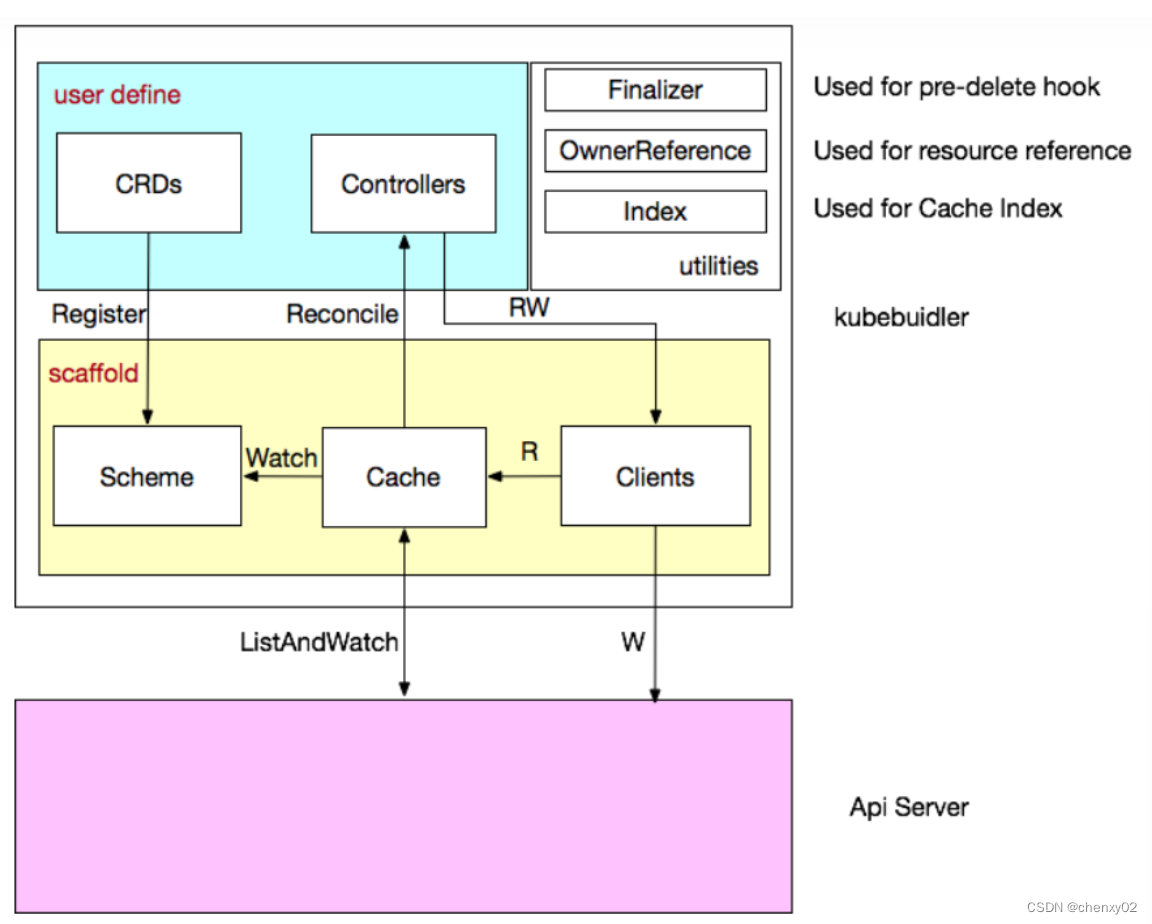
Learning rate is a crucial parameter in deep learning training , Most of the time, a proper learning rate can give full play to the great potential of the model . So the learning rate adjustment strategy is also very important , This blog introduces Pytorch Common learning rate adjustment methods in .
import torch
import numpy as np
from torch.optim import SGD
from torch.optim import lr_scheduler
from torch.nn.parameter import Parameter
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, lr=0.1)
The above is a general code , Here, set the basic learning rate to 0.1. Next, just show the code of the learning rate regulator , And the corresponding learning rate curve .
1. StepLR
This is the simplest and most commonly used learning rate adjustment method , every step_size round , Multiply the previous learning rate by gamma.
scheduler=lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)

