当前位置:网站首页>使用并行可微模拟加速策略学习
使用并行可微模拟加速策略学习
2022-07-03 14:02:00 【图灵不图灵】
ACCELERATED POLICY LEARNING WITH PARALLEL DIFFERENTIABLE SIMULATION 全文翻译
我其实读的不是很懂,刚刚接触RL很多名词不知道什么意思怎么翻译。这是个翻译作业,和我一样英语不太好的同学可以用这个省去一些阅读障碍;也作为抛砖引玉,有想法的同学可以继续加强译文质量,省去挺多翻译上不必要的麻烦。通篇机翻+自己阅读修改关键处。
word资源
https://download.csdn.net/download/weixin_43395957/85790609
贴原文地址
Accelerated Policy Learning with Parallel Differentiable Simulation | OpenReviewhttps://arxiv.org/abs/2204.07137Accelerated Policy Learning with Parallel Differentiable Simulationhttps://arxiv.org/abs/2204.07137
摘要
深度强化学习可以生成复杂的控制策略,但需要大量的训练数据才能有效地工作。最近的工作试图通过利用可微分的模拟器来解决这个问题。然而这种方法存在如局部最小值和爆炸、数值梯度消失等内在(inherent)问题,无法普遍应用于关联紧密且策略复杂的任务,如经典RL(Reinforcement Learning强化学习)基准中的类人运动。在这项工作中,我们提出了一种高性能的可微分模拟器和一种新的策略学习算法(SHAC),它可以有效地利用模拟梯度,即使在存在非平滑的情况下。我们的学习算法通过一个平滑的判别函数来缓解局部最小值的问题,通过一个截断(trucated)学习窗口避免了梯度消失或梯度爆炸,且允许并行计算。我们在经典的RL控制任务上评估了我们的方法,并将结果与SOTA(state-of-the-art)和基于可微模拟的算法比比较,可观察到在采样效率和计算时间方面有显著改进。此外,我们将其应用于具有挑战性的高维肌肉驱动运动的大动作空间问题,比性能最好的RL算法减少了超过17×的训练时间,由此证明我们的方法具有良好的可扩展性。更多的视觉结果见:https://short-horizon-actor-critic.github.io/.
引言
学习控制策略是机器人技术和计算机动画技术中的一项重要任务。在各种策略学习技术中,强化学习(RL)是一个特别成功的工具,从机器人(如猎豹、影子手)((Hwangbo et al., 2019;Andrychowicz et al., 2020)到仅使用高级反馈定义的复杂动画角色(如肌肉驱动的类人)(Lee等人,2019年)。尽管取得了成功,RL仍然需要大量的训练数据来近似策略梯度,这使得学习更加昂贵和耗时间,特别是对于高维问题(图1,右)。

图1:环境:这里是我们需要评估的环境。三个经典的物理控制RL基准,从左:卡杆摆动+平衡,蚂蚁,和类人猿。此外,我们还对Lee等人(2019年)提出的高维肌肉肌腱驱动的人形MTU模型进行了训练策略。然而,无模型强化学习(PPO,SAC)需要许多样本来解决这类高维控制问题,SHAC通过使用并行实现的解析梯度来有效地扩展,包括在样本复杂度和计算时间上。
可微模拟器的最新发展为加速控制策略的学习和优化开辟了新的可能性。可微模拟器的最新发展为加速控制策略的学习和优化开辟了新的可能性。一个可微分的模拟器可以提供相对于控制输入的任务表现反馈的精确的一阶梯度。这些附加信息可能允许使用有效的基于梯度的方法来优化策略。然而,正如最近Freeman等人(2021)所显示的,尽管可微模拟器可用,但还没有令人信服地证明它们可以有效地加速复杂的高维和接触丰富的任务中的策略学习,比如一些传统的RL基准。这有几个原因:
- 局部最小值可能会导致基于梯度的优化方法失速。
- 对于长的轨迹,数值梯度可能会沿着向后的路径消失/爆炸。
- 在策略失败到提前终止期间,可能会发生不连续的优化场景。
由于这些挑战,以往的工作仅限于优化短任务范围的开环控制策略 (Hu et al., 2019; Huang et al., 2021),或优化相对简单任务(如无接触环境)的策略 (Mora et al., 2021; Du et al., 2021)。在这项工作中,我们探讨了这样一个问题:可微模拟能否在具有连续闭环控制和复杂接触丰富动态的任务中加速策略学习?
