当前位置:网站首页>OD-Model [6]: YOLOv2
OD-Model [6]: YOLOv2
2022-08-04 21:08:00 【zzzyzh】
系列文章目录
前言
YOLOv2,即YOLO9000,Is a single phase of real-time object detection model.它在几个方面对YOLOv1进行了改进,包括使用Darknet-19作为骨干,批量规范化,使用高分辨率分类器,And the use of anchor box to predict bounding box and so on.
原论文链接:
YOLO9000: Better, Faster, Stronger
1. Abstract & Introduction
1.1. Abstract
This article introduces an advanced,Real-time target detection network YOLO9000,它可以检测超过9000个类别的物体.首先,本文提出了对 YOLO 检测方法的各种改进,New and draw lessons from the former job.改进后的模型 YOLOv2 在 pascal voc 和 COCO Such as standard detection task is the most advanced.使用一种新颖的多尺度训练方法,相同的 YOLOv2 Model can run under different size,Provides a simple between speed and accuracy of compromise.在 67 FPS 下,YOLOv2 在 VOC 2007 上得到 76.8 mAP.在40帧的FPS下,YOLOv2 获得78.6 mAP,比使用 ResNet 和 SSD 的 Faster RCNN The most advanced methods, such as better,At the same time still run faster.最后,本文This paper proposes a joint training target detection and classification method.利用该方法,本文在COCO检测数据集和ImageNet分类数据集上同时训练YOLO9000.In this paper, the joint training of allowYOLO9000预测没有标记检测数据的对象类的检测.我们在ImageNetDetection task to verify our method.YOLO9000在ImageNet检测验证集上获得19.7 mAP,尽管它只有200个类中的44个类的检测数据.在156个不在COCO中的类中,YOLO9000得到16.0 mAP(弱监督). .YOLO9000Can real-time prediction9000A variety of different object categories of test results.
1.2. Introduction
General target detection should be fast、Accurate and can identify various objects.Due to the development of the neural network,Network has become more and more rapid and accurate.然而,Most testing networks are still limited to a few objects within the scope of.
And for classification and marking of other tasks, such as data sets compared to,The current target detection data set is limited.Target detection data sets usually contain hundreds of thousands to millions of pictures and thousands of categories,And image classification dataset usually contains tens of millions of images and tens of thousands of categories.
We hope the testing could extend to object classification level.然而,Used to detect the label image than used in the classification or markup tags are much expensive.因此,What we see is unlikely in the near future and classification data sets of the same size detection data set.
This paper proposes a new method to control the we have a lot of classification data,And use it to expand the scope of the current detection system.In this paper, the method using object classification layered view,允许我们将不同的数据集组合在一起.
This paper also proposed a joint training algorithm,The algorithm allows us both on training target detection data set,Also on the image classification data set training target detection network.To study the method of using the tag detection images accurate positioning objects,Using the classification image at the same time to increase their vocabulary library(Able to identify the category of the)和鲁棒性.
2. Better
Compared with the advanced testing system,YOLOv1 存在各种缺点.与Fast R-CNN相比,YOLO的错误分析表明YOLOv1 产生了大量的定位误差. 此外,与基于 region proposal(Two stage algorithm to extract candidate box)的方法相比,YOLOv1 With a relatively low recall(The ability to detect all the target). 因此,We focus on improving recall 和定位误差,同时保持分类准确性.
计算机视觉通常趋向于更大,更深的网络.Better performance depends on the network training more often or multiple model.但是,对于 YOLOv2,We need more accurate detection,But still very fast.我们没有扩展网络,而是简化网络,Then make characteristics are more easy to learn.We will work in the past in various ideas combined with our own new ideas,以提高 YOLO 的性能.
