当前位置:网站首页>Idea remotely submits spark tasks to the yarn cluster
Idea remotely submits spark tasks to the yarn cluster
2022-07-06 00:28:00 【The south wind knows what I mean】
List of articles
- 1. Local idea Remote submit to yarn colony
- 2. Problems that may be encountered during operation
- 2.1 First of all, we need to put yarn-site.xml,core-site.xml,hdfs-site.xml Put it in resource below , Because these environments are needed when the program is running
- 2.2 Permission problems
- 2.3 Missing environment variable
- 2.4 No settings driver Of ip
- 2.5 Make sure your computer and virtual machine are in the same network segment , And turn off the firewall of your computer , Otherwise, the connection may not be connected .
1. Local idea Remote submit to yarn colony
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010.{
ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.{
SparkConf}
import spark.wordcount.kafkaStreams
object RemoteSubmitApp {
def main(args: Array[String]) {
// Set the user who submits the task
System.setProperty("HADOOP_USER_NAME", "root")
val conf = new SparkConf()
.setAppName("WordCount")
// Set up yarn-client Mode submission
.setMaster("yarn")
// Set up resourcemanager Of ip
.set("yarn.resourcemanager.hostname","master")
// Set up executor The number of
.set("spark.executor.instance","2")
// Set up executor The memory size of
.set("spark.executor.memory", "1024M")
// Set the yarn queue
.set("spark.yarn.queue","spark")
// Set up driver Of ip Address
.set("spark.driver.host","192.168.17.1")
// Set up jar The path of the package , If there are other dependent packages , You can add... Here , commas
.setJars(List("D:\\develop_soft\\idea_workspace_2018\\sparkdemo\\target\\sparkdemo-1.0-SNAPSHOT.jar"
))
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val scc = new StreamingContext(conf, Seconds(1))
scc.sparkContext.setLogLevel("WARN")
//scc.checkpoint("/spark/checkpoint")
val topic = "jason_flink"
val topicSet = Set(topic)
val kafkaParams = Map[String, Object](
"auto.offset.reset" -> "latest",
"value.deserializer" -> classOf[StringDeserializer]
, "key.deserializer" -> classOf[StringDeserializer]
, "bootstrap.servers" -> "master:9092,storm1:9092,storm2:9092"
, "group.id" -> "jason_"
, "enable.auto.commit" -> (true: java.lang.Boolean)
)
kafkaStreams = KafkaUtils.createDirectStream[String, String](
scc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicSet, kafkaParams))
kafkaStreams.foreachRDD(rdd=> {
if (!rdd.isEmpty()) {
rdd.foreachPartition(fp=> {
fp.foreach(f=> {
println(f.value().toString)
})
})
}
})
scc.start()
scc.awaitTermination()
}
}
Then right click to run , Look at the printed log
19/08/16 23:17:24 INFO SparkContext: Running Spark version 2.2.0
19/08/16 23:17:25 INFO SparkContext: Submitted application: WordCount
19/08/16 23:17:25 INFO SecurityManager: Changing view acls to: JasonLee,root
19/08/16 23:17:25 INFO SecurityManager: Changing modify acls to: JasonLee,root
19/08/16 23:17:25 INFO SecurityManager: Changing view acls groups to:
19/08/16 23:17:25 INFO SecurityManager: Changing modify acls groups to:
19/08/16 23:17:25 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(JasonLee, root); groups with view permissions: Set(); users with modify permissions: Set(JasonLee, root); groups with modify permissions: Set()
19/08/16 23:17:26 INFO Utils: Successfully started service 'sparkDriver' on port 62534.
19/08/16 23:17:26 INFO SparkEnv: Registering MapOutputTracker
19/08/16 23:17:26 INFO SparkEnv: Registering BlockManagerMaster
19/08/16 23:17:26 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
19/08/16 23:17:26 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
19/08/16 23:17:26 INFO DiskBlockManager: Created local directory at C:\Users\jason\AppData\Local\Temp\blockmgr-6ec3ae57-661d-4974-8bc9-7357ab4a0c06
19/08/16 23:17:26 INFO MemoryStore: MemoryStore started with capacity 4.1 GB
19/08/16 23:17:26 INFO SparkEnv: Registering OutputCommitCoordinator
19/08/16 23:17:26 INFO log: Logging initialized @2170ms
19/08/16 23:17:26 INFO Server: jetty-9.3.z-SNAPSHOT
19/08/16 23:17:26 INFO Server: Started @2236ms
19/08/16 23:17:26 INFO AbstractConnector: Started [email protected]{
HTTP/1.1,[http/1.1]}{
0.0.0.0:4040}
19/08/16 23:17:26 INFO Utils: Successfully started service 'SparkUI' on port 4040.
