当前位置:网站首页>Semi-Decentralized Federated Learning for Cooperative D2D Local Model Aggregation
Semi-Decentralized Federated Learning for Cooperative D2D Local Model Aggregation
2022-08-05 02:19:00 【carrion】
Summary
Proposed Dual Time Scale Hybrid Federated Learning (TT-HF), a semi-decentralized learning architecture that combines the traditional device-to-server communication paradigm for federated learning with a device-to-device (D2D) communication is combined.
During each global aggregation interval, a device
(i) performs multiple iterations of stochastic gradient descent on its single dataset,
(ii) communicates via cooperative distributed D2D within the local cluster, aperiodicallyparticipate in the negotiation process of its model parameters.
Developed an adaptive control algorithm that can adjust the step size of TT-HF, the number of D2D communication rounds and the global aggregation period over time to achieve a sub-linear convergence speed of O(1/t) while minimizing theoptimize network resource utilization.
Traditional Federated Learning
In each iteration, each device trains a local model based on its own dataset, usually using (stochastic) gradient descent.The device then uploads its local model to the server, which aggregates it into a global model, usually using a weighted average, and synchronizes the device with this new model to initiate the next round of local training.
To reduce the cost of uplink and downlink transmission, a combination of local model training and periodic but infrequent global aggregation is proposed.
However, local datasets may exhibit significant heterogeneity in their statistical distributions, resulting in learning models that may be biased towards the local datasets, thus reducing the accuracy of the global model.
TT_HF
(i) involves a mix between device-to-device and device-to-server communication
(ii) contains two timescales for model training: stochastic gradient descent iterations and clustering on a single deviceMulti-round collaborative D2D communication within.
During global aggregation, only one device in the cluster needs to upload the cluster model to the server,
Specifically, during the local update interval of federated learning, a device can systematically share its model parameters with other devices in its vicinity, to form a distributed consensus among each cluster of edge devices.
At the end of each local training interval, assuming that each device's model now reflects the consistency of its cluster, the master can randomly select a device from each cluster forGlobal Aggregation.
Quantify the relationship between device-level stochastic gradient updates, cluster-level consensus processes, and network-level global aggregation.and use them to adjust the length of each local update and consensus cycle.
Results: A version of federated learning that optimizes global model convergence properties while minimizing uplink communication requirements in the system.
Recommended Literature: A Comprehensive Understanding of Federated Learning
[28] S. Abdulrahman, H. Tout, H. Ould-Slimane, A. Mourad, C. Talhi, and
M. Guizani, “A survey onfederated learning: The journey from central-
ized to distributed on-site learning and beyond,” IEEE Internet Things
J., vol. 8, no. 7, pp. 5476–5497, Apr. 2021.
[29] T. Li, A. K. Sahu, A. Talwalkar, and V. Smith, “Federated learning:
Challenges, methods, and future directions,” IEEE Signal Process. Mag.,
vol. 37, no. 3, pp. 50–60, May 2020.
In terms of wireless communication efficiency, several works have investigated the impact of performing multiple rounds of local gradient updates between successive global aggregations, including optimizing the aggregation period according to the total resource budget.
To further reduce the need for global aggregation, [31] proposed a hierarchical system model for federated learning, where edge servers are used for partial global aggregation.
[31] L. Liu, J. Zhang, S. Song, and K. B. Letaief, “Client-edge-cloud hierarchical federated learning,” in Proc. IEEE Int. Conf. Commun.
(ICC),vol. 2020, pp. 1–6.
Model quantization[] and sparsification techniques are also proposed.
This paper proposes a semi-decentralized architecture in which D2D communication is used to exchange model parameters between nodes together with global aggregation.
For data heterogeneity, in [34], the authors propose to upload a portion of the local dataset to the server, which is then used to augment global model training.
[34] N. Y oshida, T. Nishio, M. Morikura, K. Yamamoto, and R. Yo onetani,
“Hybrid-FL for wireless networks: Cooperative learning mechanism
using non-IID data,” in Proc. IEEE Int. Conf. Commun. (ICC), Jun. 2020,
pp. 1–7.
this articleUsing D2D communication to exchange between devicesmodel parameters, which alleviates such concerns.
The distributed collaborative learning among devices is introduced into the local update process, forming a new system architecture with D2D reinforcement learning.
Addresses both communication efficiency and data heterogeneity challenges.
In this case
(i) the device may perform multiple (stochastic) gradient iterations between global aggregations,
(ii) the global aggregation is aperiodic,
(iii) the deviceThe consensus process among them may happen aperiodically during each global aggregation.
Due to device mobility, the topology of each cluster (i.e. the number of nodes and their location within the cluster) may change over time, although we assume that compared to the time between two global aggregates,This evolution is slow.
Triangular inequality is used for the upper bound on the gradient...Smoothness Condition
TT-HF: Dual Time Scale Hybrid Federated Learning
1) Overview and rationale: consists of a series of local model training intervals between aperiodic global aggregations.During each interval, the device performs local stochastic gradient descent (SGD) iterations and aperiodically synchronizes its model parameters through a local consistency process within the cluster.
Looking at it later, there are too many formulas.....
边栏推荐
- 特殊矩阵的压缩存储
- 【MySQL series】- Does LIKE query start with % will make the index invalid?
- Transfer Learning - Distant Domain Transfer Learning
- fragment可见性判断
- Understand the recommendation system in one article: Recall 06: Two-tower model - model structure, training method, the recall model is a late fusion feature, and the sorting model is an early fusion
- KingbaseES V8 GIS data migration solution (2. Introduction to the capabilities of Kingbase GIS)
- 使用OpenVINO实现飞桨版PGNet推理程序
- ExcelPatternTool: Excel table-database mutual import tool
- Oracle encapsulates restful interfaces into views
- LPQ (local phase quantization) study notes
猜你喜欢