受 actor-critic RL算法(Konda&Tsitsiklis,2000)的启发,我们提出了一种有效利用可微模拟器进行策略学习的方法。复杂的动态和策略失败情况可能导致的潜在噪声,我们通过使用一个critic网络来缓解这种出现的局部最小值的问题,该网络可以对噪声做补偿,得到一个近似平滑拟合(图2)。此外,我们使用一个截断的学习窗口来缩短反向传播路径,以解决梯度消失/爆炸的问题,减少内存需求,并提高学习效率。

图2: BPTT和SHAC之间的现象比较。我们从一个策略中选择一个单一的权重,并通过∆θk∈[−1,1]改变其值,以绘制BPTT和SHAC w.r.t.的任务损失情况一个策略参数。BPTT的任务视界为H=1000,我们的方法的短视界长度为H=32。正如我们所看到的,更长的优化范围会导致难以优化的噪声损失,而我们的方法可以看作是真实情况的平滑近似。
可微模拟器的另一个挑战是,与优化的前向动力学物理引擎相比,反向传递通常会引入一些额外计算开销。为了确保有意义的比较,我们必须确保我们的学习方法不仅提高了采样效率,而且还缩短了计算时间。基于gpu的物理模拟在加速无模型RL算法方面显示出了显著的有效性(Liang et al., 2018; Allshire et al., 2021),鉴于此,我们开发了一个基于gpu的可微模拟器,可以在许多环境中并行计算标准机器人模型的梯度。我们的基于pytorch的模拟器允许我们应用有的算法和工具做出高质量模拟实验。
据我们所知,这项工作是第一个提供合理且全面比较基于梯度和基于基于强化学习策略的方法,合理的定义如下(a)对偏好(favored)强化学习任务和偏好(favored)可微模拟任务均进行基准测试,(b)测试复杂任务(即相关联系紧密且任务范围较长),(c)比较RL算法的SOTA(state-of the-art)实现,以及(d)比较采样效率和计算时间。我们在标准的RL基准测试任务上评估了我们的方法,以及一个具有超过150个驱动自由度的高维字符控制任务(其中一些任务如图1所示)。我们将我们的方法称为short-horizon actor-critic(SHAC),我们的实验表明,SHAC在采样效率和计算时间方面都优于策略学习方法的SOTA效果。
相关工作
可微分模拟 基于物理的模拟已在机器人领域得到广泛应用(Todorov et al., 2012; Coumans & Bai, 2016)。最近,人们对可微模拟器的构建很感兴趣,它可以直接计算模拟输出与动作和初始条件相关的梯度。这些模拟器可能基于自动微分框架 (Griewank & Walther, 2003; Heiden et al., 2021; Freeman et al., 2021)或分析梯度计算(Carpentier & Mansard, 2018; Geilinger et al., 2020; Werling et al., 2021)。可微模拟的一个挑战是接触动力学的非光滑性,导致许多工作关注如何通过线性互补(LCP)接触模型有效地区分(Degrave et al., 2019; de Avila Belbute-Peres et al., 2018; Werling et al., 2021)或利用平滑的基于惩罚的接触公式(Geilinger et al., 2020; Xu et al., 2021)。
深度强化学习 深度强化学习已成为系统学习控制策略的流行工具,包括从 机器人(Hwangbo et al., 2019; OpenAI et al., 2019; Xu et al., 2019; Lee et al., 2020; Andrychowicz et al., 2020; Chen et al., 2021a) 到 复杂动画人物(Peng et al., 2018; 2021; Liu & Hodgins, 2018; Lee et al., 2019)。无模型RL算法将底层动态视为策略学习过程中的一个黑盒子。