当前位置:网站首页>What is text mining? "Suggested collection"
What is text mining? "Suggested collection"
2022-07-05 18:39:00 【Full stack programmer webmaster】
Hello everyone , I meet you again , I'm your friend, Quan Jun .
What is text mining Text mining is effective 、 novel 、 Useful 、 Understandable 、 Valuable knowledge scattered in text files , And use this knowledge to better organize the process of information .1998 end of the year , It is clearly pointed out in the first implementation projects of the national key research and development plan , Text mining is “ Images 、 Language 、 Natural language understanding and knowledge mining ” Important content in . Text mining is a research branch of information mining , For knowledge discovery based on text information . Text mining uses intelligent algorithms , Such as neural network 、 Case based reasoning 、 Possibility reasoning, etc , Combined with word processing technology , Analyze a large number of unstructured text sources ( Such as documents 、 The spreadsheet 、 Customer email 、 Question query 、 Web page, etc ), Extract or tag keyword concepts 、 The relationship between words , And classify the documents according to the content , Get useful knowledge and information . Text mining is a multidisciplinary field , It covers a variety of technologies , Including data mining technology 、 Information extraction 、 Information retrieval , machine learning 、 natural language processing 、 Computational linguistics 、 Statistical data analysis 、 Linear geometry 、 Probability theory and even graph theory .
The development of text mining technology Data mining technology itself is a new field of current data technology development , Text mining has a shorter history . The traditional information retrieval technology is not satisfactory for the processing of massive data , Text mining is becoming increasingly important , It can be seen that text mining technology is slowly evolving from the field of information extraction and related technologies . With the advent of the Internet age , The information available to users includes information from technical data 、 Business information to news reports 、 Entertainment information and other types and forms of documents , It constitutes an extremely large heterogeneous 、 Open distributed database , This database stores unstructured text data . Combine natural language understanding and computer linguistics in the field of artificial intelligence , Two new research fields of data mining are derived from data mining : Web Mining and text mining . Web Mining focuses on analyzing and mining web related data , Including text 、 Link structure and access statistics ( Finally, user network navigation is formed ). A web page contains many different data types , Therefore, web mining includes text mining 、 Data mining in database 、 Image mining . Text mining is a new field of data mining , Its purpose is to transform text information into knowledge that people can use .
Text mining preprocessing Text mining is developed from data mining , But it does not mean that text mining can be realized simply by applying data mining technology to a large number of text sets , A lot of preparation needs to be done . The preparation of text mining is collected by text 、 Text analysis and feature pruning consist of three steps , See the picture 1. ◆ Text collection The text data to be mined may have different types , And scattered in many places . You need to find and retrieve all the texts that are considered possibly relevant to your current work . In a general way , System users can define text sets , But we still need a system to filter relevant text . ◆ Text analysis Compared with structured data in the database , Text has a finite structure , Or there is no structure at all ; In addition, the content of the document is the natural language used by humans , It is difficult for computers to deal with its semantics . The particularity of text data source makes the existing data mining technology can not be directly applied to it , The text needs to be analyzed , Extract metadata representing its characteristics , These features can be saved in a structured form , As an intermediate representation of the document . Its purpose is to scan and extract the required facts from the text ◆ Feature pruning Feature trimming includes horizontal selection and vertical projection . Horizontal selection refers to eliminating noisy documents to improve mining accuracy , Or when the number of documents is too large, only a part of the samples are selected to improve the mining efficiency . Longitudinal projection refers to the selection of useful features according to the mining target , Trim through features , You can get a valid 、 Reduced feature subset , On this basis, various document mining work can be carried out .
