当前位置:网站首页>人身变声器的原理
人身变声器的原理
2022-07-03 12:34:00 【卓晴】

姓名:石湛
学号:2020011069
院系:自动化系
指导老师:卓晴
简 介: 声音作为一种由振动而产生的机械波,本身就是一个连续的时间信号。我们对声音的处理将会充分运用信号与系统的相关知识。笔者从生活出发,通过一些基本的技术手段实现声音的转变,并取得了较好的效果。由于人声的两大特点来自于基频和共振峰,我们可以简单地利用采样率的重采样实现声音第一印象的转变。而由于常见的重采样方法将会带来时域上速度的改变,需要寻求一种补偿的方式来满足我们正常人耳对本真人声的听觉感受。由此引入了 TSM技术在尽可能保证频率不变的情况下延拓时间,从而实现在频域的全部变换。最终通过逆变换得到一个大体相同而人声的基频部分发生搬移,共振峰得到一定偏移的信号。由于这种操作在共振峰的对应变换上存在失真,笔者在完成本项工作的过程中也没有使用到先进的滤波器进行处理,导致部分声音仍存在刺耳或是失真的情况。不过,在尝试的男变女和女变男中,普通的念白和部分歌曲的表现都较为优秀。本篇工作虽然原理并不高深,但涉及到了非常广泛的信号处理知识,于笔者个人而言是一次非常重要的提升,颇有收获。
关键词:人声;基频变声;频域处理;重采样;TSM
§01引 言
随着信号处理技术的发展,在诸多行业出于隐私保护或是美化的需要,或多或少都会使用到变声器的人声信号处理技术。对很多人来说,幼年时期都将变声视为一种神奇的魔力。就像《名侦探柯南》手中的万能变声蝴蝶结,笔者对此憧憬许久。在本文中,笔者将介绍使用数字信号处理技术完成一个完整的声音变化处理的基本方法以及涉及到的知识延拓。本文借助 GitHub开源项目 SoundLab进行基本的音频信号采样和分析工作,链接将附在文后以供查阅。
本文的写作契机是因为笔者在本学期也选修了日语的二外课程。在期末的口语考试中尝试了对影片角色的配音工作。借助 Adobe Audition的滤波工具完成了对视频人声的消除的同时又保留背景音乐的工作,大致是利用滤波器进行滤波,这利用了人声和乐器乐音在频率上的较大差异。而在此过程中我注意到了人声对应的频谱本身也是具有差异的。我们的小组成员全是男生而需要反串配音片段中的女角色,这给我们带来了很大的挑战,我提出尝试使用变声器的方法但网上所能找到的变声器大多效果欠佳,最后只能是让声音稍尖细的一名同学来扮演女性角色。而我仍由此产生了想要尝试实现变声器软件实现的想法,并在本文之中予以落地。

▲ 图1.1 柯南利用变声蝴蝶结破案我们知道,对于人类语言所发出的声音而言,两个非常重要的特征就是基频和共振峰。其中基频即为发出浊音时声带自然振动的频率,就好比男性说话的基频会偏低,而女性声音的基频较高,体现在日常的听觉之中就是说话腔调的高低感。由此不难理解,年龄同样会一定程度上影响我们语音的基频。因此,若要改变他人对自身语音的直观感知印象,一个非常重要的部分就是改变基频,从而实现语音的“听觉错位”,影响他人对本人性别乃至年龄的判断。
而共振峰则是之声门波在声道里发生共鸣的频率。共振峰的主要影响因素是声道的长度:声道越长共振峰的频率越高,反之亦然。相对来说,男子的声道比女子的声道要长一些,所以男声的共振峰频率比女声的共振峰频率相对也要高一些。因此通过改变共振峰,也能够影响人对说话人的判断。
目前,对于改变基频,目前已经有了很多方法。经过笔者的调查,应用比较广泛的有 PSOLA算法 (Pitch Synchronous Overlap and Add),混合谐波随机模型法 (Hybrid Harmonic/StochasticModel),自回归线性预测系数法 (Auto-Regressive LPC)等方法。PSOLA算法因为方法简单,运算量小,而且合成语音的自然度很高,所以应用最为广泛。不过由于 PSOLA算法本身的局限性,当需要改变基频范围比较大时,语音就会产生相当多的混叠现象,造成很大的噪声。其他两种方法改变基频后语音的自然度要差一些,而且这两种方法的运算量都比较大,在 DSP芯片实时实现会有一定的困 难。此外,这些方法都会改变原始语音的长度,这对于变声后语音的实时传送会造成很大的问题。
对于修改共振峰的频率,大部分方法都是基于参数合成的算法。这些方法普遍存在的问题是运算量比较大,需要人工干预,合成的语音的自然度比较差。本文中将不过多涉及。
在尝试本文的课题之前,笔者曾采访过经常使用变声器进行视频配音和直播的友人,得到的普遍反馈是效果不好,声音效果失真。在尝试了市面上常见的变声软件后,我认为对变声器做进一步的探讨和研究是很有必要的。本文基于信号与系统基本的信号处理手段,借助现有的成熟采样工具和开源的滤波编辑手段,实现较为复杂而效果更优的基频调制。在信号重建的过程中,我同样发现了简单的基频调制可能带来的问题,并展望通过滤波手段和权值分配的方式更好地进行人声转换。随着人工智能深度神经网络的发展,经过学习过程来修改滤波参数或许也是一个更为可行的方案。

