当前位置:网站首页>Complete deep neural network CNN training with tensorflow to complete picture recognition case 2
Complete deep neural network CNN training with tensorflow to complete picture recognition case 2
2022-07-03 13:27:00 【Haibao 7】
To be continued . Previous link :https://blog.csdn.net/dongbao520/article/details/125456950
Convolutional neural networks
• Convolutional neural networks
• Visual cortex 、 Feel the field , Some neurons see the line , Some neurons see the line
Direction , Some neurons have larger receptive fields , Combine the patterns on the bottom
• 1998 year Yann LeCun Et al LeNet-5 framework , Widely used in hands
Written digit recognition , Including full connection layer and sigmoid Activation function , There are also volumes
Accumulation layer and pool layer
Convolutional neural networks (Convolutional Neural Networks, CNN) It is a kind of feedforward neural network with convolution calculation and depth structure (Feedforward Neural Networks), It's deep learning (deep learning) One of the representative algorithms of [1-2] . Convolutional neural network has the characteristics of representation learning (representation learning) Ability , The input information can be classified according to its hierarchical structure (shift-invariant classification), So it's also called “ Translation invariant artificial neural networks (Shift-Invariant Artificial Neural Networks, SIANN
Convolution neural network imitates biological visual perception (visual perception) Mechanism construction , Supervised learning and unsupervised learning , The sharing of convolution kernel parameters in the hidden layer and the sparsity of inter layer connections make the convolution neural network lattice with less computation (grid-like topology) features , For example, pixels and audio for learning 、 It has a stable effect and has no additional feature engineering on the data (feature engineering) Complete principle related requirements can ---->> Reference resources
For receptive field :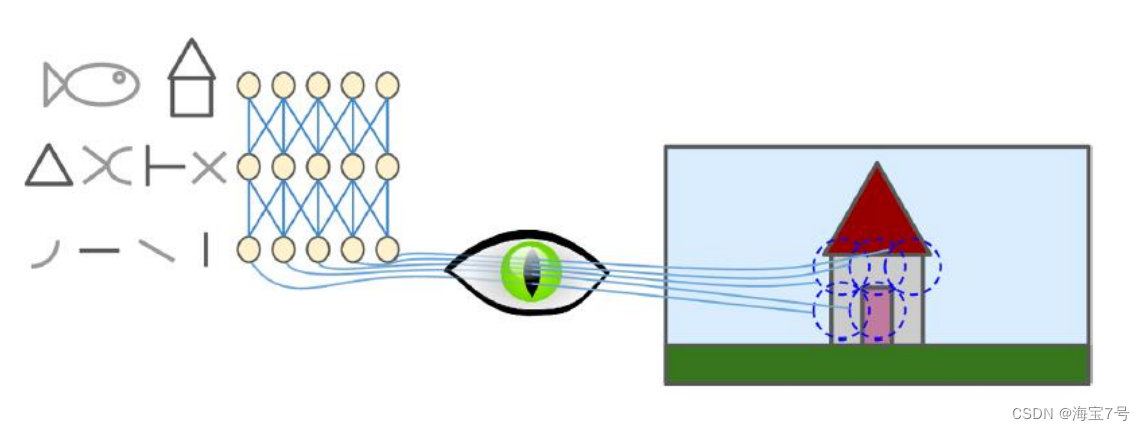
For pre trained networks  Reuse TensorFlow Model
Reuse TensorFlow Model 
CNN The most important building unit is the convolution layer
• Neurons in the first convolution layer are not connected to every pixel of the input picture ,
Just connect the pixels of their receptive field , And so on , Of the second accretion layer
