当前位置:网站首页>Recommended collection: build a cross cloud data warehouse environment, which is particularly dry!
Recommended collection: build a cross cloud data warehouse environment, which is particularly dry!
2022-07-04 23:13:00 【Wu_ Candy】
Directory structure
- background
- programme
- Deployment structure 1. Test environment deployment structure 2.Canal Service deployment structure
- Related services 1. platform 2. Code engineering 3. Deploy machine 4. Build services
- Steps to build 1. Machine resource preparation 2. Release code project 3. Installation dependency 4. Configure scheduling tasks 5. Business Mysql Library Configuration 6.Canal To configure 7.Mysql Incremental table configuration
- K8s The service command
- Summary of construction process problems
background
There is only one data testing environment , Usually it is only used for daily data requirement testing , Can't satisfy users UAT requirement , Therefore, we need to rebuild a data testing system , As a user UAT Environmental Science .
programme
Business services in Tencent cloud , Deploy data collection services on Tencent cloud machines and package and upload the obtained business data to sftp For data warehouse services on Alibaba cloud ETL Stored procedure to hive library .
Business data is stored in hive Library divided into 2 Parts of :
- Initialization data : Business mysql The full volume business data of the library is read locally, packaged and uploaded to sftp
- Incremental data :canal Listening to business mysql Of binlog Perform incremental data synchronization 、 Package and upload to sftp
Deployment structure
Test environment deployment structure :
Canal Service deployment structure :
- The whole frame structure is built locally RocketMQ colony
- Data synchronization is based on canal.adapter build , Replace the data transmission service on Alibaba cloud (DTS) function
- Data subscription is built with canal.admin Service platform for management
Related services
1. platform
- canal.admin Management platform : establish instance
- xxl-config Configuration platform : Configured to monitor instance
- xxl-job Task scheduling platform : Incremental data synchronization task execution and exception handling
- k8s Publishing platform : Data synchronization engineering pull xxl-config Configuration release
- jenkins Publishing platform : Publish projects other than data synchronization projects
- etl Task scheduling platform : Used for configuration etl Scheduling tasks , Automatically execute input hive library
2. Code engineering
- Dispatch server engineering :data-platform-schedule
- Dispatch client engineering :data-platform-schedule-client
- etl Execute Integration Tool Engineering :data-platform-etljet
- etl Data processing into hdfs engineering :data-platform-etl
- Data synchronization project :data_sync_incr
3. Deploy machine
- Dispatch server And etl machine :l-test.beta4.dt.cn4
- Business machine :l-test.beta4.ep.tx1
- k8s machine :l-test-k8s.ep.tx1
- canal.admin Service machines :l-test1.beta.plat.tp1
- canal.deploy/adapter Service machines :l-test2.beta.plat.tp2
4. Build services
Build a new set sftp service , Used for transit transmission of cross cloud data
Steps to build
1. Machine resource preparation
Apply to the operation and maintenance department for a new data warehouse machine :
l-test.beta4.dt.cn4
With the existing beta The environment data warehouse machine uses the same set hadoop Cluster resources ,hdfs New storage path /user/test/hive/warehouse_uat Isolate environmental data
notes :
- k8s machine :l-test-k8s.ep.tx1, Already exists and data-sync-incr The service is running normally
- canal.admin Service machines :l-test1.beta.plat.tp1, Already exists and canal.admin The service is running normally
- canal.deploy/adapter Service machines :l-test2.beta.plat.tp2, Already exists and canal.deploy and canal.adapter The service is running normally
2. Release code project
Data warehouse machine :l-test.beta4.dt.cn4 Deploy the following services 1. Dispatch server engineering :data-platform-schedule 2. Dispatch client engineering :data-platform-schedule-client Pay attention to the need to use hive User to boot schedule-client Carry out orders : /home/test/www/schedule/schedule-client task_loader_and_timeout_serviced start 3.etl Execute Integration Tool Engineering :data-platform-etljet Create directory : /home/test/www/data-platform-etljet
Start under the machine hive User crontab,crontab You need to configure a scheduled task first for example : 0 3 30 * * echo "helloworld"
Business machine :l-test.beta4.ep.tx1 Deploy the following services 1. Dispatch client engineering :data-platform-schedule-client (1). Before deploying the service , You need to create a directory : /home/test/www/schedule/schedule-client (2). Configure environment variables : stay /etc/profile In the document path Path join :/usr/local/bin/ And add the following contents
(3). Pay attention to the need to use hive User to boot schedule-client Carry out orders : /home/test/www/schedule/schedule-client task_loader_and_timeout_serviced start
3.etl Data processing into hdfs engineering :data-platform-etl Create directory : /home/test/www/data-platform-etl/etl_task
k8s machine :l-test-k8s.ep.tx1 Deploy the following services Data synchronization project :data_sync_incr namespace:dc-beta2 evn: betanew Corresponding to the business system beta4 Incremental data for the environment
canal.admin Service machines :l-test1.beta.plat.tp1 Deploy the following services canal.admin
canal.deploy/adapter Service machines :l-test2.beta.plat.tp2 Deploy the following services canal.deploy canal.admin
3. Installation dependency
(1). install python because data-platform-schedule-client Engineering is the use of python The process of the rise , So you need to install python, Omit here python Installation method and process .