▲ 图1.2 日语课配音中需要翻船的角色
§02变声器基本原理
2.1 声音和音频
声音作为一种由振动而产生的机械波,本身就是一个连续的时间信号,而其主要由以下三个属性来衡量:
- 响度:人主观上感觉声音大小的来源;由振幅和人离声源的距离决定,振幅越大响度越大,人和声源的距离越小,响度越大 (源于声波在传播过程中的衰减)
- 音调:声音的高低;由频率决定,频率越高音调越高
- 音色:声音的特性,由发声物体本身材料,结构决定 (表征为时域信号的不同波形)
在使用数字信号技术处理声音 (尤其是人声)的今天,声音在计算机中被编码成为音频从而方便我们的操作。在使用麦克风等设备进行声音采集的时候,是声带的振动传到麦克风后引发的受迫振动使得麦克风产生不同的电流输出,从而实现存储乃至再次利用放大器和扩音设备进行播放。计算机中的数字音频的存储方式被称之为 PCM(脉冲编码调制),声音的高低变换被转化为一系列高低电平的二进制编码。在此过程中有三个主要反映其特征的参数:采样率、通道数和位深:
- 采样率:即每秒采样的次数,单位为 Hz
- 通道数:也就是音轨数。由于自然界许多声音的混叠将会导致计算处理的困难,而如果又要重现出富有层次感的丰富声音效果,我们就需要使用到更多的通道(音轨)
- 位深:直观反映了声音的振幅范围。利用计算机常见的补码编码一个幅度的分度范围从而显示对不同振幅的模拟。
笔者在进行日语课程配音的后期音频处理中,使用 Au拼合多音轨的时候对多音轨所带来的“真实感”也有一个较为深刻的体会。储存 PCM文件并将其表现为可播放文件的过程中,常常需要加入关于这三个特征参数的描述在文件的头部。常见的音频格式都遵循这个方式,只不过对 PCM数据的编码方式不一样。抛开参数头之后的数据也就成为音频流, wav文件的流就是 PCM编码,因此也被称为原始音频文件。其他类型的编码,都是对此进行了有损或是无损的压缩,降低了存储量的消耗。
▲ 图2.1.1 使用FFT滤波,分音轨进行视频中的音频处理2.2 不同声音之间基本特征差异
之前提到 ,人类发声本质上是声带的震动引起的 ,声带的振动带动了空气压差 ,产生声波进行传播。在数学的表述上 ,我们常常使用正弦曲线来表达声波的传播特征。为了记录声波信号 ,必然绕不开采样和量化。我们对人声信号进行采样就可以得到离散的数字音频文件,如常见的 wav文件,采样率一般就是 44100Hz,量化的范围在 16bit附近。为了实现不同声音的转换,我们先来观察一下对于普通的单音,男性和女性发声在时域上的不同:(采集了我本人和女同学的同场景人声)

