当前位置:网站首页>[Paper reading] Mastering the game of Go with deep neural networks and tree search
[Paper reading] Mastering the game of Go with deep neural networks and tree search
2022-07-31 03:36:00 【meet the devil】
【论文阅读】Mastering the game of Go with deep neural networks and tree search

1 本文解决了什么问题?
在所有的 完全信息博弈 中,There is an optimal value function v ∗ ( s ) v^{*}(s) v∗(s),It determines the state s s s The game of the final output.Complete information game by recursively computing the optimal value function in the search tree to solve.But a search tree contains a b d b^d bd A possible game sequence( b b b For the action space size,The branches of the tree number; d d d Length for the game,树的深度),If in big game scene,Search space will be too big(在围棋中 b = 250 , d = 150 b=250, d=150 b=250,d=150),Therefore exhaustive search is not realistic.
At present in the field of the game's strongest technology is based on MCTS 的,And through the training of human experts to predict the fewest strategy to strengthen.These strategies for action to reduce the search scope some high probability,And during the sampling sampling was carried out on the action.但是,Previous research is limited to Based on the input characteristics of linear combination Shallow strategy or value of the function.CNN 在视觉领域大放异彩,With a strong feature extraction ability.So this article in the game a similar architecture,Will build board for a 19 × 19 19 \times 19 19×19 的图像,To build and use the convolution layer location said.
总而言之,This article USES the value network to estimate the position,Use strategy network to sampling action.The depth of neural network by combining The supervision of experts from the human games to learn 以及 Reinforcement learning from the game 来进行训练.在没有任何前瞻搜索的情况下,Neural network chess level corresponds to the most advanced monte carlo simulation tree search program thousands of randomly from the game.此外,This paper puts forward a new search algorithm,Combining monte carlo simulation and value and policy network.Use the search algorithm,本文程序 AlphaGo For other go programs since 99.8%,并以 5 比 0 击败了人类欧洲围棋冠军.
2 解决方法是什么?
In this paper, the neural network training stage as shown in the figure below,即:
首先,From a human expert action in a supervised learning strategy training network p σ p_{\sigma} pσ;
同时,Training a fast move strategy p π p_\pi pπ,So that in the simulation stage fast sampling action;
下一步,A reinforcement learning strategy training network p ρ p_\rho pρ,The result of the game by optimizing the network to improve the supervision and learning strategy p σ p_{\sigma} pσ;
(This will make supervision and learning strategy network towards the win,Rather than to maximize the accuracy of the prediction)
最后,Training a network of value v θ v_{\theta} vθ,It can predict RL The winner of the policy network and since the game.

