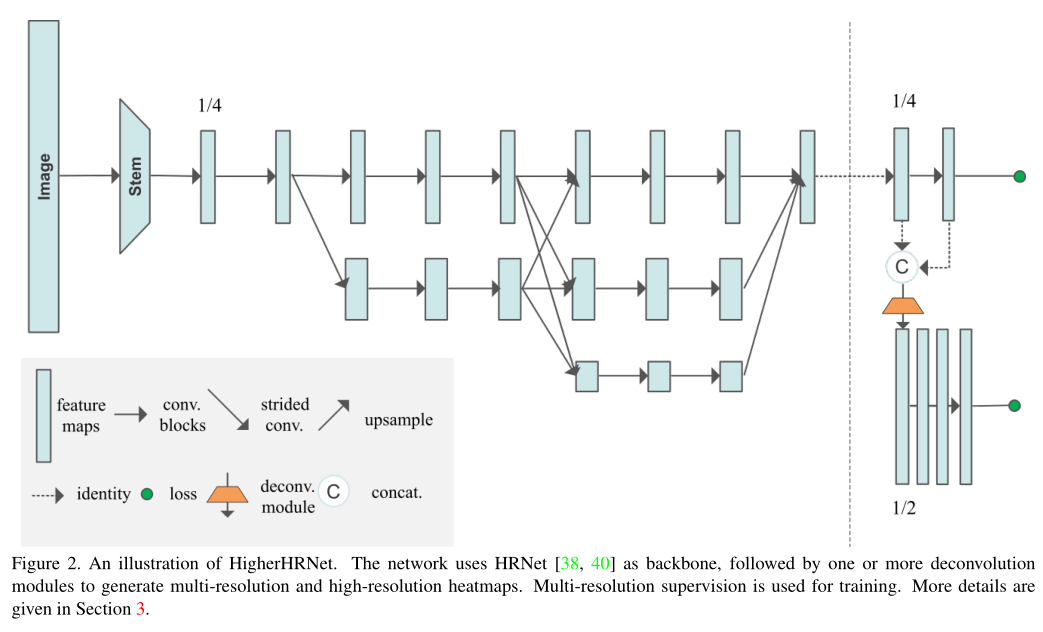
整个热图回归网络的主干网络还是HRNet,熟悉HRNet的人就会很容易理解HigherHRNet。
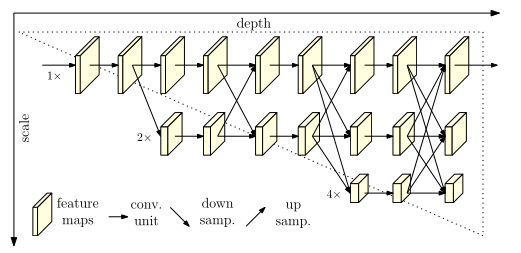
HRNet论文中的配图
这里简单介绍一下HRNet,这是来自CVPR2019年的论文:Deep High-Resolution Representation Learning for Human Pose Estimation。非常经典,从这篇论文开始直到至今(2022),基本上所有刷榜的2D姿态估计论文都会以HRNet作为主干网络,而之前的论文主要以ResNet为主。2D姿态估计任务上采用HRNet主干网普遍都会比ResNet主干网高数个百分点。
HigherHRNet网络采用两个尺寸:512和640。裁剪为512×512相比于640×640图像尺寸变小,这意味着占用的显存减小,模型参数量减小,训练和推理速度变快,检测精度降低。
(为什么HRNet采用的尺寸256×192和384×288,而HigherHRNet采用512×512和640×640?原因在于HRNet是自上而下,先检测出人,然后将roi区域再对单人进行姿态估计,图像尺寸可以减小,因为HRNet只是检测全图的一部分区域,且输出尺寸接近于人体长宽比例;
而HigherHRNet是自下而上的,全对全图进行关键点检测,然后再针对这些关键点进行分组。HigherHRNet检测全图,所以网络需要训练较大尺寸,且长宽比相等。)
然后我们从图片输入到这个模型进行介绍,其中的2,3,4,5部分的介绍是HRNet的部分,熟悉的同学可以直接跳过,直接看6部分。
这里跳转
2. Steam部分代码
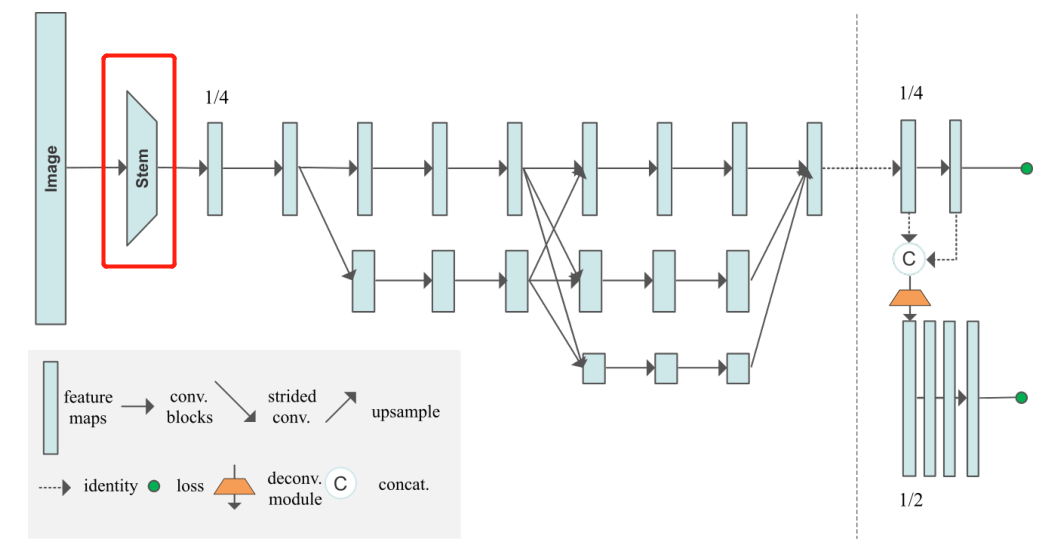
图像输入进网络的shape:[b,3,512,512],分别代表batchsize, 图像通道数(3通道), width, height。
通过steam可以从图像得到经历数次卷积相关操作初始特征图:
带有注释的代码,首先看forward函数:
# 1. 初始阶段的2重(conv+bn),输入3通道,输出64通道,单支路。
# 经过一系列的卷积, 获得初步特征图,总体过程为x[b,3,512,512]-->x[b,64,128,128]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
卷积相关操作定义:
# 进行一系列的卷积操作,获得最初始的特征图N11
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1,
bias=False)
self.bn1 = nn.BatchNorm2d(64, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1,
bias=False)
self.bn2 = nn.BatchNorm2d(64, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self._make_layer(Bottleneck, 64, 4)
我们画图可以得到: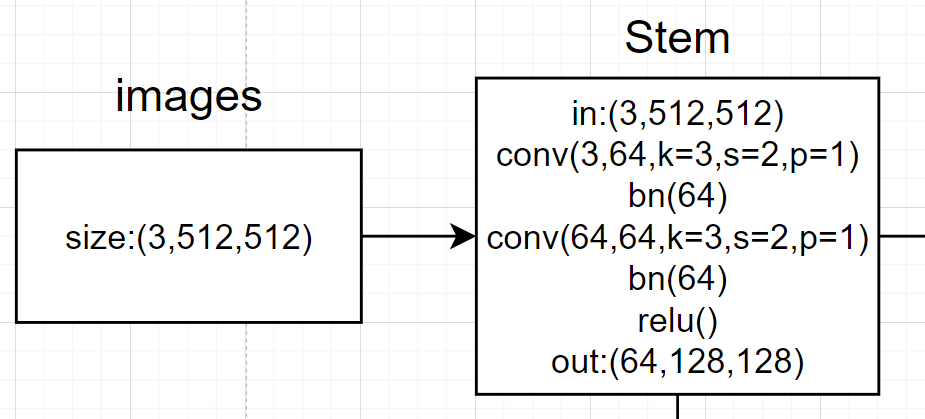
3. HRNet模型中stage的设计思想
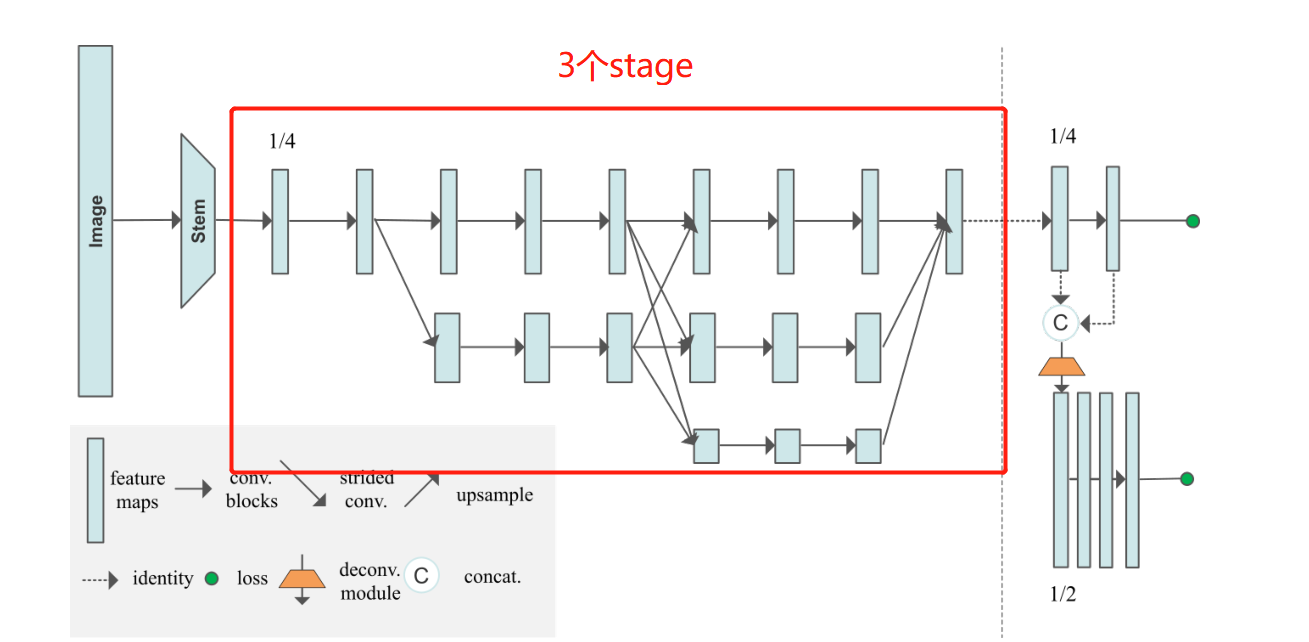
这部分是HRNet的精髓,也是最难理解的部分。理解这一部分,基本可以理解整个HRNet网络了。为了更好地理解,我们必须先看懂这个图,了解相关的潜在信息。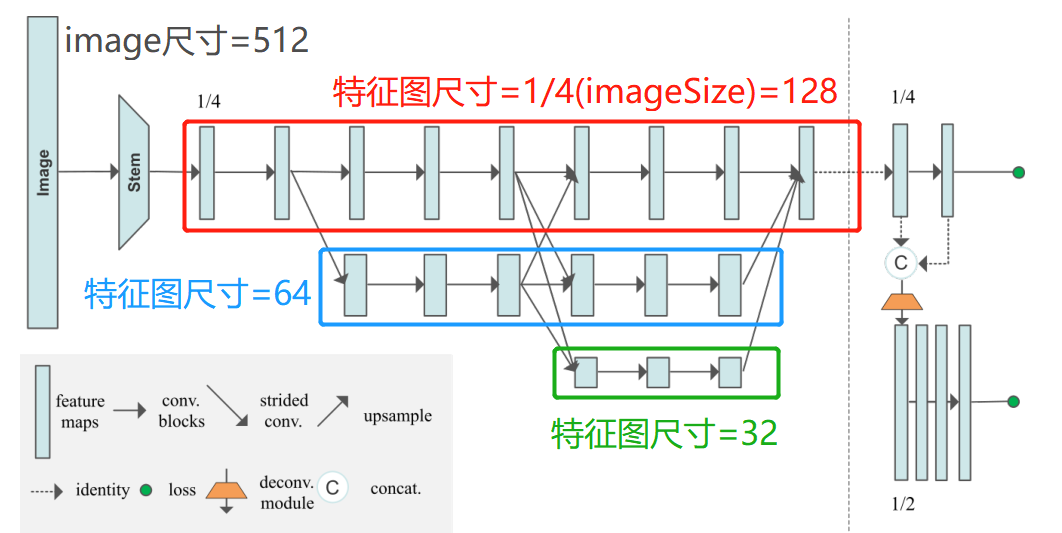
在HRNet的核心部分,每一行上所画的tensor的shape都是一样的。可以看出网络图下面一层的支路会比上面一层的支路尺寸(shape的后两位)减少一半,而特征通道数(shape的第2位会增加一倍)。概括一下,越往下,特征图分辨率越低。图像中的矩形块的高表示
然后介绍一下HRNet的核心思想,就是再整个网络中都能维持高分辨率的特征。意思就是在整个模型的始末,高分辨率的特征始终发挥作用。我们看一下HRNet之前的做法就能很好理解了。
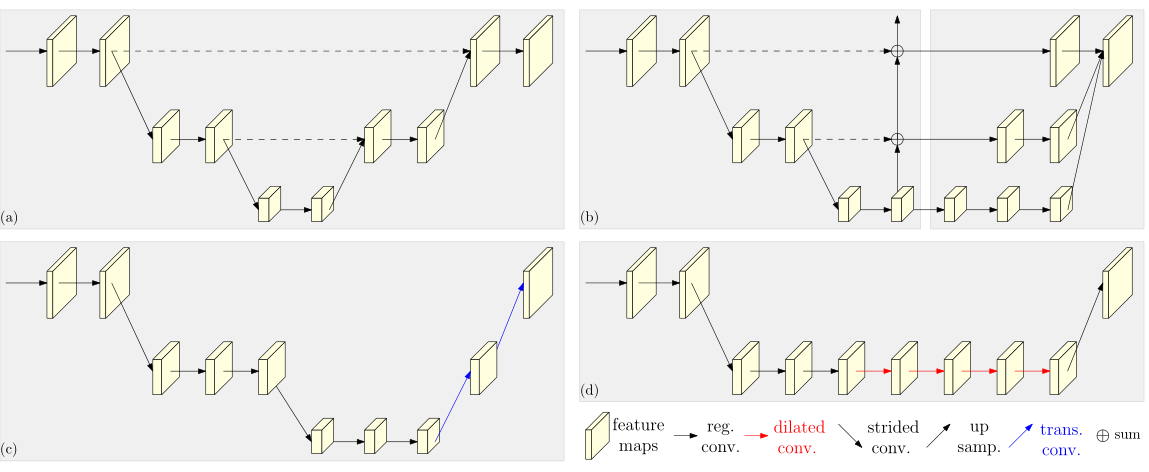
HRNet总结了以往的模型中操作,特征图都是先不断卷积操作减少分辨率,然后不断上采样(upsample)提高分辨率,但是在此过程中很多重要信息丢失。因此,HRNet可以通过不断交叉的相加的方式保持高分辨率的特征。
