当前位置:网站首页>读论文- pix2pix
读论文- pix2pix
2022-08-05 05:15:00 【sc0024】
Image-to-Image Translation with Conditional Adversarial Networks(pix2pix)
代码地址:https://github.com/phillipi/pix2pix
摘要:我们研究条件对抗网络,作为图像到图像翻译问题的通用解决方案。这些网络不仅学习从输入图像到输出图像的映射,而且学习损失函数来训练该映射。这使得可以将相同的通用方法应用于传统上需要非常不同的损失公式的问题。我们证明了这种方法可有效地从标签图合成照片,从边缘图重建对象以及为图像着色等任务。
大多数图像到图像的翻译问题要么是多对一(将照片映射到边缘、片段或语义标签),要么是一对多(把标签或稀疏的用户输入映射到真实图像上)。传统上,这些任务中的每一项都是由单独的专用模型/算法处理的,但它们的共同特点是:根据像素预测像素。本文的目标是为所有这些问题开发一个通用框架。
普通的CNN存在的问题:如果我们采取简单的方法,要求CNN最小化预测的真实像素与gt像素之间的欧几里得距离,它将倾向于产生模糊的结果[29,46]。这是因为通过对所有可能的输出求平均来最小化欧几里得距离,这会导致模糊。因此设置合适的损失函数是很难的。
(因此我们需要GAN)本文中采用cGAN(conditional GAN),以输入图像为条件并生成相应的输出图像。
1 Related Works
略
2 METHODS
GAN是生成模型,可学习从随机噪声向量z到输出图像y的映射:G:z→y。而cGAN从观察到的图像x和随机噪声矢量z映射到y:G:{x,z}→y。经过对抗训练的判别器D对发生器G进行训练,使其产生与“真实”图像难分真假的输出,判别器D的任务是尽可能地检测出生成器G伪造出的“赝品”。此训练过程如图2所示。

2.1 目标函数
CGAN的目标函数可以表示为↓。其中G试图让目标最小化,与其对抗的D试图让目标最大化。
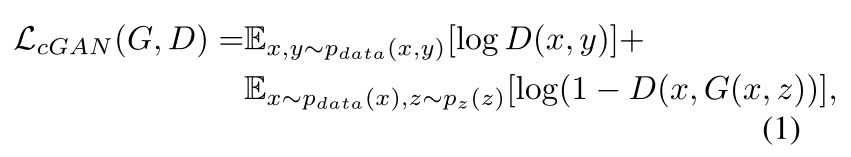
如果判别器不看输入x,普通GAN的损失函数:
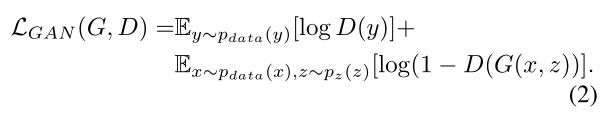
以前有条件GAN的方法已经发现,将GAN目标与更传统的损失(例如L2距离)混合是有益的[29]。鉴别器的工作保持不变,但生成器的任务不仅是欺骗鉴别器,而且还要接近L2意义上的地面真相输出。我们还探索了此选项,使用L1距离而不是L2,因为L1鼓励减少模糊:
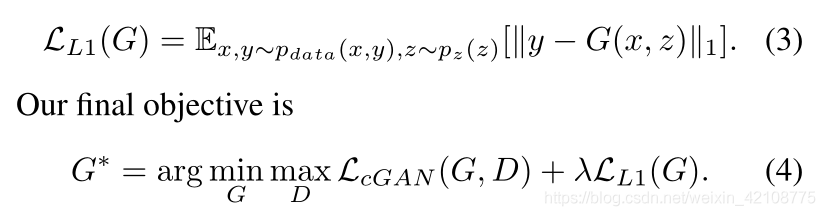
如果没有z,网络仍然可以学习从x到y的映射,但是会产生确定性的输出,因此无法匹配除delta函数以外的任何分布。过去的条件GAN都已经意识到这一点,并在输入x之外,提供了高斯噪声z作为生成器的输入(例如[39])。在最初的实验中,我们没有发现这种策略有效–生成器只是学会了忽略噪声–这与Mathieu等人的观点一致 [27]。然而,对于最终模型,我们仅以dropout的形式提供噪声,并在训练和测试时将其应用于生成器的多个层。尽管有噪声,但我们在网络输出中观察到的随机性很小。设计产生随机输出的条件GAN,从而捕获它们建模的条件分布的全部熵,是当前工作遗留的一个重要问题。
2.2 网络架构
我们根据[30]中的内容修改了生成器和鉴别器架构。生成器和鉴别器都使用 “卷积-BatchNorm-ReLu” [18]形式的模块。
2.2.1 Generator with skips
图像到图像转换问题的定义特征是,它们将高分辨率输入网格映射到高分辨率输出网格。此外,对于我们考虑的问题,输入和输出的表面外观不同,但是两者都是相同基础结构的绘制。因此,输入中的结构与输出中的结构大致对齐。我们围绕这些考虑因素设计生成器架构。
针对该领域问题的许多先前解决方案[29、39、19、48、43]已经使用了编码器-解码器网络[16]。在这样的网络中,输入将通过一系列逐渐递减采样的层,直到成为瓶颈层,然后逆转这个过程(图3)。这样的网络要求所有信息流都经过包括瓶颈在内的所有层。对于许多图像翻译问题,在输入和输出之间共享大量的低层信息,因此我们希望这些信息直接在网络上传递。例如,在图像着色的情况下,输入和输出共享突出边缘的位置。
为了给生成器一种避免此类信息瓶颈的方法,我们按照“ U-Net” [34]的一般形状添加了skip-connections(图3)。具体来说,我们在第i层和第n-i层之间添加skip-connections,其中n是层的总数。每个跳过连接仅将第i层的所有通道与第n-i层的所有通道连接在一起。