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/jobs,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/jobs/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/jobs/job,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/jobs/job/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages/stage,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages/stage/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages/pool,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages/pool/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/storage,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/storage/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/storage/rdd,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/storage/rdd/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/environment,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/environment/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/executors,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/executors/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/executors/threadDump,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/executors/threadDump/json,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/static,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/api,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/jobs/job/kill,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.[email protected]{
/stages/stage/kill,null,AVAILABLE,@Spark}
19/08/16 23:17:26 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.17.1:4040
19/08/16 23:17:26 INFO SparkContext: Added JAR D:\develop_soft\idea_workspace_2018\sparkdemo\target\sparkdemo-1.0-SNAPSHOT.jar at spark://192.168.17.1:62534/jars/sparkdemo-1.0-SNAPSHOT.jar with timestamp 1565968646369
19/08/16 23:17:27 INFO RMProxy: Connecting to ResourceManager at master/192.168.17.142:8032
19/08/16 23:17:27 INFO Client: Requesting a new application from cluster with 2 NodeManagers
19/08/16 23:17:27 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
19/08/16 23:17:27 INFO Client: Will allocate AM container, with 896 MB memory including 384 MB overhead
19/08/16 23:17:27 INFO Client: Setting up container launch context for our AM
19/08/16 23:17:27 INFO Client: Setting up the launch environment for our AM container
19/08/16 23:17:27 INFO Client: Preparing resources for our AM container
19/08/16 23:17:28 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
19/08/16 23:17:31 INFO Client: Uploading resource file:/C:/Users/jason/AppData/Local/Temp/spark-7ed16f4e-0f99-44cf-8553-b4541337d0f0/__spark_libs__5037580728569655338.zip -> hdfs://master:9000/user/root/.sparkStaging/application_1565990507758_0020/__spark_libs__5037580728569655338.zip
19/08/16 23:17:34 INFO Client: Uploading resource file:/C:/Users/jason/AppData/Local/Temp/spark-7ed16f4e-0f99-44cf-8553-b4541337d0f0/__spark_conf__5359714098313821798.zip -> hdfs://master:9000/user/root/.sparkStaging/application_1565990507758_0020/__spark_conf__.zip
19/08/16 23:17:34 INFO SecurityManager: Changing view acls to: JasonLee,root
19/08/16 23:17:34 INFO SecurityManager: Changing modify acls to: JasonLee,root
19/08/16 23:17:34 INFO SecurityManager: Changing view acls groups to:
19/08/16 23:17:34 INFO SecurityManager: Changing modify acls groups to:
19/08/16 23:17:34 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(JasonLee, root); groups with view permissions: Set(); users with modify permissions: Set(JasonLee, root); groups with modify permissions: Set()
19/08/16 23:17:34 INFO Client: Submitting application application_1565990507758_0020 to ResourceManager
19/08/16 23:17:34 INFO YarnClientImpl: Submitted application application_1565990507758_0020
19/08/16 23:17:34 INFO SchedulerExtensionServices: Starting Yarn extension services with app application_1565990507758_0020 and attemptId None
19/08/16 23:17:35 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)
19/08/16 23:17:35 INFO Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: spark
start time: 1565997454105
final status: UNDEFINED
tracking URL: http://master:8088/proxy/application_1565990507758_0020/
user: root
19/08/16 23:17:36 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)
19/08/16 23:17:37 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)
19/08/16 23:17:38 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)
19/08/16 23:17:39 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)
19/08/16 23:17:40 INFO YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(spark-client://YarnAM)
19/08/16 23:17:40 INFO YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> master, PROXY_URI_BASES -> http://master:8088/proxy/application_1565990507758_0020), /proxy/application_1565990507758_0020
19/08/16 23:17:40 INFO JettyUtils: Adding filter: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
19/08/16 23:17:40 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)
19/08/16 23:17:41 INFO Client: Application report for application_1565990507758_0020 (state: RUNNING)
19/08/16 23:17:41 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.17.145
ApplicationMaster RPC port: 0
queue: spark
start time: 1565997454105
final status: UNDEFINED
tracking URL: http://master:8088/proxy/application_1565990507758_0020/
user: root
19/08/16 23:17:41 INFO YarnClientSchedulerBackend: Application application_1565990507758_0020 has started running.