2.1 策略网络的监督学习
The first stage of the training process is the use of supervised learning strategies to initialize the network.监督学习策略网络 p σ ( a ∣ s ) p_{\sigma}(a|s) pσ(a∣s) Convolution and nonlinear activation layer between the parameters of the as σ \sigma σ,Then connected to a softmax 层输出所有合法动作 a a a 的概率分布.网络的输入 s s s Is the state board of simple said,By randomly sampling status-动作对 ( s , a ) (s, a) (s,a) ,Using the stochastic gradient descent maximization in the state s s s 下选择动作 a a a 的可能性.
Δ σ ∝ ∂ log p σ ( a ∣ s ) ∂ σ \Delta \sigma \propto \frac{\partial \log p_{\sigma}(a \mid s)}{\partial \sigma} Δσ∝∂σ∂logpσ(a∣s)
作者训练了一个 13 Supervised learning strategy network layer.When the author use all input characteristics,Supervised learning strategy network to predict human expert movements on the test set(落子)准确率为 57.0%.When using only the original board and move the accuracy in history as the input for 55.7%,相比之下,The most advanced level in the work for 44.4%.
Supervised learning strategy network prediction accuracy of tiny ascend it will boost the game ability,The more exact winning percentage is higher,如下图所示.
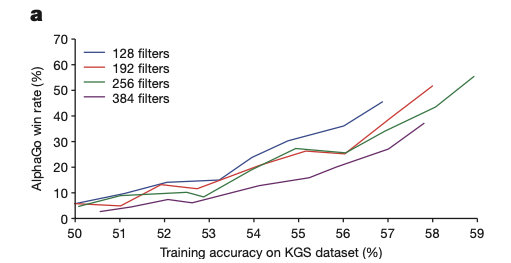
但是,Although the larger network can bring better accuracy,But in the search process evaluation is relatively slow.因此,The author training a faster,But not very accurate 快速走子网络 p π ( a ∣ s ) p_{\pi}(a|s) pπ(a∣s),The network parameters as π \pi π.它实现了 24.2% 的准确度,仅使用 2μs 来选择操作(Supervised learning strategy network need to 3ms).
2.2 策略网络的强化学习
The second phase of training through policy gradient reinforcement learning strategy to improve the network.强化学习策略网络 p ρ p_{\rho} pρ And supervised learning strategy network has the same structure,At the same time the weight of it ρ \rho ρ Is initialized to supervised learning strategy network weight value,即 ρ = σ \rho=\sigma ρ=σ.The strategy of the author in the current network p ρ p_{\rho} pρ Iteration strategy and random selection of history between the network game.In this way, randomly selected from a rival, in the pool,Can prevent excessive fitting the current strategy,从而稳定训练.
Step for all the end of time t < T t < T t<T,The authors use the reward function r ( s ) r(s) r(s) 为零.结果 z t = ± r ( s T ) z_t =±r(s_T) zt=±r(sT) For the current players in time steps t t t The ultimate reward at the end of the game:1 代表赢,−1 代表输.然后,在每个时间步 t t t 中,By rising along the direction of the expected utility maximization of stochastic gradient to update the weight.
Δ ρ ∝ ∂ log p ρ ( a t ∣ s t ) ∂ ρ z t \Delta \rho \propto \frac{\partial \log p_{\rho}\left(a_{t} \mid s_{t}\right)}{\partial \rho} z_{t} Δρ∝∂ρ∂logpρ(at∣st)zt
Through the action on the probability distribution action sampling a t ∼ p ρ ( ⋅ ∣ s t ) a_{t} \sim p_{\rho}\left(\cdot \mid s_{t}\right) at∼pρ(⋅∣st) To assess the reinforcement learning strategy network performance in the game.When carries on the confrontation,Reinforcement learning strategies over supervision and learning strategy network game winning 80%.
2.3 Value network of reinforcement learning
The last stage of the training process focuses on the assessment board,估计一个价值函数 v p ( s ) v^p(s) vp(s),Both sides of the function prediction using strategy p p p For the position of the game s s s 的结果.
v p ( s ) = E [ z t ∣ s t = s , a t … T ∼ p ] v^{p}(s)=\mathbb{E}\left[z_{t} \mid s_{t}=s, a_{t \ldots T} \sim p\right] vp(s)=E[zt∣st=s,at…T∼p]
The author used to take parameters θ \theta θ The value of the network v θ ( s ) v_{\theta}(s) vθ(s) 来近似价值函数.Value network structure and strategy of the network structure is the same,But its output is a single scalar forecast,而不是概率分布.The author through to the state-结果对 ( s , z ) (s, z) (s,z) The return of the training value of network weights,Using the stochastic gradient descent to minimize forecast v θ ( s ) v_θ(s) vθ(s) 与相应结果 z z z 之间的均方误差(MSE).
Δ θ ∝ ∂ v θ ( s ) ∂ θ ( z − v θ ( s ) ) \Delta \theta \propto \frac{\partial v_{\theta}(s)}{\partial \theta}\left(z-v_{\theta}(s)\right) Δθ∝∂θ∂vθ(s)(z−vθ(s))
If you use the full game data to predict the result of simple method will lead to a fitting.原因在于,Continuous board position is closely related to,The difference is only one piece,But back to target in the whole game is the same.When on training data set in this way,Remember the value network game results,Instead of generalization to the new board position,On the test set minimumMSE为 0.37,而在训练集上为 0.19.为了缓解这个问题,This paper produces a new since the game data set,包含 3000万 Different board position,Every position from a separation rate of sampling in the game.Every game inRLStrategy between network and its own,直到游戏终止.The training data set,训练集和测试集的MSEs分别为 0.226 和 0.234,Before fitting the minimum.
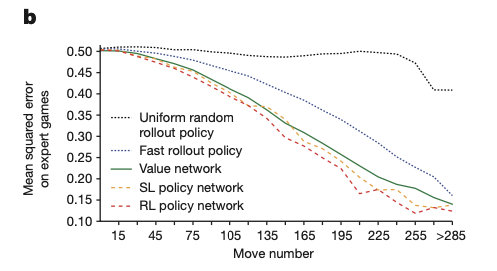
The diagram below shows the value of network board position evaluation accuracy,With rapid move strategy p π p_π pπ Compared with the monte carlo simulation,Value function is always more accurate.利用RL策略网络 p ρ p_ρ pρ 对 v θ ( s ) v_θ(s) vθ(s) A single assessment was close to the accuracy of monte carlo simulation,但使用了15000倍的计算量.
2.4 使用策略和价值网络进行搜索
AlphaGo Combination of strategy and value network in aMCTS算法中,The algorithm through the search action selection in advance.

