当前位置:网站首页>Flink SQL knows why (12): is it difficult to join streams? (top)
Flink SQL knows why (12): is it difficult to join streams? (top)
2022-07-03 13:10:00 【Big data sheep said】
1. Preface
After reading so many technical articles , Can you understand what the author wants you to learn after reading the article ?
Big data sheep said __ Your article will let you understand
1. The blogger will clarify what help the blogger expects this article to bring to the little partners , Let the little partner Meng intuitively understand the blogger's mind
2. Bloggers will start with practical application scenarios and cases , It's not just a simple pile of knowledge points
3. Bloggers will analyze the principles of important knowledge points , Let the young partner Meng understand in simple terms
To enter the body .
Source official account back office reply 1.13.2 sql join The wonderful way of analysis obtain .
The following is the article directory , It also corresponds to the conclusion of this paper , Small partners can look at the conclusion first and quickly understand what help this article can bring to you :
Introduction to background and application scenarios :join As the most common scenario in offline data warehouse , It must be impossible to lack it in the real-time data warehouse ,flink sql Offers a wealth of join The way ( summary 6 Kind of :regular join, Dimension table join,temporal join,interval join,array Beat flat ,table function function ) It provides a strong backing for us to meet our needs
Let's start with a practical case : Take an exposure log left join Click the log to expand the case , Introduce flink sql join Solutions for
flink sql join Solutions and existing problems : This paper mainly introduces regular join The running results of the above cases and the analysis of the source code mechanism , It's simple , however left join,right join,full join There will be retract The problem of , So before using , You should fully understand its operation mechanism , Avoid data duplication , More questions .
This paper mainly introduces regular join retract The problem of , The next section describes how to use interval join To avoid this retract problem , And meet the requirements of article 2 Actual combat case requirements of points .
2. Introduction to background and application scenarios
In our daily scenes , One of the most widely used operations must be join A place for , for example
Calculate the of exposure data and click data CTR, Need to go through the only id Conduct join relation
Fact data association dimension data acquisition dimension , Then calculate the dimension index
The above scenario , I won't say much about the wide application of offline data warehouse .
that , How to associate real-time streams ?
flink sql It provides us with four powerful ways of correlation , Help us achieve the purpose of flow correlation in the flow scenario . As shown in the screenshot of the official website below :

join
regular join: namely left join,right join,full join,inner join
Dimension table lookup join: Dimension table Association
temporal join: Snapshot table join
interval join: Two streams in a period of time join
array Explode : Column turned
table function join: adopt table function Custom function implementation join( Similar to the effect of column to row , Or similar to dimension table join The effect of )
In the real-time data warehouse ,regular join as well as interval join, And two join The combination of is the most commonly used . So this paper mainly introduces these two ( You may not want to see it for too long , So the following article will be concise , Short as the goal ).
3. Let's start with a practical case
First, let's take a real case to see in the scenario of specific input values , What the output value should look like .
scene : That is, the common exposure log stream (show_log) adopt log_id Associated click log stream (click_log), Distribute the data association results .
A wave of input data :
Exposure data :
| log_id | timestamp | show_params |
|---|---|---|
| 1 | 2021-11-01 00:01:03 | show_params |
| 2 | 2021-11-01 00:03:00 | show_params2 |
| 3 | 2021-11-01 00:05:00 | show_params3 |
Click data :
| log_id | timestamp | click_params |
|---|---|---|
| 1 | 2021-11-01 00:01:53 | click_params |
| 2 | 2021-11-01 00:02:01 | click_params2 |
The expected output data are as follows :
| log_id | timestamp | show_params | click_params |
|---|---|---|---|
| 1 | 2021-11-01 00:01:00 | show_params | click_params |
| 2 | 2021-11-01 00:01:00 | show_params2 | click_params2 |
| 3 | 2021-11-01 00:02:00 | show_params3 | null |
Familiar with offline hive sql My classmates may 10s Just finish the above sql 了 , as follows hive sql
INSERT INTO sink_table
SELECT
show_log.log_id as log_id,
show_log.timestamp as timestamp,
show_log.show_params as show_params,
click_log.click_params as click_params
FROM show_log
LEFT JOIN click_log ON show_log.log_id = click_log.log_id;
So let's take a look at the above requirements if we want to flink sql What needs to be done to achieve ?
