当前位置:网站首页>Memory management chapter of Kobayashi coding
Memory management chapter of Kobayashi coding
2022-07-05 18:03:00 【Luo Xiaohei has a good war record】
Kobayashi coding Official website of the course
Four memory management
Single chip microcomputer has no operating system , Single chip microcomputer CPU yes Direct memory operation Of 「 Physical address 」. under these circumstances , To be in memory It is impossible to run two programs at the same time . If the first program is in 2000 Write a new value at the position of , Will erase everything that the second program stored in the same location .
The operating system provides a mechanism , Put the address used by the process 「 Isolation 」 Open , Let the operating system assign each process a separate set of 「 Virtual address 」. Map the virtual address of different processes to the physical address of different memory .
If you want to access the virtual address , From the operating system to a different physical address , So when different processes are running , Write a different physical address , such There will be no conflict .
- The memory address used by our program is called virtual memory address (Virtual Memory Address)
- The actual space address in the hardware is called the physical memory address (Physical Memory Address).
The program is made up of several logical segments , If it can be segmented by code 、 Data segmentation 、 Stack segment 、 The stack section consists of . Different segments have different properties , So we use segmentation (Segmentation) To separate these segments out .
It's a good way to segment , It solves the problem that the program itself does not need to care about the specific physical memory address , But it also has some shortcomings :
The first is memory fragmentation .
The second problem is the low efficiency of memory exchange .
Open program 123 , When the second program is finished , Memory usage will become discontinuous . That can be occupied by fragmented programs A few MB The memory is written to the hard disk , And then read it back from the hard disk to the memory . But when I read it back , We can't load it back to its original location , It's following the occupied one 512MB Behind memory . Namely By moving out and back , Integrate a continuous space , Then the new program can be loaded .
This memory swap space , stay Linux In the system , That's what we often see Swap Space , This space is Divided from the hard disk , For space exchange between memory and hard disk .
For multi process systems , In a segmented way , Memory fragmentation is very easy to create , Memory fragmentation is generated , That has to be renewed Swap Memory area , The access speed of hard disk is much slower than that of memory , This process creates performance bottlenecks .
In order to solve memory fragmentation and memory segmentation Low exchange efficiency The problem of , And that's what happened paging .
Paging is cutting the entire virtual and physical memory space into segments of fixed size . Such a continuous and fixed size memory space , We call it page (Page). stay Linux Next , The size of each page is 4KB.
Because the memory space is pre divided , It won't create memory with very small gaps like segmentation , That's why fragmentation can cause memory fragmentation . Paging is used , Then the memory released is Released in pages , It will not generate small memory that cannot be used by the process . If there's not enough memory , The operating system will put other running processes in 「 It hasn't been used recently 」 To release the memory page of , That is to write it on the hard disk temporarily , It's called swapping out (Swap Out). Once you need it , Then load in , It's called swapping in (Swap In).
stay 32 In a bit environment , Virtual address spaces share 4GB, Suppose the size of a page is 4KB(2^12), So it takes about 100 ten thousand (2^20) A page , Every 「 Page table item 」 need 4 Byte size to store , So the whole 4GB Space mapping needs to have 4MB To store the page table .
this 4MB The size of the page table , It doesn't look very big either . But know that each process has its own virtual address space , In other words, they all have their own page tables . At this time of the The table used to convert the number of recorded pages takes up too much space .
To solve the above problems , We need to adopt a method called multi-level page table (Multi-Level Page Table) Solutions for .
So let's take this 100 More than a 「 Page table item 」 Pagination of single level page table of , Page table ( First level page table ) It is divided into 1024 Page tables ( Second level page table ), Each table ( Second level page table ) Contained in the 1024 individual 「 Page table item 」, formation Secondary paging .
