当前位置:网站首页>mysql8.0(新特性小结)
mysql8.0(新特性小结)
2022-06-10 18:16:00 【缘友一世】
文章目录

一窗口函数
🪬🪬1.1 使用情况及特点
需要的情况:需要用到分组统计的结果对每一条记录进行计算的场景下,使用窗口函数更好
窗口函数的特点是可以分组,而且可以在分组内排序。另外,窗口函数不会因为分组而减少原表中的行数,这对我们在原表数据的基础上进行统计和排序非常有用。
1.2 窗口函数分类
- 窗口函数可以分为 静态窗口函数 和 动态窗口函数 。
- 静态窗口函数的窗口大小是固定的,不会因为记录的不同而不同;
- 动态窗口函数的窗口大小会随着记录的不同而变化。
窗口函数总体上可以分为序号函数、分布函数、前后函数、首尾函数和其他函数,如下表: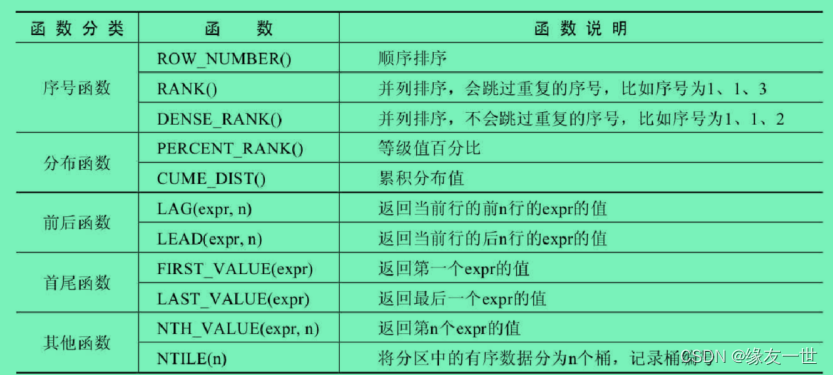
🧩🧩1.3语法结构
窗口函数的语法结构:
函数 OVER([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])
or
函数 OVER 窗口名 … WINDOW 窗口名 AS ([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])
- OVER 关键字指定函数窗口的范围。
- 如果省略后面括号中的内容,则窗口会包含满足WHERE条件的所有记录,窗口函数会基于所有满足WHERE条件的记录进行计算。
- 如果OVER关键字后面的括号不为空,则可以使用如下语法设置窗口。 - 窗口名:为窗口设置一个别名,用来标识窗口。
- PARTITION BY子句:指定窗口函数按照哪些字段进行分组。分组后,窗口函数可以在每个分组中分别执行。
- ORDER BY子句:指定窗口函数按照哪些字段进行排序。执行排序操作使窗口函数按照排序后的数据记录的顺序进行编号。
- FRAME子句:为分区中的某个子集定义规则,可以用来作为滑动窗口使用。
1.3.1 序号函数
1.ROW_NUMBER()函数
ROW_NUMBER()函数能够对数据中的序号进行顺序显示。
- 举例:查询 goods 数据表中每个商品分类下价格最高的3种商品信息
SELECT *
FROM (
SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id, category_id, category, NAME, price, stock
FROM goods) t
WHERE row_num <= 3;
2.RANK()函数
使用RANK()函数能够对序号进行并列排序,并且会跳过重复的序号,比如序号为1、1、3。
3.DENSE_RANK()函数
DENSE_RANK()函数对序号进行并列排序,并且不会跳过重复的序号,比如序号为1、1、2
1.3.2 分布函数
1.PERCENT_RANK()函数
PERCENT_RANK()函数是等级值百分比函数。按照如下方式进行计算。
(rank - 1) / (rows - 1)
rank的值为使用RANK()函数产生的序号,rows的值为当前窗口的总记录数
mysql> SELECT RANK() OVER w AS r,
-> PERCENT_RANK() OVER w AS pr,
-> id, category_id, category, NAME, price, stock
-> FROM goods
-> WHERE category_id = 1 WINDOW w AS (PARTITION BY category_id ORDER BY price
DESC);
+---+-----+----+-------------+---------------+----------+--------+-------+
| r | pr | id | category_id | category | NAME | price | stock |
+---+-----+----+-------------+---------------+----------+--------+-------+
| 1 | 0 | 6 | 1 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 |
| 2 | 0.2 | 3 | 1 | 女装/女士精品 | 卫衣 | 89.90 | 1500 |
| 2 | 0.2 | 4 | 1 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 |
| 4 | 0.6 | 2 | 1 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 |
| 5 | 0.8 | 1 | 1 | 女装/女士精品 | T恤 | 39.90 | 1000 |
| 6 | 1 | 5 | 1 | 女装/女士精品 | 百褶裙 | 29.90 | 500 |
+---+-----+----+-------------+---------------+----------+--------+-------+
6 rows in set (0.00 sec)
2.CUME_DIST()函数
CUME_DIST()函数主要用于查询小于或等于某个值的比例。
SELECT CUME_DIST() OVER(PARTITION BY category_id ORDER BY price ASC) AS cd,
id, category, NAME, price
FROM goods;
1.3.3 前后函数
1.LAG(expr,n)函数
LAG(expr,n)函数返回当前行的前n行的expr的值。
2.LEAD(expr,n)函数
LEAD(expr,n)函数返回当前行的后n行的expr的值。
1.3.4 首尾函数
1.FIRST_VALUE(expr)函数
FIRST_VALUE(expr)函数返回第一个expr的值。