Although not flink sql Provides left join The ability of , But in practice , Unexpected problems may arise . The next section details .
4.flink sql join
4.1.flink sql
Or the above case , Let's actually run it first and see the results :
INSERT INTO sink_table
SELECT
show_log.log_id as log_id,
show_log.timestamp as timestamp,
show_log.show_params as show_params,
click_log.click_params as click_params
FROM show_log
LEFT JOIN click_log ON show_log.log_id = click_log.log_id;
flink web ui The operator diagram is as follows :

flink web ui
give the result as follows :
+[1 | 2021-11-01 00:01:03 | show_params | null]
-[1 | 2021-11-01 00:01:03 | show_params | null]
+[1 | 2021-11-01 00:01:03 | show_params | click_params]
+[2 | 2021-11-01 00:03:00 | show_params | click_params]
+[3 | 2021-11-01 00:05:00 | show_params | null]
In terms of the results , The output data are +,-, The data representing its output is a retract Stream data . Analysis of the cause found that , Because of Article 1 show_log Precede click_log arrive , So just send it directly first +[1 | 2021-11-01 00:01:03 | show_params | null], Back click_log Upon arrival , The last unassociated show_log withdraw , Then associate the to +[1 | 2021-11-01 00:01:03 | show_params | click_params] Send out .
however retract The stream will result in writing to kafka More data , This is unacceptable . The result we expect should be a append Data flow .
Why? left join There will be such problems ? Then it's from left join The principle of .
To locate the specific implementation source code . Have a look first transformations.
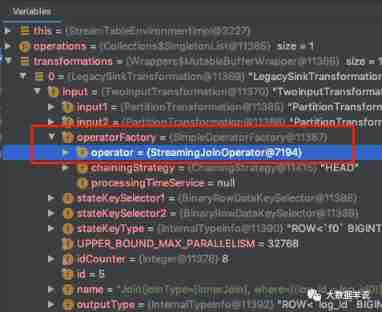
transformations
You can see left join The specific operator yes org.apache.flink.table.runtime.operators.join.stream.StreamingJoinOperator.
Its core logic focuses on processElement On the way . And the source code for processElement The processing logic of is explained in detail , As shown in the figure below .
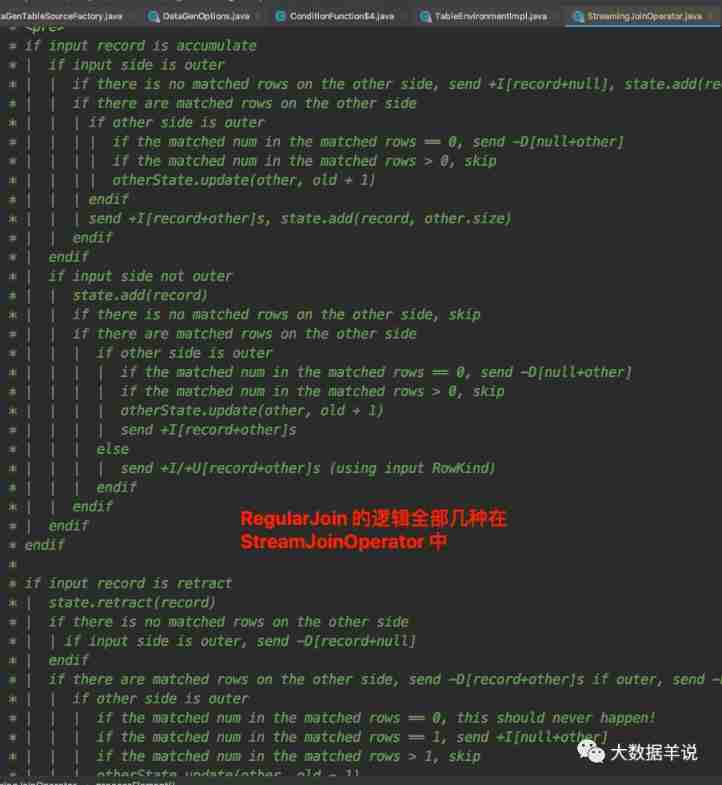
StreamingJoinOperator#processElement
Comments seem to be logically complex . We are here according to left join,inner join,right join,full join Classify and explain to you .
