当前位置:网站首页>[reinforcement learning medical] deep reinforcement learning for clinical decision support: a brief overview
[reinforcement learning medical] deep reinforcement learning for clinical decision support: a brief overview
2022-07-08 02:00:00 【Wwwilling】
Article
- author :Siqi Liu, Kee Yuan Ngiam, Mengling Feng
- Literature title : Deep reinforcement learning for clinical decision support : A brief overview
- Document time :2019
- Links to Literature :https://arxiv.org/abs/1907.09475
Abstract
- Due to the latest progress of artificial intelligence, especially deep learning , Many data-driven decision support systems have been implemented , To promote doctors to provide personalized care . In this article, we focus on deep reinforcement learning (DRL) Model . DRL Models in computer vision and game tasks ( For example, go and yadali Games ) It shows human level and even excellent performance . However , It is still rare to use deep reinforcement learning technology in clinical decision optimization . Here we show the first survey , The survey summarizes the use of deep Neural Networks (DNN) Reinforcement learning algorithm for clinical decision support . We also discussed some case studies , Different DRL Algorithms to solve various clinical challenges . We further compare and contrast various DRL Advantages and limitations of the algorithm , And how to choose the right one for specific clinical application DRL The algorithm provides a preliminary guide .
background
- In the field of health care , The clinical process is very dynamic . Making clinical decisions “ The rules ” Usually not clear (Marik,2015). for example , Let's consider the following clinical decision-making issues : Will the patient benefit from organ transplantation ? When will transplantation become a better choice ; What is the best drug and dose prescribed after transplantation ? Decisions made from these questions should be specific to the situation of individual patients . In order to find the best decision for these problems , Randomized clinical trials are usually selected (RCT). However , In some clinical cases , Randomized controlled trials may be impractical and infeasible . therefore , From analyzing observation data, it becomes an alternative method . With the improvement of data collection and DRL Technological progress , We see that based on DRL Decision support system has great potential in optimizing treatment recommendations .
- Technical significance
This research paper summarizes and discusses the main factors that have been applied in clinical applications to provide clinical decision support DRL Algorithm type . Besides , We discussed these DRL The tradeoffs and assumptions of the algorithm . This article is intended as a guideline , Help our readers choose the right one for their specific clinical application DRL Model . As far as we know , This is the first article about DRL Research papers for treatment recommendations or clinical decision support . - Clinical relevance
The fact proved that ,DRL The ability to reach the human level , Can be in specific areas ( For example, video games 、 Board games and autonomous control ) Learn complex sequential decisions . And in health care ,DRL It has not been widely used in clinical applications . In this paper , We investigated the main factors that provide sequential decision support in the clinical field DRL Algorithm . We believe that , From the collection of a large number of electronic health records (EHR) Learning from data ,DRL Be able to extract and summarize the knowledge and experience needed to optimize the treatment of new patients . DRL It also has the potential to expand our understanding of the current clinical system by automatically exploring various treatment options and estimating their possible outcomes .
Reinforcement learning MDP
- In a clinical setting , We regard intelligent bodies as clinicians . We can regard status as the well-being of patients / condition . The state of a patient can depend on his demographics ( for example , Age 、 Gender 、 Race, etc )、 Longitudinal and physiological measurements ( for example , Laboratory tests 、 Vital signs 、 Medical image report, etc ) And some other clinical features . Action is the treatment of patients by clinicians ( for example , Prescriptions for certain drugs 、 Arrangement of surgery, etc ). Transfer function P ( s t + 1 ∣ s t , a t ) P(s_{t+1}|s_t,a_t) P(st+1∣st,at) It can be regarded as the patient's own biological system , Given current health and interventions , The patient will move on to the next time step s t + 1 s_{t+1} st+1. If health improves , We will allocate rewards to agents , If the patient's condition worsens or stagnates after the intervention , We will punish the agent .
Deep reinforcement learning
- in application , Especially in clinical application , Data generation is usually a big problem , Because it's real-time , And many observations ( From electronic health records ) It's the right to use private data that we don't easily own . We also don't want to estimate the value through trial and error , Because this is usually unethical and expensive . therefore , When we choose RL When the algorithm , We need to understand these constraints .
- In this paper , We will first focus on the application of RL The main types of algorithms , But only briefly introduces one which is rarely used in clinical application RL Algorithm . We will also discuss the comparison with other algorithms in the field of healthcare , Specific algorithms are not so “ popular ” Root cause of .
