当前位置:网站首页>(tree) Last Common Ancestor (LCA)
(tree) Last Common Ancestor (LCA)
2022-07-31 03:33:00 【God-sent fine lotus】
前言
Like the name of this question,Our purpose is to find the nearest common ancestor of two points in a tree
Usually, the operation of the tree is naturally inseparable from the search,其中dfsThe understanding and writing must be familiar with the heart
解决LCAThere are three common algorithms,Tarjan,树链剖分,倍增算法
参考资料:
322 最近公共祖先 Tarjan算法_哔哩哔哩_bilibili
The table below is also organized by Mr. Dong Xiao
倍增算法 Tarjan算法 树链剖分 数据结构 fa[][], dep[]fa[], vis[], query[], ans[]fa[], dep[], sz[], son[], top[]算法 倍增法
Search deeply,跳跃查询并查集
深搜, When I return, I refer to my father, Search when you are away重链剖分
Search and play the table twice,跳跃查询时间复杂度 O ( ( n + m ) l o g n ) {O((n+m)logn)} O((n+m)logn) O ( n + m ) {O(n+m)} O(n+m) O ( n + m l o g n ) {O(n+mlogn)} O(n+mlogn) 其中,The multiplication algorithm is less efficient
Tarjan是离线算法
Required for tree chain splittingdfs两次
It can be said that each algorithm has its own characteristics
练习题:
The code in this article is for this question:洛谷:P3379 【模板】最近公共祖先(LCA)
杭电:2586 How far away ? This question is weighted
具体算法
Tarjan
Tarjan is an offline algorithm
Here is a clever use of the help of the union check set
Record all query status first,Force conversion to offline algorithm
在每次dfsAfter finishing child nodes,Let the union of child nodes point to the current node (子->父)
在当前节点dfs完毕后,Check the search set,Whether there is a corresponding query point
若存在,and have been visited,It means that the union of corresponding points has been recorded
At this point, the corresponding query group can be recordedlca,注意这里一定要写路径压缩的并查集
Because we can pass constant compression,Point the point of the union to the top of the tree continuously
Ultimately make sure to compress to the targetlca
/** * https://www.luogu.com.cn/problem/P3379 * P3379 【模板】最近公共祖先(LCA) * Tarjan */
#include <bits/stdc++.h>
using namespace std;
const int M = 10 + 5 * 100000;
vector<vector<int>> graph(M); // 存图(树)
vector<vector<pair<int, int>>> query(M); // 询问
int father[M]; // 并查集
bool vis[M]; // vis
int ans[M]; // 第几组询问的答案
void initUnionFind(int n) {
for (int i = 0; i <= n; i++) {
father[i] = i;
}
}
// 必须路径压缩
int unionFind(int x) {
return x == father[x] ? x : father[x] = unionFind(father[x]);
}
// Tarjan 算法
void Tarjan(int cur) {
vis[cur] = true;
for (int& nex : graph[cur]) {
if (!vis[nex]) {
Tarjan(nex);
// 核心 nex 指向 cur
father[nex] = cur;
}
}
// 递归完毕
for (auto& it : query[cur]) {
int &to = it.first, &idx = it.second;
// 若访问过,则可以记录
if (vis[to]) {
ans[idx] = unionFind(to);
}
}
}
int main() {
// 边数 询问数 根节点
int n, m, root;
scanf("%d %d %d", &n, &m, &root);
// 初始化并查集
initUnionFind(n);
// 存无向图
for (int i = 1, u, v; i <= n - 1; i++) {
scanf("%d %d", &u, &v);
graph[v].emplace_back(u);
graph[u].emplace_back(v);
}
// 离线算法,Know everything first,再算
// 询问 也要双向存
for (int i = 1, x, y; i <= m; i++) {
scanf("%d %d", &x, &y);
query[x].emplace_back(y, i);
query[y].emplace_back(x, i);
}
Tarjan(root);
for (int i = 1; i <= m; i++) {
printf("%d\n", ans[i]);
}
return 0;
}
树链剖分
树链剖分 分为很多种,What is written here is the heavy chain dissection
The weight here represents the number of nodes in the current tree
When a certain subtree has the largest number of all subtrees,This node is the so-called heavy child
Then the current point is the heavy chain head of all points in this heavy subtree
The remaining subtrees then independently develop heavy chains
在求lca时,Constantly relying on the jump of the chain head node,across a large number of nodes
dfs1()主要获得
son[], father[], deep[]其中size[]is an auxiliary search outson[]用的
dfs2()借助
son[]和father[]求出top[](重链的头)
lca()首先明确一点,The chain head node of the heavy chain head is itself
Constantly judge whether the chain heads of two points are equal
If not, let the deeper point jump to the parent node of the chain head
This way the deep point can get a lot closer to the root node,And can be updated to the new chain,can be re-judged
最终,When the two chain heads are equal,Returns a point with a lower depth,获得lca
/** * https://www.luogu.com.cn/problem/P3379 * P3379 【模板】最近公共祖先(LCA) * 树链剖分 (重链) */
#include <bits/stdc++.h>
using namespace std;
const int M = 10 + 5 * 100000;
vector<vector<int>> graph(M); // 图
vector<int> father(M); // 父节点
vector<int> son(M); // 重孩子
vector<int> size(M); // 子树节点个数
vector<int> deep(M); // 深度,根节点为1
vector<int> top(M); // 重链的头,祖宗
void dfs1(int cur, int from) {
deep[cur] = deep[from] + 1; // 深度,从来向转化来
father[cur] = from; // 父节点,记录来向
size[cur] = 1; // 子树的节点数量
son[cur] = 0; // 重孩子 (先默认0表示无)
