当前位置:网站首页>【论文阅读】Mastering the game of Go with deep neural networks and tree search
【论文阅读】Mastering the game of Go with deep neural networks and tree search
2022-07-31 03:23:00 【见见大魔王】
【论文阅读】Mastering the game of Go with deep neural networks and tree search

1 本文解决了什么问题?
在所有的 完全信息博弈 中,存在一个最优价值函数 v ∗ ( s ) v^{*}(s) v∗(s),它决定了在状态 s s s 下博弈的最终输出。完全信息博弈可以通过递归地计算搜索树中的最优价值函数来解决。但一棵搜索树包含了 b d b^d bd 个可能的博弈序列( b b b 为动作空间大小,树的分支数量; d d d 为博弈长度,树的深度),如果在大型博弈场景中,搜索的空间就会特别庞大(在围棋中 b = 250 , d = 150 b=250, d=150 b=250,d=150),因此穷举搜索是不现实的。
目前在围棋领域中最强的技术是基于 MCTS 的,并通过训练来预测人类专家的棋路的策略进行加强。这些策略用于将搜索范围缩小到一些高概率的行动,并在采样期间对行动进行抽样。但是,以前的研究仅限于 基于输入特征线性组合 的浅层策略或价值函数。CNN 在视觉领域大放异彩,具有强大的特征提取能力。因此本文在围棋游戏中采用类似的架构,将棋盘构建为一个 19 × 19 19 \times 19 19×19 的图像,并使用卷积层来构建位置的表示。
总而言之,本文使用值网络来评估位置,使用策略网络来采样行动。这些深度神经网络通过结合 来自人类专家游戏的监督学习 以及 来自自博弈的强化学习 来进行训练。在没有任何前瞻搜索的情况下,神经网络下围棋的水平相当于最先进的蒙特卡洛树搜索程序模拟数千场随机的自博弈。此外,本文提出了新的搜索算法,将蒙特卡洛模拟与价值和政策网络相结合。利用该搜索算法,本文程序 AlphaGo 对其他围棋程序的胜率达到 99.8%,并以 5 比 0 击败了人类欧洲围棋冠军。
2 解决方法是什么?
本文提出的神经网络的训练阶段如下图所示,即:
首先,从人类专家动作中训练一个监督学习的策略网络 p σ p_{\sigma} pσ;
同时,训练一个快速走子策略 p π p_\pi pπ,以便在模拟阶段快速采样动作;
下一步,训练一个强化学习策略网络 p ρ p_\rho pρ,通过优化自博弈的结果来改进监督学习策略网络 p σ p_{\sigma} pσ;
(这将使得监督学习策略网络朝着赢得比赛的目标前进,而不是最大化预测的准确性)
最后,训练一个价值网络 v θ v_{\theta} vθ,它能预测 RL 策略网络与自博弈的赢家。

