当前位置:网站首页>Semantic segmentation | learning record (3) FCN
Semantic segmentation | learning record (3) FCN
2022-07-08 02:09:00 【coder_ sure】
Tips : come from up Lord thunderbolt Wz, I'm just taking study notes
List of articles
Preface
Fully Convolutional Networks for Semantic Segmentation(FNC) The network is published in 2015CVPR An article on . Interested readers can click the link to download by themselves .
One 、Fully Convolutional Network
FCN(Fully Convolutional Network) yes First end-to-end For Pixel level prediction Of Fully convolutional network . The full convolution in this article means that the full connection layer in the classification network in the whole network is replaced by the convolution layer . This is a leading article in the field of semantic segmentation .
Let's take a look FCN The effect of semantic segmentation of the network :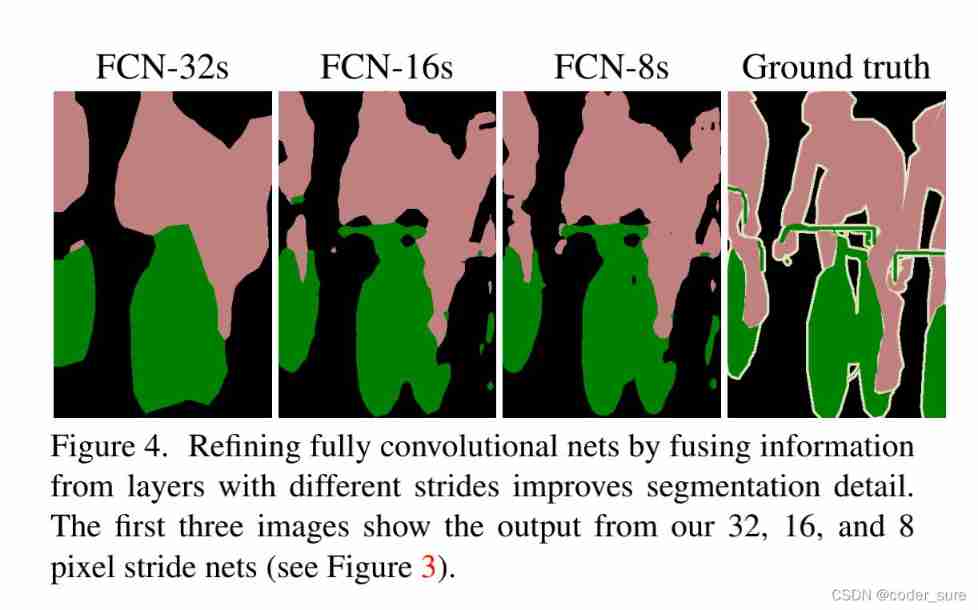
We can see FCN-8s The semantic segmentation effect of has been compared with Ground truth Very close , It can be explained here FCN The effect of the network is still very good ( At least in that year, the effect was good ).
The author will also FCN Compared with the mainstream algorithm of that year , stay mean IoU And reasoning time can sling opponents .
Let's take a look at the article FCN-32s Network structure , You can also find that its network structure is very simple , But in fact, the semantic segmentation structure is very good , This is also FCN The excellence of .
By the way , We can observe through a series of convolutions 、 Down sampling , The last characteristic layer is observed channel=21, This is because the data set used is PASCAL VOC(20 Category + background ), Then, we can get the same size feature map as the original image by up sampling (channel=21), For each pixel 21 Value for softmax Handle , The prediction probability of the pixel for each category is obtained , Take the one with the greatest probability as the prediction category .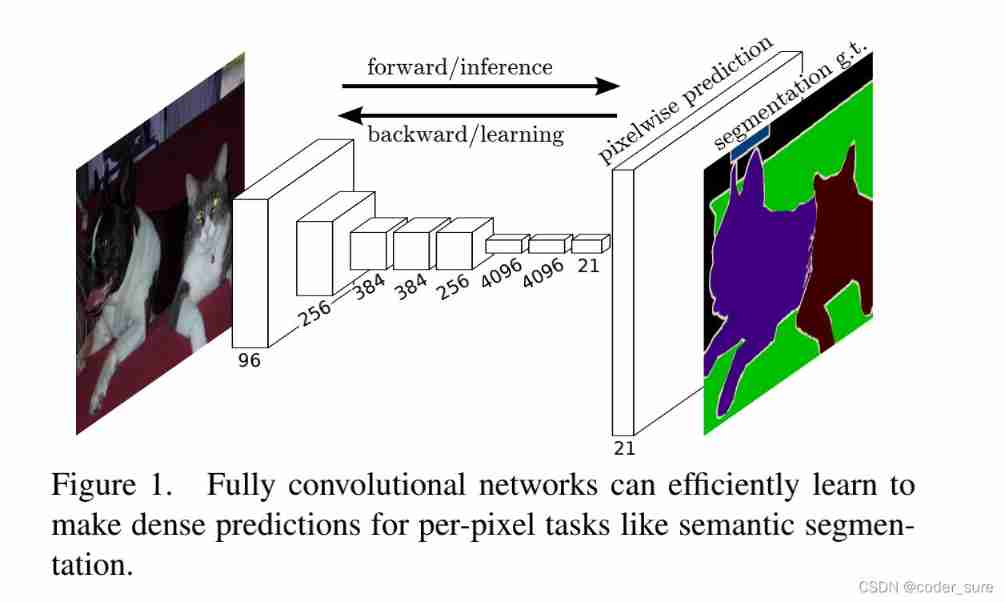
Two 、Convolutionalization
We know that the full connection layer requires us The pixels of the input picture are fixed . We need to fix the image input when training the classification network .
