当前位置:网站首页>运用tensorflow中的keras搭建卷积神经网络
运用tensorflow中的keras搭建卷积神经网络
2022-07-07 07:12:00 【guluC】
运用tensorflow中的keras搭建卷积神经网络
六步法
1、导入tensorflow库
import tensorflow.keras as keras
2、准备训练数据
x_train,y_train
x_test,y_test
3、搭建网络结构
- 生成一个保存网络结构的容器
model = keras.models.Sequential() #描述各层网络
- 卷积层
keras.layers.Conv2D(
filters, #卷积核个数
kernel_size, #卷积核尺寸 一般为(3,3)
strides=(1, 1), #滑动步长 默认(1,1)
padding='valid', #补零策略 'valid'或者'same'
activation=None, #激活函数 常用的有relu,softmax,selu
input_shape #定义输入的数据样式 (64,64,3)64*64的三维图
)
- 池化层
keras.layers.MaxPooling2D(
pool_size=(2, 2), #池化层大小
strides=None, #步长
padding='valid', #补零策略 'valid'或者'same'
data_format=None
)
- 压平(将数据变为一维,常用在从卷积层到全连接层的过度)
keras.layers.Flatten()
- 全连接层
keras.layers.Dense(
units, # 输出空间的维数
activation=None, # 激活函数 常用的有relu,softmax,selu
use_bias=True, # 布尔值,是否使用偏移向量
)
- Dropout层(防止过拟合,提高模型的泛化能力)
keras.layers.Dropout(
rate, #0-1之间的小数 丢弃的百分比
noise_shape=None,
seed=None #随机种子
)
4、打印网络结构和参数统计
model.summary()
summary 函数用于打印网络结构和参数统计
5、配置训练时用的优化器、损失函数和准确率评测标准
model.compile(
optimizer, #优化器
loss, # 损失函数
metrics #网络评价指标
)
- optimizer参数可以是字符串形式给出的优化器名字,也可以是函数形式,使用函数形式可以设置学习率、动量和超参数
- “sgd” 或者 keras.optimizers.SGD(lr = 学习率,decay = 学习衰减率,momentum = 动量参数)
- "adagrad’"或者 keras.optimizers.Adagrad(lr = 学习率, decay = 学习率衰减率)
- "adadelta"或者 keras.optimizers.Adadelta(lr = 学习率, decay = 学习率衰减率)
- "adam"或者 keras.optimizers.Adam(lr = 学习率,decay = 学习率衰减率)
- lose参数可以是字符串形式给出的损失函数的名字,也可以是函数形式、
- "mse"或者 keras.losses.MeanSquaredError()
- “sparse_categorical_crossentropy” 或者keras.losses.SparseCatagoricalCrossentropy(from_logits = False)
- Metrics标注网络评价指标
- “accuracy” : y_ 和 y 都是数值,如y_ = [1] y = [1] #y_为真实值,y为预测值
- "sparse_accuracy"y_和y都是以独热码 和概率分布表示,如y_ = [0, 1, 0], y = [0.256, 0.695, 0.048]
- "sparse_categorical_accuracy"y_是以数值形式给出,y是以 独热码给出,如y_ = [1], y = [0.256 0.695, 0.048]
6、fit
model.fit(
x, y,
batch_size=32,
epochs=10,
verbose=1,
callbacks=None,
validation_split=0.0,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None,
initial_epoch=0
)
- x:输入数据。如果模型只有一个输入,那么x的类型是numpy
array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array - y:标签,numpy array
- batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
- epochs:整数,训练终止时的epoch值,训练将在达到该epoch值时停止,当没有设置initial_epoch时,它就是训练的总轮数,否则训练的总轮数为epochs - inital_epoch
- verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
- callbacks:list,其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数
- validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
- validation_data:形式为(X,y)的tuple,是指定的验证集。此参数将覆盖validation_spilt。
- shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
- class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)
- sample_weight:权值的numpy
array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode=’temporal’。 - initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况
边栏推荐
- Dynamics 365online applicationuser creation method change
- 字节跳动 Kitex 在森马电商场景的落地实践
- Database multi table Association query problem
- [4G/5G/6G专题基础-147]: 6G总体愿景与潜在关键技术白皮书解读-2-6G发展的宏观驱动力
- [4g/5g/6g topic foundation-146]: Interpretation of white paper on 6G overall vision and potential key technologies-1-overall vision
- 第一讲:包含min函数的栈
- 2020CCPC威海 J - Steins;Game (sg函数、线性基)
- Niuke - Huawei question bank (61~70)
- CDZSC_ 2022 winter vacation personal training match level 21 (1)
- Please ask me a question. I started a synchronization task with SQL client. From Mysql to ADB, the historical data has been synchronized normally
猜你喜欢

一大波开源小抄来袭

AI从感知走向智能认知
企业实战|复杂业务关系下的银行业运维指标体系建设
What development models did you know during the interview? Just read this one
![[original] what is the core of programmer team management?](/img/11/d4b9929e8aadcaee019f656cb3b9fb.png)
[original] what is the core of programmer team management?