The key technology of text mining After feature pruning , Data text mining can be carried out . The workflow of text mining is shown in Figure 2 Shown . From the current research and application of text mining technology , From the perspective of semantics to achieve text mining is still very few , At present, the most studied and applied text mining technologies are : Document clustering 、 Document classification and abstract extraction . ◆ Document clustering First , Document clustering can find a batch of documents similar to a certain document , Help knowledge workers find relevant knowledge ; secondly , Document clustering can cluster a document into several classes , Provides a way to organize document collections ; Again , Document clustering can also generate classifiers to classify documents . Clustering in text mining can be used for : Provide an overview of the content of large-scale document sets ; Identify the similarity between hidden documents ; Reduce browsing related 、 The process of similar information . Clustering methods usually have : Hierarchical clustering 、 Plane division 、 Simple Bayesian clustering 、K- Nearest neighbor reference clustering 、 Hierarchical clustering 、 Concept based text clustering . ◆ Document classification The difference between classification and clustering is : Classification is based on the existing classification system table , Clustering has no classification table , Just based on the similarity between documents . Because the classification system table is generally more accurate 、 It scientifically reflects the division of a certain field , Therefore, the classification method is used in the information system , Users can manually traverse a hierarchical classification system to find the information they need , Achieve the purpose of discovering knowledge , This is for users who are just beginning to contact a field and want to know about it , Or it is especially useful when users cannot accurately express their information needs . In the traditional search engine, the catalog search engine belongs to the category of classification , But many directory search engines use manual classification , Not only is the workload huge , And the accuracy is not high , It greatly limits the effective play . in addition , Users can often get thousands of documents when searching , This makes them have trouble deciding what is relevant to their needs , If the system can present the search results to users by categories , It will obviously reduce the workload of users to analyze the search results , This is another important application of automatic classification . Automatic document classification is generally realized by statistical methods or machine learning . Common methods are : Simple Bayesian classification , Matrix transformation 、K- Nearest neighbor reference classification algorithm and support vector machine classification method . ◆ Auto digest Text information on the Internet 、 The contents of internal documents and databases are growing exponentially , When users are retrieving information , You can get thousands of returned results , Many of them have nothing to do with their information needs , If you want to eliminate these documents , You must read the full text , This requires users to pay a lot of labor , And the effect is not good . Automatic summarization can generate short indicative information about the content of the document , Present the main content of the document to the user , To decide whether to read the original document , This can save a lot of browsing time . In short, automatic summarization is the use of computers to automatically extract simple and coherent essays from the original document that comprehensively and accurately reflect the central content of the document . Automatic summarization has the following characteristics :(1) Automatic summarization should be able to automatically extract the theme or central content of the original text .(2) The abstract should be general 、 Objectivity 、 Intelligibility and readability .(3) It can be applied to any field . According to the sentence source of the generated abstract , Automatic summarization methods can be divided into two categories , One is to use the sentences in the original text completely to generate abstracts , The other is that sentences can be automatically generated to express the content of documents . The latter is more powerful , At the time of realization , Automatic sentence generation is a complex problem , Often, new sentences cannot be understood , Therefore, at present, most of the methods used are extraction and generation .
The application prospect of text mining Using text mining technology to deal with a large number of text data , It will undoubtedly bring great business value to the enterprise . therefore , At present, there is a strong demand for text mining , Text mining technology has broad application prospects .
Knowledge Links Evaluation method of text mining system It is very important to evaluate text mining system , There are many ways to measure progress in this area , Several generally accepted evaluation methods and standards are as follows : ◆ Classification accuracy : The classification accuracy is obtained by calculating the probability of text samples and texts to be classified . ◆ Precision rate : The precision rate refers to the size of the object set occupied by the correctly classified objects , ◆ Recall rate : Recall refers to the proportion of the number of objects in the specified category in the set to the number of objects in the actual target class . ◆ Support : Support indicates the frequency of the rule . ◆ Degree of confidence : Confidence indicates the strength of the rule .
———————————————————————————————————————————————-
Case study : Application of text mining in internet keyword analysis
Mr. Shen Hao takes the headline of sina sports international football news as an example , It vividly describes the application of text mining in internet keyword analysis .
In data analysis technology , The use of text analysis has always been a less involved field , Especially the text mining of Chinese characters .
Text mining can be roughly composed of three parts : The bottom layer is the basic field of text data mining , Including machine learning 、 mathematical statistics 、 natural language processing ; On this basis, it is the basic technology of text data mining , There are five categories , Including text information extraction 、 Text classification 、 Text clustering 、 Text data compression 、 Text data processing ; Above the basic technology, there are two main application fields , Including information access and knowledge discovery , Information access includes information retrieval 、 Information browsing 、 Information filtering 、 Information report , Knowledge discovery includes data analysis 、 Data forecast . Among them, the extraction of text information and content classification need to pay a lot of human and material resources , Especially for Chinese, the keyword terms in different fields and industries are different , therefore , It is particularly important to build a key thesaurus suitable for different industries .
