当前位置:网站首页>[Pytorch study notes] 11. Take a subset of the Dataset and shuffle the order of the Dataset (using Subset, random_split)
[Pytorch study notes] 11. Take a subset of the Dataset and shuffle the order of the Dataset (using Subset, random_split)
2022-08-05 05:42:00 【takedachia】
(pytorch版本:1.2)
我们在使用Dataset定义好数据集后,These problems are often encountered when dealing with datasets:如何把Dataset拆分成两个子集(as used to specify training and test sets、k折交叉验证等)?How to do random splits?How to scramble oneDataset内数据的顺序?
Dataset取子集、拆分
使用 torch.utils.data.Subset() Data sets can be subsetted.
传入一个Dataset,A sequence sliceindices,to get a subset.
1.我们可以传入一个range():
indices = range(18353) # Take the label as the first0个到第18352个数据
sub_imgs = torch.utils.data.Subset(imgs, indices)
len(imgs), len(sub_imgs)

2.interval can be taken:
indices = range(18353, 27153) # Take the label as the first18353个到第27152个数据
sub_imgs = torch.utils.data.Subset(imgs, indices)
len(imgs), len(sub_imgs)

3.可以传入一个List.有ListYou can use list comprehensions:
indices = [x for x in range(1234)]
sub_imgs = torch.utils.data.Subset(imgs, indices)
len(imgs), len(sub_imgs)

打乱Dataset内数据的顺序
We can pass in an out-of-order one directlyindexIt can achieve the purpose of out-of-order data set:
from torch import randperm
lenth = randperm(len(Leaf_dataset_train)).tolist() # Generate out-of-order indexes
rand_train = torch.utils.data.Subset(imgs, lenth)
# Show the first image、original label
X = rand_train[0]
plt.imshow(torch.transpose(X[0],0,2)), lenth[0]
After we shuffle the order, we can take subsets to perform on the datasetkfold cross-validation and other behaviors.
随机拆分Dataset
使用 torch.utils.data.random_split() The dataset can be split directly,Randomly divided into multiple portions.
可以传入一个List,注意传入的ListThe size of each subset is included in the sequence(数量),And the sum of these numbers must be等于传入Dataset的长度.
示例:
# 这里Leaf_dataset_trainmust be equal in size 17000+1353
train_set, test_set = torch.utils.data.random_split(Leaf_dataset_train, [17000, 1353])
print(len(train_set), len(test_set))

