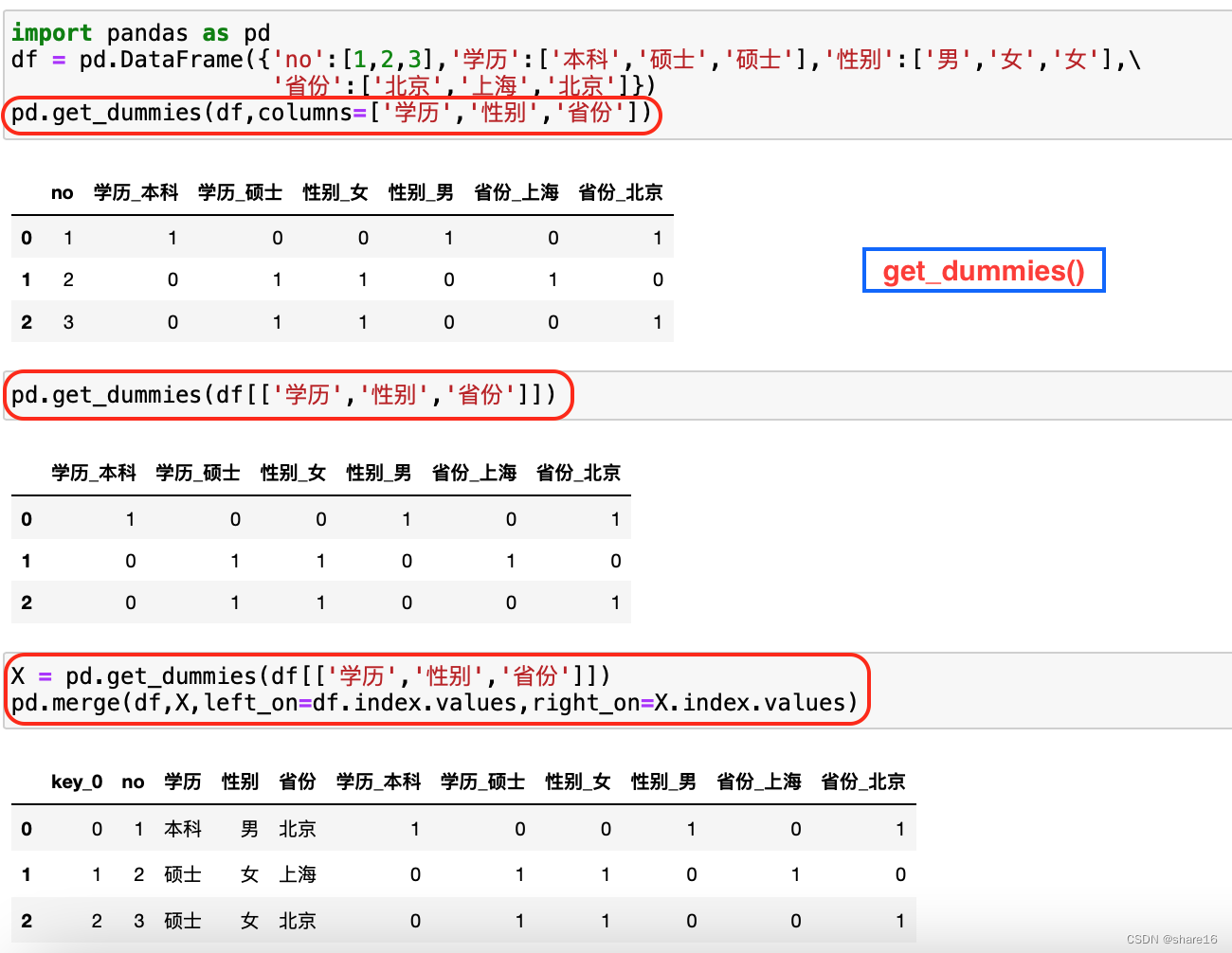
当前位置:网站首页>MaskDistill - Semantic segmentation without labeled data
MaskDistill - Semantic segmentation without labeled data
2022-08-05 05:38:00 【FightingCV】

本篇分享论文『Discovering Object Masks with Transformers for Unsupervised Semantic Segmentation』,苏黎世联邦理工学院&鲁汶大学提出MaskDistill,用Transformer来进行无监督语义分割,在PASCAL VOC上SOTA!代码已开源!
