当前位置:网站首页>R语言 第一部分
R语言 第一部分
2022-07-31 06:47:00 【jeff one】
R语言 第一章
1.对象赋值与运行

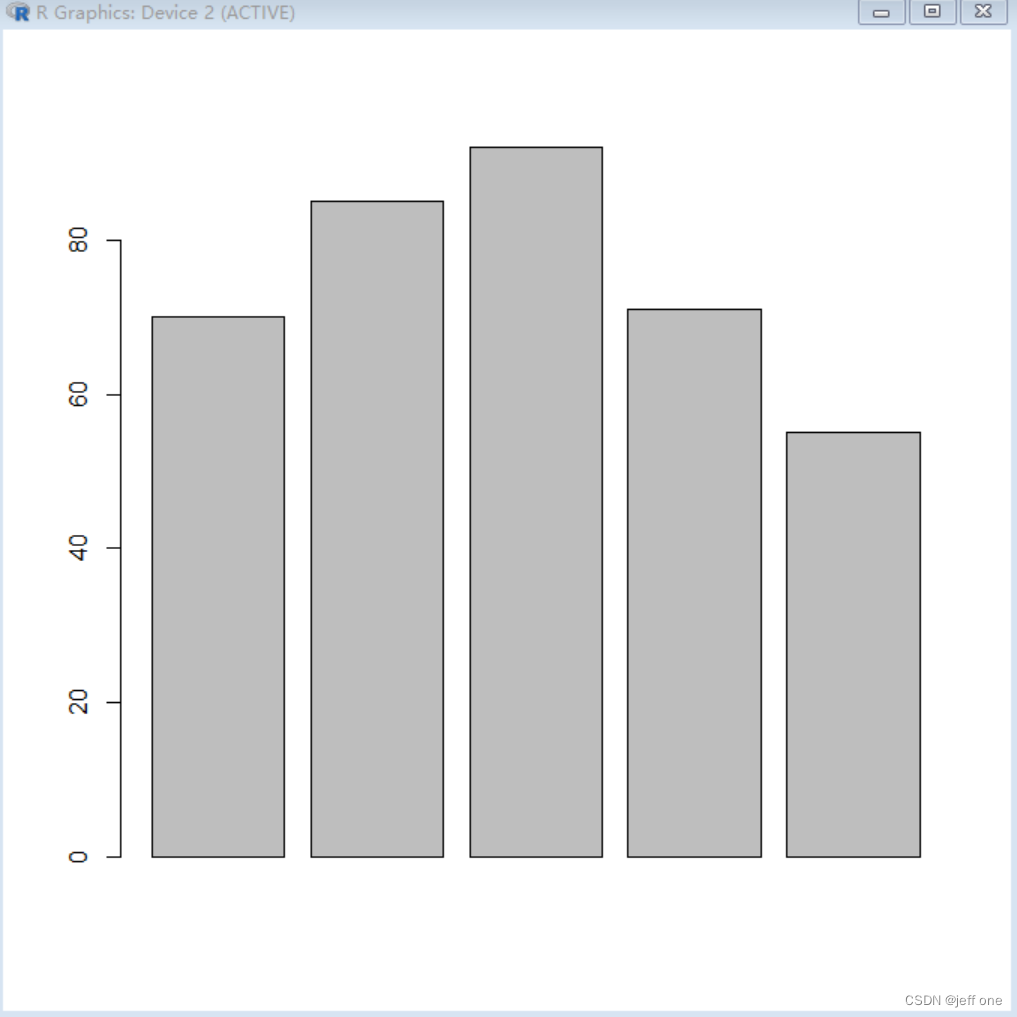
2.脚本代码

3.帮助文件
4.向量,矩阵和数组
(1)向量
(2)矩阵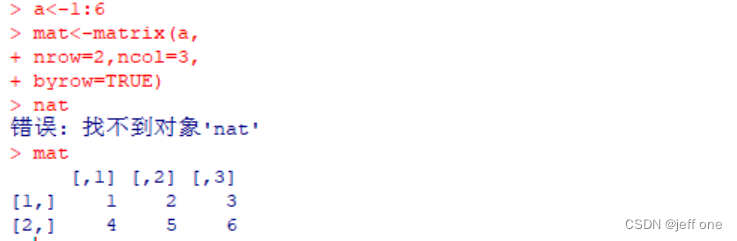

(3).数组

5.数据框
1)创建数据框


2)数据框的合并
mytable<-rbind(table1_1,table1_2)
cbind(mytable,table1_3[2:3]) # 按列合并数据框
3)数据框排序
6.因子和列表
1)因子
2)列表
7.R语言数据处理
1)数据读取和保存
1.读取包含标题的csv格式数据 table1_1<-read.csv(“C:/mydata/chap01/table1_1.csv”)
2. 读取不包含标题的csv格式数据
3. table1_1<-read.csv(“C:/mydata/chap01/table1_1.csv”,header=FALSE)
3.读取R格式数据 load(“C:/mydata/chap01/table1_1.RData”)
4.将tablel_1存为csv格式文件 write.csv(table1_1,file=“C:/mydata/chap01/table1_1.csv”)
2)随机数和数据抽样
3)生成频数分布表
一频表:
生成满意度的简单频数表。
data1_1<-read.csv(“C:/mydata/chap01/data1_1.csv”) attach(data1_1)
mytable1<-table(满意度);mytable1 prop.table(mytable1)*100
二频表:
生成性别和满意度的二维列联表。 data1_1<-read.csv(“C:/mydata/chap01/data1_1.csv”)
attach(data1_1) mytable2<-table(性别,满意度) # 生成性别和满意度的二维列联表 mytable2
addmargins(mytable2) # 为列联表添加边际和
addmargins(prop.table(mytable2)*100) # 将列联表转换成百分比表
多维表:
生成三维频数表(列变量为“满意度”)
data1_1<-read.csv(“C:/mydata/chap01/data1_1.csv”)
mytable3<-ftable(data1_1,row.vars=c(“性别”,“网购次数”),col.vars=“满意度”)
mytable3 生成三维频数表(列变量为"性别"和"满意度")
mytable4<-ftable(data1_1,row.vars=c(“网购次数”),col.vars=c(“性别”,“满意度”))
mytable4
4)生成频数分布表——数值数据——cut 函数
data1_2<-read.csv(“C:/mydata/chap01/data1_2.csv”)
v<-as.vector(data1_2KaTeX parse error: Expected 'EOF', got '#' at position 8: 销售额) #̲ 将销售额转化成向量 d<-t…Freq/sum(ddKaTeX parse error: Expected 'EOF', got '#' at position 14: Freq)*100,2) #̲ 计算频数百分比,结果保留2位…Var1,频数=df F r e q , 频数百分比 = d f Freq,频数百分比=df Freq,频数百分比=dfpercent)
重新命名并组织成频数分布表 mytable #
显示频数分布表
5) 生成频数分布表——数值数据——Freq 函数
data1_2<-read.csv(“C:/mydata/chap01/data1_2.csv”) library(DescTools)
加载包DescTools 使用默认分组,含上限值
tab<- Freq(data1_2 销售额 ) t a b 使用 F r e q 函数并生成频数分布表,指定组距 = 20 (不含上限值) t a b 1 < − F r e q ( d a t a 1 2 销售额) tab 使用Freq函数并生成频数分布表,指定组距=20(不含上限值) tab1<-Freq(data1_2 销售额)tab使用Freq函数并生成频数分布表,指定组距=20(不含上限值)tab1<−Freq(data12