The applet realizes multi-level page switching back and forth, and supports sliding and clicking operations
Lesson 1: finding the minimum of a matrix
js逆向教程第二发-猿人学第一题
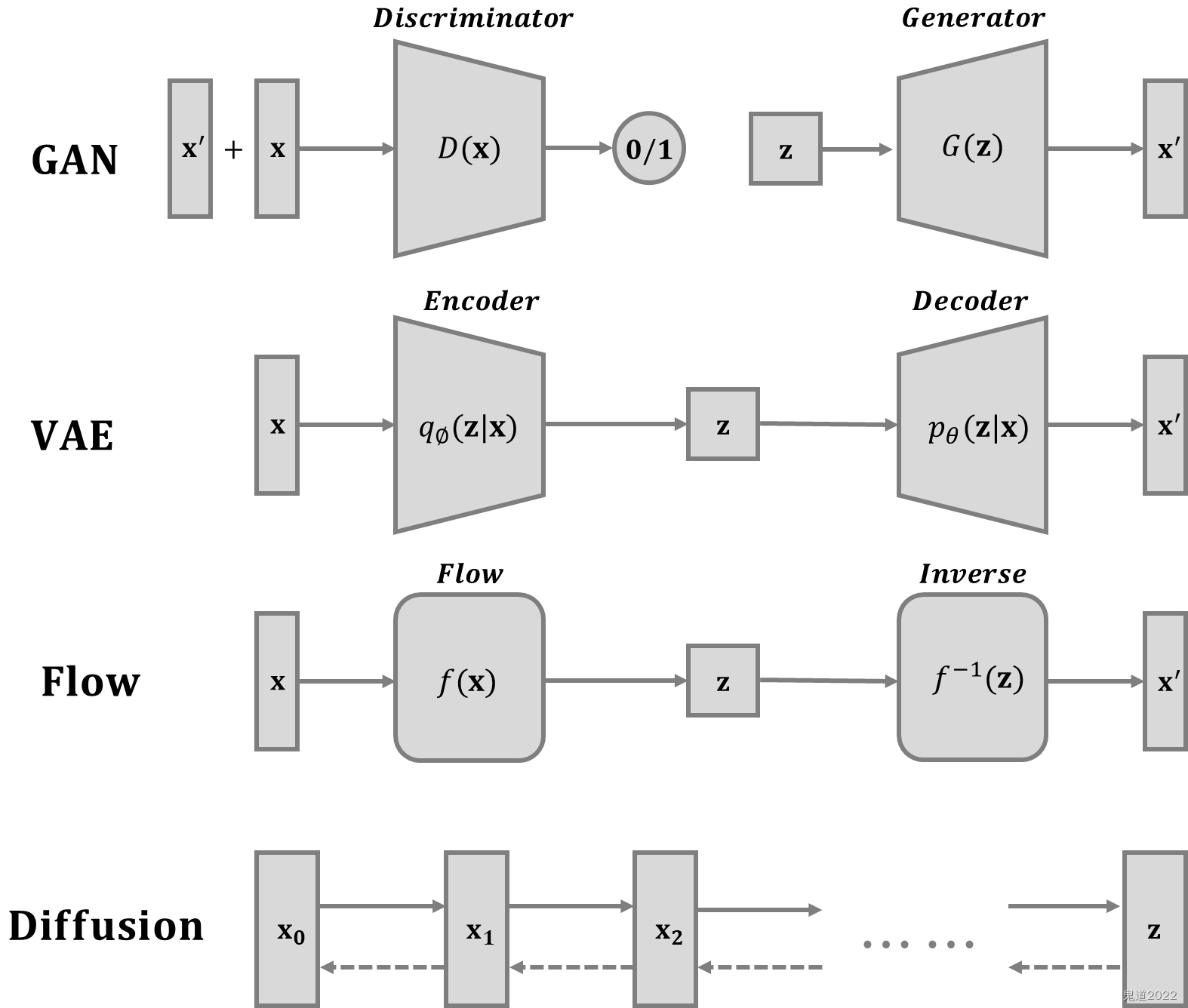
Detailed explanation of diffusion model
csdn涨薪技术-浅学Jmeter的几个常用的逻辑控制器使用
随机推荐
Detailed explanation of diffusion model
Sword finger offer II 107 Distance in matrix
CSDN salary increase technology - learn about the use of several common logic controllers of JMeter
第一讲:包含min函数的栈
There is a problem using Chinese characters in SQL. Who has encountered it? Such as value & lt; & gt;` None`
Switching value signal anti shake FB of PLC signal processing series
视频化全链路智能上云?一文详解什么是阿里云视频云「智能媒体生产」
洛谷P2482 [SDOI2010]猪国杀
大佬们,有没有遇到过flink cdc读MySQLbinlog丢数据的情况,每次任务重启就有概率丢数
[4G/5G/6G专题基础-147]: 6G总体愿景与潜在关键技术白皮书解读-2-6G发展的宏观驱动力
JS reverse tutorial second issue - Ape anthropology first question
JS inheritance prototype
Gauss elimination
[bw16 application] Anxin can realize mqtt communication with bw16 module / development board at instruction
第一讲:寻找矩阵的极小值
Guys, have you ever encountered the case of losing data when Flink CDC reads mysqlbinlog? Every time the task restarts, there is a probability of losing data
面试被问到了解哪些开发模型?看这一篇就够了
Deep understanding of UDP, TCP
哈夫曼编码压缩文件
如何成为一名高级数字 IC 设计工程师(1-6)Verilog 编码语法篇:经典数字 IC 设计