当前位置:网站首页>Explain of SQL optimization
Explain of SQL optimization
2022-07-04 14:29:00 【Dying fish】
explain
id
id The number of the column is select The serial number of , Just look up a few tables id, also id The higher the value, the higher the execution priority . If id Same value , Just execute from top to bottom , Finally, execute id by null Of .
select_type
Query type , There are several values as follows 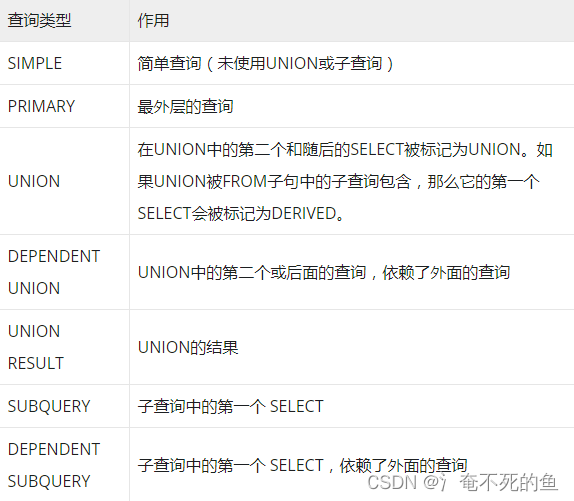
Raise a point SUBQUERY Query depends on external examples
explain select * from (select erp_travel.*,erp_travel_detail.destination from erp_travel left join erp_travel_detail on erp_travel.travel_no = erp_travel_detail.travel_no ) erp_travel
where erp_travel.travel_no in (
select max(erp_travel_cost.travel_no) from erp_travel_cost where erp_travel_cost.project_no = erp_travel.project_no
)
limit 1
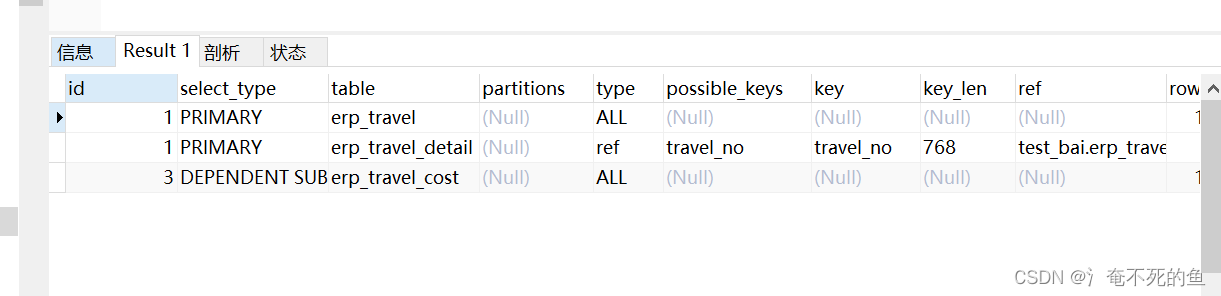
Parse the query process
1. See the execution sequence, execute first id by 3 Subquery of , Check the whole table directly , Full table IO
2. Query the data results of external query , Match the results of sub query row by row . External query Query the largest according to the conditions one by one travel_no
3. We know the Cartesian product of self query matching , namely primar Of size ride subquery Of size, If the data volume of the two queries is only over 10000 respectively , Then the number of cycles will be more than 100 million . therefore DEPENDENT SUBQUERY Try to avoid , Once it appears, there is basically no way to use sql.
SUBQUERY Example
Remove the association conditions in the sub query and the external query
explain select * from (select erp_travel.*,erp_travel_detail.destination from erp_travel left join erp_travel_detail on erp_travel.travel_no = erp_travel_detail.travel_no ) erp_travel
where erp_travel.travel_no in (
select max(erp_travel_cost.travel_no) from erp_travel_cost where erp_travel_cost.is_manage is not null
)
limit 1;
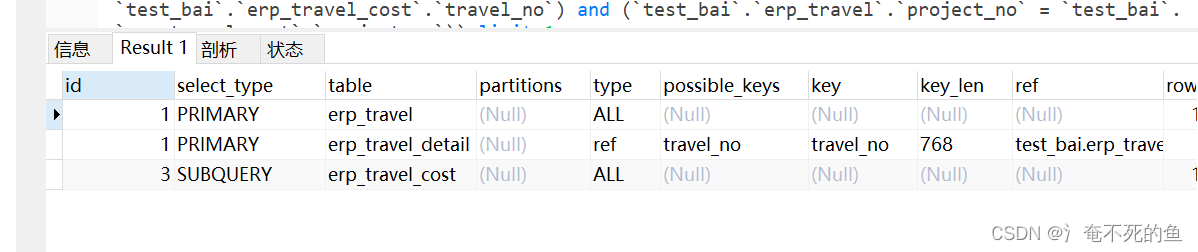
SUBQUERY The speed of execution is very fast , Because the subquery is only executed once , Generate a record , It is not associated with external query . There is no Cartesian product loop matching process at all .
What happens if it is an ordinary subquery
Aggregate subqueries max Get rid of , avoid DEPENDENT SUBQUERY