2.1 策略网络的监督学习
训练流程的第一阶段是使用监督学习来初始化策略网络。监督学习策略网络 p σ ( a ∣ s ) p_{\sigma}(a|s) pσ(a∣s) 的卷积层与非线性激活层之间的参数为 σ \sigma σ,随后接上一个 softmax 层输出所有合法动作 a a a 的概率分布。网络的输入 s s s 是棋盘状态的简单表示,通过随机采样状态-动作对 ( s , a ) (s, a) (s,a) ,使用随机梯度下降最大化在状态 s s s 下选择动作 a a a 的可能性。
Δ σ ∝ ∂ log p σ ( a ∣ s ) ∂ σ \Delta \sigma \propto \frac{\partial \log p_{\sigma}(a \mid s)}{\partial \sigma} Δσ∝∂σ∂logpσ(a∣s)
作者训练了一个 13 层的监督学习策略网络。当作者使用所有输入特征时,监督学习策略网络预测人类专家在测试集上的动作(落子)准确率为 57.0%。当仅使用原始棋盘和移动历史作为输入的准确率为 55.7%,相比之下,当前工作中最先进水平为 44.4%。
监督学习策略网络预测准确度的微小提升会对博弈能力带来大幅提升,即越准胜率越高,如下图所示。
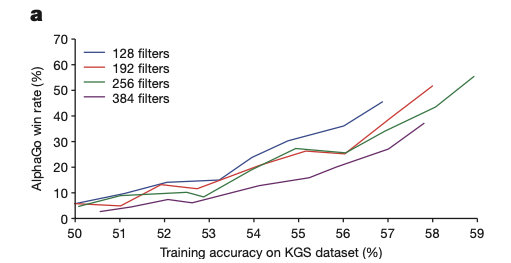
但是,较大的网络虽然能够带来比较好的准确率,但在搜索过程中评估速度就比较慢了。因此,作者训练了一个更快,但不太准的 快速走子网络 p π ( a ∣ s ) p_{\pi}(a|s) pπ(a∣s),其网络参数为 π \pi π。它实现了 24.2% 的准确度,仅使用 2μs 来选择操作(监督学习策略网络需要 3ms)。
2.2 策略网络的强化学习
训练的第二阶段旨在通过策略梯度强化学习来改进策略网络。强化学习策略网络 p ρ p_{\rho} pρ 与监督学习策略网络具有相同的结构,同时它的权重 ρ \rho ρ 被初始化为监督学习策略网络的权重值,即 ρ = σ \rho=\sigma ρ=σ。作者在当前的策略网络 p ρ p_{\rho} pρ 和随机选择的历史迭代策略网络之间进行博弈。以这种方式从一个对手池中随机抽取,可以防止过度拟合当前的策略,从而稳定训练。
对于所有非终结时间步 t < T t < T t<T,作者使用的奖励函数 r ( s ) r(s) r(s) 为零。结果 z t = ± r ( s T ) z_t =±r(s_T) zt=±r(sT) 为当前玩家在时间步骤 t t t 时在游戏结束时的终极奖励:1 代表赢,−1 代表输。然后,在每个时间步 t t t 中,通过沿期望收益最大化的方向上升的随机梯度来更新权重。
Δ ρ ∝ ∂ log p ρ ( a t ∣ s t ) ∂ ρ z t \Delta \rho \propto \frac{\partial \log p_{\rho}\left(a_{t} \mid s_{t}\right)}{\partial \rho} z_{t} Δρ∝∂ρ∂logpρ(at∣st)zt
通过在动作概率分布上进行动作采样 a t ∼ p ρ ( ⋅ ∣ s t ) a_{t} \sim p_{\rho}\left(\cdot \mid s_{t}\right) at∼pρ(⋅∣st) 来评估强化学习策略网络在博弈中的性能表现。当进行正面交锋时,强化学习策略网络战胜监督学习策略网络的游戏胜率超过 80%。
2.3 值网络的强化学习
训练流程的最后阶段侧重于棋盘评估,估计一个价值函数 v p ( s ) v^p(s) vp(s),该函数预测双方使用策略 p p p 进行的博弈的位置 s s s 的结果。
v p ( s ) = E [ z t ∣ s t = s , a t … T ∼ p ] v^{p}(s)=\mathbb{E}\left[z_{t} \mid s_{t}=s, a_{t \ldots T} \sim p\right] vp(s)=E[zt∣st=s,at…T∼p]
作者使用带参数 θ \theta θ 的值网络 v θ ( s ) v_{\theta}(s) vθ(s) 来近似价值函数。值网络的结构与策略网络的结构相同,但它的输出是一个单标量的预测值,而不是概率分布。作者通过对状态-结果对 ( s , z ) (s, z) (s,z) 的回归训练值网络的权值,使用随机梯度下降最小化预测值 v θ ( s ) v_θ(s) vθ(s) 与相应结果 z z z 之间的均方误差(MSE)。
Δ θ ∝ ∂ v θ ( s ) ∂ θ ( z − v θ ( s ) ) \Delta \theta \propto \frac{\partial v_{\theta}(s)}{\partial \theta}\left(z-v_{\theta}(s)\right) Δθ∝∂θ∂vθ(s)(z−vθ(s))
如果使用完整游戏的数据来预测游戏结果的朴素方法会导致过拟合。原因在于,连续的棋盘位置是紧密相关的,差别只有一个棋子,但回归目标在整个游戏中是相同的。当以这种方式在数据集上训练时,值网络记住了游戏结果,而不是泛化到新的棋盘位置,在测试集上的最小MSE为 0.37,而在训练集上为 0.19。为了缓解这个问题,本文生成了一个新的自博弈数据集,包含 3000万 个不同的棋盘位置,每个位置都从一个分离率的游戏中采样。每次游戏都在RL策略网络和它自己之间进行,直到游戏终止。对该数据集进行训练,训练集和测试集的MSEs分别为 0.226 和 0.234,过拟合最小。
下图显示了值网络的棋盘位置评估精度,与使用快速走子策略 p π p_π pπ 的蒙特卡洛模拟相比,值函数始终更准确。利用RL策略网络 p ρ p_ρ pρ 对 v θ ( s ) v_θ(s) vθ(s) 的单次评估也接近蒙特卡洛模拟的精度,但使用了15000倍的计算量。
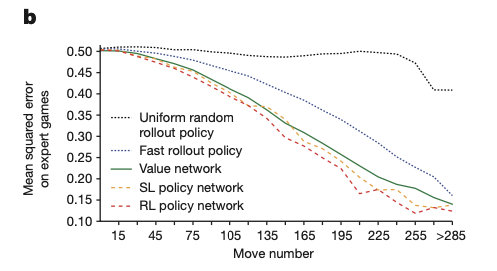
2.4 使用策略和价值网络进行搜索
AlphaGo 将策略网络和价值网络结合在一个MCTS算法中,该算法通过提前搜索选择动作。