19/08/16 23:17:41 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 62586.
19/08/16 23:17:41 INFO NettyBlockTransferService: Server created on 192.168.17.1:62586
19/08/16 23:17:41 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
19/08/16 23:17:41 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.17.1, 62586, None)
19/08/16 23:17:41 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.17.1:62586 with 4.1 GB RAM, BlockManagerId(driver, 192.168.17.1, 62586, None)
19/08/16 23:17:41 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.17.1, 62586, None)
19/08/16 23:17:41 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.17.1, 62586, None)
19/08/16 23:17:41 INFO ContextHandler: Started o.s.j.s.[email protected]{
/metrics/json,null,AVAILABLE,@Spark}
19/08/16 23:17:44 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.17.145:40622) with ID 1
19/08/16 23:17:44 INFO BlockManagerMasterEndpoint: Registering block manager storm1:44607 with 366.3 MB RAM, BlockManagerId(1, storm1, 44607, None)
19/08/16 23:17:48 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.17.147:58232) with ID 2
19/08/16 23:17:48 INFO YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.8
19/08/16 23:17:48 INFO BlockManagerMasterEndpoint: Registering block manager storm2:34000 with 366.3 MB RAM, BlockManagerId(2, storm2, 34000, None)
19/08/16 23:17:49 WARN KafkaUtils: overriding enable.auto.commit to false for executor
19/08/16 23:17:49 WARN KafkaUtils: overriding auto.offset.reset to none for executor
19/08/16 23:17:49 WARN KafkaUtils: overriding executor group.id to spark-executor-jason_
19/08/16 23:17:49 WARN KafkaUtils: overriding receive.buffer.bytes to 65536 see KAFKA-3135
See that the submission is successful , And then we open up yarn Check the monitoring page of job.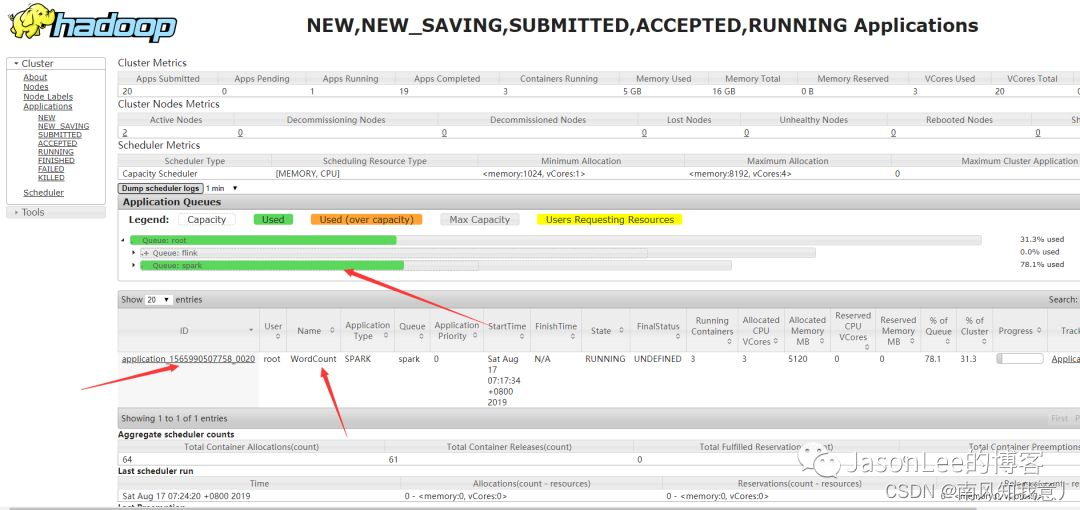