explain select * from (select erp_travel.*,erp_travel_detail.destination from erp_travel left join erp_travel_detail on erp_travel.travel_no = erp_travel_detail.travel_no ) erp_travel
where erp_travel.travel_no in (
select erp_travel_cost.travel_no from erp_travel_cost where erp_travel_cost.project_no = erp_travel.project_no
)
limit 1
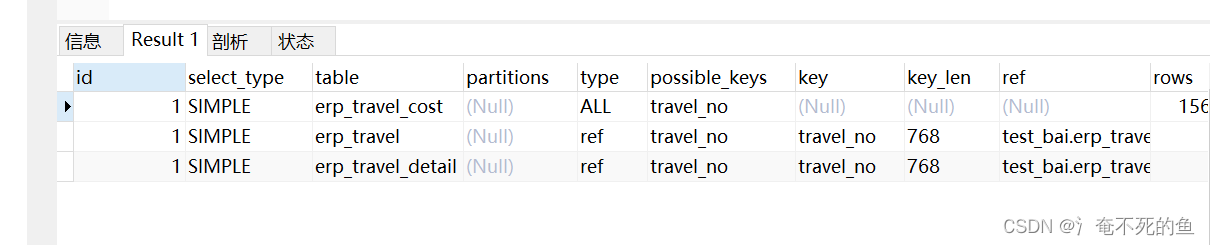
Why is this query so fast , Let's analyze
after sql Optimizer optimization , It can be seen that the subquery has been optimized into a join query 
Why turn subquery into associated query ?
We know that subquery means the Cartesian product of external query and internal query , What about connection query . The connection method used for connection query is Nest Loop Join, For internal connections , Automatic optimization drives large tables for small tables
1. Subquery erp_travel_cost Full table IO Find out the results , As a driving table
2. Use join buffer Batch query the query result set outside the connection .
because peoject_no It's not an index , Both watches have 15w Left and right data , So this whole table connection , It must be a disaster . It's almost impossible to get the result
table
Indicates which table this row is accessing , If SQL It defines the alias , And show the alias of the table
partitions
The partition of the current query matching record . For tables that are not partitioned , return null
When partitioning, different data will be divided into corresponding blocks , In this way, the size of each piece becomes smaller , To speed up the IO Speed
Understand what partitions are MySQL Table partitioning ? Knowledge is up !
type
| ALL | Full table scan
| index | Index full scan
| range | Index range scan , Common words <,<=,>=,between Wait for the operation
| ref | Use non unique index Scan or unique index prefix scan , Returns a single record , It often appears in association queries
| eq_ref | similar ref, The difference is that you use a unique index , Use primary key Association query
| const/system | single record , Other columns in the matching row are treated as constants , Such as primary key or unique index query
| null | MySQL Do not access any tables or indexes , Direct return
ALL Full table scan
When the query condition has no index, you can go , Then it's the whole table io
explain select * from erp_travel_cost where is_manage is null

