当前位置:网站首页>Sofaregistry source code | data synchronization module analysis
Sofaregistry source code | data synchronization module analysis
2022-06-29 15:12:00 【SOFAStack】


writing | Song Guolei (GitHub ID:glmapper )
SOFAStack Committer、 Senior R & D Engineer of huami technology
Responsible for huami account system 、 Development of framework governance direction
this paper 3024 word read 10 minute
| Preface |
This article focuses on SOFARegistry The source code of the data synchronization module is analyzed . among , For the concept of registry and SOFARegistry The infrastructure of will not be described in detail , Interested friends are 《 Registration Center under massive data - SOFARegistry Architecture introduction 》[1] Get relevant introduction in the article .
The main ideas of this paper are roughly divided into the following 2 Parts of :
- The first part , With the help of SOFARegistry The role classification in the shows which roles will synchronize data ;
- The second part , Analyze the specific implementation of data synchronization .
PART. 1——SOFARegistry Role classification

As shown in the figure above ,SOFARegistry Contains the following 4 A character :
Client
Provide the basic information of application access service registry API Ability , The application system depends on the client JAR package , Call the service subscription and service publishing capabilities of the service registry programmatically .
SessionServer
Session server , To accept Client Service publishing and service subscription request of , And forward the write operation as an intermediate layer DataServer layer .SessionServer This layer can be expanded with the increase of the number of business machines .
DataServer
Data server , Responsible for storing specific service data , Data press dataInfoId Be consistent Hash Fragmentation storage , Support multi copy backup , Ensure high availability of data . This layer can be expanded with the growth of service data volume .\
MetaServer
metadata server , Responsible for maintaining the cluster SessionServer and DataServer A consistent list of , As SOFARegistry Address discovery service inside the cluster , stay SessionServer or DataServer When the node changes, the whole cluster can be notified .
Here 4 In roles ,MetaServer As a metadata server, it does not process actual business data , Only responsible for maintaining the cluster SessionServer and DataServer A consistent list of , It does not involve data synchronization .
Client And SessionServer The core action between is to subscribe and publish , In a broad sense , It belongs to the user side client and SOFARegistry Cluster data synchronization , Details can be found in :
https://github.com/sofastack/sofa-registry/issues/195, Therefore, it is beyond the scope of this article .
SessionServer As a session service , It mainly solves the problem of massive client connections , The second is to cache all pub data .Session Does not persist service data by itself , Instead, the data is transcribed to DataServer.DataServer The service data is stored according to dataInfoId Be consistent Hash Partitioned storage , Support multi copy backup , Ensure high availability of data .
from SessionServer and DataServer From the functional analysis of :
SessionServer The cached service data needs to be consistent with DataServer The stored service data is consistent .

DataServer Support multiple copies to ensure high availability , therefore DataServer Service data consistency needs to be maintained between multiple replicas .
SOFARegistry in , For the above two, the data consistency guarantee is realized through the data synchronization mechanism .
PART. 2—— The concrete realization of data synchronization
I understand SOFARegistry After the role classification of , We begin to delve into the implementation details of data synchronization . I will focus on SessionServer and DataServer Data synchronization between , as well as DataServer Data synchronization between multiple replicas is expanded by two pieces of content .
「SessionServer and DataServer Data synchronization between 」
SessionServer and DataServer Data synchronization between , It is based on the following push-pull mechanism :
PUSH : DataServer When the data changes , Will inform you SessionServer,SessionServer Check to make sure you need to update ( contrast version) After the initiative to DataServer get data .
PULL : In addition to the above DataServer Take the initiative to push out ,SessionServer At regular intervals , Will take the initiative to DataServer Query all dataInfoId Of version Information , And then with SessionServer In memory version The comparison . If you find version There are changes , Take the initiative to DataServer get data . This “ PULL ” The logic of , It's mainly about “ PUSH ” A supplement to , If in “ PUSH ” Mistakes and omissions in the process of can be made up in time at this time .
Push and pull mode inspection version There will be some differences , See the following for details “ Data synchronization in push mode ” and “ Data synchronization in pull mode ” Specific introduction in .
「 Data synchronization process in push mode 」
Push mode is through SyncingWatchDog This daemon thread keeps loop Implementation to realize data change inspection and notification initiation :