If the page table entry of a first level page table is not used , There is no need to create the secondary page table corresponding to this page table item , That is to say, you can Create a secondary page table only when necessary . Do a simple calculation , Assuming that only the 20% The first level page table item of is used , Then the page table takes up only 4KB( First level page table ) + 20% * 4MB( Second level page table )= 0.804MB, This is compared to the single level page table 4MB Is it a huge saving ?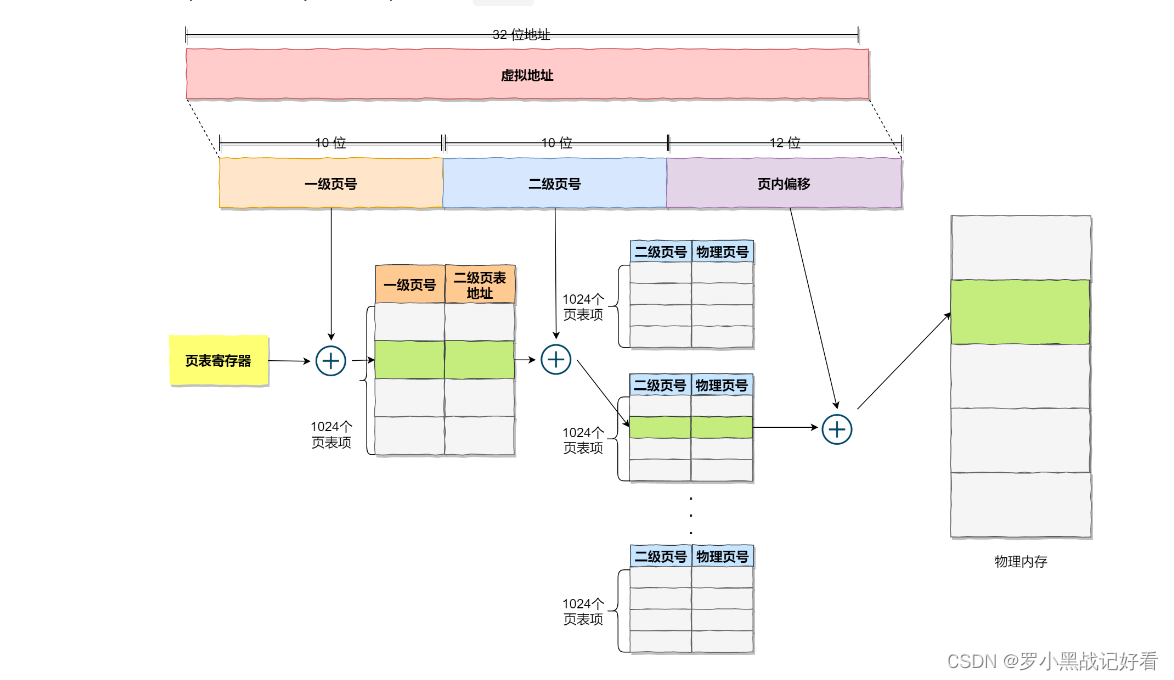
So why can't a hierarchical page table save memory like this ?
From the nature of the page table , The page table stored in memory is responsible for translating virtual address into physical address . If the virtual address cannot find the corresponding page table entry in the page table , The computer system won't work . So the page table must cover all the virtual address space , The page table without grading needs to have 100 More than ten thousand page table entries to map , Second level paging only needs 1024 Page table items ( At this time, the first level page table covers all the virtual address space , Secondary page tables are created when needed ).
about 64 A system of , Two level paging is definitely not enough , It becomes a four level catalog , Namely :
Global page directory entry PGD(Page Global Directory);
Top page directory entry PUD(Page Upper Directory);
Middle page directory entry PMD(Page Middle Directory);
Page table item PTE(Page Table Entry);
Although the multi-level page table solves the space problem , But the conversion from virtual address to physical address There are several more conversion processes , This obviously slows down the speed of these two address translation , That is to say, it brings time cost .【 It's so busy , Why do you want both fish and bear paws !】
Programs are local , For a period of time , The execution of the whole program is limited to one part of the program . Accordingly , The memory space accessed by the execution is also limited to a certain memory area .
We can take advantage of this feature , Store the most frequently accessed page table entries to faster hardware , So computer scientists , It's just CPU In chip , Added a special storage program most frequently accessed page table entries Cache, This Cache Namely TLB(Translation Lookaside Buffer) , It's often called page table caching 、 Address bypass cache 、 Quick watch, etc .
With TLB after , that CPU In addressing , Meeting First check TLB, If not , Will continue to look up the regular page table .TLB The hit rate is actually very high , Because the most frequently visited pages are just a few .