▲ 图2.2.1 男性声音发出“哈”
▲ 图2.2.2 女性声音发出“哈” 不难发现,声波在时域上本身呈现一定的周期性,这其实方便了我们对频域的分析。在图中展示的时域图中,横坐标是以 5mm为刻度,可以观察得知:男性声音的重复单元占据了 7 8ms,而女性则小得多,大约为 4 5ms。从时域的幅度上来说也能发现区别,男性的声音幅度更为平缓而低,女性的声音则更高,冲击更大的刺边也更为明显。这个重复单元就是之前所说的基波,而基波在时域所对应的时长也就称之为基音周期,由此可以简单地计算得到基音的频率。经过查找资料,常见的三种人声基频可以总结如下:
| 人群 | 基频分布(Hz) | 共振峰频率分布 |
|---|---|---|
| 男声 | [50,180] | 偏低 |
| 女生 | [160,380] | 中 |
| 童声 | [400,1000] | 偏高 |
一个直观的想法是,我们将自己输入的(比如笔者的男性声音)进行时域上的尺度变换等系列操作。但经过信号与系统课程的学习,不难理解这样的处理方式是极为困难且难以应用于各种发声场景的。由于之前我们已经观察到了人声在发每一个单音的持续时间内都是具有周期性的,这也就意味着频域的相关分析有可能更好地帮助我们解决这一问题。
2.3 离散傅里叶频域分析问题
下面讨论离散傅里叶进行频域分析面临的问题。我们使用离散傅里叶变换来处理音频信号(使用 FFT算法)。由于基于 2的 FFT(课上所介绍的常见 FFT算法)要求信号的长度为 2的基数,这也就意味着我们需要合理地在各段音频之中选取一个合适的时间间隔来将原本的人声文件做切割,其长度保持为 2的基数且其展现的波形大 致仍保持有周期特性,这一点十分重要,我们之后再谈。 FFT可以使用来自 MATLAB或是 python相关包中的现成工具。也可以使用如下 C语言代码直观实现:
void FFT_Sort(complex x [] , int N) {
int eb , er , i , j , k ;
complex excomplex ,Wnk, cx0 , cx1 ;
if (N>>2) {
// 如果样本数大于2
eb=1;
er =0;
while (er<N){
er=eb<<2;
for (i =0; i<N/er; i++){
for ( j =0; j<eb; j++) {
excomplex = x [er*i+eb+j];
x [er*i+eb+j]=x[ er*i+eb*2+j];
x [er*i+eb*2+j]=excomplex;
}
}
eb<<=1;
}
FFT_Sort(x ,N>>1);// 计算前半部分的偶数列
FFT_Sort(x+(N>>1),N>>1);// 计算后半部分奇序列
for (k=0;k<N>>1;k++) {
Wnk.re = (float)cos(-2*__PI*k/N);
Wnk.im = (float)sin(-2*__PI*k/N);
cx0 = x[k] ;
cx1 = x[k+(N>>1)];
x[k] = complexAdd(cx0, complexMult(Wnk, cx1));
Wnk.re = -Wnk.re ;
Wnk.im = -Wnk.im ;
x[k+(N>>1)] = complexAdd(cx0, complexMult(Wnk, cx1));
}
} else {
cx0 =x[0] ;
cx1 = x[1] ;
x[0] = complexAdd(cx0, cx1);
cx1.im = -cx1.im;
cx1.re = -cx1.re;
x[1] = complexAdd(cx0, cx1);
}
}
之前提到,一个重要的问题在于如何对一段连贯的音频做切割,从而在保证其长度为 2基数的同时尽可能留有周期特性。为此,我采集了多段来自室友和我本人的正常语速说话的时域文件,结合相关文章,大致分析可以得知由于人的发声系统是一个时变系统,对于环境而言,我们发声的变
化是较为快速的,带来了在一个音素的发音区间内的短时平稳特性:

▲ 图2.3.1 连续语音的短时平稳特性 由上图也可以得到一个直观的感受,大致在 20ms-40ms这个范围内,人声的信号大致可以被看做为一个平稳的周期信号。根据上文所说,在 44100Hz的采样频率下,我们可以选择的分析帧长度可以计算得到:
L 1 = 20 m s ÷ 1000 m s 44100 = 882 ( H z ) L_1 = 20ms \div { {1000ms} \over {44100}} = 882\,\,\left( {Hz} \right) L1=20ms÷441001000ms=882(Hz) L 1 = 40 m s ÷ 1000 m s 44100 = 1764 ( H z ) L_1 = 40ms \div { {1000ms} \over {44100}} = 1764\,\,\left( {Hz} \right) L1=40ms÷441001000ms=1764(Hz)
因此较为合理的一个采样区间分析帧的长度为 512、1024或者 2048这三个值,而考虑到如上计算结果,我们选取 1024作为帧长来进行下一步的分析。这很好理解,长度过短必然导致频域分辨率不足,导致我们在重建的过程中失真;而长度过长同样将会纳入更多不平稳的部分,因此事实上对于不同的语速和音调都应该有相应的帧长调整。
2.4 评语操作流程解析
1. 在由此得到频域图像后,考虑到男女声的音调本身的差异,第一个直观的操作就是进行变调。日常生活中往往会出现一个容易察觉的现象,那就是任何一个视频或者音频,在倍速播放之后,男生的声音会显得更高,有时甚至听起来就是女声。这很直观,就是因为在倍速播放的过程中频率升高了。在调查了相关技术之后,这一部分的一个简单处理方式和我的想法是相似的,那就是通过增添或删去部分采样点来实现。这一步骤被称之为采样率重采样,在此过程中可能引入线性插值法实现含有小数点位数的频率放大。 (在完成这一步后发现市面上大部分变声软件可能就只做了这一步和一点延拓 )当然,也存在一系列类似于频域变换法 ,正弦建模法等方法都可以完成升高(降低)频率的目的,本文就不予讨论了。