2.2.2马尔可夫鉴别器(PatchGAN)
众所周知,L2损失和L1(见图4)在图像生成问题上会产生模糊的结果[22]。尽管这些损耗不能促进高频脆性(highfrequency crispness),但在许多情况下,它们仍然可以准确地捕获低频。对于这种情况下的问题,我们不需要全新的框架,即可在低频下增强正确性。 L1就可以。
这促使将GAN鉴别器限制为仅对高频结构建模,这取决于L1项来强制实现低频正确性(公式4)。为了对高频进行建模,仅将注意力集中在局部图像补丁中就可以了。因此,我们设计了一个鉴别器架构(我们称之为PatchGAN),该架构只会在补丁规模上惩罚结构。该鉴别器尝试对图像中的每个N×N色块的真假进行分类。我们对该图像进行卷积运算,对所有响应求平均以提供D的最终输出。
在第3.4节中,我们证明N可以比图像的整个尺寸小得多,并且仍然可以产生高质量的结果。这是有利的,因为较小的PatchGAN具有较少的参数,运行速度更快,并可应用于任意大的图像。
这样的鉴别器有效地将图像建模为马尔可夫随机场,并假设相隔大于补丁直径的像素之间具有独立性。这种联系先前在[25]中进行过探讨,也是纹理[8,12]和样式[7,15,13,24]模型中的常见假设。因此,我们的PatchGAN可以理解为一种质地/样式(texture/style)损失的形式。
2.3. Optimization and inference
为了优化我们的网络,我们遵循[14]中的标准方法:我们在D的一个梯度下降步骤与G的一个步骤之间交替。我们使用minibatch SGD并应用Adam求解器[20]。
在测试时,我们以与训练阶段完全相同的方式运行生成器网络。这与通常的协议不同,在于我们在测试时应用dropout(一般来说,训练时用dropout屏蔽掉部分权重,测试时取消dropout),并且我们使用测试batch的统计数据,而不是训练batch的汇总统计数据,来应用BN[18]。当batchsize设置为1时,这种批标准化的方法被称为“实例标准化”(instance normalization),并已被证明对图像生成任务有效[38]。在我们的实验中,我们将batchsize = 1用于某些实验,将bathsize = 4用于其他实验,注意这两个条件之间的差异很小。
3 EXPERIMENTS
为了探索条件GAN的一般性,我们在各种任务和数据集上测试了该方法,包括图形任务(如照片生成)和视觉任务(如语义分割):
- 语义标签→照片,在Cityscapes数据集上训练[4]。
- 建筑标签→照片:在CMP Facades数据集[31]上训练。
- 地图→航拍图片,用从Google地图抓取的数据训练。
- BW→彩色照片,在[35]上训练。
- 边缘→照片,使用来自[49]和[44]的数据进行训练;使用HED边缘检测器[42]生成的二进制边缘加上后处理。
