当前位置:网站首页>Wchars, coding, standards and portability - wchars, encodings, standards and portability
Wchars, coding, standards and portability - wchars, encodings, standards and portability
2022-07-06 18:14:00 【javail】
problem :
The following may not qualify as a SO question; The following may not meet SO problem ;if it is out of bounds, please feel free to tell me to go away. If it is out of range , Please feel free to tell me to leave .The question here is basically, "Do I understand the C standard correctly and is this the right way to go about things?" The problem here is basically ,“ Whether I understand correctly C standard , Is this the right way ?”
I would like to ask for clarification, confirmation and corrections on my understanding of character handling in C (and thus C++ and C++0x). I want to ask for clarification , Confirm and correct my understanding of C Understanding of Chinese character processing ( as well as C ++ and C ++ 0x).First off, an important observation: First , An important observation :
Portability and serialization are orthogonal concepts. Portability and serialization are orthogonal concepts .
Portable things are things like C, unsigned int , wchar_t . Portable things are like C, unsigned int , wchar_t .Serializable things are things like uint32_t or UTF-8. Serializable things are like uint32_t or UTF-8."Portable" means that you can recompile the same source and get a working result on every supported platform, but the binary representation may be totally different (or not even exist, eg TCP-over-carrier pigeon).“Portable” This means that you can recompile the same source and get working results on each supported platform , But binary representations can be completely different ( Or it doesn't even exist , for example TCP-over-carrier pigeon).Serializable things on the other hand always have the same representation, eg the PNG file I can read on my Windows desktop, on my phone or on my toothbrush. On the other hand , Serializable things always have same Express , For example, I can Windows desktop , Read on mobile phone or toothbrush PNG file .Portable things are internal, serializable things deal with I/O. Portable things are internal , Serializable things to deal with I / O.Portable things are typesafe, serializable things need type punning. Portable things are type safe , Serializable things need typing .</preamble></ Leading >
When it comes to character handling in C, there are two groups of things related respectively to portability and serialization: When it comes to C When processing characters in , There are two groups related to portability and serialization :
wchar_t,setlocale(),mbsrtowcs()/wcsrtombs(): The C standard says nothing about "encodings" ;wchar_t,setlocale(),mbsrtowcs()/wcsrtombs(): C The standard does not mention “ code ” ;in fact, it is entirely agnostic to any text or encoding properties. in fact , It has nothing to do with any text or encoding properties .It only says "your entry point ismain(int, char**); you get a typewchar_twhich can hold all your system's characters; you get functions to read input char-sequences and make them into workable wstrings and vice versa. It just says “ Your entry point ismain(int, char**); You get a typewchar_t, It can hold all the characters of your system ; You get the function to read the input character sequence and make them a feasible string , vice versa .iconv()and UTF-8,16,32: A function/library to transcode between well-defined, definite, fixed encodings.iconv()and UTF-8,16,32: A function that transcodes between well-defined fixed codes / library .All encodings handled by iconv are universally understood and agreed upon, with one exception. from iconv All codes processed are generally understood and agreed , With one exception .
The bridge between the portable, encoding-agnostic world of C with its wchar_t portable character type and the deterministic outside world is iconv conversion between WCHAR-T and UTF . portable , Coding independent C The world and its wchar_t The bridge between portable character types and the deterministic external world is WCHAR-T and UTF Between iconv transformation .
So, should I always store my strings internally in an encoding-agnostic wstring, interface with the CRT via wcsrtombs() , and use iconv() for serialization? that , Should I always store my strings internally in encoding independent wstring in , adopt wcsrtombs() And CRT Interface , And use iconv() serialize ?Conceptually: Concept :
my program <-- wcstombs --- /==============\ --- iconv(UTF8, WCHAR_T) -->CRT | wchar_t[] | <Disk> --- mbstowcs --> \==============/ <-- iconv(WCHAR_T, UTF8) --- | +-- iconv(WCHAR_T, UCS-4) --+ | ... <--- (adv. Unicode malarkey) ----- libicu ---+Practically, that means that I'd write two boiler-plate wrappers for my program entry point, eg for C++: actually , This means that I will write two template wrappers for my program entry point , for example C ++:
// Portable wmain()-wrapper#include <clocale>#include <cwchar>#include <string>#include <vector>std::vector<std::wstring> parse(int argc, char * argv[]); // use mbsrtowcs etcint wmain(const std::vector<std::wstring> args); // user starts here#if defined(_WIN32) || defined(WIN32)#include <windows.h>extern "C" int main(){ setlocale(LC_CTYPE, ""); int argc; wchar_t * const * const argv = CommandLineToArgvW(GetCommandLineW(), &argc); return wmain(std::vector<std::wstring>(argv, argv + argc));}#elseextern "C" int main(int argc, char * argv[]){ setlocale(LC_CTYPE, ""); return wmain(parse(argc, argv));}#endif// Serialization utilities#include <iconv.h>typedef std::basic_string<uint16_t> U16String;typedef std::basic_string<uint32_t> U32String;U16String toUTF16(std::wstring s);U32String toUTF32(std::wstring s);/* ... */Is this the right way to write an idiomatic, portable, universal, encoding-agnostic program core using only pure standard C/C++, together with a well-defined I/O interface to UTF using iconv? This is using pure standards C / C ++ Write a idiomatic , portable , General purpose , The right way to code the core of an unknowable program , And the use of iconv Define the UTF Explicit I / O Interface? ?(Note that issues like Unicode normalization or diacritic replacement are outside the scope; only after you decide that you actually want Unicode (as opposed to any other coding system you might fancy) is it time to deal with those specifics, eg using a dedicated library like libicu.)( Please note that ,Unicode Problems such as normalization or diacritical substitution are out of scope ; Only when you determine your actual needs Unicode ( Not any other coding system you might want ) Then we can deal with these details , For example, use a dedicated Library libicu.)