详细信息如下:

- 论文地址:https://arxiv.org/abs/2206.06363
- 代码地址:https://github.com/wvangansbeke/MaskDistill
01
摘要
无监督语义分割的任务旨在将像素聚类成具有语义意义的组.具体来说,分配给同一簇的像素应该共享高级语义属性,例如它们的对象或部件类别.
本文提出了 MaskDistill:一种基于三个关键思想的无监督语义分割新框架.首先,作者提倡一种数据驱动的策略来生成对象掩码,作为语义分割的像素分组先验.这种方法省略了手工制作的先验,这些先验通常是为特定的场景组合而设计的,并限制了目前框架的适用性.其次,MaskDistill 对对象掩码进行聚类以获得用于训练初始对象分割模型的伪ground-truth.第三,利用这个模型过滤掉低质量的对象掩码.这种策略减轻了之前像素分组中的噪声,并产生了一个干净的掩码集合,使用这些掩码来训练最终的分割模型.
通过结合这些组件,可以在 PASCAL (+11% mIoU) 和 COCO (+4% mask AP50) 上大大优于以前的无监督语义分割工作.有趣的是,与现有方法相反,本文的框架不锁定低级图像线索,也不限于以对象为中心的数据集.
02
Motivation为图像中的每个像素分配类别标签的任务(语义分割)已被广泛研究.语义分割工具用于许多领域,如自动驾驶、医学成像和农业.今天,研究人员通过深度卷积网络处理分割任务,该网络从完全标注的数据集中学习分层图像表示,其中每个像素都与一个类别标签相关联.然而,收集这样的标注会消耗大量的时间和金钱.
因此,一些工作探索了劳动强度较低的标记形式来训练分割模型,例如涂鸦、边界框、点击和图像级标签.还有一些工作研究了半监督方法,这些方法通过在训练期间利用额外的未标记图像来提高性能.在本文中,作者更进一步,以自监督的方式学习分割模型.具体来说,目标是学习一个聚类函数,将语义相关的像素分配给同一个聚类,而不依赖于人工标记.
为了实现这一概念,端到端方法通过对图像增强视图中像素的聚类分配施加一致性来学习聚类功能.然而,这些方法倾向于锁定低级图像线索,如颜色或纹理.此外,聚类强烈依赖于网络的初始化.与这些方法不同,作者不采用端到端策略.
另一组工作提出了一种自下而上的方法来解决这个问题.首先,他们利用边缘检测或显着性估计等低级或中级视觉先验来寻找可能共享相同语义的图像区域.在第二步中,他们使用图像区域来学习捕获语义信息的像素嵌入.特别是,图像区域充当正则化器,消除了分割对网络初始化的依赖.随后可以通过 K-means 对像素嵌入进行聚类以获得图像分割.虽然自下而上的方法获得了更好的结果,但它们也存在一些缺点.
最重要的是,手工制作的先验(例如边缘或显着性)对像素进行分组的依赖限制了它们的使用.例如,显着性估计仅适用于以对象为中心的图像.此外,一些作品需要标记来识别适当的图像区域.
本文提出了 MaskDistill,这是一个解决上述限制的新框架.与自底向上方法一样,MaskDistill 首先识别可能属于同一对象的像素组.由于对象性是一个高级构造,因此避免使用手工制作的先验,而是提倡数据驱动的方法.作者观察到自监督视觉Transformer学习空间结构的图像表示.