So if the The whole connection layer is changed into convolution layer , Then there is no limit to the size of the input image .
Here we will do the whole connection layer Convolutionalization Handle , As shown in the figure below , This is a picture of any size that can be input . But if the input image is Greater than 224*224 Words , Then the height and width of the last feature layer are greater than 1 了 , This corresponds to every last channel The data of is a 2 D data . Then we can develop it into a plane visualization .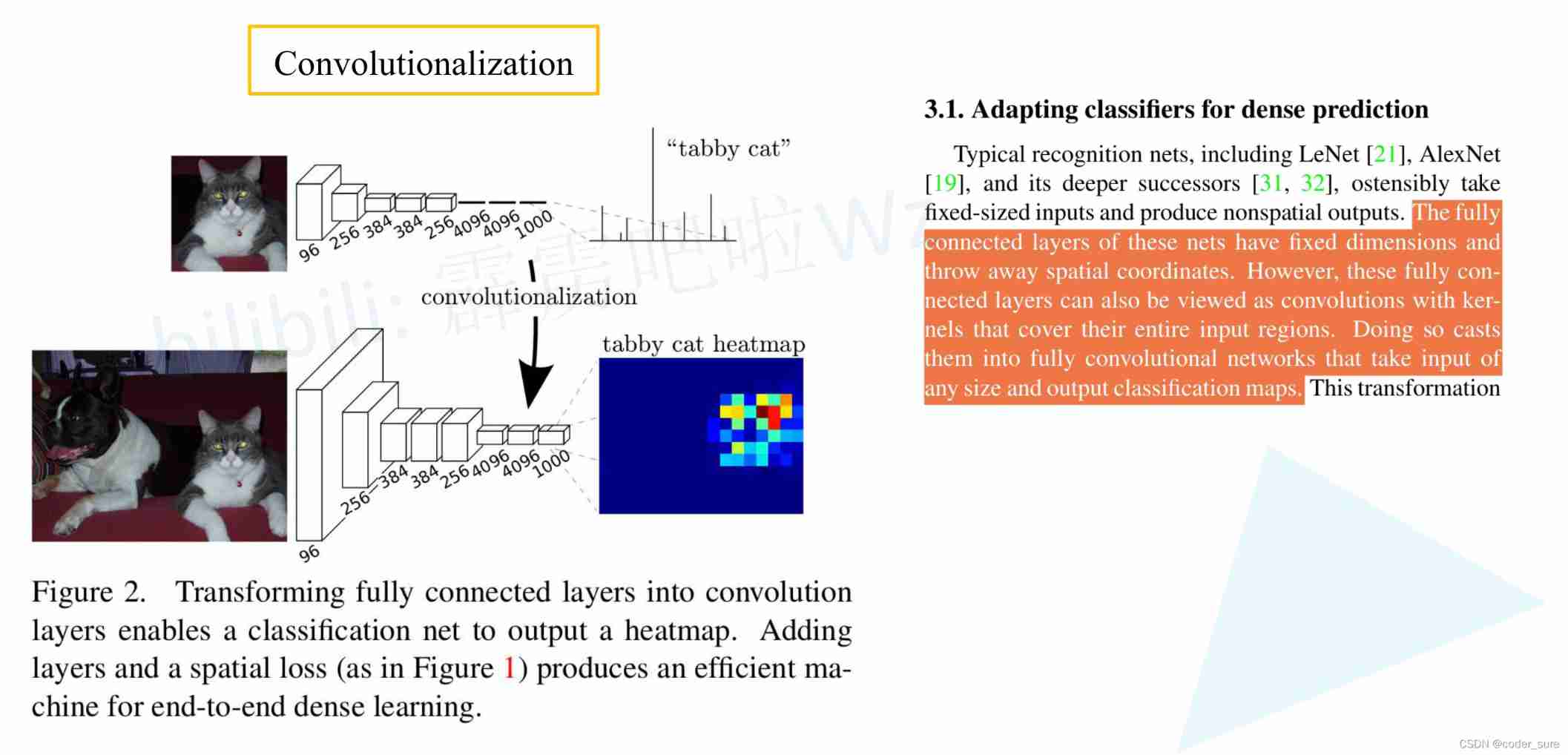