其中,RL策略方法 (Schulman et al., 2015; 2017)根据当前策略产生的经验改进策略,而策略外方法(Lillicrap et al., 2016; Mnih et al.,2016; Fujimoto et al., 2018; Haarnoja et al., 2018)利用所有过去经验作为学习资源来提高采样效率。另一方面,基于模型的RL方法(Kurutach等人,2018;Janner等人,2019)被提出从少量经验中学习近似的动态模型,然后在策略学习过程中充分利用学习到的动态模型。我们的方法的基本思想与之前一些基于模型的方法相似(Hafner等人,2019;Clavera等人,2020),这些方法既在AC(actor-critic)模式下学习,又利用模拟器“模型”的梯度。然而,我们证明了我们的方法使用并行可微模拟可以代替学习到的模型,并能获得更好的计算时间效率和策略性能。附录A.4.6提供了与基于模型的RL的详细比较说明。
基于可微模拟的策略学习 可微模拟器的发展使通过提供的梯度信息优化控制策略。时间反向传播(Backpropagation Through Time, BPTT)(Mozer,1995)在之前的工作中被广泛用于展示可微系统 (Hu et al., 2019; 2020; Liang et al., 2019; Huang et al., 2021; Du et al., 2021)。然而,在长期任务中会出现优化存在噪声以及梯度爆炸/消失的情况,这种情况下直接进行一阶微分基本无效。人们已经提出了一些方法来解决这个问题。Qiao等人(2021)提出了一种样本增强方法,以提高简单的MuJoCo Ant环境下的RL采样效率。然而,由于该方法遵循基于模型的学习框架,它明显慢于策略方法的SOTA,如PPO(Schulmanetal.,2017)。Mora等人(2021)提出了将轨迹优化阶段和模仿学习阶段交叉,以此将策略从计算图分离来缓解爆炸性梯度问题。他们在简单的控制任务上演示了他们的方法(例如,停止一个钟摆)。然而,通过长时间的状态轨迹返回的梯度仍然可以为更复杂的任务创建更好的优化。此外,这两种方法都需要完整的雅可比矩阵,这在反转模式(reverse-mode)可微模拟器中并不普遍且未必有效。而我们的方法只依赖于一阶梯度。因此,它可以很自然地利用能够提供这些信息的模拟器和框架。
方法
1. 基于gpu的可微动力学仿真
从概念上讲,我们把模拟器作为一个抽象函数 从时间t→t+1得到状态s,其中a是在该时间步长中应用的驱动控制的向量(取决于待解决的问题,可能代表关节力矩,或肌肉收缩信号)。给定一个可微标量损失函数L及其伴随矩阵
从时间t→t+1得到状态s,其中a是在该时间步长中应用的驱动控制的向量(取决于待解决的问题,可能代表关节力矩,或肌肉收缩信号)。给定一个可微标量损失函数L及其伴随矩阵 ,模拟器反向传播:
,模拟器反向传播:

连接这些步骤可以让我们在整个轨迹中传播梯度。
为了模拟动力学函数F,我们的物理模拟器求解了正向动力学方程
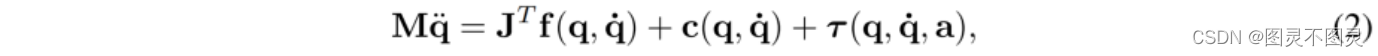
其中q,˙q,¨q分别为联合坐标、速度和加速度,f表示外力,c表示Coriolis力,τ表示联合空间驱动。质量矩阵M和雅可比矩阵J是在每个环境用一个线程并行计算的。我们使用复合刚体算法(CRBA)来计算关节动力学,这允许我们在每一步缓存中得到矩阵分解(使用并行共享的矩阵分解获得),以便在向后传递中重复使用。在确定联合加速度¨q后,我们执行半隐式欧拉积分步获取更新后的系统状态s=(q,˙q)。
对于简单的环境,我们使用基于扭矩的控制来驱动我们的代理,其中策略在每个时间步长输出τ。对于更复杂的肌肉驱动情况,每块肌肉都由一系列可能通过多个刚体的附着位点组成,并且策略输出每块肌肉的激活值。肌肉激活信号产生纯粹的收缩力(模拟生物肌肉)(Leeetal.,2019)。
当引入接触和关节极限分析时,关节动力学分析模拟可以是不光滑甚至不连续的,但特别注意需要确保动力学平滑。为了建立接触模型,我们采用了Geilinger等人(2020)的摩擦接触模型,该模型结合Xu等人(2021)的接触阻尼力公式,用线性阶跃函数近似库仑摩擦力以提供更好的非渗透接触动力学:

其中fc、ft分别为接触法向力和接触摩擦力,d、d˙为接触穿透深度及其时间导数(渗透率’penetration’为负),n为接触法向方向,vt为沿接触切向方向接触点的相对速度,kn、kd、kt、µ分别为接触刚度、接触阻尼系数、摩擦刚度和摩擦系数。
为了模拟联合极限,可以应用一个连续的基于惩罚的力:

其中k极限是关节极限刚度,![[q_{lower}, q_{upper}]](http://img.inotgo.com/imagesLocal/202207/03/202207031402154496_3.gif) 是关节角q的界。
是关节角q的界。
我们在PyTorch(Paszke等人,2019)上建立了可微分的模拟器,并使用源代码转换方法生成模拟内核的前向传播和反向传播版本(Griewank&Walther,2003;Hu等人,2020年)。我们使用分布式GPU内核并行化模拟器,用于密集矩阵例程和评估接触和联合力。
2. 优化情况分析
虽然平滑的物理模型改善了局部优化现象,但前向动力学和神经网络控制策略的结合使每个模拟步骤都具有非线性和非凸性。当数千个模拟步骤被连接起来,并且每个步骤中的动作都被一个反馈控制策略耦合时,这个问题就会加剧。由此产生的反馈现象的复杂性导致简单的基于梯度的方法很容易陷入局部最优状态。
此外,为了处理主体(agent)故障(例如,类人体下降)并提高采样效率,提前终止技术被广泛应用于策略学习算法(Brockmanetal.,2016)。虽然这些已经被证明对无模型算法是有效的,但提前终止给优化问题带来了额外的不连续性,这可能使基于分析梯度的方法无效。
为了分析这个问题,受之前的工作(Parmasatal.,2018)的启发,我们在图2(左)中绘制了一个具有1000步任务范围的类人运动问题的优化现象(landscape)。具体来说,我们采用一个训练过的策略,扰动神经网络中单个参数θk的值,并评估策略变化的性能。如图所示,由于任务范围较长和提前终止,类人问题的现象是高度非凸和不连续的。此外,由反向传播计算出的梯度 的范数大于
的范数大于 。我们在附录A.5中提供了更多的现象分析。因此,以往大多数基于可微模拟的工作都集中在具有无接触动态和无提前终止的短期任务上,在这些任务中,纯基于梯度的优化(如BPTT)可以正常运行。
。我们在附录A.5中提供了更多的现象分析。因此,以往大多数基于可微模拟的工作都集中在具有无接触动态和无提前终止的短期任务上,在这些任务中,纯基于梯度的优化(如BPTT)可以正常运行。
3. SHORT-HORIZON ACTOR-CRITIC(SHAC)
为了解决上述基于梯度的策略学习的问题,我们提出了短视界参与-评估方法(SHAC)。我们的方法在任务执行过程中同时学习策略网络(即accor)πθ和价值网络(即评论家)Vφ,并在学习过程中将整个任务范围划分为几个更小的子窗口(图3)。利用子窗口中的多步反馈加上来自学习得到评估的终端值估计来改进策略网络。可微模拟用于通过子窗口内的状态和动作反向传播梯度,以提供精确的策略梯度。在每个学习集中收集轨迹状态并用于学习评估网络。
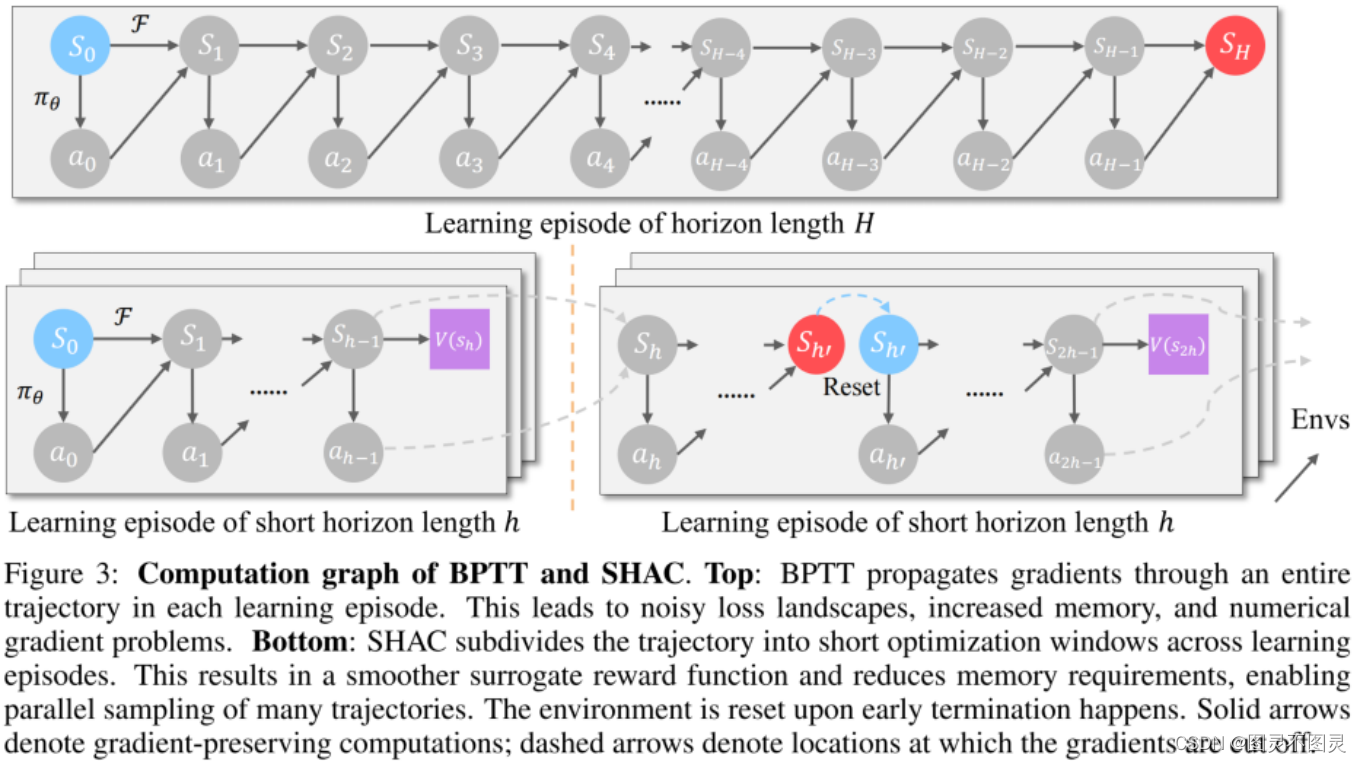
图3: BPTT和SHAC的计算图。顶部:BPTT在每个学习过程中通过整个轨迹传播梯度。这导致了嘈杂的损失现象、增加的记忆和数值梯度问题。底部:SHAC将学习期间的轨迹细分为较短的优化窗口。这导致了一个更平滑的替代反馈功能,并减少了记忆需求,使许多轨迹的并行采样。在提前终止时重置环境。实心箭头表示保持梯度的计算;虚线箭头表示梯度被切断的位置。
具体来说,我们模型的控制问题建模为一个有限水平马尔可夫决策过程(MDP),包括状态空间S,行动空间A,反馈函数R,过渡函数F,初始状态分布Ds0以及任务范围H。在每一步由反馈策略πθ(|st)计算每一个动作向量。虽然我们的方法没有限制策略为确定或随机,但我们在我们的实验中使用随机策略来促进额外的探索。具体来说,该动作由a_t ∼N(µθ(st),σθ(st))采样。过渡函数F由我们的可微模拟(第3.1节)建模。每步都会收到一个单步反馈rt=R(st,at)。该问题的目标是找到能够最大化预期有限视野反馈的策略参数θ。