搜索树中的每一条边 ( s , a ) (s,a) (s,a),存储了一个动作价值 Q ( s , a ) Q(s,a) Q(s,a),访问次数 N ( s , a ) N(s,a) N(s,a) 和先验概率 P ( s , a ) P(s,a) P(s,a)。模拟遍历树(即在没有备份的完整游戏中向下遍历树)从根状态开始。在每次模拟的每一步 t t t 中,从状态 s t s_t st 中选择一个动作 a t a_t at,从而使动作价值与奖励之和最大化。
a t = argmax a ( Q ( s t , a ) + u ( s t , a ) ) a_{t}=\underset{a}{\operatorname{argmax}}\left(Q\left(s_{t}, a\right)+u\left(s_{t}, a\right)\right) at=aargmax(Q(st,a)+u(st,a))
其中,
u ( s , a ) ∝ P ( s , a ) 1 + N ( s , a ) u(s, a) \propto \frac{P(s, a)}{1+N(s, a)} u(s,a)∝1+N(s,a)P(s,a)
它与先验概率成正比,但随访问次数增加而逐步衰减以鼓励探索。当在步骤 L L L 时到达叶节点 s L s_L sL,
叶节点可以扩展。叶节点的棋盘位置由监督学习策略网络 p σ p_{\sigma} pσ 只处理一次,对每个合法的动作 a a a 输出的概率被存储为先验概率 P P P, P ( s , a ) = p σ ( a ∣ s ) P(s, a)=p_{\sigma}(a \mid s) P(s,a)=pσ(a∣s)。
叶节点的评估有两种不同的方式:首先,由值网络 v θ ( s L ) v_θ(s_L) vθ(sL) 进行评估;第二,通过随机模拟的结果 z L z_L zL 进行评估,使用快速走子策略 p π p_π pπ,直到终端步骤 T T T;利用混合参数 λ λ λ,将这两者组合到叶节点评估 V ( s L ) V(s_L) V(sL) 中。
V ( s L ) = ( 1 − λ ) v θ ( s L ) + λ z L V\left(s_{L}\right)=(1-\lambda) v_{\theta}\left(s_{L}\right)+\lambda z_{L} V(sL)=(1−λ)vθ(sL)+λzL
在模拟结束时,更新所有遍历边的动作值和访问次数。每条边都会累计经过这条边的所有模拟的访问次数和平均值:
N ( s , a ) = ∑ i = 1 n 1 ( s , a , i ) Q ( s , a ) = 1 N ( s , a ) ∑ i = 1 n 1 ( s , a , i ) V ( s L i ) \begin{aligned} &N(s, a)=\sum_{i=1}^{n} 1(s, a, i) \\ &Q(s, a)=\frac{1}{N(s, a)} \sum_{i=1}^{n} 1(s, a, i) V\left(s_{L}^{i}\right) \end{aligned} N(s,a)=i=1∑n1(s,a,i)Q(s,a)=N(s,a)1i=1∑n1(s,a,i)V(sLi)
其中 s L i s^i_L sLi 是第 i i i 次模拟的叶节点, 1 ( s , a , i 1(s, a, i 1(s,a,i ) 表示第 i i i 次模拟是否遍历了一条边 ( s , a ) (s, a) (s,a)。一旦搜索完成,算法从根棋盘位置选择访问次数最多的动作。
边栏推荐
- 接口测试关键技术
- [Godot][GDScript] 2D cave map randomly generated
- What is distributed and clustered?What is the difference?
- How to develop a high-quality test case?
- [C language] General method of expression evaluation
- SQL injection Less46 (injection after order by + rand() Boolean blind injection)
- Day32 LeetCode
- Mysql 45讲学习笔记(二十五)MYSQL保证高可用
- endian mode
- 分布式锁以及实现方式三种
猜你喜欢
STM32问题合集

Based on the local, linking the world | Schneider Electric "Industrial SI Alliance" joins hands with partners to go to the future industry
识Flutter 基本组件之showTimePicker 方法
Problems that need to be solved in distributed system architecture

With 7 years of experience, how can functional test engineers improve their abilities step by step?

LeetCode中等题之分数加减运算
![[Dynamic programming] Maximum sum of consecutive subarrays](/img/3d/10731cc64d1c69d2beb3666ae0f064.png)
[Dynamic programming] Maximum sum of consecutive subarrays

IIR滤波器和FIR滤波器
C# remote debugging

TCP详解(三)
随机推荐
原子操作 CAS
C# remote debugging
VS QT——ui不显示新添加成员(控件)||代码无提示
WebSocket Session is null
MultipartFile文件上传
LeetCode每日一练 —— 138. 复制带随机指针的链表
What is a system?
[C language] Preprocessing operation
RESTful api接口设计规范
SQL injection Less46 (injection after order by + rand() Boolean blind injection)
测试中的误报和漏报同样的值得反复修正
LeetCode每日一练 —— OR36 链表的回文结构
接口测试关键技术
IDEA常用快捷键与插件
Point Cloud DBSCAN Clustering (MATLAB, not built-in function)
「 每日一练,快乐水题 」1331. 数组序号转换
Detailed explanation of TCP (1)
安全20220709
STM32 problem collection
观察者模式