2. MultiStepLR
MultiStepLR It is also a very common learning rate adjustment strategy , It will be in every milestone when , Multiply the previous learning rate by gamma.
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[30,80], gamma=0.5)

3. ExponentialLR
ExponentialLR It is a learning rate regulator with exponential decline , Each round will multiply the learning rate by gamma, So pay attention here gamma Don't set it too small , Otherwise, the learning rate will drop to 0.
scheduler=lr_scheduler.ExponentialLR(optimizer, gamma=0.9)

4. LinearLR
LinearLR Is the linear learning rate , Given start factor And finally factor,LinearLR Will do linear interpolation in the intermediate stage , For example, the learning rate is 0.1, start factor by 1, The final factor by 0.1, So the first 0 Sub iteration , The learning rate will be 0.1, The final round learning rate is 0.01. The total number of rounds set below total_iters by 80, So over 80 when , The learning rate is constant 0.01.
scheduler=lr_scheduler.LinearLR(optimizer,start_factor=1,end_factor=0.1,total_iters=80)

5. CyclicLR
scheduler=lr_scheduler.CyclicLR(optimizer,base_lr=0.1,max_lr=0.2,step_size_up=30,step_size_down=10)
CyclicLR There are more parameters for , Its curve looks like continuous uphill and downhill ,base_lr For the learning rate at the bottom ,max_lr For the peak learning rate ,step_size_up It is the number of rounds needed from the bottom to the top ,step_size_down The number of rounds from the peak to the bottom . As for why it is set like this , You can see The paper , In short, the best learning rate will be base_lr and max_lr,CyclicLR Instead of blindly declining, the process of increasing is to avoid falling into the saddle point .
scheduler=lr_scheduler.CyclicLR(optimizer,base_lr=0.1,max_lr=0.2,step_size_up=30,step_size_down=10)

6. OneCycleLR
OneCycleLR As the name suggests, it's like CyclicLR One cycle version of , It also has multiple parameters ,max_lr Is the maximum learning rate ,pct_start Is the proportion of the rising part of the learning rate , The initial learning rate is max_lr/div_factor, The final learning rate is max_lr/final_div_factor, The total number of iterations is total_steps.
scheduler=lr_scheduler.OneCycleLR(optimizer,max_lr=0.1,pct_start=0.5,total_steps=120,div_factor=10,final_div_factor=10)

7. CosineAnnealingLR
CosineAnnealingLR Is the cosine annealing learning rate ,T_max It's half the cycle , The maximum learning rate is optimizer It is specified in , The minimum learning rate is eta_min. This can also help escape the saddle point . It is worth noting that the maximum learning rate should not be too large , otherwise loss There may be sharp fluctuations up and down in cycles similar to the learning rate .
scheduler=lr_scheduler.CosineAnnealingLR(optimizer,T_max=20,eta_min=0.05)

7. CosineAnnealingWarmRestarts
Here is relatively responsible , The formula is as follows , among T_0 It's the first cycle , From optimizer The learning rate in fell to eta_min, Each subsequent cycle becomes the previous cycle multiplied by T_mult.
\(eta_t = \eta_{min} + \frac{1}{2}(\eta_{max} - \eta_{min})\left(1 +
\cos\left(\frac{T_{cur}}{T_{i}}\pi\right)\right)\)
scheduler=lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=20, T_mult=2, eta_min=0.01)

8. LambdaLR
LambdaLR In fact, there is no fixed learning rate curve , In the name lambda It refers to that the learning rate can be customized as a related epoch Of lambda function , For example, we define an exponential function , Realized ExponentialLR The function of .
scheduler=lr_scheduler.LambdaLR(optimizer,lr_lambda=lambda epoch:0.9**epoch)