边栏推荐
- flink项目开发-配置jar依赖,连接器,类库
- CVPR 2020 - 频谱正则化
- [Pytorch study notes] 9. How to evaluate the classification results of the classifier - using confusion matrix, F1-score, ROC curve, PR curve, etc. (taking Softmax binary classification as an example)
- 学习总结week3_3迭代器_模块
- 【零基础开发NFT智能合约】如何使用工具自动生成NFT智能合约带白名单可Mint无需写代码
- Comparison and summary of Tensorflow2 and Pytorch in terms of basic operations of tensor Tensor
- A deep learning code base for Xiaobai, one line of code implements 30+ attention mechanisms.
- Pandas(五)—— 分类数据、读取数据库
- [Database and SQL study notes] 9. (T-SQL language) Define variables, advanced queries, process control (conditions, loops, etc.)
- Mesos learning
猜你喜欢
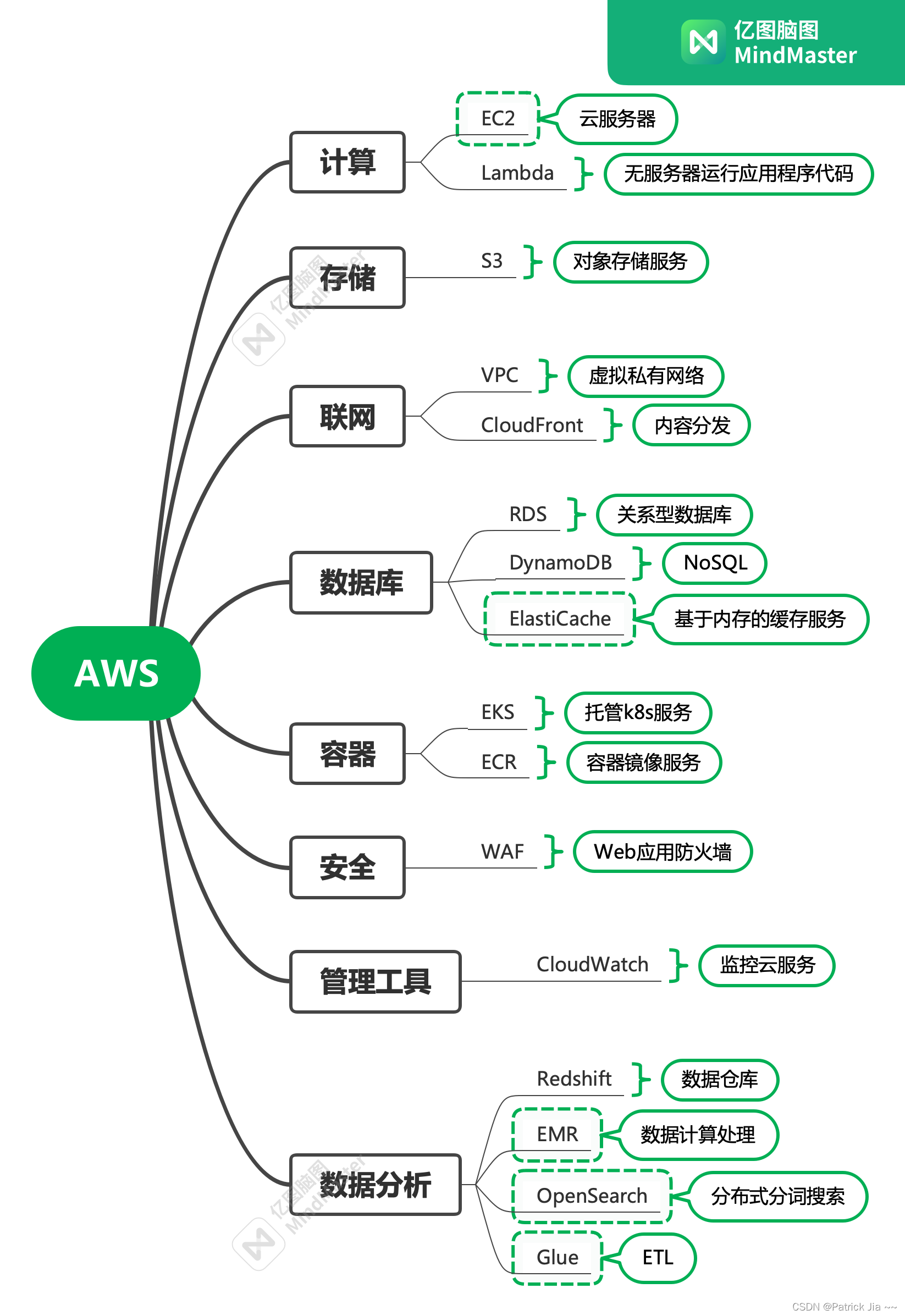
AWS 常用服务
Tensorflow steps on the pit notes and records various errors and solutions
Day1:用原生JS把你的设备变成一台架子鼓!
关于基于若依框架的路由跳转
【数据库和SQL学习笔记】10.(T-SQL语言)函数、存储过程、触发器
【论文精读】ROC和PR曲线的关系(The relationship between Precision-Recall and ROC curves)

flink yarn-session的两种使用方式
el-table,el-table-column,selection,获取多选选中的数据

Flutter 3.0升级内容,该如何与小程序结合
【数据库和SQL学习笔记】5.SELECT查询3:多表查询、连接查询
随机推荐
2021电赛资源及经验总结
浅谈Servlet生命周期
表情捕捉的指标/图像的无参考质量评价
[Go through 9] Convolution
[Database and SQL study notes] 10. (T-SQL language) functions, stored procedures, triggers
CH32V307 LwIP移植使用
Web Component-处理数据
SharedPreferences和SQlite数据库
【Pytorch学习笔记】10.如何快速创建一个自己的Dataset数据集对象(继承Dataset类并重写对应方法)
It turns out that the MAE proposed by He Yuming is still a kind of data enhancement
flink实例开发-batch批处理实例
[Go through 4] 09-10_Classic network analysis
flink项目开发-配置jar依赖,连接器,类库
Flink和Spark中文乱码问题
面向小白的深度学习代码库,一行代码实现30+中attention机制。
如何编写一个优雅的Shell脚本(二)
记我的第一篇CCF-A会议论文|在经历六次被拒之后,我的论文终于中啦,耶!
全尺度表示的上下文非局部对齐
读论文- pix2pix
vscode要安装的插件