- 草图→照片:在[10]中的人为绘制的草图上测试边缘→照片模型。
- Day→night,用[21]训练。
3.1 评估指标
评估合成图像的质量是一个开放且困难的问题[36]。传统指标(如每像素均方误差)无法评估结果的联合统计信息,因此无法衡量结构化损失旨在捕获的结构。
为了更全面地评估结果的视觉质量,我们采用了两种策略。首先,我们在Amazon Mechanical Turk(AMT)上进行了“真假对比”感知研究。对于诸如着色和照片生成之类的图形问题,对于人类观察者而言,合理性通常是最终目标。因此,我们使用这种方法测试地图生成,航空照片生成和图像着色。
其次,我们测量合成的城市景观是否足够现实,以至于现成的识别系统可以识别其中的物体。此度量类似于[36]中的“初始得分”,[39]中的对象检测评估以及[46]中的“语义可解释性”度量。
AMT感知研究 对于我们的AMT实验,我们遵循[46]中的协议:向Turker进行了一系列试验,将“真实”图像与我们算法生成的“假”图像进行对比。在每次试验中,每张图像出现1秒钟,之后图像消失,并且给了Turkers无限制的时间来回答哪个是假的。每次练习的前10张图像都是练习,Turkers得到了反馈。没有对主要实验的40个试验提供反馈。每个会话一次只能测试一种算法,并且不允许Turkers完成一个以上的会话。约有50位Turker评估了每种算法。所有图像均以256×256分辨率呈现。与[46]不同,我们没有包括警戒性试验。对于我们的着色实验,真实和伪造的图像是从相同的灰度输入生成的。对于地图→航拍图像,真实图像和虚假图像不是从相同的输入生成的,从而使任务更加困难,并避免了最差的结果。
FCN-scores 虽然已知对生成模型的定量评估具有挑战性,但最近的工作[36、39、46]尝试使用预训练的语义分类器,将生成的图像的可分辨性作为伪度量,来进行测量。直觉是,如果生成的图像是真实的,则在真实图像上训练的分类器也将能够正确地对合成图像进行分类。为此,我们采用流行的FCN-8s [26]架构进行语义分割,并将其训练在城市景观数据集上。然后,我们根据合成精度对合成照片的标签进行分类,对合成照片进行评分。
3.2 目标函数分析
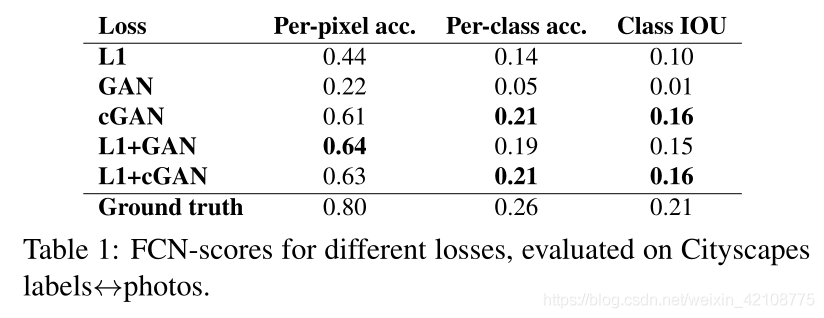
公式(4)中目标函数的哪些组成部分是重要的呢?我们进行了消融实验,以隔离L1项,GAN项的影响,并使用以输入为条件的鉴别器(cGAN,等式1)与使用无条件鉴别器(GAN,等式2)进行比较。
图4显示了这些变化对两个“标签→照片”问题的定性影响。仅L1会导致合理但模糊的结果。单独使用cGAN(在等式4中将λ设置为0)会给出更清晰的结果,但会导致外观合成中出现一些伪影。将两个项加在一起(λ= 100)可减少这些伪像。