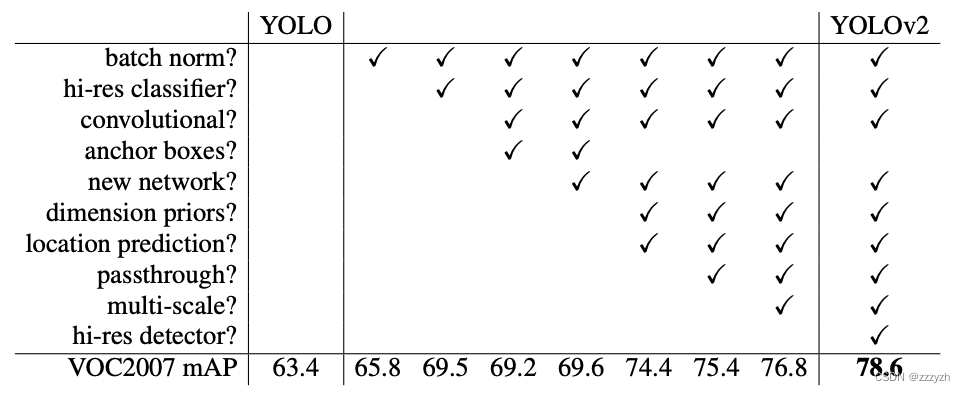
2.1. Batch Normalization
Batch Normalization The convergence significantly improve,At the same time eliminates the need for other forms of regularization.通过在YOLO中的所有卷积层上添加 BN 层,我们可以使mAP提高 2% 以上.BN Layer also helps to model regularization.通过使用 BN 层,我们可以从模型中删除 dropout 而不会过度拟合.
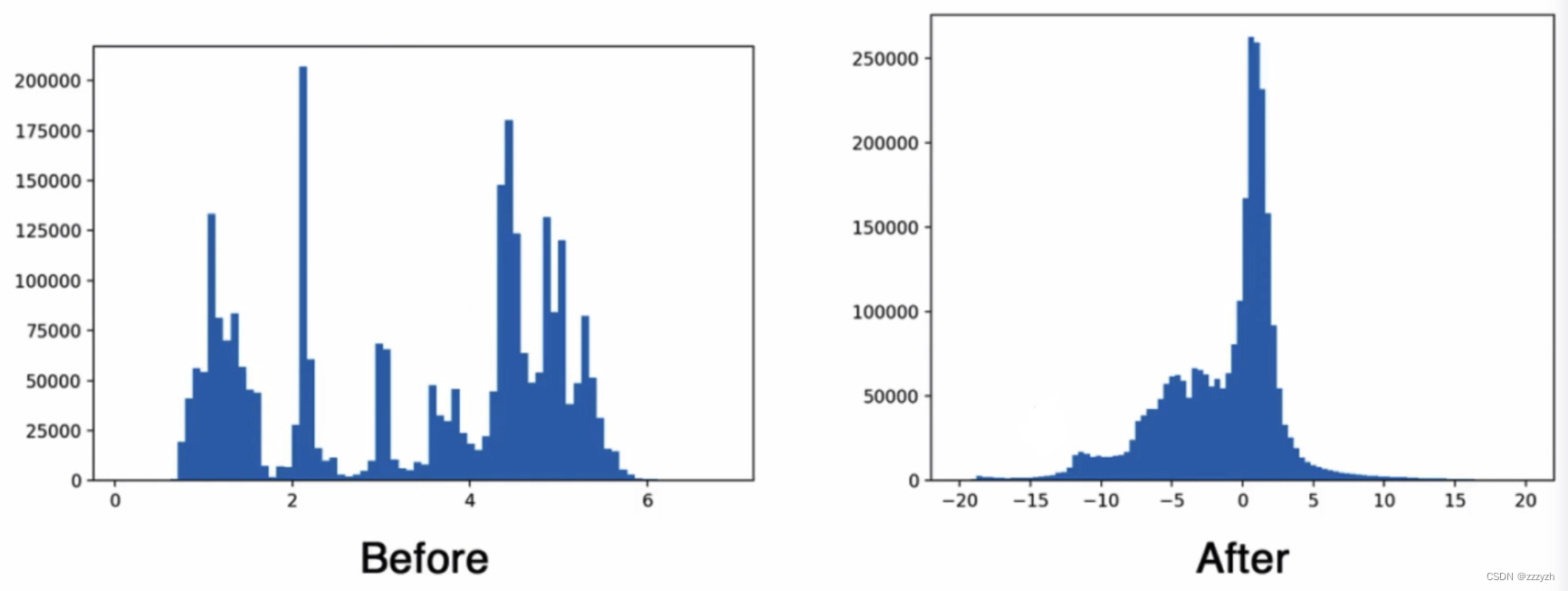
- The regular distribution
- 以0为均值,标准差为1的分布
- Most of the activation function in the0附近是非饱和区,变化大;At both ends is saturated zone(Near the convergence value),梯度消失,平缓

- 训练阶段
- Every layer of each neuron output a set of(batch)响应值,Response to this set of values to do standardized
- 标准化
- x i ^ = x i − μ σ \hat{x_i} = \frac{x_i - \mu}{\sigma} xi^=σxi−μ
- y i = γ x i ^ + β y_i = \gamma \hat{x_i} + \beta yi=γxi^+β
- Each neuron training a group of γ , β \gamma, \beta γ,β
- Through linear transform to revert to the original space,Make up the loss of information
- 标准化
- The response to0附近,Greatly accelerate the convergence speed
- 需要注意的是,BN The output of the operation for each neuron to standardize,Rather than on a layer of the output of standardize
- Every layer of each neuron output a set of(batch)响应值,Response to this set of values to do standardized
- 测试阶段
- The mean test phase、方差、 γ \gamma γ、 β \beta βAll in the training phase of the global out
- μ t e s t = E ( μ b a t c h ) \mu_{test} = \mathbb{E}(\mu_{batch}) μtest=E(μbatch)
- 对每一组batchThe average of average,Get a global average
- σ t e s t 2 = m m − 1 E ( σ b a t c h 2 ) \sigma^2_{test} = \frac{m}{m-1} \mathbb{E}(\sigma^2_{batch}) σtest2=m−1mE(σbatch2)
- 对每一组batchThe variance of calculating mean
- 使用 m m − 1 \frac{m}{m-1} m−1m,无偏估计,To find the global variance
- μ t e s t = E ( μ b a t c h ) \mu_{test} = \mathbb{E}(\mu_{batch}) μtest=E(μbatch)
- Batch Normalization Equivalent to linear transformation
- B N ( X t e s t ) = γ ⋅ X t e s t − μ t e s t σ t e s t w + ϵ BN(X_{test}) = \gamma \cdot \frac{X_{test} - \mu_{test}}{\sqrt{\sigma^w_{test} + \epsilon }} BN(Xtest)=γ⋅σtestw+ϵXtest−μtest
- The mean test phase、方差、 γ \gamma γ、 β \beta βAll in the training phase of the global out
- 例子
- In the position and role of network
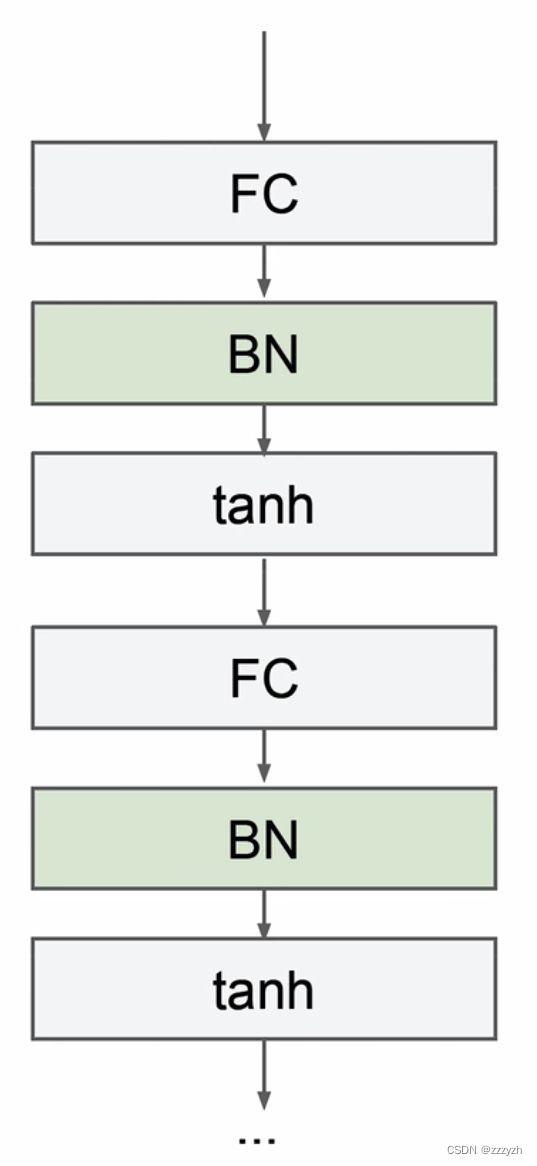
- Usually in back of the linear layer、In the front of the activation layer
- 在 YOLOv2 中,Behind the linear layer,leaky ReLuIn the front of the activation function
- 作用
- Make the network more easy to train(加快收敛)
- 改善梯度(Let data from saturated zone)
- Allows the use of vector big
- 对初始化不敏感
- 可以起到正则化的作用
- 需要注意的是,训练和测试的 BN 层不一样
- 与DropoutUsing the result is bad
- Usually in back of the linear layer、In the front of the activation layer
2.2. High Resolution Classifie
所有最先进的检测方法都使用在 ImageNet 上预先训练的分类器.原始的 YOLO Training classifier networks as 224 × 224 224 \times 224 224×224 And increase the resolution of 448 × 448 448 \times 448 448×448 进行检测.This means that the network must learn at the same time to switch to the target detection and adjust to the new input resolution.
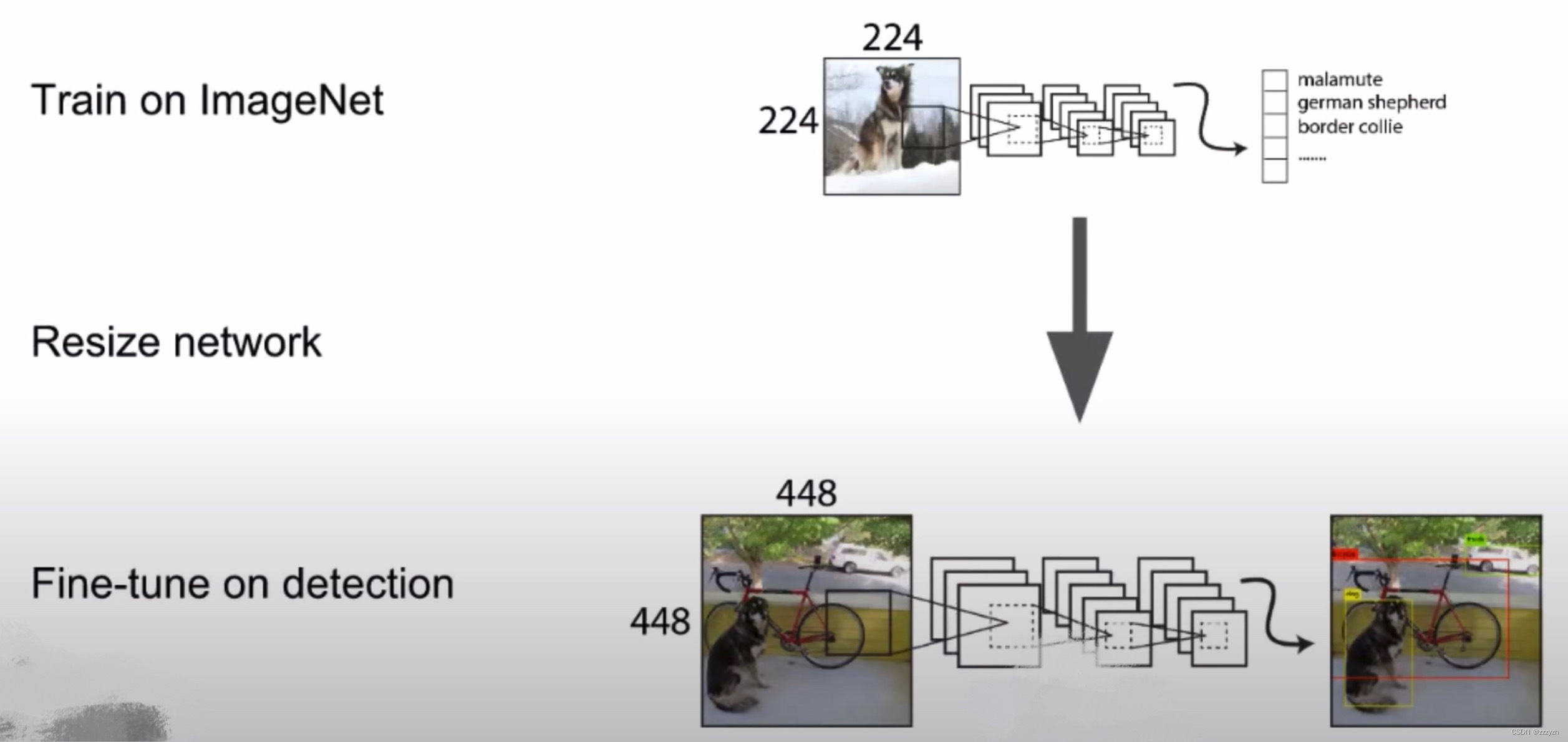
对于YOLOv2,我们首先在 ImageNet In order to complete 448 × 448 448 \times 448 448×448 分辨率微调分类网络10个 epoch(迭代周期).The network has time to adjust its convolution kernels,以便在更高分辨率的输入上更好地工作.然后我们在检测时对生成的网络进行微调.高分辨率分类网络使我们的 mAP 增加了近4%.