9.SequentialLR
SequentialLR You can connect multiple learning rate adjustment strategies in sequence , stay milestone Switch to the next learning rate adjustment strategy . The following is to combine an exponential decay learning rate with a linear decay learning rate .
scheduler=lr_scheduler.SequentialLR(optimizer,schedulers=[lr_scheduler.ExponentialLR(optimizer, gamma=0.9),lr_scheduler.LinearLR(optimizer,start_factor=1,end_factor=0.1,total_iters=80)],milestones=[50])

10.ChainedScheduler
ChainedScheduler and SequentialLR similar , It also calls several learning rate adjustment strategies in series in order , The difference is ChainedScheduler The learning rate changes continuously .
scheduler=lr_scheduler.ChainedScheduler([lr_scheduler.LinearLR(optimizer,start_factor=1,end_factor=0.5,total_iters=10),lr_scheduler.ExponentialLR(optimizer, gamma=0.95)])

11.ConstantLR
ConstantLRConstantLR It's simple , stay total_iters In wheel general optimizer Multiply the specified learning rate by factor,total_iters The original learning rate is restored outside the round .
scheduler=lr_scheduler.ConstantLRConstantLR(optimizer,factor=0.5,total_iters=80)

12.ReduceLROnPlateau
ReduceLROnPlateau There are so many parameters , Its function is to adaptively adjust the learning rate , It's in step You will observe on the validation set loss Or accuracy ,loss Of course, the lower the better , The higher the accuracy, the better , So use loss As step Parameter time ,mode by min, When using accuracy as a parameter ,mode by max.factor Is the proportion of each decline in learning rate , The new learning rate is equal to the old learning rate multiplied by factor.patience Is the number of times you can tolerate , When patience Next time , Network performance has not improved , Will reduce the learning rate .threshold Is the threshold for measuring the best value , Generally, we only focus on relatively large performance improvements .min_lr Is the minimum learning rate ,eps Refers to the smallest change in learning rate , When the difference between the old and new learning rates is less than eps when , Keep the learning rate unchanged .
Because the parameters are relatively complex , Here you can see a complete code Practice .
scheduler=lr_scheduler.ReduceLROnPlateau(optimizer,mode='min',factor=0.5,patience=5,threshold=1e-4,threshold_mode='abs',cooldown=0,min_lr=0.001,eps=1e-8)
scheduler.step(val_score)
The most comprehensive learning rate adjustment strategy in history lr_scheduler More articles about
- Good back-end architect must know : In the history of the most complete MySQL Summary of large table optimization
The original author of this article “ manong”, Original published in segmentfault, Link to the original text :segmentfault.com/a/1190000006158186 1. introduction MySQL As one of the representative works of open source technology , yes ...
- understand iOS A message push is enough : In the history of the most complete iOS Push Technical details
The author of this article : Chen Yufa , Tencent System Test Engineer , By Tencent WeTest Organize and publish . 1. introduction Development iOS In the system Push push , Usually there are the following 3 In this case : 1) On-line Push: such as QQ. WeChat, etc. IM When the interface is in the foreground , Chat messages and refer to ...
- Mobile IM Developers must read ( Two ): Summary of the most complete mobile weak network optimization methods in history
1. Preface This article continues with the previous article < Mobile IM Developers must read ( One ): Easy to understand , Understand the mobile network “ weak ” and “ slow ”>, About the main features of mobile networks , In the last part, I have explained it in detail , This article will focus on the features mentioned in the previous article , Combined with our practice ...
- 【 Reprint 】 PyTorch Six learning rate adjustment strategies
Original address : https://blog.csdn.net/shanglianlm/article/details/85143614 ----------------------------------- ...
- The most complete in history maven Of pom.xml File, ( Reprint )
This article is from : The most complete in history maven Of pom.xml File, —— O ho talks about dry goods <project xmlns="http://maven.apache.org/POM/4.0.0" x ...
- JVM There is not one of the most complete practical optimization in history
JVM None of the most complete optimizations in history 1.jvm Operation parameters of 1.1 Three parameter types 1.1.1 -server And -clinet Parameters 2.1 -X Parameters 2.1.1 -Xint.-Xcomp.-Xmixed 3.1 ...