(2). install mysql package Using tools :
wget -q http://peak.telecommunity.com/dist/ez_setup.py
python ez_setup.py
easy_install mysql-connector
import mysql.connector
Pay attention to the authority : python -m site You can find the installation address of the package , Modify permissions to hive Users can access
(3). install sftp service Because of the cross Cloud Architecture , So you need to install sftp The service is used for data transfer , Here I am in the data warehouse machine :l-test.beta4.dt.cn4 Installed on sftp service , It can also be installed on other machines , Pay attention to the access rights between the associated calling service machines .
Open the business service machine :l-test.beta4.ep.tx1 And sftp Communication between machines ( Turn off firewall restrictions ) Open the data warehouse machine :l-test.beta4.dt.cn4 And sftp Communication between machines ( Turn off firewall restrictions )
4. Configure scheduling tasks
Configure scheduling tasks :http://l-test.beta4.dt.cn4:8088/project/queryList The page is shown as follows
5. Business Mysql Library Configuration
(1). newly added Mysql Of binlog News subscription Start the business database machine :l-test.beta4.ep.tx1 Of binlog journal , And is row Format . Open and finish using sql sentence :
show variables like '%log_bin%';
see binlog Status should be ON
(2).Mysql Create a sync account First, you need to create a synchronization account in the database , Execute the following command to create a synchronization account :
CREATE USER canal IDENTIFIED BY '[email protected]';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
6.Canal To configure
(1).canal.admin Configured to monitor stay canal.admin Under service http://10.7.80.80:8000/#/canalServer/canalInstances Add listening instance by :test-beta-tcp.
The instance Cluster and server Are all :test-dev-tcp, It needs to be created in advance , establish instance Directly select the corresponding cluster and server that will do .
Configured instance.properties The information is as follows :
instance name Very important , It is the target of the client to pull messages , It can be understood as MQ The theme .
beta Environmental instance name The format is : Type of environment _ Environment number _ Database name _ application
for example :test_test4_db4_adapter, Express test Of test4 Of db4 Provide to adapter Application consumption messages .
The current values of the application are adapter and sync.adapter Application of one-to-one extraction canal.adapter.
sync For listening binlog Personalized synchronization logic of messages through code , It is also the data synchronization method mainly used in this data warehouse construction .
Newly added instance Select this... After saving successfully instance The start button on the right , Start subscription .
After successful startup, it becomes the startup state , Then you can go to mqadmin Check whether there are messages delivered to the queue . You can click the Log button to check whether the startup log is normal .
(2).canal.adapter modify Edit profile /home/test/q/canal/canal.adapter/conf/application.yaml
server:
port: 8010
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: rocketMQ
mqServers: beta-mqns1:5432;beta-mqns2:5433
flatMessage: true
batchSize: 500
syncBatchSize: 1000
retries: 10
timeout: 5000
accessKey:
secretKey:
namespace:
srcDataSources:
beta-test:
url: jdbc:mysql://l-test.beta4.ep.tx1:3306/?useUnicode=true
username: ****
password: ****
(3). restart client.adapter By default, new configuration files will be automatically scanned , But if it doesn't take effect, you can restart it manually . Must be tomcat User restart client.adapter.
