当前位置:网站首页>[knowledge map paper] attnpath: integrate the graph attention mechanism into knowledge graph reasoning based on deep reinforcement
[knowledge map paper] attnpath: integrate the graph attention mechanism into knowledge graph reasoning based on deep reinforcement
2022-07-08 02:09:00 【Wwwilling】
Article
Literature title :Incorporating Graph Attention Mechanism into Knowledge Graph Reasoning Based on Deep Reinforcement
Document time :2019
Journal Publishing :EMNLP
Abstract
- Knowledge map (KG) Reasoning aims to find the reasoning path of relationship , To solve the problem of incompleteness in the knowledge map . Many previous path based methods , Such as PRA and DeepPath, all Lack of memory components , Or get into training . therefore , Their performance always depends on good pre training . In this paper , We put forward a proposal called AttnPath A model based on deep reinforcement learning , The model will == LSTM and Graph Attention Mechanism As a memory component ==. We define two indicators , Average selection rate (MSR) and Average replacement rate (MRR), Quantify the difficulty of learning query relationships , And use them to fine tune the model under the framework of reinforcement learning . meanwhile , A new reinforcement learning mechanism is proposed , By forcing the agent to move forward every step , To avoid the agent constantly stopping on the same entity node . Based on this operation , The proposed model can not only get rid of the pre training process , And compared with other models, it also achieves the most advanced performance . We have different tasks FB15K-237 and NELL 995 Test our model on the dataset . A lot of experiments show that , Our model is effective and competitive with many of the most advanced methods at present , And perform well in practice .
introduction
- Knowledge map (KG), for example NELL (Carl son et al., 2010)、Freebase (Bollacker et al., 2008) and WordNet (Miller, 1995) In many downstream NLP Applications play an increasingly important role , for example , Question and answer (Dubey et al., 2018), Information retrieval (Liu et al., 2018), Personalized recommendation (Wang et al., 2019) etc. . however ,KG Always incomplete , This will affect many downstream tasks . KG Many links may be lost between entities in . therefore , How to predict the missing links between entities by reasoning based method to complete the knowledge map is an important and challenging task . for example , If KG There's always p l a y e r P l a y s F o r T e a m ( X , Y ) playerPlaysForTeam(X, Y) playerPlaysForTeam(X,Y) and t e a m P l a y s I n L e a g u e ( Y , Z ) teamPlaysInLeague(Y, Z) teamPlaysInLeague(Y,Z), Then we can infer that athletes P l a y s I n L e a g u e ( X , Z ) PlaysInLeague(X, Z) PlaysInLeague(X,Z), That is to say X X X and Z Z Z Between filling the missing edge athletes P l a y s I n L e a g u e PlaysInLeague PlaysInLeague .
- There are three main ways to accomplish this task , Such as Rule-Based (Wang and Cohen, 2016; Yang et al., 2017), Embedding-Based (Bor des et al., 2013; Lin et al., 2015) And path based (Lao et al., 2011). meanwhile , It will be deep reinforcement learning (DRL) Introducing the task of predicting missing links provides a new perspective , for example DeepPath (Xiong et al., 2017), A path based approach . DeepPath It's the first one to DRL Included in the KG The work of reasoning . And PRA comparison , It has made significant improvements , But there are still some shortcomings . First , It lacks memory components , Lead to need Preliminary training . The operation of pre training needs to provide many known for model training ( Or exist ) The path of . This brute force operation may make the model easy to over fit on the given path of pre training . secondly , In training for KG It is not appropriate to set the same super parameters in different relationships , This ignores the diversity of connections between entities . Last , When agent When an invalid path is selected , Will stop and choose again , This leads to the continuous selection of this invalid path , Finally, it gets stuck on a node .
- therefore , In this paper , We propose a novel deep reinforcement learning model and Algorithm , It aims to solve the above shortcomings . The proposed model also belongs to the path based framework . Our contributions can be summarized as follows :
- We proposed AttnPath, This is a will == LSTM And figure attention == As a model of memory components , And there is no need for pre training .
- Two indicators are defined (MSR and MRR), Quantitatively measure the difficulty of alternative paths of learning relationships , Used to fine tune the model .
- A new reinforcement learning mechanism is proposed , By forcing the agent to move forward every step , To avoid the agent constantly stopping on the same entity node .
- We are FB15K-237 and NELL 995 Two downstream task tests are used on the dataset AttnPath: Fact prediction and link prediction . We also tested the success rate of finding the path , The effectiveness of the graph attention mechanism is shown in the experiment .
Related work