然后HRNet的操作可以概括为执行了多少次stage。每一次的make_stage包括以下几个环节:残差块计算,支路之间交叉计算fuse_layer(最后一个stage除外),添加新支路操作transition_layer(最后一个stage除外)。
还是画图理解,思路理解了,代码才容易理解。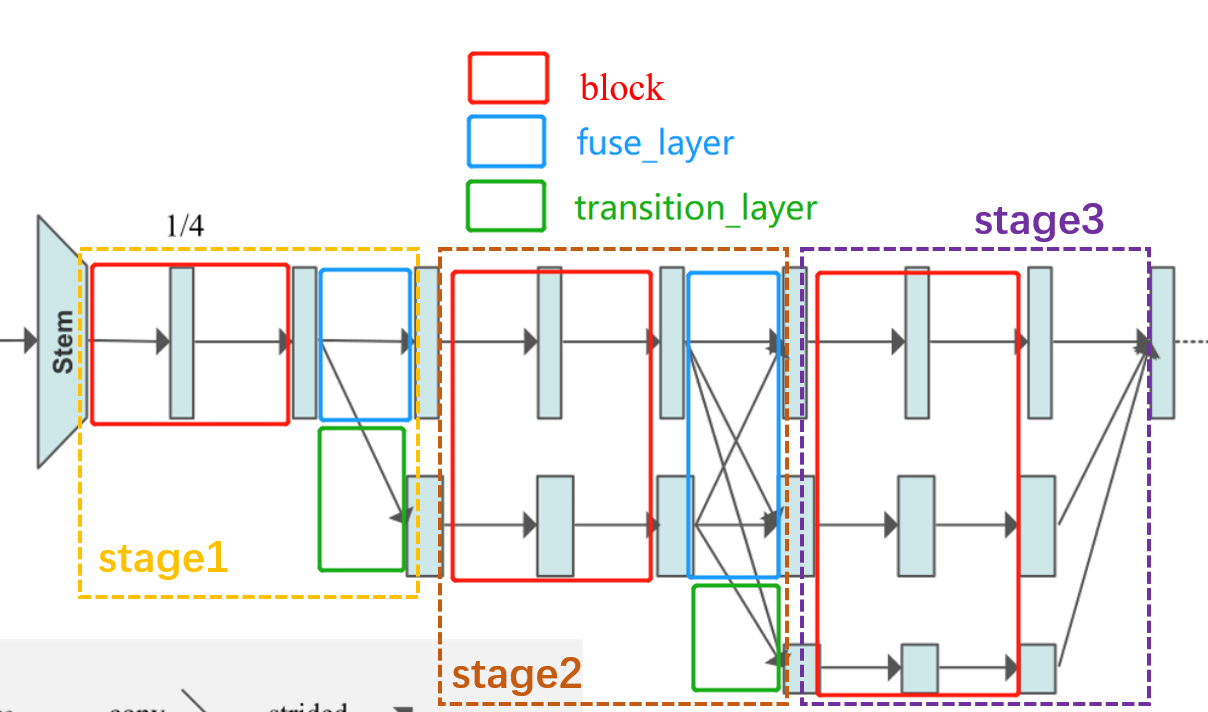
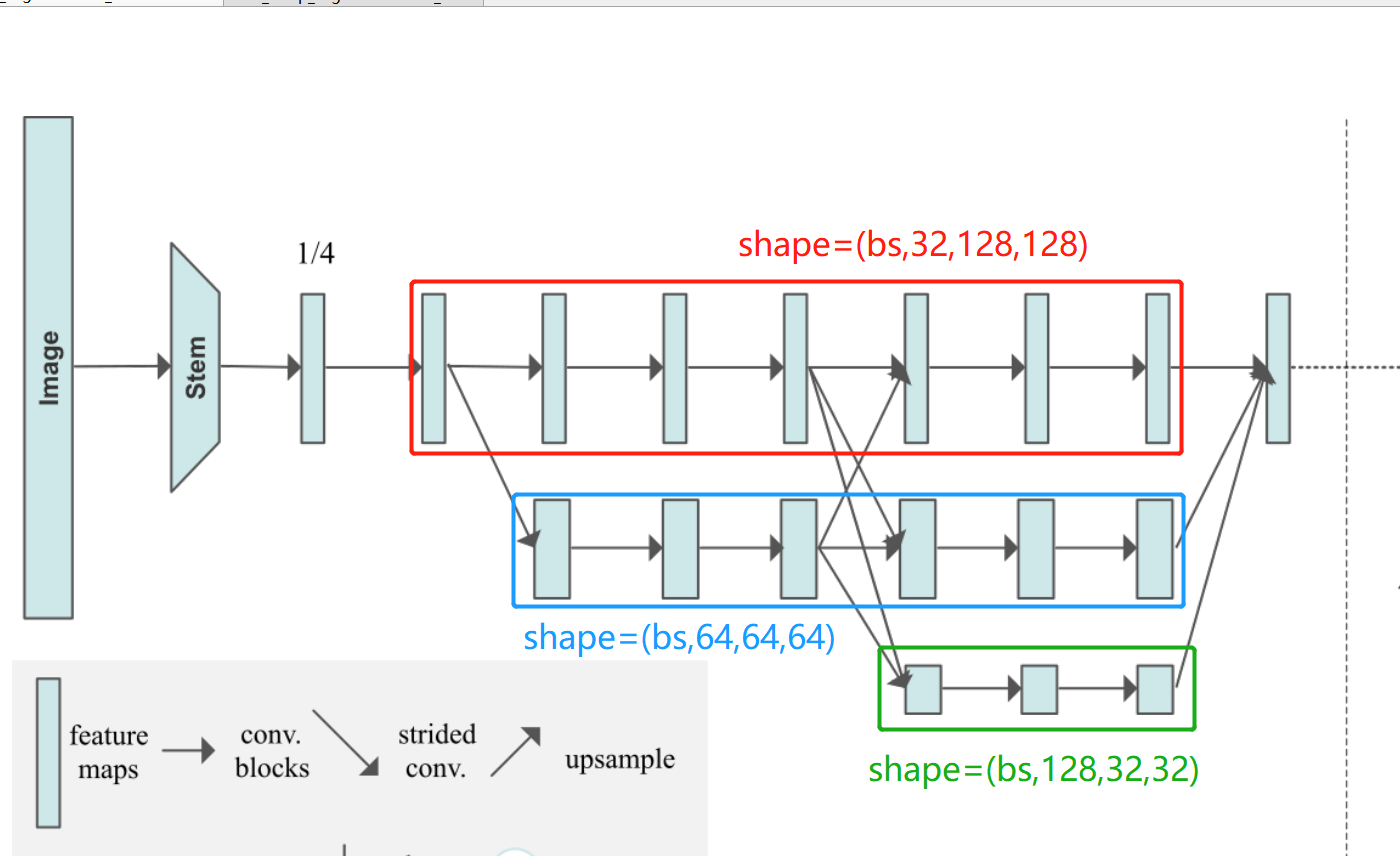
从图中可以清晰看出,除了最后一个stage,其他的stage都是由3个模块组成:
block:如红色框所示 经过数个残差块计算,但输入和输出的tensor的shape不变。
在stage1的时候使用bottleneck残差块,且特征图的通道数增多: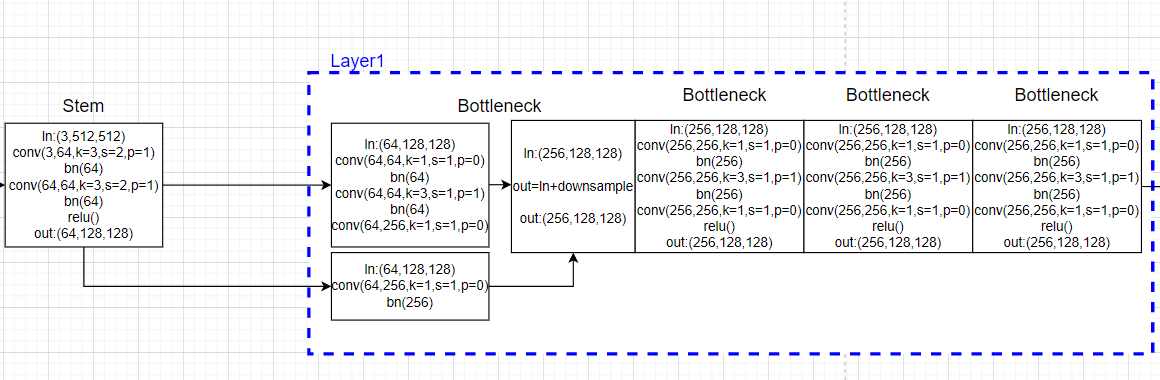
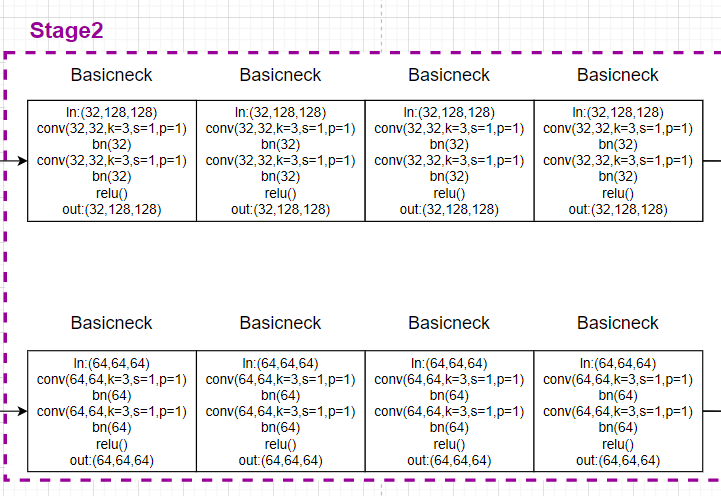
在后面的stage则使用basicneck残差块,输入和输出一致:
fuse_layer: 如蓝色框所示 ,网络中的每个特征图交错相加,当低分辨率的特征图与高分辨率特征图相加生成高分辨率的特征图时,会对低分辨率的特征图进行上采用以增大其分辨率;同理,当低分辨率的特征图与高分辨率特征图相加生成低分辨率的特征图时,会对高分辨率特征图进行卷积操作以降低其分辨率。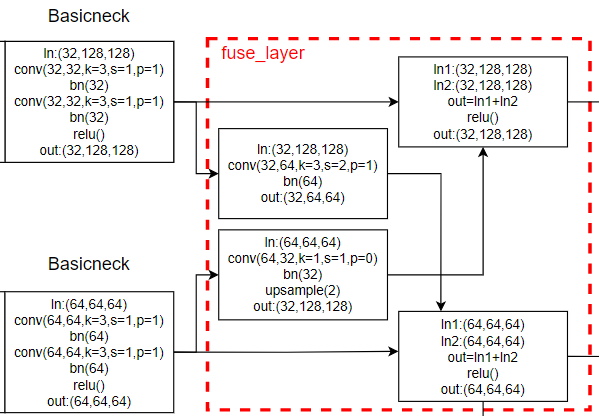
transition_layer:如绿色框所示,就是往下生成一个新的支路,他的分辨率继续减半,特征通道继续加倍。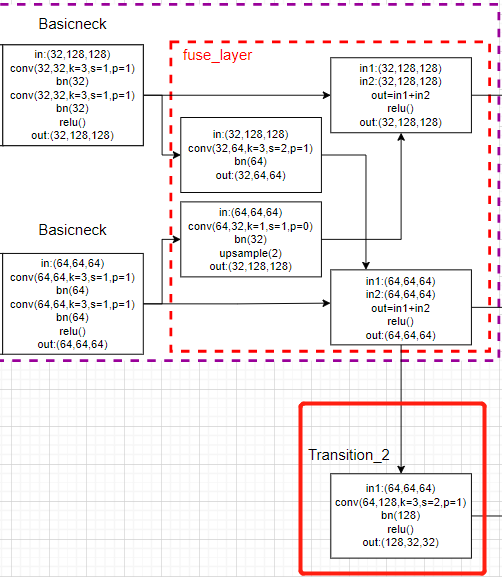
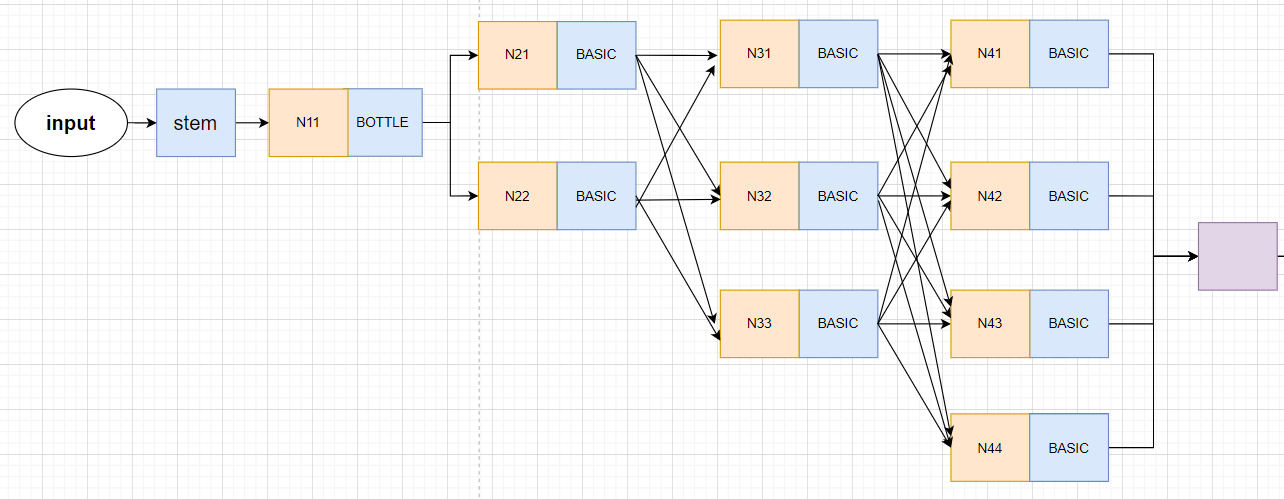
注意:HigherHRNet的网络结构与它画出的模型并不是完全一致的!!!画出的模型只有3个stage和3条支路,而HigherHRNet的实际模型是由4个stage,4条支路的。
画了以下简图,大致是这样的,Nxx表示生成的特征图,并不表示什么操作。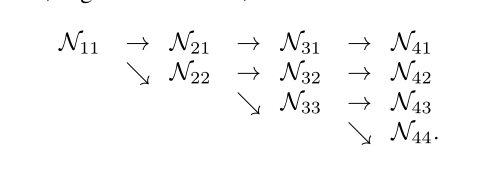
HRNet的论文也是画了3个stage的模型图,然后网络模型确实也是3stage的,因为网络输入的尺寸小。输入image的尺寸为256×192,则第一层支路的尺寸为64×48,第二层支路为32×24,第三层支路为16×12,如果设置为4个stage,则第4层支路的尺寸过小。
而HigherHRNet是自下而上的方法,输入的尺寸为512×512,则第一层支路的尺寸为128×128,第二层支路为64×64,第三层支路为32×32,第四层支路为16×16。所以需要4stage的HRNet网络。
4. HRNet主干网中stage的代码实现
在前面一部分,image通过steam层,生成了初始特征图: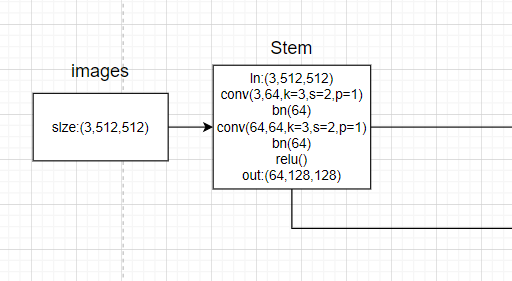
4.1 第一个stage:
首先就是block部分,也就是下图红框内部分: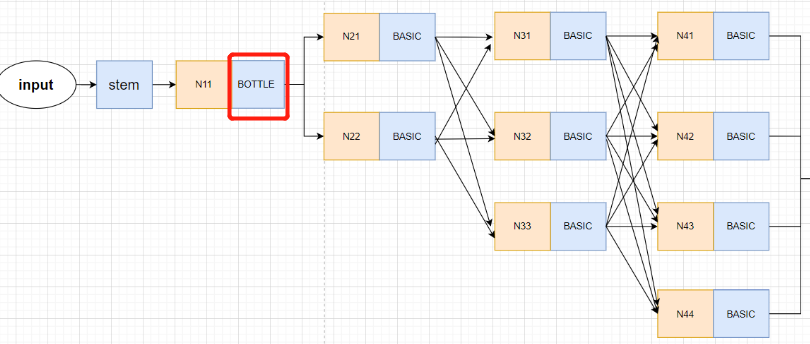
首先看forward代码:
# 2. 经历4次bottleneck模块,输入64通道,输出256通道,单支路。
# [b,256,64,48]-->x[b, 256, 128, 128]
x = self.layer1(x)
定义部分:
self.layer1 = self._make_layer(Bottleneck, 64, 4)
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion, momentum=BN_MOMENTUM),
)
layers = []
# 0: self.inplanes=64, planes=64, stride=1
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes)) # 256, 64
return nn.Sequential(*layers)
这部分代码绘图: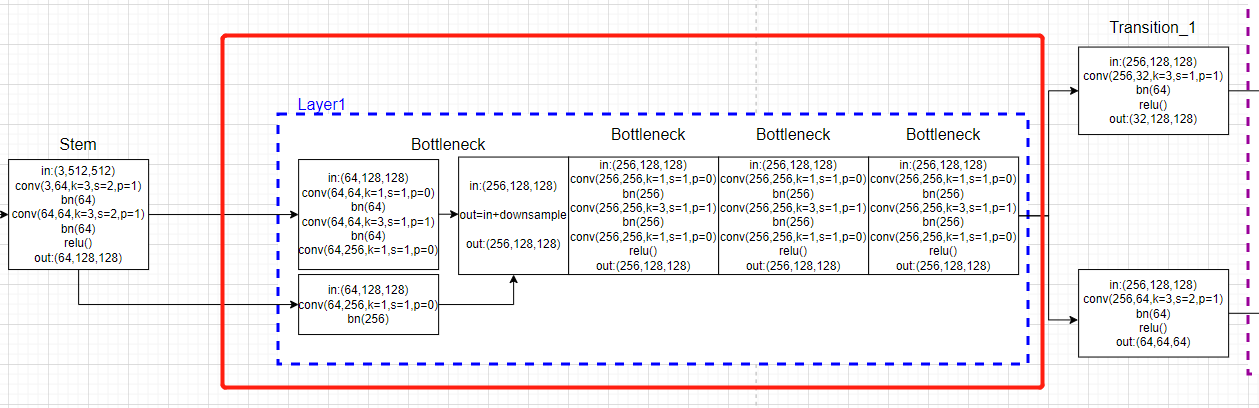
然后第一个stage只有交叉计算,不需要进行fuse_layer交叉计算。
所以直接进行生成新支路的transition_layer操作,也就是下图红框内部分: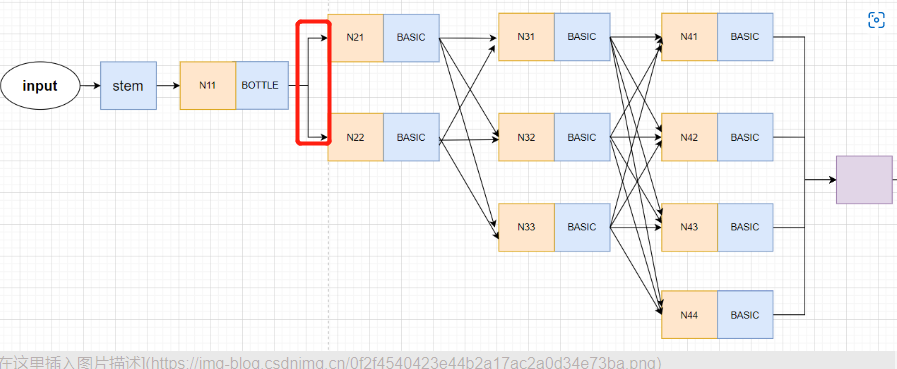
forward代码:
x_list = []