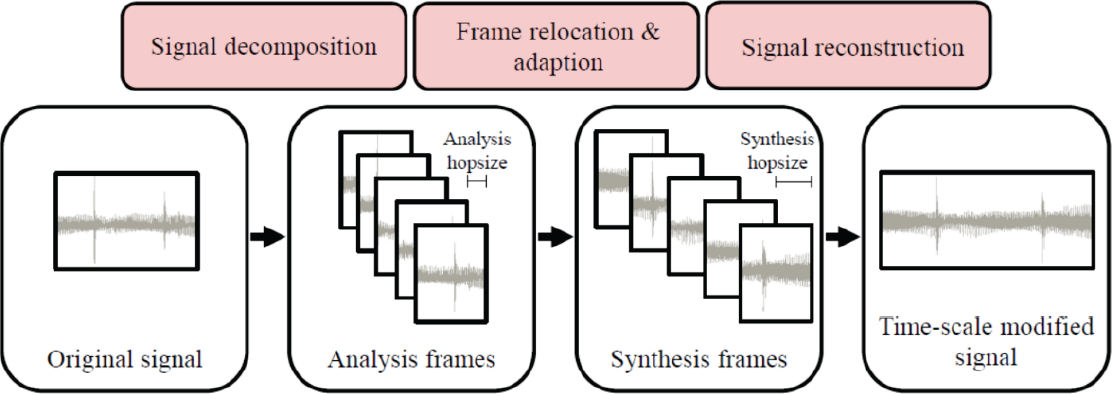
▲ 图2.4.1 频率变化带来的影响2. 在进行了频率的升高后,为了解决由第一步带来的声音长度变化问题,我们需要进行时域压缩或者延拓。基本目的是在不改变已经获得的音频文件的音调这一基础上,完成时域的时长修正。使用 TSM算法 (Time-scale modification)可以方便地在时域进行信号的拉长和缩短更改而几乎不影响其频域特征 (如基频、采样率、共振峰等等 )。具体的相关实现和基本方法我们将在之后介绍。
▲ 图2.4.2 TSM的经典算法3. 处理完成后使用逆变换代码回到时域,通过对比获得的时域特性和期望变声的时域特性差异进行调整。这一步较为简单,但要注意的是,由于我们是切割获得了多个用于频域分析的采样点块的,因此还需要进行重新的拼接工作。
§03实验过程
下面给出变声器的具体实验过程和效果演示 。
3.1 时域信号切割
在前文中我们提到,我们需要对人声信号进行分段的切割,然后再进行频域分析。为了保证不同帧块之间前后处理特征的平滑性,在切割过程中会在其之间加入一部分的重叠区 (overlap)。overlap的存在可以很好地避免信号中出现的跳变从而规避一些可能产生的模糊。一般而言, overlap的值大概选取为 50%-75%,我们选用百分之 75作为我们处理的 overlap。

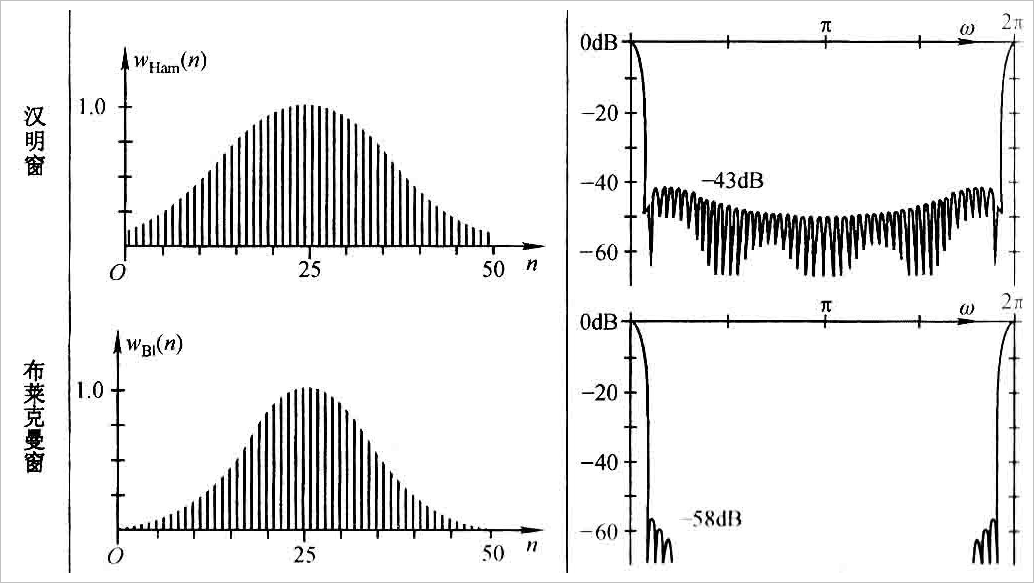
▲ 图3.1.1 保留overlap部分的截取 在课上老师曾经提到过关于截取信号时发生“频率泄露”的有关问题,故在截取每一段时域信号的过程中,我也尝试了多种不同的平滑窗口,如汉明窗和布莱克曼窗。在 MATLAB中,可以直接使用“h=hamming(N);”调用汉明窗,也可以使用如下代码:
▲ 图3.1.2 两种窗口的频谱特性VectorXd calc_hanning(size_t m, size_t n){
return 0.5 - 0.5*(2*M_PI*VectorXd::LinSpaced(m,1,m).array()/ (n+1)).cos();
}
VectorXd sym_hanning(size_t n) {
int half ;
VectorXd w1, w2;
if (n%2 ==0) {
//偶数阶
half =n/ 2;
w1 = calc_hanning(half , n);
w2= w1.reverse();
} else {
half =(n+1)/ 2;
w1 = calc_hanning(half , n);
w2=w1.reverse().segment(1, n-half);
}
VectorXd w(w1.size() + w2.size());
w << w1, w2;
return w;
}
VectorXd hanning(size_t n, bool flag=true) {
VectorXd w,w1;
if (flag) w = sym_hanning(n);
else {
w1 = sym_hanning(n ? 1);
w. resize(n);
w(0) = 0;
for (int i=0; i<n-1; i++)
w(i + 1) = w1(i);
return w;
}
使用 MATLAB可以对之前采集到的男女声进行时频图的绘画分析,从而判断人声的基频、第一和第二泛音等等。这和在本学期第一堂课中,使用时频图来分析电话号码是类似的道理。通过分析能量集中的高亮部分,我们可以得知不少信息:

▲ 图3.1.3 绘制的视频图(男)不难发现,颜色越亮则能量功率密度越大,也就意味着能量更为集中。最底部的频率为人声所产生的基频,这和我们之前所探讨的男性基频范围相吻合。基频往上的亮线则对应了第一、第二等等泛音。在本文的开头我们提到,声音还有一个重要的特征叫做共振峰,这一系列含有主要能量的黄线就对应共振峰,其频率为基频的整数倍。因此,更为合理且相似的变声策略同样需要在改变基频的基础上对共振峰做相应的修正。
3.2 升降频率实现变调
之前我们说过,可以通过对采样点的重采样完成频率的升高和降低。我们对样本点进行抽取就可以实现升高频率,而内插幅度为 0的样本点就可以实现降频。在进行相关操作之前,应该先使用滤波器来防止混叠;完成后也需要使用滤波器来滤去多出来的频率分量。这将会带来不可避免的信息损失,但影响不大。
而事实上,整数倍的频率提升也是不合理的,正常人声的差别很少存在如此大的差距。因此我们需要使用到先抽取、后插值的方法实现更为精确(如 1.4倍)的频率提升。
在此基础上,也有较为常用的线性插值重采样法等,主要使用在计算机算力较为有限的情况下。
将 8位位深的音频从 x Hz到 y Hz的重采样代码如下:
  void reSampleFreq(unsigned long inFreq, unsigned char * inData, unsigned long inLen,
  unsigned long outFreq, unsigned cha r* &outData, unsigned long &outLen,
  unsigned short bits, unsigned short channels) {
  outLen = (unsigned long)(inLen * (double)outFreq/inFreq);
  outData = new unsigned char[outLen];
  in bitBytes = (int)(bits / 8);
  int pointBytes = (int)(bitBytes * channels);
  unsigned long inSamplePoints = inLen / pointBytes;
  unsigned long outSamplePoints = outLen / pointBytes;
  unsigned char * ptInData = (unsigned char *)inData;
  unsigned char * ptOutData = (unsigned char *)outData;
  for(unsigned longi = 0; i < outSamplePoints; i ++) {
  double index = (double)i * inFreq / outFreq;
  int point1 = (int)index;
  int point2 = (inSamplePoints - 1 == point1) ? (inSamplePOints - 1) : point1 + 1;
  double coe = index - point1;
  ptOutData[i] = (unsigend char)((1.f - coe) * ptInData[point1] + coe * ptInData[point2]);
}
}
3.3 TSM算法原理介绍和实现
前文提及到,TSM可以用于帮助我们恢复因频率升降而导致的时域长度不对应问题。其主要思想是将一段音频信号进行分帧:
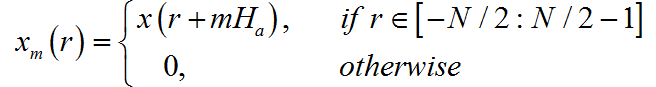
以 Ha和 Hs表示分帧和合帧的 overlap值;若分帧小于合帧,则“播放速度加快”,时域变短 ,反之变长。然后根据所需要拉缩的因子 α = Hs/Ha进行变换定位,变换完成后重新加和变成最终帧:
y ( r ) = ∑ m ∈ Z y m ( r − m H S ) y\left( r \right) = \sum\limits_{m \in Z}^{} {y_m \left( {r - mH_S } \right)} y(r)=m∈Z∑ym(r−mHS)
3.4.1 OLA 方法
一个最为简单的实现方式叫做 OLA(Overlap-and-Add),大致思想是经过汉宁窗等窗口叠加后,直接将 x(m+1)的波形拷贝到 y(m+1)处,并与 y(m)进行叠加。这样必然会导致块与块之间衔接处的断裂和损失,变化前后的相似性被忽略了,产生严重的相位断裂和重叠区域基频丢失。因为音频信号中的局部周期性与谐音(基音、泛音)相对应,因此 OLA并不适合处理这类信号:
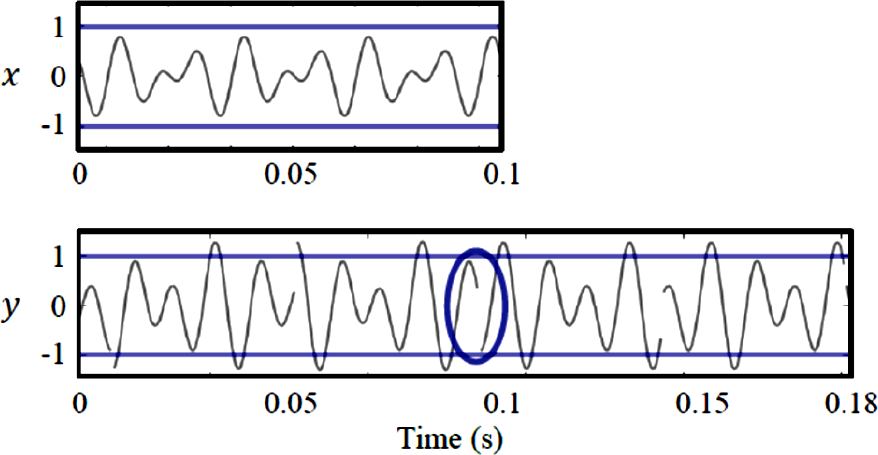
▲ 图3.4.1 OLA 发生连接处的断裂图 13: OLA发生连接处的断裂
在具体实现中会将 Ha取为两个帧之间的间隔,而 HS为两个块叠加的长度偏移( overlap值):

