当前位置:网站首页>RL reinforcement learning summary (1)
RL reinforcement learning summary (1)
2022-08-05 05:03:00 【Times & Beliefs】
Recently, I summarized the knowledge points of reinforcement learning. I listened to Dr. Tang Yudi's course. I will express it in my own words and understanding!!!
1. Overview of Reinforcement Learning
Reinforcement learning, the full name in English is Reinforcement Learning, or RL for short.
Introduction
You must have heard the news that AlphaGo beat the world Go champion.The AlphaGo here uses the reinforcement learning in AI. By learning a lot of chess records in the world, AlphaGo will determine the best choice for each step in chess (select the step with the largest reward value in the current state).
Main mechanism
Reinforcement learning is constantly interacting with the environment. When faced with a choice, after the choice, if the effect is better, it will carry out reward; if the effect is not good, carry out Punishment.Let the model learn with rewards and penalties.When faced with a choice later, choose a choice with a large reward value first, so as to achieve the purpose of continuous learning!
2. Basic concepts of reinforcement learning
Basic Concepts
(1) agent: The Chinese translation is agent, which is the object that will be learned and operated in our model.For example: a car in self-driving.
(2) state: Translated as state at noon, it is the surrounding situation and state of the current agent.For example: when AlphaGo and Li Shishi are playing chess, the position and distribution of the black and white chess pieces that have already fallen on the chessboard at the time of the move; where on the road the self-driving car is at this time.
(3) action: The Chinese translation is action, which is the next step the agent will take in the current state.For example: where on the chessboard the AlphaGo will play; what kind of driving behavior will the self-driving car take at the next moment (go straight, turn left, turn right...)
(4) reward: Chinese translation is reward. Reward includes positive reward, also called reward for short, and negative reward, also called punishment.It is what kind of feedback the current agent will get after taking action.For example: a self-driving car, driving closer and closer to the destination, will be rewarded; if it collides with surrounding buildings, vehicles, etc., it will be punished.By rewarding and punishing, "teach" the agent to learn!!!
(5) policy: The Chinese translation is strategy, which is a series of actions to be taken in order to achieve my ultimate goal, which is called a strategy.
Reinforcement learning process

The agent observes before taking action.At the beginning, you will make different choices. After interacting with the environment (rewarding and punishing), learn to choose the one with the largest reward value.
Observe->Act->Observe
Keep looping...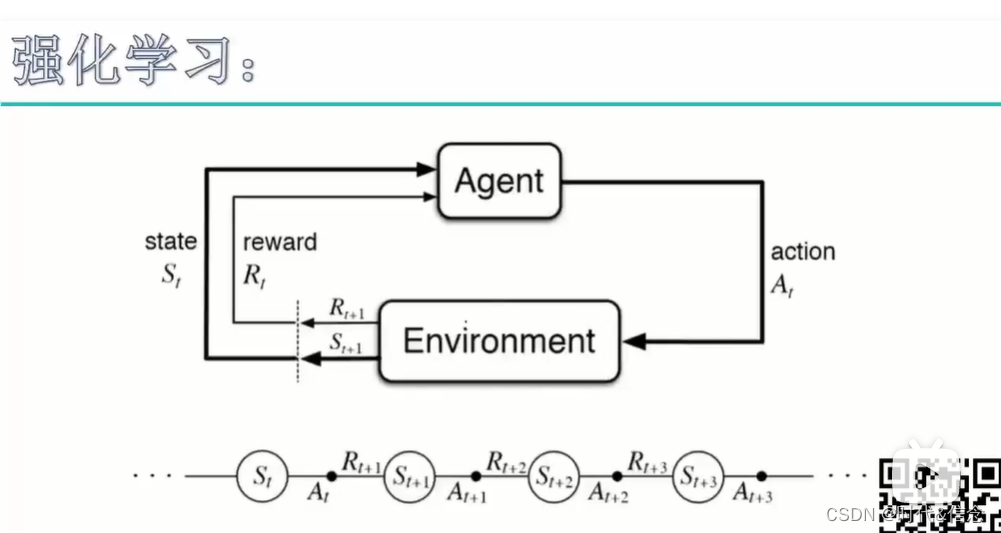
As shown in the figure above, in short: the agent constantly interacts with the environment, and the environment rewards and punishes the intelligence, thereby changing the state of the agent.