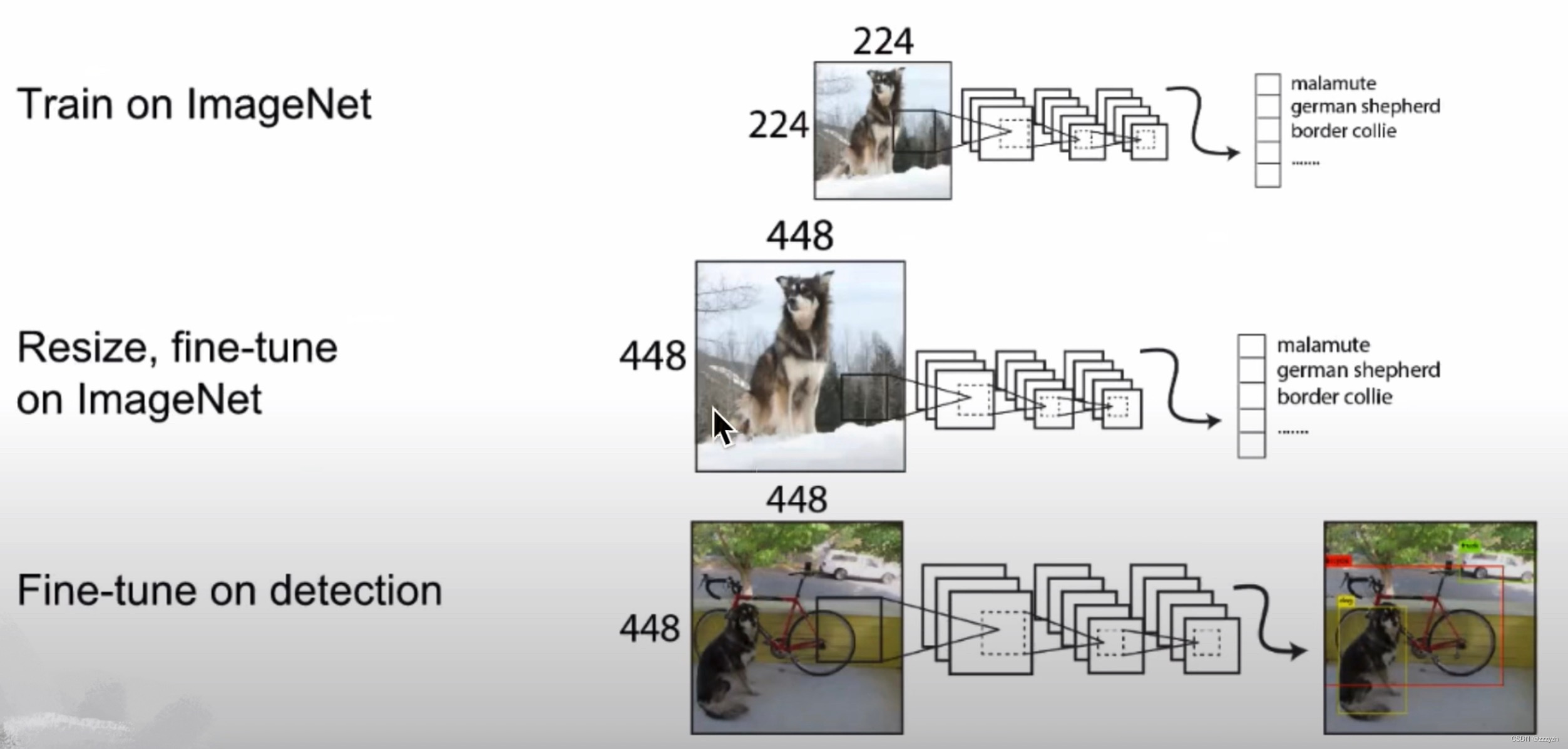
2.3. Convolutional With Anchor Boxes
借鉴Faster RCNN的做法,YOLOv2 也尝试采用先验框(anchor).在每个grid预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度,这些先验框作为预定义的候选区在神经网络中将检测其中是否存在对象,以及微调边框的位置.
每个 grid cell 预测5个大小、The aspect ratio of differentanchor.每个anchor对应一个预测框,And only need to predict the prediction casing、The output relative to his correspondinganchor的偏移量.Artificial marking the center of the box,In which grid cell 中,就由哪个 grid cell 产生的 5 个 anchor 中,With the bubbles IOU 最大的anchor去预测,Forecast and predict box need only with the corresponding anchor 的偏移量即可.
In this paper, removedYOLOAll links in the network layer and useanchor boxes来预测边界框.YOLOv2 移除了一个pooling层,The output of the network convolution layer higher resolution.This article also to reduce the network used in 416 × 416 416 \times 416 416×416 The input image rather than 448 × 448 448 \times 448 448×448 上操作.Do this because we want to be in our feature maps with an odd number of position,So only one center cell.物体,Especially the big object,往往占据图像的中心,So it's best to have a place in the center to predict these objects instead of the four locations near the.
YOLOThe convolution of layer to reduce the image32倍,因此通过使用 416 × 416 416 \times 416 416×416 的输入图像,我们得到 13 × 13 13 \times 13 13×13 的输出特征图.
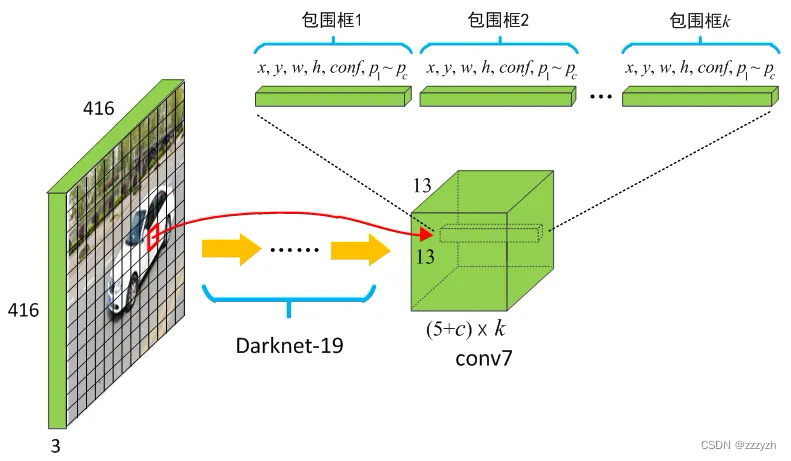
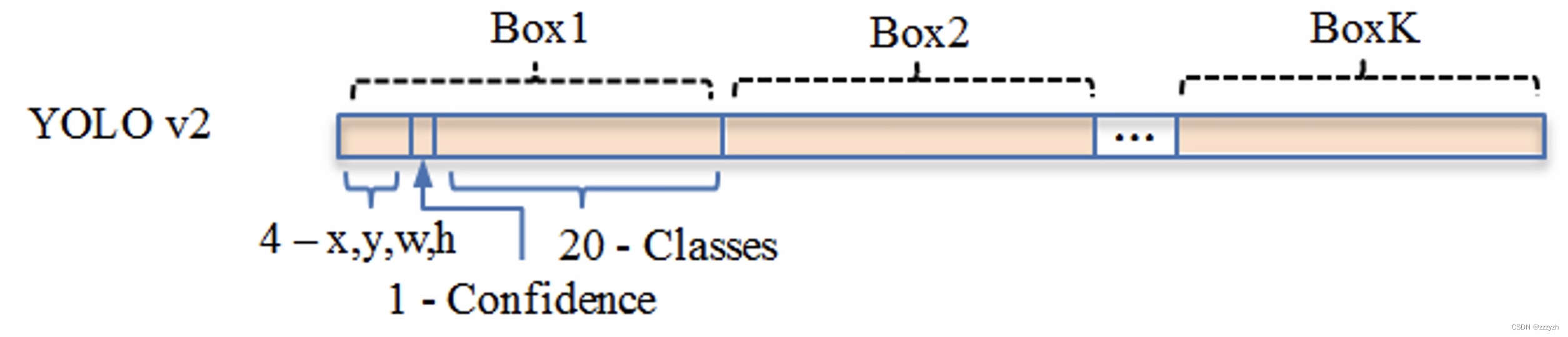
对应的输出,是一个 13 × 13 × 125 13 \times 13 \times 125 13×13×125 的 feature map.The original image is divided into13个 grid cell,每个 grid cell 对应 5 个 anchor,每个 anchor 包含 25 个 参数:位置信息(4),置信度(1),概率分布(20).
