当前位置:网站首页>Flink SQL knows why (19): the transformation between table and datastream (with source code)
Flink SQL knows why (19): the transformation between table and datastream (with source code)
2022-07-03 13:11:00 【Big data sheep said】
1. Preface
Source official account back office reply 1.13.2 table datastream obtain .
I don't say much nonsense , Let's go directly to the contents and conclusions of this article , Small partners can see the conclusion first and quickly understand what help the blogger expects this article to bring to small partners :
Introduction to background and application scenarios : Bloggers expect you to know ,Flink Support SQL and Table API Medium Table And DataStream The interface to each other . In this way , We can add some custom data sources (DataStream) Create as SQL surface , Can also be SQL The execution result is converted to DataStream Then follow up to complete some in SQL Complex operations that cannot be realized in . The convenience of fat intestines .
At present, only flow tasks support inter conversion , Batch tasks do not support : stay 1.13 In the version , Due to the flow and batch env Different interfaces , Flow task is StreamTableEnvironment, Batch tasks are TableEnvironment, At present, only StreamTableEnvironment It supports the interface of mutual conversion ,TableEnvironment There is no such interface , Therefore, at present, flow tasks support mutual transfer , Batch tasks do not support . however 1.14 Batch task in version env It's all unified to StreamTableEnvironment in , All flow batch tasks can be transferred to each other .
Retract semantics SQL turn DataStream We need to pay more attention to :Append Semantic SQL To DataStream The use of API by
StreamTableEnvironment::toDataStream,Retract Semantic SQL To DataStream The use of API byStreamTableEnvironment::toRetractStream, The two interfaces are different , Young partner Meng must pay special attention to .
2. Introduction to background and application scenarios
I believe when you see the title of this article , I'll be more curious , To write SQL Just pure SQL Chant , To write DataStream Just pure DataStream Chant , Why integrate these two interfaces ?
Bloggers cite a case : In the scenario of selling more coupons , To control costs , Hope to add more than... To the daily coupon amount 1w when , Call the police in time , Control the budget .
Distribution data of coupon table :
| id(id) | time( Time ) | money( amount of money ) |
|---|---|---|
| 1 | 2021-11-01 00:01:03 | 10 |
| 2 | 2021-11-01 00:03:00 | 20 |
| 3 | 2021-11-01 00:05:00 | 30 |
| 4 | 2021-11-01 00:06:00 | 40 |
| 5 | 2021-11-01 00:07:00 | 50 |
The final expected result is : Daily money The sum exceeds 1w When , Alarm... Alarm !!!
So for the above scenario , There are two corresponding solutions :
programme 1: As one can imagine ,DataStream Is bound to solve our problems .
programme 2:DataStream Low development efficiency , have access to SQL Calculate the result of coupon issuance , however SQL Unable to call the police . So you can SQL The results of the query ( namely Table) To DataStream, And then in DataStream Operator of custom alarm logic after , Alarm when the threshold is exceeded .
This section introduces the scheme 2 How to realize .
Be careful :
Of course, there are other scenarios, such as pattern recognition, monitoring exceptions and then giving an alarm DataStream It's more complicated to implement , So we can use a similar idea , First SQL Implement business logic , And then one after another DataStream Operator to realize alarm logic .
3.Table And DataStream API The specific implementation of the transformation
3.1. Let's first look at a simple case on the official website
The case on the official website is mainly to show you what to do Table And DataStream API Which interfaces will be involved in the conversion of .
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
DataStream<String> dataStream = env.fromElements("Alice", "Bob", "John");
// 1. Use StreamTableEnvironment::fromDataStream API take DataStream To Table
Table inputTable = tableEnv.fromDataStream(dataStream);
// take Table Register as a temporary form
tableEnv.createTemporaryView("InputTable", inputTable);
// Then you can do some custom queries on this temporary table
Table resultTable = tableEnv.sqlQuery("SELECT UPPER(f0) FROM InputTable");
// 2. You can also use StreamTableEnvironment::toDataStream take Table To DataStream
// Be careful : This can only be changed to DataStream<Row>, The data type can only be Row
DataStream<Row> resultStream = tableEnv.toDataStream(resultTable);
// take DataStream The results are printed to the console
resultStream.print();
env.execute();
// prints:
// +I[Alice]
// +I[Bob]
// +I[John]
You can see that the key interface is :
StreamTableEnvironment::toDataStream: take Table To DataStream
StreamTableEnvironment::fromDataStream: take DataStream To Table
3.2. Realization of the first 2 The logic in Section
We use the two interfaces described above to implement the case of coupon payment amount early warning .