我们的方法在以下策略模式下工作。在每个学习过程中,算法从模拟中并行采样N个短水平h<<H的轨迹{τi},从前一个学习阶段轨迹的结束状态开始。然后计算以下策略损失:
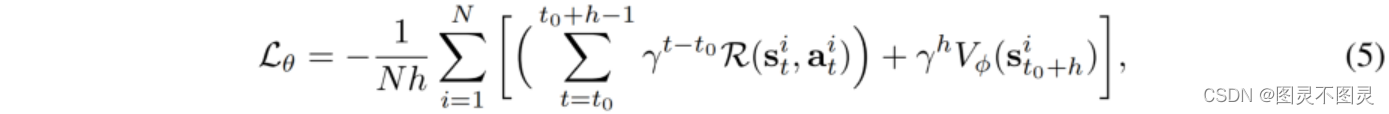
其中, 和
和 是第i个轨迹的第t步的状态和动作,和γ<1是为稳定训练而引入的一个折扣因素。在轨迹采样过程中发生任务终止时,会进行重置贴现率等特殊处理。
是第i个轨迹的第t步的状态和动作,和γ<1是为稳定训练而引入的一个折扣因素。在轨迹采样过程中发生任务终止时,会进行重置贴现率等特殊处理。
为了计算策略损失 的梯度,我们将模拟器视为可微层(等式中显示的后传递1)在PyTorch计算图中,并执行定期的反向传播。我们应用再参数化抽样的方法来计算随机策略的梯度。有关梯度计算的详细信息,请参见附录A.1。然后,我们的算法使用Adam的一步来更新策略(Kingma&Ba,2014)。可微模拟器在这里扮演着至关重要的作用,因为它允许我们充分利用连接状态和行动的潜在动态,以及优化策略,在轨迹内产生更好的短期反馈和更有前途的终端状态,以实现长期性能。我们注意到,在学习事件之间的梯度被切断,以防止在长时间反向传播过程中不稳定的梯度。
的梯度,我们将模拟器视为可微层(等式中显示的后传递1)在PyTorch计算图中,并执行定期的反向传播。我们应用再参数化抽样的方法来计算随机策略的梯度。有关梯度计算的详细信息,请参见附录A.1。然后,我们的算法使用Adam的一步来更新策略(Kingma&Ba,2014)。可微模拟器在这里扮演着至关重要的作用,因为它允许我们充分利用连接状态和行动的潜在动态,以及优化策略,在轨迹内产生更好的短期反馈和更有前途的终端状态,以实现长期性能。我们注意到,在学习事件之间的梯度被切断,以防止在长时间反向传播过程中不稳定的梯度。
在我们更新策略πθ后,我们使用在当前学习事件中收集的轨迹来训练值函数Vφ。值函数网络通过以下MSE损失进行训练:
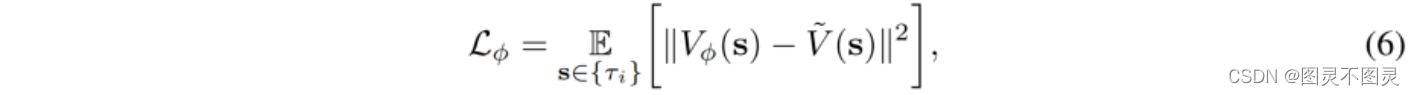
其中V˜(s)是状态s的估计值,通过td-λ公式从采样的短期轨迹计算出来(Sutton等人,1998),该公式通过对不同k步的指数平均回归计算估计值,以平衡估计的方差和偏差:
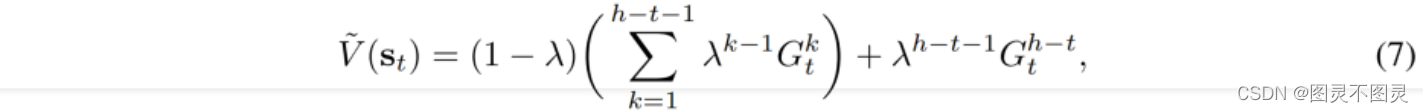
其中
![]()
是从时间t返回的k步。估计值V˜(s)在评论家训练中被视为常数,就像在常规的演员-评论家RL方法中一样。换句话说,就是等式6的梯度不通过等式7中的状态和动作而流动。
我们进一步利用目标值函数技术(Mnihetal.,2015),通过从之前的值函数平稳过渡到新拟合的值函数来稳定训练,并使用目标值函数Vφ0来计算策略损失(Eq.5)并估计状态值(Eq. 7).此外,我们应用RL算法中常见的观察归一化,它通过从之前学习事件中的状态观察中计算出的运行平均值和标准差来将状态观察归一化。在算法1中给出了该方法的伪代码。

我们的参与-评价公式有几个优点,使它能够有效和有效地利用模拟梯度。首先,终端值函数将长动态范围上的噪声现象和早期终止引入的不连续吸收为平滑函数,如图2(右)所示。这种平滑的替代公式有助于减少局部峰值的数量,并减轻了容易陷入局部最优的问题。其次,短范围事件避免了通过深度嵌套的更新链反向传播梯度时的数值问题。最后,使用短范围的情节允许我们更频繁地更新演员,当这与并行可微模拟相结合时,可以显著加快训练时间。
实验
我们设计实验来调查五个问题:(1)在采样效率和计算时间效率方面,我们的方法与最先进的RL算法在经典的RL控制任务上相比如何?(2)我们的方法与之前的基于可微模拟的策略学习方法相比如何?(3)我们的方法是否适用于高维问题?(4)终端评估有必要吗?(5)选择短视(short horizon)长度h对我们的方法有多重要?
