当前位置:网站首页>Adaptive personalized federated learning paper interpretation + code analysis
Adaptive personalized federated learning paper interpretation + code analysis
2022-06-12 07:17:00 【Programmer long】
The address of the paper is here
One . Introduce
Federal learning emphasizes ensuring local privacy , Train multiple clients , Clients do not exchange data but exchange parameters to communicate . The goal is to aggregate into a global model , Make this model read on each client and get better results . Federal learning FedAvg The most extensive method , However, due to the inherent diversity between local data slices and the high degree of data re client iid( Independent homologous distribution ),FedAvg Very sensitive to super parameters , Can't benefit from a good Bracelet guarantee . Therefore, in the case of equipment heterogeneity , The global model cannot well summarize the individual local data of each customer .
As the diversity of client data increases , Global model and personalization ( client ) The error of the model will be larger and larger , A good global model leads to a bad local client model .
In this work , The author proposes a new federal learning framework , The framework optimizes the performance of all customers . The reduction of generalization error depends on the distribution characteristics of local data . therefore , The goal of the model is to tend to learn a personalized model that combines global and local models . But the difficulty is how to ensure that the local data is a global model suitable for all customers .
Two . Related work
The main goal of Federated learning is to learn a global model , This global model is good enough for data that has not yet been seen , And it can quickly converge to the local optimum , This is similar to meta - learning . But despite this similarity , The meta learning method is mainly to learn multiple models with common sense , Personalized learning for each new task , And in most federal studies , Focus more on a single global model . The difference between the global model and the local model is an important manifestation of personalization . There are three main categories of personalization in federal learning , Local trim , Multitasking and situational learning .
Local trim (Local fine tuning): Local tuning means that each client receives a global model , And use your own local data and several gradient descent steps to tune it , This method mainly combines meta learning .
Multi task learning (multi_task learning): Another view of personalization is that it is a multi task learning problem . The optimization of each client under this setting can be seen as a new task .
Situational (Contextualization): An important application of personalized federated learning is to use models in different situations . We need to personalize a client in different environments .
Personalize through model blending (Personalization via mixing models): By mixing global and local models, different personalized methods are introduced to conduct federated learning . Based on this , There are three different ways to personalize , Customer clustering 、 Data interpolation and model interpolation . The first two destroy data privacy , Only the third mode is more reasonable .
3、 ... and . Personalized federal learning
3.1 Definition :
D i : D_i : Di: The first i Datasets on clients ( There are labels )
D ˉ = ( 1 / n ) ∑ i = 1 n D i \bar{D} = (1/n)\sum_{i=1}^{n}D_i Dˉ=(1/n)∑i=1nDi: The average distribution of all clients
L D i ( h ) = E ( x , y ) ∈ D i [ l ( h ( x ) , y ) ] : \mathcal{L}_{D_i}(h) = \mathbb{E}_{(x,y)\in D_i}[\mathcal{l(h(x),y)}]: LDi(h)=E(x,y)∈Di[l(h(x),y)]: On the client side i The real risk of .
L ^ D i ( h ) : \widehat{\mathcal{L}}_{D_i}(h): LDi(h): On the client side i On the h Experience risk
3.2 Personalised models
In a standard federated learning scenario , The goal is to learn a global model for all devices . At the same time, each client has a local model , In adaptive personalized federated learning , The goal is to find the optimal combination of global model and local model , To achieve a better model for customers . In this setup , Each user trains a local model , At the same time, some global models are merged , And use some blend weights , The mathematical expression is as follows :