Each side in the search tree ( s , a ) (s,a) (s,a),Store the value an action Q ( s , a ) Q(s,a) Q(s,a),访问次数 N ( s , a ) N(s,a) N(s,a) 和先验概率 P ( s , a ) P(s,a) P(s,a).Simulation traversal tree(That there is no backup complete game down traversal tree)从根状态开始.Every step of the simulation every time t t t 中,从状态 s t s_t st 中选择一个动作 a t a_t at,To maximize the action value and reward the sum.
a t = argmax a ( Q ( s t , a ) + u ( s t , a ) ) a_{t}=\underset{a}{\operatorname{argmax}}\left(Q\left(s_{t}, a\right)+u\left(s_{t}, a\right)\right) at=aargmax(Q(st,a)+u(st,a))
其中,
u ( s , a ) ∝ P ( s , a ) 1 + N ( s , a ) u(s, a) \propto \frac{P(s, a)}{1+N(s, a)} u(s,a)∝1+N(s,a)P(s,a)
It is proportional to the prior probability,But gradually with the increase of access frequency attenuation to encourage exploration.当在步骤 L L L When reach the leaf node s L s_L sL,
Leaf nodes can扩展.Leaf node board position by the supervised learning strategy network p σ p_{\sigma} pσ 只处理一次,For each legal action a a a The probability of the output is stored as a priori probability P P P, P ( s , a ) = p σ ( a ∣ s ) P(s, a)=p_{\sigma}(a \mid s) P(s,a)=pσ(a∣s).
叶节点的评估有两种不同的方式:首先,By the value network v θ ( s L ) v_θ(s_L) vθ(sL) 进行评估;第二,Through the stochastic simulation results z L z_L zL 进行评估,Use quick move strategy p π p_π pπ,直到终端步骤 T T T;Using hybrid parameter λ λ λ,Will this combination to the leaf node evaluation V ( s L ) V(s_L) V(sL) 中.
V ( s L ) = ( 1 − λ ) v θ ( s L ) + λ z L V\left(s_{L}\right)=(1-\lambda) v_{\theta}\left(s_{L}\right)+\lambda z_{L} V(sL)=(1−λ)vθ(sL)+λzL
在模拟结束时,Update all traverse the action values of the edge and visited.Each edge will be accumulated after all, on the edge of the simulation and the average number of visits:
N ( s , a ) = ∑ i = 1 n 1 ( s , a , i ) Q ( s , a ) = 1 N ( s , a ) ∑ i = 1 n 1 ( s , a , i ) V ( s L i ) \begin{aligned} &N(s, a)=\sum_{i=1}^{n} 1(s, a, i) \\ &Q(s, a)=\frac{1}{N(s, a)} \sum_{i=1}^{n} 1(s, a, i) V\left(s_{L}^{i}\right) \end{aligned} N(s,a)=i=1∑n1(s,a,i)Q(s,a)=N(s,a)1i=1∑n1(s,a,i)V(sLi)
其中 s L i s^i_L sLi 是第 i i i 次模拟的叶节点, 1 ( s , a , i 1(s, a, i 1(s,a,i ) 表示第 i i i Whether the time simulation traversing an edge ( s , a ) (s, a) (s,a).一旦搜索完成,Algorithm from the root location selection of the most visited board action.
边栏推荐
- Why SocialFi achievement Web3 decentralized social in the future
- STM32 problem collection
- 组件传值 provide/inject
- Day32 LeetCode
- Mysql 45 study notes (twenty-five) MYSQL guarantees high availability
- Getting Started with CefSharp - winform
- $attrs/$listeners
- $attrs/$listeners
- 浅识Flutter 基本组件之CheckBox组件
- [Swift]自定义点击APP图标弹出的快捷方式
猜你喜欢
![[Swift] Customize the shortcut that pops up by clicking the APP icon](/img/d4/84b237995fc3d3700916eb57f6670d.png)
[Swift] Customize the shortcut that pops up by clicking the APP icon
type_traits元编程库学习

LeetCode simple problem to find the subsequence of length K with the largest sum

What is a system?
识Flutter 基本组件之showTimePicker 方法

Database implements distributed locks
数据库实现分布式锁
【Exception】The field file exceeds its maximum permitted size of 1048576 bytes.
Mysql 45 study notes (twenty-five) MYSQL guarantees high availability

大小端模式
随机推荐
some of my own thoughts
No qualifying bean of type 问题
[Compilation principle] Lexical analysis program design principle and implementation
Select the smoke test case, and make the first pass for the product package entering QA
2022 Nioke Multi-School League Game 4 Solution
Redis uses LIST to cache the latest comments
Ambiguous method call.both
LeetCode每日一练 —— OR36 链表的回文结构
Getting Started with CefSharp - winform
【AUTOSAR-RTE】-4-Port和Interface以及Data Type
自己的一些思考
Point Cloud DBSCAN Clustering (MATLAB, not built-in function)
Component pass value provide/inject
Database implements distributed locks
type_traits metaprogramming library learning
【HCIP】ISIS
安全20220715
els 方块向右移
Safety 20220712
Safety 20220722