特别是,可以通过视觉Transformer中的注意力层提取高度准确的对象掩码.与依赖手工先验的现有工作不同,这有助于将本文的框架扩展到更具挑战性的数据集.特别是,手工制作的先验往往是为特定的场景组合而设计的.例如,显着性估计适用于对象较少的图像(例如PASCAL),但不适用于更复杂的场景(例如 COCO).本文的框架不存在这个问题.
本文对对象掩码进行聚类,并将结果用作伪ground-truth来训练对象分割模型,例如 Mask R-CNN.该模型预测对象掩码候选者及其置信度分数.作者观察到,较高的置信度分数与质量较好的对象掩码相关.基于这一观察,作者通过利用模型的预测构建了一组更清晰的对象掩码.具体来说,作者过滤掉每张图像的置信度分数低的预测.生成的对象掩码集用作伪ground-truth来训练最终的语义分割模型.
本文的贡献是:
开发了一个新的自下而上的框架来解决无监督语义分割的任务,
提出了一种数据驱动的策略来获得用于语义分割的像素分组先验基于自监督Transformer模型,
使用置信对象掩码候选者来改进分割结果,
在无监督设置下,在 PASCAL和COCO数据集上SOTA.
03
方法
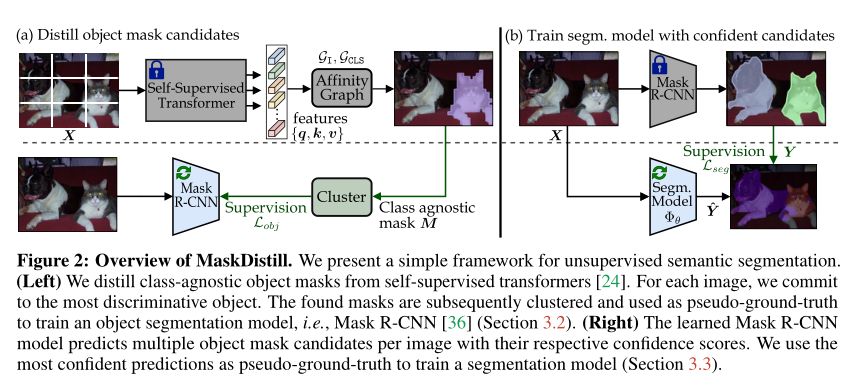
本文的方法遵循自下而上的方案来解决无监督语义分割任务.首先,作者提倡一种数据驱动的方法,通过自监督的视觉Transformer来挖掘对象掩码.其次,通过对象分割模型,即 Mask R-CNN提取每个图像的多个对象掩码.第三,讨论如何使用找到的对象掩码训练最终的分割模型.作为关键组件,作者仅使用具有高置信度分数的对象掩码.该策略减轻了掩码蒸馏步骤中引入的噪声.上图显示了本文提出的 MaskDistill 框架的概述.
3.1 Learning Objectness

端到端方法不太可能发现属于高级对象类别的图像区域,例如鸟类、猫、建筑物等.出于这个原因,作者遵循之前的工作,并提倡一种自下而上的方法来解决无监督语义分割的任务.特别是,在进行语义分割之前,首先将图像分解为其不同的组件是有利的.现有方法通过手工制作的低级(例如,超像素或边缘)或中级(例如,显着性)像素分组先验来实现这一点.然而,这样的先验是次优的.
基于超像素或边缘的低级先验会产生图像的过度分割,从而产生具有低语义内容的图像区域(见上图中的第一行).不同的是,中级先验可以聚合来自不同对象的部分(参见上图中的中间行).为了解决这些缺点,作者提出通过依赖自监督表示学习以数据驱动的方式获得像素分组先验.上图中的底行显示了一些示例.与手工制作的像素分组先验不同,本文的方法生成与真实目标对齐的对象掩码.
在本文中,作者基于自监督的视觉Transformer来挖掘对象掩码.做出这个决定的原因有三个.首先,transformers 在patch级别进行推理,这允许模型构建一个表示不同图像区域之间相似性的亲和图(affinity graph).
