当前位置:网站首页>Machine Learning Overview
Machine Learning Overview
2022-08-05 04:11:00 【Mika grains】
1.1人工智能概述
达特茅斯会议-人工智能的起点
机器学习是人工智能的一个实现途径
深度学习是机器学习的一个方法发展而来
1.1.2机器学习、深度学习能做些什么
传统预测
图像识别
自然语言处理
1.2什么是机器学习
数据、模型、预测
从历史数据中获得规律?这些历史数据是怎么的格式?
1.2.3数据集构成
特征值+目标值
1.3机器学习算法分类
监督学习
目标值:类别——分类问题
k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归
目标值:连续型的数据-回归问题
线性回归、岭回归
目标值:无-无监督学习
聚类 k-means
1、Predict what the temperature will be tomorrow? 回归
2、预测明天是阴、晴、雨? 分类
3、Face age prediction? 回归/分类
4、人脸识别 ? 分类
2.1数据集
2.1.1可用数据集
公司内部 百度
数据接口 花钱
数据集
学习阶段可以用的数据集:
1、sklearn
2、kaggle
3、UCI
1 Scikit-learn工具介绍
2.1.2sklearn数据集
sklearn.datasets
load_* 获取小规模数据集
from sklearn.datasets import load_iris
def datasets_demo():
"""
sklearn数据集使用
:return:
"""
# 获取数据集
iris = load_iris()
print("鸢尾花数据集:\n",iris)
print("鸢尾花数据集描述:\n", iris["DESCR"])
print("The name of the iris eigenvalue:\n", iris.feature_names)
print("Iris eigenvalues:\n", iris.data.shape)
return None
if __name__ == "__main__":
# 代码1:sklearn数据集使用
datasets_demo()运行如下(数据过多,展示部分)

fetch_* 获取大规模数据集
2 sklearn小数据集
sklearn.datasets.load_iris()
3 sklearn大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None)
4 数据集的返回值
datasets.base.Bunch(继承自字典)
dict["key"] = values
bunch.key = values
思考:Whether the obtained data is used to train a model?
2.1.3数据集的划分
训练数据集:用于训练、构建模型
测试数据:is used in model checking,用于评估模型是否有效
测试集 20%~30%
sklearn.model_selection.train_test_split(arrays,*options)
训练集特征值,测试集特征值,训练集目标值,测试集目标值
x_train, x_test, y_train, y_test
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def datasets_demo():
"""
sklearn数据集使用
:return:
"""
# 获取数据集
iris = load_iris()
print("鸢尾花数据集:\n",iris)
print("鸢尾花数据集描述:\n", iris["DESCR"])
print("The name of the iris eigenvalue:\n", iris.feature_names)
print("Iris eigenvalues:\n", iris.data.shape)
# 数据集的划分
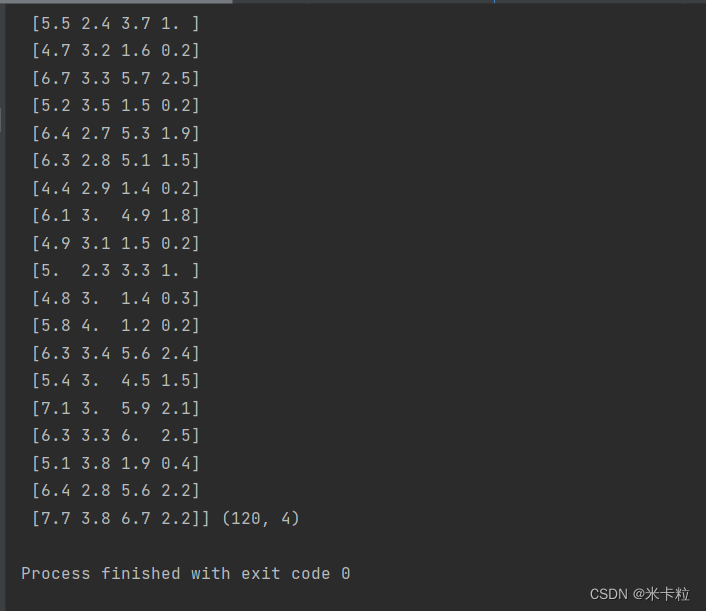
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("Features of the training dataset:\n", x_train, x_train.shape)
return None
if __name__ == "__main__":
# 代码1:sklearn数据集使用
datasets_demo()部分运行结果如下
边栏推荐
- Shell script: for loop and the while loop
- [CISCN2019 South China Division]Web11
- 1007 Climb Stairs (贪心 | C思维)
- 概率论的学习和整理8: 几何分布和超几何分布
- 特征预处理
- UE4 第一人称角色模板 添加生命值和调试伤害
- pyqt5 + socket 实现客户端A经socket服务器中转后主动向客户端B发送文件
- In the WebView page of the UI automation test App, the processing method when the search bar has no search button
- UI自动化测试 App的WebView页面中,当搜索栏无搜索按钮时处理方法
- [Paper Notes] MapReduce: Simplified Data Processing on Large Clusters
猜你喜欢