SELECT id, category, NAME,price,stock,FIRST_VALUE(price) OVER w AS first_price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
2.LAST_VALUE(expr)函数
LAST_VALUE(expr)函数返回最后一个expr的值。
1.3.5 其他函数
1. NTH_VALUE(expr,n)函数
NTH_VALUE(expr,n)函数返回第n个expr的值。
2.NTILE(n)函数
NTILE(n)函数将分区中的有序数据分为n个桶,记录桶编号
SELECT NTILE(3) OVER w AS nt,id, category, NAME, price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
🧣🧣 二 公用表表达式
- 公用表表达式(或通用表表达式)简称为CTE(Common Table Expressions)。CTE是一个命名的临时结果集,作用范围是当前语句。CTE可以理解成一个可以复用的子查询,当然跟子查询还是有点区别的,CTE可以引用其他CTE,但子查询不能引用其他子查询。所以,可以考虑代替子查询。
- 依据语法结构和执行方式的不同,公用表表达式分为 普通公用表表达式 和 递归公用表表达式 2 种。
2.1 普通公用表表达式
- 语法结构:
WITH CTE名称
AS (子查询)
SELECT|DELETE|UPDATE 语句;
普通公用表表达式类似于子查询,不过,跟子查询不同的是,它可以被多次引用,而且可以被其他的普
通公用表表达式所引用。
案例:查询员工所在的部门的详细信息。
mysql> WITH emp_dept_id
-> AS (SELECT DISTINCT department_id FROM employees)
-> SELECT *
-> FROM departments d JOIN emp_dept_id e
-> ON d.department_id = e.department_id;
+---------------+------------------+------------+-------------+---------------+
| department_id | department_name | manager_id | location_id | department_id |
+---------------+------------------+------------+-------------+---------------+
| 90 | Executive | 100 | 1700 | 90 |
| 60 | IT | 103 | 1400 | 60 | |
| 100 | Finance | 108 | 1700 | 100 |
+---------------+------------------+------------+-------------+---------------+
公用表表达式可以起到子查询的作用。以后如果遇到需要使用子查询的场景,你可以在查询
之前,先定义公用表表达式,然后在查询中用它来代替子查询。而且,跟子查询相比,公用表表达式有
一个优点,就是定义过公用表表达式之后的查询,可以像一个表一样多次引用公用表表达式,而子查询
则不能。
2.2 递归公用表表达式
- 递归公用表表达式也是一种公用表表达式,只不过,除了普通公用表表达式的特点以外,它还有自己的特点,就是可以调用自己。它的语法结构是:
WITH RECURSIVE CTE名称
AS (子查询)
SELECT|DELETE|UPDATE 语句;
递归公用表表达式由 2 部分组成,分别是种子查询和递归查询,中间通过关键字 UNION [ALL]进行连接。
这里的种子查询,意思就是获得递归的初始值。这个查询只会运行一次,以创建初始数据集,之后递归
查询会一直执行,直到没有任何新的查询数据产生,递归返回。
烧手案例
- 针对于我们常用的employees表,包含employee_id,last_name和manager_id三个字段。如果a是b的管理者,那么,我们可以把b叫做a的下属,如果同时b又是c的管理者,那么c就是b的下属,是a的下下属。
- 思路:
- 用递归公用表表达式中的种子查询,找出初代管理者。字段 n 表示代次,初始值为 1,表示是第一代管理者。
- 用递归公用表表达式中的递归查询,查出以这个递归公用表表达式中的人为管理者的人,并且代次的值加 1。直到没有人以这个递归公用表表达式中的人为管理者了,递归返回。
- 在最后的查询中,选出所有代次大于等于 3 的人,他们肯定是第三代及以上代次的下属了,也就是下下属了。这样就得到了我们需要的结果集。
WITH RECURSIVE cte
AS
( SELECT employee_id,last_name,manager_id,1 AS n FROM employees WHERE employee_id = 100
-- 种子查询,找到第一代领导
UNION ALL
SELECT a.employee_id,a.last_name,a.manager_id,n+1 FROM employees AS a JOIN cte
ON (a.manager_id = cte.employee_id) -- 递归查询,找出以递归公用表表达式的人为领导的人
)
SELECT employee_id,last_name FROM cte WHERE n >= 3;
递归公用表表达式对于查询一个有共同的根节点的树形结构数据,非常有用。它可以不受层级的
限制,轻松查出所有节点的数据。
总结:公用表表达式的作用是可以替代子查询,而且可以被多次引用。递归公用表表达式对查询有一个共同根节点的树形结构数据非常高效,可以轻松搞定其他查询方式难以处理的查询。