其次,自监督视觉Transformer学习了丰富的空间表示,这些表示可以捕获对象信息,这有助于它们用于挖掘对象掩码.此外,这些表示对每个图像组件的详细信息进行编码,这些信息可能超出人类定义的分类法.
第三,自监督的视觉Transformer不依赖于人类标记,这使模型能够利用大型未标记数据集.受这些发现的启发,作者提出从视觉Transformer中的最终自注意力层中提取对象信息.
3.2 Distilling Object Masks Using Self-Attention
Preliminaries
首先将图像reshape为 N 个patch序列.每个patch的大小为 S × S 像素.作者将图像patch称为patch token.patch token进一步与特殊分类token [CLS] 连接,从而产生由 N + 1 个token组成的输入序列.作者使用来自最终多头自注意力 (MSA) 块的特征来计算对象掩码,其中每个头 h 执行单个自注意力操作.Construct Affinity Graphs
Follow在之前的工作,作者构建了一个亲和图来测量图像patch之间的相似性.给定输入序列,将亲和向量 计算为最终 MSA 块中分类token [CLS] 和patch token [I] 之间的成对相似性.类似地,亲和矩阵测量所有patch token [I] 对之间的成对相似性.特别是,元素在序列的两个token i 和 j 之间计算,作为它们的特征表示和的点积,其中 .最后,作者对注意力头 上的亲和力进行平均:
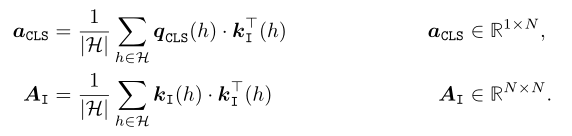
Select Discriminative Tokens
本文的目标是选择可能对应于对象部分的patch token.特别是,作者根据CLS token相应的的亲和力关注前 k 个响应.形式上,定义patch集,which represents the graph from the classificationtoken [CLS] 到patch token的有向边.此外,将 中具有最大(即 top-1)亲和力的patch定义为源patch.该区域往往对应于最具辨别力的图像组件,例如鸟的喙、犀牛的角等.
Construct Initial Masks
根据其源 s 和proposal ,为每个图像 X 生成单个对象掩码.源 s 应该属于预测的对象掩码,因为它代表对象最具辨别力的部分.遵循之前的工作,作者将信息从 s 扩散到proposal .特别是,只有 中与 s 相似的patch被进一步视为proposal .仅当时,对象掩码在位置 j 设置为 1.因此,如果 s 和之间的成对相似性总和为正,则块 j 与 s 属于同一对象.最后,使用最近邻插值对获得的掩码进行整形和上采样到原始图像大小(H,W),得到.
Distill Mask R-CNN
为了为每个图像生成多个候选对象掩码,作者训练了一个region proposal网络,即 Mask R-CNN.该对象分割模型需要每个图像的类别 c、边界框坐标 b 和前景-背景掩码 M.请注意,在上一步中已经获得了对象掩码及其对应的边界框坐标.但是,这些掩码与类无关.为了给每个掩码分配一个类标签 c,作者将聚类算法(例如,K-means)应用于掩码图像的输出 [CLS] token.现在,可以通过以下目标函数训练 Mask R-CNN:
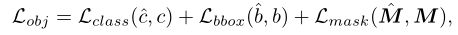
其中表示预测的类、边界框和掩码.重要的是,经过训练的模型预测每个图像的多个对象掩码候选者及其相关的置信度分数.作者利用这些预测作为伪ground-truth来训练下一节中的分割模型.
3.3 Training a Segmentation Model from Noisy Object Mask Candidates
考虑一组图像及其对应的对象掩码候选和置信度分数.一些掩码将不可避免地分配到错误的集群或不会与对象或部分对齐.有趣的是,作者通过实验观察到模型非常confident的掩码往往是正确的.与以前的方法不同,这使模型能够利用置信度分数来抑制先前噪声的影响.具体来说,只接受来自 Mask R-CNN 超过阈值 τ 作为的置信预测.最后,模型聚合属于同一图像的掩码以获得每个图像的初始语义分割.当两个候选重叠时,模型只保留最confident的掩码.构建的掩码用作伪ground-truth来训练语义分割模型.