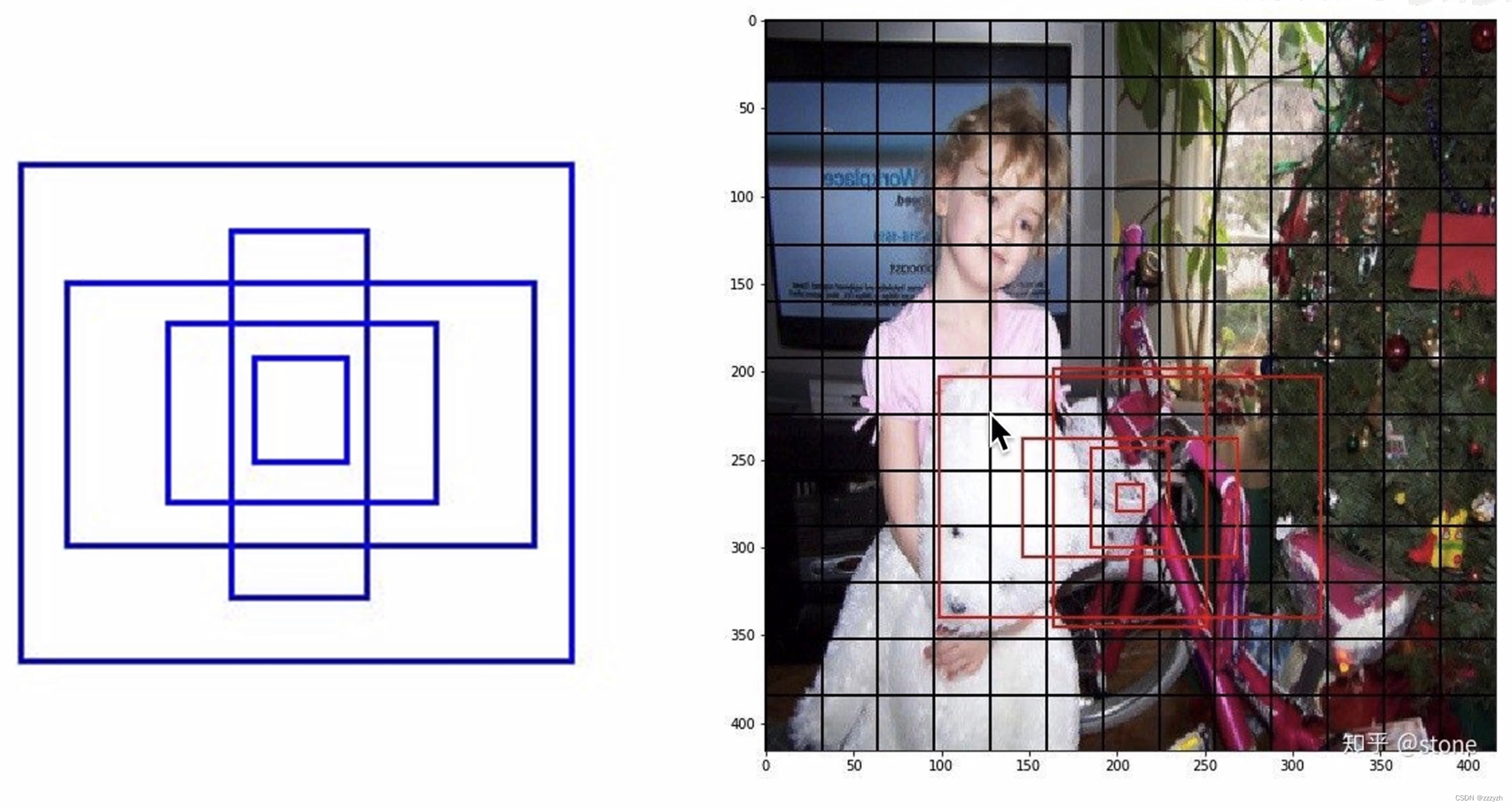
2.4. Dimension Clusters
This article no longer manually select a priori,而是在训练集边界框上运行 k-means 聚类,以自动找到好的先验.本文尝试使用With standard Euclidean distance k-means,So the larger box will generate more error smaller box.但是,We really want is to get goodIOU分数的先验,With the box box 的大小无关. 因此,对于我们的距离度量,我们使用:
d ( b o x , c e n t r o i d ) = 1 − I O U ( b o x , c e n t r o i d ) d(box, centroid) = 1 - IOU(box, centroid) d(box,centroid)=1−IOU(box,centroid)
其中,centroid 是聚类时被选作中心的边框,box 就是其它边框,d 就是两者间的距离,IOU 越大,距离越近.聚类中心越多,anchor能覆盖的 IOU 就越大,But model will become more complicated.在 model 复杂性与 high recall 之间权衡之后,选择聚类分类数 K=5.
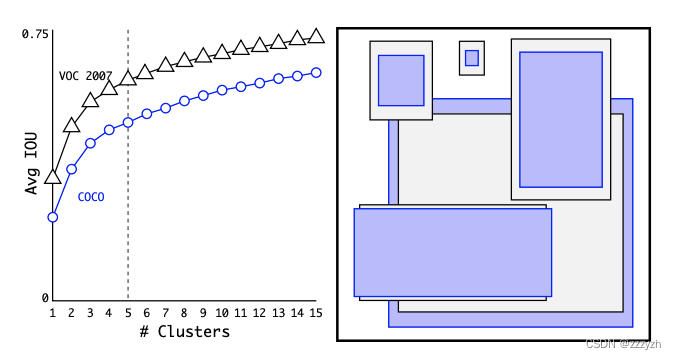
5个 anchor The aspect such as shown on the right,The black box is in PASCAL VOC 2007 上的 anchor 长宽比;Blue box is in COCO Target detection data set anchor 长宽比.
2.5. Direct location prediction
在YOLO网络中使用anchor boxes时,模型不稳定,Especially in the early iterations during.Most of the instability from the predictbox的 ( x , y ) (x, y) (x,y) 位置.在区域提议网络RPN中,网络预测值 t x t_x tx 和 t y t_y ty,并且 ( x , y ) (x, y) (x,y) 中心坐标计算为:
x = ( t x × w a ) + x a y = ( t y × h a ) + y a x = (t_x \times w_a) + x_a \\ y = (t_y \times h_a) + y_a x=(tx×wa)+xay=(ty×ha)+ya
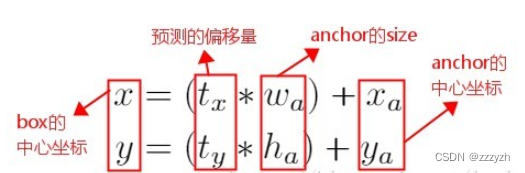
这个公式是不受约束的,因此任何anchor boxCan the image anywhere in the end,Regardless of the predictbox的位置如何.随机初始化,Model requires a long time to forecast stability to reasonable deviation.