Reinforcement learning algorithm
Strategic gradients strengthen learning
On the strategic gradient RL in ,DNN Used in step 3 Build strategies in , among DNN The input of is status , Output is action . chart 1 It's a strategic gradient RL Of MDP chart . By adopting J(θ) And update DNN Weight in , Learning strategies accordingly . In a clinical setting , And others RL The algorithm is compared with , Policy gradient RL Does not “ popular ”. The fundamental reason may be that it is a policy based algorithm , Data needs to be collected iteratively based on the new strategy . The algorithm is through “ Repeated test ” Study of the . Most clinical applications cannot afford to collect real-time clinical data . for example , To understand the best clinical decision of drug dosage in patients with sepsis , It is immoral to try again and again , It will also be time-consuming . However , Policy gradient RL It is still popular in other fields , For example, robot control and computer board games , The environment in these fields is a simulator that can withstand trial and error .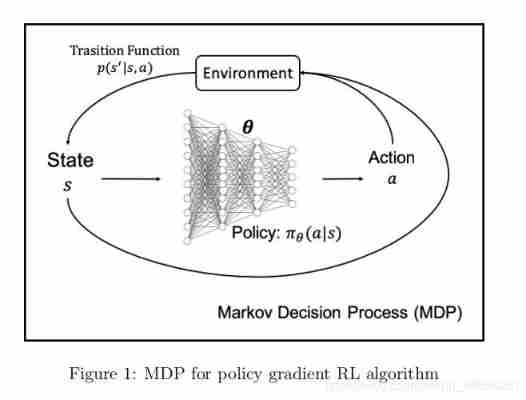
Value based reinforcement learning
Value based reinforcement learning is common in clinical applications , We will be in the 3 Section on DRL See more examples in clinical applications .
Actor-Critic Reinforcement learning
Actor-critic RL It's a kind of off-policy Algorithm , But the alternative version can also be a on-policy Algorithm . The only difference is in step 1 in , We only collect one track and update the strategy to generate new samples from the updated strategy , Instead of collecting a batch of tracks . Again ,on-policy It is not suitable for real-time clinical application ; therefore , One of the applications discussed in this article (Wang wait forsomeone ,2018 year ) Take advantage of off-policy actor-critic RL Algorithm .
Model based reinforcement learning
All discussed above RL Algorithms are model free RL, In the absence of models RL in , Let's assume that we don't know the exact conversion function p ( s t + 1 ∣ s t , a t ) p(s_{t+1} | s_t, a_t) p(st+1∣st,at). therefore , In view of the current state and action on , We don't know what the real next state is . No model RL Don't try to learn conversion functions explicitly , Instead, it bypasses it by sampling from the environment . It is always helpful to know the correct conversion function or environment . Besides , In some cases , We do know the conversion function , For example, we design a simple board game with our own rules . For clinical applications , Most of the time, we are not sure about the exact conversion function , But we do know something about the dynamics of the environment . for example , Clinicians generally know , After giving the patient an appropriate dose of Medicine , The patient will gradually recover from illness to health . Even if we don't know the whole picture of the environment , We can still propose several models to estimate the real transformation function ( Environmental Science ) And optimize it from there . It is called model-based reinforcement learning (Doya etc. ,2002). We can use a variety of models to estimate the transfer function , For example, Gaussian process (GP)(Deisenroth and Rasmussen,2011;Rasmussen,2003)、DNN、 Gaussian mixture model (GMM)(Chernova and Veloso,2007) wait . Based on DNN Model RL,DNN The input of is status - The action is right ( s t , a t ) (s_t, a_t) (st,at), The output is s t + 1 s_{t+1} st+1. DNN In the 2 Step is the implementation of the transfer function . And as an environmental model DNN comparison ,GP The data efficiency of is very high . GP A few data samples can be used to reasonably predict the next state . It is very useful in clinical settings , Because most clinical applications have insufficient data . however ,GP Its limitation lies in , When the actual transition function is not smooth , It will run into trouble . Besides , If the number of samples is large and in high-dimensional space ,GP It could be very slow . It is associated with DNN Just the opposite , among DNN The larger the number of samples , Generally, the more accurate the prediction is . therefore , The input status is medical image ( Very high dimension ) In the clinical context ,DNN Will compare GP More suitable for model-based RL.