1. 实验设置
为了确保对计算时间性能的公平比较,我们在相同的GPU模型(titanX)和CPU模型(IntelXeon(R)E5-2620)上运行所有算法。此外,我们对所有算法进行超参数搜索,并报告每个问题的最佳超参数的性能。此外,我们还报告了每个算法对每个问题的5次单独运行的平均性能。实验装置的细节见附录A.2。我们还实验了一个固定的超参数设置和一个确定性的策略选择的我们的方法。由于空间的限制,这些实验的详细信息见附录A.4。
2. 基准控制问题
对于全面评估,我们选择了6个广泛的控制任务,包括5个不同复杂级别的经典RL任务,以及一个具有大动作空间的高维控制任务。所有任务都具有随机初始状态,以进一步提高学习策略的鲁棒性。我们在主要论文中介绍了四个具有代表性的任务,并将其他任务留在附录中。
经典任务:我们选择软骨杆摆动向上、蚂蚁和类人动物作为三个具有代表性的RL任务,如图1所示。他们的困难范围从最简单的无接触动力学(软骨向上摆动)到策略复杂且关联紧密(类人)。对于软骨杆向上摆动,我们使用H=240作为任务视界,而其他任务使用H=1000的视界。
类人MTU:为了评估我们的方法如何扩展到高维任务,我们研究了肌肉驱动的类人控制的一个具有挑战性的问题(图1,右)。我们使用了Lee等人(2019年)提出的类人模型的下半身,该模型包含152个肌肉-肌腱单位(MTUs)。每个MTU提供一个驱动的自由度,控制施加在连接体上附着部位的收缩力。这个问题的任务范围是H=1000。
为了与可微模拟兼容,每个问题的反馈公式都用来定义可微函数。每个任务的详细信息见附录A.3。
3. 实验结果
与无模型RL的比较。我们将SHAC与近端策略优化( Proximal Policy Optimization(PPO) (Schulman et al., 2017)(策略上)和Soft Actor-Critic (SAC) (Haarnoja et al., 2018)(策略外)进行了比较。我们使用来自RL游戏的高性能实现(马科维丘克和马科维丘克,2021年)。为了实现最先进的性能,我们遵循Makoviychuk等人(2021):所有模拟、反馈和观察数据保留在GPU上,并在模拟器之间作为PyRL算法Torch张量共享。PPO和SAC的实现是并行化的,并在矢量化的状态和操作上进行操作。在PPO中,我们在训练期间使用了短集长度、自适应学习率和大的小批量,以获得尽可能好的性能。
如图4的第一行所示,我们的方法显示,在三个经典的RL问题中,我们的样本识别效率比PPO和SAC有显著提高,特别是当问题的维度增加时(例如,类人猿)。可微模拟所提供的分析梯度使我们能够通过少量的样本有效地获得预期的策略梯度。相比之下,PPO和SAC必须收集更多蒙特卡罗样本来估计策略梯度。
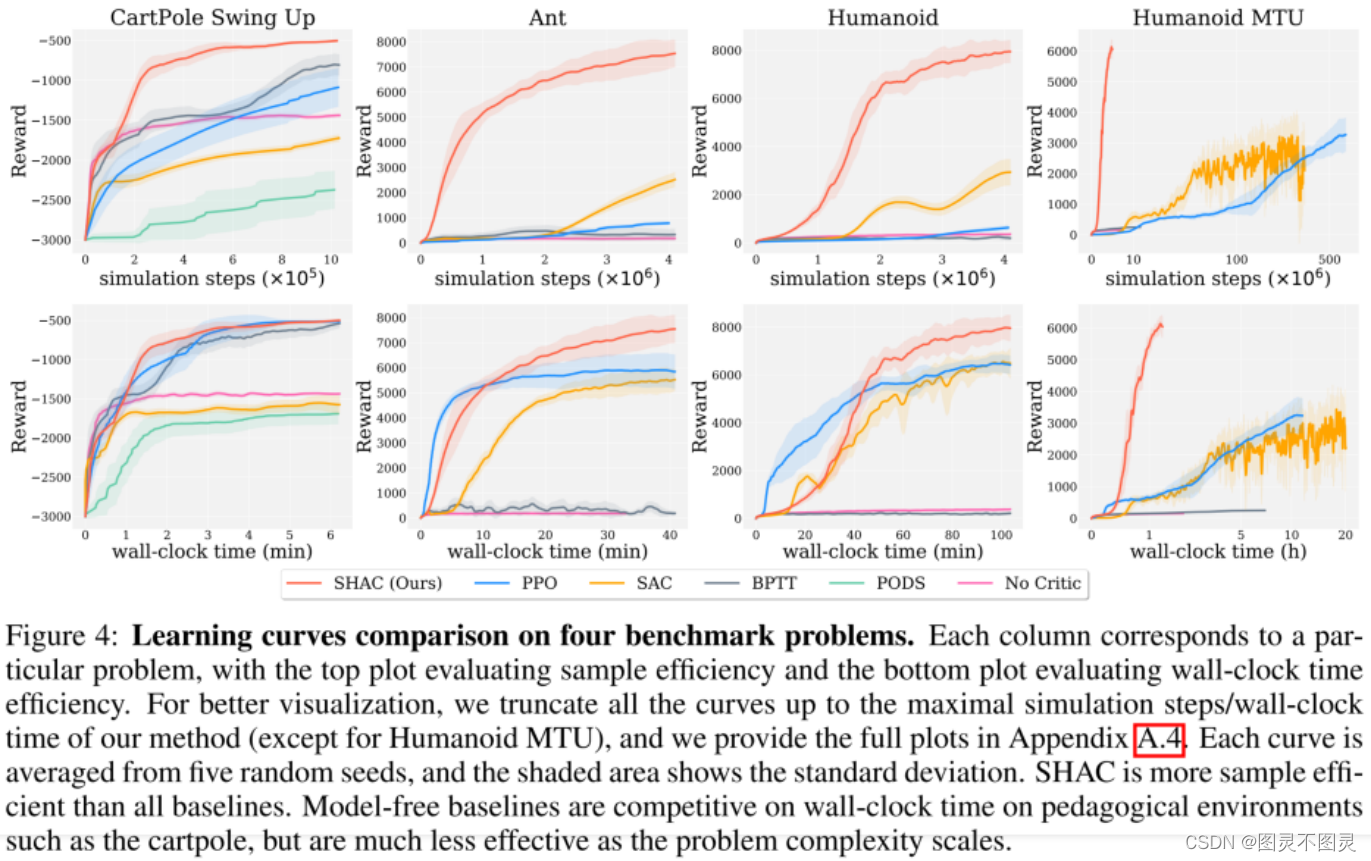
图4: 四个基准问题的学习曲线比较。每一列对应一个特定的问题,顶部图评估采样效率,底部图评估计算时间效率。为了更好地可视化,我们将所有曲线截断到我们的方法的最大模拟步长/计算时间(类人猿MTU除外),并在附录A.4中提供了完整的图。每条曲线都从5个随机的种子中取平均值,阴影区域表示标准偏差。SHAC比所有基线都更具有采样效率。在诸如碳基极等教学环境中,无模型基线在计算时间上具有竞争力,但随着问题复杂性的增加,其效率要低得多。
无模型算法通常比基于可微模拟的方法每次迭代成本更低;因此,评估计算时间效率也是有意义的,而不是单独的采样效率。如图4的第二行所示,我们的方法采样效率性能更强,计算时间比PPO、SAC的要少得多。有趣的是,我们的方法的训练速度在训练开始时比PPO要慢。我们假设在我们的方法中的目标值网络最初需要足够的过程(episodes)做准备。我们还注意到,我们的模拟的后退时间始终在向前通过的2×左右。这表明,我们的方法仍然有通过开发更优化的可微分模拟器来提高其整体计算时间效率的空间。我们在附录a.4中提供了我们的方法的详细的时间分类。
我们观察到,我们的方法在所有问题上都比RL方法获得了更好的策略。我们假设,虽然RL方法在远离(far from)解决方案的探索中是有效的,但它们难以准确地估计接近最优值的策略梯度,特别是在复杂的问题中。我们还将我们的方法与附录A.4中的另一种无模型方法REDQ(Chenetal.,2021b)进行了比较。
与以往基于梯度的方法比较。我们将我们的方法与三种基于层次的学习方法进行了比较:(1)通过时间反向传播(BPTT),它已在可微模拟文献中广泛使用(胡等人,2019;杜等人,2021年)、(2)PODS(Mora等人,2021年)和(3)基于样本增强模型的策略优化(SE-MBPO)(Qiao等人,2021年)。