3、 ... and 、Convolutionalization Process principle
We use VGG16 Take the Internet for example :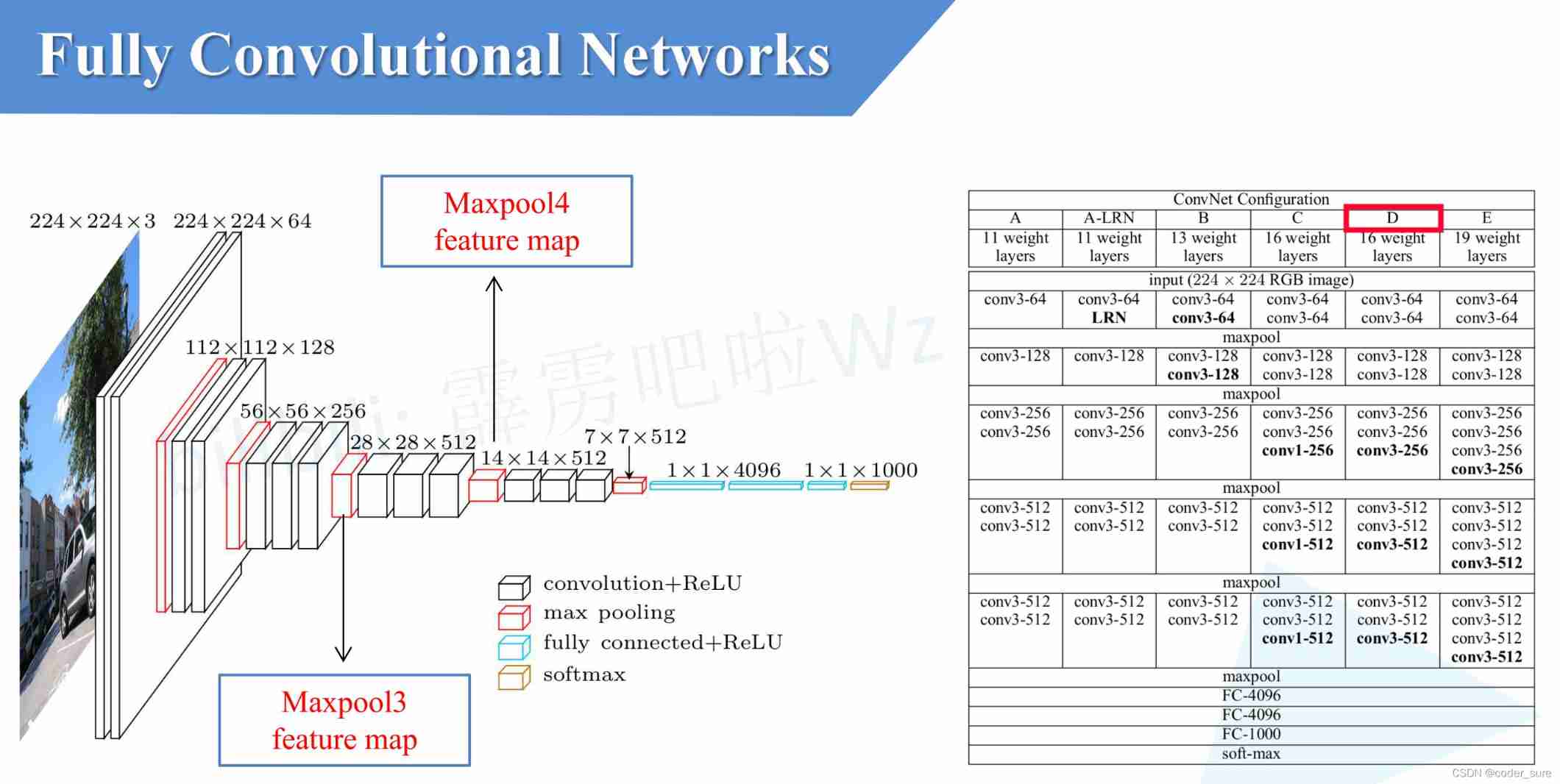
- take 7 * 7 * 512 The characteristic layer of flatten And a set of lengths after full connection operation 4096 The layer ,FC1 The parameter is 102760448
- take 7 * 7 * 512 Through conv(7*7,s1,4096) After the operation ,conv The parameter quantity is also 102760448
From the above description, we can know that the two processes are completely equivalent , This is the same. Convolutionalization The process of .