- so far , Many solutions have been proposed KG Work on incomplete problems . A rule-based approach , Such as ProPPR (Wang and Cohen, 2016) and Neural LP (Yang et al., 2017), Generate reasoning rules manually or through mathematical logic rules , Then apply them based on the existing triples to fill in the missing links . Although such methods have a solid mathematical background , But they are difficult to expand to large KG, Because they operate directly on symbols , The number of possible reasoning paths is exponentially related to the number of entities . Embedding based approach , Such as TransE (Bordes et al., 2013) and TransR (Lin et al., 2015), Mapping entities and relationships into a low dimensional and continuous vector space , It captures the distance between entities and relationships . then , They judge whether the query relationship exists by comparing the distance between the embedding of two training entities and the embedding of query relationship . Such methods require KG All triples in participate in training , Only applicable to single hop reasoning .
- Path based , Such as PRA (Lao et al., 2011) and DeepPath (Xiong et al., 2017), Training agents in KG Navigation on the Internet , Find an alternative path for a specific relationship , Then use them as features for downstream tasks . Path ranking algorithm (PRA) Is the first path based reasoning method . Neelakantan A method based on RNN The combination model of , The model combines the meaning of path and the reason of multi hop relation connection in a non atomic way (Neelakantan wait forsomeone ,2015). Guu Et al. Proposed a soft edge ergodic operator , It can be recursively applied to predict paths and reduce single hops KG How to do it ( Such as TransE and TransR) Facing cascading propagation errors (Guu wait forsomeone ,2015). Toutanova Et al. Proposed a dynamic programming algorithm , The algorithm combines the bounded length paths of all relationships into KG in , And modeling the relationship and intermediate nodes in the composite path representation (Toutanova wait forsomeone ,2016). Such representation can help generate more high-quality reasoning paths .
- Das People will DeepPath(Xiong wait forsomeone ,2017 year ) Improve to MINERVA(Das wait forsomeone ,2018 year ), The latter from QA From the perspective of KG. It gets rid of pre training , Introduced LSTM To remember the path before , And train the agent to cycle on some entity , If it thinks the entity is the right answer . Lin Et al. Improved these two methods by introducing reward shaping and action loss (Lin wait forsomeone ,2018). Reward shaping replaces the fixed punishment of useless choices with dynamic punishment , Dynamic penalty can be embedded based on marginal pre training , Such as TransE, Or probability based embedding , Such as ConvE (Dettmers et al., 2018). and action dropout Will cover randomly Cover a certain proportion of effective action , To reduce the irrelevant path of query relationship . DIVA (Chen et al., 2018) Treat paths as potential variables , Treat the relationship as an observation variable , So as to build a variational reasoning model to complete KG Reasoning task . It also uses beam search to broaden the search range . M-Walk (Shen et al., 2018) Using another method called Monte Carlo tree search (MCTS) Of RL Algorithm to solve the problem of sparse reward . The attention mechanism is first determined by (Wang et al., 2018) Introduce multi hop KG Reasoning . However , It only calculates the attention weight of query embedding and all found path embedding . They are used to help judge whether the answer found by the vanilla model is correct .
AttnPath: Merge memory components
- In this section , We will introduce the proposed AttnPath Details of . We will also show the average selection rate (MSR) And average replacement rate (MRR) The definition of , And how to use them to fine tune the model to adapt to different query relationships .
be used for KG Reasoned RL frame
- Because we use reinforcement learning (RL) As a training algorithm of sequential decision model , We first introduced KG In reasoning RL The basic elements of the framework , Including the environment 、 state 、 Actions and rewards .
- Environmental Science : In this task , Environment refers to the whole KG, It does not include the query relationship and its inverse . The environment is consistent throughout the training .
- state : The state of the agent is connected by three parts : Embedded part 、LSTM Part and figure attention part . We will show in the next section LSTM Calculation of part and attention part of graph , And first introduce the embedded part .
- stay (Xiong et al., 2017) after , Embedded part m t m_t mt Connect with two sub parts . The first is e t e_t et , It is the embedding of the current entity node . The other is e t a r g e t − e t e_{target} - e_t etarget−et , Represents the distance between the tail entity node and the current node . And use TransE (Bordes et al., 2013) Embedded as pre training DeepPath Different , We make use of TransD (Ji et al., 2015), That's right TransE Improvement , It is also a common benchmark . stay TransD Next , For query relationship , We project all entities onto the vector space of the query relationship . then , Projection embedding of entities e ⊥ e⊥ e⊥ Turn into