However, text mining based on Chinese is also widely used , For example, the major media 2011 Ten key words inventory . For example, at zero some time ago E-lab The key words of Chinese Tang poetry and Song poetry drawn by the Research Office , It's very interesting , Capture the high-frequency or trendy words of ancient poetry . And use the method of network analysis diagram to clearly show the relationship between various keywords , Even some readers can deduce some classic poems according to the network diagram . What about? ? I can tell that the picture is an analysis of Tang poetry , Which one is Song poetry ?
Get down to business , The author is also dealing with the content of text analysis , Just take this opportunity to share the method of text analysis .
As mentioned earlier , Chinese text mining focuses on the establishment of key vocabulary , Without the help of special software , Use “ Artificial intelligence ” It's an expedient . The key point of building a key vocabulary artificially is coding , Coders are required to have considerable experience and sufficient sensitivity to keywords , In case of multi person coding, we also need to take into account the team's personality differences, division of labor and cooperation and other factors .
The author chooses the news headlines of the international football page of sina sports website as the research object ( You know the reason why you don't choose domestic football ……), I hope to find the personal characteristics of news editors and the writing of headlines through the analysis of small to large through the method of text mining “ Hidden rules ”.
First , I chose 2011 year 7 month 1 solstice 2011 year 12 month 20 Japanese news headlines as the research object , This time period includes large-scale Cup matches ( Americas Cup )、 Transfer period 、 Daily league matches and other contents , It should be said that it covers most news reports that may appear in football activities , share 25,598 News headlines .
News can be roughly divided into three categories , namely : picture 、 written words 、 video .
After finishing , The author screened 500 Multiple keywords , Such as : transfer 、 captain 、 legend 、 list 、 General 、 Fabulous 、 New star 、 rival 、 Training 、 International football team 、 Feng Ba 、 A penalty 、VS、 home 、 King of heaven, wait . Screening of these keywords , The main basis for the author to screen keywords is as follows :
l Related to sports , But outside or inside
l It belongs to everyday language , Can't make words
l Need is through vocabulary , It is universal , Such as “ Beckham took his son shopping ” Not as a keyword , Because other players have a low probability of similar situations .
l Find as many as possible , And sort it out . such as “ Xiaoluo ” and ”C ROM. ” It's the same person , But the author regards it as two key words .
Don't talk nonsense , Here are the analysis results of these words :
The following part of the overview lists the keyword ranking of three categories of news headlines , Pictures are in “ Celebrate “、” Training ”、” goal ” As a representative ; Video news with “ goal ”、” Break the door ”、” Lionel messi ” As a representative , Mainly related to stadium activities , What is quite different from the first two categories is the literal news , The top ones are ” Lionel messi ”、” announce ”、” First episode ”、”C ROM. ”、” official ” etc. , It contains a lot of content , And look at the whole text news page , The most frequently used adjectives .
People rank top 20 There are three character names in the vocabulary of :” Lionel messi ”、”C ROM. ”、” Mu Shuai ”. As players, the first two people account for a large proportion in pictures and videos , Mourinho is the only one among the top news keywords 20 My coach .
Technical articles rank top 20 In the vocabulary of , Words related to football match descriptions are mainly concentrated in videos , The second is pictures , The content outside the field of text news accounts for a large space .
Writing is so , How to write good news headlines , Or how to write the title of sina sports ? To solve this problem , The author will cover all the titles before 100 Network analysis of relevance of news headlines :
After finishing, it is as follows , What about? , Can you summarize a news headline ?
Publisher : Full stack programmer stack length , Reprint please indicate the source :https://javaforall.cn/149822.html Link to the original text :https://javaforall.cn
边栏推荐
- 开户注册挖财安全吗?有没有风险的?靠谱吗?
- 《ClickHouse原理解析与应用实践》读书笔记(5)
- 2022最新中高级Android面试题目,【原理+实战+视频+源码】
- ClickHouse(03)ClickHouse怎么安装和部署
- Whether to take a duplicate subset with duplicate elements [how to take a subset? How to remove duplicates?]
- Is it complicated to open an account? Is online account opening safe?