Updates to update
Following many very nice comments I'd like to add a few observations: After many very good comments , I would like to add a few comments :
If your application explicitly wants to deal with Unicode text, you should make the
iconv-conversion part of the core and useuint32_t/char32_t-strings internally with UCS-4. If your application specifically deals with Unicode Text , Then you should puticonv-conversion As part of the core , And in UCS-4 For internal useuint32_t/char32_t-strings.Windows: While using wide strings is generally fine, it appears that interaction with the console (any console, for that matter) is limited, as there does not appear to be support for any sensible multi-byte console encoding and
mbstowcsis essentially useless (other than for trivial widening).Windows: Although using wide strings is usually good , But it seems to be related to the console ( Any console , In this respect ) The interaction of is limited , Because it doesn't seem to support any reasonable multi byte console coding andmbstowcsIt's basically useless ( Except for trivial expansion ).Receiving wide-string arguments from, say, an Explorer-drop together withGetCommandLineW+CommandLineToArgvWworks (perhaps there should be a separate wrapper for Windows). from Explorer-drop andGetCommandLineW+CommandLineToArgvWReceive wide string parameters together ( Maybe there should be a separate Windows Wrappers ).File systems: File systems don't seem to have any notion of encoding and simply take any null-terminated string as a file name. file system : The file system doesn't seem to have any coding concept , Just put anything in null The ending string is used as the file name .Most systems take byte strings, but Windows/NTFS takes 16-bit strings. Most systems use byte strings , but Windows / NTFS use 16 A string .You have to take care when discovering which files exist and when handling that data (eg
char16_tsequences that do not constitute valid UTF16 (eg naked surrogates) are valid NTFS filenames). When discovering which files exist and processing the data ( for example , Does not constitute valid UTF16 Ofchar16_tSequence ( For example, naked agents ) It works NTFS file name ), You must be careful .The Standard Cfopenis not able to open all NTFS files, since there is no possible conversion that will map to all possible 16-bit strings. standard CfopenUnable to open all NTFS file , Because no possible transformation will map to all possible 16 A string .Use of the Windows-specific_wfopenmay be required. You may need to use a specific Windows Of_wfopen.As a corollary, there is in general no well defined notion of "how many characters" comprise a given file name, as there is no notion of "character" in the first place. As a corollary , Usually not clearly defined “ How many characters ” Contains the concept of a given file name , Because first of all, there is no “ character ” The concept of .Caveat emptor. The buyer is conceited .
Solution :
Reference resources : https://stackoom.com/en/question/QR7s边栏推荐
- Today in history: the mother of Google was born; Two Turing Award pioneers born on the same day
- 2019阿里集群数据集使用总结
- adb常用命令
- Smart street lamp based on stm32+ Huawei cloud IOT design
- J'aimerais dire quelques mots de plus sur ce problème de communication...
- Kill -9 system call used by PID to kill process
- Five data structures of redis
- Video fusion cloud platform easycvr adds multi-level grouping, which can flexibly manage access devices
- Manifest of SAP ui5 framework json
- 从交互模型中蒸馏知识!中科大&美团提出VIRT,兼具双塔模型的效率和交互模型的性能,在文本匹配上实现性能和效率的平衡!...
猜你喜欢
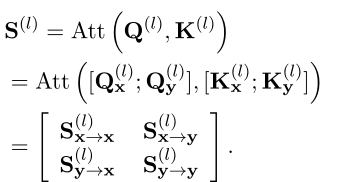
Distiller les connaissances du modèle interactif! L'Université de technologie de Chine & meituan propose Virt, qui a à la fois l'efficacité du modèle à deux tours et la performance du modèle interacti

带你穿越古罗马,元宇宙巴士来啦 #Invisible Cities

1700C - Helping the Nature
Video fusion cloud platform easycvr adds multi-level grouping, which can flexibly manage access devices
从交互模型中蒸馏知识!中科大&美团提出VIRT,兼具双塔模型的效率和交互模型的性能,在文本匹配上实现性能和效率的平衡!...
【Android】Kotlin代码编写规范化文档
What is the reason why the video cannot be played normally after the easycvr access device turns on the audio?
C language exchanges two numbers through pointers
1700C - Helping the Nature
從交互模型中蒸餾知識!中科大&美團提出VIRT,兼具雙塔模型的效率和交互模型的性能,在文本匹配上實現性能和效率的平衡!...
随机推荐
Stealing others' vulnerability reports and selling them into sidelines, and the vulnerability reward platform gives rise to "insiders"
【剑指 Offer】 60. n个骰子的点数
Interesting - questions about undefined
How to solve the error "press any to exit" when deploying multiple easycvr on one server?
SQL statement optimization, order by desc speed optimization
重磅硬核 | 一文聊透对象在 JVM 中的内存布局,以及内存对齐和压缩指针的原理及应用
Recommend easy-to-use backstage management scaffolding, everyone open source
FMT open source self driving instrument | FMT middleware: a high real-time distributed log module Mlog
【Android】Kotlin代码编写规范化文档
1700C - Helping the Nature
Pytest learning ----- detailed explanation of the request for interface automation test
Prophet模型的简介以及案例分析
2022暑期项目实训(一)
容器里用systemctl运行服务报错:Failed to get D-Bus connection: Operation not permitted(解决方法)
2022 Summer Project Training (III)
std::true_type和std::false_type
Interview shock 62: what are the precautions for group by?
从交互模型中蒸馏知识!中科大&美团提出VIRT,兼具双塔模型的效率和交互模型的性能,在文本匹配上实现性能和效率的平衡!...
转载:基于深度学习的工业品组件缺陷检测技术
Excel usage record