4.2.left join
First of all left join, On the surface of the above show_log( The left table ) left join click_log( Right table ) For example :
First of all, if join xxx on The condition in is that the equation represents join It's in the same key Next on ,join Of key namely show_log.log_id,click_log.log_id, identical key The data will be sent to a concurrent for processing . If join xxx on The condition in is inequality , Then the two streams source Operator direction join The operator sends data according to global Of partition The policy is issued , also join Operator concurrency is set to 1, All data will be sent to this concurrent processing .
identical key Next , When show_log A piece of data , If click_log There's data : be show_log And click_log All the data in the are traversed and correlated, and output [+(show_log,click_log)] data , And the show_log Save to the state of the left table ( For follow-up join Use ).
identical key Next , When show_log A piece of data , If click_log No data in : be show_log Don't wait for , Direct output [+(show_log,null)] data , And the show_log Save to the state of the left table ( For follow-up join Use ).
identical key Next , When click_log A piece of data , If show_log There's data : be click_log Yes show_log Traverse and correlate all the data in the . Before outputting data , Will judge , If the associated one show_log Not previously associated with click_log( That is, send it down [+(show_log,null)]), Then send one first [-(show_log,null)], Then send a message [+(show_log,click_log)] , It means that the previous one is not related to click_log Data show_log The intermediate result is withdrawn , Distribute the latest results related to the current , And put click_log Save to the state of the right table ( For subsequent left table Association ). This explains why the output stream is a retract flow .
identical key Next , When click_log A piece of data , If show_log No data : hold click_log Save to the state of the right table ( For subsequent left table Association ).
4.3.inner join
On the surface of the above show_log( The left table ) inner join click_log( Right table ) For example :
First of all, if join xxx on The condition in is that the equation represents join It's in the same key Next on ,join Of key namely show_log.log_id,click_log.log_id, identical key The data will be sent to a concurrent for processing . If join xxx on The condition in is inequality , Then the two streams source Operator direction join The operator sends data according to global Of partition The policy is issued , also join Operator concurrency is set to 1, All data will be sent to this concurrent processing .
identical key Next , When show_log A piece of data , If click_log There's data : be show_log And click_log All the data in the are traversed and correlated, and output [+(show_log,click_log)] data , And the show_log Save to the state of the left table ( For follow-up join Use ).
identical key Next , When show_log A piece of data , If click_log No data in : be show_log No data will be output , Will be able to show_log Save to the state of the left table ( For follow-up join Use ).
identical key Next , When click_log A piece of data , If show_log There's data : be click_log And show_log All the data in the are traversed and correlated, and output [+(show_log,click_log)] data , And the click_log Save to the state of the right table ( For follow-up join Use ).
identical key Next , When click_log A piece of data , If show_log No data : be click_log No data will be output , Will be able to click_log Save to the state of the right table ( For follow-up join Use ).
4.4.right join
right join and left join equally , It's just in reverse order , No more details here .
4.5.full join
On the surface of the above show_log( The left table ) full join click_log( Right table ) For example :
First of all, if join xxx on The condition in is that the equation represents join It's in the same key Next on ,join Of key namely show_log.log_id,click_log.log_id, identical key The data will be sent to a concurrent for processing . If join xxx on The condition in is inequality , Then the two streams source Operator direction join The operator sends data according to global Of partition The policy is issued , also join Operator concurrency is set to 1, All data will be sent to this concurrent processing .
identical key Next , When show_log A piece of data , If click_log There's data : be show_log Yes click_log Traverse and correlate all the data in the . Before outputting data , Will judge , If the associated one click_log Not previously associated with show_log( That is, send it down [+(null,click_log)]), Then send one first [-(null,click_log)], Then send a message [+(show_log,click_log)] , It means that the previous one is not related to show_log Data click_log The intermediate result is withdrawn , Distribute the latest results related to the current , And put show_log Save to the state of the left table ( For follow-up join Use )
identical key Next , When show_log A piece of data , If click_log No data in : be show_log Don't wait for , Direct output [+(show_log,null)] data , And the show_log Save to the state of the left table ( For follow-up join Use ).