【解密】OpenSea免费创造的NFT都没上链竟能出现在我的钱包里?
Xunrui cms website cannot be displayed normally after relocation and server change

基于OpenVINO工具套件简单实现YOLOv7预训练模型的部署
DAY23: Command Execution & Code Execution Vulnerability
如何基于OpenVINO POT工具简单实现对模型的量化压缩

iNFTnews | 对体育行业和球迷来说,NFT可以带来什么?
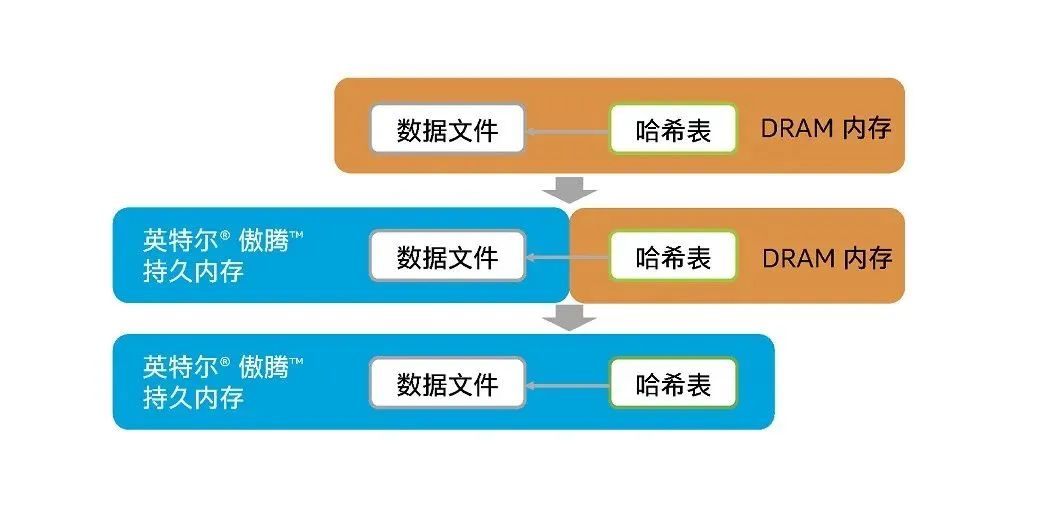
Optimizing the feed flow encountered obstacles, who helped Baidu break the "memory wall"?
ROS通信 —— 服务(Service)通信](/img/4d/4657f24bd7809abb4bdc4b418076f7.png)
[ROS](10)ROS通信 —— 服务(Service)通信

js中try...catch和finally的用法

2022了你还不会『低代码』?数据科学也能玩转Low-Code啦!
随机推荐
matlab绘制用颜色表示模值大小的箭头图
CPDA|运营人如何从负基础学会数据分析(SQL)
常见的硬件延迟
How to deal with your own shame
在这个超连接的世界里,你的数据安全吗
"Dilili, wait for the lights, wait for the lights", the prompt sound for safe production in the factory
Xunrui cms website cannot be displayed normally after relocation and server change
select tag custom style
Fragment visibility judgment
[Endnote] Word inserts a custom form of Endnote document format
SDC简介
Flink 1.15.1 集群搭建(StandaloneSession)
C语言日记 9 if的3种语句
C language implements a simple number guessing game
后期学习计划
js中try...catch和finally的用法
ARM Mailbox
优化Feed流遭遇拦路虎,是谁帮百度打破了“内存墙”?
重新审视分布式系统:永远不会有完美的一致性方案……
KingbaseES V8 GIS data migration solution (2. Introduction to the capabilities of Kingbase GIS)