当前位置:网站首页>Spark实战1:单节点本地模式搭建Spark运行环境
Spark实战1:单节点本地模式搭建Spark运行环境
2022-07-03 12:39:00 【星哥玩云】
前言:
Spark本身用scala写的,运行在JVM之上。
JAVA版本:java 6 /higher edition.
1 下载Spark
http://spark.apache.org/downloads.html
你可以自己选择需要的版本,这里我的选择是:
http://d3kbcqa49mib13.cloudfront.net/spark-1.1.0-bin-hadoop1.tgz
如果你是奋发图强的好码农,你可以自己下载源码:http://github.com/apache/spark.
注意:我这里是运行在Linux环境下。没有条件的可以安装下虚拟机之上!
2 解压缩&进入目录
tar -zvxf spark-1.1.0-bin-Hadoop1.tgz
cd spark-1.1.0-bin-hadoop1/
3 启动shell
./bin/spark-shell
你会看到打印很多东西,最后显示
4 小试牛刀
先后执行下面几个语句
val lines = sc.textFile("README.md")
lines.count()
lines.first()
val pythonLines = lines.filter(line => line.contains("Python"))
scala> lines.first() res0: String = ## Interactive Python Shel
---解释,什么是sc
sc是默认产生的SparkContext对象。
比如
scala> sc res13: org.apache.spark.SparkContext = [email protected]
这里只是本地运行,先提前了解下分布式计算的示意图:
5 独立的程序
最后以一个例子结束本节
为了让它顺利运行,按照以下步骤来实施即可:
--------------目录结构如下:
/usr/local/spark-1.1.0-bin-hadoop1/test$ find . . ./src ./src/main ./src/main/scala ./src/main/scala/example.scala ./simple.sbt
然后simple.sbt的内容如下:
name := "Simple Project" version := "1.0" scalaVersion := "2.10.4" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.1.0"example.scala的内容如下:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.SparkContext._
object example { def main(args: Array[String]) { val conf = new SparkConf().setMaster("local").setAppName("My App") val sc = new SparkContext("local", "My App") sc.stop() //System.exit(0) //sys.exit() println("this system exit ok!!!") } }
红色local:一个集群的URL,这里是local,告诉spark如何连接一个集群,local表示在本机上以单线程运行而不需要连接到某个集群。
橙黄My App:一个项目的名字,
然后执行:sbt package
成功之后执行
./bin/spark-submit --class "example" ./target/scala-2.10/simple-project_2.10-1.0.jar
结果如下:
说明确实成功执行了!
结束!
边栏推荐
- Mysql database basic operation - regular expression
- Sword finger offer 14- ii Cut rope II
- Idea full text search shortcut ctr+shift+f failure problem
- PowerPoint tutorial, how to save a presentation as a video in PowerPoint?
- The 35 required questions in MySQL interview are illustrated, which is too easy to understand
- Sword finger offer 15 Number of 1 in binary
- Some thoughts on business
- 2022-02-10 introduction to the design of incluxdb storage engine TSM
- [Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter 6 exercises]
- luoguP3694邦邦的大合唱站队
猜你喜欢

Flink SQL knows why (16): dlink, a powerful tool for developing enterprises with Flink SQL
 [email protected]奇安信:透视俄乌网络战 —— 网络空间基础设施面临的安全对抗与制裁博弈..."/>
[email protected]奇安信:透视俄乌网络战 —— 网络空间基础设施面临的安全对抗与制裁博弈..."/>开始报名丨CCF C³[email protected]奇安信:透视俄乌网络战 —— 网络空间基础设施面临的安全对抗与制裁博弈...
已解决TypeError: Argument ‘parser‘ has incorrect type (expected lxml.etree._BaseParser, got type)

Huffman coding experiment report
File uploading and email sending
解决 System has not been booted with systemd as init system (PID 1). Can‘t operate.
![[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [sqlserver2012 comprehensive exercise]](/img/47/78d9dd098dcb894ba1f459873d5f52.png)
[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [sqlserver2012 comprehensive exercise]
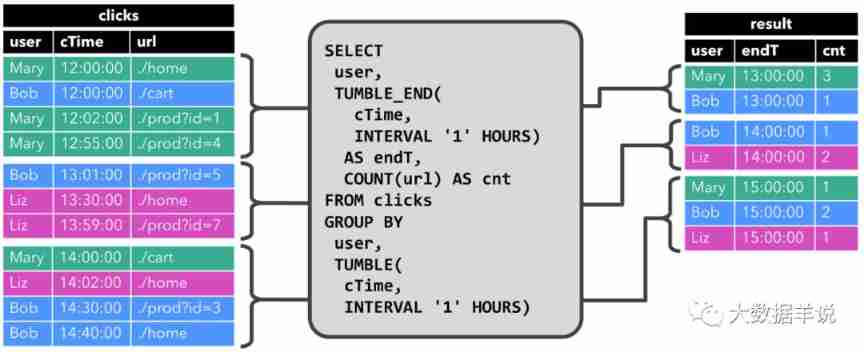
(first) the most complete way to become God of Flink SQL in history (full text 180000 words, 138 cases, 42 pictures)

Annotation and reflection

2022-02-14 incluxdb cluster write data writetoshard parsing
随机推荐
Leetcode234 palindrome linked list
DQL basic query
Logseq 评测:优点、缺点、评价、学习教程
35道MySQL面试必问题图解,这样也太好理解了吧
STM32 and motor development (from MCU to architecture design)
Setting up Oracle datagurd environment
[combinatorics] permutation and combination (multiple set permutation | multiple set full permutation | multiple set incomplete permutation all elements have a repetition greater than the permutation
这本数学书AI圈都在转,资深ML研究员历时7年之作,免费电子版可看
[colab] [7 methods of using external data]
Mysql database basic operation - regular expression
Mysqlbetween implementation selects the data range between two values
2022-02-11 heap sorting and recursion
MySQL
用户和组命令练习
mysqlbetween实现选取介于两个值之间的数据范围
剑指 Offer 14- II. 剪绳子 II
[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter III exercises]
Slf4j log facade
Idea full text search shortcut ctr+shift+f failure problem
01 three solutions to knapsack problem (greedy dynamic programming branch gauge)