当前位置:网站首页>【论文阅读-表情捕捉】ExpNet: Landmark-Free, Deep, 3D Facial Expressions
【论文阅读-表情捕捉】ExpNet: Landmark-Free, Deep, 3D Facial Expressions
2022-08-05 05:15:00 【sc0024】
ExpNet: Landmark-Free, Deep, 3D Facial Expressions
introduction
同团队的两篇前作……
我们的论文使用类似的技术来模拟 3D 面部表情。具体来说,我们展示了如何使用我们提出的深度神经网络:ExpNet,直接从图像强度建模面部表情。据我们所知,这是第一次展示 CNN 直接估计 3D 表达系数,而不需要或涉及面部标志检测。
然而,我们超越了以前的工作,还提供了我们面部表情估计的定量比较。为此,我们建议测量不同的表情回归方法在扩展 Cohn-Kanade (CK+) [27] 和 EmotiW17 基准 [10] 上捕捉面部情绪的能力。这两个基准都包含标记为情绪类别的面部图像,使我们能够专注于我们的方法和其他方法如何捕捉情绪。我们表明,我们的深度方法不仅提供了更有意义的表达表示,而且与为此目的依赖地标的方法相比,它在缩放变化方面更加稳健。最后,为了促进我们结果的再现,我们的代码和深度模型是公开的。
Related Work
A. Expression Estimation
我们首先强调 情感分类 与 表情回归 任务之间的区别。前者试图将图像或视频分类为离散的面部情感类集 [10]、[27] 或动作单元 [14]、[47]。这个问题通常通过考虑面部标志的位置来解决。近年来,越来越多的最先进的方法转而采用深度网络[25]、[26]、[48],将它们直接应用于图像强度,而不是将地标位置估计为代理步骤。
表情回归方法试图提取面部变形的参数。这些参数通常以 active appearance models (AAM) [27] 和 Blendshape 模型系数 [33]、[49]、[50] 的形式表示。在这项工作中,我们专注于估计 3D 表达系数,使用 3DDFA [49] 描述的相同表示。然而,与 3DDFA 不同,我们将表情系数回归与面部标志检测完全分离。我们的测试表明,通过这样做,我们获得了一种对改变图像比例更稳健的方法。
B. Facial Landmark Detection
已经有大量工作致力于准确检测面部标志,而不仅仅是因为它们在表情估计中的作用。人脸标志检测是一个普遍的问题,在许多人脸相关系统中都有应用。地标检测器通常用于通过在 2D 和 3D 中应用刚性 [12]、[13]、[40] 和非刚性变换 [16]、[22]、[49] 变换来对齐人脸图像 [17]、[ 28]、[29]、[30]、[31]。
一般来说,地标检测器可以分为两大类:基于回归的[6]、[23]、[41]和基于模型的[2]、[46]、[49]技术。基于回归的方法直接从面部外观估计地标位置,而基于模型的方法明确地对地标的形状和外观进行建模。无论采用哪种方法,只要以极端的平面外旋转(远离正面)、低比例或当人脸边界框与用于开发地标检测器的人脸边界框显着不同时,地标估计都可能失败。
为了解决变化 3D 姿势的问题,与我们自己相关的最近的 3DDFA [49] 使用 CNN 学习 3DMM 表示的参数。然而,与我们不同的是,它们规定了一种迭代的、综合分析的方法。与我们相关的还有最近的 CE-CLM [46]。 CE-CLM 引入了卷积专家网络来捕获非常复杂的地标外观变化,从而实现最先进的地标检测精度。