- among p p p Represents the projection vector . therefore m t m_t mt Should be [ e t ⊥ ; e t a r g e t ⊥ − e t ⊥ ] [e_t⊥; e_{target}⊥ - e_t⊥] [et⊥;etarget⊥−et⊥].
- action : about KG Reasoning task , Action means that the agent chooses the relationship path to move forward . be based on DRL Framework , Choose the relationship according to the probability obtained by the model . The operation is valid or invalid . Effective action indicates that there is an output relationship with the current entity , An invalid action indicates that there is no relationship .
- Reward: The reward depends on whether the action is effective , And whether a series of actions can lead to ground truth Tailstock . We use (Lin et al., 2018) Proposed reward shaping skills . For invalid actions , The reward is -1. For actions that do not lead to basic facts , We choose ConvE (Dettmers et al., 2018) As a reward . because ConvE The probability of output is (0, 1) Within the scope of , Therefore, we use logarithmic operators to expand the scope of the reward and improve discrimination . For actions that lead to basic facts , That is, the successful plot , The reward is global accuracy 、 Weighted sum of path efficiency and path diversity . By convention , Global accuracy Set to 1, Path efficiency Is the reciprocal of the path length , Because we encourage agents to go as far as possible . == Path diversity (path diversity)== Defined as

- among ∣ F ∣ |F| ∣F∣ Is the number of paths found , p p p Is path embedding , The sum of all relationships embedded in the path . The above definition ensures that the reward of effective actions is always greater than that of invalid actions , And successful plot episodes The reward is always greater than the unsuccessful plot .
LSTM and Graph Attention As a memory component
- In our model , We use three layers LSTM, Enable agents to remember and learn from previous actions . use h t h_t ht Express LSTM Steps in t t t The hidden state of , use 0 Indicates the initial hidden state h 0 h_0 h0. And then we get

- among m t m_t mt stay Eq(1) In the definition of . This is the above state LSTM part .
- Usually , An entity has several different aspects , for example , A football player may play with playForTteam or playsInLeague And other professional relationships , It may also be related to family relationships such as spouse or father . For different query relationships , Agents should pay more attention to relationships and neighbors that are highly related to query relationships . therefore , We will Graph Attention Mechanism (GAT) Into our model , This is from (Velickovic et al., 2018) Proposed .
- GAT It is indeed self attention on entity nodes . We use a single-layer feedforward neural network to calculate the attention weight , With linear transformation matrix W W W And weight vectors a ⃗ \vec{a} a Share among all entities . Choose to have a negative input slope α = 0.2 α = 0.2 α=0.2 Of LeakyReLU As a nonlinear . So from the entity i i i To the entity j j j The attention weight of is calculated as

- For entities i i i, We only calculate the attention weight of all its directly connected neighbors , And use SoftMax Normalize it . So the normalized attention weight is
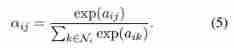
- Now we can calculate the attention part of the state graph , It is just the weighted sum of all neighbors embedded in the attention space