The least efficient
INDEX Index full table scan
explain select project_no from erp_travel_cost ; -- all
explain select travel_no from erp_travel_cost -- index

index: Full Index Scan, index And ALL The difference for index Type only traverses the index tree . This is usually better than ALL fast , Because index files are usually smaller than data files .( That is to say, although all and index Read the whole watch , but index It's read from the index , and all It's read from the hard disk )
index It refers to scanning the full index , And there is no need to return the table , Or directly check the primary key index , Or directly check the secondary index
RANGE
- range: Retrieve only rows in the given range , Use an index to select rows .key Column shows which index is used
It's usually in your where In the sentence between、<、>、in And so on
This range scan index scan is better than full table scan , Because he just needs to start indexing at a certain point , And the conclusion is another point , Don't scan all indexes
First range The requirement is to specify the range of the index , For non index, it must be a full table
explain select * from erp_travel_cost where erp_travel_cost.create_time > '2022-01-01 00:00:00' -- all
explain select * from erp_travel_cost where travel_no> '2' --range

Because the index has its own order , It's easy to use B+ The tree determines the index range , If you need to return the form , Then the returned data from the index will be returned to the table for query according to the primary key , If there is a lot of data in the back table , In addition, the index also needs Io, Therefore, when the range is large, the full table query will be used directly
ref
- ref: Non unique index scan , Returns a match All rows of individual values .
In essence, it is also an index access , It returns all rows that match a single value , However ,
It may find more than one eligible row , So it should be a mixture of search and scan
explain select * from erp_travel_cost where travel_no = ( '1000127141') -- ref
explain select * from erp_travel_cost where travel_no in( '1000127141','1000127142') --range
eq_ref
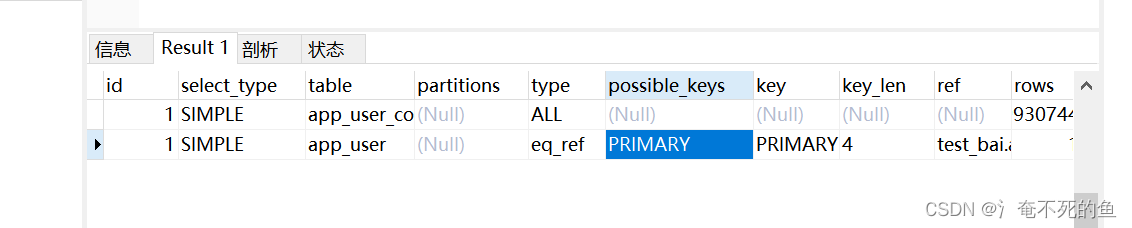
Read a row composed of each row in this table and the associated table . except 了 system and const Out of type , This is the best connection type . When links use all parts of the index , Index is primary key or unique non NULL When indexing , This value will be used .
eq_ref Available for use = Index column for operator comparison . The comparison value can be a constant or an expression of a column in a table previously read using this table . In the following example , MySQL Able to use eq_ref link (join)ref_table To deal with it :ui
explain select * from app_user_copy1 left join app_user on app_user.id = app_user_copy1.id
const
Indicates that it is found through index once ,const For comparison primary key perhaps unique Indexes . Because only one line of data is matched , So soon . If the primary key is set to where In the list ,MySQL You can convert the query to a constant
system
- system: There is only one line in the table ( It's equal to the system table ), This is a const Special case of type , Not usually , This can also be ignored
index_merge
But my question today is , Two different secondary index trees , Will it take effect at the same time ? In theory , It should be effective at the same time , Otherwise, this MySQL It's stupid . It basically happens in or Conditionally
explain select * from erp_travel where project_no_form = 'A21020028' or user_no ='00022139'