面部标志的确切位置曾经被认为是特定于主题的信息,可用于面部识别[11]。然而,今天,这些尝试几乎都被放弃了。转向其他人脸表示的原因可能是由于现代人脸识别系统 [24] 通常假设的真实图像条件,其中即使是最先进的地标检测精度也不足以仅根据他们的位置来区分个体检测到面部标志。然而,在其他应用中,面部标志占主导地位。这项工作遵循最近的尝试,最著名的是 Chang 等人[7]通过为面部理解任务提出具有里程碑意义的免费替代方案。这项工作旨在允许对无视界标检测技术的图像进行准确的表达估计,其精神类似于放弃界标作为表示身份的手段。据我们所知,以前从未尝试过这种直接、无里程碑、深度的表达建模方法。
建模
A. Representing 3D Faces and Expressions
我们建议使用直接应用于图像强度的 CNN 来估计面部表情系数。训练这种深度网络时的一个主要问题是标记训练数据的可用性。出于我们的目的,训练标签是表达系数的 29D 实值向量。这些标签没有自然的解释,人类操作员可以很容易地使用这些标签来手动收集和标记训练数据。接下来,我们将解释如何表示 3D 形状及其表达式,以及如何收集大量数据以有效训练深度网络以达到我们的目的。
n n n: I \bold{I} I 中的像素数
m m m:3DMM系数的维度,这里取29
s s s:number of components,这里取99
α \alpha α和 η \eta η:控制变形的强度,也就是要估计的参数。有了这两个参数,就能用公式1重建出三维人脸。区别是 α \alpha α 是形状系数, η \eta η是表情系数。
B. Generating 3D Expression Data
据我们所知,没有公开可用的数据集包含足够多的用 29D 表达系数标记的人脸图像。据推测,缓解此问题的一种方法是使用 3D 面部表情数据库,例如 BU-4DFE [45] 作为训练数据集。然而,BU-4DFE 人脸是在受限条件下查看的,因此这会将网络的应用限制在受限设置中。此外,BU-4DFE 仅包含 101 个对象和 6 个面部表情,因此可以限制我们的网络预测的表情系数范围。
解决训练数据问题的另一种方法是利用面部标志检测基准。也就是说,在现有的地标检测基准中获取人脸图像,并使用其地面实况地标注释计算其表达系数,以获得 29D 地面实况表达标签。然而,现有的地标检测基准的大小有限:例如,流行的 300W 地标检测数据集 [36] 的训练和测试分割中的图像数量为 3,026。这对于训练深度 CNN 来回归 29D 实值向量来说太小了。
鉴于缺乏足够大和丰富的 3D 表情训练集,我们提出了一种简单的方法来生成大量的人脸示例,并结合 29D 表情系数标签。我们首先为 CASIA WebFace 集合 [44] 中的 50 万张人脸图像估计 99D 3DMM 系数。 3DMM 形状参数是按照 [38] 的最新方法估计的,为每个 CASIA 图像提供了其形状系数 α 的估计值。我们假设属于同一主题的所有图像都应具有相同的单一 3D 形状。因此,我们应用 [38] 的形状系数池化方法来平均属于同一主题的所有图像的 3DMM 形状估计,从而获得每个主题的单个 3DMM 形状估计。
使用 FPN [7] 额外估计每个图像的姿势。然后,我们使用标准技术 [15] 从该方法提供的 6DoF 计算投影矩阵 ∏ \prod ∏。
给定一个投影矩阵 ∏ \prod ∏,其作用是从恢复出的三维形状 S ′ S' S′ 映射到图像中的2D点,我们可以解决以下优化问题以获得表情系数 η \eta η:

C.训练的过程
在训练 ExpNet 时,我们使用从方程式 (2) 获得的表情系数作为 gt 标签。在实践中,ExpNet 采用了 ResNet-101 深度网络架构 [18]。我们没有尝试使用更小的网络结构,因此更紧凑的网络可能同样适用于我们的目的。我们的 ExpNet 经过训练以回归参数函数 f({W, b}, I \bold{I} I) → η \eta η,其中 {W, b} 表示 CNN 的参数过滤器和权重。我们在 ExpNet 预测与其表情系数标签之间使用标准的 L2 重建损失。