The start command is as follows :
sudo su tomcat
cd /home/test/q/canal/canal.adapter/bin
./restart.sh
The log file is in /home/test/q/canal/canal.adapter/logs Next , You can view the startup log .
7.Mysql Incremental table configuration
Initialize delta table & Configure tasks
(1). Determine the business type of incremental table Existing components only support two types :
- test-story type , monitor test_main Tabular binLog Information , And then through binLog Information counter check test_detail surface , Get full data , Take this data as the data required by the incremental table .
- General table type , Monitor for example :person、person_individual Isometric information , Directly to binLog The data in the information is the data required by the incremental table , No need to check .
(2). Configure incremental table business In the project delta table database , Add incremental table business configuration , Used to create business increment tables using . for example :
INSERT INTO `dt_sync`.`init_table_config`( `table_name`, `delete_flag`, `create_time`, `update_time`) VALUES ( 'beta4_teachers_detail_inc_', 0, '2021-11-10 16:02:33', '2021-11-10 16:02:38');
Main configuration table_name、delete_flag attribute ,table_name That is, the name of the incremental table added this time ,delete_flag Indicates whether this record is effective ,0—— take effect ,1—— Don't take effect
(3). Configure incremental table execution policy During incremental synchronization , We need to configure the execution strategy of synchronization
INSERT INTO `dt_sync`.`inc_sync_strategy_config`( `execute_strategy`, `match_rule`, `execute_rule`, `create_time`, `update_time`, `delete_flag`) VALUES ( 'detail', '{\"defaultRule\":{\"instance\":\"test-beta-tcp\",\"dataBase\":\"people\",\"table\":\"teacher\",\"opType\":\"in:INSERT,UPDATE,DELETE\"},\"additionalRule\":{\"columnName\":\"teacher_id\",\"ruleType\":\"prefix\",\"ruleContent\":\"1\"}}\n', '{\"pkColumn\":\"teacher_id\",\"pkRule\":\"PK_COLUMN\",\"monitorBizType\":\"reservation\",\"localTargetTableName\":\"beta4_teachers_detail_inc_\",\"converts\":[{\"field\":\"data\",\"type\":\"json\",\"operation\":[{\"operationName\":\"uncompress\",\"priority\":1},{\"operationName\":\"convertJson\",\"priority\":2}]}]}\n', '2021-11-07 14:24:41', '2021-12-02 16:21:53', 0);
Main concern :[1]、execute_strategy - Execution strategy At present, only (NORMAL、ENTITY_DETAIL) Choose one of the two
[2]、match_rule - Matching rules
Attribute interpretation :
a、defaultRule - Default matching rule ( Required ):
instance: The instance to which the business table belongs ( For expression support ——canalServer Configured in instance Information )
dataBase: The original database to which the business table belongs ( For expression support )
table: The original data table to which the business table belongs ( For expression support )
opType: binlog Monitor the effective operation of the business table ( Currently only supported INSERT, UPDATE, DELETE)( For expression support )
b、additionalRule - Additional matching rules ( Mainly data Grade , Not required )
columnName: Name
ruleType: Type of rule ( Prefix is currently supported - prefix、 suffix - postfix)
ruleContent: Rules match text content
Example : If you want to add additional such as teacher_id Need to be 50 Only the first one can hit the execution of this policy configuration , The configuration is as follows :columnName = teacher_id , ruleType = prefix , ruleContent = 50
[3]、execute_rule - Execution rules during incremental synchronization With t_teacher Incremental business table instance :
{
"pkColumn":"id", Field meaning —— The only business of the original table id( Required ), Used for incremental synchronization business
"pkRule":"TABLE_SUFFIX_COLUMN_COMBINATION", Field meaning —— Incremental table data id Generate rules ( Required )—— At present, there are only two ways :
The way 1、PK_COLUMN——( With pkColumn The value of the column is used as the primary key of the incremental table id, This method is generally recommended for businesses that do not have separate databases and tables )
The way 2、TABLE_SUFFIX_COLUMN_COMBINATION——( Suffixed with the original table + , It is generally recommended to use this method for the business of sub database and sub table )