- therefore , Entity i i i In time t t t State vector of s i , t s_{i,t} si,t by
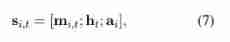
- It inputs a three-layer feedforward neural network in turn , Its final output is a length equal to KG The number of all relationships in Softmax probability . The agent chooses an action and gets a reward . After successfully reaching the tail entity or not reaching the specified number of times , All parameters will be updated with the rewards of the entire plot . Optimization is using REINFORCE (Williams, 1992) The algorithm is finished , And update with the following random gradient θ θ θ:
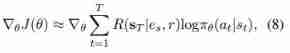
- among e s e_s es Is the head entity , r r r Is the query relation , and π θ ( a t ∣ s t ) π_θ(a_t|s_t) πθ(at∣st) Is the probability of all relationships . chart 1 It shows our AttnPath Model .
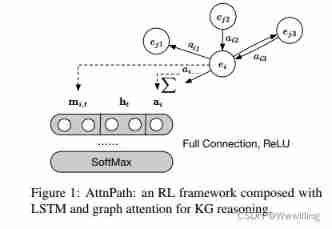
- chart 1:AttnPath: from LSTM And figure attention for KG Reasoned RL frame .
Average choice / Replacement rate
- For different query relationships , You need to train different models for each query relationship . In practice , The difficulty value of each relationship is completely different . Some relationships may have more replacement relationships , This shows that the agent can easily choose a replacement path from head entity to tail entity . So we invented two indicators here , Average selection rate (MSR) And average replacement rate (MRR), To quantify the difficulty of each relationship .
- Use a group T r = { ( h , r o , t ) ∣ r o = r } T_r = \{(h, r_o, t)|r_o = r\} Tr={ (h,ro,t)∣ro=r} Representation and relation r r r All related triples . Relationship r r r About triples ( h , r , t ) (h, r, t) (h,r,t) The selection rate is defined as
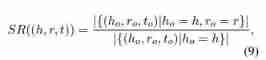
- That is relationship r r r Occupy h h h The proportion of outlets .
- therefore ,MSR yes T r T_r Tr On SR Average value :

- Lower MSR It means learning r r r More difficult , Because of the relationship with r r r Connected entities may have more aspects .
- Relationship r r r About triples ( h , r , t ) (h, r, t) (h,r,t) The replacement rate of is defined as
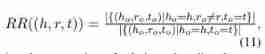
- Direct connection h h h and t t t The proportion of the relationship , Except for relationships r r r.
- Similarly ,MRR yes T r T_r Tr On RR Average value :

- Higher MRR Indicates that a relationship may have more replacement relationships , So it's easier to learn , Because the agent can directly choose the alternative relationship to reach the destination .
- In our model , We have three ways to prevent over fitting :L2 Regularization 、dropout and action dropout. However , For relationships that are easier to learn ( high MSR and MRR), We want to apply more regularization to encourage agents to find more different paths , Without over fitting, it will succeed immediately . otherwise , For relationships that are more difficult to learn ( low MSR and MRR), We'd better pay attention to the success rate of finding the path , So we should reduce regularization .
- For the sake of simplicity , We use the index to calculate the relationship r r r The difficulty coefficient of . It is defined as e x p ( M S R ( r ) + M R R ( r ) ) exp(MSR(r)+MRR(r)) exp(MSR(r)+MRR(r)) And multiply the basic rates of the three regularization methods respectively . The basic rate of regularization method is based on KG Of , In the same KG Applies to all relationships in .
Overall training algorithm
- Based on the proposed model , We propose a new training algorithm , Such as algorithm 1 Shown .