Repeatedly loop, push the agent to move towards the state change (the direction with the larger reward value).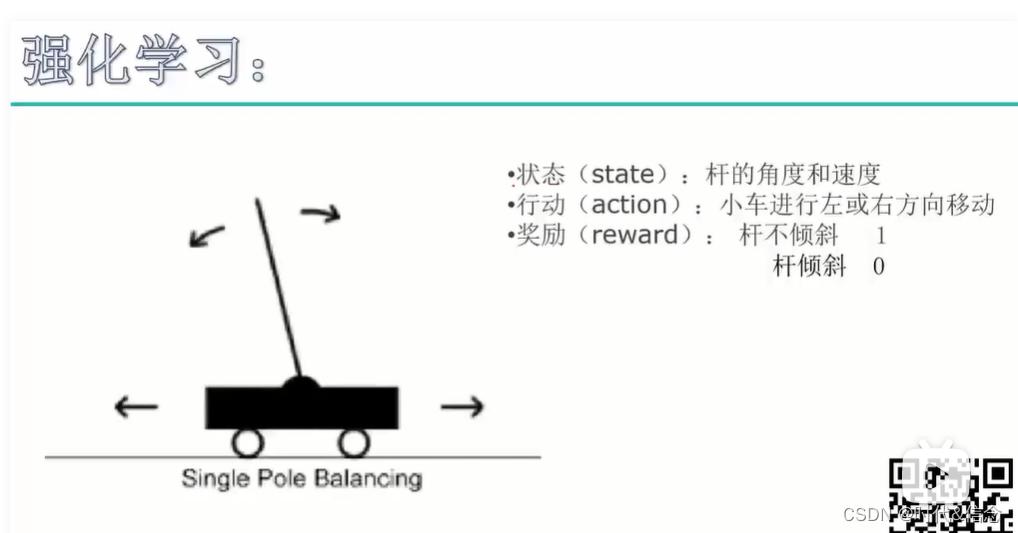
Example
The car, after taking action (moving left or right), continuously modifies its state (angle and speed of the pole) through incentive measures
边栏推荐
- for..in和for..of的区别
- [Surveying] Quick Summary - Excerpt from Gaoshu Gang
- 使用二维码解决固定资产管理的难题
- flex布局青蛙游戏通关攻略
- Error creating bean with name ‘configDataContextRefresher‘ defined in class path resource
- u-boot调试定位手段
- Excel画图
- 【cesium】加载并定位 3D Tileset
- AUTOCAD - dimension association
- Is the NPDP certificate high in gold content?Compared to PMP?
猜你喜欢
作业8.4 进程间的通信 管道与信号
Flutter真机运行及模拟器运行
Please write the SparkSQL statement
![[BSidesCF 2019] Kookie](/img/29/19e7c244feb86b37ab32a53aa11f25.png)
[BSidesCF 2019] Kookie
The log causes these pits in the thread block, you have to guard against
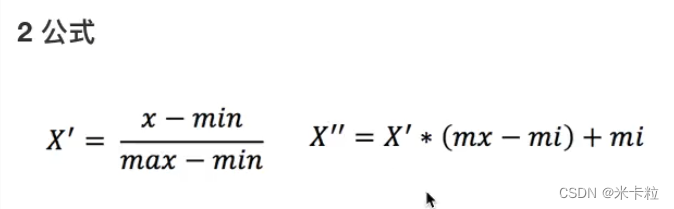
Feature preprocessing
About the installation of sklearn library
Flutter learning 5-integration-packaging-publish
![[cesium] 3D Tileset model is loaded and associated with the model tree](/img/03/50b7394f33118c9ca1fbf31b737b1a.png)
[cesium] 3D Tileset model is loaded and associated with the model tree
u-boot debugging and positioning means
随机推荐
Why did you start preparing for the soft exam just after the PMP exam?
淘宝账号如何快速提升到更高等级
算法---一和零(Kotlin)
phone call function
Visibility of multi-column attribute column elements: display, visibility, opacity, vertical alignment: vertical-align, z-index The larger it is, the more it will be displayed on the upper layer
App快速开发建设心得:小程序+自定义插件的重要性
Day019 方法重写与相关类的介绍
MySQL基础(一)---基础认知及操作
RL强化学习总结(一)
The log causes these pits in the thread block, you have to guard against
关于sklearn库的安装
ansible各个模块详解
Error creating bean with name ‘configDataContextRefresher‘ defined in class path resource
WPF中DataContext作用
Machine Learning Overview
dedecms后台生成提示读取频道信息失败的解决方法
Feature preprocessing
dedecms织梦tag标签不支持大写字母修复
Please write the SparkSQL statement
JeeSite New Report