BPTT:原始的BPTT方法在整个轨迹上反向传播梯度,这导致了梯度的爆炸,如第3.2节所示。我们修改了BPTT,以完成更短的任务窗口(碳极点64步,其他任务128步),并利用并行可微模拟同时采样多个轨迹,以提高其时间效率。如图4所示,BPTT成功地优化了无接触的卡特波尔摆动(CartPole Swing Up)策略,而在所有其他涉及接触的任务中,它迅速进入局部最小值。例如,BPTT为Ant学习的策略是一个向前倾斜的固定位置,这是一个局部最小值。
PODS:我们与一阶版本的PODS进行比较,因为二阶版本需要相对于整个动作轨迹的完整雅可比矩阵,这在反模可微模拟器(包括我们的)中是无效的。由于pod依赖于轨迹优化步骤来优化开环动作序列,因此尚不清楚如何适应在优化过程中轨迹长度可能发生变化的早期终止。因此,我们只在吊杆摆动问题上测试pod的性能。如图4所示,pod快速收敛到局部最优,无法进一步改进。这是因为pod被设计成一种高梯度开发却无法继续探索的方法。具体来说,在轨迹优化阶段应用的线搜索有助于它快速收敛,但也阻止了它探索更多的周围空间。此外,由线搜索和缓慢的模拟学习阶段引入的额外模拟调用使其在样本或计算时间效率方面的竞争力降低。
SE-MBPO:Qiao等人(2021)提出改进一种基于模型的RL方法MBPO(Janner等人,2019),通过使用可微模拟器的雅可比矩阵数据增强来增加推出样本。虽然SE-MBPO显示出较高的采样效率,但底层的基于模型的RL算法和非策略训练导致了更高的计算时间。相比之下,官方发布的SE-MBPO代码在Qiao等人(2021)使用的蚂蚁问题中需要8个小时来实现一个合理的策略,而我们的算法需要不到15分钟来在我们的蚂蚁问题中获得一个步态水平相同的策略。为了进行更公平的比较,我们将它们的实现应用于模拟器中的Ant问题。然而,我们发现,即使经过相当大的超参数调优,它也不能成功地优化策略。无论如何,两种算法之间的计算时间的差异是明显的,而SEMBPO的训练时间不太可能通过集成到我们的仿真环境中而得到显著改善。此外,正如Qiao等人(2021)所建议的那样,SE-MBPO并不能很好地推广到其他任务中,而我们的方法可以成功地应用于各种复杂级别的任务中。
对高维问题的可扩展性。我们在类人MTU例子上测试我们的算法和RL基线,以比较它们的高维问题的可扩展性。在较大的152维动作空间中,PPO和SAC都在努力学习该策略,如图4(右)所示。具体来说,PPO和SAC在经过超过10个小时的培训和数亿个样本后,学习到的策略明显更糟糕。这是因为,随着状态和行动空间变得较大,准确估计策略梯度所需的数据量会显著增加。相比之下,我们的方法尺度很好,因为通过重新参数化技术的可微模拟提供的更精确的梯度。为了达到与PPO相同的反馈水平,我们的方法只需要大约35分钟的训练和1.7米的模拟步骤。与PPO和SAC相比,其计算时间分别提高了17×和30×以上,样品效率提高了382×和170×。此外,经过1.5小时的训练,我们的方法能够从RL方法中找到性能最佳策略的两倍的策略。图5显示了一个学习过的跑步步态。这种对高维控制问题的可扩展性为在计算机动画中应用可微模拟开辟了新的可能性,其中,复杂角色模型被广泛用于提供更自然的运动。
终端评估的消融研究。我们在等式中引入了一个终端评估值Eq.5来解释在短过程(episode)后该策略的长期表现。在这个实验中,我们评估了这个术语的重要性。通过从等式中删除终端评估Eq.5,我们得到了一个等效的算法BPTT具有短范围窗口和折扣反馈计算(discounted reward calculation)。我们将这种不使用评估的变化应用于所有四个问题,并在图4中绘制了训练曲线,用“非评估(No Critic)”表示。如果没有终端批评函数,该算法就无法学习一个合理的策略,因为它只能优化策略的短期反馈,而不管其长期行为如何。
短视界长度h的研究。视界长度h的选择对我们的方法的性能很重要。h不能太小,因为它会导致更糟糕的值td-λ(Eq.7)并没有充分利用可微模拟器的能力来预测未来性能对策略权重的敏感性。另一方面,水平太长会导致嘈杂的优化现象和较少的策略更新。根据经验,我们发现短水平长度h=32和N=64平行轨迹对我们的实验中的所有任务都很有效。我们对短视野长度进行了研究,以显示该超参数的影响。我们用6个短视界长度h=4、8、16、32、64、128来运行我们的算法。我们为该变量设置了相应的平行轨迹数N=512、256、128、64、32、16,这样每个平行轨迹在单个学习事件中产生相同数量的样本。我们用5个单独的随机种子对相同数量反馈,以及总的训练时间。与预期的一样,当h=为16或32时,获得最佳反馈,训练时间随着h的增加呈线性增长。
结论和未来的工作
