当前位置:网站首页>Leetcode(46)——全排列
Leetcode(46)——全排列
2022-07-06 22:50:00 【SmileGuy17】
Leetcode(46)——全排列
题目
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例 2:
输入:nums = [0,1]
输出:[[0,1],[1,0]]
示例 3:
输入:nums = [1]
输出:[[1]]
提示:
- 1 1 1 <= nums.length <= 6 6 6
- − 10 -10 −10 <= nums[i] <= 10 10 10
- n u m s nums nums 中的所有整数 互不相同
题解
方法一:回溯法
思路
怎样输出所有的排列方式呢?对于每一个当前位置 i,我们可以将其于之后的任意位置交换,然后继续处理位置 i+1,直到处理到最后一位。为了防止每次遍历时都要新建一个子数组储存位置 i 之前已经交换好的数字——我们可以利用回溯法,只对原数组进行修改,在递归完成后再修改回来。
具体来说,假设我们已经填到第 first \textit{first} first 个位置,那么 nums \textit{nums} nums 数组中 [ 0 , first − 1 ] [0, \textit{first} - 1] [0,first−1] 是已填过的数的集合, [ first , n − 1 ] [\textit{first}, n - 1] [first,n−1] 是待填的数的集合。我们肯定是尝试用 [ first , n − 1 ] [\textit{first}, n - 1] [first,n−1] 里的数去填第 first \textit{first} first 个数,假设待填的数的下标为 i i i,那么填完以后我们将第 i i i 个数和第 first \textit{first} first 个数交换,即能使得在填第 first + 1 \textit{first} + 1 first+1 个数的时候 nums \textit{nums} nums 数组的 [ 0 , first ] [0, \textit{first}] [0,first] 部分为已填过的数, [ first + 1 , n − 1 ] [\textit{first} + 1, n - 1] [first+1,n−1] 为待填的数,回溯的时候交换回来即能完成撤销操作。
举个简单的例子,假设我们有 [ 2 , 5 , 8 , 9 , 10 ] [2, 5, 8, 9, 10] [2,5,8,9,10] 这 5 5 5 个数要填入,已经填到第 3 3 3 个位置,已经填了 [ 8 , 9 ] [8, 9] [8,9] 两个数,那么这个数组目前为 [ 8 , 9 ∣ 2 , 5 , 10 ] [8, 9~|~2, 5, 10] [8,9 ∣ 2,5,10] 这样的状态,分隔符区分了左右两个部分。假设这个位置我们要填 10 10 10 这个数,为了维护数组,我们将 2 2 2 和 10 10 10 交换,即能使得数组继续保持分隔符左边的数已经填过,右边的待填 [ 8 , 9 , 10 ∣ 2 , 5 ] [8, 9, 10~|~2, 5] [8,9,10 ∣ 2,5]。
当然我们会发现这样生成的全排列并不是按字典序存储在答案数组中的,如果题目要求按字典序输出,那么请还是用标记数组或者其他方法。
下面的图展示了回溯的整个过程: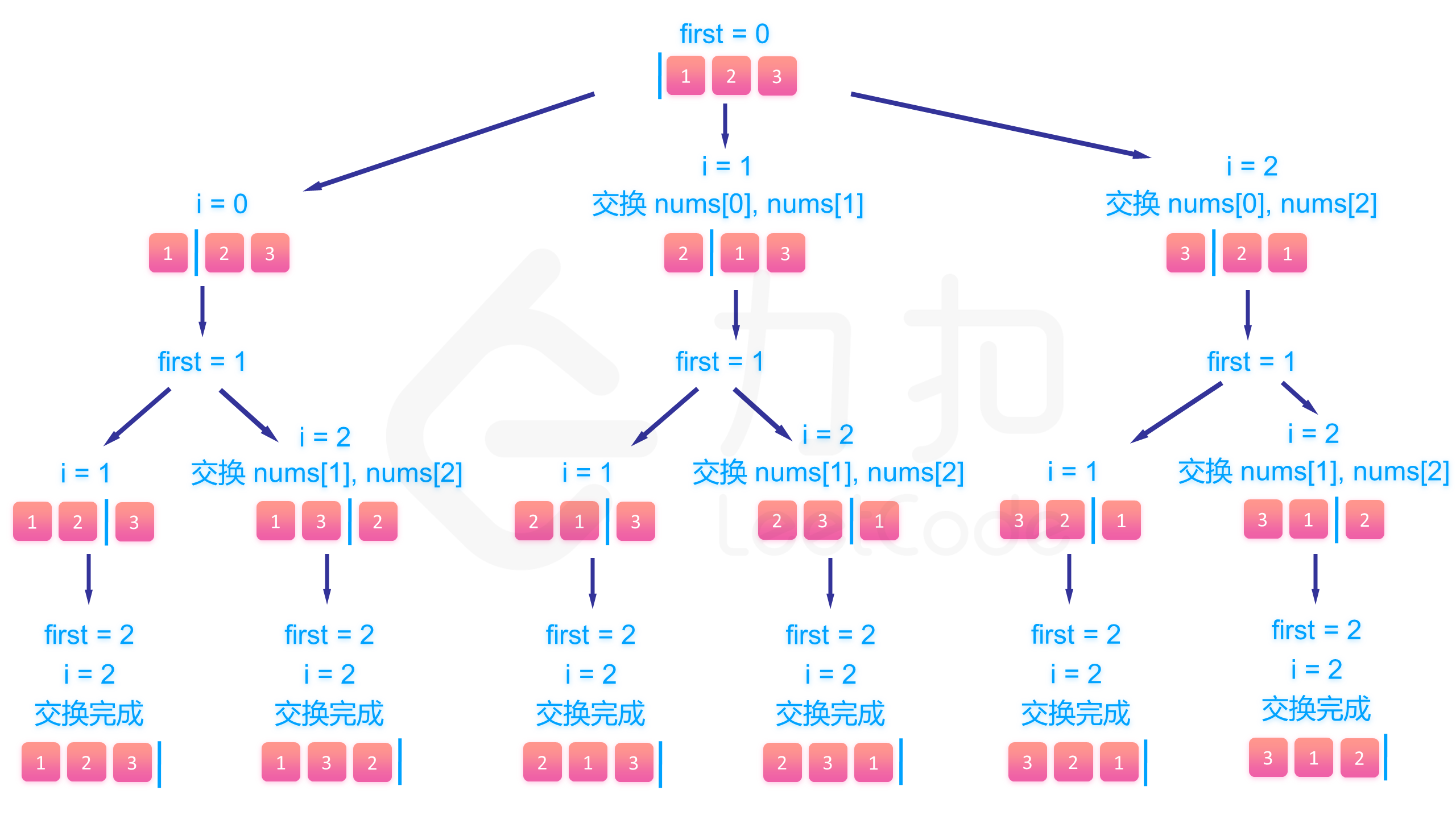
代码实现
Leetcode 官方题解:
class Solution {
public:
void backtrack(vector<vector<int>>& res, vector<int>& output, int first, int len){
// 所有数都填完了
if (first == len) {
res.emplace_back(output);
return;
}
for (int i = first; i < len; ++i) {
// 动态维护数组
swap(output[i], output[first]);
// 继续递归填下一个数