# 3. 分别经历1次(conv+bn),形成二支路。输入256通道,输出[32,64]通道,双支路。
# 对应论文中的stage2
# 其中包含了创建分支的过程,即 N11-->N21,N22 这个过程
# N22的分辨率为N21的二分之一,总体过程为:
# x[b,256,128,128] ---> y[b, 32, 128, 128] 因为通道数不一致,通过卷积进行通道数变换
# y[b, 64, 128, 128] 通过新建平行分支生成
for i in range(self.stage2_cfg['NUM_BRANCHES']):
if self.transition1[i] is not None:
x_list.append(self.transition1[i](x))
else:
x_list.append(x)
init部分:
# 这里会生成新的平行分N2支网络,即N11-->N21,N22这个过程
# 同时会对输入的特征图x进行通道变换(如果输入输出通道书不一致)
self.transition1 = self._make_transition_layer([256], num_channels) # _make_transition_layer([256],[32,64])
定义函数过长,后面就不放了,在代码里跳转着看。。。。
对应的模型画图: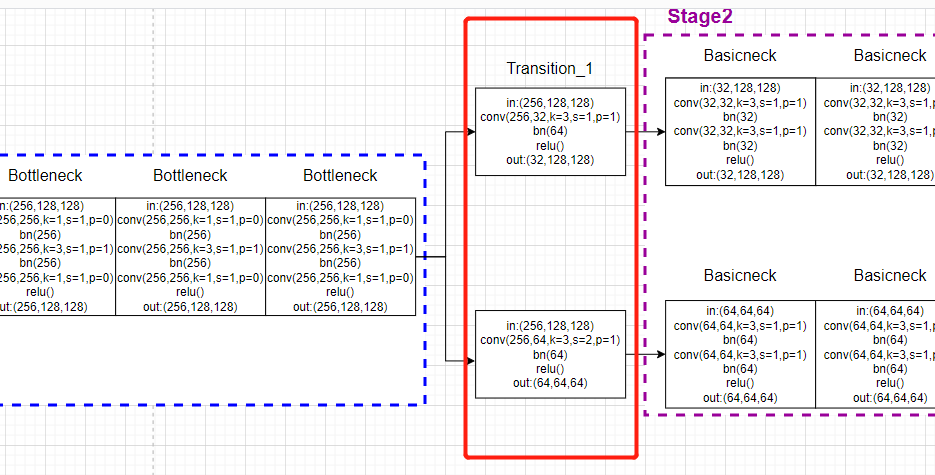
4.2 第二个stage:
主要就是第一个stage和最后一个stage比较特殊外,其他的都非常具有规律性。
后面所有的stage的block模块和fuse_layer都被放到了一个函数内。
forword代码:
# 4. 输入:第1支路32通道,经过4次basicneck共8(conv+bn),输出tmp11; 输入:第2支路32通道,经过4次basicneck共8(conv+bn),输出tmp22;
# 融合卷积,输入第1支路32通道,经过1(conv+bn)输出64通道tmp12;输入第2支路64通道,经过1(conv+bn),upsample,输出32通道,输出tmp21
# 最后,x1=tmp11+tmp21,通道32;x2=tmp12+tmp22,通道64;x_list = [32,64]
# 总体过程如下(经过一些卷积操作,但是特征图的分辨率和通道数都没有改变):
# x[b, 32, 128, 128] ---> y[b, 32, 128, 128]
# x[b, 64, 64, 64] ---> y[b, 64, 64, 64]
y_list = self.stage2(x_list)
init部分:
# 对平行子网络进行加工,让其输出的y,可以当作下一个stage的输入x,
# 这里的pre_stage_channels为当前stage的输出通道数,也就是下一个stage的输入通道数
# 同时平行子网络信息交换模块,也包含再其中
self.stage2, pre_stage_channels = self._make_stage(
self.stage2_cfg, num_channels)
然后再_make_stage函数里,会生成一个class
def _make_stage(self, layer_config, num_inchannels,
multi_scale_output=True):
num_modules = layer_config['NUM_MODULES'] #
num_branches = layer_config['NUM_BRANCHES']
num_blocks = layer_config['NUM_BLOCKS']
num_channels = layer_config['NUM_CHANNELS']
block = blocks_dict[layer_config['BLOCK']]
fuse_method = layer_config['FUSE_METHOD']
modules = []
for i in range(num_modules):
# multi_scale_output is only used last module
if not multi_scale_output and i == num_modules - 1:
reset_multi_scale_output = False
else:
reset_multi_scale_output = True
modules.append(
HighResolutionModule(
num_branches,
block,
num_blocks,