@Slf4j
public class AlertExample {
public static void main(String[] args) throws Exception {
FlinkEnv flinkEnv = FlinkEnvUtils.getStreamTableEnv(args);
String createTableSql = "CREATE TABLE source_table (\n"
+ " id BIGINT,\n"
+ " money BIGINT,\n"
+ " row_time AS cast(CURRENT_TIMESTAMP as timestamp_LTZ(3)),\n"
+ " WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND\n"
+ ") WITH (\n"
+ " 'connector' = 'datagen',\n"
+ " 'rows-per-second' = '1',\n"
+ " 'fields.id.min' = '1',\n"
+ " 'fields.id.max' = '100000',\n"
+ " 'fields.money.min' = '1',\n"
+ " 'fields.money.max' = '100000'\n"
+ ")\n";
String querySql = "SELECT UNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end, \n"
+ " window_start, \n"
+ " sum(money) as sum_money,\n"
+ " count(distinct id) as count_distinct_id\n"
+ "FROM TABLE(CUMULATE(\n"
+ " TABLE source_table\n"
+ " , DESCRIPTOR(row_time)\n"
+ " , INTERVAL '5' SECOND\n"
+ " , INTERVAL '1' DAY))\n"
+ "GROUP BY window_start, \n"
+ " window_end";
// 1. Create data source table , That is, coupon distribution details
flinkEnv.streamTEnv().executeSql(createTableSql);
// 2. perform query Inquire about , Calculate the daily payment amount
Table resultTable = flinkEnv.streamTEnv().sqlQuery(querySql);
// 3. Alarm logic (toDataStream return Row type ), If sum_money exceed 1w, Call the police
flinkEnv.streamTEnv()
.toDataStream(resultTable, Row.class)
.flatMap(new FlatMapFunction<Row, Object>() {
@Override
public void flatMap(Row value, Collector<Object> out) throws Exception {
long l = Long.parseLong(String.valueOf(value.getField("sum_money")));
if (l > 10000L) {
log.info(" Call the police , exceed 1w");
}
}
});
flinkEnv.env().execute();
}
}
The implementation effect is as follows :
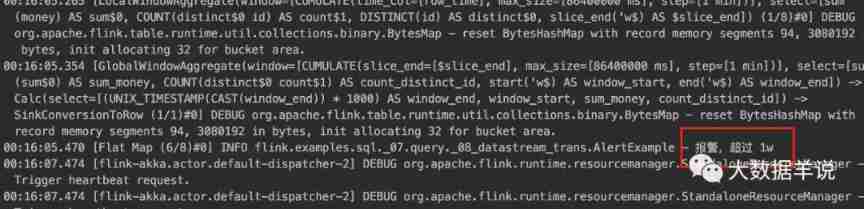
warn
3.3.Table and DataStream Conversion considerations
3.3.1. At present, only flow task rotation is supported (1.13)
Currently in 1.13 In the version ,Flink about Table and DataStream There are some restrictions on the transformation of :
Currently used by flow tasks env by StreamTableEnvironment, Batch tasks are TableEnvironment, and Table and DataStream At present, there are only StreamTableEnvironment Interface support for .
So in fact, little partner Meng can be understood as only flow tasks can support Table and DataStream Conversion between , Batch tasks are not supported ( Although you can use flow patterns to deal with bounded flows ( Batch data ), But less efficient , This kind of operation does not suggest that we engage in ).
When can we support the batch of tasks Table and DataStream The transition between ?
1.14 Versioning support .1.14 In the version , The flow and batch are unified to StreamTableEnvironment in , So you can do Table and DataStream Of each other .
3.3.2.Retract semantics SQL turn DataStream matters needing attention
Retract Semantic SQL Use toDataStream The conversion will report an error, which is not supported . The specific screenshot of error reporting is as follows . Does not support update Type of result data .

Retract error
If you want to put the Retract Semantic SQL To DataStream, We need to use toRetractStream. The following cases :
@Slf4j
public class AlertExampleRetract {
public static void main(String[] args) throws Exception {
FlinkEnv flinkEnv = FlinkEnvUtils.getStreamTableEnv(args);
String createTableSql = "CREATE TABLE source_table (\n"
+ " id BIGINT,\n"
+ " money BIGINT,\n"
+ " `time` as cast(CURRENT_TIMESTAMP as bigint) * 1000\n"
+ ") WITH (\n"
+ " 'connector' = 'datagen',\n"
+ " 'rows-per-second' = '1',\n"
+ " 'fields.id.min' = '1',\n"
+ " 'fields.id.max' = '100000',\n"
+ " 'fields.money.min' = '1',\n"
+ " 'fields.money.max' = '100000'\n"
+ ")\n";
String querySql = "SELECT max(`time`), \n"
+ " sum(money) as sum_money\n"
+ "FROM source_table\n"
+ "GROUP BY (`time` + 8 * 3600 * 1000) / (24 * 3600 * 1000)";
// 1. Create data source table , That is, coupon distribution details
flinkEnv.streamTEnv().executeSql(createTableSql);
// 2. perform query Inquire about , Calculate the daily payment amount
Table resultTable = flinkEnv.streamTEnv().sqlQuery(querySql);
// 3. Alarm logic (toRetractStream return Tuple2<Boolean, Row> type ), If sum_money exceed 1w, Call the police
// Tuple2<Boolean, Row> f0 Of Boolean Identify whether it is a fallback message
flinkEnv.streamTEnv()
.toRetractStream(resultTable, Row.class)
.flatMap(new FlatMapFunction<Tuple2<Boolean, Row>, Object>() {
@Override
public void flatMap(Tuple2<Boolean, Row> value, Collector<Object> out) throws Exception {
long l = Long.parseLong(String.valueOf(value.f1.getField("sum_money")));
if (l > 10000L) {
log.info(" Call the police , exceed 1w");
}
}
});
flinkEnv.env().execute();
}
}
5. Summary and prospect
Source official account back office reply 1.13.2 table datastream obtain .