backtrack(res, output, first + 1, len);
// 撤销操作
swap(output[i], output[first]);
}
}
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int> > res;
backtrack(res, nums, 0, (int)nums.size());
return res;
}
};
我自己的:
class Solution {
void DFS(vector<vector<int>>& ans, vector<int>& s, vector<int>& nums, int p){
if(s.size() == nums.size()) ans.push_back(s);
else{
for(int n = p; n < nums.size(); n++){
swap(nums[p], nums[n]);
s.push_back(nums[p]);
DFS(ans, s, nums, p+1); // 从下标1开始
s.pop_back(); // 回溯
swap(nums[p], nums[n]);
}
}
}
public:
vector<vector<int>> permute(vector<int>& nums) {
vector<int> s;
vector<vector<int>> ans;
DFS(ans, s, nums, 0);
return ans;
}
};
改进后:
class Solution {
void DFS(vector<vector<int>>& ans, vector<int>& nums, int p){
if(p+1 == nums.size())
ans.push_back(nums);
else{
for(int n = p; n < nums.size(); n++){
swap(nums[p], nums[n]);
DFS(ans, nums, p+1); // 从下标 p+1 开始
swap(nums[p], nums[n]); // 回溯
}
}
}
public:
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int>> ans;
DFS(ans, nums, 0);
return ans;
}
};
复杂度分析
- 时间复杂度: O ( n × n ! ) O(n \times n!) O(n×n!),其中 n n n 为序列的长度。
算法的复杂度首先受 backtrack \textit{backtrack} backtrack 的调用次数制约, backtrack \textit{backtrack} backtrack 的调用次数为 ∑ k = 1 n P ( n , k ) \sum_{k = 1}^{n}{P(n, k)} ∑k=1nP(n,k) 次,其中 P ( n , k ) = n ! ( n − k ) ! = n ( n − 1 ) … ( n − k + 1 ) P(n, k) = \frac{n!}{(n - k)!} = n (n - 1) \ldots (n - k + 1) P(n,k)=(n−k)!n!=n(n−1)…(n−k+1),该式被称作 n 的 k - 排列,或者部分排列。
而 ∑ k = 1 n P ( n , k ) = n ! + n ! 1 ! + n ! 2 ! + n ! 3 ! + … + n ! ( n − 1 ) ! < 2 n ! + n ! 2 + n ! 2 2 + n ! 2 n − 2 < 3 n ! \sum_{k = 1}^{n}{P(n, k)} = n! + \frac{n!}{1!} + \frac{n!}{2!} + \frac{n!}{3!} + \ldots + \frac{n!}{(n-1)!} < 2n! + \frac{n!}{2} + \frac{n!}{2^2} + \frac{n!}{2^{n-2}} < 3n! ∑k=1nP(n,k)=n!+1!n!+2!n!+3!n!+…+(n−1)!n!<2n!+2n!+22n!+2n−2n!<3n!