num_inchannels, # [32, 64, 128]
num_channels, # [32, 64, 128]
fuse_method,
reset_multi_scale_output)# false
)
num_inchannels = modules[-1].get_num_inchannels() #
return nn.Sequential(*modules), num_inchannels
我们跳转的到HighResolutionModule的forward函数:
这部分就是block模块
def forward(self, x):
if self.num_branches == 1:
return [self.branches[0](x[0])]
for i in range(self.num_branches):
x[i] = self.branches[i](x[i])
对应的模型画图: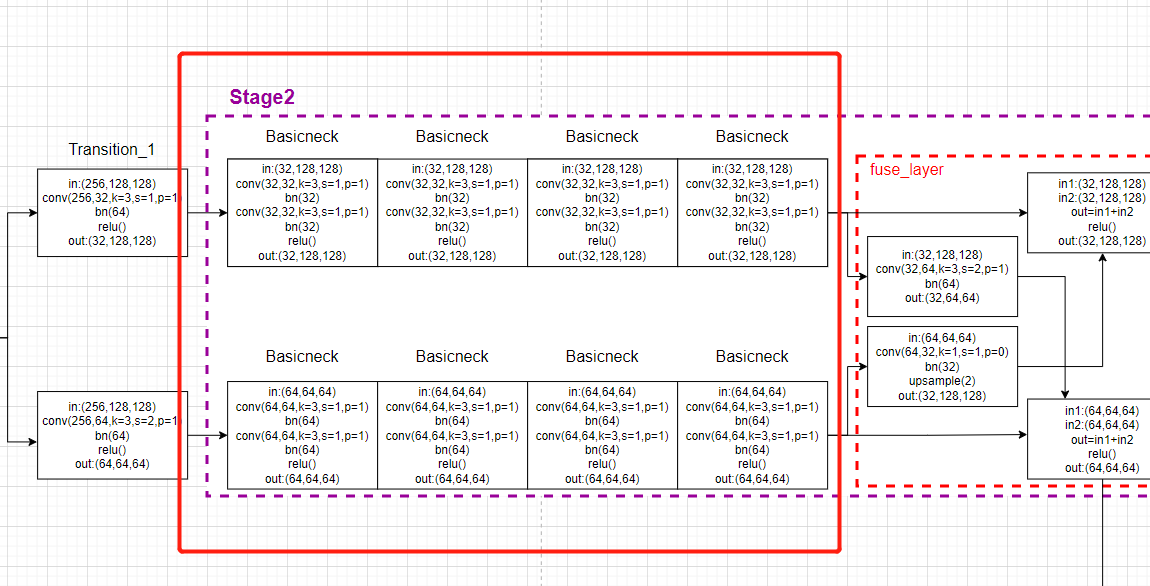
然后forward函数的后半部分就是fuse_layer模块:
x_fuse = []
for i in range(len(self.fuse_layers)):
y = x[0] if i == 0 else self.fuse_layers[i][0](x[0])
for j in range(1, self.num_branches):
if i == j:
y = y + x[j]
else:
y = y + self.fuse_layers[i][j](x[j])
x_fuse.append(self.relu(y))
return x_fuse
对应的模型画图: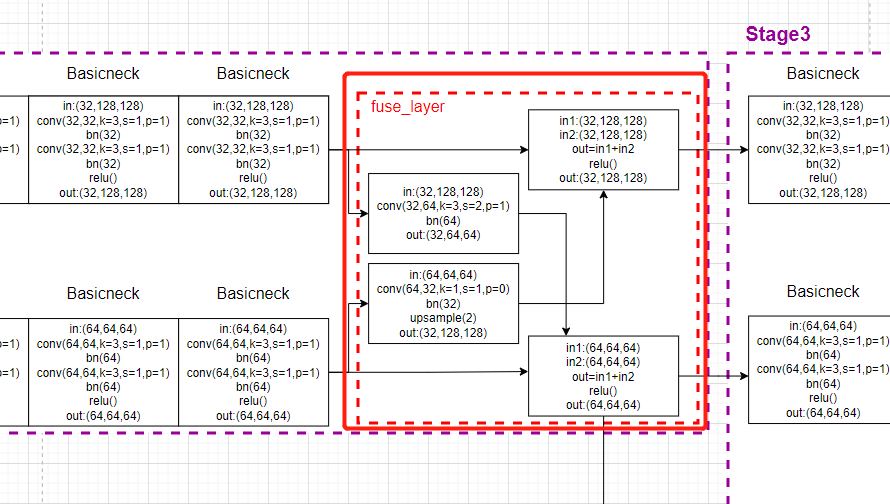
然后最后一个模块transition_layer在主体模型的forward函数内:
x_list = []
# 5. 输入:第2支路64通道,1(conv+bn);输出:第3支路128通道,模型共三支路
# 其中包含了创建分支的过程,即 N22-->N32,N33 这个过程
# N33的分辨率为N32的二分之一,
# y[b, 32, 128, 128] ---> x[b, 32, 128, 128] 因为通道数一致,没有做任何操作
# y[b, 64, 64, 64] ---> x[b, 64, 64, 64] 因为通道数一致,没有做任何操作
# x[b, 128, 32, 32] 通过新建平行分支生成
for i in range(self.stage3_cfg['NUM_BRANCHES']):
if self.transition2[i] is not None:
x_list.append(self.transition2[i](y_list[-1]))
else:
x_list.append(y_list[i])
x_list存储的就是各个支路的特征图。
对应的模型画图: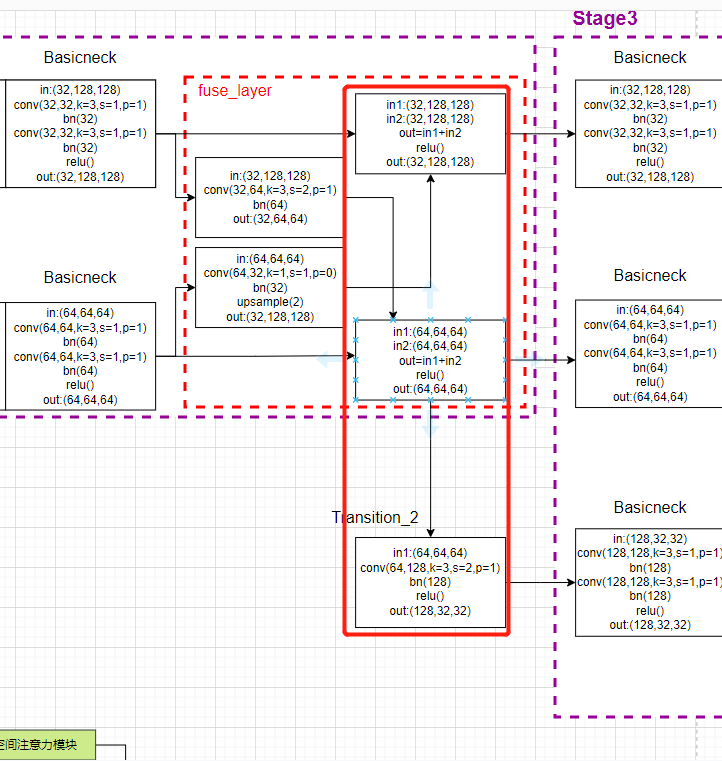
4.3 第三个stage:
和第二个stage一样的规则,只不过支路的数量增加,x_list的元素量增多,会导致遍历的时候计算量大幅上升,复杂度大幅上升。
首先看模型的forward函数:
# 6. 输入:第1支路32通道,经过4次basicneck共8(conv+bn),输出tmp11; 输入:第2支路32通道,经过4次basicneck共8(conv+bn),输出tmp22;
# 第3支路128通道,经过4次basicneck共8(conv + bn),输出tmp33;
# 融合卷积,输入第1支路32通道,经过1(conv+bn)输出64通道tmp12; 输入第1支路32通道,经过2(conv+bn)输出128通道tmp13
# 输入第2支路64通道,经过1(conv+bn),upsample(2),输出32通道,输出tmp21; 输入第2支路64通道,经过1(conv+bn)输出128通道tmp23
# 输入第3支路128通道,经过1(conv+bn),upsample(4),输出32通道,输出tmp31;输入第3支路128通道,经过1(conv+bn),upsample(2),输出642通道,输出tmp31;
# 最后,x1=tmp11+tmp21+tmp31,通道32;x2=tmp12+tmp22+tmp32,通道64; x3=tmp13+tmp23+tmp33,通道128; x_list = [32,64,128]
# 总体过程如下(经过一些卷积操作,但是特征图的分辨率和通道数都没有改变):
# x[b, 32, 128, 128] ---> x[b, 32, 128, 128]
# x[b, 32, 64, 64] ---> x[b, 32, 64, 64]
# x[b, 64, 32, 32] ---> x[b, 64, 32, 32]
y_list = self.stage3(x_list)