- Case sharing | integrated construction of data operation and maintenance in the financial industry
- Use of websocket tool
- 技术分享 | 常见接口协议解析
- Take a look at semaphore, the current limiting tool provided by JUC
猜你喜欢

Insufficient picture data? I made a free image enhancement software

A2L file parsing based on CAN bus (3)

解决 contents have differences only in line separators
Record eval() and no in pytoch_ grad()
How to automatically install pythn third-party libraries
Idea configuring NPM startup

ICML2022 | 长尾识别中分布外检测的部分和非对称对比学习
Reptile 01 basic principles of reptile
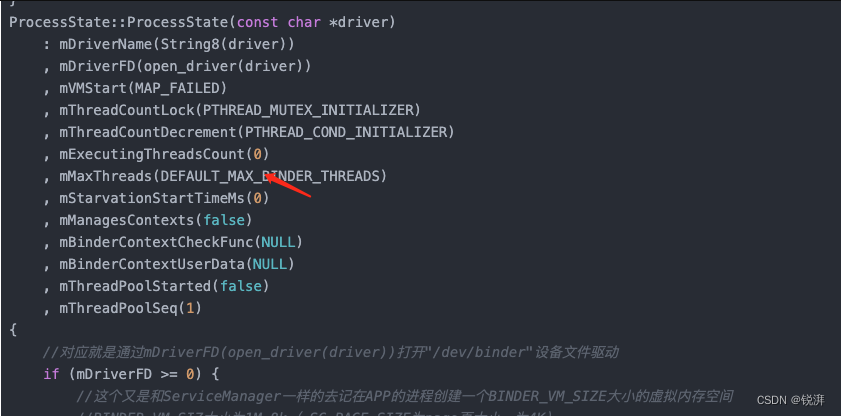
The main thread anr exception is caused by too many binder development threads
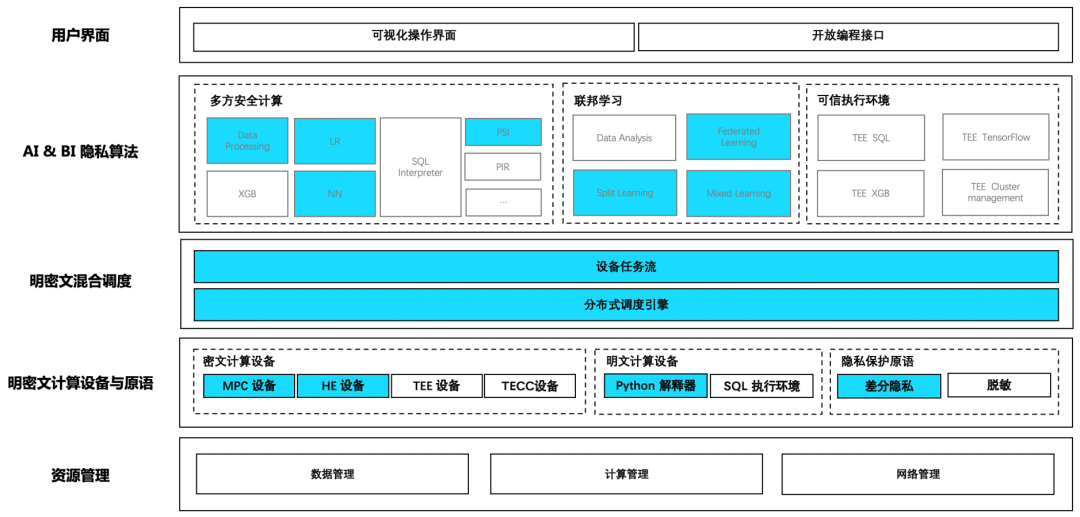
蚂蚁集团开源可信隐私计算框架「隐语」:开放、通用
随机推荐
lombok @Builder注解
[QNX hypervisor 2.2 user manual]6.3.2 configuring VM
Memory management chapter of Kobayashi coding
Record a case of using WinDbg to analyze memory "leakage"
Tupu software digital twin | visual management system based on BIM Technology
Rse2020/ cloud detection: accurate cloud detection of high-resolution remote sensing images based on weak supervision and deep learning
@Extension、@SPI注解原理
爱因斯坦求和einsum
蚂蚁集团开源可信隐私计算框架「隐语」:开放、通用
Electron安装问题
瀚升优品app翰林优商系统开发功能介绍
Thoroughly understand why network i/o is blocked?
LeetCode 6109. 知道秘密的人数
Insufficient picture data? I made a free image enhancement software
MySQL优化六个点的总结
Crontab 日志:如何记录我的 Cron 脚本的输出
How to choose the most formal and safe external futures platform?
websocket 工具的使用
FCN: Fully Convolutional Networks for Semantic Segmentation
The 2022 China Xinchuang Ecological Market Research and model selection evaluation report released that Huayun data was selected as the mainstream manufacturer of Xinchuang IT infrastructure!