ExpNet 使用随机梯度下降 (SGD) 进行训练,小批量大小为 144,动量为 0.9,权重衰减为 5e-4。网络权重使用设置为 1e-3 的学习率进行更新。当验证损失饱和时,我们将学习率降低一个数量级,直到验证损失停止减少。训练期间不执行数据增强:也就是说,我们使用 CASIA 集中的普通图像,因为它们已经大致对齐 [44]。为了使训练更容易,我们从所有输入面中删除了经验平均值。
D. Estimating Expressions Coefficients with ExpNet
现有的表情估计方法通常采用综合分析方法来优化面部标志位置。与他们相反,我们的表达式是在我们的 CNN 的单次前向传播中获得的。为了估计表情系数向量 η t \eta_t ηt,我们为测试图像 I t \bold{I}_t It 评估 It f({W, b}, I t \bold{I}_t It)。我们使用 Yang 等人 [43]的人脸检测器对测试图像进行预处理,并将其返回的人脸边界框增加其大小的1.25倍。这种缩放是手动确定的,以使人脸边界框的大小与 CASIA 人脸的松散边界框的大小大致相同。
EXPERIMENTAL RESULTS
A. 定量测试
Benchmark settings. 除了 3DDFA [49],我们知道以前没有直接估计 29D 表达系数向量的方法。相反,以前的工作依赖于面部标志检测器,并使用它们检测到的标志来估计面部表情。因此,我们将 ExpNet 估计的表达式与从最先进的地标检测器获得的表达式进行比较。由于不存在具有基本真实表达系数的基准,我们将这些方法与面部情绪分类的相关任务进行比较。我们在这里的基本假设是,更好的表达估计意味着更好的情绪分类。
我们使用包含标记为离散情感类别的面部图像的基准。对于每张图像,我们估计其表达系数,要么直接使用我们的 ExpNet 和 3DDFA,或者如III-B节所述,通过求解方程(2) ,使用检测到的landmark。 然后,我们尝试使用和这些 29D expression representations 完全相同的分类流程,对测试图像的情绪进行分类。
我们的测试利用扩展的 Cohn-Kanade (CK+) 数据集 [27] 和野外挑战中的情绪识别 (EmotiW-17) 数据集 [10]。
CK+ 数据集是一个受约束的集合,正面图像是在实验室中拍摄的。CK+ 数据集包含 327 个面部视频片段,标记为七种情绪类别:愤怒 (An)、蔑视 (Co)、厌恶 (Di)、恐惧 (Fe)、快乐 (Ha)、悲伤 (Sa)、惊讶 (Su)。从每个剪辑中,我们获取分配有情感标签的帧的峰值帧(视频结尾)并将其用于分类。
而 EmotiW-17 数据集包含从 54 张电影 DVD [9] 中收集的极具挑战性的视频帧。另一方面,EmotiW-17 数据集提供 383 个面部视频剪辑,标记为 7 种情绪类别:愤怒 (An)、厌恶 (Di)、恐惧 (Fe)、快乐 (Ha)、中性 (Ne)、悲伤 (Sa ),惊喜(苏)。我们估计每帧的 29D 表达式表示,并在每个视频的所有帧上应用每帧估计的平均池化。
按照 [27] 使用的协议,我们运行了一个 leaveone 剪辑测试协议来评估性能。我们还评估了不同方法对规模变化的稳健性。具体来说,我们在多个版本的 CK+ 和 EmotiW-17 基准测试中测试了所有方法,每个版本的所有图像都缩小到 ×0.8、0.6、0.4 和 0.2 倍的大小。
情感分类pipeline 在我们所有的测试中,所有方法都使用了相同的简单分类方法。我们更喜欢简单的分类方法而不是最先进的技术,以防止通过使用复杂的分类器来掩盖地标检测器/情绪估计的质量。因此,我们使用 K = 5 的简单 kNN 分类器。重要的是要注意,所有测试方法获得的结果与该集合的最新技术水平相去甚远。我们的目标不是超越最先进的情感分类方法,而只是比较表达系数估计技术。