The indexes of both columns will be used
possible_keys
MYSQL The optimizer will find all the solutions that can be used to execute the statement , And after comparing these schemes, find out the scheme with the lowest cost . Here we will list the indexes that may be used
Show the indexes that may be applied to this table , One or more . If there is an index on the field involved in the query , Then the index will be listed , But it doesn't have to be actually used by the query .
key
Possible to use key There are many. , But the optimizer will choice Index to query , You don't have to choose only one index index_merge
key The list shows the index names that the query optimizer decides to use after calculating the cost of using different indexes , That is, the index column actually used . If null No index is used .
If an overlay index is used in the query , Then index and query select Fields overlap
key_len
key_len The list shows when the optimizer decides to execute a query using an index , The maximum length of the index record , It consists of these three parts :
① For index columns with fixed length types , The maximum length of the storage space actually occupied by it is the fixed value , For variable length index columns of the specified character set , For example, the type of an index column is varchar(255), The character set used is utf8(MySQL utf8 Character set usage 3 Byte length ), Then the maximum storage space actually occupied by this column is 255 × 3 + 2= 767 Bytes .
② If the index column can store NULL value , be key_len Can't store NULL When the value is more 1 Bytes by 758.
③ For variable length words (varchar) For example , There will be 2 A space of bytes to store the actual length of the variable length column .
The union index can also be through key_len You can see how many columns of joint indexes are used , The more columns you use , You can filter more by index , Reduce io frequency
explain select * from erp_travel where user_no = '00022139' -- key_len 768
explain select * from erp_travel where user_no = '00022139' and user_name = '00022139' --key_len 1536
explain select * from erp_travel where user_no = '00022139' and user_name = '00022139' and creater = '00022139' --key_len 2304
ref
When a query is executed using the condition of index column equivalence matching , That is, the access method is const、eq_ref、ref、ref_or_null、unique_subquery、index_subquery One of them ,ref The column shows the conditions for equivalent matching with the index column , Such as a constant or a column .
explain select * from erp_travel where user_no ='00022139'

Here is the index column student_name What makes equivalence matching is a specific string , Is constant , therefore ref This column shows const
explain select erp_travel.*,erp_travel_detail.destination from erp_travel left join erp_travel_detail on erp_travel.travel_no = erp_travel_detail.travel_no

erp_travel_detail When doing equivalent matching erp_travel Of travel_no Field , So here it shows erp_travel.travel_no
rows
According to table statistics and index selection , Roughly estimate the number of rows to read to find the required record . This can be regarded as the most important indicator , Because the ultimate goal of all optimization is to reduce the number of lines scanned at last , That is to reduce rows This value .
rows How exactly is it calculated ?
This rows The explanation in the official website document is as follows :
“
rows (JSON name: rows)
The rows column indicates the number of rows MySQL believes it must examine to execute the query.
For [InnoDB] tables, this number is an estimate, and may not always be exact.
http://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain_rows
A simple translation is : This method is only based on the given conditions about the index and the index itself , To determine how many lines need to be scanned .
summary
MySQL Explain Inside rows This value
- yes MySQL The number of lines that it is supposed to check ( Just for your reference ), Not the number of rows in the result set ;
- meanwhile SQL Inside LIMIT It has nothing to do with this .
in addition , Many optimization methods , For example, association buffer and query cache , Can't affect rows Display of .MySQL Maybe you don't have to really read all the lines it estimates , It also doesn't know any information about the operating system or hardware cache .
This rows The value of index is to see the role of index in query , Is it reasonable? Only make a rough estimation based on the index of query or connection conditions . If there is no index, it must be valued as a full table , Even with Limit
explain select erp_travel.*,erp_travel_detail.destination from erp_travel left join erp_travel_detail on erp_travel.travel_no = erp_travel_detail.travel_no