for (int& to : graph[cur]) {
// 避免环
if (to == from) {
continue;
}
// 处理子节点
dfs1(to, cur);
// 节点数量叠加
size[cur] += size[to];
// 松弛操作,更新重孩子
if (size[son[cur]] < size[to]) {
son[cur] = to;
}
}
}
void dfs2(int cur, int grandfather) {
top[cur] = grandfather; // top记录祖先
// 优先dfs重儿子
if (son[cur] != 0) {
dfs2(son[cur], grandfather);
}
for (int& to : graph[cur]) {
// 不是cur的父节点,不是重孩子
if (to == father[cur] || to == son[cur]) {
continue;
}
// dfs轻孩子
dfs2(to, to);
}
}
int lca(int x, int y) {
// 直到top祖宗想等
while (top[x] != top[y]) {
// 比较top祖先的深度,x始终设定为更深的
if (deep[top[x]] < deep[top[y]]) {
swap(x, y);
}
// 直接跳到top的父节点
x = father[top[x]];
}
// 在同一个重链中,深度更小的则为祖宗
return deep[x] < deep[y] ? x : y;
}
int main() {
// 边数 询问数 根节点
int n, m, root;
cin >> n >> m >> root;
// 该树编号 [1, n]
// 本题仅仅说有边,未说方向
for (int i = 1, u, v; i <= n - 1; i++) {
cin >> u >> v;
graph[v].emplace_back(u);
graph[u].emplace_back(v);
}
// 树链剖分 重链
dfs1(root, 0);
dfs2(root, root);
for (int i = 1, x, y; i <= m; i++) {
cin >> x >> y;
cout << lca(x, y) << endl;
}
return 0;
}
倍增算法
倍增
cin, cout不能过
倍增算法 The essence is a kind of dynamic programming with the help of binary,And here is the operation on the tree,It can also be said to be a tree shapedp了
通常定义
father[i][j]表示i到j的状态,And here is multipliedj指的是2的倍数即
2^j,Multiply in binary,This is called multiplication
dfs这里的dfsThe multiplication is mainly based on depth
Jump from father to grandpa,Jump from grandfather to great grandfather
由于是dfsWe can deal with nodes with high rank first
Subsequent recursion can use the already processed high-level nodes to play the multiplication table
lcaThe search here is also mostly handled by pulling high depths back to low depths
The high-depth nodes of the two are processed first
Since any decimal number can be decomposed into binary,Therefore, we must be able to jump the distance we need
Let's jump first,Taking small steps in the jump ensures that we can reach our target position with one run of the loop
After the jump, the situation where the two nodes overlap will be judged first
此时,The heights of the two points are equal,Then both jump up together.
Note that we can only jump to togetherlca的下一层节点
If you continue to jump down,In the end, it must be jumped togetherroot,那就没有任何意义了
/** * https://www.luogu.com.cn/problem/P3379 * P3379 【模板】最近公共祖先(LCA) * 倍增算法 * cin cout 超时 */
#include <bits/stdc++.h>
using namespace std;
const int M = 10 + 100000 * 5;
// log2(5e5 + 10) = 18.9
vector<vector<int>> graph(M); // 存图
vector<int> deep(M); // 深度
vector<vector<int>> father(M, vector<int>(20)); // i点跳2^j步到达的点(点号)
void dfs(int cur, int from) {
deep[cur] = deep[from] + 1; // 深度 + 1
father[cur][0] = from; // 跳2^0=1A step is the immediate parent node
// Jump to the grandpa node with the help of the parent node of the previous layer
int log = log2(M + 1);
for (int i = 1; i <= log; i++) {
father[cur][i] = father[(father[cur][i - 1])][i - 1];
}
for (int& nex : graph[cur]) {
if (nex == from) {
continue;
}
dfs(nex, cur);
}
}
int lca(int u, int v) {
// uSet to a point with a large depth,对umake a hop
if (deep[u] < deep[v]) {
swap(u, v);
}
// Calculate the depth,Filter out some loops
// +1保精度
int log = log2(deep[u] + 1);
// 二进制拆分,Jump first
// Jump the deeper ones to the same depth
for (int i = log; i >= 0; i--) {
if (deep[father[u][i]] >= deep[v]) {
u = father[u][i];
}
}
// v正好是u的lca,可以直接return
if (u == v) {
return v;
}
for (int i = log; i >= 0; i--) {
// 有父节点,to be able to jump
// 实际可以省略,Because it is the same level,都是0则if为false
// If the parent node is different, you have to jump
if (father[u][i] != 0 && father[u][i] != father[v][i]) {
u = father[u][i];
v = father[v][i];
}
}
// 退出循环时,Guaranteed to be at two pointslcaon the same level directly below
return father[u][0];
}
int main() {
// 边数 询问数 根节点
int n, m, root;
scanf("%d %d %d", &n, &m, &root);
// 该树编号 [1, n]
// 本题仅仅说有边,未说方向
for (int i = 1, u, v; i <= n - 1; i++) {
scanf("%d %d", &u, &v);
graph[v].emplace_back(u);
graph[u].emplace_back(v);
}
// Preprocessing multipliedfather[i][2^j]和deep[]
dfs(root, 0);
for (int i = 1, x, y; i <= m; i++) {
scanf("%d %d", &x, &y);
printf("%d\n", lca(x, y));
}
return 0;
}
END
边栏推荐
- SIP Protocol Standard and Implementation Mechanism
- [Godot][GDScript] 二维洞穴地图随机生成
- [Dynamic programming] Maximum sum of consecutive subarrays
- Distributed locks and three implementation methods
- Golang中的addressable
- [C language] General method of expression evaluation
- False positives and false negatives in testing are equally worthy of repeated corrections
- 安全20220715
- Redis 使用LIST做最新评论缓存
- Several common errors when using MP
猜你喜欢