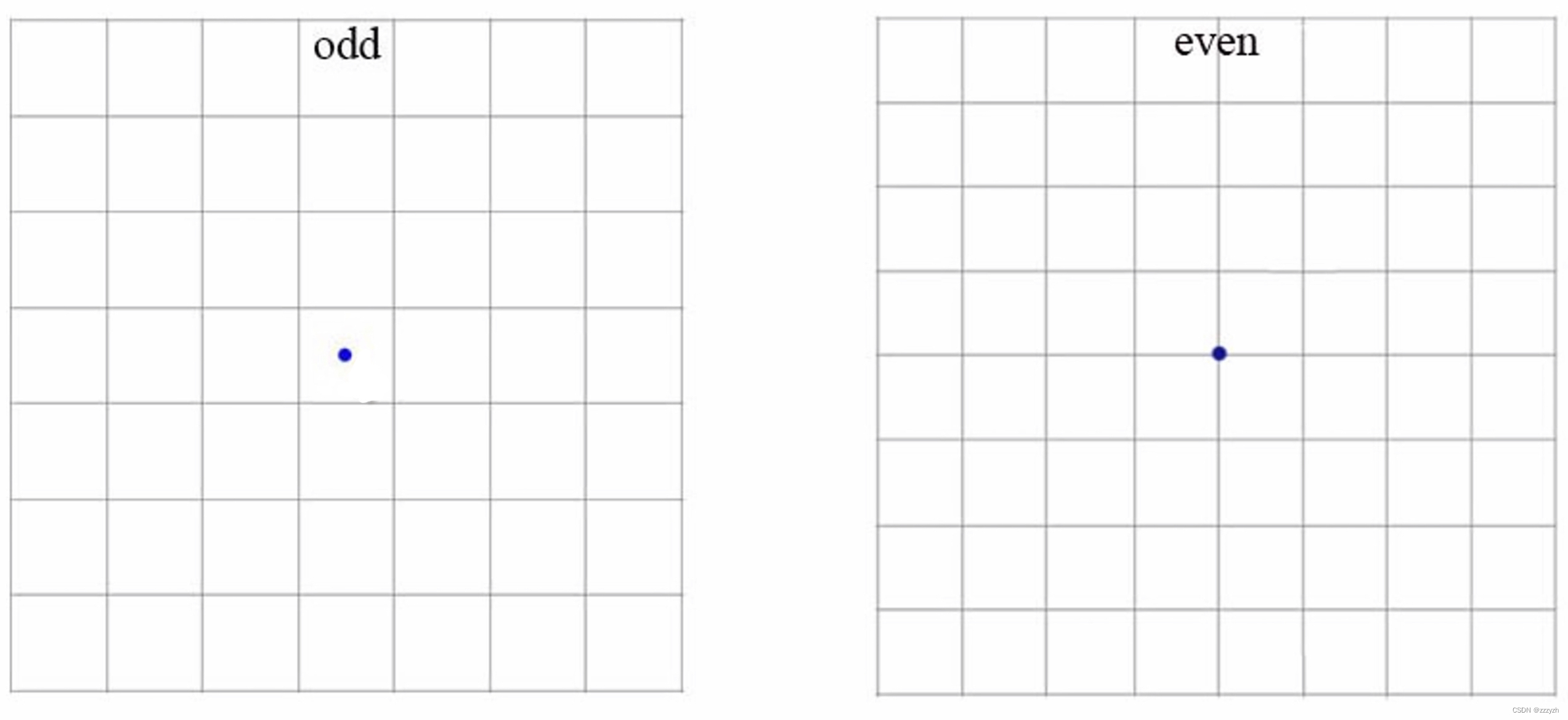
因此 YOLOv2 在此方法上进行了一点改变:预测边界框中心点相对于该网格左上角坐标 ( C x , C y ) (C_x, C_y) (Cx,Cy) 的相对偏移量,同时为了将 bounding box 的中心点约束在当前网格中,Using logical activation function sigmoid ( σ \sigma σ) To constrain network will t x , t y t_x, t_y tx,ty 进行归一化处理,将值约束在 ( 0 , 1 ) (0, 1) (0,1),这使得模型训练更稳定.
下图为 Anchor box 与 bounding box 转换示意图,其中蓝色的是要预测的bounding box,黑色虚线框是Anchor box:
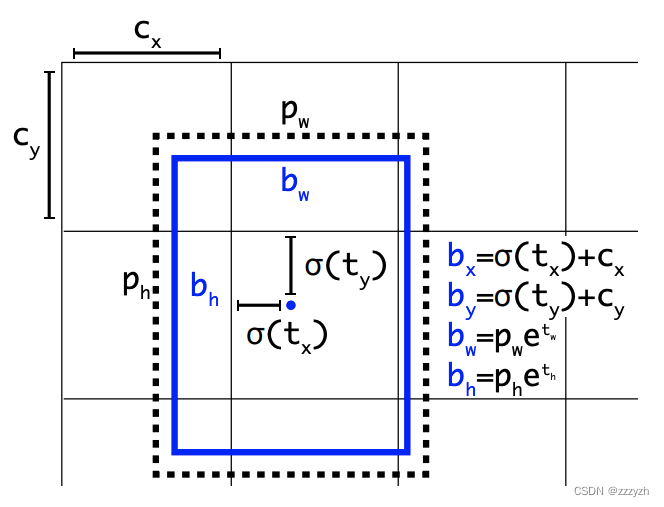
使用 sigmoid 即 σ \sigma σ 函数,Will predict box limits in the frame of the center of the grid cell 中.同时 grid cell 的大小,也归一化为 1 ∗ 1 1 * 1 1∗1
Network in the output feature map In the prediction of each cell5个边界框.网络预测每个边界框的 5 个坐标,即相对于 anchor 的偏移量, t x t_x tx, t y t_y ty, t w t_w tw, t h t_h th 和 t o t_o to.如果单元格从图像的左上角偏移 ( c x , c y ) (c_x, c_y) (cx,cy) 并且前面的 anchor 具有宽度和高度 p w p_w pw, p h p_h ph,则预测对应于:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h P r ( o b j e c t ) ∗ I O U ( b , o b j e c t ) = σ ( t o ) b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) + c_y \\ b_w = p_w e^{t_w} \\ b_h = p_h e^{t_h} \\ Pr(object) * IOU(b, object) = \sigma(t_o) bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=phethPr(object)∗IOU(b,object)=σ(to)
参数解析:
- c x c_x cx:grid cell 左上角x坐标
- c y c_y cy:grid cell 左上角y坐标
- p w p_w pw:anchor 宽度
- p h p_h ph:anchor 高度
- b x b_x bx:预测框x坐标
- b y b_y by:预测框y坐标
- b w b_w bw:预测框宽度
- b h b_h bh:预测框高度
2.6. Fine-Grained Features
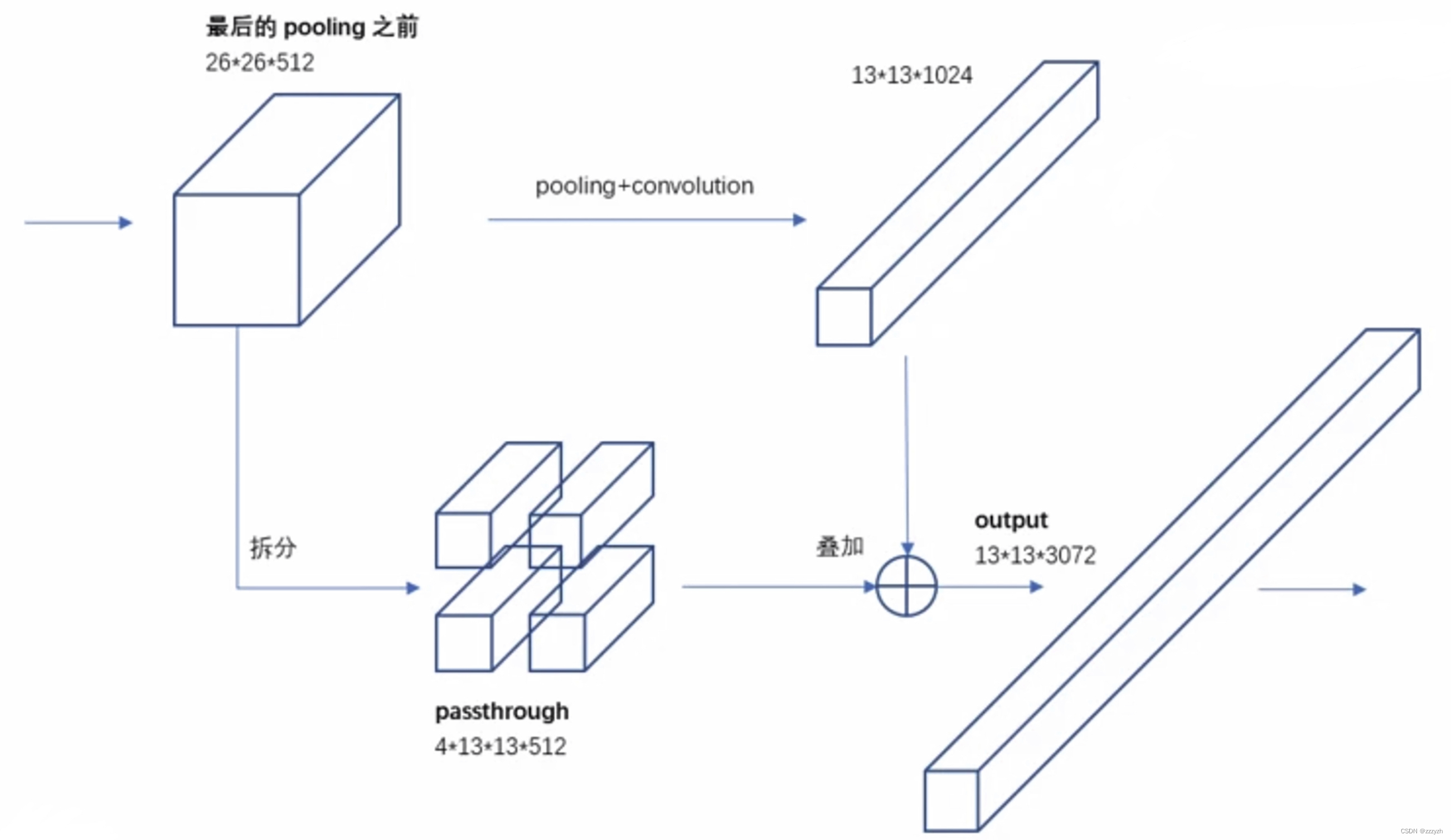
改进后的 YOLO 在 13 ∗ 13 13 * 13 13∗13 特征图上预测检测.我们采用的方法,只需添加一个直通层(passthrough layer),以 26 ∗ 26 26 * 26 26∗26 The resolution of the obtained from earlier in the feature.