See a spark The program is running , Then we point in , Take a look at the specific operation :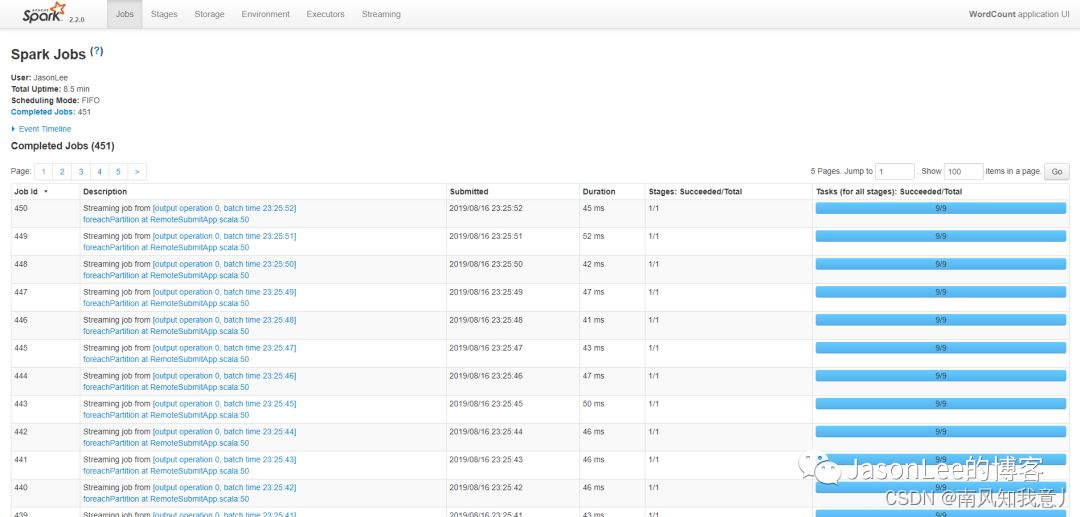
Choose one. job, look down executor Printed logs
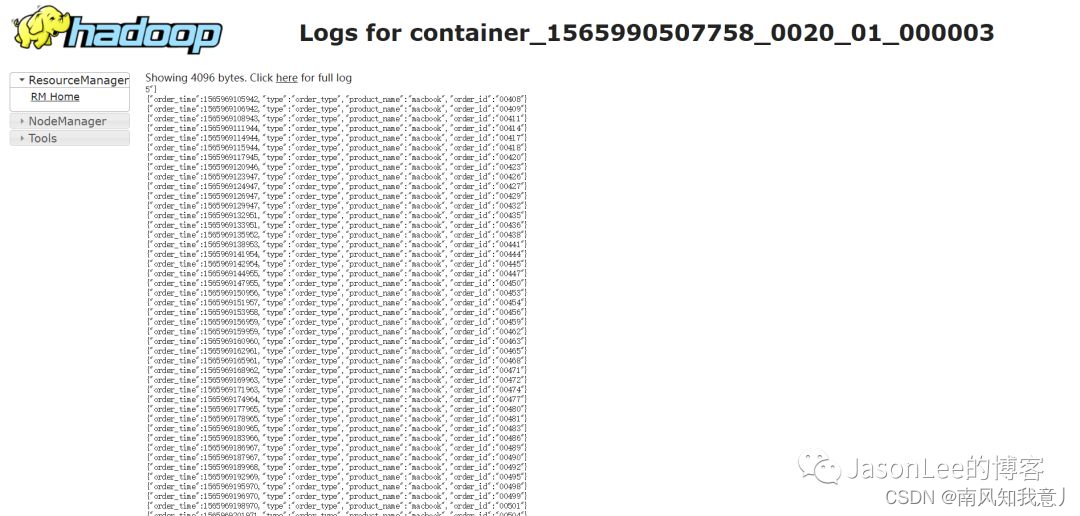
writes kafka The data of , No problem , When it stops , Only need idea Click to stop the program , It will be much easier to test in this way .
2. Problems that may be encountered during operation
2.1 First of all, we need to put yarn-site.xml,core-site.xml,hdfs-site.xml Put it in resource below , Because these environments are needed when the program is running
2.2 Permission problems
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=JasonLee, access=WRITE, inode="/user":root:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:342)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:251)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:189)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1744)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1728)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1687)
at org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:60)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:2980)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1096)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:652)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:503)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:989)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:868)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:814)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1886)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2603)
This is submitted locally, so the user name is JasonLee, It has no access hdfs Authority , The simplest solution is to set the user in the code as root.