self.stage3(x_list)部分就是包含了block模块和fuse_layer模块,具体与上一部分调用的函数一致。
init部分:
self.stage3, pre_stage_channels = self._make_stage(
self.stage3_cfg, num_channels)
整个stage3对应的模型画图: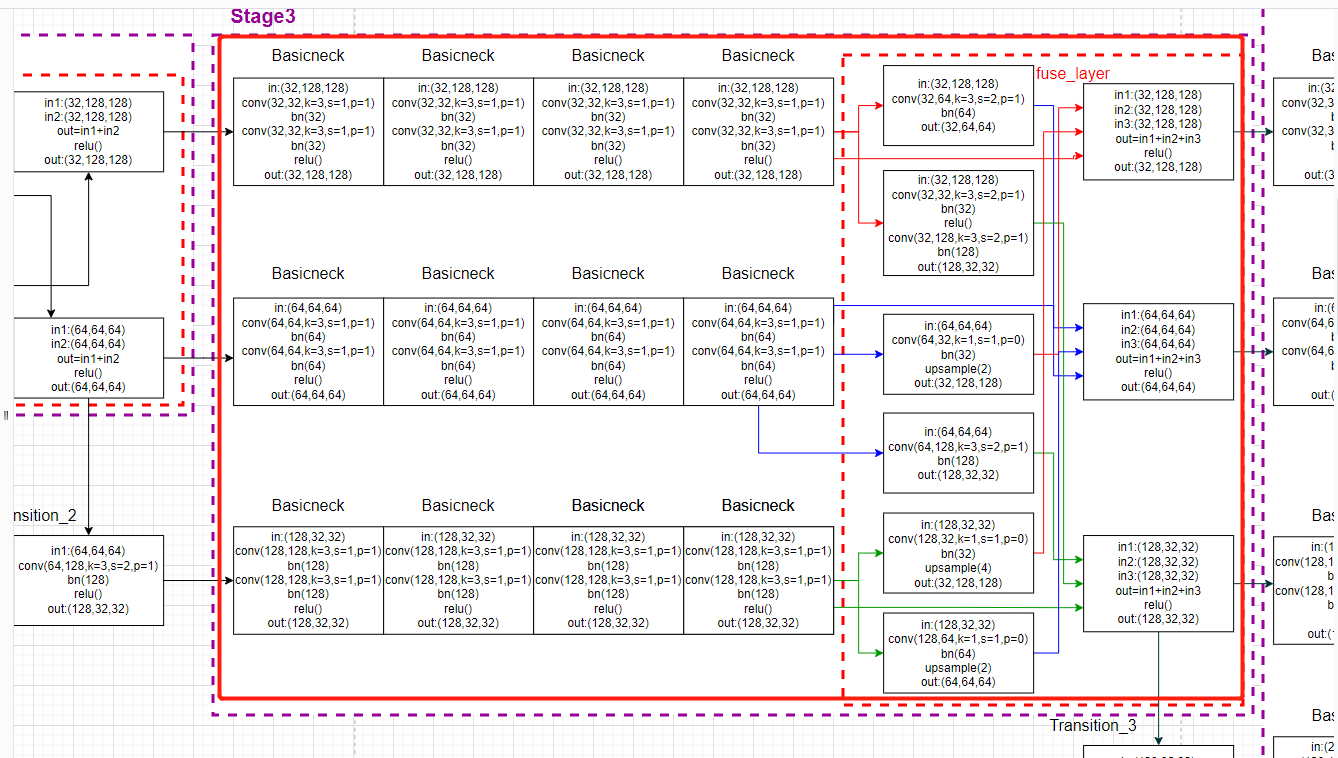
然后最后一个模块transition_layer在forward函数内的代码:
x_list = []
# 7. 新增支路:输入:第3支路128通道,1(conv+bn);输出:第4支路256通道,模型共四支路
# 其中包含了创建分支的过程,即 N33-->N43,N44 这个过程
# N44的分辨率为N43的二分之一
# y[b, 32, 128, 128] ---> x[b, 32, 128, 128] 因为通道数一致,没有做任何操作
# y[b, 64, 64, 64] ---> x[b, 64, 64, 64] 因为通道数一致,没有做任何操作
# y[b, 128, 32, 32] ---> x[b, 128, 32, 32] 因为通道数一致,没有做任何操作
# x[b, 256, 16, 16] 通过新建平行分支生成
for i in range(self.stage4_cfg['NUM_BRANCHES']):
if self.transition3[i] is not None:
x_list.append(self.transition3[i](y_list[-1]))
else:
x_list.append(y_list[i])
4.3 第四个stage:
前面的block模块和fuse_layer模块规则还是一样。
首先看模型的forward函数:
# 8.输入:第1支路32通道,经过4次basicneck共8(conv+bn),输出tmp11; 输入:第2支路32通道,经过4次basicneck共8(conv+bn),输出tmp22;
# 第3支路128通道,经过4次basicneck共8(conv + bn),输出tmp33; 第4支路256通道,经过4次basicneck共8(conv + bn),输出tmp44;
# 融合卷积,输入第1支路32通道,经过1(conv+bn)输出64通道tmp12; 输入第1支路32通道,经过2(conv+bn)输出128通道tmp13;
# 输入第1支路32通道,经过3(conv+bn)输出256通道tmp14;
# 输入第2支路64通道,经过1(conv+bn),upsample(2),输出32通道tmp21;输入第2支路64通道,经过1(conv+bn),输出128通道tmp23;
# 输入第2支路64通道,经过2(conv+bn),输出256通道tmp24;
# 输入第3支路128通道,经过1(conv+bn),upsample(4),输出32通道tmp31;输入第3支路128通道,经过1(conv+bn),upsample(2),输出64通道tmp32;
# 输入第3支路128通道,经过1(conv+bn),输出256通道tmp34;
# 输入第4支路256通道,经过1(conv+bn),upsample(8),输出32通道tmp41;输入第4支路256通道,经过1(conv+bn),upsample(4),输出64通道tmp42;
# 输入第4支路256通道,经过1(conv+bn),upsample(2),输出256通道tmp43;
# x[b, 32, 128, 128] --->
# x[b, 64, 64, 64] --->
# x[b, 128, 32, 32] --->
# x[b, 256,16, 16 ] ---> y[b, 32, 128, 128]
y_list = self.stage4(x_list)
init部分:
self.stage4, pre_stage_channels = self._make_stage(
self.stage4_cfg, num_channels, multi_scale_output=False) #
整个stage4对应的模型画图: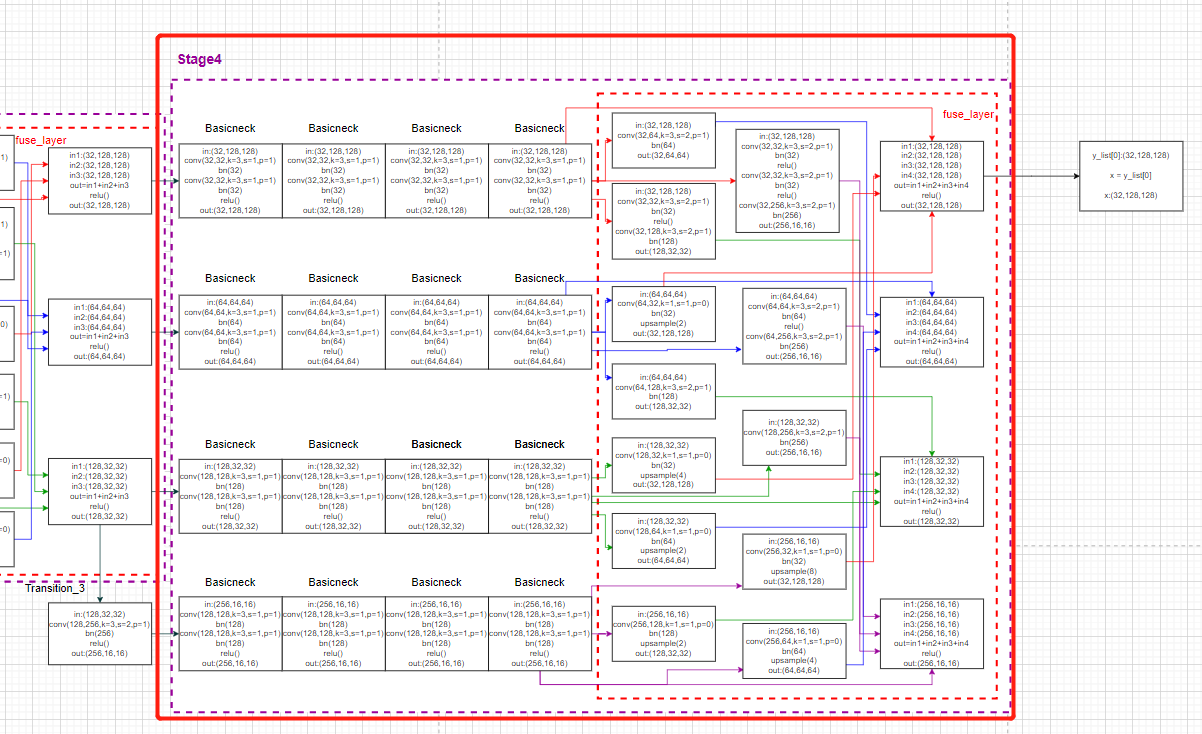