这说明 backtrack \textit{backtrack} backtrack 的调用次数是 O ( n ! ) O(n!) O(n!) 的。
而对于 backtrack \textit{backtrack} backtrack 调用的每个叶结点(共 n ! n! n! 个),我们需要将当前答案使用 O ( n ) O(n) O(n) 的时间复制到答案数组中,相乘得时间复杂度为 O ( n × n ! ) O(n \times n!) O(n×n!)。
因此时间复杂度为 O ( n × n ! ) O(n \times n!) O(n×n!)。 - 空间复杂度: O ( n ) O(n) O(n),其中 n n n 为序列的长度。除答案数组以外,递归函数在递归过程中需要为每一层递归函数分配栈空间,所以这里需要额外的空间且该空间取决于递归的深度,这里可知递归调用深度为 O ( n ) O(n) O(n)。
边栏推荐
- STM32F103ZE+SHT30检测环境温度与湿度(IIC模拟时序)
- Analysis -- MySQL statement execution process & MySQL architecture
- Some understandings about 01 backpacker
- Liste des hôtes d'inventaire dans ansible (je vous souhaite des fleurs et de la romance sans fin)
- 使用Thread类和Runnable接口实现多线程的区别
- 记录一次压测经验总结
- How does vscade use the built-in browser?
- JS input and output
- offer如何选择该考虑哪些因素
- Terms used in the Web3 community
猜你喜欢
深入解析Kubebuilder
3GPP信道模型路损基础知识
Gavin teacher's perception of transformer live class - rasa project actual combat e-commerce retail customer service intelligent business dialogue robot microservice code analysis and dialogue experim

Weebly移动端网站编辑器 手机浏览新时代
Programmers go to work fishing, so play high-end!
Chapter 9 Yunji datacanvas company has been ranked top 3 in China's machine learning platform market
Read of shell internal value command

Field data acquisition and edge calculation scheme of CNC machine tools
Introduction to namespace Basics
Batch normalization (Standardization) processing
随机推荐
【數模】Matlab allcycles()函數的源代碼(2021a之前版本沒有)
DFS and BFS concepts and practices +acwing 842 arranged numbers (DFS) +acwing 844 Maze walking (BFS)
Canteen user dish relationship system (C language course design)
PLC模拟量输出 模拟量输出FB analog2NDA(三菱FX3U)
Ansible概述和模块解释(你刚走过了今天,而扑面而来的却是昨天)
IMS data channel concept of 5g vonr+
装饰器基础学习02
Using thread class and runnable interface to realize the difference between multithreading
Thread和Runnable创建线程的方式对比
JDBC link Oracle reference code
Markdown editor
If you ask me about R code debugging, I will tell you head, STR, help
[Android kotlin collaboration] use coroutinecontext to realize the retry logic after a network request fails
Tiktok may launch an independent grass planting community platform: will it become the second little red book
3.基金的类型
LabVIEW在打开一个新的引用,提示内存已满
一个酷酷的“幽灵”控制台工具
Flex layout and usage
How to package the parsed Excel data into objects and write this object set into the database?
Basic idea of counting and sorting