- One of our contributions to the algorithm is , When the proxy chooses an invalid path , Our model will not only punish it , It will also be forced to choose valid relationships to move forward . The probability from the neural network is normalized in all effective relationships , This in turn affects the probability of forced action .
- After initialization , The first 6 Rows sample actions based on the output of the network . When the agent selects an invalid action , Execution section 7 ∼ 10 That's ok , The first 9 ∼ 10 The bank forces the agent to move forward . When the agent selects a valid action , Execution section 12 That's ok . The first 19、22 and 25 The invalid actions are updated in the rows 、 Parameters of effective actions in successful plots and effective actions in unsuccessful plots , The reward is -1、 R t o t a l R_{total} Rtotal and R s h a p i n g R_{shaping} Rshaping.
experiment
- Increment in this section , We will conduct extensive experiments to verify our proposed AttnPath The effectiveness of the . For each task , We will focus on three quantitative indicators : The success rate of finding the path (SR)、 Facts predict MAP(FP) And link predicted MAP(LP). We will also demonstrate some reasoning paths and triples , To show that graph attention is effective in finding more high-quality paths and mining entities, which aspect is important in a specific task .
Data sets and settings
- Two data sets were used in our experiment ,FB15K-237 (Toutanova et al., 2015) and NELL-995 (Xiong et al., 2017). The statistics of these two data sets are shown in table 1 in . According to the previous work , For each triple ( h , r , t ) (h, r, t) (h,r,t), We add its inverse triples ( t , r − 1 , h ) (t, r^{−1}, h) (t,r−1,h), Let the agent step back .
- Here we summarize the hyperparameters involved in our experiment . The pre training embedding dimension is set to 100.LSTM The hidden dimension is set to 200. Note that the dimension is set to 100. therefore , s s s It's a 500 Dimension vector , By connecting the above three vectors with twice the pre training embedding aspect . λ 1 λ_1 λ1 by 0.1, λ 2 λ_2 λ2 by 0.8, λ 3 λ_3 λ3 by 0.1. about FB15K-237 Data sets , We will base L2 Regularization 、Dropout Rate and action dropout The rates are set to 0.005、0.15 and 0.15. Besides , about NELL-995, We set them to 0.005、0.1 and 0.1. We choose Adam (Kingma and Ba, 2015) As an optimizer , The different learning rates are 0.001、 β 1 β_1 β1 0.9 and β 2 β_2 β2 0.999. For each task , We train 500 Set , And for each set , The maximum number of steps is set to 50.
- We are based on BFS Methods (Xiong et al., 2017) Verify during training FP and LP The learning path of each triplet in the task .
Road finding success rate
- Our model knows nothing about the environment , At first it was three times , Because it doesn't rely on pre training . therefore , We recorded the recent 10 Total of sets SR and SR, To verify the ability of agent learning path . For training samples less than 500 A task , First, iterate the sample , Then the random sampling reaches 500 Set . For training samples more than 500 A task , We choose 500 One for training .
- We from NELL-995 Select two relationships , t h l e t e P l a y s I n L e a g u e thletePlaysInLeague thletePlaysInLeague and o r g a n i z a t i o n H e a d q u a r t e r e d I n C i t y organizationHeadquarteredInCity organizationHeadquarteredInCity, To investigate its recent 10 Total of sets SR and SR. formerly MSR and MRR Relatively low , The latter is higher . chart 2 Show the results . You can find ,DeepPath Better than our method at first , But in 50 ∼ 150 individual epoch after , Our model exceeds it . from AttnPath Force Of SR-10 in , We found that the initial SR Approximate to MRR, Because the model didn't know anything at first , So it randomly chooses a path . As the training goes on , Performance will steadily improve . stay FB15K-237 Similar results can be found in other relationships .

- chart 2:NELL-995 The total of the two relationships SR and SR-10. DeepPath / AttnPath TransD It means using TransD Embedded as pre training . AttnPath MS/RR Adding MSR and MRR To fine tune the super parameters . AttnPath Force Is forcing agents to take every step forward . These abbreviations are used throughout this section .
Facts predict
- Facts predict (FP) Designed to predict the truth of unknown facts . The ratio of positive triples to negative triples is about 1 : 10. For every relationship , We use the reciprocal of all found paths and lengths as the weight , According to the path in h h h and t t t Whether it is effective to accumulate the score of each triplet . Scores are ranked in all test sets , Average precision (MAP) Used as an evaluation index . Results such as table 2 Shown . It can be seen that AttnPath Obviously better than TransE/R and DeepPath. AttnPath MS / RR Use MSR and MRR To fine tune the super parameters , Performance improvement has also been achieved . AttnPath Force And it works . By force agent Every step forward , Improved pathfinding SR, Thus enriching the characteristics of downstream tasks . This is particularly important for relationships that lack alternative paths to direct connections and require paths with long-term dependencies . in fact , Our method achieves SOTA result .
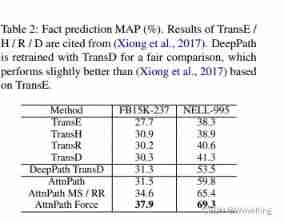
- surface 2: Facts predict MAP (%). TransE /H / R / D The results of are quoted from (Xiong et al., 2017). DeepPath Use TransD Retrain for fair comparison , Its performance is slightly better than that based on TransE Of (Xiong et al., 2017).
Link prediction
- Link prediction (LP) To predict the target entity . For each ( h , r ) (h, r) (h,r) Yes , There is a basic fact t t t And about 10 Generated errors t t t. It is divided into training set and test set . We use the found path as a binary feature , And train the classification model on the training set , And apply it to the test set . LP Also used MAP As an evaluation indicator , The detailed results are shown in table 3 Shown . And FP equally , Our model is in LP and FB15K-237 On dataset SOTA The result also achieved better results .

