当前位置:网站首页>Feature preprocessing
Feature preprocessing
2022-08-05 04:11:00 【Mika grains】
2.4.1 What is feature preprocessing
Why normalize and standardize
Dimensionless
2.4.2 Normalization: For normalization, if there are abnormal points that affect the maximum and minimum values, the results will obviously change
Map the data to ([0,1] by default) by transforming the original data
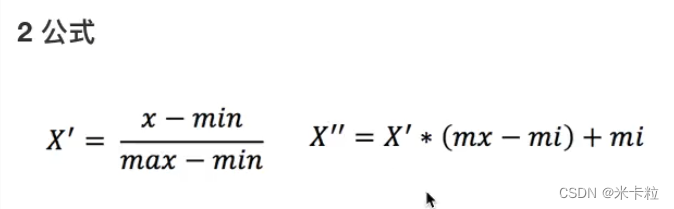
Outliers: Maximum Minimum
2.4.3 Standardization: For standardization, if there are abnormal points, due to a certain amount of data, a small number of abnormal points have little effect on the average, so the variance changes are small

(x - mean)/std
Standard Deviation: Degree of Concentration
def minmax_demo():"""Normalized:return:"""# 1 Get datadata = pd.read_csv("lizi")data = data.iloc[:, :3]print("data:\n", data)# 2 Instantiate a converter class# transfer = MinMaxScaler()transfer = MinMaxScaler(feature_range=[2,3])# 3 Call fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef stand_demo():"""standardization:return:"""# 1 Get datadata = pd.read_csv("lizi")data = data.iloc[:, :3]print("data:\n", data)# 2 Instantiate a converter classtransfer = StandardScaler# 3 Use fit_transferdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return NoneBecause factor_returns.csv was not found, I don't know if it can be run or not
def variance_demo():"""Filter low variance features:return:"""# 1. Get datadata = pd.read_csv("factor_returns.csv")data = data.iloc[:, 1:-2]print("data:\n", data)# 2. Instantiate a convertertransfer = VarianceThreshold(threshold=10)# 3. Call fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new, data_new.shape)return None2.5.1 Dimensionality Reduction - Dimensionality Reduction
ndarray
Dimensions: the number of levels of nesting
2D array
Dimension reduction here: reduce the number of features
Effect: No correlation between features
2.5.1 Dimensionality reduction
Feature selection
Filter filter
Variance selection method: low variance feature filtering
Correlation coefficient - the degree of correlation between features
Value range: -1 ~1
The correlation between features is high:
1) Choose one of them
2) Weighted Summation
3) Principal Component Analysis
Embeded
def variance_demo():"""Filter low variance features:return:"""# 1. Get datadata = pd.read_csv("factor_returns.csv")data = data.iloc[:, 1:-2]print("data:\n", data)# 2. Instantiate a convertertransfer = VarianceThreshold(threshold=10)# 3. Call fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new, data_new.shape)# Calculate the correlation coefficient between two variablesr1 = pearsonr(data["pe_ratio"], data["pb_ratio"])print("Correlation coefficient:\n", r1)r2 = pearsonr(data['revenue'], data['total_expense'])print("Correlation between revenue and total_expense:\n", r2)return NoneDecision Tree Regularization Deep Learning
Principal component analysis:
2.6.1 What is Principal Component Analysis (PCA)
sklearn.decomposition.PCA(n_compinents=None)
n_components
def pca_demo():"""PCA:return:"""data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]# 1 Instantiate a converter classtransfer = PCA(n_components=2)# call fit_transform(data)data_new = transfer.fit_transform(data)print("data_new:\n", data_new)return None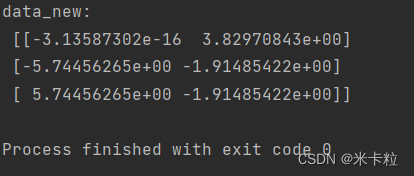
Decimal means how much information is retained
Integer reduces to how many features
2.6.2 Case study of user preferences for item categories
边栏推荐
- Based on holding YOLOv5 custom implementation of FacePose YOLO structure interpretation, YOLO data format conversion, YOLO process modification"
- 阿里本地生活单季营收106亿,大文娱营收72亿,菜鸟营收121亿
- Index Mysql in order to optimize paper 02 】 【 10 kinds of circumstances and the principle of failure
- 大佬们,我注意到mysql cdc connector有参数scan.incremental.sna
- DEJA_VU3D - Cesium功能集 之 058-高德地图纠偏
- UE4 第一人称角色模板 添加冲刺(加速)功能
- 2022软件测试工程师最全面试题
- pyqt5 + socket 实现客户端A经socket服务器中转后主动向客户端B发送文件
- Detailed and comprehensive postman interface testing practical tutorial
- Cron(Crontab)--使用/教程/实例
猜你喜欢

AUTOCAD - dimension association

将故事写成我们

Learning and finishing of probability theory 8: Geometric and hypergeometric distributions
Machine Learning Overview
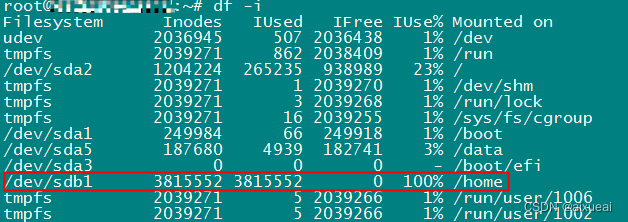
There are a lot of 4T hard drives remaining, prompting "No space left on device" insufficient disk space
小程序_动态设置tabBar主题皮肤
特征预处理
Swing有几种常用的事件处理方式?如何监听事件?
![[BJDCTF2020] EasySearch](/img/60/464de3bcdda876171b9f61ad31bff1.png)
[BJDCTF2020] EasySearch
BI业务分析思维:现金流量风控分析(二)信用、流动和投资风险
随机推荐
【树莓派】树莓派调光
商业智能BI业务分析思维:现金流量风控分析(一)营运资金风险
[MRCTF2020] Ezpop (detailed)
How to discover a valuable GameFi?
狗仔队:表面编辑多视点图像处理
Qixi Festival earn badges
token, jwt, oauth2, session parsing
七夕节代码表白
Static method to get configuration file data
1007 Climb Stairs (greedy | C thinking)
Android interview question - how to write with his hands a non-blocking thread safe queue ConcurrentLinkedQueue?
UE4 第一人称角色模板 添加生命值和调试伤害
Index Mysql in order to optimize paper 02 】 【 10 kinds of circumstances and the principle of failure
程序开发的一些常规套路(一)
[MRCTF2020]PYWebsite
markdown如何换行——md文件
Ali's local life's single-quarter revenue is 10.6 billion, Da Wenyu's revenue is 7.2 billion, and Cainiao's revenue is 12.1 billion
There are a lot of 4T hard drives remaining, prompting "No space left on device" insufficient disk space
GC Gaode coordinate and Baidu coordinate conversion
Paparazzi: Surface Editing by way of Multi-View Image Processing