according to slot Group summary data version .data With each session All connections of correspond to one SyncSessionTask,SyncSessionTask Responsible for the task of synchronizing data , The core synchronization logic is :
com.alipay.sofa.registry.server.data.slot.SlotDiffSyncer#sync Method , The general process is shown in the following sequence diagram :
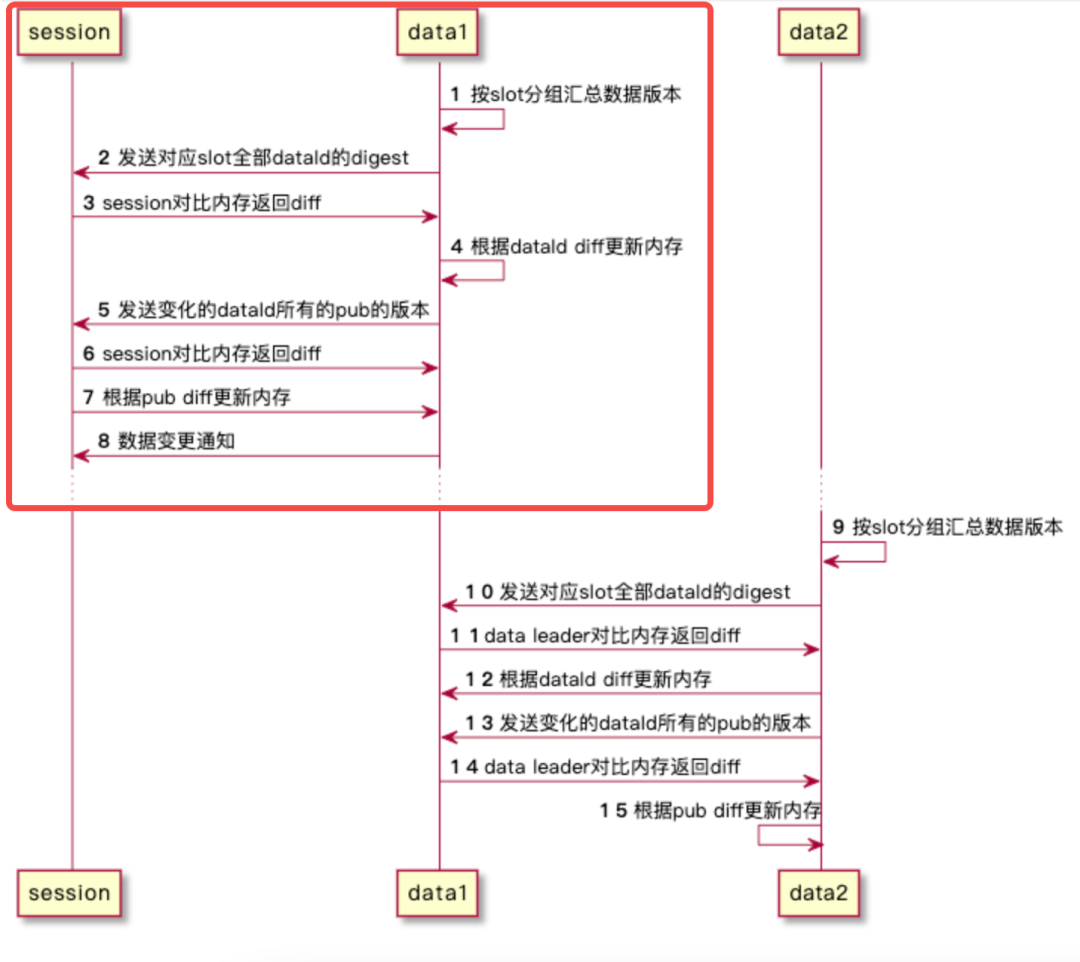
The fourth logical step of the red circle in the above figure , according to dataInfoId diff to update data Memory data , As you can see, only the removed dataInfoId, There is no task processing for the newly added and updated , But through the second 5-7 Step by step . The main reason for this is to avoid some dangerous situations caused by empty push .
The first 5 In step , Compare all the changes dataInfoId Of pub version, For specific comparison logic, please refer to the following diffPublisher The introduction in the section .
「 Event notification processing of data change 」
Data change events are collected in DataChangeEventCenter Of dataCenter2Changes In cache , Then a daemon thread ChangeMerger In charge of from dataCenter2Changes Constant reads from the cache , These retrieved event sources will be assembled into ChangeNotifier Mission , Commit to a separate thread pool (notifyExecutor) Handle , The whole process is asynchronous .