Through layer by adjacent stack characteristics on different channel instead of space,Connect the characteristics of the high resolution and low resolution characteristic,类似于ResNet中的identity mappings.这将 26 ∗ 26 ∗ 512 26 * 26 * 512 26∗26∗512 特征图转换为 13 ∗ 13 ∗ 2048 13 * 13 * 2048 13∗13∗2048 特征图,可以与原始特征连接.我们的检测器运行在这个扩展的特征图之上,因此它可以访问细粒度的特征.
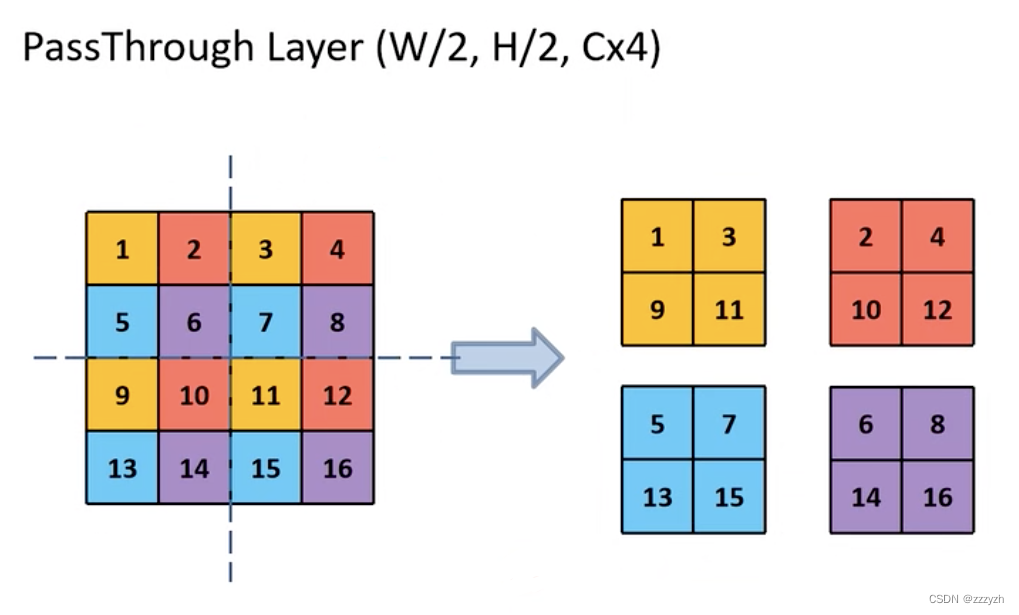
将原本的 feature map 4等分,Again from the uniform4个小 feature map The same to the new location to extract the corresponding elements feature map 中,得到了4A new small feature map And together.对应的,High and wide is the original feature map 的 1/2,The channel number is the original4倍.
2.7. Multi-Scale Training
最初的YOLOUsing the input resolution for 448 ∗ 448 448 * 448 448∗448.By adding anchor box,This article will resolution is changed to 416 ∗ 416 416 * 416 416∗416.但是,Because of this article USES the model only using convolution and pooling layer,Therefore to dynamically adjust the size.本文希望YOLOv2Able to run on the different size of image robust,So this article will be trained to the model.
We haven't fixed the size of the input image,But every few iterations change a network.每10批(batch)Our network randomly selected a new image size.As a result of our model sampling rate for 32,我们从32的倍数中提取 { 320 ; 352 ; … ; 608 } \{ 320; 352; …; 608 \} { 320;352;…;608}.因此最小的选项是 320 × 320 320 \times 320 320×320,最大的是 608 × 608 608 \times 608 608×608.We will continue to training network adjustment to this dimension and.
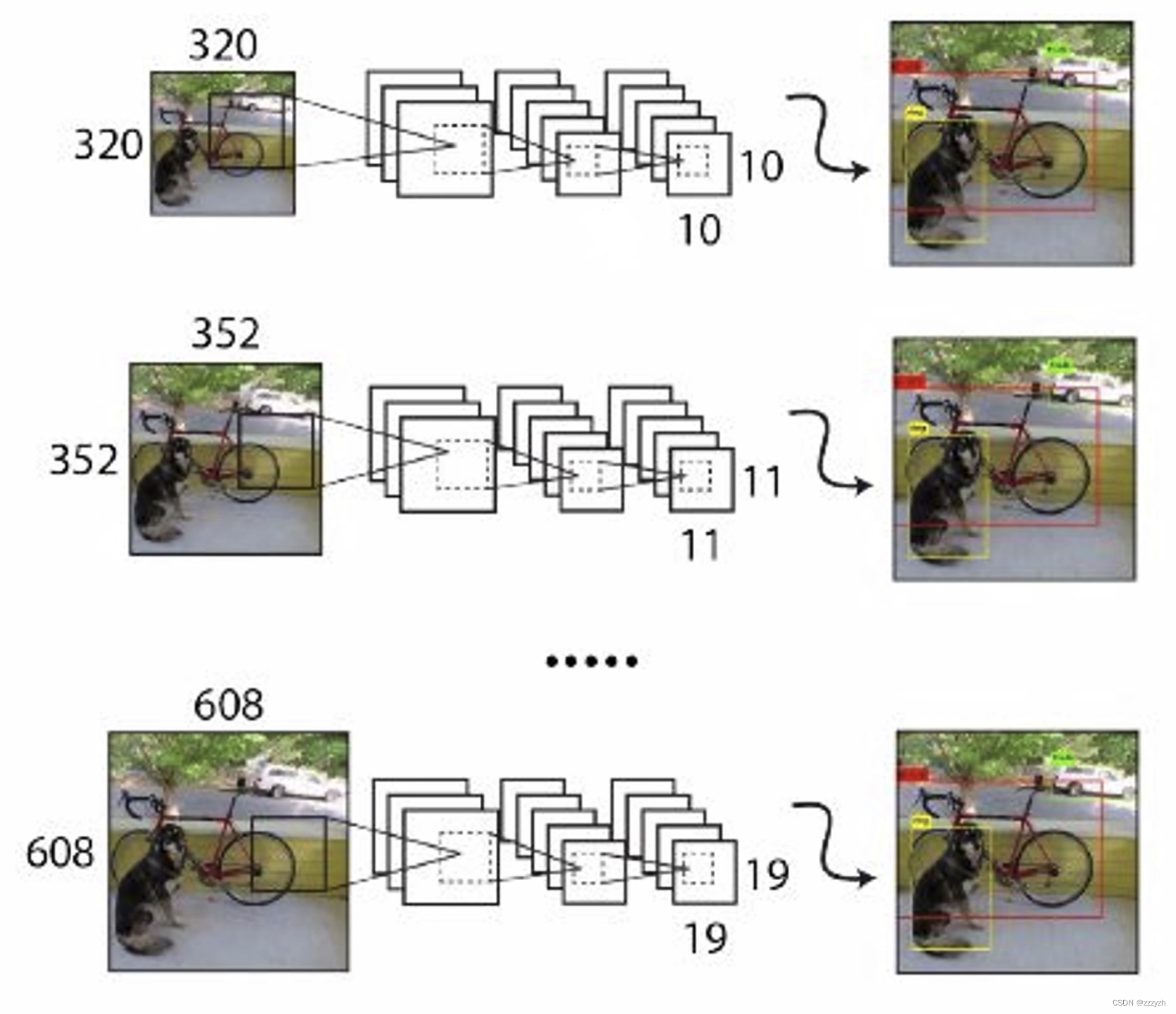
Input the picture of the small size,Prediction will soon,但精度不高;Enter the big images,Forecast will be slow,但是精度高.So can through input images of different size,To achieve speed and precision of the measure.