Okay , Nothing else . Sum up :
In order to get the physical address in segment page address transformation, three memory accesses are required :
The first time you access the segment table , Get the starting address of the page table ;
Second visit TLB Or page table , Get the physical page number ;
For the third time, combine the physical page number with the page displacement , Get the physical address .
Linux The strategy of
Linux Don't want to segment , But he used Intel The hardware flow in the processor must have segmented steps . therefore Linux Every segment in the system is from 0 The whole beginning of the address 4GB Virtual space (32 Bit environment ), In other words, the starting address of all segments is the same . It means ,Linux Code in the system , Including the operating system itself code and application code , The address space we are facing is linear address space ( Virtual address ), This is equivalent to masking the concept of logical address in the processor , Segments are used only for access control and memory protection .
stay Linux Operating system , The interior of the virtual address space is divided into Kernel space and user space Two parts , Systems with different digits , The scope of the address space is also different
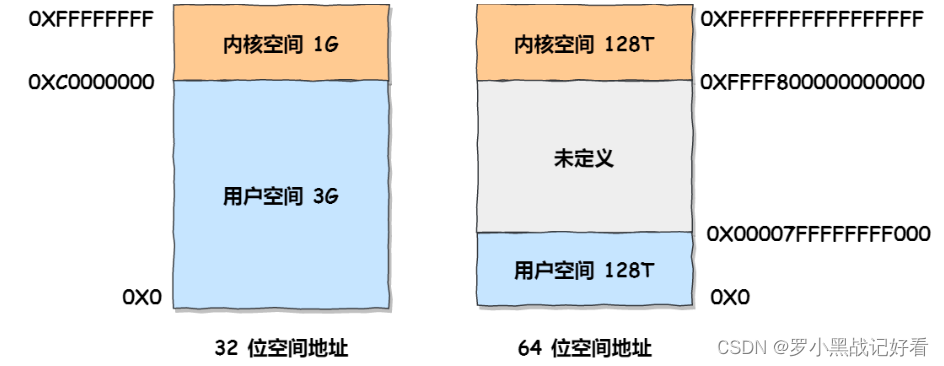
When the process is in user mode , Can only access user space memory ;
Only after entering kernel state , To access the memory in kernel space .
Although each process has its own virtual memory , But the kernel address in each virtual memory , In fact, they are all related to the same physical memory . such , After the process switches to kernel mode , You can easily access kernel space memory .【 acutely Didn't the beginning of the article say that this set of virtual addresses was made to avoid the same physical address 】
User space memory , The difference from low to high is 6 Different memory segments :
- Program file segment (.text), Including binary executable code ;
- Initialized data segment (.data), Including static constants ;
- Uninitialized data segment (.bss), Including uninitialized static variables ;
- Reactor section , Including dynamically allocated memory , From low address to up ;
- File mapping segment , Including dynamic libraries 、 Shared memory, etc , From low address to up ( It's about hardware and kernel versions (opens new window));
- Stack segment , This includes the context of local variables and function calls . The size of the stack is fixed , It's usually 8 MB. Of course, the system also provides parameters , So we can customize the size ;
Here 7 In memory segments , Memory for heap and file map segments is dynamically allocated . for instance , Use C Standard library malloc() perhaps mmap() , You can dynamically allocate memory in the heap and file map segments, respectively .
malloc
malloc() Allocated is virtual memory , When allocating memory, the memory pool will be pre allocated with more space required .malloc(1) Actually pre allocated 132K Bytes of memory .
malloc There are two ways to obtain memory and apply to the operating system Heap memory :
If the memory allocated by the user is less than 128 KB, Through brk() Application memory ;
If the memory allocated by the user is greater than 128 KB, Through mmap() Application memory ;
adopt free After releasing memory , Heap memory still exists , Not returned to the operating system .
This is because instead of putting this 1 Bytes are released to the operating system , Why don't you cache it and put it in malloc In the memory pool , When the process applies again 1 Bytes of memory can be reused directly , This speed is much faster .
Of course , When the process exits , The operating system will recycle all the resources of the process .
Above said free There is still heap memory after memory , Is aimed at malloc adopt brk() How to apply for memory .
If malloc adopt mmap Memory requested by ,free After the memory is released, it will be returned to the operating system .
Why not use all mmap To allocate memory ?