- however , We have also noticed AttnPath The best results are not achieved under a small number of query relationships , Even lower than TransE / R. By analyzing the triples related to these relationships , We found that :1) They have more other relationships that point to entities that are not really tails , Therefore, these query relationships MSR Very low . 2) The tail entity is only connected with the edge of the query relationship and its inverse , These edges are removed during training , So the tail entity becomes isolated , There are no possible alternative paths . It will also reduce the MRR. With birthPlace and bornLocation For example . If a person was born in a remote place , This place is difficult to connect with other entities , So it's easy to be isolated . However , This one-to-one relationship is TransX Advantages of the method .
qualitative analysis
DeepPath and AttnPath Found path
- We use FB15K-237 Medium capitalOf and NELL-995 Medium playerPlaysInLeague For example , analysis DeepPath and AttnPath These paths found . surface 4 Shows the front of all methods 5 Frequent paths and their frequencies . It shows that AttnPath Better able to capture long-term dependencies between relationships , This is useful for relationships that lack alternative paths to direct connections . AttnPath You can also find more important and centralized paths , Therefore, the distribution of paths has no heavy long tail . In the process of training , We also found that AttnPath He is better at retreating while entering the dead beard .

- surface 4: Use two methods for capitalOf (FB15K-237) and playerPlaysInLeague (NELL-995) Before I find it 5 Frequent paths . “inv” Indicates an inverse relationship .
Figure effectiveness of attention mechanism
- We sample several pairs of entities and relationships , Calculate the attention weight of the entity to its neighbors under this relationship , And research with pre 5 Attention weighted neighbors . surface 5 Shows an example . This shows that GAT Be able to pay more attention to the neighbors related to the query relationship , Especially for Anthony Minghella and Brandon Marshall, They pay different attention to neighbors with different query relationships .

- surface 5: Show the sample of which neighbor the model pays most attention to under a specific relationship . Bold text indicates that the entity is related to the query relationship . The first four pairs are from FB15K-237, The last four pairs are from NELL-995.
Conclusion and future work
- In this paper , We proposed AttnPath, It's based on DRL Of KG Reasoning task model , It is a combination of LSTM and Graph Attention Mechanism As a memory component , To reduce the pre training of the model . We also invented two indicators ,MSR and MRR, To measure the difficulty of relationship learning , And use it to better fine tune the training super parameters . We improved the training process , To avoid the agent falling into a meaningless state . Qualitative experiments and quantitative analysis show that , Our method is obviously superior to DeepPath And embedding based methods , Proved its validity .
- future , We are interested in using Multi task learning , The model can learn the reasoning path of multiple query relationships at the same time . We also want to study how to GAT、MSR and MRR Used for other and KG Related tasks , for example KG Express 、 Relational clustering and KB-QA.
reference
- Petar Velickovic, Guillem Cucurull, Arantxa Casanova Adriana Romero, Pietro Lio, and Yoshua Bengio. 2018. Graph attention networks. In ICLR.
边栏推荐
- Keras' deep learning practice -- gender classification based on inception V3
- LeetCode精选200道--链表篇
- Introduction to grpc for cloud native application development
- Installing and using mpi4py
- Clickhouse principle analysis and application practice "reading notes (8)
- Flutter 3.0框架下的小程序运行
- leetcode 869. Reordered Power of 2 | 869. Reorder to a power of 2 (state compression)
- Talk about the cloud deployment of local projects created by SAP IRPA studio
- 系统测试的类型有哪些,我给你介绍
- PB9.0 insert OLE control error repair tool
猜你喜欢

