当前位置:网站首页>使用百度EasyDL实现厂区工人抽烟行为识别
使用百度EasyDL实现厂区工人抽烟行为识别
2022-08-02 01:05:00 【飞桨PaddlePaddle】
项目说明
业务背景
在企业生产安全管理中,厂区安全是重要课题之一。厂区的人多、物杂、环境复杂等特性给安全管理带来挑战。当前大多数企业厂区都已加装视频摄像头,但主要依赖人工来对摄像头进行监测和预警。
业务难点
由于人眼、人脑的数据采集、分析能力具有局限性、不稳定性,因此依赖人工的监控方式无法做到视频数据的全量覆盖、及时分析和实时预警,从而给厂区安全管理带来隐患。
解决思路
为满足上述场景中的安全巡检需求,可引入AI模型进行智能分析,从而识别出厂区的人、物、环境等多种对象,并获取其位置、状态等信息,从而自动生成预警信号。例如,可识别人员着装是否规范(如安全帽、制服等)、是否产生危险行为(如抽烟等)、是否处于异常状态(如跌倒、聚集等)。这些智能分析需求可基于图像分类、物体检测、图像分割等AI模型来实现。例如,厂区抽烟行为的识别可基于物体检测模型来实现。
为了训练上述AI模型并投入生产应用,基于飞桨EasyDL,企业仅需安排一名普通业务人员,利用业余时间,即可在2-3周内从0到1训练出可用于厂区安全巡检的抽烟识别模型,并应用到厂区安全巡检场景的智能视频分析业务中。
数据准备
数据采集
客户的实际场景是基于厂区摄像头视频抽帧得到的图片来进行抽烟行为识别。因此,前期采集训练数据时,需要从摄像头视频数据中获取抽烟行为图片,且尽量覆盖不同角度、距离、光照等条件,与厂区的实际摄像条件相符。这样才能保证训练出来的模型真实可用,不可以用网络图片替代。
抽烟行为识别其实是识别出人手中握着的烟头,如下图:

数据导入
采集完毕可以根据您的使用习惯选择不同的导入方式来上传数据。可直接上传图片;也可将图片打包成zip压缩包上传;还可先将图片上传到其他网络地址(例如:百度网盘),然后拷贝链接上传。
数据标注
抽烟识别模型输出的信息是图片中是否有抽烟行为,以及烟头具体出现的位置,对应物体检测任务。因此,需选择图像-物体检测标注模板,并使用矩形框对烟头进行标注。如下图:

模型训练
选择任务类型并创建模型
抽烟识别对应物体检测模型,因此需选择物体检测任务类型。点击创建模型,根据您的业务需要来为模型自定义命名,如:抽烟行为识别。
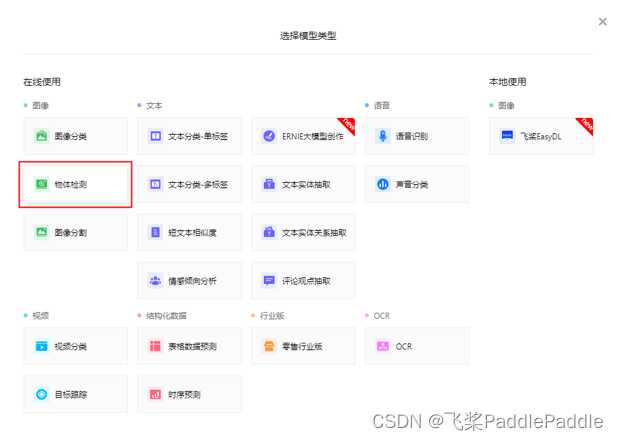

选择部署方式
如果您的业务模式是将视频上传至云端进行推理分析,则部署方式可选择公有云部署或EasyEdge本地部署-服务器。公有云部署的优势是部署较为便利,可一键发布为公有云服务;EasyEdge本地部署-服务器的优势是可下载部署包并部署至本地服务器,实现私有云服务;这两种部署方式共同的劣势是需要占用较大带宽用于视频传输,且推理计算将集中在公有云或私有云服务器,计算负荷较大。
通常情况下,我们建议智能视频分析采用端云协同模式,也就是在边缘节点上直接进行视频分析,并将分析后的结构化数据回传至云端,则部署方式可选择EasyEdge本地部署,并根据您所使用的硬件设备来进一步选择通用小型设备或专项适配硬件。该部署方式的优势在于无需将视频回传至云端,可直接在边缘侧进行推理计算,不仅带宽占用低,计算压力也分散至各边缘节点,业务实时性更佳。

选择算法
可以选择高精度、均衡或高性能算法。其中,高精度算法侧重于保障模型效果,可通俗理解为模型更准,但模型体积相对更大,计算速度相对更慢,资源消耗也相对更多;而高性能算法侧重于保障模型性能,可通俗理解为模型体积更小、速度更快,或模型所占用的资源更少;均衡算法则介于两者中间。如果您更关注模型准确性,或硬件资源较为充足,建议选择高精度算法;如果您的硬件资源较为紧张,或更关注模型速度、计算资源利用效率,则建议选择高性能算法。