"localTargetTableName":"test_t_teacher_detail_inc_", Field meaning —— Which incremental business table does this configuration belong to , As in step 2 table_name Configuration is consistent ( Required )
"monitorBizType":"t_teacher", Field meaning —— Monitor the business type of the buried point ( Required )
"converts":[// Field meaning : Attribute converter , Perform a series of conversion operations on the specified attributes ( Not required ){
"field":"detail", Field meaning —— The column names in the original table that need to be operated
"type":"json", Field meaning —— data type
"operation":[// Field meaning —— Operation set of transformation ( At present, there is only decompression )
"uncompress"
]
}
]
}
create_time: Field meaning —— The creation time of this record
update_time: Field meaning —— The revision time of this record
delete_flag: Field meaning —— Logical deletion identification of this record ,0 Not delete ,1 deleted , Deleted data does not take effect
Expressions support :
in expression ——in: instanceA, instanceB
regex expression ——regex: regex:t_teacher_\d+
equal expression ——t_teacher_info
any expression ——*
[4]、 Configure the required data source If it is a regular table type, ignore this step If it is an unconventional type , You need to configure the data source of the reverse query
INSERT INTO `dt_sync`.`data_source_config`( `data_source_name`, `url`, `user_name`, `password`, `delete_flag`, `connection_pool`, `create_time`, `update_time`) VALUES ( 'people', 'jdbc:mysql://l-test.beta4.ep.tx1:3306/people?characterencoding=utf-8&zerodatetimebehavior=converttonull&autoreconnect=true&generatesimpleparametermetadata=true', 'beta4', '123456', 0, 'a', '2021-10-17 15:01:25', '2021-10-17 15:01:25');
[5]、 Configure data sources and instance The mapping relation of Why configuration is needed ? Because in the process of incremental synchronization , There is a problem of multiple data sources , Need to pass through instance Dynamically route to the corresponding data source to obtain data
INSERT INTO `dt_sync`.`instance_datasource_relation_config`(`data_source_name`, `instance_name`, `create_time`, `update_time`, `delete_flag`) VALUES ( 'people', 'test-beta-tcp', '2021-10-25 15:06:01', '2021-10-17 15:37:43', 0);
K8s The service command
see namespace by :dc-beta2 Download all running instances
The order is as follows :
kubectl get po -n dc-beta2
Check out the examples data-sync-incr-54549d7567-98pch Under the log Information
The order is as follows :
kubectl logs -f --tail=100 data-sync-incr-54549d7567-98pch -n dc-beta2
Check out the examples data-sync-incr-54549d7567-98pch Specific content of
The order is as follows :
kubectl exec -ti data-sync-incr-54549d7567-98pch -n dc-beta2 bash
k8s see pod Of ip Address ( Connecting to the database will use )
The order is as follows :
kubectl get pods -n Namespace -o wide |grep pod name
Example :
kubectl get pods -n dc-beta2 -o wide |grep data-sync-incr-54549d7567-98pch
Summary of construction process problems
1. problem : The lack of python Installation package :threadpool resolvent : step1: Use command :
python -m pip install threadpool
step2: After successful installation, enter python The client under the command
import threadpool
Check if the installation is successful
step3: Set up site-packages Access rights of files under the directory , Let it all go
sudo chmod 777 -R /usr/lib64/python3.6/site-packages
2. problem : Can't find lftp command resolvent : step1: Use command :
yum install lftp
install , Tips :Error: rpmdb open failed
step2: Get into rpmdb Catalog , command :
cd /var/lib/rpm
step3: Remove the original rpmdb file , command :
rm -f __db.*
step4: The reconstruction rpm database , command :
rpm --rebuilddb
step5: Clear all yum The cache of , command :
yum clean all
step6: Use command :
yum install lftp
install , No error reported
3. problem :hive Users write crontab Failure reports error Report errors :You (hive) are not allowed to access to (crontab) because of pam configuration
Problem troubleshooting : step1、 Check crond jurisdiction .
1、cat /etc/corn.deny, The file is empty .