Other extensions of reinforcement learning
- Hierarchical reinforcement learning
When the learning task is huge , And we are RL See several different states in - Action space and several suboptimal strategies , It is very intuitive to sort the subspaces and try to obtain the optimal strategy of the global space . layered RL(Kulkarni wait forsomeone ,2016 year ) It usually contains a two-level structure . The lower level is just like we are RL The training strategy in the algorithm is the same , Try to suggest a given action ( s t , a t ) (s_t, a_t) (st,at). meanwhile , There is a higher level of network , among “ Meta strategy ” Training selects which of these lower level strategies to apply to the trajectory . Compared with the random start strategy , layered RL It has the advantage of learning the global optimal strategy faster , And it transfers knowledge learned from past tasks from lower level strategies . In a clinical setting , Due to the complex behavior of human interaction , state - The action space may be large . therefore , Applying hierarchical reinforcement learning is a very natural choice for clinical application . However , layered RL The structure of training is more complex , Improper transfer learning will lead to “ Negative transfer ”(Pan and Yang,2010), The final strategy is not necessarily better than the low-level strategy . - Circular reinforcement learning
A basic limiting assumption of Markov decision process is Markov property ( Yes MDP Complete observation of ), This is rarely satisfied in real world problems . In medical applications , It is unlikely to measure the patient's complete clinical status . It is called partially observable Markov decision process (POMDP) problem (Kaelbling et al., 1998). POMDP There is one 4 Tuples ( S , A , R , O ) (S, A, R, O) (S,A,R,O), among O O O It's an observation . classic DQN It is only useful when observation reflects the potential state .(Hausknecht and Stone,2015). Hausknecht and Stone (2015) Put forward the right DQN Network expansion to deal with POMDP problem , among DQN The first fully connected layer of is replaced by long-term and short-term memory (LSTM) (Hochreiter and Schmidhuber,1997). This new RL The algorithm is called deep loop Q The Internet (DRQN)(Hausknecht and Stone,2015 year ). Their algorithm shows , It can successfully integrate information through time , And it can be in the standard Atari Copy on the game DQNâĂŹs Performance of , And set for the game screen POMDP. - Reverse reinforcement learning
In order to learn most standards in clinical application RL Algorithm , We will manually design the reward function , But we don't know what the real reward is . If you specify , This reward design is very vulnerable . The inverse RL It's an algorithm , We can infer the correct reward function from the expert demonstration , There is no need to program rewards manually .(Ghavamzadeh wait forsomeone ,2015 year ;Abbeel and Ng,2004 year ;Ng wait forsomeone ,2000 year ) reverse RL The alternative is to learn them directly from the behavior of experts , This usually refers to imitation learning (Schaal,1999). However , One limitation of imitation learning is that experts may have different abilities and are prone to imperfections (Wang et al., 2018); Learning from experts may only lead to sub optimal policies . therefore , Usually in reverse RL in , We will get the state in the dynamic model - Action space and suboptimal strategy . The inverse RL The goal of is to restore the correct reward function . Then we can use the learned reward function to obtain a new strategy better than the suboptimal strategy . Rewards can be passed DNN Study , The input is determined by the suboptimal strategy π # {\pi}^{\#} π# The resulting state - The action is right ( s , a ) (s, a) (s,a), then DNN The output of is reward r ϕ ( s , a ) r_{\phi}(s, a) rϕ(s,a), among ϕ \phi ϕ We will learn through back propagation DNN Parameters . Later we get r ϕ ( s , a ) r_{\phi}(s, a) rϕ(s,a) after , We can use the new reward function to plan better strategies , And hope to be the optimal strategy π ∗ {\pi}^∗ π∗. In a clinical context , It is important to reason about what clinicians are trying to achieve and what they consider essential .
Deep reinforcement learning in clinical application
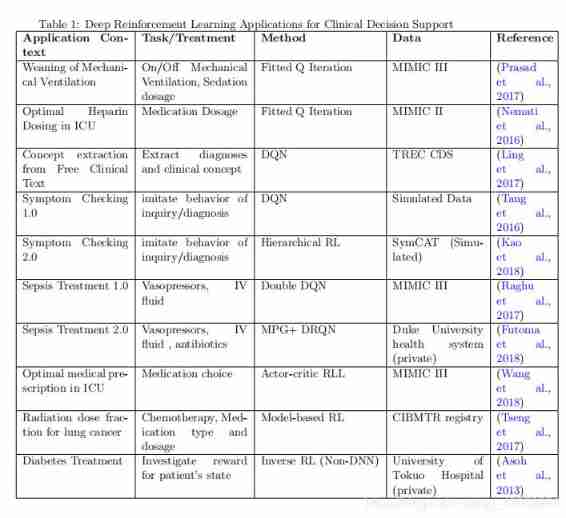
- Recent research (Prasad wait forsomeone ,2017;Nemati wait forsomeone ,2016 year ;Tseng wait forsomeone ,2017 year ) indicate ,DRL It can be used to provide treatment suggestions and clinical decision support for various applications with different types of data sources , Including electronic medical records 、 Online disease database and genetic data . Applications include drugs / Liquid selection 、 Dose for patients with acute or chronic diseases 、 Setting and duration of mechanical ventilation , And building clinical themes based on clinical records . surface 1 All clinical application papers discussed in this survey are summarized , Especially emphasized DRL Different subtypes of methods and different clinical problems . As discussed in the previous section , Policy gradient RL It is an online algorithm that is not suitable for most clinical applications . therefore , Value based reinforcement learning algorithm is very popular in clinical applications .