Four 、FCN Model details
Given in the original paper FCN-32s-fixed,FCN-32s,FCN-16s,FCN-8s Comparison list of various performance indicators , We can also find that the effect is getting better .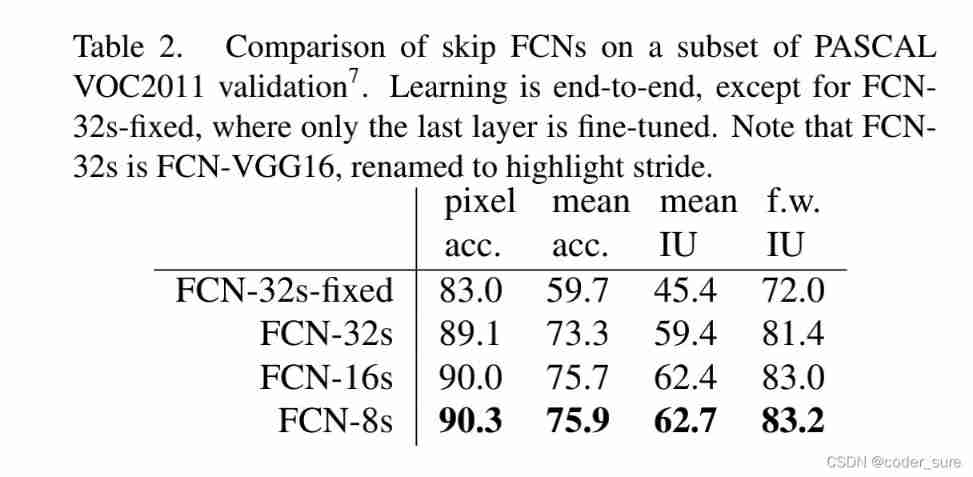
What exactly are these models ?
- FCN-32s: Is to sample the prediction results 32 times , Restore to the original size .
- FCN-16s: Is to sample the prediction results 16 times , Restore to the original size .
- FCN-8s: Is to sample the prediction results 8 times , Restore to the original size .
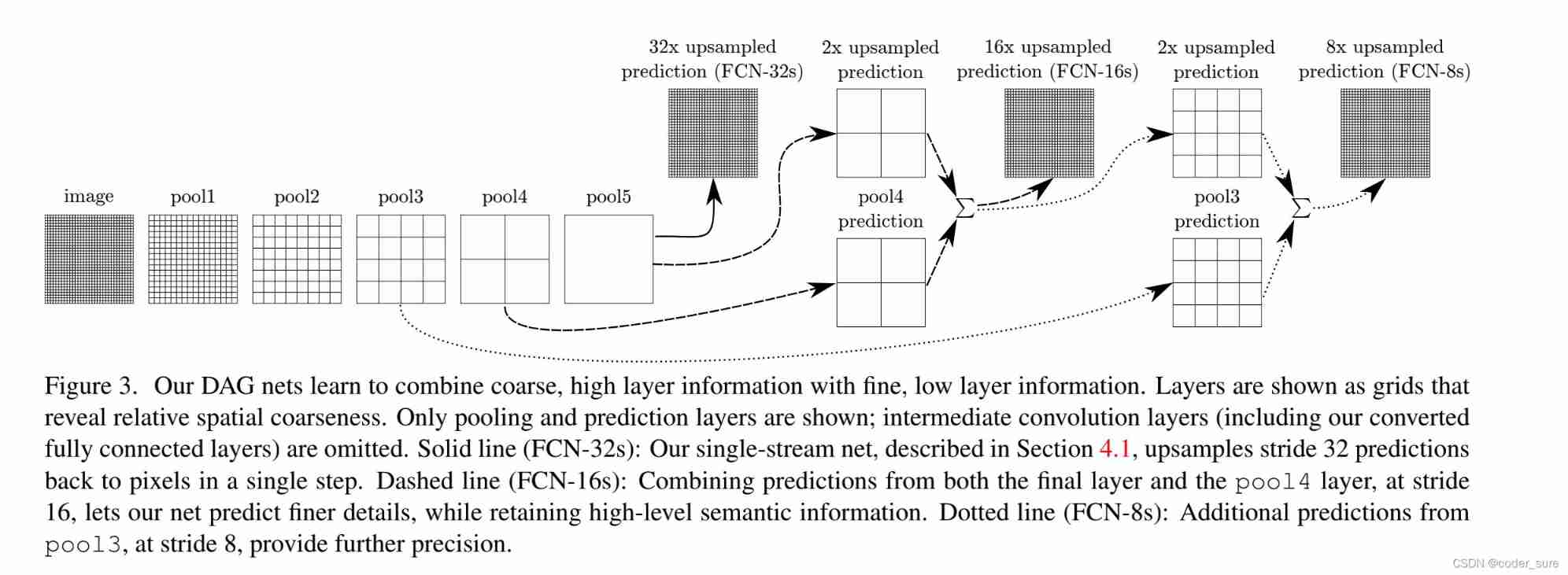
1. FCN-32s

The network structure is shown in the figure above , Here are some key points :
In the original paper, the author is backbone At the first convolution layer of padding=100, Why? ?
In order to make FCN The network can adapt to networks of different sizes
If not padding=100 How will it be handled ?
If the size of the picture is smaller than 192 * 192, The size of the last feature layer is less than 7*7 了 , If padding=0 Words , Then you can't control less than 7 * 7 The layer of is equivalent to the convolution operation of normal full connection .
In addition, if the size of the image we input is smaller than 32 * 32,backbone You have already reported an error before you finish leaving .
But think about this from the current perspective , The author is unnecessary padding=100 Of