2、ll /usr/bin/crontab, Have S Permission bits , normal .
step2、 Check PAM modular .
cat /etc/pam.d/crond
The file configuration is normal , No exceptions with those on other hosts .
step3、 Check the system log
cat /var/log/secure
The log shows that the user password has expired ! resolvent :
chage -M 99999 hive
chage -l hive
4. problem :test Business library data update , Data does not enter dt_sync Target table reason : uat Environment configuration monitoring instance by :test-beta-tcp, Corresponding namespace by :dc-beta2
stay namespace by :dc-beta1 Or others namespace You can't monitor at the same time :test-beta-tcp
The reason for the problem here is dc-beta1 Also monitored the instance
there namespace Embodied in conf The configuration page is shown in the optional list in the upper right corner of the figure below , Image below beta2(betanew) Corresponding namespace by :dc-beta2
stay k8s Pay attention to the choice of environment when deploying , As shown in the second picture below :namespace And env It's a set of parameters namespace:dc-beta1 env:beta namespace:dc-beta2 env:betanew
resolvent : Divide namespace:dc-beta2 Other than listening test-beta-tcp Of namespace Remove the configuration of listening , The modification position is shown in the first figure above After modifying the configuration , It needs to be reissued , Make its configuration modification effective . Guarantee 1 individual instance Only be 1 individual namespace monitor .
end
边栏推荐
- 小程序vant tab组件解决文字过多显示不全的问题
- ETCD数据库源码分析——处理Entry记录简要流程
- Duplicate ADMAS part name