h α i = α i h ^ i ∗ + ( 1 − α i ) h ˉ ∗ h_{\alpha_i} = \alpha_i \widehat{h}_i^*\ +\ (1 -\alpha_i )\bar{h}^* hαi=αihi∗ + (1−αi)hˉ∗
among h ˉ ∗ = a r g min h ∈ H L ^ D ˉ ( h ) \bar{h}^* = arg\min_{h\in\mathcal{H}}\widehat{\mathcal{L}}_{\bar{D}}(h) hˉ∗=argminh∈HLDˉ(h) Optimize the minimum for the overall experience ,
h ^ i ∗ = a r g min h ∈ H L ^ D ˉ ( α i h + ( 1 − α i ) h ˉ ∗ ) \widehat{h}_i^* = arg\min_{ {h\in\mathcal{H}}}\widehat{\mathcal{L}}_{\bar{D}}(\alpha_ih+(1-\alpha_i)\bar{h}^*) hi∗=argminh∈HLDˉ(αih+(1−αi)hˉ∗) It's one in the i A hybrid model that achieves minimum loss on clients .
( Let me explain , That is to say, our model consists of two parts , One is the global model , The other is the client model , As for why the client model is composed of a mixture ? Here, consider multiple rounds of training , hypothesis t-1 The global model of the wheel is w, The local model is v, Then we fuse it into a hybrid model h=w+v. stay t When the wheel , The global model is new w, The local model is inheritance t-1 A hybrid model of the wheel h, So the corresponding v It can be referred to as the local model )
3.3 APFL Algorithm
Just like the traditional meaning of federal learning , The server needs to address the following objectives :
min w ∈ R d [ F ( w ) = 1 n ∑ i = 1 n { f i ( w ) = E ξ [ f i ( w , ξ i ) ] } ] \min_{\mathcal{w}\in \mathbb{R^d}}[F(w)=\frac{1}{n}\sum_{i=1}^n\{f_i(w)=\mathbb{E_\xi[f_i(w,\xi_i)]}\}] w∈Rdmin[F(w)=n1i=1∑n{ fi(w)=Eξ[fi(w,ξi)]}]
The client adopts the above method ( Individualization )
min v ∈ R d f i ( α i v + ( 1 − a l p h a i ) w ∗ ) \min_{\mathcal{v}\in \mathbb{R^d}}f_i(\alpha_iv+(1-alpha_i)w^*) v∈Rdminfi(αiv+(1−alphai)w∗)
among w ∗ = a r g min w F ( w ) w^*=arg\min_w F(w) w∗=argminwF(w)
The specific steps are as follows :
For training clients , There are two parameters . One is w: Global parameter , One is v: Own parameters . First, according to the data set w updated ( use t-1 Parameters of the wheel ). Yes v The same is true of the update method ,v By mixing parameters ( v ˉ \bar{v} vˉ) Calculate the gradient to update , After that, the new w and v Synthesize our current mixing parameters , And then w Send it to the server for merging .
3.4 α \alpha α The value of
Intuitive to see , When the local data is more uniform , When the local model of each client is close to the global model, we need smaller α \alpha α; contrary , When the diversity of local data is strong , α \alpha α Should be close to 1. We need to update our α \alpha α:
α i ∗ = a r g min α i ∈ [ 0 , 1 ] f i ( α i v + ( 1 − α i ) w ) \alpha^*_i = arg\min_{\alpha_i \in[0,1]}f_i(\alpha_iv+(1-\alpha_i)w) αi∗=argαi∈[0,1]minfi(αiv+(1−αi)w)
We can use gradient descent to update once α \alpha α.
α i ( t ) = α i ( t − 1 ) − η t ∇ α f i ( v ˉ i ( t − 1 ) ; ξ i t ) = α i ( t − 1 ) − η t < v i ( t − 1 ) − w i ( t − 1 ) , ∇ f i ( v ˉ i ( t − 1 ) ; ξ i t ) > \begin{aligned} \alpha_i^{(t)}&=\alpha_i^{(t-1)}-\eta_t \nabla_\alpha f_i(\bar{v}_i^{(t-1)};\xi_i^t)\\ &=\alpha_i^{(t-1)}-\eta_t <v_i^{(t-1) }-w_i^{(t-1)},\nabla f_i(\bar{v}_i^{(t-1)};\xi_i^t)> \end{aligned} αi(t)=αi(t−1)−ηt∇αfi(vˉi(t−1);ξit)=αi(t−1)−ηt<vi(t−1)−wi(t−1),∇fi(vˉi(t−1);ξit)>
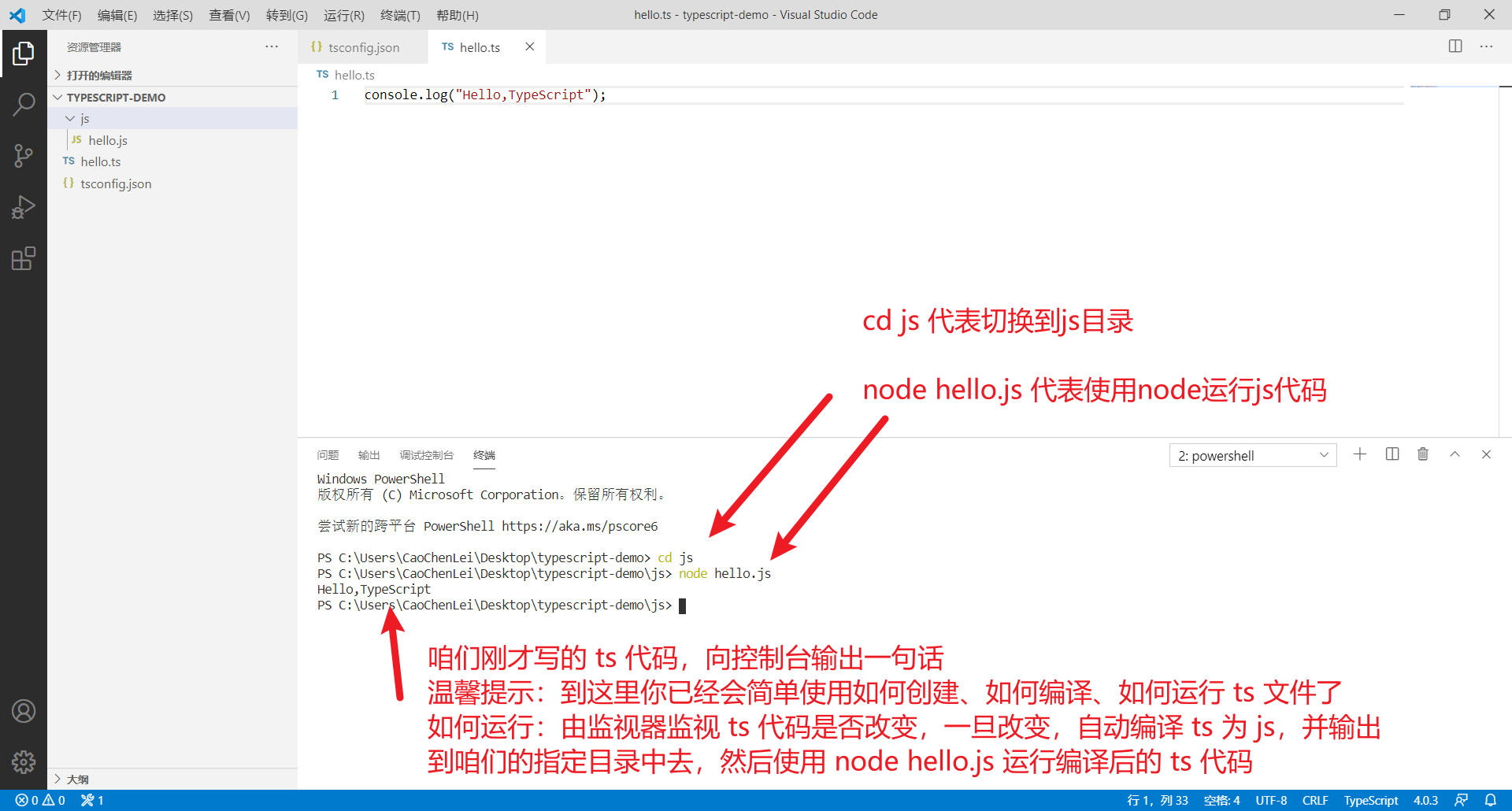
Four . Key code analysis
Author's code github Address here , This github There are many other federated learning algorithms , This is only for APFL Explain the algorithm .
APFL The main difference is in the update of the client , So we interpret the client training .
The first is the global model parameters w Update
Read data directly , Seeking loss , use SGD to update
_input, _target = load_data_batch(client.args, _input, _target, tracker)
# Skip batches with one sample because of BatchNorm issue in some models!
if _input.size(0)==1:
is_sync = is_sync_fed(client.args)
break
# inference and get current performance.
client.optimizer.zero_grad()
loss, performance = inference(client.model, client.criterion, client.metrics, _input, _target)
# compute gradient and do local SGD step.
loss.backward()
client.optimizer.step(
apply_lr=True,
apply_in_momentum=client.args.in_momentum, apply_out_momentum=False
)
The next step is to update the local model parameters v:
client.optimizer_personal.zero_grad()
loss_personal, performance_personal = inference_personal(client.model_personal, client.model,