First , Generally, no one will be less than 32 * 32 Semantic segmentation of pictures , in addition , When the picture is greater than 32 * 32 when , We can make FC6 in 7*7 Convoluted padding=3, We can train any height and width larger than 32 * 32 Pictures of the .
In the original paper, the author used the bilinear difference method to initialize the parameters of transpose convolution
2. FCN-16s
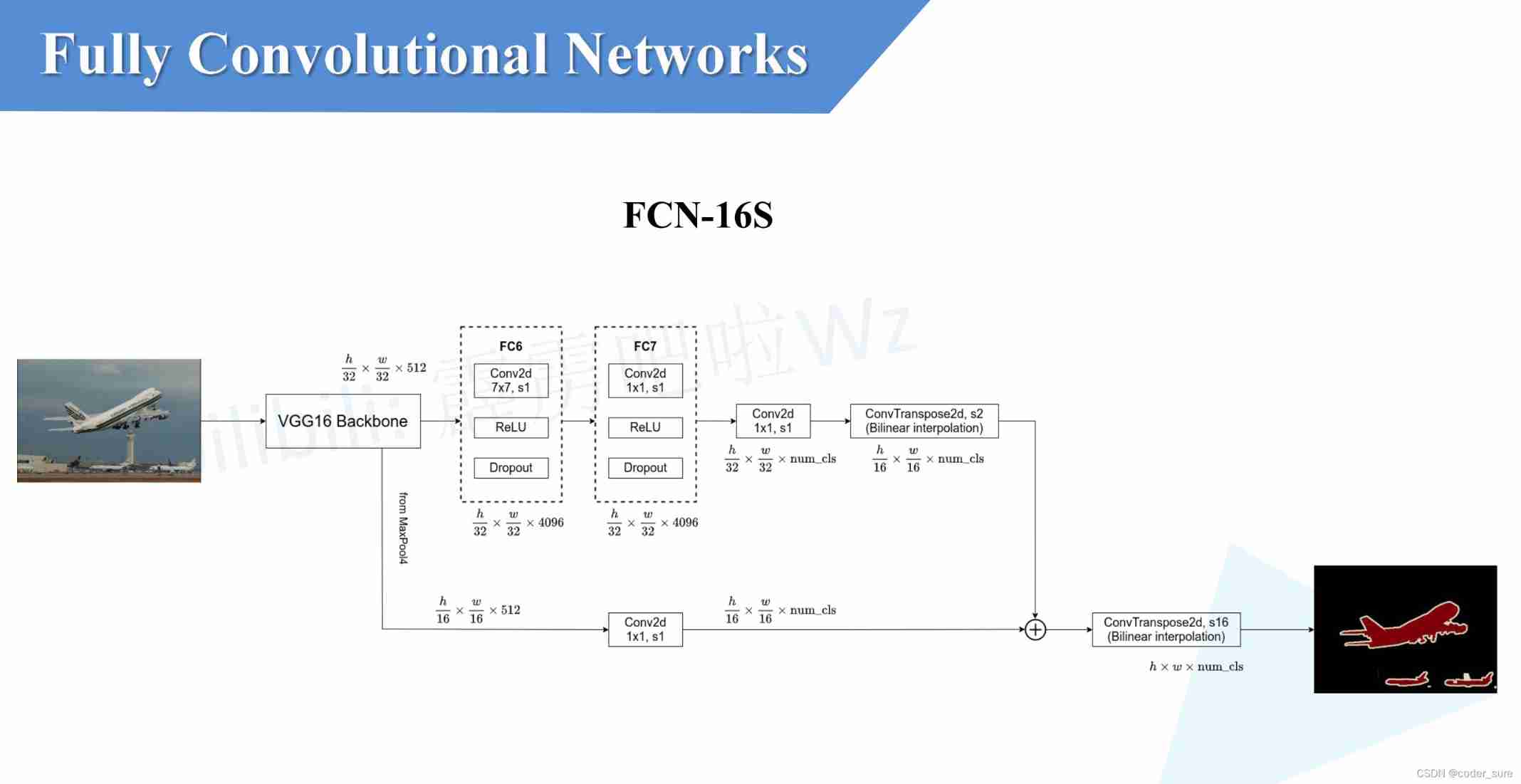
And above FCN-32s The difference lies in :
- The transpose convolution in this is sampled 2 times
- Extra use comes from maxpooling4 Input characteristic diagram of ( Down sampling 16 times )
3. FCN-8s

FCN-8s In addition to the above fusion operations , It also makes use of resources from maxpooling3 An output of
summary
FCN The biggest feature of the network is to convert the ordinary full connection layer into convolution layer , It not only realizes the degree of freedom of the input image , And the segmentation effect is very ideal .
common FCN There are three types of networks :,FCN-32s,FCN-16s,FCN-8s. Their effects are becoming more and more ideal in turn . In fact, through integration maxpoling Operation of layer information , To achieve better results .
Reference material
边栏推荐
- 需要思考的地方
- 金融业数字化转型中,业务和技术融合需要经历三个阶段
- BizDevOps与DevOps的关系
- Usage of hydraulic rotary joint
- [knowledge map] interpretable recommendation based on knowledge map through deep reinforcement learning
- 软件测试笔试题你会吗?