Because the request for memory from the operating system , It is to be called through the system , The execution of system calls is to enter the kernel state , Then return to the user state , The switching of running state will It takes a lot of time .
Why not use all brk To allocate ?
If we apply continuously 10k,20k,30k These three pieces of memory , If 10k and 20k These two pieces release , Become free memory space , If the memory requested next time is less than 30k, Then you can reuse this free memory space . But if it is greater than 30k, Then you have to apply for additional memory , And that 30k already free The memory will not be returned to the system , Over time, it will cause Memory leak .


Um. ? No contradiction ?malloc(1) It directly exceeds the threshold ?
Application through malloc When the function applies for memory , In fact, the application is virtual memory , Physical memory is not allocated at this time .
When the application reads and writes this virtual memory ,CPU Will access this virtual memory , At this time, you will find that the virtual memory is not mapped to the physical memory , CPU There will be a page break , The process will switch from user mode to kernel mode , And give the page missing interrupt to the kernel Page Fault Handler ( Missing page interrupt function ) Handle .
The missing page interrupt handler will see if there is free physical memory , If there is , Just allocate physical memory directly , And establish the mapping relationship between virtual memory and physical memory .
If there is no free physical memory , Then the kernel will begin to reclaim memory , There are two main ways of recycling : Direct memory recycling and background memory recycling .
- Memory recovery in the background (kswapd): When physical memory is tight , Will wake up kswapd
Kernel threads to reclaim memory , The process of reclaiming memory is asynchronous , It will not block the execution of the process . - Reclaim memory directly (direct reclaim): If the background asynchronous recycling cannot keep up with the speed of process memory request , Will start recycling directly , The process of reclaiming memory is synchronous , Will block the execution of the process .【 ah , Is the program not responding because it is reclaiming memory ?
If the memory is recycled directly , The free physical memory is still unable to meet the physical memory application , Then the kernel will select a process that occupies a high amount of physical memory according to the algorithm , And kill it , To free up memory resources , If the physical memory is still low ,OOM Killer Will continue Kill processes that occupy high physical memory , Until enough memory locations are freed .【 Kill ? It's the program that crashes and dodges ? Not to delete other running programs ?】
What memory can be recycled ?
Recycle infrequently accessed memory page data first . And make sure there is a backup in the disk before recycling , If you don't save it to disk, save a copy first, and then delete it in memory .
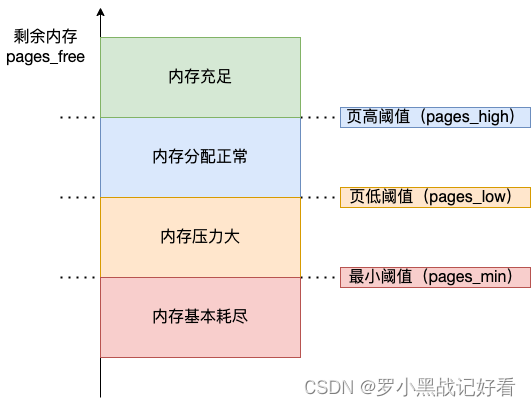
Orange part of the picture : If there is memory left (pages_free) Low threshold on page (pages_low) And page minimum threshold (pages_min) Between , It indicates that the memory pressure is relatively high , There is not much memory left . At this time kswapd0 Will perform memory reclamation , Until the remaining memory is greater than the high threshold (pages_high) until . Although it will trigger memory recycling , But it won't block the application , Because the relationship between the two is asynchronous .
The red part of the picture : If there is memory left (pages_free) Less than the minimum page threshold (pages_min), It means that the user's available memory is exhausted , Direct memory reclamation is triggered at this time , Then the application will be blocked , Because the relationship between the two is synchronous .
If the minimum threshold is set too high , It will make the system reserve too much free memory , This reduces the amount of memory available to the application to a certain extent , This wastes memory to some extent . Set in extreme cases min_free_kbytes Close to the actual physical memory size , The amount of memory left to the application will be too small and can often lead to OOM Happen .
So I'm adjusting min_free_kbytes Before , You need to think about it first , What does the application pay more attention to , If you focus on the delay, increase it appropriately min_free_kbytes, If you focus on memory usage, turn it down appropriately min_free_kbytes.