Use of QML
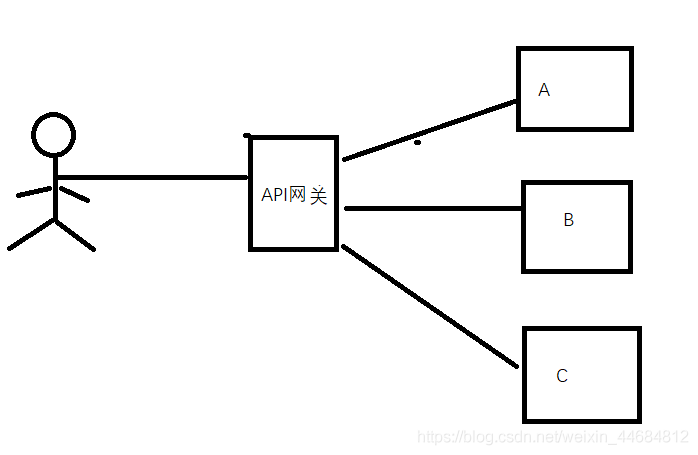
分布式系统架构需要解决的问题

LeetCode简单题之两个数组间的距离值

LeetCode每日一练 —— OR36 链表的回文结构

Just debuted "Fight to Fame", safety and comfort are not lost
Know the showTimePicker method of the basic components of Flutter

Unity2D 自定义Scriptable Tiles的理解与使用(四)——开始着手构建一个基于Tile类的自定义tile(下)
![[C language] Three-pointed chess (classic solution + list diagram)](/img/64/18ed08b64f9618bbd7f24ee16e6a6f.jpg)
[C language] Three-pointed chess (classic solution + list diagram)
Getting Started with CefSharp - winform

TCP详解(三)
随机推荐
els block to the right
SQL Interview Questions (Key Points)
从滴滴罚款后数据治理思考
TCP详解(一)
C primer plus study notes - 8, structure
RESTful api接口设计规范
LocalDate加减操作及比较大小
识Flutter 基本组件之showTimePicker 方法
点云DBSCAN聚类(MATLAB,非内置函数)
2022 Nioke Multi-School League Game 4 Solution
BP神经网络
Problems that need to be solved in distributed system architecture
安全20220722
Why SocialFi achievement Web3 decentralized social in the future
想从手工测试转岗自动化测试,需要学习哪些技能?
els 方块向右移动边界判断、向下加速
errno错误码及含义(中文)
【Cocos Creator 3.5】缓动系统停止所有动画
STM32问题合集
TCP和UDP详解