- WPF custom realistic wind radar chart control
- PHP 计算个人所得税
- Anan's judgment
- Random walk reasoning and learning in large-scale knowledge base
猜你喜欢

力争做到国内赛事应办尽办,国家体育总局明确安全有序恢复线下体育赛事
常见的磁盘格式以及它们之间的区别
静态路由配置全面详解,静态路由快速入门指南
![[knowledge map] interpretable recommendation based on knowledge map through deep reinforcement learning](/img/62/70741e5f289fcbd9a71d1aab189be1.jpg)
[knowledge map] interpretable recommendation based on knowledge map through deep reinforcement learning
Introduction à l'outil nmap et aux commandes communes
C语言-模块化-Clion(静态库,动态库)使用
JVM memory and garbage collection-3-object instantiation and memory layout

From starfish OS' continued deflationary consumption of SFO, the value of SFO in the long run

Partage d'expériences de contribution à distance

burpsuite
随机推荐
力扣4_412. Fizz Buzz
系统测试的类型有哪些,我给你介绍
魚和蝦走的路
保姆级教程:Azkaban执行jar包(带测试样例及结果)
C language -cmake cmakelists Txt tutorial
Introduction to Microsoft ad super Foundation
Clickhouse principle analysis and application practice "reading notes (8)
Introduction to ADB tools
Mouse event - event object
#797div3 A---C
Le chemin du poisson et des crevettes
C语言-模块化-Clion(静态库,动态库)使用
谈谈 SAP iRPA Studio 创建的本地项目的云端部署问题
cv2-drawline
VR/AR 的产业发展与技术实现
See how names are added to namespace STD from cmath file
Ml self realization /knn/ classification / weightlessness
快手小程序担保支付php源码封装
nmap工具介绍及常用命令
Kwai applet guaranteed payment PHP source code packaging