Each neuron is only connected to a small square God located in the first convolution layer
Jing Yuan
Convolution layer diagram 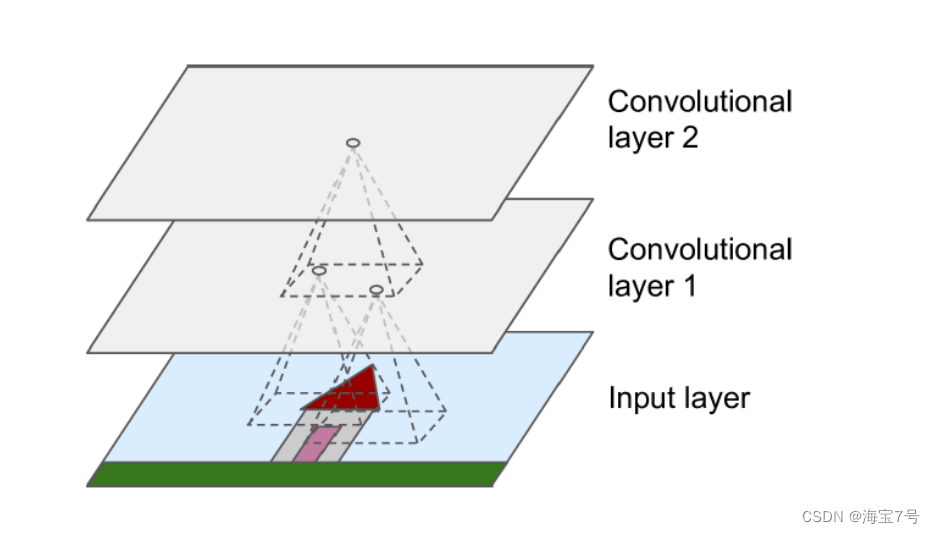
Convolution cases :
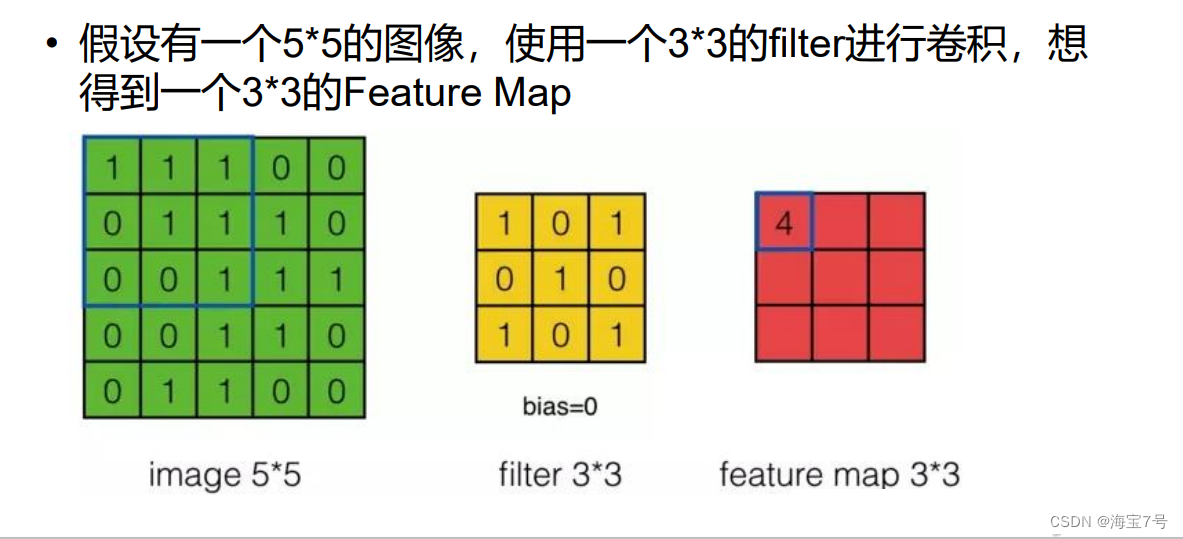
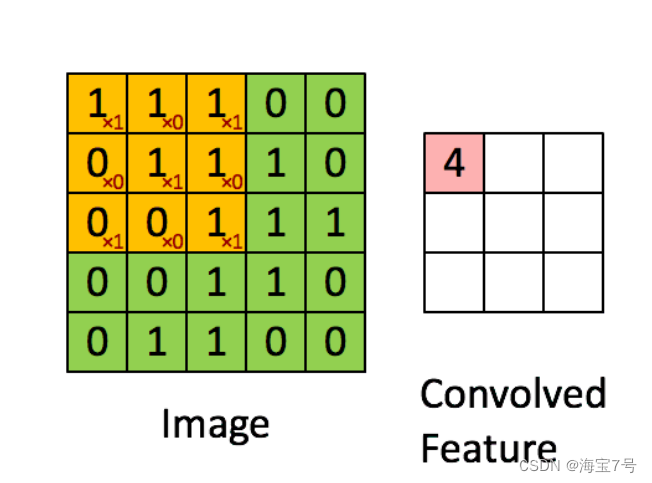
In steps of 2, Then there are 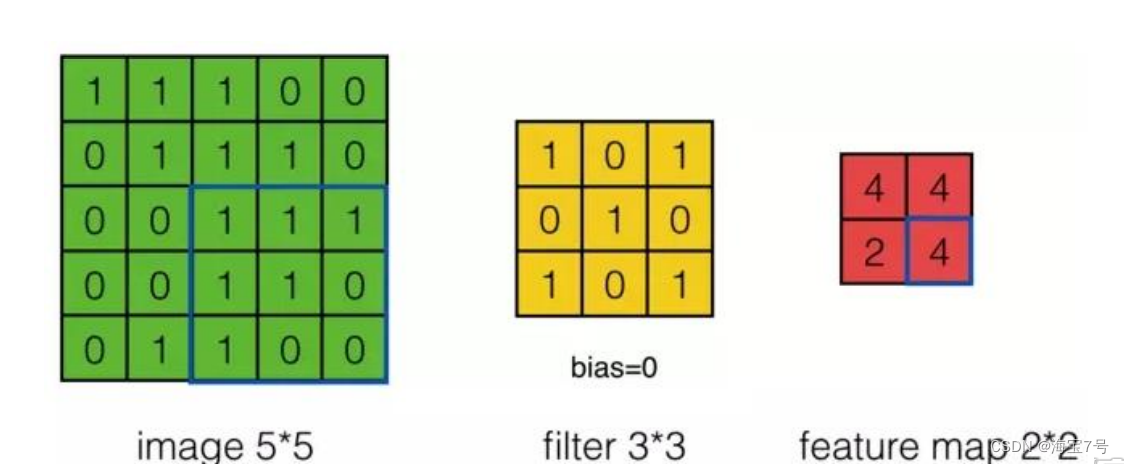
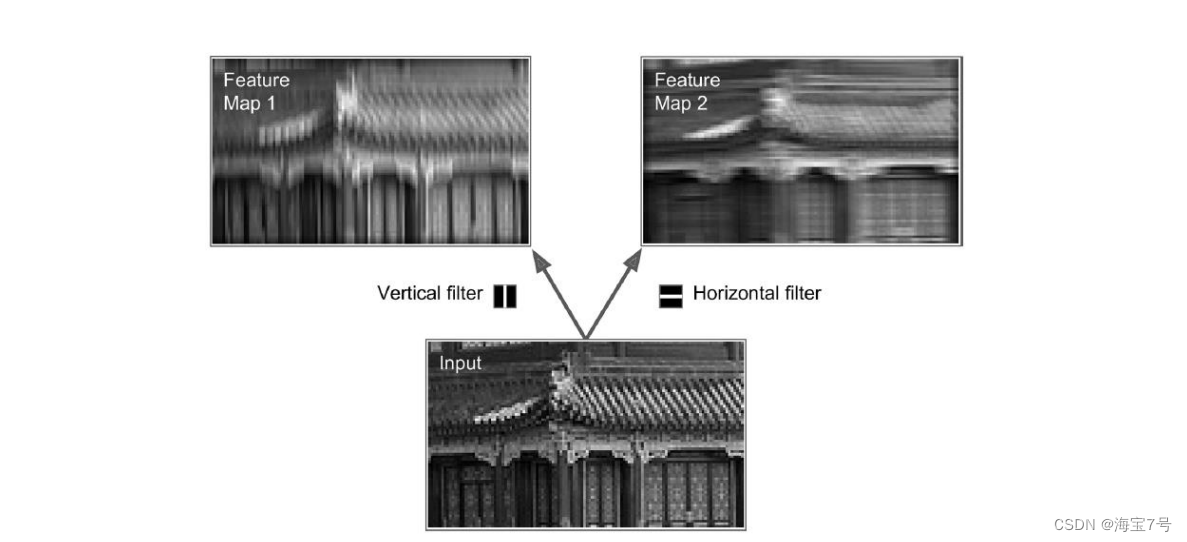
Filter Convolution kernel
• Convolution kernels
• Vertical line filter The middle column is 1, The surrounding areas are listed as 0
• Horizontal line filter Intermediate behavior 1, Surrounding behavior 0
• 7*7 matrix
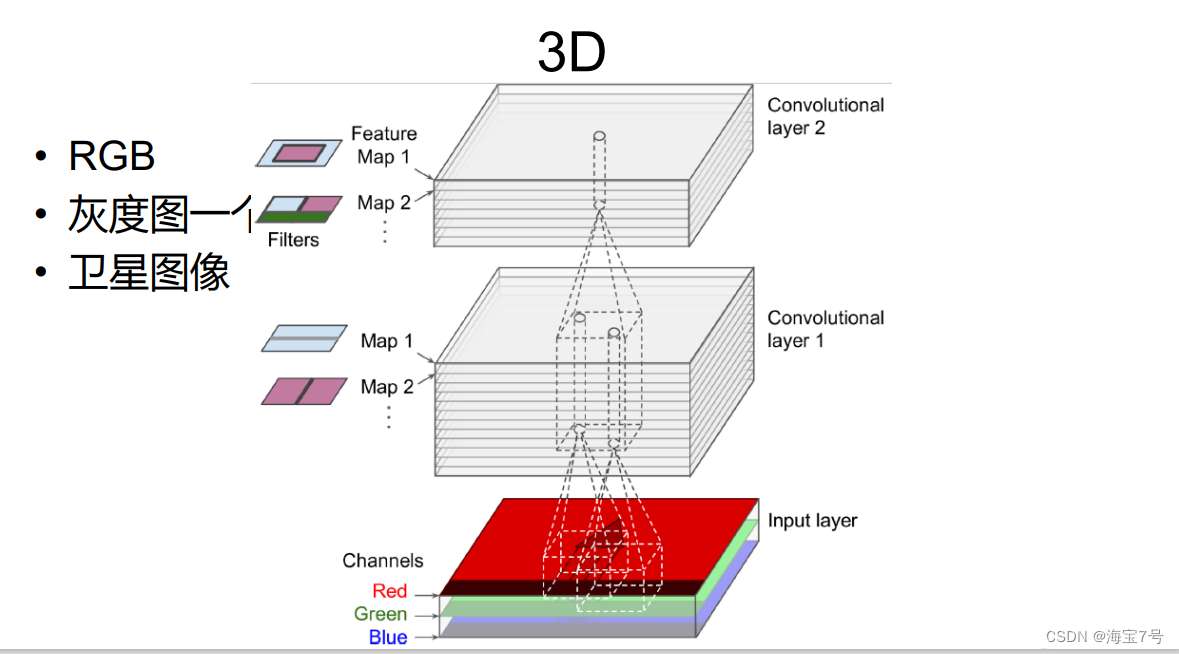
In a feature map , All neurons share the same parameters (
weights bias), Weight sharing
• Different feature maps have different parameters
Convolution training process 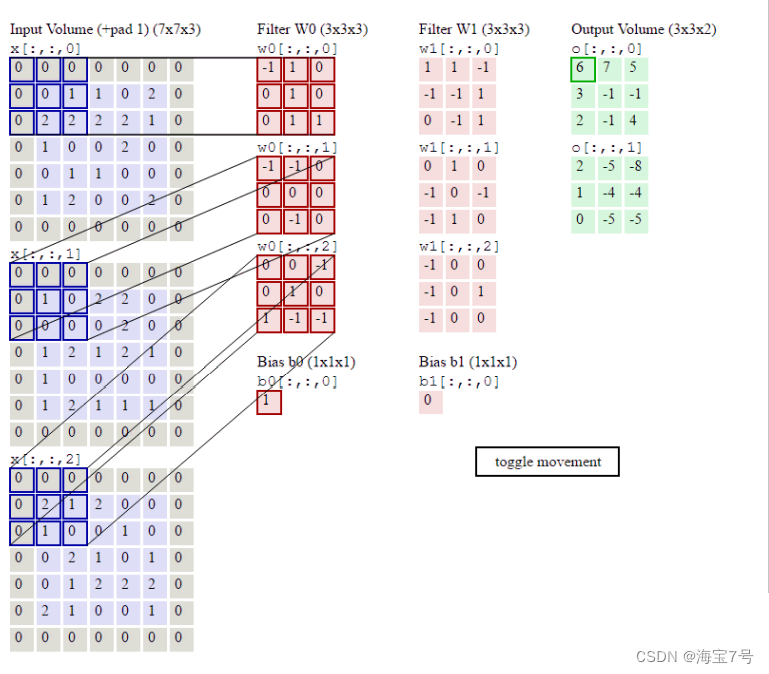
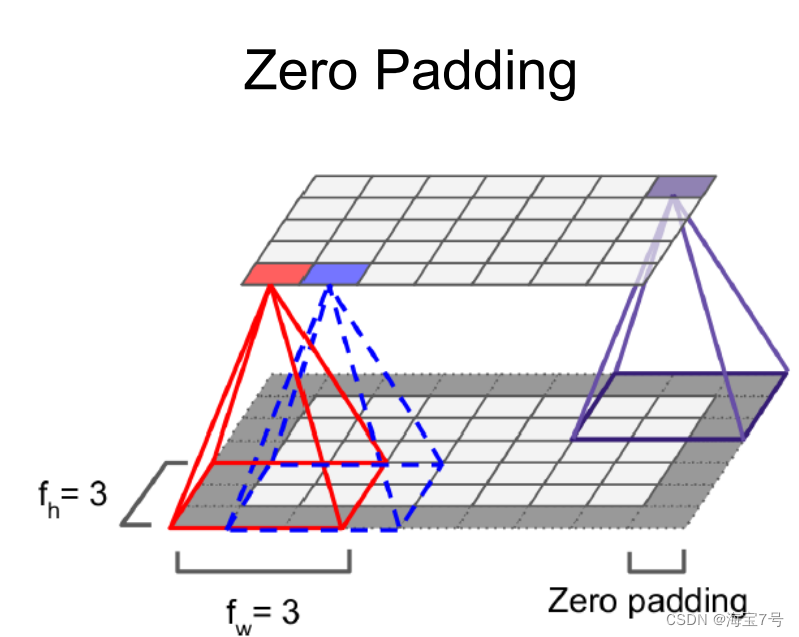
Padding Pattern
VALID
• Do not apply zero padding, It is possible to ignore the right or bottom of the picture , This depends stride Set up
• SAME
• If necessary, add zero padding, In this case , The number of output neurons is equal to the number of input neurons divided by the step size ceil(13/5)=3

