当前位置:网站首页>特征预处理
特征预处理
2022-08-05 04:08:00 【米卡粒】
2.4.1 什么事特征预处理
为什么要进行归一化、标准化
无量纲化
2.4.2归一化:对于归一化来说,如果出现异常点,影响了最大值和最小值,那么结果显然是会发生改变的
通过对原始数据进行变换把数据映射到(默认为[0,1])之间
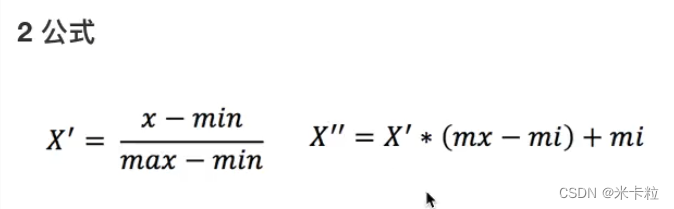
异常值:最大值 最小值
2.4.3 标准化:对于标准化来说,如果出现异常点,由于具有一定数据量,少量的异常点,对于平均值的影响并不大,从而方差改变较小

(x - mean)/ std
标准差:集中程度
def minmax_demo():
"""
归一化
:return:
"""
# 1 获取数据
data = pd.read_csv("lizi")
data = data.iloc[:, :3]
print("data:\n", data)
# 2 实例化一个转换器类
# transfer = MinMaxScaler()
transfer = MinMaxScaler(feature_range=[2,3])
# 3 调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None
def stand_demo():
"""
标准化
:return:
"""
# 1 获取数据
data = pd.read_csv("lizi")
data = data.iloc[:, :3]
print("data:\n", data)
# 2 实例化一个转换器类
transfer = StandardScaler
# 3 使用fit_transfer
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None由于 factor_returns.csv 没有找到,所以不知道可不可以运行
def variance_demo():
"""
过滤低方差特征
:return:
"""
# 1、获取数据
data = pd.read_csv("factor_returns.csv")
data = data.iloc[:, 1:-2]
print("data:\n", data)
# 2、实例化一个转化器
transfer = VarianceThreshold(threshold=10)
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new, data_new.shape)
return None2.5.1 降维 - 降低维度
ndarray
维数 : 嵌套的层数
二维数组
此处的降维:降低特征的个数
效果: 特征与特征之间不相关
2.5.1 降维
特征选择
Filter过滤式
方差选择法:低方差特征过滤
相关系数 - 特征与特征之间的相关程度
取值范围: -1 ~1
特征与特征之间的相关性很高:
1)选取其中一个
2)加权求和
3)主成分分析
Embeded嵌入式
def variance_demo():
"""
过滤低方差特征
:return:
"""
# 1、获取数据
data = pd.read_csv("factor_returns.csv")
data = data.iloc[:, 1:-2]
print("data:\n", data)
# 2、实例化一个转化器
transfer = VarianceThreshold(threshold=10)
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new, data_new.shape)
# 计算两个变量之间的相关系数
r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])
print("相关系数:\n", r1)
r2 = pearsonr(data['revenue'], data['total_expense'])
print("revenue与total_expense之间的相关性:\n", r2)
return None决策树 正则化 深度学习
主成分分析:
2.6.1 什么是主成分分析(PCA)
sklearn.decomposition.PCA(n_compinents=None)
n_components
def pca_demo():
"""
PCA
:return:
"""
data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]
# 1 实例化一个转换器类
transfer = PCA(n_components=2)
# 调用fit_transform(data)
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None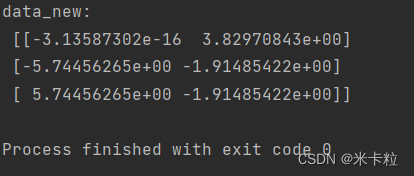
小数 表示保留百分之多少的信息量
整数 减少到多少特征
2.6.2案例探究用户对物品类别的喜好细分
边栏推荐
猜你喜欢
How to wrap markdown - md file

Growth-based checkerboard corner detection method

C+ +核心编程
Ice Scorpion V4.0 attack, security dog products can be fully detected
35岁的软件测试工程师,月薪不足2W,辞职又怕找不到工作,该何去何从?
![[Software testing] unittest framework for automated testing](/img/80/caedd5cf6dd61c9d75475866613cac.png)
[Software testing] unittest framework for automated testing

银行数据采集,数据补录与指标管理3大问题如何解决?
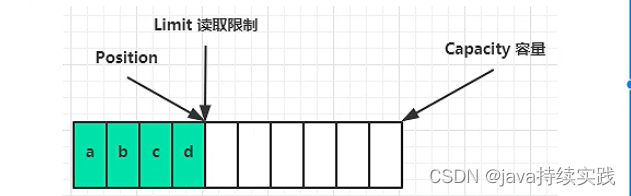
bytebuffer 内部结构
10 years of testing experience, worthless in the face of the biological age of 35
不看后悔,appium自动化环境完美搭建
随机推荐
Spark基础【介绍、入门WordCount案例】
测试薪资这么高?刚毕业就20K
【Mysql进阶优化篇02】索引失效的10种情况及原理
[8.1] Code Source - [The Second Largest Number Sum] [Stone Game III] [Balanced Binary Tree]
DEJA_VU3D - Cesium功能集 之 058-高德地图纠偏
【8.1】代码源 - 【第二大数字和】【石子游戏 III】【平衡二叉树】
2022.8.4-----leetcode.1403
Defect detection (image processing part)
[Geek Challenge 2019]FinalSQL
【8.2】代码源 - 【货币系统】【硬币】【新年的问题(数据加强版)】【三段式】
Qixi Festival code confession
UE4 第一人称角色模板 添加冲刺(加速)功能
C+ +核心编程
Based on holding YOLOv5 custom implementation of FacePose YOLO structure interpretation, YOLO data format conversion, YOLO process modification"
DEJA_VU3D - Cesium功能集 之 059-腾讯地图纠偏
ffmpeg enumeration decoders, encoders analysis
UI自动化测试 App的WebView页面中,当搜索栏无搜索按钮时处理方法
四位数显表头设计
Redis key basic commands
The most comprehensive exam questions for software testing engineers in 2022