文盘Rust -- 给程序加个日志
COMSOL --- construction of micro resistance beam model --- final temperature distribution and deformation --- addition of materials
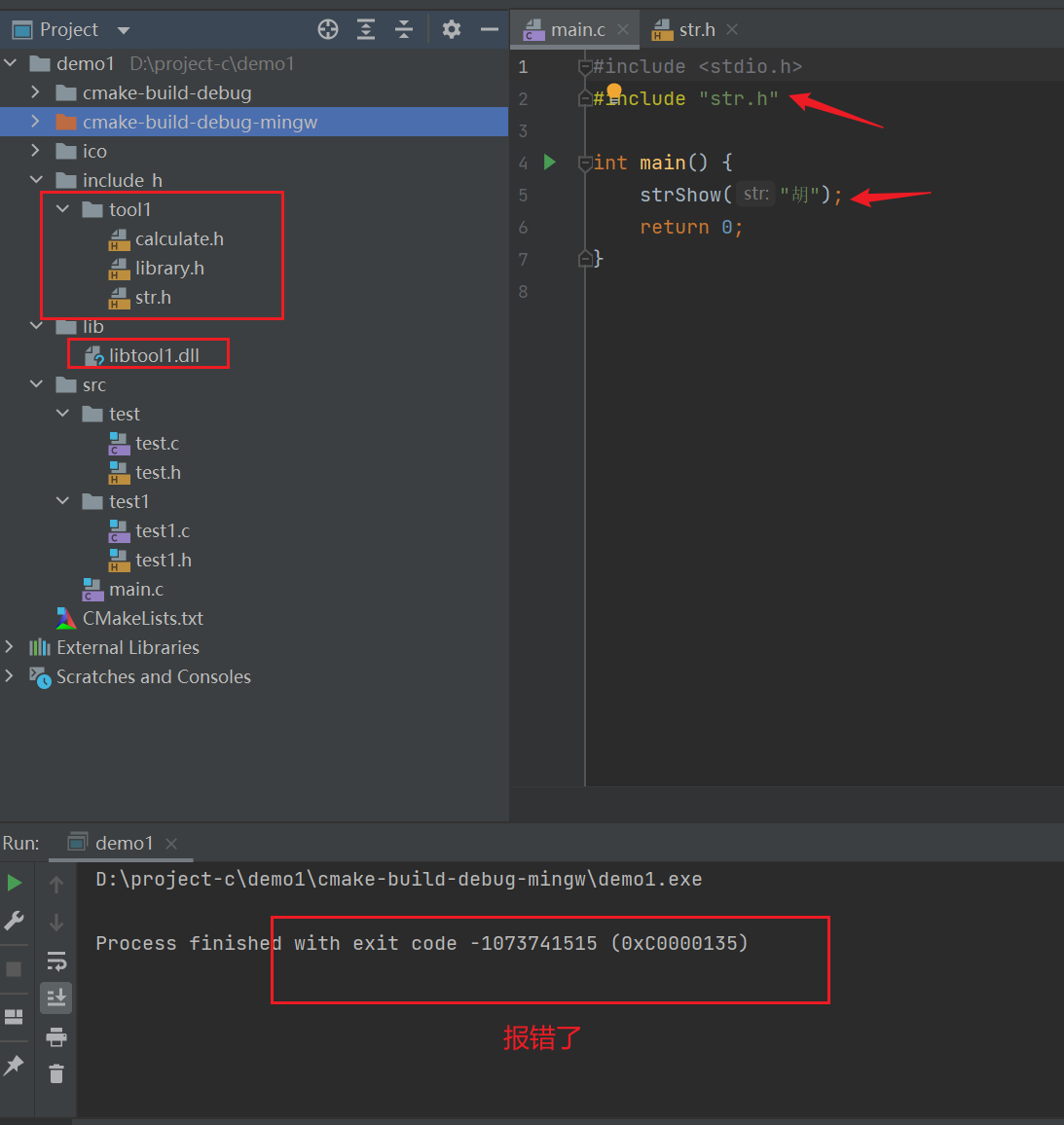
C language - modularization -clion (static library, dynamic library) use

