当前位置:网站首页>深度学习系列(二)优化器 (Optimization)
深度学习系列(二)优化器 (Optimization)
2022-08-05 05:16:00 【yiyexy】
梯度下降
在上一节中,我们已经提到了,我们最终估计一个模型他的拟合程度是通过成本函数计算结果来判断的。
因此我们很容易知道,当成本函数达到最小值时,我们的模型就达到了最优。因此,我们更新参数的目标应该是朝着减少成本函数值的方向前进。
这里我们可以用到一个数学上的概念去求成本函数的最小值。通过梯度来求解。当我们根据成本函数L求得了对参数W的偏导时,便可以根据公式:W := W- α \alpha αdW 对参数W进行更新。
其中, α \alpha α称为学习率,实际上你可以理解为W朝着梯度下降方向行走的步长。这里面梯度下降的具体原理,不过多解释,我们主要关注的是梯度下降的数据量问题。
在我们正常的模型训练中,我们通常是将所有样本放在一个矩阵中进行训练,但是当我们的数据集特别大的时候,往往会遇到这样的问题,每进行一次的梯度下降,我们就需要对所有样本集中求一次梯度。因此正确的参数更新如下: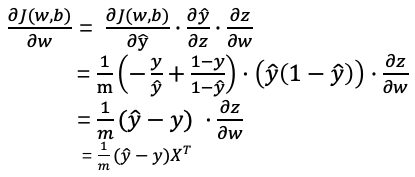
因此,当我们的样本数量很大时,每一次迭代都会花费大量时间,这对电脑内存和时间都是个不小的压力。
随机梯度下降
针对上面的问题,有人就提出了随机梯度下降法(SGD,Stochastic Gradient Descent)。所谓的随机梯度下降,就是指每一次梯度下降,都不再是求出所有样本的平均损失值来进行梯度下降,而是随机选择一个样本进行训练,根据这个样本的损失值进行梯度下降。
这个方法听上去似乎解决了大内存的问题,但是实际上,这个方法有很多的弊端,首先迭代次数过多,参数修改过于频繁;其次,每次梯度下降都是根据一个样本的值进行的,而一个样本的值计算出来的梯度可能会有误差,导致了参数向着相反的方向前进。
因此,随机梯度下降法并不能很好的解决梯度下降问题,人们结合这两种方法的各自有缺点提出了批量梯度下降法的概念。
批量梯度下降法
结合前两种方法各自的优缺点,我们每次梯度下降时候使用一批样本进行,这样的一批样本被称为(mini batch)。
这样,既解决了多样本消耗内存的问题,由降低了仅一个样本梯度的波动。使用批量梯度下降法时,尽管在下降的过程中,还是有向着相反方向前进的错误,但是这种错误会少很多,且对最终结果影响不大。
边栏推荐
猜你喜欢
Redis集群(docker版)——从原理到实战超详细
![[Pytorch study notes] 11. Take a subset of the Dataset and shuffle the order of the Dataset (using Subset, random_split)](/img/59/ce3e18f32c40a97631f5ac1b53662a.png)
[Pytorch study notes] 11. Take a subset of the Dataset and shuffle the order of the Dataset (using Subset, random_split)
【shell编程】第二章:条件测试语句
【数据库和SQL学习笔记】5.SELECT查询3:多表查询、连接查询
Comparison and summary of Tensorflow2 and Pytorch in terms of basic operations of tensor Tensor
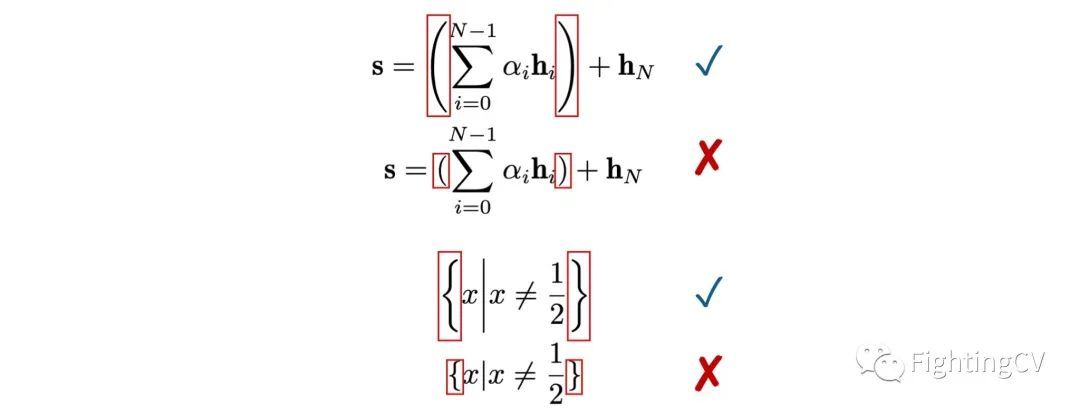
You should write like this
Redis设计与实现(第一部分):数据结构与对象

华科提出首个用于伪装实例分割的一阶段框架OSFormer
![[Practice 1] Diabetes Genetic Risk Detection Challenge [IFLYTEK Open Platform]](/img/10/7aa3153e861354178f048fb73076f7.png)
[Practice 1] Diabetes Genetic Risk Detection Challenge [IFLYTEK Open Platform]
物联网:LoRa无线通信技术
随机推荐
常见的 PoE 错误和解决方案
SSL 证书签发详细攻略
【ts】typescript高阶:分布式条件类型
物联网-广域网技术之NB-IoT
Thread handler handle IntentServvice handlerThread
单片机按键开发库-支持连击、长按等操作
基于STM32F407的WIFI通信(使用的是ESP8266模块)
发顶会顶刊论文,你应该这样写作
物联网:LoRa无线通信技术
网络信息安全运营方法论 (下)
【nodejs】第一章:nodejs架构
通过Flink-Sql将Kafka数据写入HDFS
【ts】typescript高阶:条件类型与infer
OSPF故障排除办法
【论文精读】ROC和PR曲线的关系(The relationship between Precision-Recall and ROC curves)
【ts】typescript高阶:联合类型与交叉类型
网工必用神器:网络排查工具MTR
1008 数组元素循环右移问题 (20 分)
八、响应处理——ReturnValueHandler匹配返回值处理器并处理返回值原理解析
[Database and SQL study notes] 8. Views in SQL