client.args.fed_personal_alpha, client.criterion,
client.metrics, _input, _target)
# compute gradient and do local SGD step.
loss_personal.backward()
client.optimizer_personal.step(
apply_lr=True,
apply_in_momentum=client.args.in_momentum, apply_out_momentum=False
)
It's the same , To get a batch data , Seeking loss , Note that the parameter corresponding to the loss is the mixing parameter of the previous round , Not just local parameters , The mixed parameter loss code is as follows :
In fact, it is to use α \alpha α To synthesize the mixing parameters and calculate the loss
def inference_personal(model1, model2, alpha, criterion, metrics, _input, _target):
"""Inference on the given model and get loss and accuracy."""
# TODO: merge with inference
output1 = model1(_input)
output2 = model2(_input)
output = alpha * output1 + (1-alpha) * output2
loss = criterion(output, _target)
performance = accuracy(output.data, _target, topk=metrics)
return loss, performance
In fact, it has been realized here APFL, But there is another key point , Each round is more detailed before training α \alpha α, adopt 3.4 Update the way of explanation in section :
def alpha_update(model_local, model_personal,alpha, eta):
grad_alpha = 0
for l_params, p_params in zip(model_local.parameters(), model_personal.parameters()):
## Here for v - w
dif = p_params.data - l_params.data
## Here for f(\bar{v} The loss of )
grad = alpha * p_params.grad.data + (1-alpha)*l_params.grad.data
## Just multiply it
grad_alpha += dif.view(-1).T.dot(grad.view(-1))
grad_alpha += 0.02 * alpha
## updated
alpha_n = alpha - eta*grad_alpha
## Make sure that the 0,1 Between
alpha_n = np.clip(alpha_n.item(),0.0,1.0)
return alpha_n
Come here ,APFL That's the end of the algorithm , The last attached apfl The whole training code , It's convenient for you to check :
def train_and_validate_federated_apfl(client):
"""The training scheme of Personalized Federated Learning. Official implementation for https://arxiv.org/abs/2003.13461 """
log('start training and validation with Federated setting.', client.args.debug)
if client.args.evaluate and client.args.graph.rank==0:
# Do the testing on the server and return
do_validate(client.args, client.model, client.optimizer, client.criterion, client.metrics,
client.test_loader, client.all_clients_group, data_mode='test')
return
tracker = define_local_training_tracker()
start_global_time = time.time()
tracker['start_load_time'] = time.time()
log('enter the training.', client.args.debug)
# Number of communication rounds in federated setting should be defined
for n_c in range(client.args.num_comms):
client.args.rounds_comm += 1
client.args.comm_time.append(0.0)
# Configuring the devices for this round of communication
# TODO: not make the server rank hard coded
log("Starting round {} of training".format(n_c), client.args.debug)
online_clients = set_online_clients(client.args)
if (n_c == 0) and (0 not in online_clients):
online_clients += [0]
online_clients_server = online_clients if 0 in online_clients else online_clients + [0]
online_clients_group = dist.new_group(online_clients_server)
if client.args.graph.rank in online_clients_server:
client.model_server = distribute_model_server(client.model_server, online_clients_group, src=0)
client.model.load_state_dict(client.model_server.state_dict())
if client.args.graph.rank in online_clients:
is_sync = False
ep = -1 # counting number of epochs
while not is_sync:
ep += 1
for i, (_input, _target) in enumerate(client.train_loader):
client.model.train()
# update local step.
logging_load_time(tracker)
# update local index and get local step
client.args.local_index += 1
client.args.local_data_seen += len(_target)
get_current_epoch(client.args)
local_step = get_current_local_step(client.args)
# adjust learning rate (based on the # of accessed samples)
lr = adjust_learning_rate(client.args, client.optimizer, client.scheduler)
# load data
_input, _target = load_data_batch(client.args, _input, _target, tracker)
# Skip batches with one sample because of BatchNorm issue in some models!
if _input.size(0)==1:
is_sync = is_sync_fed(client.args)
break
# inference and get current performance.
client.optimizer.zero_grad()
loss, performance = inference(client.model, client.criterion, client.metrics, _input, _target)
# compute gradient and do local SGD step.
loss.backward()