Learning and finishing of probability theory 8: Geometric and hypergeometric distributions
多御安全浏览器 V10.8.3.1 版正式发布,优化多项内容
Some conventional routines of program development (1)

Growth-based checkerboard corner detection method

flink reads mongodb data source
新人如何入门和学习软件测试?
JeeSite新建报表
![[Geek Challenge 2019]FinalSQL](/img/e4/0c8225ef7c5e7e5bdbaac2ef6fc867.png)
[Geek Challenge 2019]FinalSQL
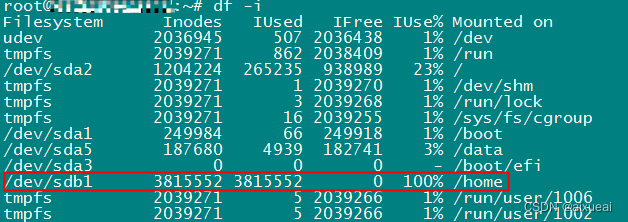
4T硬盘剩余很多提示“No space left on device“磁盘空间不足
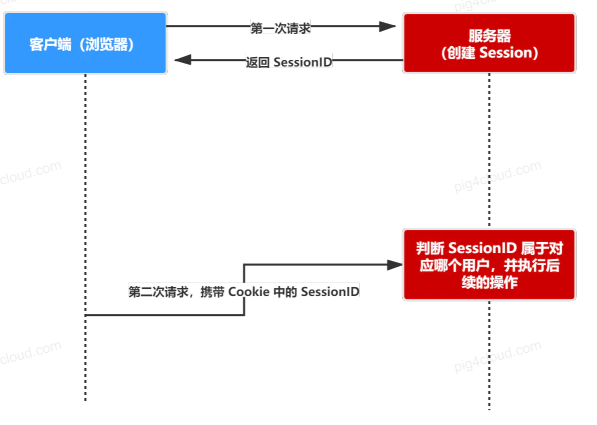
token、jwt、oauth2、session解析
随机推荐
DEJA_VU3D - Cesium功能集 之 059-腾讯地图纠偏
C+ +核心编程
markdown如何换行——md文件
How to solve complex distribution and ledger problems?
机器学习概述
cross domain solution
Four-digit display header design
Use Unity to publish APP to Hololens2 without pit tutorial
token, jwt, oauth2, session parsing
How to solve the three major problems of bank data collection, data supplementary recording and index management?
Static method to get configuration file data
关于#SQL#的迭代、父子结构查询问题,如何解决?
Ali's local life's single-quarter revenue is 10.6 billion, Da Wenyu's revenue is 7.2 billion, and Cainiao's revenue is 12.1 billion
【树莓派】树莓派调光
JeeSite新建报表
[8.2] Code Source - [Currency System] [Coins] [New Year's Questions (Data Enhanced Edition)] [Three Stages]
【测量学】速成汇总——摘录高数帮
flink reads mongodb data source
Event parse tree Drain3 usage and explanation
Growth-based checkerboard corner detection method