我们使用在城市景观标签→照片任务(表1)上的FCN分数对这些观察值进行量化:基于GAN的目标函数获得更高的分数,表明合成图像包含更多可识别的结构。我们还测试了从鉴别器去除条件(标记为GAN)的效果。在这种情况下,损失不会惩罚输入和输出之间的不匹配;它只关心输出看起来逼真,这导致了非常差的性能。检查结果表明,不管输入照片如何,生成器都会崩溃,以产生几乎完全相同的输出。显然,在这种情况下,损失函数能够衡量输入和输出之间匹配的质量是非常重要的,实际上cGAN的性能要比GAN好得多。但是请注意,添加L1项还鼓励输出尊重输入,因为L1损失函数会惩罚“匹配输入的地面真实输出”和“可能不匹配的合成输出”之间的距离。相应地,L1 + GAN还可以有效地创建尊重输入标签图的逼真的效果图。将所有项组合起来,L1 + cGAN的效果最好。
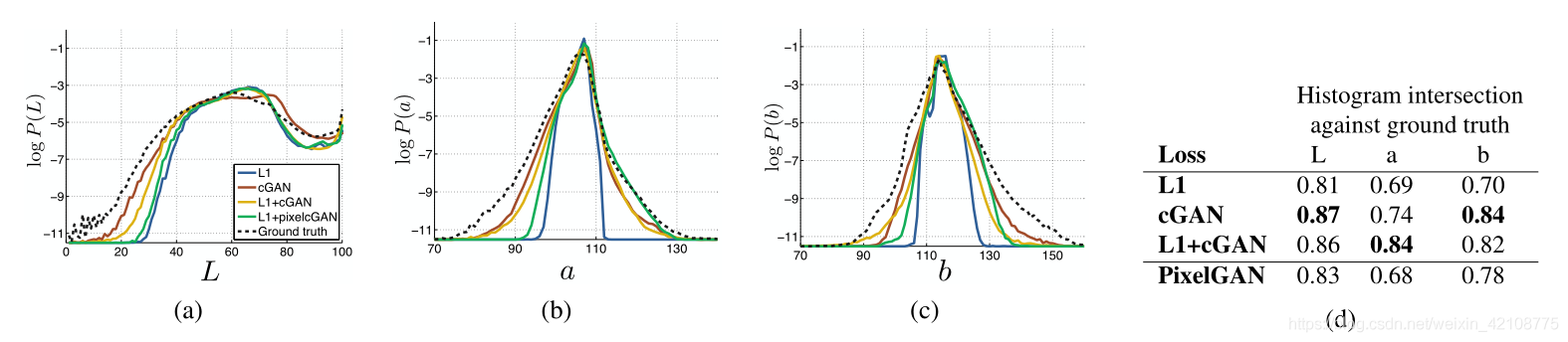
Colorfulness 条件GAN的惊人效果是,它们会产生清晰的图像,甚至在输入标签图中不存在空间结构时也会使空间结构产生幻觉。可能有人会想到cGAN在频谱维度上对“锐化”具有类似的作用-即使图像更彩色。正如L1在不确定要精确定位边缘的位置时,会使图像模糊一样,在不确定像素应采用几种可能的颜色值中的哪一个时,也会倾向于采用平均的浅灰色。特别是,L1将通过选择条件概率密度函数在可能颜色上的中值来最小化。另一方面,对抗性损失原则上可以意识到灰色输出是不现实的,并鼓励匹配真实的颜色分布[14]。在图7中,我们调查了我们的cGAN是否确实在Cityscapes数据集上实现了这种效果。这些图显示了Lab颜色空间中输出颜色值的边际分布。GT分布以虚线显示。显然,L1导致比实际情况更窄的分布,从而证实了L1鼓励使用平均的浅灰色的假设。另一方面,使用cGAN可使输出分布更接近基本情况。
3.3 生成器结构分析
U-Net体系结构允许低级信息在网络上走捷径。这会带来更好的结果吗?图5将U-Net与encoder-decoder结构在城市景观数据上进行了比较。只需通过切断U-Net中的跳过连接即可创建编码器/解码器。在我们的实验中,编码器/解码器无法学习生成逼真的图像,并且实际上崩溃了,无法为每个输入标签图生成几乎相同的结果。 U-Net的优势似乎并不是特定于条件GAN的:当U-Net和编码器/解码器都用L1损失训练时,U-Net再次获得了优异的结果(图5)。