- Is Huatai Securities a nationally recognized securities firm? Is it safe to open an account?
- 初试为锐捷交换机跨设备型号升级版本(以RG-S2952G-E为例)
- 【ODX Studio編輯PDX】-0.2-如何對比Compare兩個PDX/ODX文件
- Common methods in string class
- Basic use and upgrade of Android native database
- Sword finger offer 67 Convert a string to an integer
- Google Earth engine (GEE) - globfire daily fire data set based on mcd64a1
猜你喜欢
小程序vant tab组件解决文字过多显示不全的问题
Redis getting started complete tutorial: Geo
S32 Design Studio for ARM 2.2 快速入门

Redis introduction complete tutorial: slow query analysis
Excel shortcut keys - always add

Redis入门完整教程:HyperLogLog
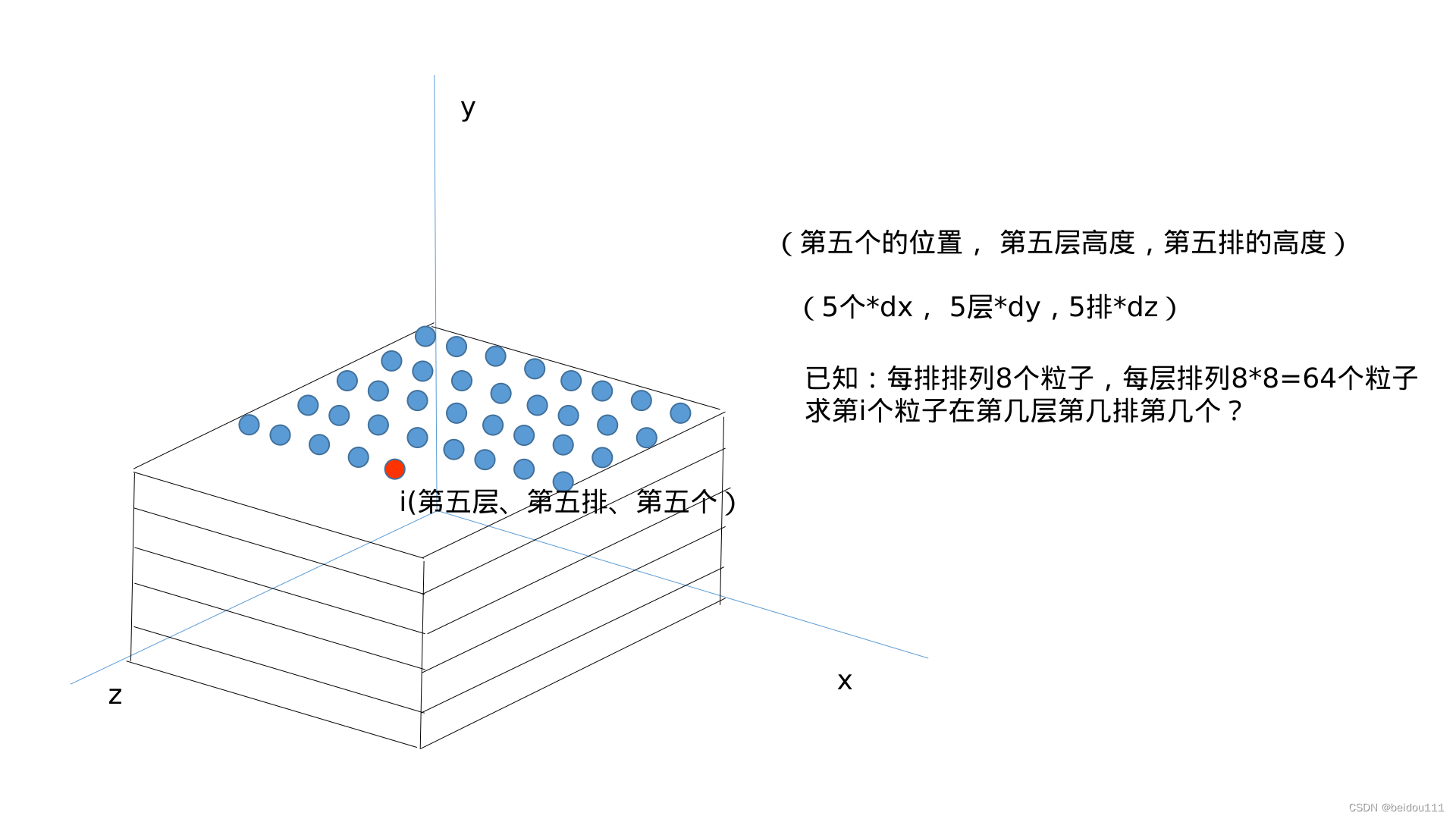
The initial arrangement of particles in SPH (solved by two pictures)
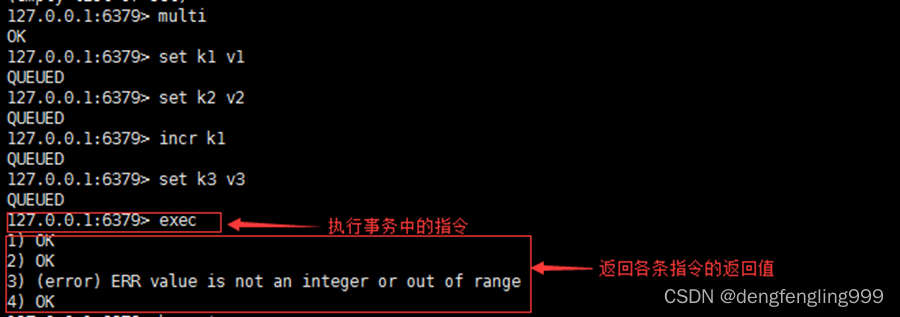
Redis:Redis的事务

Qt加法计算器(简单案例)
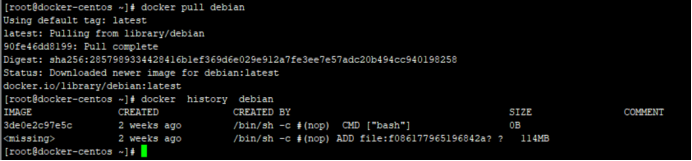
Docker镜像的缓存特性和Dockerfile
随机推荐
Common methods in string class
[graph theory] topological sorting
常用技术指标之一文读懂BOLL布林线指标
Object detection based on OpenCV haarcascades
HMS core unified scanning service
机器学习在房屋价格预测上的应用
该如何去选择证券公司,手机上开户安不安全
How can enterprises cross the digital divide? In cloud native 2.0
【爬虫】数据提取之JSONpath
A mining of edu certificate station
String类中的常用方法
LabVIEW中比较两个VI
Set up a website with a sense of ceremony, and post it to 1/2 of the public network through the intranet
Redis introduction complete tutorial: slow query analysis
A complete tutorial for getting started with redis: transactions and Lua
Redis入门完整教程:Redis使用场景
Advantages of Alibaba cloud international CDN
Redis入門完整教程:Pipeline
VIM editor knowledge summary
浅聊一下中间件