- For each application in this section , We will study the RL Algorithm 、 Context based MDP ( S , A , R ) (S,A,R) (S,A,R) Formula , And finally RL Performance of . Let's first discuss the use of value - based RL Application , Then the actors - Critic RL、 Model based RL、 layered RL、 loop RL, Finally, reverse RL. For value based reinforcement learning , We further divide the applications according to the subtypes of the value based reinforcement learning algorithm , Including fitting Q iteration 、DQN And double DQN.
Value based reinforcement learning
fitting Q iteration
- Removal of mechanical ventilation
- Patients in the intensive care unit from mechanical ventilation (MV) The withdrawal machine is usually random and inefficient . In this regard ,Prasad wait forsomeone . (2017) Use the separation strategy to fit Q iteration (FQI) Algorithm to determine MV Managed ICU Strategy , They aim to develop a decision support tool , The tool can take advantage of data rich ICU The available patient information in the setting reminds the clinician that the patient is ready to start the withdrawal , And recommend personalized treatment . They use MIMIC-III Database from 8182 Patients received invasive ventilation for more than 24 Hours of unique adult patients extracted 8860 Cases admitted .
- They include the demographic characteristics of patients 、 Past situation 、 Complications and vital signs that change over time . They use Gaussian processes (GP) Pretreatment of laboratory measurements and vital signs , To estimate the missing value ; This ensures more accurate policy estimates . state s t s_t st It's a 32 The eigenvectors of the dimensions . The action is designed as a two-dimensional vector , The first dimension is open / Turn off MV, The second dimension is four different levels of sedative dose . Rewards in each state r t r_t rt Including ventilation time and physiological stability , The reward will increase with the stability of vital signs and successful extubation , But it will punish the adverse events ( Re intubation ) And extra ventilator hours . University of Pennsylvania Hospital HUP Compared with the actual policies implemented , The policies they learned are different from the actual policies 85% Match .
- ICU The best heparin dose in
- Poor management of certain drugs will unnecessarily prolong the hospital stay , And then push up the cost , And put the patient at risk . Unfractionated heparin (UH) Is an example of such drugs , Overdose can increase the risk of bleeding , Insufficient use can increase the risk of thrombosis . In view of the sequence of clinical treatment ,RL It is especially applicable to the problem of drug dosage .Nemati wait forsomeone . (2016) Trained a RL Drug delivery agent , To learn a dosing strategy , This strategy allows patients to activate part of their thromboplastin time during their therapeutic (aPTT) Maximize the proportion of total time spent in . They use MIMIC-II The database extracts 4470 Named in ICU Patients who received intravenous heparin during hospitalization , The time window is 48 Hours . Variables include demographics 、 Laboratory measurements and severity scores ( Glasgow Coma Score (GCS)、 Daily sequential organ failure assessment (SOFA) score ). Use features to build States and distinguish hidden Markov models (DHMM)(Kapadia,1998) It is estimated that . The discrete action uses discrete heparin values from six quantile intervals , The reward is based on aPPT Feedback design . Based on feedback , Decided to add 、 Reduce or maintain heparin dose , Until the next time aPTT measurement . r t = 2 1 + e − ( a P T T t − 60 ) − 2 1 + e − ( a P T T t − 100 ) − 1 r_t = \frac{2}{1+e^{-(aPTT_t-60)}} - \frac{2}{1+e^{-(aPTT_t-100)}} -1 rt=1+e−(aPTTt−60)2−1+e−(aPTTt−100)2−1.. When the patient's aPTT When the value is in the treatment window , The maximum reward allocated by this function is 1, As the distance from the treatment window increases , This value is quickly reduced to the minimum reward -1.
- By comparing clinicians with trained RL The cumulative rewards of agents to test the performance of the best strategy . On average, , as time goes on ,RL The algorithm follows the advice of the agent , Produces the best long-term performance .
Deep Q Network
- Extract clinical concepts from free clinical texts
- Extracting relevant clinical concepts from free clinical texts is the key first step of diagnostic reasoning .Ling et all. (2017) Put forward to use DQN Learn clinical concepts from external evidence ( Wikipedia : Signs and symptoms part and MayoClinic: Symptoms ). They use TREC CDS Data sets (Simpson et al., 2014) experiment . The dataset contains 30 A theme , Each of these topics is a medical free text that describes the diagnosis of patients . MetaMap(Aronson,2006) from TREC CD5 And external articles extract clinical concepts . The state contains two vectors : Current clinical concepts , And candidate concepts from external articles : The more similar the two vectors are , The higher the status value . The action space is discrete , Including the action of accepting or rejecting candidate concepts . The design of the reward is , When the candidate concept is more relevant than the current concept of patient diagnosis , The reward will be high . Training DQN To optimize the reward function to measure the accuracy of candidate clinical concepts . They are TREC CDS Preliminary experiments on data sets have proved DQN Effectiveness on various baselines based on non reinforcement learning .