metasploit
谈谈 SAP 系统的权限管控和事务记录功能的实现

JVM memory and garbage collection-3-runtime data area / method area

《ClickHouse原理解析与应用实践》读书笔记(7)
神经网络与深度学习-5- 感知机-PyTorch
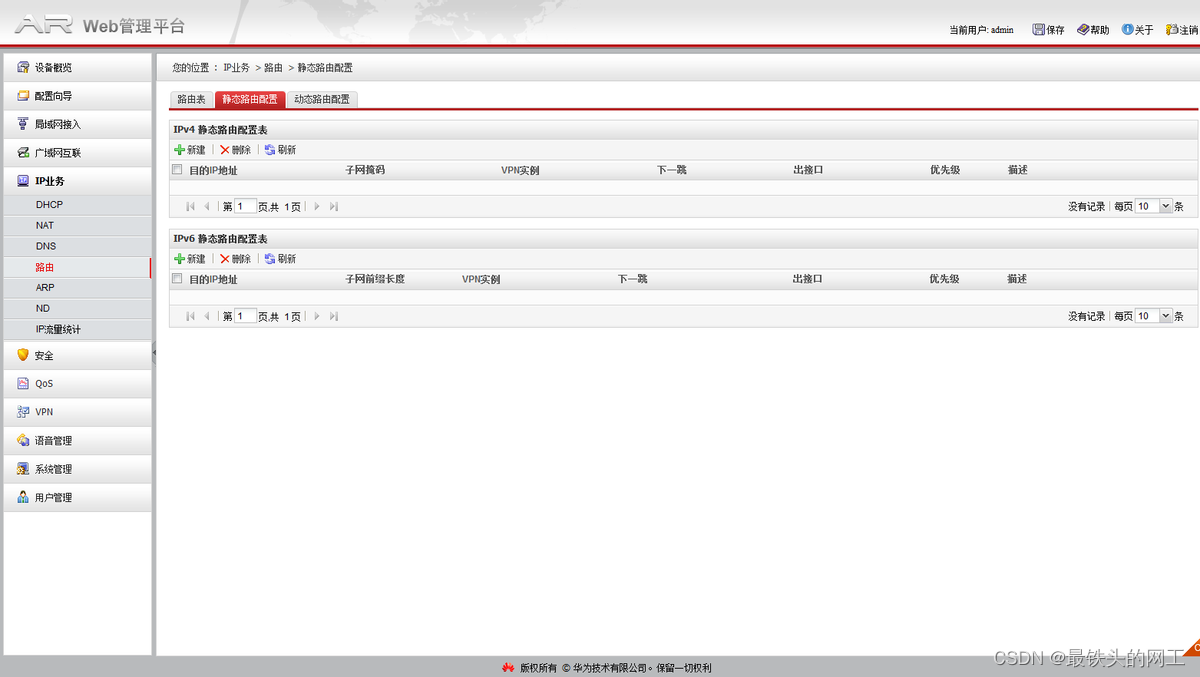
A comprehensive and detailed explanation of static routing configuration, a quick start guide to static routing
常见的磁盘格式以及它们之间的区别
随机推荐
leetcode 865. Smallest Subtree with all the Deepest Nodes | 865.具有所有最深节点的最小子树(树的BFS,parent反向索引map)
MySQL查询为什么没走索引?这篇文章带你全面解析
Why did MySQL query not go to the index? This article will give you a comprehensive analysis
JVM memory and garbage collection-3-object instantiation and memory layout
Remote Sensing投稿經驗分享
How mysql/mariadb generates core files
A comprehensive and detailed explanation of static routing configuration, a quick start guide to static routing
很多小伙伴不太了解ORM框架的底层原理,这不,冰河带你10分钟手撸一个极简版ORM框架(赶快收藏吧)
Beaucoup d'enfants ne savent pas grand - chose sur le principe sous - jacent du cadre orm, non, ice River vous emmène 10 minutes à la main "un cadre orm minimaliste" (collectionnez - le maintenant)
Partage d'expériences de contribution à distance
CorelDRAW2022下载安装电脑系统要求技术规格
Matlab r2021b installing libsvm
Get familiar with XML parsing quickly
XXL job of distributed timed tasks
C language -cmake cmakelists Txt tutorial
Usage of hydraulic rotary joint
See how names are added to namespace STD from cmath file
PHP calculates personal income tax
ArrayList源码深度剖析,从最基本的扩容原理,到魔幻的迭代器和fast-fail机制,你想要的这都有!!!
ClickHouse原理解析与应用实践》读书笔记(8)