作者给出了三个方法在两个数据集上的分类混淆矩阵:
还有不同分辨率下不同方法的分类准确率(可见他们对低分辨率图像的效果也不错):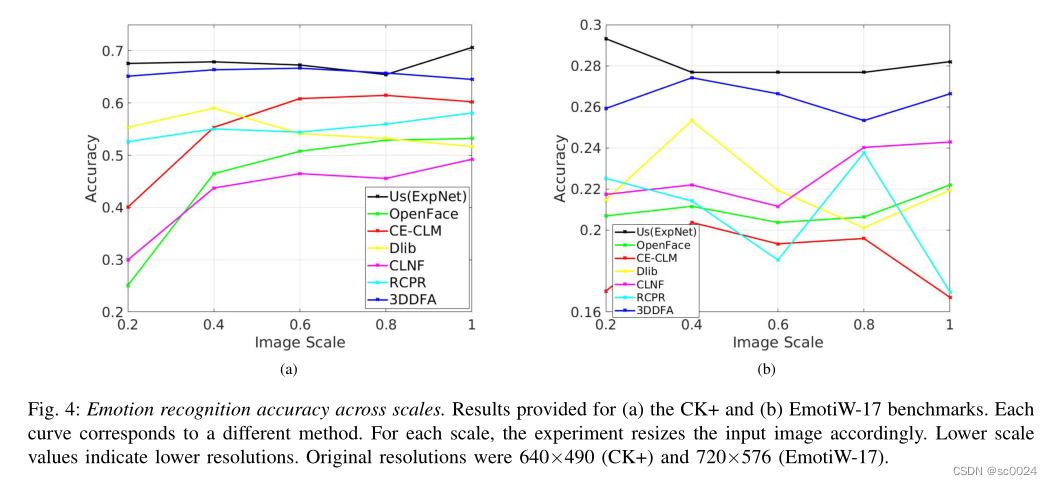
在运行时间方面:
基于landmark 的方法,都需要三步,总时间慢很多。一步到位的深度方法快了至少1个数量级,就快达到实时了。
B.定性测试
效果不错。

边栏推荐
猜你喜欢
怎么更改el-table-column的边框线
【数据库和SQL学习笔记】3.数据操纵语言(DML)、SELECT查询初阶用法

Calling Matlab configuration in pycharm: No module named 'matlab.engine'; 'matlab' is not a package
![[Practice 1] Diabetes Genetic Risk Detection Challenge [IFLYTEK Open Platform]](/img/10/7aa3153e861354178f048fb73076f7.png)
[Practice 1] Diabetes Genetic Risk Detection Challenge [IFLYTEK Open Platform]
【Pytorch学习笔记】9.分类器的分类结果如何评估——使用混淆矩阵、F1-score、ROC曲线、PR曲线等(以Softmax二分类为例)
![[Go through 8] Fully Connected Neural Network Video Notes](/img/0a/8b2510b5536621f402982feb0a01ef.png)
[Go through 8] Fully Connected Neural Network Video Notes

哥廷根大学提出CLIPSeg,能同时作三个分割任务的模型
Lecture 5 Using pytorch to implement linear regression
![[Over 17] Pytorch rewrites keras](/img/a2/7f0c7eebd119373bf20c44de9f7947.png)
[Over 17] Pytorch rewrites keras
My 的第一篇博客!!!
随机推荐
哥廷根大学提出CLIPSeg,能同时作三个分割任务的模型
flink on yarn 集群模式启动报错及解决方案汇总
What are the characteristics of the interface of the physical layer?What does each contain?
Kubernetes常备技能
Xiaobai, you big bulls are lightly abused
SQL(1) - Add, delete, modify and search
HQL statement execution process
DOM and its applications
MySQL
Lecture 2 Linear Model Linear Model
【NFT网站】教你制作开发NFT预售网站官网Mint作品
Flink HA安装配置实战
[Let's pass 14] A day in the study room
学习总结week2_2
flink部署操作-flink on yarn集群安装部署
Flink Oracle CDC写入到HDFS
Flutter 3.0升级内容,该如何与小程序结合
周末作业-循环练习题(2)
flink中文文档-目录v1.4
基于Flink CDC实现实时数据采集(四)-Sink接口实现