- Symptom check 1.0
- In order to facilitate self diagnosis ,Tang wait forsomeone (2016) Proposed a symptom examination system . The symptom inspector first asks a series of questions about the patient's condition . then , The patient will provide a series of answers based on the questions . Then the symptom inspector tries to diagnose based on the question and answer .Tang wait forsomeone , A new method based on RL To train this symptom checker . They achieved 11 individual DQN Model , Each model represents an anatomical part of the human body , Like the head 、 neck 、 Arm, etc . These models are trained independently of each other . For each anatomical model , state s It is a single heat coding based on symptoms . ( namely , If the symptom is headache , Then only the anatomical model representing the head will have s = 1, Other models will have s = 0). Actions are discrete , There are two types of : Inquiry and diagnosis . If the biggest Q The value corresponds to the query operation , Then the symptom checker will continue to ask the next question . If the biggest Q The value corresponds to the diagnostic action . The symptom checker will give a diagnosis and terminate . Rewards are designed as scalars . When agents can correctly predict diseases through a limited number of queries , It will be rewarded . They will DQN The algorithm is applied to simulated disease data sets , The results show that the symptom checker can imitate the doctor's inquiry and diagnostic behavior .
Double DQN
- Sepsis treatment 1.0
- Raghu wait forsomeone (2017). Is the earliest direct discussion will DRL One of the people who apply it to health care problems . They use MIMIC-III Data sets Sepsis A subset of , And choose to define the action space as composed of vasopressor and intravenous infusion . They divided the drug dose into four boxes , It consists of different quantities of each drug . Q Value is often overestimated in practice , Lead to wrong predictions and bad policies . therefore , The author uses double DQN That solved the problem (Wang etc. ,2015). They also used a duel depth Q Network to separate value stream and advantage stream , Where value represents the quality of the current state , Advantage represents the quality of the selected action . The reward function is based on measuring organ failure SOFA Clinical motivation of scoring . They proved that , Modeling using continuous state space , The strategies found can reduce patient mortality in hospitals 1.8% To 3.6%.
Actor-critic Reinforcement learning
- ICU Best medical prescription
- Wang wait forsomeone (2018) use Actor-critic RL Algorithm to find the best medical prescription for patients with various diseases . They are for MIMIC-III The database is tested , And extracted 22,865 Name admission . Functions for state building include presentation graphics 、 Vital signs 、 Laboratory results, etc . The action space is 180 Different ATC Code .Wang wait forsomeone , It not only realizes the classic actor comment reinforcement learning . contrary , They will strengthen learning and supervised learning in the actor network (SL) Combine . Objective function J ( θ ) J(\theta) J(θ) Evaluated as in the equation RL and SL Linear combination of objective functions : J ( θ ) = ( 1 − ϵ ) J R L ( θ ) + ϵ ( − J S L ( θ ) ) J(θ) = (1-\epsilon)J_{RL}(\theta) + \epsilon(-J_{SL}(\theta)) J(θ)=(1−ϵ)JRL(θ)+ϵ(−JSL(θ)) , among ϵ \epsilon ϵ Is a range from 0 To 1 The super parameter of , It is used to balance RL and SL. J R L ( ϵ ) J_{RL}(\epsilon) JRL(ϵ) stay actor-network Is objective , and J S L ( ϵ ) J_{SL}(\epsilon) JSL(ϵ) It is evaluated as the cross entropy loss between the predicted treatment and the prescription given by the doctor .
- They apply gradient rise to the objective function w.r.t. ϵ \epsilon ϵ stay actor-network in , And tried different RL-SL Equilibrium value . Besides , They also combined a LSTM Network to improve some of the observed MDP (POMDP) Performance of , state s s s Be used c t = f ( o 1 , o 2 , . . . , o t ) c_t = f(o_1, o_2, ...,o_t) ct=f(o1,o2,...,ot) Summarize the whole historical observation replaced , c t c_t ct Used as the status of actors and comment Networks . Their experiments show that , The proposed network can automatically detect good drug therapy .
Model based reinforcement learning
- Radiation dose fraction of lung cancer
- Tseng wait forsomeone (2017) Implemented model-based RL, Training dose escalation strategies for lung cancer patients receiving radiotherapy . They are RL The design includes 114 Famous patients , And first trained a DNN To estimate the transformation function p ( s t + 1 ∣ s t , a t ) p(s_{t+1} | s_t , a_t) p(st+1∣st,at). DNN The loss function of the model is designed to minimize the estimated trajectory Q The difference between the expected value and the observed value . After building the transition function ,Tseng wait forsomeone . application DQN To learn the best strategy for chest irradiation dose , In local control (LC) And radiation-induced pneumonia (RP) Trade off between risks . Rewards for the network are designed to encourage improvement LC And trying to suppress RP The trade-off between . DQN The state is defined as 9 A combination of features , Including cytokines 、PET Radiomics and dose characteristics . This effect is designed as a dose per fraction .