基础篇学完了,再见!!!
边栏推荐
- 【数据库语言SPL】写着简单跑得又快的数据库语言 SPL
- 实时商业智能BI(二):合理的ETL架构设计实现准实时商业智能BI
- Anchor type and row data type of DB2 SQL pl
- Db2 SQL PL简介
- 瑞芯微RK1126平台 平台移植libevent 交叉编译libevent
- VMware horizon 82111 deployment series (XVI) blast bandwidth test
- 第四章 数据类型(三)
- 【Vulnhub靶场】JANGOW: 1.0.1
- Wechat applet, get the current page and judge whether the current page is a tabbar page
- 北京地铁票务系统
猜你喜欢

Form form of the uniapp uview framework, input the verification mobile number and verification micro signal

基于ssm在线订餐系统设计与实现.rar(项目源码)
Rk1126 adds a new module

VS从txt文件读取中文汉字产生乱码的解决办法(超简单)

【Vulnhub靶场】JANGOW: 1.0.1

Chapter II data type (I)

抢唱玩法升级,正版音乐高潮片段、实时打分能力等你集成~

"Digital transformation, data first", talk about how important data governance is to enterprises

Openssl1.1.1 vs2013 compilation tutorial

Three ways generated by stream lambda
随机推荐
Adobe Premiere basic special effects (card point and transition) (IV)
Adobe Premiere foundation - opacity (mixed mode) (XII)
Anchor type and row data type of DB2 SQL pl
How can bi help enterprises reduce labor, time and management costs?
MySQL index invalidation scenario
Introduction to ad18 device library import
Jsp基于ssm项目实验室管理系统设计与现实.doc
直播预告 | 社交新纪元,共探元宇宙社交新体验
In 2021, the world's top ten analog IC suppliers: Ti ranked first, and skyworks' revenue growth was the highest
nodejs-基本架构分析-解析引擎目录-插件安装-核心模块
In the era of data processing, data analysis has become the basic construction
The value of Bi in the enterprise: business analysis and development decision
VIM common shortcut keys
Seata安装Window环境
基于谱加权的波束方向图分析
[Code] neural symbol generation machine
Pits encountered during the use of ETL (ETL Chinese garbled)
WordPress 6.0 “Arturo阿图罗” 发布
& and||
如何设置 SaleSmartly 以进行 Google Analytics(分析)跟踪