System.setProperty("HADOOP_USER_NAME", "root")
2.3 Missing environment variable
Exception in thread "main" java.lang.IllegalStateException: Library directory 'D:\develop_soft\idea_workspace_2018\sparkdemo\assembly\target\scala-2.11\jars' does not exist; make sure Spark is built.
at org.apache.spark.launcher.CommandBuilderUtils.checkState(CommandBuilderUtils.java:248)
at org.apache.spark.launcher.CommandBuilderUtils.findJarsDir(CommandBuilderUtils.java:347)
at org.apache.spark.launcher.YarnCommandBuilderUtils$.findJarsDir(YarnCommandBuilderUtils.scala:38)
at org.apache.spark.deploy.yarn.Client.prepareLocalResources(Client.scala:526)
at org.apache.spark.deploy.yarn.Client.createContainerLaunchContext(Client.scala:814)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:169)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:56)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:173)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:509)
at org.apache.spark.streaming.StreamingContext$.createNewSparkContext(StreamingContext.scala:839)
at org.apache.spark.streaming.StreamingContext.<init>(StreamingContext.scala:85)
at spark.RemoteSubmitApp$.main(RemoteSubmitApp.scala:31)
at spark.RemoteSubmitApp.main(RemoteSubmitApp.scala)
This error is reported because we have no configuration SPARK_HOME Environment variables of , Directly in idea Inside configurations Inside environment variables It set up SPARK_HOME That's all right. , As shown in the figure below :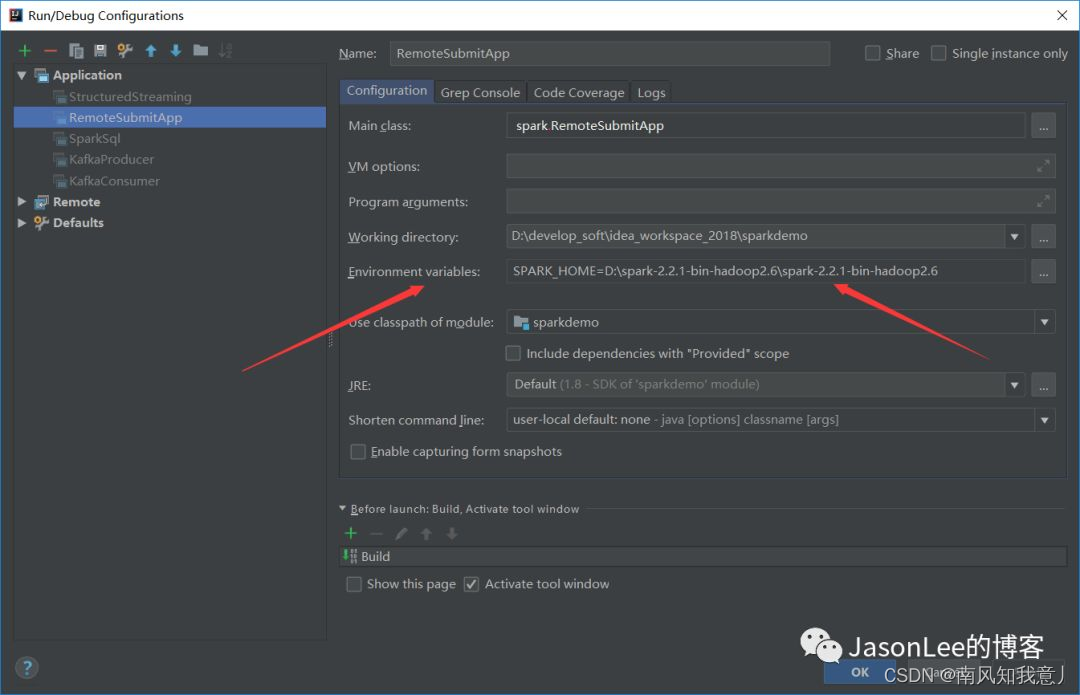
2.4 No settings driver Of ip
9/08/17 07:52:45 ERROR ApplicationMaster: Failed to connect to driver at 169.254.42.204:64010, retrying ...
19/08/17 07:52:48 ERROR ApplicationMaster: Failed to connect to driver at 169.254.42.204:64010, retrying ...