- Because building transfer functions requires a lot of data . The author's DNN Implemented in the drop-off To avoid over fitting . On the other hand , The author implemented the generation confrontation network (GAN)(Goodfellow wait forsomeone ,2014 year ) To simulate more data to alleviate the problem of insufficient data . come from GAN The analog data of is also fed to the conversion function DNN Training . The proposed ( Model based RL) The network shows a promising result , Compared with clinicians , It can suggest similar therapeutic doses .
Hierarchical reinforcement learning
- Symptom check 2.0
- Kao wait forsomeone (2018) The main idea is to imitate a group of doctors with different professional knowledge to jointly diagnose patients . Because patients can only accept one doctor's inquiry at a time , Therefore, a meta strategy is needed to specify that doctors ask patients in turn . Meta strategies come from higher-level Networks . At every step , Meta strategy is responsible for specifying an anatomical part model to perform symptom query of disease prediction .
- stay Kao In the paper of et al , The first level is the master agent M M M. Lord M M M Have its action space A M A_M AM And strategy π M {\pi}_M πM. At this level , Action space A M A_M AM be equal to P P P, That is, the collection of anatomical parts . Steps in t t t, The master agent enters the state s t s_t st, And according to its strategy π M {\pi}_M πM from A M A_M AM Select an action in a M t a_{M_t} aMt. The second layer of the hierarchy consists of anatomical models m p m_p mp form . If the master performs a M a^M aM, Then the task will be entrusted to the anatomical model m p = m a M m_p = m_{a^M} mp=maM . Once the model is selected m p m_p mp, According to m p m_p mp The strategy of the a t ∈ A a_t \in A at∈A Perform the actual action at , Expressed as π m p {\pi}_{m_p} πmp.
- Based on this structure ,Kao wait forsomeone , Use from SymCAT Simulated data training of symptom disease database online symptom checker , For self diagnosis of health-related diseases . It is Symptom Checking 1.0 Improved version ,Kao wait forsomeone , stay Symptom Checking 1.0 Another layer is added to the anatomical model of DQN As the main agent . Both anatomical model and main model are applied DQN To choose maximization Q A worthy action . Their results show that , Compared with traditional systems , The proposed hierarchical reinforcement learning algorithm significantly improves the accuracy of symptom examination .
Circular reinforcement learning
- Sepsis treatment 2.0
- Futoma wait forsomeone (2018) Put forward the right DRQN New extensions to the architecture , Use multi output Gaussian processes to train agents to learn the best treatment for patients with sepsis . They collected from the private database of Duke University Health System 9,255 Patients with sepsis and 165 Item characteristics ( Including demographics 、 Longitudinal physiological variables 、 Medication, etc ) The data of , And in 30 Follow up was carried out within days . Operations are discrete values , from 3 A common treatment composition for patients with sepsis : Antibiotic 、 Vasopressor and intravenous infusion . Rewards are sparsely encoded . The reward for each non terminating time point is 0. If the patient survives , At the end of the track, the reward is +10; If the patient dies, the reward is -10 . They studied in DQN Used in architecture LSTM The effect of layer replacement of fully connected neural network layer . The optimization policy of sepsis treatment can reduce the mortality of patients from 13.3% The overall baseline mortality rate decreased 8.2%.
Reverse reinforcement learning
- Diabetes treatment
- In previous papers , The reward function is approximated by heuristic . however , The appropriateness of the reward function cannot be verified . Recently about RL In the research of , Someone put forward a counter proposal RL To estimate their reward function from the behavior data of experts . There have been some papers on inverse RL(Ng wait forsomeone ,2000 year ;Abbeel and Ng,2004 year ). However , As far as we know , There is no paper based on DNN The inverse of RL Algorithm used in clinical decision support . For non DNN The inverse of RL,Asoh(2013) In Bayesian framework, inverse RL, And use Markov chain Monte Carlo sampling (Ghavamzadeh etc. ,2015) Learn the reward function in the clinical environment . They apply inverse RL To learn the reward function of diabetes treatment with a unified priori . The drug prescription data is the private data of Tokyo University Hospital . States are discrete , Defined as the severity of diabetes (“ normal ”、“ in ”、“ severe ”). They use MCMC Sample and place 3 The rewards of states are deduced as r = ( 0.01 , 0.98 , 0.01 ) r = (0.01, 0.98, 0.01) r=(0.01,0.98,0.01). Reward display “ Moderate ” Patients with diabetes have the highest value . This seems to contradict the current clinical understanding , That is, the reward should be right “ normal ” Level of diabetes patients have the highest value .Asoh wait forsomeone , explains , In their database 65% Of diabetes patients are already in “ secondary ” state . therefore , Put the patient in “ secondary ” Status may be the clinician's best effort .