Pooling Pooling Handle
The goal is downsampling subsample,shrink, Reduce the calculated load , Memory usage , The number of arguments ( It can also prevent over fitting )• Reducing the size of the input image also allows the neural network to withstand a little image translation , Not affected by location
• Just like convolutional neural networks , Each neuron in the pooling layer is connected to the neuron output in the upper layer , It only corresponds to a small area of receptive field . We have to define size , step ,padding type
• Pooled neurons have no weight value , It just aggregates the input according to the maximum or the average
• 2*2 The pooled core of , In steps of 2, There is no filling , Only the maximum value is passed down

Twice as long and twice as wide , area 4 Times smaller , lose 75% The input value of
• In general , The pooling layer works on each independent input channel , So the depth of output is the same as that of input
CNN framework
• Typical CNN The architecture heap lists some volume layers :
• Usually a convolution layer is followed by ReLU layer , Then there is a pool layer , Then there are other convolutions +ReLU layer , Then another pooling layer , The pictures transmitted through the network are getting smaller and smaller , But it's getting deeper and deeper , For example, more feature maps !
• Finally, the conventional feedforward neural network is added , By some fully connected layers +ReLU layers , Finally, the output layer prediction , For example, one softmax Class probability of layer output prediction
• A common misconception is that the convolution kernel is too large , You can use and 99 Two of the same effect of the nucleus 33 The core of , The advantage is that there will be fewer parameters , Simplify the operation . To be continued ..
To be continued ..
边栏推荐
- Can newly graduated European college students get an offer from a major Internet company in the United States?
- 父亲和篮球
- SSH login server sends a reminder
- MySQL functions and related cases and exercises
- 物联网毕设 --(STM32f407连接云平台检测数据)
- The 35 required questions in MySQL interview are illustrated, which is too easy to understand
- Flink code is written like this. It's strange that the window can be triggered (bad programming habits)
- 常见的几种最优化方法Matlab原理和深度分析
- [today in history] July 3: ergonomic standards act; The birth of pioneers in the field of consumer electronics; Ubisoft releases uplay
- Useful blog links
猜你喜欢