- Springcloud To configure | In the history of the most complete , I know everything
Springcloud High concurrency To configure ( I know everything ) Crazy maker circle Java High concurrency [ 100 million traffic chat room actual battle ] Practical series 15 [ The main entrance of blog Park ] Preface Crazy maker circle ( The high concurrency study community created by the author neen )Spring ...
- Tomcat8 The most comprehensive optimization practice in history
Tomcat8 The most comprehensive optimization practice in history 1.Tomcat8 Optimize 1.1.Tomcat Configuration optimization 1.1.1. Deployment installation tomcat8 1.1.2 Ban AJP Connect 1.1.3. actuator ( Thread pool ) 1.1.4 3 Two kinds of operation ...
- The most complete audio and video in history SDK Bag to share with you
The most complete audio and video in history SDK Bag to share with you To summarize SDK function : project Details video communication Support video communication and voice communication with multiple resolutions Provide voice communication , It can support HD broadband voice to dynamically create rooms As needed , Create rooms at any time H5 Support ...
- PyTorch Six learning rate adjustment strategies
PyTorch Learning rate adjustment strategy through torch.optim.lr_scheduler Interface implementation .PyTorch There are three types of learning rate adjustment strategies provided , Namely Adjust in order : Adjust at equal intervals (Step), Adjust learning rates as needed (Mul ...
Random recommendation
- jQuery plug-in unit (cookie Store value )
Use cookie After the plug-in , It's easy to pass through cookie Object preservation . Read . Delete user information , Also can pass the cookie The plug-in keeps the user's browsing history , Its calling format is : preservation :$.cookie(key,value): Read :$ ...
- For the first time to use Axure~
Just touched axure I feel a lot better... No ~ But step by step ~ Later, I found that the font changes very strange , There is always only one font , Only when editing, the font I set appears . But in the end, something came out ~ Made a new contact page Finally, the student sister ...
- simulation Executor The implementation of the strategy
Executor As a management tool for threads , Just like the manager that manages threads , Don't be like before , adopt start To start a thread Executor Separate the submission thread from the execution thread , Make users only need to submit threads , It doesn't matter how ...
- 【elasticsearch】python Use below
Useful links : The most useful :http://es.xiaoleilu.com/054_Query_DSL/70_Important_clauses.html Good blog :http://www.cnblogs. ...
- The pursuit of backtracking n The power set of sets
Power set : There is a set A, aggregate A The power set of is made up of sets A A set composed of all subsets of . Each element in the set has only two states : Set of elements belonging to power set or set of elements not belonging to power set . aggregate {1,2,3}, Use a binary tree to represent . Recursive function voi ...
- CS The second stage of the team sprint standing meeting (5 month 31 Japan )
Yesterday's achievements : Find out about C# Information , Be clear bug Have a problem : The icon resolution obtained by the system is too low , I don't understand the code for obtaining icons found on the Internet Today's plan : Improve the function of obtaining file icons , And can delete the obtained icon file
- dia Unable to input Chinese ?
resolvent : Open with administrator privileges /usr/bin/dia , Make the following changes #dia-gnome --integrated "[email protected]" dia-gnome "[email protected]"
- ios Development int,NSInteger,NSUInteger,NSNumber
Share it , Some careless places encountered in the work project : 1. When needed int Type variables , It can be like writing C The program is the same as , use int, It can also be used. NSInteger, But it is more recommended to use NSInteger, Because in this way, there is no need to consider the equipment ...
- oracle Assign read-only permission to a specific table under a specific user
The following is the test process , Test environment oracle 11.2.0.3 linux platform : The simulation will HR Under the user employees The read-only permission of the table is not allocated test_ycr Create user :SQL> create user tes ...
- Sublime Text2 Usage rule
Sublime Text I found a useful editor , It doesn't just support python , Almost support the current mainstream language , Rich shortcut keys , It can greatly improve the efficiency of code development .Sublime Text website :http://www ...