最后一个stage不需要transition_layer层,代码中是直接输出第一个支路的特征图。forward函数:
final_outputs = []
# x= x1,通道32
x = y_list[0]
对应的模型画图:
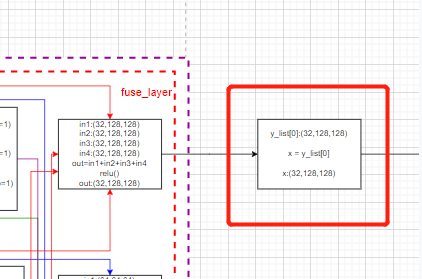
至此,HRNet作为主干网的部分已经结束了。
输出的x变量就是image数据经过HRNet主干网后输出的特征图了。
5. HRNet主干网中热图的生成热图的代码
从模型图上来看,从主干网中生成热图的部分如红框所示: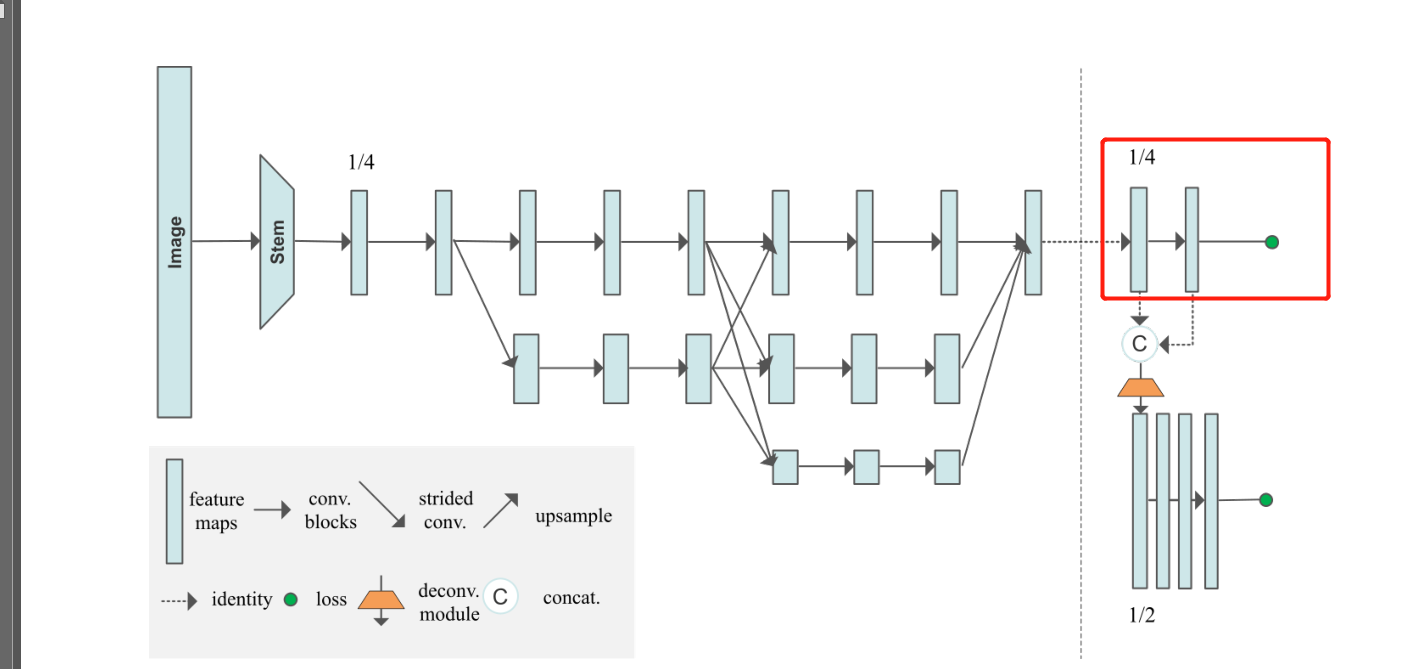
也非常简单,主要就是一个卷积层:
模型的forward函数:
# conv(32,34,k=1)
# y[b, 32, 64, 48] --> x[b, 17, 64, 48]
y = self.final_layers[0](x)
final_outputs.append(y)
init部分:
# 对最终的特征图混合之后进行一次卷积, 预测人体关键点的heatmap
self.final_layers = self._make_final_layers(cfg, pre_stage_channels[0])
_make_final_layers函数定义:
def _make_final_layers(self, cfg, input_channels):
dim_tag = cfg.MODEL.NUM_JOINTS if cfg.MODEL.TAG_PER_JOINT else 1 # 17
extra = cfg.MODEL.EXTRA
final_layers = []
# 17+17
output_channels = cfg.MODEL.NUM_JOINTS + dim_tag \
if cfg.LOSS.WITH_AE_LOSS[0] else cfg.MODEL.NUM_JOINTS # default:True
final_layers.append(nn.Conv2d(
in_channels=input_channels, # 32
out_channels=output_channels, # num_joints*2
kernel_size=extra.FINAL_CONV_KERNEL, # default:1
stride=1,
padding=1 if extra.FINAL_CONV_KERNEL == 3 else 0 # 0
))
deconv_cfg = extra.DECONV #
for i in range(deconv_cfg.NUM_DECONVS): # 1
input_channels = deconv_cfg.NUM_CHANNELS[i] # 32
# output_channels = 34
output_channels = cfg.MODEL.NUM_JOINTS + dim_tag \
if cfg.LOSS.WITH_AE_LOSS[i+1] else cfg.MODEL.NUM_JOINTS
final_layers.append(nn.Conv2d(
in_channels=input_channels, # 32
out_channels=output_channels, # num_joints*2
kernel_size=extra.FINAL_CONV_KERNEL, # 1
stride=1,
padding=1 if extra.FINAL_CONV_KERNEL == 3 else 0
))
return nn.ModuleList(final_layers)
可以看出生成热图是调用的是layers列表的一个卷积操作,实质上就是:
nn.Conv2d( in_channels=32, out_channels= num_joints*2, kernel_size=1, stride=1, padding=0)
然后画图就是: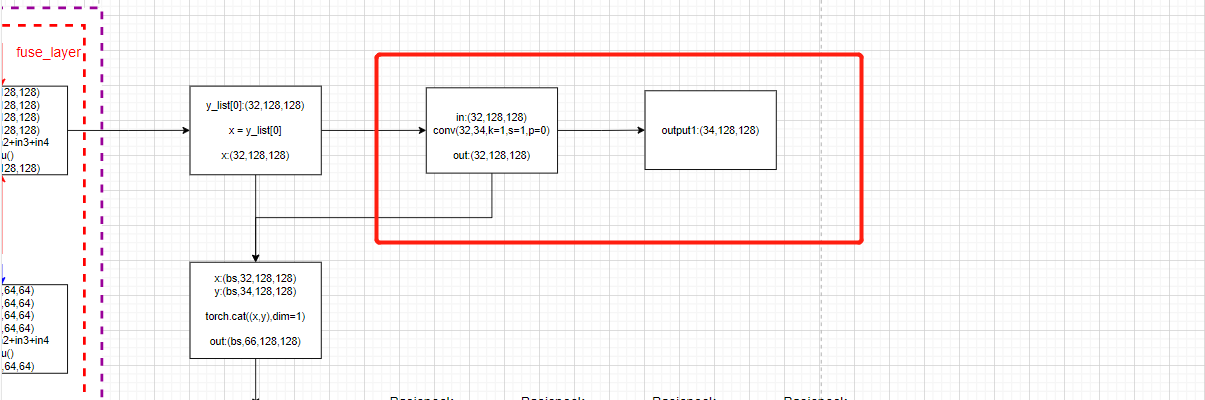
这也是HRNet模型中生成热图的方式,也是HigherHRNet网络的输出之一。
在HigherHRNet网络中,按照HRNet网络的方式输出一个热图,然后再经历反卷积操作后,输出第二个分辨率更大的热图,总共生成两个热图作为网络的输出。
6. HigherHRNet的反卷积模块生成热图的代码
从模型图上来看,从主干网中生成热图的部分如红框所示:
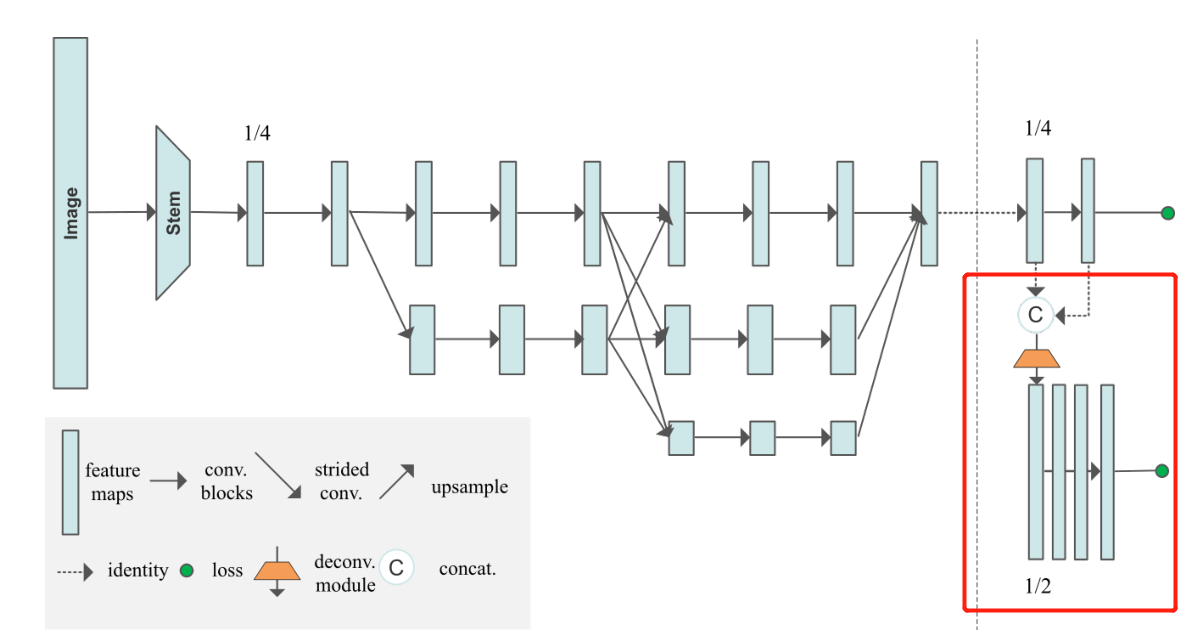