Flink SQL knows why (XI): weight removal is not only count distinct, but also powerful duplication
Comprehensive evaluation of double chain notes remnote: fast input, PDF reading, interval repetition / memory

When we are doing flow batch integration, what are we doing?

Kivy教程之 如何自动载入kv文件

My creation anniversary: the fifth anniversary

Setting up remote links to MySQL on Linux

Today's sleep quality record 77 points

2022-02-14 incluxdb cluster write data writetoshard parsing
MyCms 自媒体商城 v3.4.1 发布,使用手册更新

Mysql database basic operation - regular expression
随机推荐
2022-02-14 analysis of the startup and request processing process of the incluxdb cluster Coordinator
Cadre de logback
Road construction issues
常见的几种最优化方法Matlab原理和深度分析
PowerPoint 教程,如何在 PowerPoint 中將演示文稿另存為視頻?
道路建设问题
刚毕业的欧洲大学生,就能拿到美国互联网大厂 Offer?
Task5: multi type emotion analysis
untiy世界边缘的物体阴影闪动,靠近远点的物体阴影正常
Oracle memory management
Box layout of Kivy tutorial BoxLayout arranges sub items in vertical or horizontal boxes (tutorial includes source code)
MapReduce实现矩阵乘法–实现代码
IDEA 全文搜索快捷键Ctr+Shift+F失效问题
Luogup3694 Bangbang chorus standing in line
[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter III exercises]
Comprehensive evaluation of double chain notes remnote: fast input, PDF reading, interval repetition / memory
Smbms project
18W word Flink SQL God Road manual, born in the sky
Ubuntu 14.04 下开启PHP错误提示
已解决(机器学习中查看数据信息报错)AttributeError: target_names