- Although few clinical applications have achieved inverse RL, But we believe in inverse RL Is a valuable topic , It will be beneficial to the application in clinical environment . We not only optimize the strategy by imitating the behavior of experts , And we are also very keen on training strategies , So that it can automatically find out the treatment methods that clinicians consider important .
How to choose reinforcement learning algorithm
- There is no single answer to this question . RL The choice of algorithm will depend on the actual application . The following is a list of trade-offs and assumptions to consider :
- Sample efficiency : Sample efficiency refers to how many samples are needed to make the algorithm converge . If the algorithm is on-policy, such as policy gradient RL, Then it needs more samples . by comparison , Value based RL And model-based RL yes off-policy Algorithm , Therefore, less samples are required for training . Actor-critic RL The algorithm is between value based RL And strategic gradient RL Between . Given the different sample efficiency , This does not mean that we should always choose the one that requires less samples . For specific applications that are easy to generate samples ( Symptom checker 1.0 Use the simulator to generate data ), The clock time of model training may be more important than the number of samples required . under these circumstances ,on-policy RL Algorithm may be preferred , Because they are usually better than off-policy RL The algorithm converges faster .
- convergence : The strategy gradient makes a gradient rise to the objective function , Ensure convergence . Value based RL Minimized the fitting “ Behrman error ”, But in the worst case , There is no guarantee that it will converge to anything in the case of nonlinearity . For model-based reinforcement learning algorithm , Model minimizes fitting error , Ensure the convergence of the model . However , A better model is not equal to a better strategy .
- Episodic/ Infinite horizon :Episodic It means state - The action track has an end . for example , In the disease symptom checker Application , Agents constantly search for symptoms , When the agent finds the disease , It's over . The plot is usually assumed by the strategic gradient method , Also by some model-based RL The method assumes . Infinite horizon means that the trajectory has no definite end . The time step of the trajectory can reach infinity , But there will always be some , The distribution of state action pairs remains stable , No more changes . We call it a stationary distribution . Most of the applications we discuss in this article are episodic (Episodic) Of , And there is a clear end ( Mortality 、 Disease diagnosis ). Episodic Assumptions are usually made by pure policy gradients RL And some model-based RL Algorithm hypothesis . And we observe value based RL The algorithm is also applicable to many clinical applications in this paper .
- Completely observe / Observation part MDP: When fully observed MDP when , Can apply all major RL Algorithm . And for some observed MDP, One possible solution is to use loops RL, For example, based on LSTM Of DRQN Algorithm , Aggregate all historical observations into a confidence state . In real time , Most clinical applications are POMDP; We can only express the state of patients through their physiological characteristics . For in POMDP Methods of working in , except RNN outside , Methods of maintaining confidence are also widely used . Belief state is a posterior distribution of potential states based on incomplete history and noisy observations . McAllister and Rasmussen (2017) It illustrates a special case , Part of the observability is caused by additive Gaussian white noise in the unobserved state . Then you can use beliefs to filter out noisy observations .Igl wait forsomeone (2018) This paper proposes a deep variational reinforcement learning (DVRL) Algorithm , The algorithm uses DNN Directly output the confidence state from noisy observations . They show that their algorithm is superior to cyclic reinforcement learning in inferring actual belief States .
Challenges and remedies
- Learn from limited observational data
- Deep RL Application in clinical environment and Atari The game is very different , stay Atari In the game , You can repeat the game many times and play all possible scenes , With permission Deep RL The best strategy of agent learning . In a clinical setting ,Deep RL Agents need to learn from a limited set of data collected and changes in interventions . It is called POMDP problem . therefore , For clinical applications ,RL The improvement strategy learned by agents is often not the optimal strategy . As mentioned in the previous section , This problem can be solved by using such as LSTM(Futoma wait forsomeone ,2018 year ) Or by using DNN(Igl wait forsomeone ,2018 year ) Infer and maintain confidence states to solve .
- Definition of state action , Reward space for clinical application
- Find the state in the clinical environment 、 Proper representation of actions and reward functions is challenging (Futoma etc. ,2018). A reward function needs to be defined to balance the trade-off between short-term improvement and long-term success . With ICU For example, patients with sepsis . The periodic improvement of blood pressure may not lead to the improvement of patients' prognosis . However , If we only focus on the patient's results ( Live or die ) As a reward , This will lead to a long learning sequence , Without any feedback to the agent . Although the good news is some RL Algorithm , For example, inverse RL, We don't need to design rewards manually . have access to DNN Approximate it , We can even train the reward that is closer to the actual reward than the handmade reward .
- Performance benchmarking
- In other areas , For example, video games ,DQN stay Atari The successful implementation of the game has aroused great interest in this field Mnih wait forsomeone . (2013). for example ,DeepMind The actors will be - Critic RL Applied to their video games “ starcraft II”(Alghanem wait forsomeone ,2018 year ). Microsoft has developed an open source environment for researchers , For testing their video games “ Malmo ”(Johnson wait forsomeone ,2016). Now? , All these successful implementations become RL Benchmark for any new applications in video games . however , In the field of health care , Due to the lack of many successful applications , So there is no benchmark . We observed that most of the existing RL Healthcare applications use MIMIC EHR database Johnson wait forsomeone (2016a). therefore , We plan to use MIMIC Data to establish a set of benchmarks , To apply deep reinforcement learning to ICU Clinical decision support .