▲ 图3.4.2 OLA的基本流程3.4.2 WSOLA方法
针对 OLA进行修正改进,人们提出了 WSOLA方法:因为考虑到先前的叠加断裂很大程度上源自于前后相加的部分原本存在的相似性被忽略了,拼接部分的过渡平滑做得很差。因此同样是先选取一个帧块进行窗口叠加,然后在选取块附件小范围平移得到一个参考块,我们用于生成 y(m+1)的 x(m+1)块不直接复制,而是在原本选择的点附近寻找和参考块最为相似的块来作为 y(m+1),这样就更好地保持了前后的连接相似性。寻找最相似块的方法就是每一个 x(m+1)附近的偏移块都和参考块做相关运算,比较其求值大小即可。叠加效果得到了极大改善:
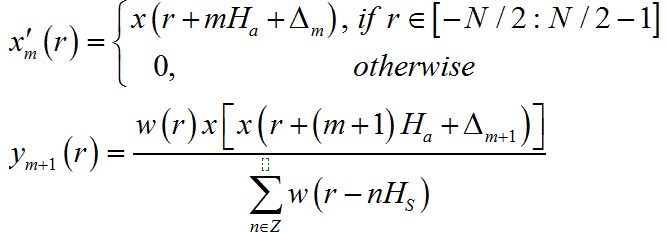
上述两种方式都或多或少会产生失真,且不提连接处丢失基频的问题,拼接的过程本身就可能导致一些冲击较强的信号被多次重复,使得毛刺和底噪增多。