identical key Next , When click_log A piece of data , If show_log There's data : be click_log Yes show_log Traverse and correlate all the data in the . Before outputting data , Will judge , If the associated one show_log Not previously associated with click_log( That is, send it down [+(show_log,null)]), Then send one first [-(show_log,null)], Then send a message [+(show_log,click_log)] , It means that the previous one is not related to click_log Data show_log The intermediate result is withdrawn , Distribute the latest results related to the current , And put click_log Save to the state of the right table ( For follow-up join Use )
identical key Next , When click_log A piece of data , If show_log No data in : be click_log Don't wait for , Direct output [+(null,click_log)] data , And the click_log Save to the state of the right table ( For follow-up join Use ).
4.6.regular join Summary of
In general, the above four join It can be divided as follows .
inner join Will wait for each other , Not until there is data .
left join,right join,full join Don't wait for each other , As long as the data comes , Will try to associate , If it can be associated, the fields distributed are all , If not, the field on the other side is null. When the follow-up data comes , When it is found that the previously issued data is not associated , Will do a pullback , Distribute the related results
4.7. How to solve retract This leads to repeated data distribution to kafka This question ?
since flink sql stay left join、right join、full join The principle of implementation is based on this retract The way to achieve , You can't meet the business in this way .
Let's change our thinking , Above join The characteristic of is that they don't wait for each other , Is there a kind of join We can wait for each other . With left join For example , When the left table cannot be associated with the right table , You can choose to wait for a period of time , If you can't wait beyond this period of time, you can issue it again (show_log,null), If you wait, send it (show_log,click_log).
interval join The debut . About interval join How to realize the above scenario , Its principle and implementation , this ( Next ) Will introduce in detail , Coming soon .
5. Summary and prospect
Source official account back office reply 1.13.2 sql join The wonderful way of analysis obtain .
This paper mainly introduces flink sql regular I'm satisfied join Problems in the scene , The operation principle is explained by analyzing its implementation , It mainly includes the following two parts :
Introduction to background and application scenarios :join As the most common scenario in offline data warehouse , It must be impossible to lack it in the real-time data warehouse ,flink sql Offers a wealth of join The way ( summary 4 Kind of :regular join, Dimension table join,temporal join,interval join) It provides a strong backing for us to meet our needs
Let's start with a practical case : Take an exposure log left join Click the log to expand the case , Introduce flink sql join Solutions for
flink sql join Solutions and existing problems : This paper mainly introduces regular join The running results of the above cases and the analysis of the source code mechanism , It's simple , however left join,right join,full join There will be retract The problem of , So before using , You should fully understand its operation mechanism , Avoid data duplication , More questions .
This paper mainly introduces regular join retract The problem of , The next section describes how to use interval join To avoid this retract problem , And meet the requirements of article 2 Actual combat case requirements of points .