When the system is out of free memory , The process applied for a large amount of memory , If direct memory recycling cannot reclaim enough free memory , Then it will trigger OOM Mechanism . The kernel will scan the processes in the system that can be killed , And rate each process , The process with the highest score will be killed first .
// points Represents the result of scoring
// process_pages Represents the number of physical memory pages used by the process
// oom_score_adj representative OOM Calibration value
// totalpages Represents the total number of pages available in the system
points = process_pages + oom_score_adj*totalpages/1000
Of each process oom_score_adj The default value is zero 0, So the larger the memory consumed, the easier it is to be killed . If you want a process that can't be killed anyway , Then you can oom_score_adj Configure to -1000.
We'd better put some very important system services oom_score_adj Configure to -1000, such as sshd, Because once these system services are killed , It's hard for us to log into the system again .
however , It is not recommended that our own business process oom_score_adj Set to -1000, Because once a memory leak occurs in a business program , And it can't be killed , This will cause the memory overhead to increase as it increases ,OOM killer Constantly awakened , So as to kill other processes one by one .
stay 32 position /64 Bit operating system environment , What happens when the applied virtual memory exceeds the physical memory ?
stay 32 Bit operating system , Because the process can only apply for 3 GB Size of virtual memory , So apply directly 8G Memory , The application will fail .
stay 64 Bit operating system , Because the process can only apply for 128 TB Size of virtual memory , Even if the physical memory is only 4GB, apply 8G Memory is no problem , Because the requested memory is virtual memory .
Virtual memory requested by the program , If not used , It doesn't take up physical space . After accessing this virtual memory , The operating system will allocate physical memory .
If the requested physical memory size exceeds the free physical memory size , It depends on whether the operating system is turned on Swap Mechanism : When there's pressure on memory usage , Will start triggering the memory reclamation behavior , These infrequently accessed memory will be written to disk first , Then free the memory , Use... For other processes that need it more . When accessing these memories again , Just re read from disk into memory .【 This mechanism makes the memory space that the application can actually use far exceed the physical memory of the system . But it will be too laggy to use 】
If it's not on Swap Mechanism , The program will directly OOM;
If it's on Swap Mechanism , The program can run normally .
边栏推荐
- rsync
- Sophon AutoCV:助力AI工业化生产,实现视觉智能感知
- Mask wearing detection based on yolov3
- Generate classes from XML schema
- Unicode processing in response of flash interface
- Access the database and use redis as the cache of MySQL (a combination of redis and MySQL)
- LeetCode每日一题:合并两个有序数组
- pytorch yolov5 训练自定义数据
- 最大人工岛[如何让一个连通分量的所有节点都记录总节点数?+给连通分量编号]
- Privacy computing helps secure data circulation and sharing
猜你喜欢
Le cours d'apprentissage de la machine 2022 de l'équipe Wunda arrive.

ISPRS2020/云检测:Transferring deep learning models for cloud detection between Landsat-8 and Proba-V
JVM第三话 -- JVM性能调优实战和高频面试题记录

EPM相关
FCN: Fully Convolutional Networks for Semantic Segmentation

Leetcode daily question: merge two ordered arrays

南京大学:新时代数字化人才培养方案探讨
GFS distributed file system
mybash

Leetcode daily practice: rotating arrays
随机推荐
Sophon CE Community Edition is online, and free get is a lightweight, easy-to-use, efficient and intelligent data analysis tool
Generate classes from XML schema
EasyCVR平台通过接口编辑通道出现报错“ID不能为空”,是什么原因?
星环科技数据安全管理平台 Defensor重磅发布
Leetcode daily question: merge two ordered arrays
QT console printout
MATLAB查阅
修复漏洞 - mysql 、es
Anaconda中配置PyTorch环境——win10系统(小白包会)
Sophon kg upgrade 3.1: break down barriers between data and liberate enterprise productivity
Cmake tutorial step1 (basic starting point)
Access the database and use redis as the cache of MySQL (a combination of redis and MySQL)
Matlab built-in function how different colors, matlab subsection function different colors drawing
消除`if()else{ }`写法
Elk log analysis system
小林coding的内存管理章节
tkinter窗口预加载
Teamcenter 消息注册前操作或后操作
EPM相关
Interpretation: how to deal with the current security problems faced by the Internet of things?