「 Data synchronization process in pull mode 」
In pull mode , from SessionServer Responsible for initiating ,
com.alipay.sofa.registry.server.session.registry.SessionRegistry.VersionWatchDog
By default, every 5 Scan the version data once per second , If the version changes , Then take the initiative to pull , The process is as follows :
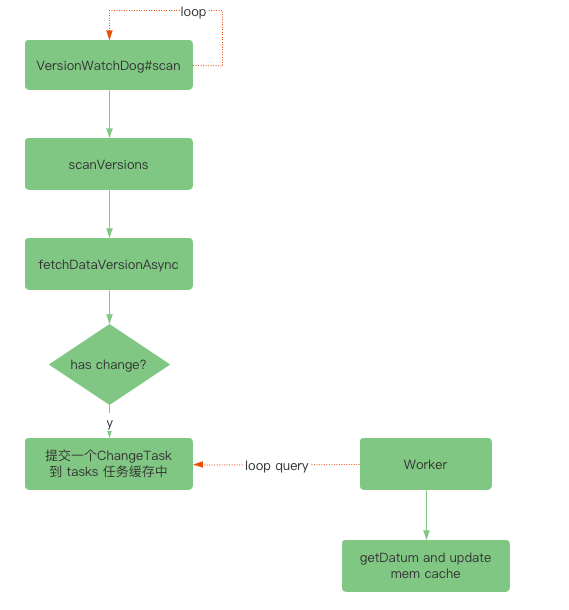
It should be noted that , The pull mode complements the push process , there version Is each sub Of lastPushedVersion, And push mode version yes pub Data. version. About lastPushedVersion You can refer to :
com.alipay.sofa.registry.server.session.store.SessionInterests#selectSubscribers

「DataServer Data synchronization between multiple replicas 」
Mainly slot Corresponding data Of follower Regularly and leader Data synchronization , Its synchronization logic is the same as SessionServer and DataServer There is little difference in data synchronization logic between ; The same is true of the initiation method ;data Judge if the current node is not leader, Will proceed with leader Data synchronization between .

「 The incremental synchronization diff Computational logic analysis 」
Whether it's SessionServer and DataServer Synchronization between , still DataServer Synchronization between multiple replicas , Are based on incremental diff synchronous , The full amount of data will not be synchronized at one time .
This section describes incremental synchronization diff Simple analysis of computational logic , The core code is :
com.alipay.sofa.registry.common.model.slot.DataSlotDiffUtils ( It is recommended to read this part of the code directly in combination with the test cases in the code ) .
It mainly includes calculation digest and publishers Two .
diffDigest
use DataSlotDiffUtils#diffDigest Method accepts two parameters :
- targetDigestMap It can be understood as target data
- sourceDigestMap It can be understood as baseline data
The core computing logic is analyzed as follows :

Then according to the above diff Calculation logic , Here are several scenarios ( Assume that the baseline dataset data dataInfoId by a and b) :
1. The target dataset is empty : return dataInfoId by a and b Two items are added ;
2. The target data set is equal to the baseline data set , What's new 、 Both the items to be updated and the items to be removed are empty ;
3. The target dataset includes a、b、c Three dataInfoId, Then return to c As an item to be removed ;
4. The target dataset includes a and c Two dataInfoId, Then return to c As an item to be removed ,b As a new item
diffPublisher
diffPublisher And diffDigest The calculation is slightly different ,diffPublisher Receive three parameters , In addition to the target and baseline datasets , One more publisherMaxNum ( Default 400) , Used to limit the number of data processed each time ; The core code is also explained here :