简单概括一下反卷积的模块的操作:
- 首先将HRNet主干网输出的特征图
x与经过卷积后生成的热图y进行拼接(cat) - 进行反卷积操作(nn.ConvTranspose2d),分辨率提升
- 然后通过4次basicneck残差块
- 最后再进行一次卷积操作输出高分辨率热图:
模型forward函数:
for i in range(self.num_deconvs): # rang(1)
if self.deconv_config.CAT_OUTPUT[i]: # True
x = torch.cat((x, y), 1) # torch.cat是将两个张量(tensor)拼接在一起, 按维数1(列)拼接
# 进行反卷积操作(nn.ConvTranspose2d), 然后通过4次basicneck残差块
# conv(66, 34, k=4), 4 BasicBlock(34,34)
x = self.deconv_layers[i](x)
# 最后再进行一次卷积操作输出高分辨率热图:
# conv(34,34,k=1)
y = self.final_layers[i+1](x)
final_outputs.append(y)
return final_outputs
init部分:
# 反卷积层
self.deconv_layers = self._make_deconv_layers(
cfg, pre_stage_channels[0])
_make_deconv_layers函数的定义:
def _make_deconv_layers(self, cfg, input_channels):
dim_tag = cfg.MODEL.NUM_JOINTS if cfg.MODEL.TAG_PER_JOINT else 1 # 17
extra = cfg.MODEL.EXTRA
deconv_cfg = extra.DECONV
deconv_layers = []
for i in range(deconv_cfg.NUM_DECONVS): # 1
if deconv_cfg.CAT_OUTPUT[i]: # ture
final_output_channels = cfg.MODEL.NUM_JOINTS + dim_tag \
if cfg.LOSS.WITH_AE_LOSS[i] else cfg.MODEL.NUM_JOINTS # 34
input_channels += final_output_channels # 32+34
output_channels = deconv_cfg.NUM_CHANNELS[i] # 32
deconv_kernel, padding, output_padding = \
self._get_deconv_cfg(deconv_cfg.KERNEL_SIZE[i]) # 4, 1, 0
layers = []
# 进行反卷积操作
layers.append(nn.Sequential(
nn.ConvTranspose2d(
in_channels=input_channels, # ?+34
out_channels=output_channels, # 32
kernel_size=deconv_kernel, # 4
stride=2,
padding=padding, # 1
output_padding=output_padding, # 0
bias=False),
nn.BatchNorm2d(output_channels, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)
))
# 通过4次BasicBlock残差块
for _ in range(cfg.MODEL.EXTRA.DECONV.NUM_BASIC_BLOCKS): # 4
layers.append(nn.Sequential(
BasicBlock(output_channels, output_channels),
))
deconv_layers.append(nn.Sequential(*layers))
input_channels = output_channels
return nn.ModuleList(deconv_layers)
根据模型画图: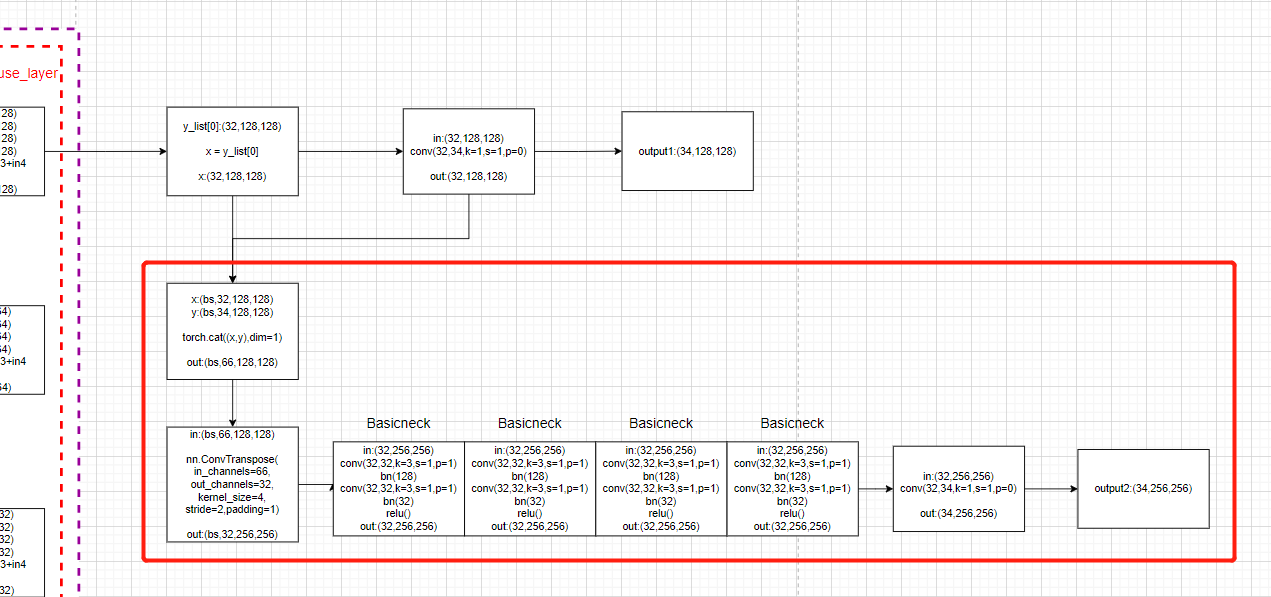
边栏推荐
- 基于gis三维可视化技术的智慧城市建设
- 官媒关注!国内数字藏品平台百强榜发布,行业加速合规健康发展
- 中国首款电音音频类“山野电音”数藏发售来了!