First erp_travel As a driving table , A full table query , Estimate rows Is the number of rows in the whole table
Then according to the index connection conditions ,travel_no Connect erp_travel_detail, Estimate according to the index , Only one row of data is needed to match the index , But it must be more than that ,
filtered
MySql explain In the return result of the statement ,filtered How to understand fields ?
MySql5.7 The official documents are as follows :
The filtered column indicates an estimated percentage of table rows filtered by the table condition. The maximum value is 100, which means no filtering of rows occurred. Values decreasing from 100 indicate increasing amounts of filtering. rows shows the estimated number of rows examined and rows × filtered shows the number of rows joined with the following table. For example, if rows is 1000 and filtered is 50.00 (50%), the number of rows to be joined with the following table is 1000 × 50% = 500.
This passage is not easy to understand , for instance , There are three query statements explain result , in the light of b and c The display of the table filtered yes 100, And for the a The display of the table is 18.
+-------------+-------+--------+---------+---------+------+----------+
| select_type | table | type | key | key_len | rows | filtered |
+-------------+-------+--------+---------+---------+------+----------+
| PRIMARY | a | range | search | 4 | 174 | 18.00 |
| PRIMARY | b | eq_ref | PRIMARY | 4 | 1 | 100.00 |
| PRIMARY | c | ALL | PRIMARY | 4 | 1 | 100.00 |
How can we understand filtered The value of ? from filtered What conclusion can be drawn from the value of ? What is the 100 Better still 18 Better ?
First , there filtered Indicates the number of final record lines obtained by query criteria type The percentage of record lines searched by the search method indicated in the field .
The first statement in the figure above is an example ,MySQL First use the index ( there type yes range) Scan table a, Expected to receive 174 Bar record , That is to say rows Number of records displayed in column . Next MySql Additional query criteria will be used for this 174 Line records are filtered twice , Finally, we get 32 Bar record , That is to say 174 Bar record 18%. and 18% Namely filtered Value .
In a more perfect situation , It should use an index , Direct search 32 Records and filter out other 82% The record of .
So one is lower filtered Value indicates that a better index is needed , If type=all, It means to get by full table scanning 1000 Bar record , And filtered=0.1%, Only 1 Records match the search criteria . At this point, if you add an index, you can search it directly 1 Data , that filtered Can be promoted to 100%.
thus it can be seen ,filtered=100% It's really better than 18% It is better to .
Of course ,filtered Not everything , It is more important to focus on the values of other columns in the execution plan results and optimize the query . For example, in order to avoid filesort( Use can satisfy order by The index of ), Even if filtered There is no problem that the value of is low . Another example is above filtered=0.1% Scene , We should pay more attention to adding an index to improve query performance , Instead of looking at filtered Value .
Extra
Extra Columns are used to illustrate some additional information , We can use this additional information to understand more accurately MySQL How the given query statement will be executed .MySQL Dozens of additional information were provided , Not one by one , Here are some common additional information descriptions .
① Using filesort: If you sort by index column (order by Index columns ) Index can be used ,SQL The query engine will first sort according to the index column , Then get the primary key of the corresponding record id Perform a return operation , If the sorting field does not use an index, it can only be sorted in memory or disk ,MySQL This method of sorting in memory or on disk is collectively referred to as file sorting ( English name :filesort), If a query needs to be executed by file sorting , Will be carrying out the plan Extra Column shows Using filesort
explain select * from erp_travel_detail order by travel_no limit 1000

Sort by index , Generally not used filesort But if the amount of data is large , Will not take the miniature
hold 1000 Change to 10000
explain select * from erp_travel_detail order by travel_no limit 10000

Even follow up index sorting , Still using filesort
② Using temporary
Using temporary Indicates that there is no index due to sorting 、 Use union、 Subquery join query 、 Use some views and other reasons ( See internal-temporary-tables), Therefore, an internal temporary table is created . Note that the temporary table here may be a temporary table in memory , It may also be a temporary table on the hard disk , Of course, the time consumption of memory based temporary tables is certainly smaller than that of hard disk based temporary tables .
The temporary table is also easy to understand , According to sql Deal with a result first , According to this result, we can get the final result . Then the intermediate result is the intermediate table
mysql> show global status like '%tmp%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Created_tmp_disk_tables | 0 |
| Created_tmp_files | 5 |
| Created_tmp_tables | 11 |
+-------------------------+-------+
3 rows in set
explain select updater from erp_travel
group by updater

explain select travel_no from erp_travel
group by travel_no
Go to the index . Index comes with order , Directly according to the index, you can group on an orderly basis , Instead of sorting , Create a temporary table 
explain select distinct updater from erp_travel;
Non index , Created a temporary table 
explain select distinct updater from erp_travel where updater = '00022139';