最后,作者训练了一个语义分割模型,参数化权重为θ.该函数用softmax 操作,to perform a soft assignment on the cluster.为了克服类不平衡,同时获得细粒度的分割结果,作者采用了难像素挖掘策略.在每batch中选择前 k the most difficult pixels to train on.特别是,目标函数变为:
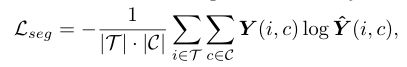
如果像素 i 属于 c 类,则获得的分割掩码为 1,否则为 0.
04
实验
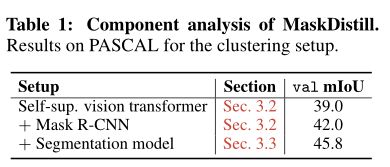
上表分析了 MaskDistill 的不同组件对 PASCAL 的 val 集的影响.通过 K-means 对初始对象掩码进行聚类时,实现了 39.0% mIoU(第一行).对象掩码是通过自监督视觉Transformer的亲和图获得的.当使用使用初始对象掩码(从 39.0% 到 42.0% mIoU - 第二行)训练的 Mask R-CNN 模型进行预测时,结果会得到进一步改进.
这表明本文的对象掩码候选者捕获了高级对象信息,这很难通过手工制作的先验来实现.最后,作者利用 Mask R-CNN 预测的置信度分数.结果表明,通过仅使用来自 Mask R-CNN 的可靠对象掩码候选,分割结果从 42.0% 提高到 45.8% mIoU.
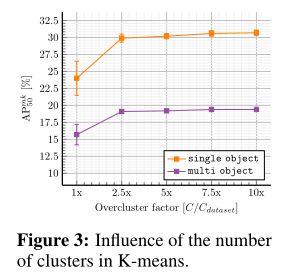
上图量化了在初始对象掩码的 K-means 聚类期间更改簇 C 数量的影响.
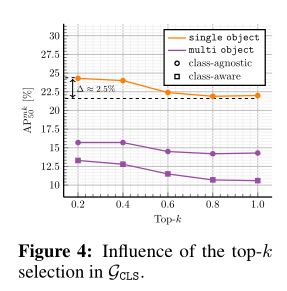
上图显示了 top-k 选择的影响.为了减轻虚假细节(例如背景杂波)的影响,作者在中选择与最具辨别力的patch token相对应的前 k 个patch.
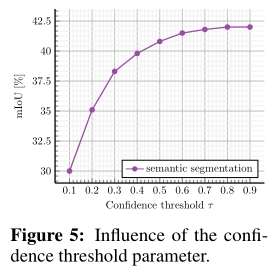
上图研究了选择具有阈值 τ 的最confident的对象掩码候选者的影响.
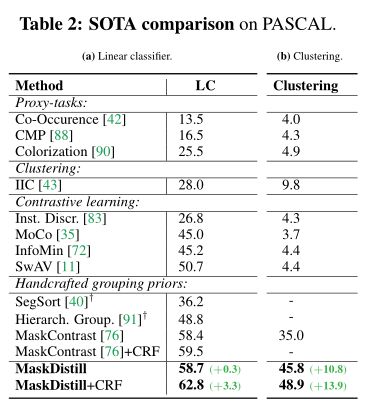
上表将本文的结果与 PASCAL 验证集上的 state-of-theart 进行了比较.MaskDistill 在线性分类器设置下的表现始终优于先前的工作.

上图展示了本文方法在PASCAL 数据集上的定性结果.