- SolidWorks工程图中添加中心线和中心符号线的办法
- Become a "founder" and make reading a habit
- Postman interface test III
- 对存储过程进行加密和解密(SQL 2008/SQL 2012)
- Integer inversion
- The request object parses the request body and request header parameters
- STM32 Basics - memory mapping
猜你喜欢

Future development blueprint of agriculture and animal husbandry -- vertical agriculture + artificial meat
fiddler-AutoResponder
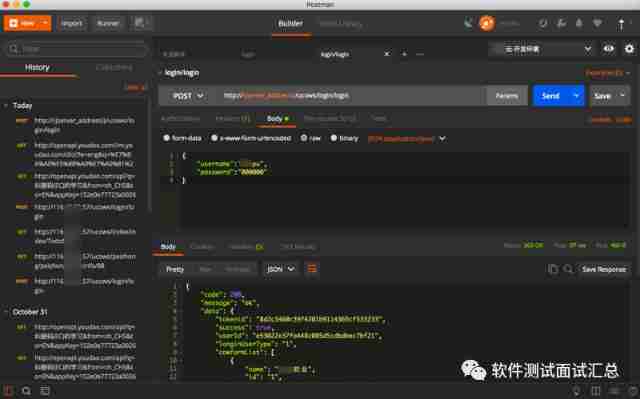
Postman interface test V
![[untitled]](/img/5b/61efbaded29250bc8d921b0cf087c8.png)
[untitled]
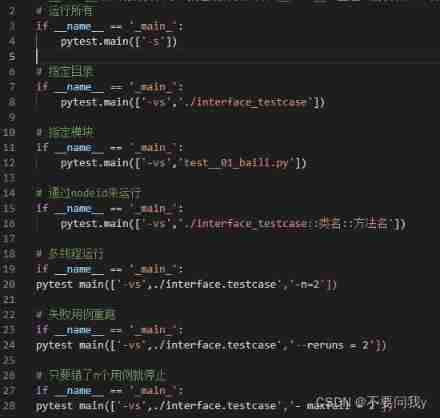
Pytest learning - dayone
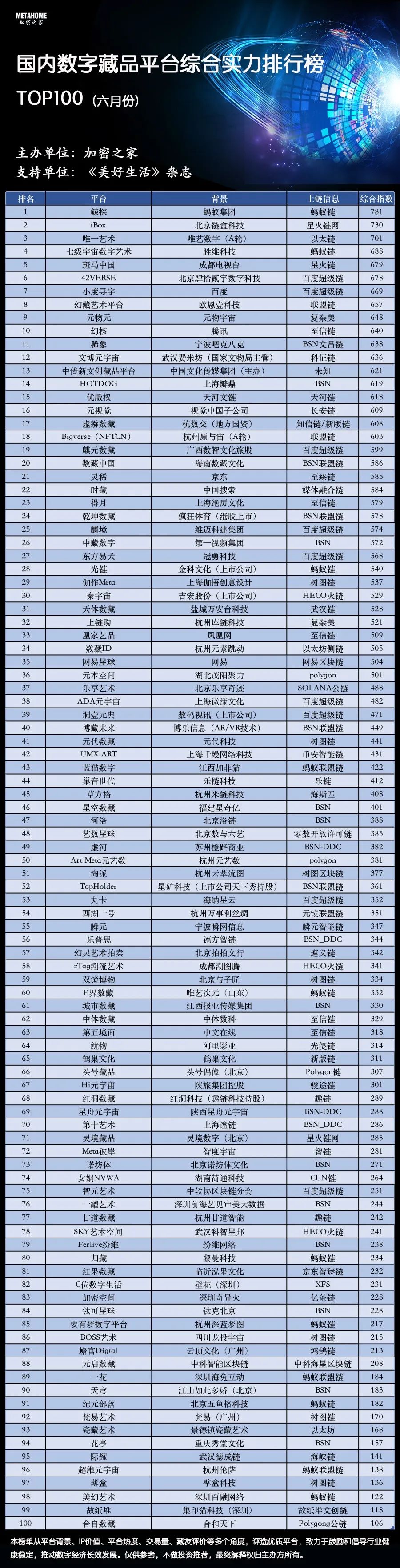
官媒关注!国内数字藏品平台百强榜发布,行业加速合规健康发展

ISP、IAP、ICP、JTAG、SWD的编程特点

喜马拉雅网页版每次暂停后弹窗推荐下载客户端解决办法
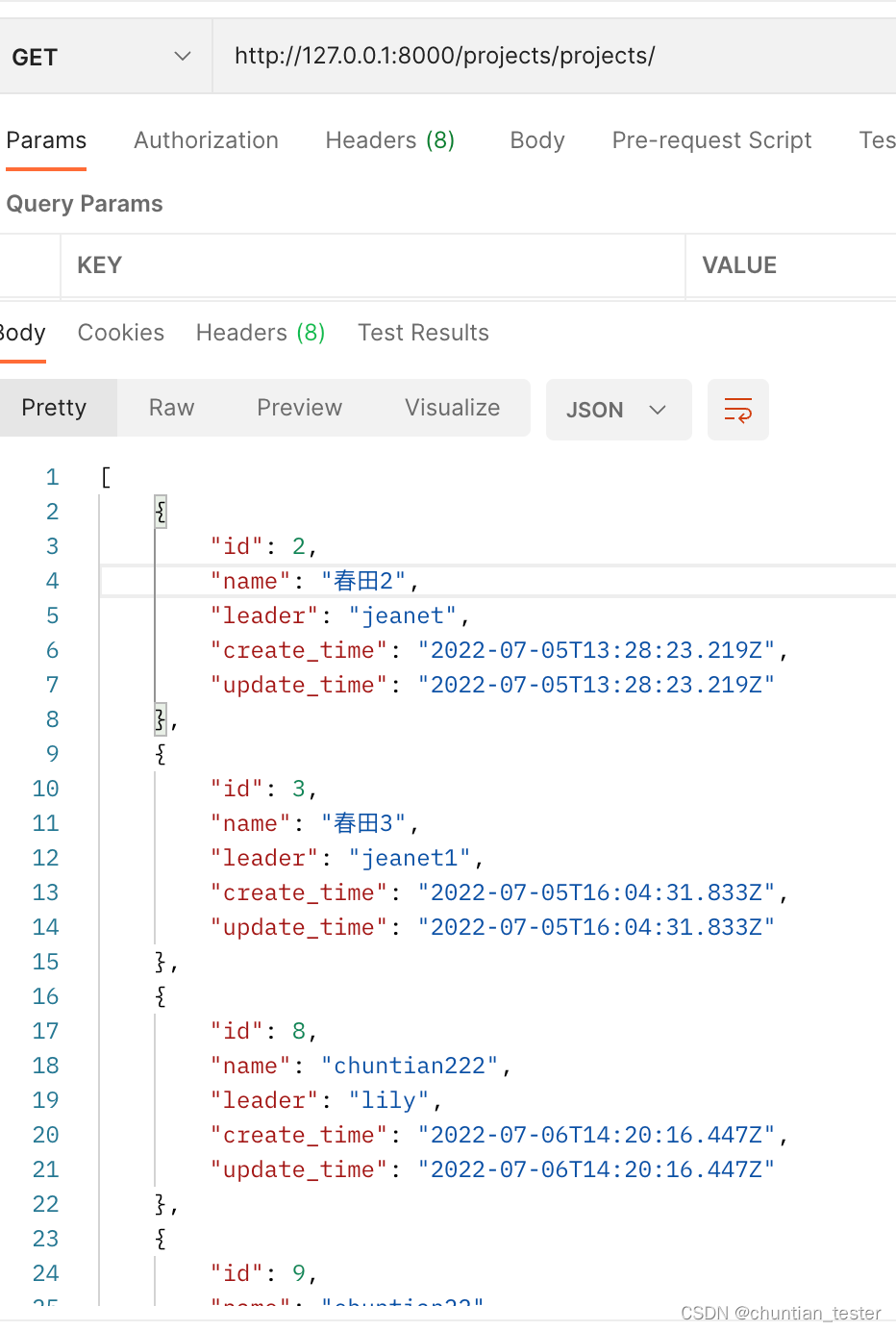
ORM--数据库增删改查操作逻辑
arcgis操作:dwg数据转为shp数据
随机推荐
运用tensorflow中的keras搭建卷积神经网络
“十二星座女神降临”全新活动推出
Chris LATTNER, the father of llvm: why should we rebuild AI infrastructure software
能源路由器入门必读:面向能源互联网的架构和功能
Why are social portals rarely provided in real estate o2o applications?
Weekly recommended short videos: what are the functions of L2 that we often use in daily life?
基于gis三维可视化技术的智慧城市建设
MCU与MPU的区别
arcgis操作:dwg数据转为shp数据
高数_第1章空间解析几何与向量代数_向量的数量积
There is a problem using Chinese characters in SQL. Who has encountered it? Such as value & lt; & gt;` None`
Use of JSON extractor originals in JMeter
Why does the starting service report an error when installing MySQL? (operating system Windows)
Parameter sniffing (1/2)
Methods of adding centerlines and centerlines in SolidWorks drawings
Chris Lattner, père de llvm: Pourquoi reconstruire le logiciel d'infrastructure ai
Programming features of ISP, IAP, ICP, JTAG and SWD
ORM--逻辑关系与&或;排序操作,更新记录操作,删除记录操作
Internship log - day04
Postman interface test V