3. Faster
3.1. Model
3.1.1. Backbone
Darknet - 19(19个卷积层)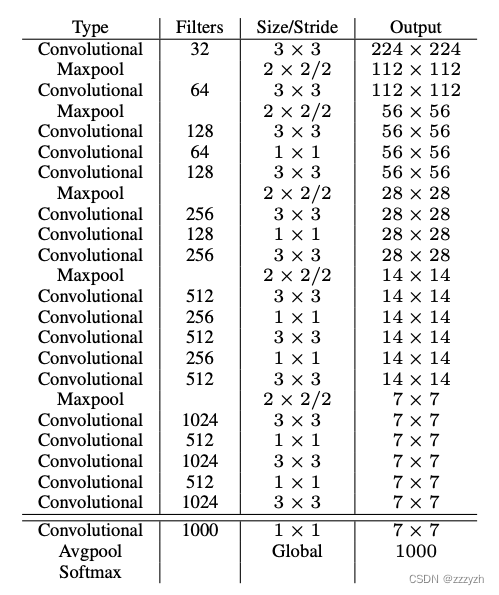
3.1.2. Training for detection
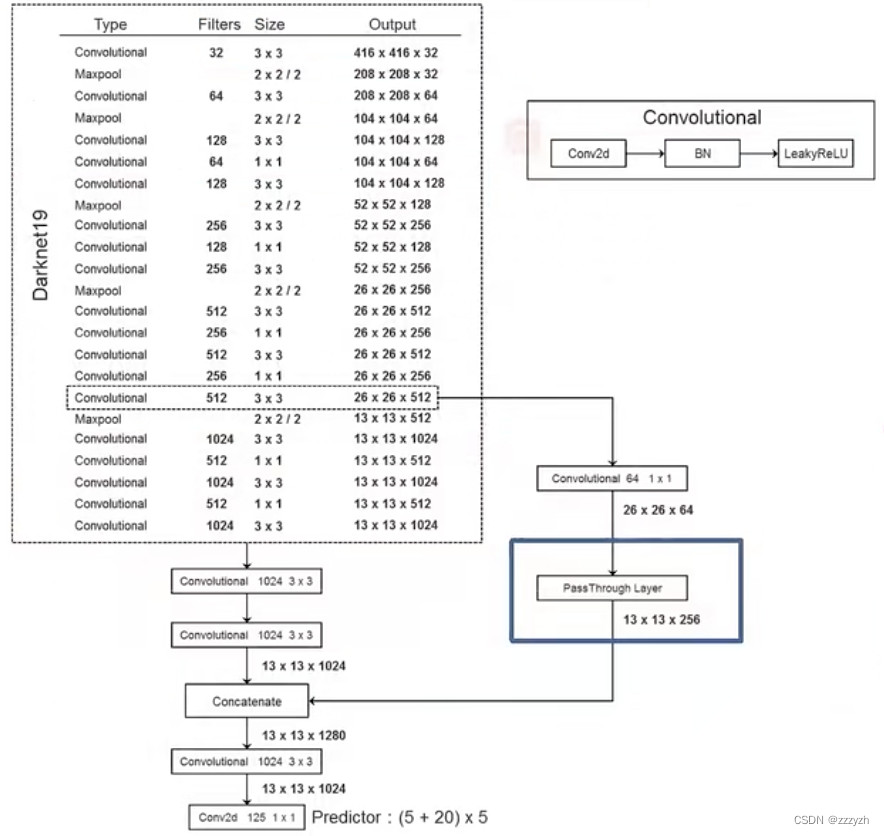
In this paper, by removing the last a convolution layer,并在三个 3 × 3 3 \times 3 3×3 Convolution layer with1024个滤波器,After each filter combined with the last one 1 × 1 1 \times 1 1×1 卷积层,Coupled with the need to detect the number of output,To modify the network for testing.
参数:
- Filters:卷积核个数
- Size:卷积核大小
- 没There are special instructions,步长=1,padding = 1
- There are special instructions,Step for the value of the corresponding
The image target in all Convolutional,All consists of three parts:
- Conv2d
- 不包含偏置
- BN
- Leaky ReLu
- 需要注意的是,最后一层的 Conv2d Does not contain other layers,Because have the effect of is full connection layer,进行分类
Pass through层
- The original does not exist 1 × 1 1 \times 1 1×1 的卷积层,Played the compression feature map 的作用
- 高宽减半,深度变为原来的4倍
- 将 pass through layer Joining together into the model in depth direction,To realize the integration of low-level features and high-level
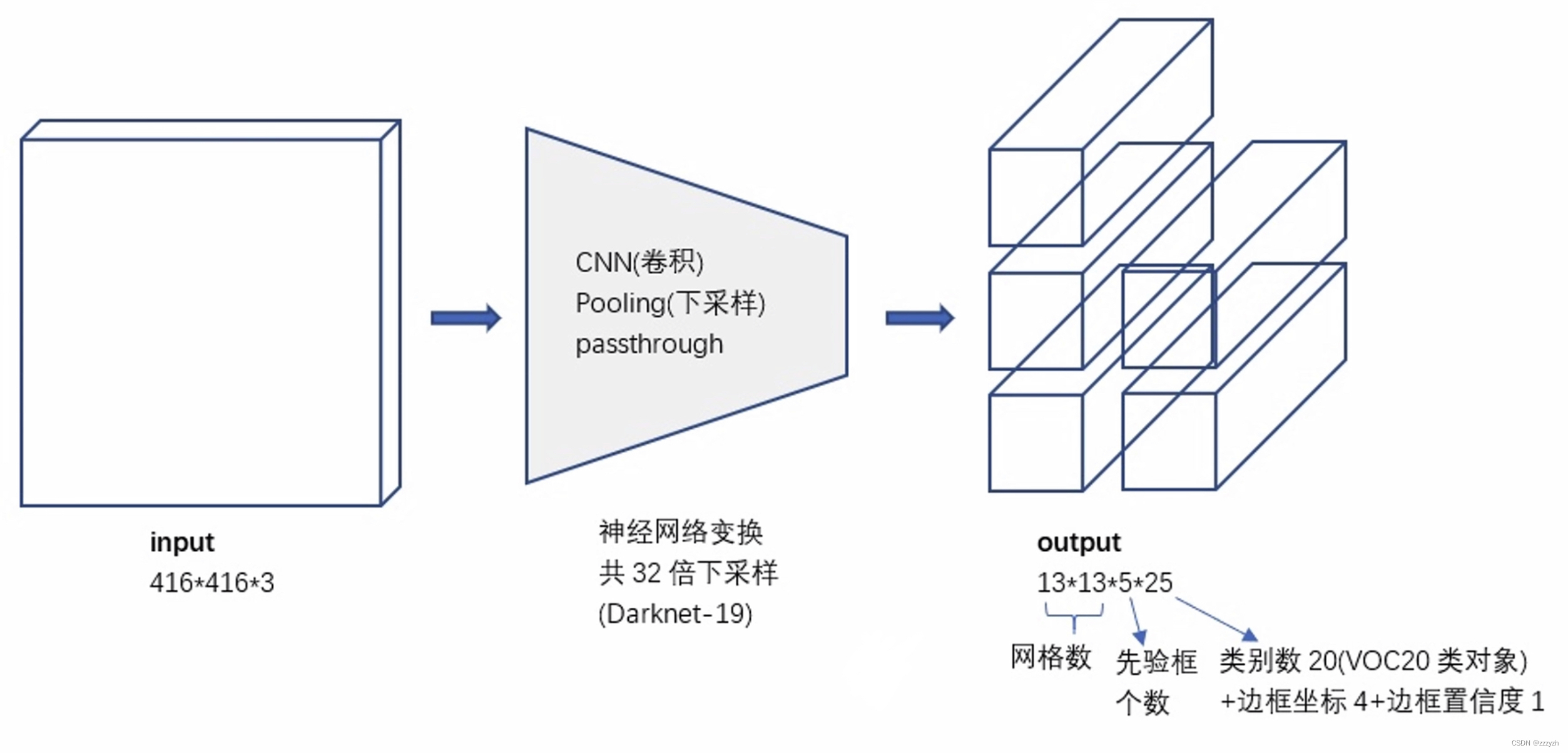
3.2. Loss
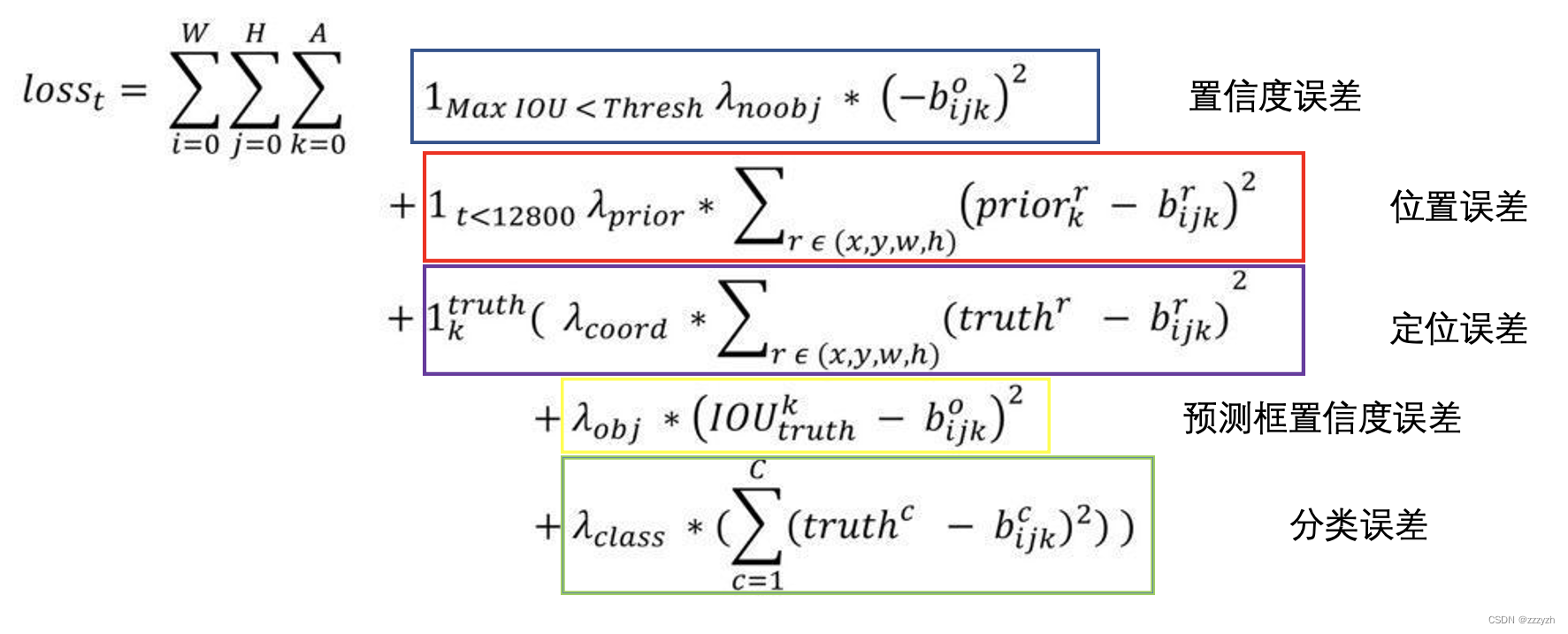
- 置信度误差
- The forecast box are corresponding background
- 越小越好
- 1 M a x ( I O U < T h r e s h ) 1_{Max(IOU < Thresh)} 1Max(IOU<Thresh)
- 非0即1:是否与 GT box 的 I O U < 0.6 IOU < 0.6 IOU<0.6
- IOU计算法:将Anchor与 GT box中心点重合
- 位置误差
- 预测框与 anchor 位置误差,Make the model more quickly learn to predict anchor 位置
- 1 t < 12800 1_{t<12800} 1t<12800
- 非0即1:Whether it is before12800次迭代
- Is responsible for the predicted object forecast of box
- 1 k t r u t h 1_k^{truth} 1ktruth
- 非0即1:Predict whether frame prediction objects
- 该 anchor 与 GT box 的 IOU Forecast the biggest box is responsible for the predicted object
- I O U > 0.6 IOU > 0.6 IOU>0.6 But the biggest forecast box,Ignore the loss
- 定位误差
- 标注框位置 - 预测框位置