销售额, breaks=c(500,520,540,560,580,625,600,620,640,660,680,700,720),right=FALSE)
指定组距=20,不含上限值
tab2<-data.frame(分组=tab1 l e v e l , 频数 = t a b 1 level,频数=tab1 level,频数=tab1freq,频数百分比=tab1 p e r c ∗ 100 , 累积频数 = t a b 1 perc*100,累积频数=tab1 perc∗100,累积频数=tab1cumfreq,累积百分比=tab1$cumperc*100)
重新命名频数表中的变量 print(tab2,digits=3)
用print函数定义输出结果的小数位数
边栏推荐
- interrupt and pendSV
- 嵌入式系统驱动初级【2】——内核模块下_参数和依赖
- 2022.07.13_每日一题
- Ceph单节点部署
- Thread 类的基本用法——一网打尽
- 金融租赁业务
- 文件 - 03 下载文件:根据文件id获取下载链接
- Chapter 17: go back to find the entrance to the specified traverse, "ma bu" or horse stance just look greedy, no back to search traversal, "ma bu" or horse stance just look recursive search NXM board
- 【愚公系列】2022年07月 Go教学课程 022-Go容器之字典
- CNN--Introduction to each layer
猜你喜欢
2022.07.14_每日一题

【解决】mysql本地计算机上的MySQL服务启动后停止。某些服务在未由其他服务或程序使用时将自动停止
【Go语言刷题篇】Go完结篇函数、结构体、接口、错误入门学习
手把手教你开发微信小程序自定义底部导航栏

把 VS Code 当游戏机

Super detailed mysql database installation guide

【Go报错】go go.mod file not found in current directory or any parent directory 错误解决
Zotero | Zotero translator plugin update | Solve the problem that Baidu academic literature cannot be obtained

Yu Mr Series 】 【 2022 July 022 - Go Go teaching course of container in the dictionary

【Go】Go 语言切片(Slice)
随机推荐
Leetcode952. 按公因数计算最大组件大小
从 Google 离职,前Go 语言负责人跳槽小公司
2022.07.20_Daily Question
MySQL安装到最后一步 write configuration file 失败 怎么办?及后安装步骤
2022.07.26_每日一题
Pygame Surface对象
完美指南|如何使用 ODBC 进行无代理 Oracle 数据库监控?
iOS大厂面试查漏补缺
The Ballad of Lushan Sends Lu's Servant to the Void Boat
opencv、pil和from torchvision.transforms的Resize, Compose, ToTensor, Normalize等差别
SCI写作指南
把 VS Code 当游戏机
2. (1) Chained storage of stack, operation of chain stack (illustration, comment, code)
2022.07.18_每日一题
Shell编程之条件语句
链表实现及任务调度
2022.07.15_Daily Question
【科普向】5G核心网架构和关键技术
XSS靶场prompt.ml过关详解
安装部署KubeSphere管理kubernetes