在这项工作中,我们提出了一种有效利用可微模拟策略学习。其核心是使用一个批评网络,作为一个平滑的代理来近似潜在的噪声优化现象。此外,还采用了截断的学习窗口来缓解深度反向传播路径中的梯度爆炸/消失问题。通过开发的并行可微仿真证明我们的方法比现有的RL和基于梯度的方法有更高的采样效率和计算时间效率,特别是当问题复杂度增加时。正如我们的实验所示,无模型方法在训练开始时证明了有效的学习,但SHAC能够在足够数量的发作后获得更好的表现。未来一个引人注目的研究方向是如何将无模型方法与我们的基于梯度的方法相结合,以利用两者的优势。此外,在我们的方法中,我们在整个学习过程中使用一个固定的和预先确定的短视野长度h;因此,未来的工作可能集中在实现一个随着优化现象的状态而变化自适应的短视野计划(schedule)。
边栏推荐
- MongoDB索引
- Strategy, tactics (and OKR)
- Doxorubicin loaded on metal organic framework MIL-88 DOX | folic acid modified uio-66-nh2 doxorubicin loaded [email
- 7-7 12-24 hour system
- page owner特性浅析
- Redis: operation command of string type data
- 战略、战术(和 OKR)
- Polestar美股上市:5.5万台交付如何支持得起超200亿美元估值
- 虽然不一定最优秀,但一定是最努力的!
- JS new challenges
猜你喜欢
FPGA test method takes mentor tool as an example

Message subscription and publishing

7-10 calculate salary
Vite project commissioning
 [email protected] Nanoparticles) | nano metal organic framework carry"/>
[email protected] Nanoparticles) | nano metal organic framework carry"/>Metal organic framework material zif-8 containing curcumin( [email protected] Nanoparticles) | nano metal organic framework carry

Exercise 6-2 using functions to sum special A-string sequences
JS first summary

剑指 Offer 28. 对称的二叉树

【吉林大学】考研初试复试资料分享
Configure stylelint
随机推荐
Scroll detection of the navigation bar enables the navigation bar to slide and fix with no content
中国锂电池电解液行业市场专项调研报告(2022版)
Exercise 7-6 count capital consonants
etcd集群权限管理和账号密码使用
Concat and concat_ Ws() differences and groups_ Use of concat() and repeat() functions
Current situation, analysis and prediction of information and innovation industry
“又土又穷”的草根高校,凭什么被称为“东北小清华”?
Polestar美股上市:5.5万台交付如何支持得起超200亿美元估值
Page generation QR code
7-11 calculation of residential water charges by sections
Understanding of closures
Exercise 10-6 recursively find Fabonacci sequence
jvm-类加载
The small project (servlet+jsp+mysql+el+jstl) completes a servlet with login function, with the operation of adding, deleting, modifying and querying. Realize login authentication, prevent illegal log
JVM class loading
Exercise 8-7 string sorting
Invalid Z-index problem
中感微冲刺科创板:年营收2.4亿净亏1782万 拟募资6亿
concat和concat_ws()区别及group_concat()和repeat()函数的使用
Exercise 6-1 classify and count the number of characters