19/08/17 07:52:48 ERROR ApplicationMaster: Uncaught exception:
org.apache.spark.SparkException: Failed to connect to driver!
at org.apache.spark.deploy.yarn.ApplicationMaster.waitForSparkDriver(ApplicationMaster.scala:577)
at org.apache.spark.deploy.yarn.ApplicationMaster.runExecutorLauncher(ApplicationMaster.scala:433)
at org.apache.spark.deploy.yarn.ApplicationMaster.run(ApplicationMaster.scala:256)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anonfun$main$1.apply$mcV$sp(ApplicationMaster.scala:764)
at org.apache.spark.deploy.SparkHadoopUtil$$anon$2.run(SparkHadoopUtil.scala:67)
at org.apache.spark.deploy.SparkHadoopUtil$$anon$2.run(SparkHadoopUtil.scala:66)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1692)
at org.apache.spark.deploy.SparkHadoopUtil.runAsSparkUser(SparkHadoopUtil.scala:66)
at org.apache.spark.deploy.yarn.ApplicationMaster$.main(ApplicationMaster.scala:762)
at org.apache.spark.deploy.yarn.ExecutorLauncher$.main(ApplicationMaster.scala:785)
at org.apache.spark.deploy.yarn.ExecutorLauncher.main(ApplicationMaster.scala)
This error is reported because it is not set driver host, Because what we're running is yarn-client Pattern ,driver It's our local machine , So set the local ip, Or we can't find it driver.
.set("spark.driver.host","192.168.17.1")
2.5 Make sure your computer and virtual machine are in the same network segment , And turn off the firewall of your computer , Otherwise, the connection may not be connected .
边栏推荐
- Yolov5, pychar, Anaconda environment installation
- [Chongqing Guangdong education] reference materials for Zhengzhou Vocational College of finance, taxation and finance to play around the E-era
- Recognize the small experiment of extracting and displaying Mel spectrum (observe the difference between different y_axis and x_axis)
- The global and Chinese markets of dial indicator calipers 2022-2028: Research Report on technology, participants, trends, market size and share