边栏推荐
- Will Huawei be the next one to fall
- 2022-02-10 introduction to the design of incluxdb storage engine TSM
- 【习题五】【数据库原理】
- When the R language output rmarkdown is in other formats (such as PDF), an error is reported, latex failed to compile stocks Tex. solution
- 【数据挖掘复习题】
- PostgreSQL installation
- Analysis of a music player Login Protocol
- C graphical tutorial (Fourth Edition)_ Chapter 18 enumerator and iterator: enumerator samplep340
- C graphical tutorial (Fourth Edition)_ Chapter 13 entrustment: what is entrustment? P238
- Kotlin notes - popular knowledge points asterisk (*)
猜你喜欢
![[problem exploration and solution of one or more filters or listeners failing to start]](/img/82/e7730d289c4c1c4800b520c58d975a.jpg)
[problem exploration and solution of one or more filters or listeners failing to start]
![[combinatorics] permutation and combination (the combination number of multiple sets | the repetition of all elements is greater than the combination number | the derivation of the combination number](/img/9d/6118b699c0d90810638f9b08d4f80a.jpg)
[combinatorics] permutation and combination (the combination number of multiple sets | the repetition of all elements is greater than the combination number | the derivation of the combination number
Seven second order ladrc-pll structure design of active disturbance rejection controller

Grid connection - Analysis of low voltage ride through and island coexistence

Seven habits of highly effective people
Glide question you cannot start a load for a destroyed activity
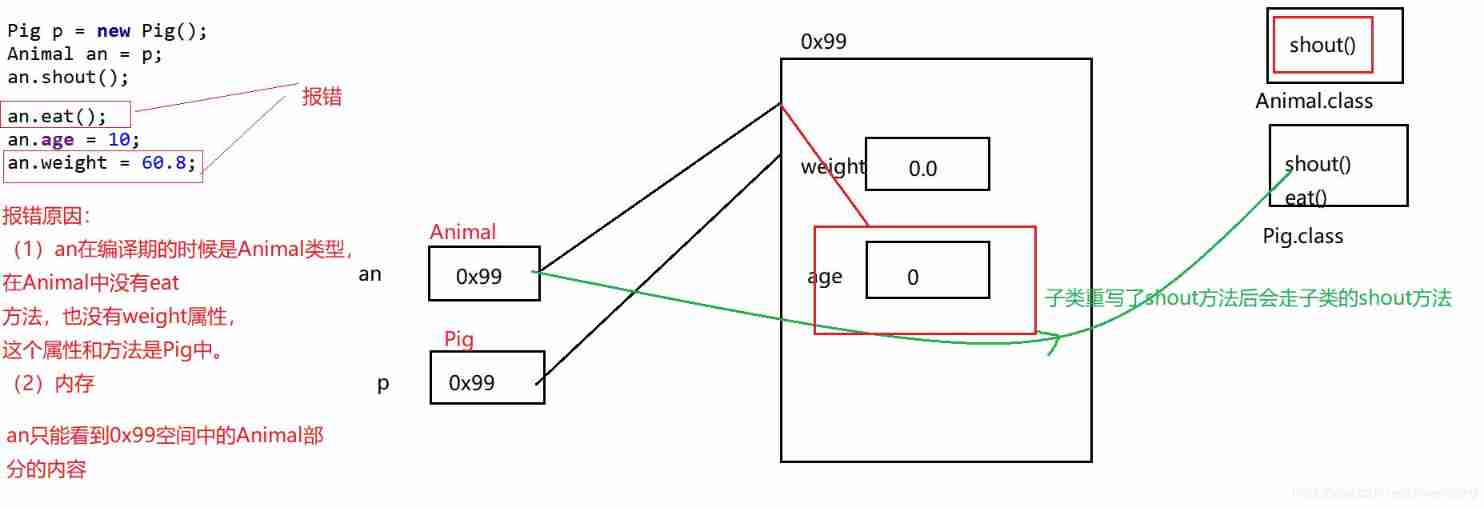
The upward and downward transformation of polymorphism

Finite State Machine FSM

Gan totem column bridgeless boost PFC (single phase) seven PFC duty cycle feedforward
The latest version of lottery blind box operation version
随机推荐
Two solutions of leetcode101 symmetric binary tree (recursion and iteration)
Powerful avatar making artifact wechat applet
[network counting] Chapter 3 data link layer (2) flow control and reliable transmission, stop waiting protocol, backward n frame protocol (GBN), selective retransmission protocol (SR)
2022-01-27 redis cluster brain crack problem analysis
sitesCMS v3.0.2发布,升级JFinal等依赖
Grid connection - Analysis of low voltage ride through and island coexistence
SLF4J 日志门面
CVPR 2022 图像恢复论文
CVPR 2022 image restoration paper
Cache penetration and bloom filter
Project video based on Linu development
[exercise 6] [Database Principle]
Integer case study of packaging
Deeply understand the mvcc mechanism of MySQL
[review questions of database principles]
[Exercice 5] [principe de la base de données]
Glide question you cannot start a load for a destroyed activity
studio All flavors must now belong to a named flavor dimension. Learn more
【数据挖掘复习题】
【数据库原理及应用教程(第4版|微课版)陈志泊】【第三章习题】