Here, we will also analyze several scenarios ( The following refers to updates dataInfoId Corresponding publisher,registerId And publisher One-to-one correspondence ) :
1. The target data set is the same as the baseline data set , And the data does not exceed publisherMaxNum, The returned to be updated and to be removed are both empty , And no unprocessed data remains ;
2. Circumstances requiring removal : The target data set is not included in the baseline dataInfoId Of registerId ( What was removed was registerId, No dataInfoId)
3. What needs to be updated : - The target data set contains data that does not exist in the baseline data set registerId - The target data set and the baseline data set exist registerId Different versions of
PART. 3—— summary
This paper mainly introduces SOFARegistry Data synchronization module in . In the whole process , We start with SOFARegistry Role classification describes the data synchronization problems between different roles , And for which SessionServer And DataServer Data synchronization between and DataServer Data synchronization between multiple replicas is expanded .
stay SessionServer And DataServer Data synchronization analysis , The overall process of data synchronization in push and pull scenarios is emphatically analyzed . Finally, SOFARegistry Added to the data in diff The calculation logic is introduced , Combined with the relevant core code, the specific scenario is described .
On the whole ,SOFARegistry The following three points can enlighten us on the processing of data synchronization :
1. In terms of consistency ,SOFARegistry be based on ap, The final consistency is satisfied , And in the actual synchronous logic processing , Combined with the event mechanism , It is basically done asynchronously , This effectively weakens the impact of data synchronization on the core process ;
2. In pull mode and data change notification , Similar to “ production - Consumption model ”, One is the decoupling of production and consumption logic , More code independent ; On the other hand, cache or queue can be used to eliminate the problem of mutual blocking caused by different production and consumption speeds ;
3. The pull mode complements the push mode ; We know that the push mode is server -> client, Occurs when data changes , If there are some exceptions , Cause a server -> client Link push failed , Will make a difference client Inconsistent data held ; Pull mode supplement , Give Way client Be able to take the initiative to complete the data consistency check .
【 Reference link 】
[1]《 Registration Center under massive data - SOFARegistry Architecture introduction 》:https://www.sofastack.tech/blog/sofa-registry-introduction/
The original address of the project :https://www.sofastack.tech/projects/sofa-registry/code-analyze/code-analyze-data-synchronization/
Learn more about
SOFARegistry Star once :
https://github.com/sofastack/sofa-registry
Recommended reading this week
SOFARegistry Source code | Core of data fragmentation - Routing table SlotTable analyse
Explore SOFARegistry( One )| Infrastructure

MOSN structure Subset Share optimization ideas

Nydus — Next generation container mirroring exploration practice


边栏推荐
- 打造一个 API 快速开发平台,牛逼!
- Informatics Olympiad all in one 1194: mobile route
- Get the width of text component content
- Lumiprobe reactive dye carboxylic acid: sulfo cyanine7.5 carboxylic acid
- Hi, you have a code review strategy to check
- Lumiprobe 点击化学丨非荧光叠氮化物:叠氮化物-PEG3-OH
- PyTorch 二维多通道卷积运算方式
- 我 35 岁,可以转行当程序员吗?
- What is the relationship between synchronized and multithreading
- 卫龙更新招股书:年营收48亿 创始人刘卫平家族色彩浓厚
猜你喜欢
![Abnormal logic reasoning problem of Huawei software test written test [2] Huawei hot interview problem](/img/f0/5c2504d51532dcda0ac115f3703384.gif)
Abnormal logic reasoning problem of Huawei software test written test [2] Huawei hot interview problem

What should phpcms do when it sends an upgrade request to the official website when it opens the background home page?

Alibaba cloud experience Award: use polardb-x and Flink to build a large real-time data screen
阿里云体验有奖:使用PolarDB-X与Flink搭建实时数据大屏

wieshark抓包mysql协议简单分析

ROS notes (10) - Launch file startup

Lumiprobe 点击化学丨非荧光叠氮化物:叠氮化物-PEG3-OH

如临现场的视觉感染力,NBA决赛直播还能这样看?

第九章 APP项目测试(4) 测试工具

June 27 talk SofiE
随机推荐
材质 动态自发光
Lumiprobe 点击化学丨非荧光叠氮化物:叠氮化物-PEG3-OH
Is Guangzhou futures regular? If someone asks you to log in with your own mobile phone and help open an account, is it safe?
投资reits基金是靠谱吗,reits基金安全吗
FIFO implementation with single port RAM
Abnormal logic reasoning problem of Huawei software test written test [2] Huawei hot interview problem
Pytorch two-dimensional multi-channel convolution operation method
The 5th China software open source innovation competition | opengauss track live training
I log in to the RDB database and prompt that the master account authorization is required. How do I know who to call?
Is 100W data table faster than 1000W data table query in MySQL?
ROS 笔记(10)— launch 文件启动
文本预处理库spaCy的基本使用(快速入门)
Lumiprobe 点击化学丨非荧光炔烃:己酸STP酯
捷氢科技冲刺科创板:拟募资10.6亿 上汽集团是大股东
关于项目采购管理,这些你需要知道
Implementing redis distributed locks using custom annotations
MCS:离散随机变量——几何分布
Informatics Olympiad all in one 1003: aligned output
模电 2个NPN管组成的恒流源电路分析
Heavyweight! The latest SCI impact factors were released in 2022, and the ranking of the three famous journals NCS and the top10 of domestic journals has changed (the latest impact factors in 2022 are