client.optimizer.step(
apply_lr=True,
apply_in_momentum=client.args.in_momentum, apply_out_momentum=False
)
client.optimizer.zero_grad()
client.optimizer_personal.zero_grad()
loss_personal, performance_personal = inference_personal(client.model_personal, client.model,
client.args.fed_personal_alpha, client.criterion,
client.metrics, _input, _target)
# compute gradient and do local SGD step.
loss_personal.backward()
client.optimizer_personal.step(
apply_lr=True,
apply_in_momentum=client.args.in_momentum, apply_out_momentum=False
)
# update alpha
if client.args.fed_adaptive_alpha and i==0 and ep==0:
client.args.fed_personal_alpha = alpha_update(client.model, client.model_personal, client.args.fed_personal_alpha, lr) #0.1/np.sqrt(1+args.local_index))
average_alpha = client.args.fed_personal_alpha
average_alpha = global_average(average_alpha, client.args.graph.n_nodes, group=online_clients_group)
log("New alpha is:{}".format(average_alpha.item()), client.args.debug)
# logging locally.
# logging_computing(tracker, loss, performance, _input, lr)
# display the logging info.
# logging_display_training(args, tracker)
# reset load time for the tracker.
tracker['start_load_time'] = time.time()
is_sync = is_sync_fed(client.args)
if is_sync:
break
else:
log("Offline in this round. Waiting on others to finish!", client.args.debug)
do_validate(client.args, client.model, client.optimizer_personal, client.criterion, client.metrics,
client.train_loader, online_clients_group, data_mode='train', personal=True,
model_personal=client.model_personal, alpha=client.args.fed_personal_alpha)
if client.args.fed_personal:
do_validate(client.args, client.model, client.optimizer_personal, client.criterion, client.metrics,
client.val_loader, online_clients_group, data_mode='validation', personal=True,
model_personal=client.model_personal, alpha=client.args.fed_personal_alpha)
# Sync the model server based on model_clients
log('Enter synching', client.args.debug)
tracker['start_sync_time'] = time.time()
client.args.global_index += 1
client.model_server = fedavg_aggregation(client.args, client.model_server, client.model,
online_clients_group, online_clients, client.optimizer)
# evaluate the sync time
logging_sync_time(tracker)
# Do the validation on the server model
do_validate(client.args, client.model_server, client.optimizer, client.criterion, client.metrics,
client.train_loader, online_clients_group, data_mode='train')
if client.args.fed_personal:
do_validate(client.args, client.model_server, client.optimizer, client.criterion, client.metrics,
client.val_loader, online_clients_group, data_mode='validation')
# logging.
logging_globally(tracker, start_global_time)
# reset start round time.
start_global_time = time.time()
# validate the models at the test data
if client.args.fed_personal_test:
do_validate(client.args, client.model_client, client.optimizer_personal, client.criterion,
client.metrics, client.test_loader, online_clients_group, data_mode='test', personal=True,
model_personal=client.model_personal, alpha=client.args.fed_personal_alpha)
elif client.args.graph.rank == 0:
do_validate(client.args, client.model_server, client.optimizer, client.criterion,
client.metrics, client.test_loader, online_clients_group, data_mode='test')
else:
log("Offline in this round. Waiting on others to finish!", client.args.debug)
dist.barrier(group=client.all_clients_group)
Be careful , Here, please α \alpha α Is the first in every round of training batch Then update , I think the purpose is to prevent the initial w and v The result of initialization has too much impact , So instead of training a batch Post update .
边栏推荐
- Error mcrypt in php7 version of official encryption and decryption library of enterprise wechat_ module_ Open has no method defined and is discarded by PHP. The solution is to use OpenSSL
- Kotlin插件 kotlin-android-extensions
- Difference and application of SPI, UART and I2C communication
- 8 IO Library
- FCPX插件:简约线条呼出文字标题介绍动画Call Outs With Photo Placeholders for FCPX
- RT thread studio learning (x) mpu9250
- Test left shift real introduction
- 8086/8088 instruction execution pipeline disconnection reason
- 晶闸管,它是很重要的,交流控制器件
- Keil installation of C language development tool for 51 single chip microcomputer
猜你喜欢
Complete set of typescript Basics