- 置信度误差
- anchor与标注框的IOU - 预测框置信度
- 分类误差
- 标注框类别 - 预测框类别
- 1 k t r u t h 1_k^{truth} 1ktruth
总结
总的来说,YOLO2通过一些改进明显提升了预测准确性,同时继续保持其运行速度快的优势.YOLO9000则开创性的提出联合使用分类样本和检测样本的训练方法,使对象检测能够扩展到缺乏检测样本的对象
边栏推荐
- Oreo域名授权验证系统v1.0.6公益开源版本网站源码
- win10 uwp use WinDbg to debug
- Win10 uwp use ScaleTransform magnify an element
- Comic | Two weeks after the boss laid me off, he hired me back and doubled my salary!
- Web3时代的战争
- About the state transfer problem of SAP e-commerce cloud Spartacus UI SSR
- Data warehouse (1) What is data warehouse and what are the characteristics of data warehouse
- How to understand the crawler's Scrapy framework in the simplest and most popular way?
- 经验分享|盘点企业进行知识管理时的困惑类型
- Using Baidu EasyDL to realize forest fire early warning and identification
猜你喜欢
LINQ to SQL (Group By/Having/Count/Sum/Min/Max/Avg操作符)
![[2022 Hangzhou Electric Multi-School 5 1003 Slipper] Multiple Super Source Points + Shortest Path](/img/78/054329dec6a6faea5e9d583b6a8da5.png)
[2022 Hangzhou Electric Multi-School 5 1003 Slipper] Multiple Super Source Points + Shortest Path

【C语言】指针和数组的深入理解(第三期)
SAP ABAP OData 服务如何支持 $select 有选择性地仅读取部分模型字段值试读版
【数据挖掘】搜狐公司数据挖掘工程师笔试题
模拟对抗之红队免杀开发实践

面试官:Redis中过期的key是怎么被删除的?
Tear down the underlying mechanism of the five JOINs of SparkSQL

经验分享|盘点企业进行知识管理时的困惑类型

for 循环中的 ++i 与 i++
随机推荐
手撕SparkSQL五大JOIN的底层机制
Interviewer: How is the expired key in Redis deleted?
伺服电机矢量控制原理与仿真(1)控制系统的建立
拼多多开放平台订单信息查询接口【pdd.order.basic.list.get订单基础信息列表查询接口(根据成交时间)】代码对接教程
动态规划_双数组字符串
该如何训练好深度学习模型?
模拟对抗之红队免杀开发实践
如何用好建造者模式
深度解析:为什么跨链桥又双叒出事了?
【一起学Rust | 进阶篇 | Service Manager库】Rust专用跨平台服务管理库
C语言之实现扫雷小游戏
【随记】新一天搬砖 --20220727
[TypeScript] In-depth study of TypeScript enumeration
PowerCLi 导入License到vCenter 7
js数据类型、节流/防抖、点击事件委派优化、过渡动画
MySQL field type
buu web
proe和creo的区别有哪些
【学术相关】清华教授发文劝退读博:我见过太多博士生精神崩溃、心态失衡、身体垮掉、一事无成!...
拒绝服务攻击DDoS介绍与防范