模型部署
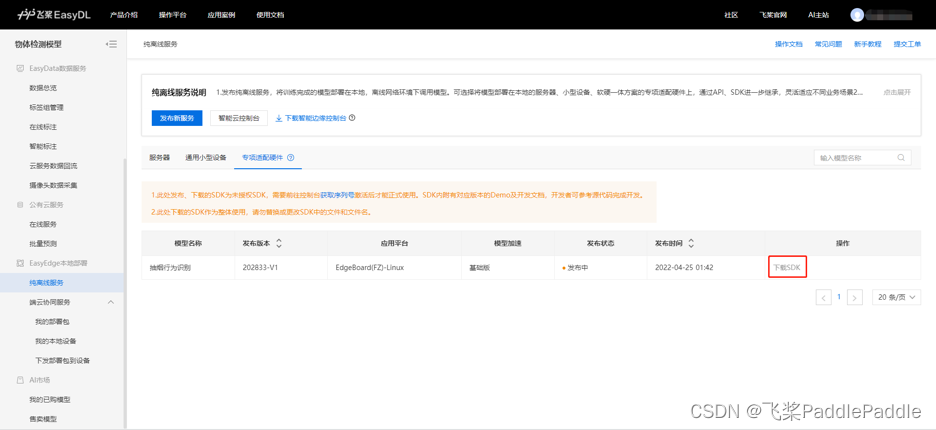
在安全巡检场景中,我们通常建议采用端云协同的业务模式,也就是将模型部署至边缘计算节点,在边缘直接完成视频分析,并将分析得到的结构化数据回传至云端,从而避免视频传输所带来的额外延时,以获得较好的业务实时性。在该模式下,我们需要在训练时选择EasyEdge本地部署,并选择通用小型设备或专项适配硬件。 以部署至Edgeboard(FZ)为例,当模型训练完并发布后,可进入EasyEdge本地部署-纯离线服务,查看已发布的模型并下载SDK。然后在本地安装智能边缘控制台,在界面上完成模型部署工作。
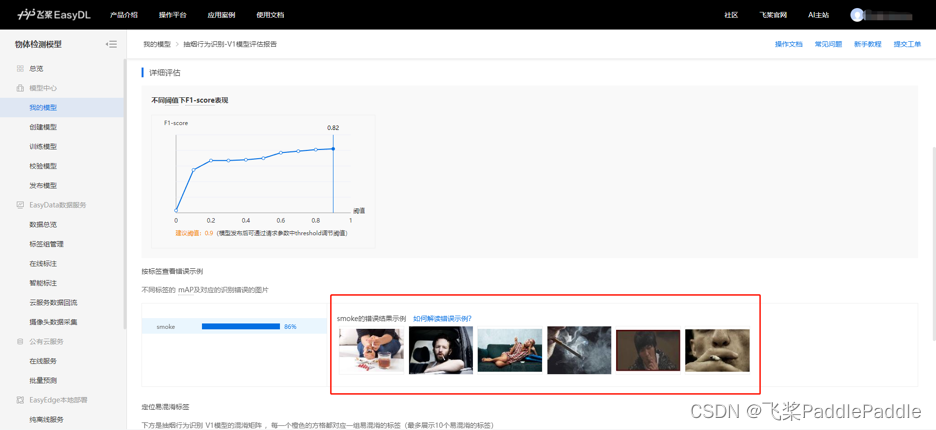
效果优化
如果训练得到的模型效果未达到预期,可通过查看模型评估报告来进行分析,并针对性进行效果优化。通过查看模型评估报告,发现识别漏的Badcase主要是烟头目标过小,识别错的Badcase主要是存在一些与烟头近似的物体。因此,可在业务上进行引导,增加包含小目标烟头的图片数据量,并增加包含烟头近似物体的图片数据量,从而帮助训练出更准确的模型。
常见问题
问题1:我应该采集多少数据?这些数据有什么要求?
在数据采集数量上,一是要保证每个标签的数据量不低于50,理论上标签量越多,模型效果更好;二是尽量保证各个标签的数据量不要差异太大,也就是要具有一定的均衡性。
在数据采集方式上,要尽量采集真实场景图片,不用使用非真实场景图片,如网络图片。
在本案例中,建议基于厂区摄像头视频数据来抽帧得到图像数据,建议包含至少100张具有抽烟标签的图片,有条件的情况下可进一步增加图片样本量。
问题2:如何将模型部署到边缘计算盒上?
训练完成后,您可以下载训练得到的离线SDK/部署包,并部署至边缘计算盒。
推荐您下载智能边缘控制台,在可视化界面轻松实现模型部署包在边缘设备上的集成、版本更新。其中,单节点版适用于离线单机模型服务应用场景,多节点版适用于多台边端设备的AI应用场景。 单节点版使用方式详见:https://ai.baidu.com/ai-doc/EASYDL/Gktuwc59w ,多节点版使用方式详见:https://ai.baidu.com/ai-doc/EASYDL/1l15tsy6m
边栏推荐
猜你喜欢



随机推荐
Kubernetes — 核心资源对象 — 网络
5年自动化测试经验的一些感悟:做UI自动化一定要跨过这10个坑
Go 1.18 的那些事——工作区、模糊测试、泛型
Debian侵犯Rust商标,妥协改名还是会得到豁免?
信息收集之cms指纹识别
html+css+php+mysql实现注册+登录+修改密码(附完整代码)
安全(1)
feign异常传递的两种方式 fallbackfactory和全局处理 获取服务端自定义异常
Newton's theorem and related corollaries
C语言实验七 二维数组程序设计
Test Cases: Four-Step Test Design Approach
制造企业数字化转型现状分析
C语言:打印整数二进制的奇数位和偶数位
mapbox使用教程
IDEA如何运行web程序
Reflex WMS中阶系列6:对一个装货重复run pick会有什么后果?
21.数据增强
Local storage in Kubernetes
hutool工具-----JSON工具-JSONUtil
JDBC PreparedStatement 的命名参数实现