CL210OpenStack操作的故障排除--章節實驗

ROS dynamic parameter configuration: use of dynparam command line tool (example + code)

Explain ADC in stm32

Elegantly spliced XML

企业微信官方 加解密库 PHP7版本报错 mcrypt_module_open 未定义方法 并且被PHP抛弃 解决方法使用 openssl解决

Pyhon的第四天

8 IO Library

2022年危险化学品经营单位安全管理人员特种作业证考试题库及答案

Detailed explanation of 8086/8088 system bus (sequence analysis + bus related knowledge)
随机推荐
"I was laid off by a big factory"
postman拼接替换参数循环调用接口
【WAX链游】发布一个免费开源的Alien Worlds【外星世界】脚本TLM
私有协议的解密游戏:从秘文到明文
[data clustering] data set, visualization and precautions are involved in this column
Tradeoff and selection of SWC compatible Polyfill
Design an open source continuous deployment pipeline based on requirements
报表工具的二次革命
5 lines of code identify various verification codes
Test manager defines and implements test metrics
SQL -- course experiment examination
Scons编译IMGUI
Imx6q pwm3 modify duty cycle
D
LED lighting experiment with simulation software proteus
Junior high school education, less than 3k, to 30k+ monthly salary, how wonderful life is without restrictions
8 IO Library
paddlepaddl 28 支持任意维度数据的梯度平衡机制GHM Loss的实现(支持ignore_index、class_weight,支持反向传播训练,支持多分类)
“我被大厂裁员了”
[image denoising] salt and pepper noise image denoising based on Gaussian filter, mean filter, median filter and bilateral filter with matlab code attached