- Location based mobile terminal network video exploration app system documents + foreign language translation and original text + guidance records (8 weeks) + PPT + review + project source code
- 如何解决ecology9.0执行导入流程流程产生的问题
- Solve the problem of reading Chinese garbled code in sqlserver connection database
- Configuring OSPF GR features for Huawei devices
- 2022-02-13 work record -- PHP parsing rich text
- 小程序技术优势与产业互联网相结合的分析
猜你喜欢
Calculate sha256 value of data or file based on crypto++
Permission problem: source bash_ profile permission denied
【DesignMode】组合模式(composite mode)

LeetCode 1189. Maximum number of "balloons"
多线程与高并发(8)—— 从CountDownLatch总结AQS共享锁(三周年打卡)
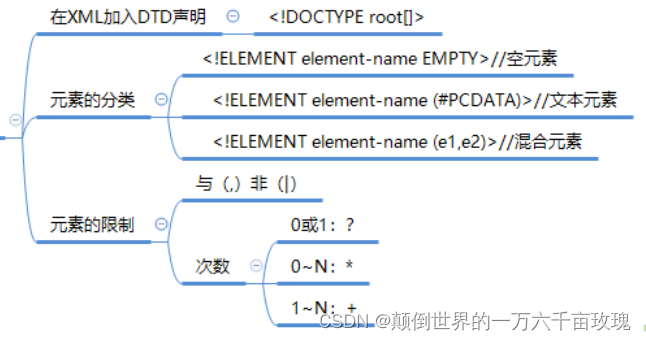
XML Configuration File
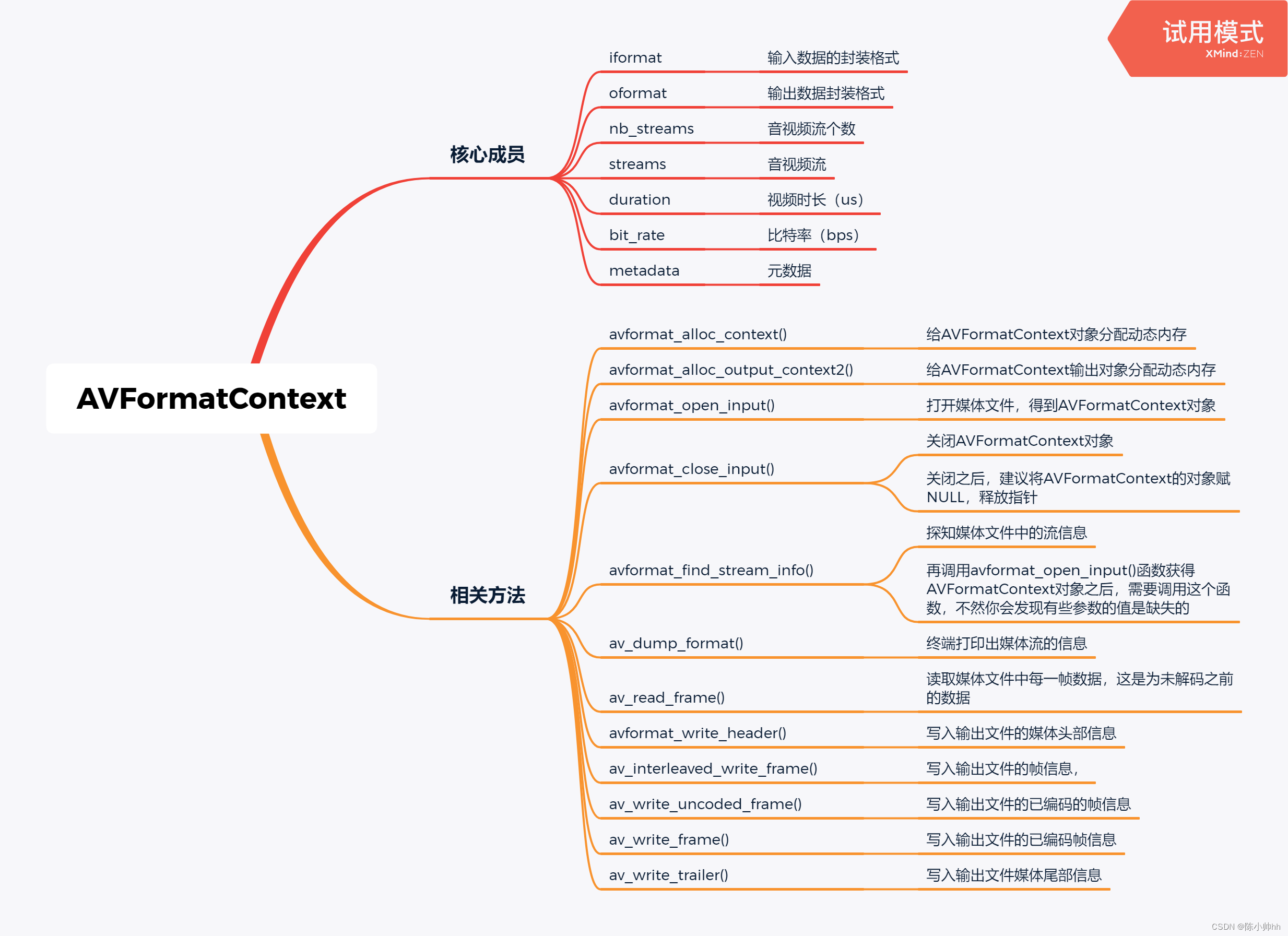
Key structure of ffmpeg - avformatcontext

Opencv classic 100 questions
MDK debug时设置数据实时更新

Analysis of the combination of small program technology advantages and industrial Internet
随机推荐
How to use the flutter framework to develop and run small programs
XML Configuration File
Calculate sha256 value of data or file based on crypto++
SQLServer连接数据库读取中文乱码问题解决
Global and Chinese market of water heater expansion tank 2022-2028: Research Report on technology, participants, trends, market size and share
Global and Chinese markets of POM plastic gears 2022-2028: Research Report on technology, participants, trends, market size and share
时间戳的拓展及应用实例
Idea远程提交spark任务到yarn集群
NSSA area where OSPF is configured for Huawei equipment
Go learning --- read INI file
Power Query数据格式的转换、拆分合并提取、删除重复项、删除错误、转置与反转、透视和逆透视
【DesignMode】装饰者模式(Decorator pattern)
MySql——CRUD
Gd32f4xx UIP protocol stack migration record
7.5 simulation summary
Problems encountered in the database
Hardware and interface learning summary
Notepad++ regular expression replacement string
MySql——CRUD
Shardingsphere source code analysis