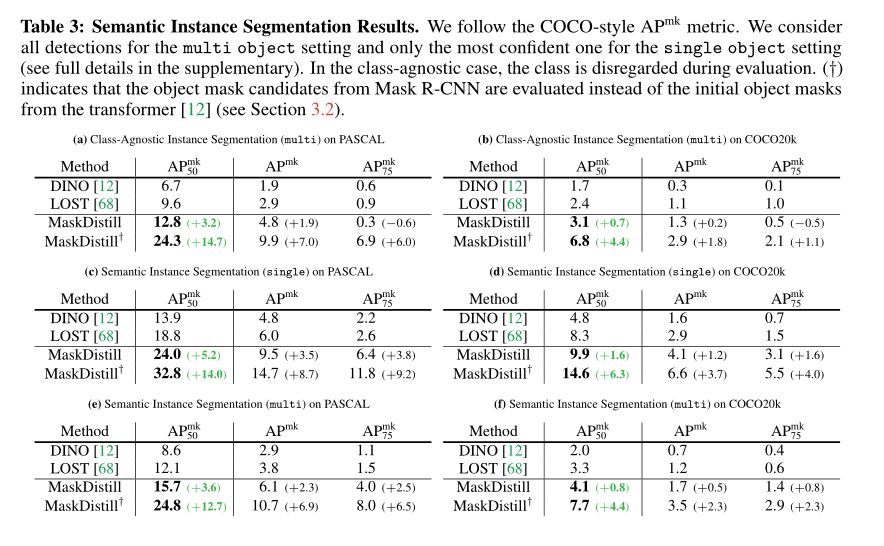
上表将本文的结果与其他两种无监督对象掩码生成方法进行了比较:DINO和 LOST.


上图显示了COCO20k 上的几个示例,其中本文的方法可以检索每个图像的多个高质量对象掩码.
05
总结首先,本文的方法以数据驱动的方式学习像素分组先验,而不是通过手工制作的先验.其次,分割模型不锁定低级图像特征,而是学习对象级信息.第三,本文的方法可以更好地处理具有多个对象的图像.最后,广泛的实验评估表明,本文的方法明显优于最先进的方法.
毫无疑问,本文的工作仍然存在一些局限性.首先,尚不清楚自监督视觉Transformer的预训练数据集如何影响对象掩码的质量.有趣的是,最近的研究表明,可以使用以对象和场景为中心的数据集来学习空间结构化表示.这一观察表明,在精选数据集(例如 ImageNet)上训练Transformer并不重要.此外,还可以通过扩展预训练数据集和模型的大小来改进结果.
参考资料
[1]https://arxiv.org/abs/2206.06363[2]https://github.com/wvangansbeke/MaskDistill▊ 作者简介研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用.知乎/公众号:FightingCV
已建立深度学习公众号——FightingCV,欢迎大家关注!!!
ICCV、CVPR、NeurIPS、ICML论文解析汇总:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
面向小白的Attention、重参数、MLP、卷积核心代码学习:https://github.com/xmu-xiaoma666/External-Attention-pytorch
边栏推荐
猜你喜欢


随机推荐
The difference between the operators and logical operators
vscode要安装的插件
【Pytorch学习笔记】10.如何快速创建一个自己的Dataset数据集对象(继承Dataset类并重写对应方法)
SQL(1) - Add, delete, modify and search
redis persistence
flink部署操作-flink on yarn集群安装部署
day9-字符串作业
【数据库和SQL学习笔记】6.SELECT查询4:嵌套查询、对查询结果进行操作
el-table鼠标移入表格改变显示背景色
CAP+BASE
day7-列表作业(1)
BroadCast Receiver(广播)详解
BFC(Block Formatting Context)
Calling Matlab configuration in pycharm: No module named 'matlab.engine'; 'matlab' is not a package
如何停止flink job
Do you use tomatoes to supervise your peers?Add my study room, come on together
Mysql-连接https域名的Mysql数据源踩的坑
flink项目开发-flink的scala shell命令行交互模式开发
原来何恺明提出的MAE还是一种数据增强
【数据库和SQL学习笔记】10.(T-SQL语言)函数、存储过程、触发器