- Explore / Development
- RL The basic dilemma is exploration and development . If the agent knows that taking certain actions will bring good returns , So how does the agent decide to try new behaviors to find behaviors with higher returns ( Explore ) Or continue to do the best thing known so far ( Development ). Exploration means doing what we know will produce the highest return , And exploration means doing something we haven't done before , But I hope to get a higher return . Due to ethical and therapeutic safety considerations , Exploration can be challenging in a clinical setting . An example of exploring development balance is using ϵ − g r e e d y \epsilon-greedy ϵ−greedy The probability of searching to explore is ϵ ∈ [ 0 , 1 ] \epsilon \in [0, 1] ϵ∈[0,1] Random action of . ϵ \epsilon ϵ The higher the value of , When agents explore any action, the more “ to open up ”. Alternative ways to choose exploration or development include optimistic exploration (Auer wait forsomeone ,2002 year )、 Thompson sampling (Chapelle and Li,2011 year ) And information gain (Mohamed and Rezende,2015 year ;Houthooft wait forsomeone ,2016 year ).
- Data defects and data quality
- Almost all deep learning models have the problem of insufficient data in the application of health care . Although there are public databases available , But smaller medical institutions usually lack enough data to rely on their local databases to fit a good deep learning model . Possible solutions include the use of GAN Our model generates data from similar distributions (Tseng wait forsomeone ,2017 year ), Or use transfer learning (Haarnoja wait forsomeone ,2017 year ) Pre training from a larger data set DNN Model , Then apply it to smaller hospitals / Institutional clinical data .
- Almost all deep learning models have the problem of insufficient data in the application of health care . Although there are public databases available , But smaller medical institutions usually lack enough data to rely on their local databases to fit a good deep learning model . Possible solutions include the use of GAN Our model generates data from similar distributions (Tseng wait forsomeone ,2017 year ), Or use transfer learning (Haarnoja wait forsomeone ,2017 year ) Pre training from a larger data set DNN Model , Then apply it to smaller hospitals / Institutional clinical data .
边栏推荐
猜你喜欢

Applet running under the framework of fluent 3.0

Beaucoup d'enfants ne savent pas grand - chose sur le principe sous - jacent du cadre orm, non, ice River vous emmène 10 minutes à la main "un cadre orm minimaliste" (collectionnez - le maintenant)

Sword finger offer II 041 Average value of sliding window
很多小伙伴不太了解ORM框架的底层原理,这不,冰河带你10分钟手撸一个极简版ORM框架(赶快收藏吧)

leetcode 873. Length of Longest Fibonacci Subsequence | 873. 最长的斐波那契子序列的长度
图解网络:揭开TCP四次挥手背后的原理,结合男女朋友分手的例子,通俗易懂
Can you write the software test questions?
Tapdata 的 2.0 版 ,开源的 Live Data Platform 现已发布

ANSI / nema- mw- 1000-2020 magnetic iron wire standard Latest original

第七章 行为级建模

随机推荐
ArrayList源码深度剖析,从最基本的扩容原理,到魔幻的迭代器和fast-fail机制,你想要的这都有!!!
Why did MySQL query not go to the index? This article will give you a comprehensive analysis
【错误】加载h5权重出错AttributeError: ‘str‘ object has no attribute ‘decode‘
#797div3 A---C
VIM use
系统测试的类型有哪些,我给你介绍
Version 2.0 of tapdata, the open source live data platform, has been released
Voice of users | understanding of gbase 8A database learning
WPF custom realistic wind radar chart control
Qml 字体使用pixelSize来自适应界面
leetcode 866. Prime Palindrome | 866. 回文素数
Urban land use distribution data / urban functional zoning distribution data / urban POI points of interest / vegetation type distribution
Exit of processes and threads
Beaucoup d'enfants ne savent pas grand - chose sur le principe sous - jacent du cadre orm, non, ice River vous emmène 10 minutes à la main "un cadre orm minimaliste" (collectionnez - le maintenant)
MySQL查询为什么没走索引?这篇文章带你全面解析
Version 2.0 de tapdata, Open Source Live Data Platform est maintenant disponible
城市土地利用分布数据/城市功能区划分布数据/城市poi感兴趣点/植被类型分布
Optimization of ecological | Lake Warehouse Integration: gbase 8A MPP + xeos
QML fonts use pixelsize to adapt to the interface
如何用Diffusion models做interpolation插值任务?——原理解析和代码实战