This paper mainly introduces flink in Table and DataStream Mutual use , It also introduces some precautions for use , Summarized below :
Introduction to background and application scenarios : Bloggers expect you to know ,Flink Support SQL and Table API Medium Table And DataStream The interface to each other . In this way , We can add some custom data sources (DataStream) Create as SQL surface , Can also be SQL The execution result is converted to DataStream Then follow up to complete some in SQL Complex operations that cannot be realized in . The convenience of fat intestines .
At present, only flow tasks support inter conversion , Batch tasks do not support : stay 1.13 In the version , Due to the flow and batch env Different interfaces , Flow task is StreamTableEnvironment, Batch tasks are TableEnvironment, At present, only StreamTableEnvironment It supports the interface of mutual conversion ,TableEnvironment There is no such interface , Therefore, at present, flow tasks support mutual transfer , Batch tasks do not support . however 1.14 Batch task in version env It's all unified to StreamTableEnvironment in , All flow batch tasks can be transferred to each other .
Retract semantics SQL turn DataStream We need to pay more attention to :Append Semantic SQL To DataStream The use of API by
StreamTableEnvironment::toDataStream,Retract Semantic SQL To DataStream The use of API byStreamTableEnvironment::toRetractStream, The two interfaces are different , Young partner Meng must pay special attention to .
边栏推荐
- Sword finger offer14 the easiest way to cut rope
- 2022-02-10 introduction to the design of incluxdb storage engine TSM
- [review questions of database principles]
- [Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter 6 exercises]
- Reptile
- Useful blog links
- 剑指 Offer 11. 旋转数组的最小数字
- The foreground uses RSA asymmetric security to encrypt user information
- Server coding bug
- 开始报名丨CCF C³[email protected]奇安信:透视俄乌网络战 —— 网络空间基础设施面临的安全对抗与制裁博弈...
猜你喜欢

How to get user location in wechat applet?
Some thoughts on business
Flink SQL knows why (12): is it difficult to join streams? (top)
自抗扰控制器七-二阶 LADRC-PLL 结构设计

2022-02-11 heap sorting and recursion
Idea full text search shortcut ctr+shift+f failure problem
Method overloading and rewriting
![[network counting] Chapter 3 data link layer (2) flow control and reliable transmission, stop waiting protocol, backward n frame protocol (GBN), selective retransmission protocol (SR)](/img/45/c2d7934b886d8090373ca9e6e23c97.gif)
[network counting] Chapter 3 data link layer (2) flow control and reliable transmission, stop waiting protocol, backward n frame protocol (GBN), selective retransmission protocol (SR)
 [email protected]奇安信:透视俄乌网络战 —— 网络空间基础设施面临的安全对抗与制裁博弈..."/>
[email protected]奇安信:透视俄乌网络战 —— 网络空间基础设施面临的安全对抗与制裁博弈..."/>开始报名丨CCF C³[email protected]奇安信:透视俄乌网络战 —— 网络空间基础设施面临的安全对抗与制裁博弈...

Flick SQL knows why (10): everyone uses accumulate window to calculate cumulative indicators
随机推荐
Flink SQL knows why (VIII): the wonderful way to parse Flink SQL tumble window
C graphical tutorial (Fourth Edition)_ Chapter 15 interface: interfacesamplep271
[data mining review questions]
elk笔记24--用gohangout替代logstash消费日志
Flick SQL knows why (10): everyone uses accumulate window to calculate cumulative indicators
An example of newtonjason
【习题五】【数据库原理】
[Exercice 5] [principe de la base de données]
[problem exploration and solution of one or more filters or listeners failing to start]
Two solutions of leetcode101 symmetric binary tree (recursion and iteration)
[exercise 6] [Database Principle]
Detailed explanation of the most complete constraintlayout in history
剑指 Offer 14- II. 剪绳子 II
[Database Principle and Application Tutorial (4th Edition | wechat Edition) Chen Zhibo] [Chapter 6 exercises]
Image component in ETS development mode of openharmony application development
Harmonic current detection based on synchronous coordinate transformation
[colab] [7 methods of using external data]
Sitescms v3.0.2 release, upgrade jfinal and other dependencies
【習題五】【數據庫原理】
C graphical tutorial (Fourth Edition)_ Chapter 13 entrustment: delegatesamplep245