▲ 图3.4.3 WSOLA的基本流程3.4.3 WSOLA基本流程
上述方法并没有加入额外的频域修正,而如果我们可以找到一个合理的修正方法去平滑这一拼接过程,不仅可以实现较好的衔接效果,重复出现的冲击内容也可以被消去。根据已经学过的知识,在傅里叶变换之中,相位谱同样包含了重要的信息。下面通过一个简单例子来说明:
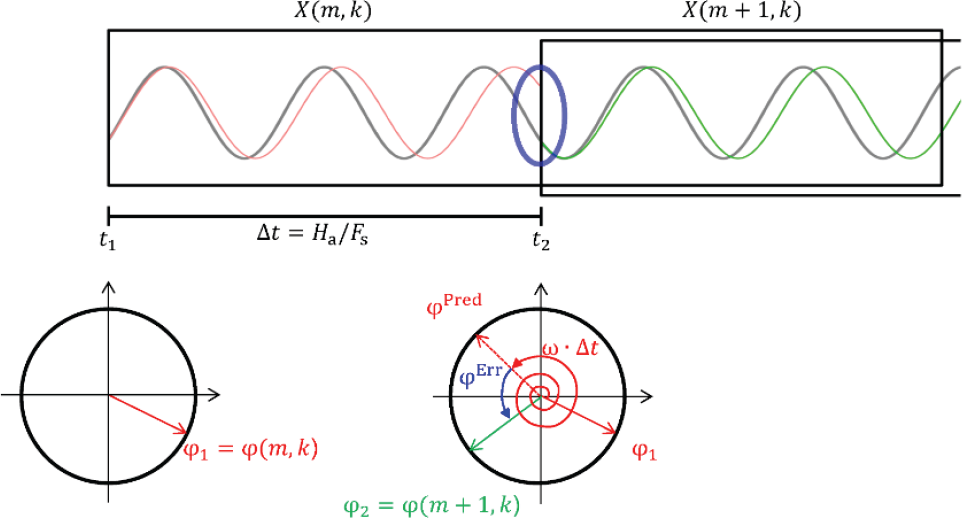
▲ 图3.4.4 借助相位关系修正频率对于任意两帧 m和 m+1,若其时间间隔为 ∆t,初始相位分别为 φ1和 φ2,那么会有
ϕ 2 = ϕ p r e d = ϕ 1 + ω Δ t \phi _2 = \phi ^{pred} = \phi _1 + \omega \Delta t ϕ2=ϕpred=ϕ1+ωΔt
φ2 = φ1 + ω∆t其中 φpred是理论上应该达到的值,但由于切割拼接过程中存在断裂和震荡,应该修改为
ϕ 2 = ϕ p r e d + ϕ e r r = ϕ 1 + ω Δ t \phi _2 = \phi ^{pred} + \phi ^{err} = \phi _1 + \omega \Delta t ϕ2=ϕpred+ϕerr=ϕ1+ωΔt
对应频率修正项就为:
Δ ω = ϕ 2 − ϕ 1 Δ t − ω = ϕ e r r Δ t \Delta \omega = { {\phi _2 - \phi _1 } \over {\Delta t}} - \omega = { {\phi ^{err} } \over {\Delta t}} Δω=Δtϕ2−ϕ1−ω=Δtϕerr
∆t其中 φerr由此给出:φerr = φ2 − φ1 − ω∆t
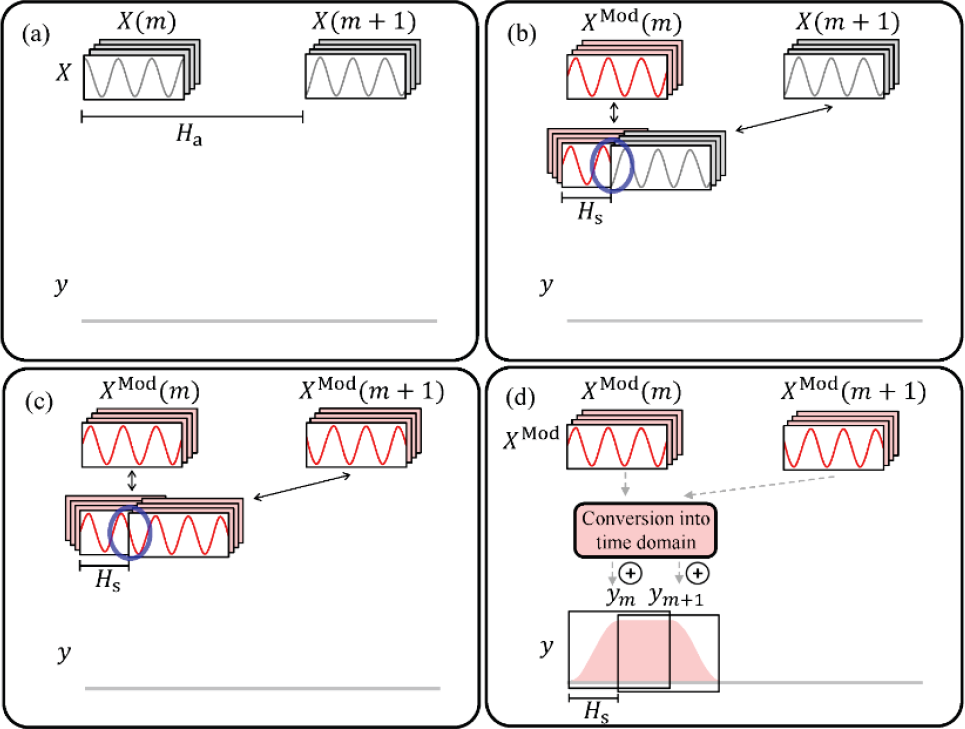
▲ 图3.4.5 PV-TSM基本原理 相位声码器 (Phase Vocoder,简称 PV)是一种通过利用给定的相位信息来完善 STFT的初略频率估计的技术。在 PV的帮助下,我们可以修正断裂的频率点,从而解决跳变问题。如上图所示,在对原信号进行分块切割后进行 STFT。不难知道:

而依次计算各个块之间的相位差后就可以从 0开始,依次迭代得到 ω修正后的值,从而构建没有频率跳变的信号:
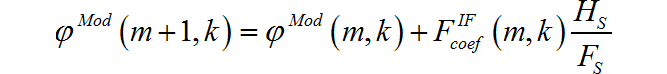
FS其中 Fcoef IF (m, k)= ω +∆ω ,边界是 φMod(0,k)= φ(0,k)这是相位谱和频率谱相互补充的体现,不仅计算量较小,也较好地保留了原本的特征。
3.5 变声模组实现
根据上文介绍的各种技术,我们最终选择使用现成的相位声码器作为调速工具,在重采样保证基频变调的基础上完成对应时域时间的长度稳定,最后做逆变换从而实现了较为简单的变声目的。变声后的成品我将在本文的附件中予以体现,通过对源代码输出流的修改就可以实现实时的输入直传输出,从而达到实时变声的目的。但本文完成的内容尚有较大提升空间,目前的设想是增加对泛音位置的权值滤波和对人声处理前的底噪和高频滤波,应当可以得到更为纯净的效果。(因为在完成本文之后笔者重听原始录音,发现在收音时的环境底噪就非常明显,其来源是宿舍的风扇)
笔者为了尝试声音变换带来的乐趣,在宿舍浅唱了两句并进行变换,没想到取得了两种不同风格的音色。目前处理后的音频还是存在一定的底噪和本音的部分,并且在唱歌的部分会产生较为突兀的尖音,显得声带很薄,像不会唱歌的人夹着嗓子唱歌。在 2号歌声中,由于歌曲风格不同,得 到了明显改善。变声器的应用场景十分广泛,对人声的处理技术也还在发展,希望今后我能在这次的基础上根据设想做出改进,而市场上也能出现一款真的可以“以假乱真”的产品(虽然,这或许并不是一件好事?)
※ 参考文献 ※
[1] Jonathan D , Meinard M . A Review of Time-Scale Modification of Music Signals[J]. Applied Sciences, 2016, 6(2):57.
[2] 变声导论-变声器原理及实现 (基音分类与滤波系统实现): https://zhuanlan.zhihu.com/p/111889443
[3] 一种基于数字信号处理的语音变声方法: https://patents.google.com/patent/CN1248191C/zh
[4] 语音信号的特性: https://blog.csdn.net/weixin_44874766/article/details/114396141
[5] 语音处理:音频信号短时平稳性分析: https://blog.csdn.net/qq_17256689/article/details/122717033
[6] 音频技术操作(重采样,增减益,混流,编解码及实际应用): https://zhuanlan.zhihu.com/p/390421970
[7] 变声导论-变声器原理及实现:https://zhuanlan.zhihu.com/p/110278983
[8] Zdeněk Pra, Holighaus N . Phase Vocoder Done Right[C]// EUSIPCO 17. 2017.
● 相关图表链接:
边栏推荐
- 01 three solutions to knapsack problem (greedy dynamic programming branch gauge)
- C graphical tutorial (Fourth Edition)_ Chapter 20 asynchronous programming: examples - cases without asynchronous
- Server coding bug
- Kotlin - improved decorator mode
- 【计网】第三章 数据链路层(2)流量控制与可靠传输、停止等待协议、后退N帧协议(GBN)、选择重传协议(SR)
- Sword finger offer 11 Rotate the minimum number of the array
- The difference between session and cookie
- 如何在微信小程序中获取用户位置?
- Quick learning 1.8 front and rear interfaces
- [colab] [7 methods of using external data]
猜你喜欢

Elk note 24 -- replace logstash consumption log with gohangout

Seven habits of highly effective people
Solve system has not been booted with SYSTEMd as init system (PID 1) Can‘t operate.

【数据库原理及应用教程(第4版|微课版)陈志泊】【第六章习题】

我的创作纪念日:五周年
IDEA 全文搜索快捷键Ctr+Shift+F失效问题

2022-02-09 survey of incluxdb cluster

并网-低电压穿越与孤岛并存分析
35道MySQL面试必问题图解,这样也太好理解了吧
![[data mining review questions]](/img/96/00f866135e06c4cc0d765c6e499b29.png)
[data mining review questions]
随机推荐
Detailed explanation of the most complete constraintlayout in history
Simple use and precautions of kotlin's array array and set list
SSH login server sends a reminder
A large select drop-down box, village in Chaoyang District
Seven second order ladrc-pll structure design of active disturbance rejection controller
GaN图腾柱无桥 Boost PFC(单相)七-PFC占空比前馈
Logback log framework
剑指 Offer 15. 二进制中1的个数
【计网】第三章 数据链路层(2)流量控制与可靠传输、停止等待协议、后退N帧协议(GBN)、选择重传协议(SR)
C graphical tutorial (Fourth Edition)_ Chapter 20 asynchronous programming: examples - using asynchronous
Slf4j log facade
剑指 Offer 14- I. 剪绳子
剑指 Offer 17. 打印从1到最大的n位数
[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [sqlserver2012 comprehensive exercise]
[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter III exercises]
对业务的一些思考
The latest version of lottery blind box operation version
[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter V exercises]
Fabric.js 更换图片的3种方法(包括更换分组内的图片,以及存在缓存的情况)
Dojo tutorials:getting started with deferrals source code and example execution summary