There is no need to establish a temporary table for processing with a small amount of data
explain select distinct creater from erp_travel

For federated indexes , Even if it does not match the leftmost match , This can also be reduced by indexing io frequency .
③ USING index: It means corresponding select The override index is used in the operation (Covering Index), Avoid the operation of returning tables , Good efficiency !
If it appears at the same time using where, Indicates that the index is used to perform index key value lookups ; If not at the same time using where, The table name index is used to read data rather than perform lookup actions .
④ Using where: Used where Filter
⑤ using join buffer: During the execution of the join query , When the driven table can not effectively use the index to speed up the access speed ,MySQL It's usually allocated a piece called join buffer To speed up the query
explain select erp_travel.*,erp_travel_detail.destination from erp_travel left join erp_travel_detail on erp_travel.user_no = erp_travel_detail.creater

The connection condition is not an index ( use join buffer)
⑥ impossible where: where The value of the clause is always false, Can't be used to get any tuples
⑦ select tables optimized away: In the absence of GROUPBY In the case of clause , Index based optimization MIN/MAX Operation or for MyISAM Storage engine optimization COUNT(*) operation , You don't have to wait until the execution phase to do the calculation , The query execution plan generation phase completes the optimization .
explain select max(travel_no) from erp_travel

⑧ distinct: Optimize distinct, Stop looking for the same value after finding the first matching tuple
⑨ Using index condition: Search uses index , But you need to return the table to query the data
explain select * from erp_travel_cost where travel_no in( '1000127141','1000127142')

边栏推荐
- 尊重他人的行为
- Stm32f1 and stm32subeide programming example -max7219 drives 8-bit 7-segment nixie tube (based on GPIO)
- Industrial Internet has greater development potential and more industry scenarios
- GCC [6] - 4 stages of compilation
- R language uses the DOTPLOT function of epidisplay package to visualize the frequency of data points in different intervals in the form of point graph, and uses the by parameter to specify the groupin
- Test evaluation of software testing
- Some problems and ideas of data embedding point
- 利用Shap值进行异常值检测
- Abnormal value detection using shap value
- Nowcoder rearrange linked list
猜你喜欢
Excel quickly merges multiple rows of data
统计php程序运行时间及设置PHP最长运行时间

软件测试之测试评估
聊聊保证线程安全的 10 个小技巧

测试流程整理(3)
Map of mL: Based on Boston house price regression prediction data set, an interpretable case of xgboost model using map value
Vscode common plug-ins summary
Count the running time of PHP program and set the maximum running time of PHP

Oppo find N2 product form first exposure: supplement all short boards

leetcode:6110. 网格图中递增路径的数目【dfs + cache】
随机推荐
Ws2818m is packaged in cpc8. It is a special circuit for three channel LED drive control. External IC full-color double signal 5v32 lamp programmable LED lamp with outdoor engineering
Industrial Internet has greater development potential and more industry scenarios
10.(地图数据篇)离线地形数据处理(供Cesium使用)
R language uses the mutation function of dplyr package to standardize the specified data column (using mean function and SD function), and calculates the grouping mean of the standardized target varia
Practical puzzle solving | how to extract irregular ROI regions in opencv
leetcode:6110. 网格图中递增路径的数目【dfs + cache】
leetcode:6110. The number of incremental paths in the grid graph [DFS + cache]
R语言使用dplyr包的group_by函数和summarise函数基于分组变量计算目标变量的均值、标准差
How to operate and invest games on behalf of others at sea
海外游戏代投需要注意的
Test evaluation of software testing
Nowcoder reverse linked list
Xcode 异常图片导致ipa包增大问题
R language uses dplyr package group_ The by function and the summarize function calculate the mean and standard deviation of the target variables based on the grouped variables
Leetcode 61: rotating linked list
Learn kernel 3: use GDB to track the kernel call chain
测试流程整理(3)
【云原生】我怎么会和这个数据库杠上了?
MySQL triggers
R语言使用epiDisplay包的followup.plot函数可视化多个ID(病例)监测指标的纵向随访图、使用stress.col参数指定强调线的id子集的颜色(色彩)