3.4 From PixelsGANs to PatchGANs to ImageGANs
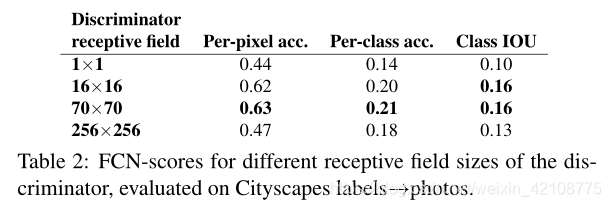
我们测试了从1×1的PixelGAN到完整的256×256的ImageGAN,改变辨别器感受野的patch大小N的效果。(我们通过调整GAN鉴别器的深度来实现patch大小的这种变化。附录中提供了此过程的详细信息以及鉴别器体系结构。)图6显示了该分析的定性结果,表2使用FCN评分量化了影响。请注意,除非另有说明,否则本文其他地方的所有实验均使用70×70 PatchGAN,对于本节而言,所有实验均使用L1 + cGAN损失。

PixelGAN对空间清晰度没有影响,但是确实增加了结果的色彩(在图7中进行了量化)。例如,当训练网络具有L1损失时,图6中的公交车被涂成灰色,但在使用PixelGAN损失时变为红色。颜色直方图匹配是图像处理中的常见问题[33],PixelGANs可能是有前途的轻量级解决方案。
使用16×16 PatchGAN足以提升清晰的输出,但也会导致平铺伪像。 70×70 PatchGAN减轻了这些伪影。扩展到整个256×256 ImageGAN似乎并不能改善结果的视觉质量,实际上FCN得分要低得多(表2)。这可能是因为ImageGAN参数更多,网络更深,更难训练。
全卷积转换 PatchGAN的一个优点是,可以将固定大小的鉴别器应用于任意大的图像。我们还可以将生成器卷积应用到比训练图像更大的图像上。我们在地图航空照片任务上对此进行了测试。在256×256图像上训练生成器后,我们在512×512图像上对其进行测试。图8中的结果证明了这种方法的有效性。
3.5 感知验证
我们验证了我们的结果在地图航空照片和灰度→彩色任务上的感知现实性。表3给出了AMT的地图照片实验结果。通过我们的方法生成的航拍照片在18.9%的试验中欺骗了参与者,大大高于L1 baseline,这会产生模糊的结果,并且几乎从未欺骗过参与者。相反,在照片→地图方向上,我们的方法仅在6.1%的试验中欺骗了参与者,这与L1基线的性能(基于自举测试)没有显着差异。这可能是因为较小的结构错误在具有刚性几何形状的地图中比在更加混乱的航空照片中更明显。

我们在ImageNet [35]上训练了色彩,并在[46,23]引入的测试分割上进行了测试。我们的方法由于L1 + cGAN缺失,在22.5%的试验中欺骗了参与者(表4)。我们还测试了[46]的结果以及使用L2损失的方法的变体(有关详细信息,请参见[46])。条件GAN的得分与[46]的L2变体相似(通过自举测试,差异不显着),但没有达到[46]的完整方法,这使参与者参加了我们实验中27.8%的试验。我们注意到,他们的方法经过专门设计,可以很好地实现着色。

3.6 语义分割
有条件的GAN似乎可以有效解决输出非常详细或照相的问题,这在图像处理和图形任务中很常见。视觉问题(例如语义分割)又如何呢?
为了对此进行测试,我们在城市景观照片→标签上训练了cGAN(有/没有L1损失)。图10显示了定性结果,表5列出了定量分类的准确性。有趣的是,经过训练的无L1损失的cGAN能够以合理的准确度解决此问题。据我们所知,这是GAN首次成功生成具有连续值变化的,几乎是离散的而不是“图像”的“标签” 。尽管cGAN取得了一些成功,但它们还远不是解决此问题的最佳方法:如表5所示,仅使用L1回归比使用cGAN可获得更好的分数。我们认为,对于视觉问题,目标(即预测接近gt的输出)可能不如图形任务那么模糊,并且像L1这样的重建损失就足够了。

4 结论
本文的结果表明,条件对抗网络是许多图像到图像翻译任务的有前途的方法,尤其是那些涉及高度结构化图形输出的任务。这些网络会学习到适合手头任务和数据的损失,这使得它们适用于多种设置。
5 附录
5.1 网络结构
令Ck表示具有k个滤波器的Convolution-BatchNorm-ReLU层。 CDk表示一个Convolution-BatchNorm-Dropout-ReLU层,其dropout率为50%。所有卷积都是stride为2的4×4空间滤波器。编码器和鉴别器中的卷积以2的系数下采样,而在解码器中,以2的系数上采样。
5.1.1 生成器结构
Encoder-Decoder 结构:
Encoder: C64-C128-C256-C512-C512-C512-C512-C512
Decoder: CD512-CD512-CD512-C512-C512-C256-C128-C64
在解码器的最后一层之后,使用卷积映射到输出通道的数量(除着色外,一般为3,为2),然后是Tanh函数。除上述标记外,BatchNorm不适用于编码器中的第一个C64层。编码器中的所有ReLU都是leaky,斜率为0.2,而解码器中的ReLU则不leaky。
除了在编码器中的每个层 i 和解码器中的层 n-i 之间加入了 skip-connections 之外,U-Net架构是相同的,其中n是层的总数。skip-connections将激活从第 i 层连接到第 n-i 层。这会更改解码器中的通道数:
U-Net decoder: CD512-CD1024-CD1024-C1024-C1024-C512-C256-C128
5.1.2 判别器结构
70×70的鉴别器架构是:C64-C128-C256-C512
在最后一层之后,应用卷积映射到一维输出,然后是Sigmoid函数。作为上述符号的例外,BatchNorm不适用于第一个C64层。所有ReLU都是leaky ReLU,斜率为0.2。
所有其他鉴别器都遵循相同的基本架构,深度不同以修改感受野的大小:
- 1 × 1 判别器: C64-C128 (note, in this special case, all convolutions are 1 × 1 spatial filters)
- 16 × 16 判别器: C64-C128
- 256 × 256 判别器: C64-C128-C256-C512-C512-C512
请注意,如果可用,则256×256鉴别器具有的感受野最多可以覆盖574×574像素,但是由于输入图像仅为256×256像素,因此只能看到256×256像素,因此我们将其作为256×256鉴别器。
5.2 训练细节
通过将256×256输入图像的大小调整为286×286,然后随机裁剪回256×256大小,来应用随机抖动。
所有网络都是从头开始训练的。从平均值为0,标准差为0.02的高斯分布初始化权重。
读后感:
- 消融实验逻辑很完整,每一步都有理有据,图和表结合很有说服力。
生成器实验:U-net VS 无skip-connections的Encoder-Decoder结构
判别器实验:不同的感受野大小
目标函数实验:L1、GAN、CGAN、L1+GAN、L1+cGAN - 不光学到了模型架构,也学了论文的组织形式、实验设计思路,而且工作量非常充实。
- 对于生成的图像的评价指标也很巧妙,没有局限于PSNR和SSIM(也没法局限)。用直方图来分析颜色分布让人想不到。第一遍看此文的时候还不知道FCN是什么,没看懂FCN-scores这个评价指标,二刷的时候觉得好厉害。
- 实验结果展示多样性,模型泛化能力强,不羞于展示自己翻车的图片和不如别人之处。
边栏推荐
- Pandas(五)—— 分类数据、读取数据库
- 【Reading】Long-term update
- 服务网格istio 1.12.x安装
- 【MySQL】数据库多表链接的查询方式
- 基于Flink CDC实现实时数据采集(一)-接口设计
- The difference between the operators and logical operators
- 用GAN的方法来进行图片匹配!休斯顿大学提出用于文本图像匹配的对抗表示学习,消除模态差异!
- 华科提出首个用于伪装实例分割的一阶段框架OSFormer
- MSRA提出学习实例和分布式视觉表示的极端掩蔽模型ExtreMA
- el-pagination左右箭头替换成文字上一页和下一页
猜你喜欢

记我的第一篇CCF-A会议论文|在经历六次被拒之后,我的论文终于中啦,耶!

Flink accumulator Counter 累加器 和 计数器

BFC详解(Block Formmating Context)
spingboot 容器项目完成CICD部署
![[Database and SQL study notes] 8. Views in SQL](/img/22/82f91388f06ef4f9986bf1e90800f7.png)
[Database and SQL study notes] 8. Views in SQL
发顶会顶刊论文,你应该这样写作
ECCV2022 | RU & Google propose zero-shot object detection with CLIP!
Flink 状态与容错 ( state 和 Fault Tolerance)

【Pytorch学习笔记】8.训练类别不均衡数据时,如何使用WeightedRandomSampler(权重采样器)
flink项目开发-flink的scala shell命令行交互模式开发
随机推荐
哥廷根大学提出CLIPSeg,能同时作三个分割任务的模型
It turns out that the MAE proposed by He Yuming is still a kind of data enhancement
神经网络也能像人类利用外围视觉一样观察图像
【After a while 6】Machine vision video 【After a while 2 was squeezed out】
SQL(1) - Add, delete, modify and search
[Go through 4] 09-10_Classic network analysis
[Database and SQL study notes] 9. (T-SQL language) Define variables, advanced queries, process control (conditions, loops, etc.)
Web Component-处理数据
el-table,el-table-column,selection,获取多选选中的数据
轻松接入Azure AD+Oauth2 实现 SSO
拿出接口数组对象中的所有name值,取出同一个值
Flink和Spark中文乱码问题
flink项目开发-flink的scala shell命令行交互模式开发
Flink accumulator Counter 累加器 和 计数器
Spark ML学习相关资料整理
基于Flink CDC实现实时数据采集(三)-Function接口实现
实现跨域的几种方式
【论文精读】ROC和PR曲线的关系(The relationship between Precision-Recall and ROC curves)
CAP+BASE
SharedPreferences和SQlite数据库