当前位置:网站首页>ucore lab 2
ucore lab 2
2022-07-06 09:25:00 【湖大金胜宇】
LAB 2
物理内存管理
实验一过后大家做出来了一个可以启动的系统,实验二主要涉及操作系统的物理内存管理。操作系统为了使用内存,还需高效地管理内存资源。在实验二中大家会了解并且自己动手完成一个简单的物理内存管理系统。
实验目的
- 理解基于段页式内存地址的转换机制
- 理解页表的建立和使用方法
- 理解物理内存的管理方法
实验内容
本次实验包含三个部分。首先了解如何发现系统中的物理内存;然后了解如何建立对物理内存的初步管理,即了解连续物理内存管理;最后了解页表相关的操作,即如何建立页表来实现虚拟内存到物理内存之间的映射,对段页式内存管理机制有一个比较全面的了解。本实验里面实现的内存管理还是非常基本的,并没有涉及到对实际机器的优化,比如针对 cache 的优化等。如果大家有余力,尝试完成扩展练习。
练习
为了实现lab2的目标,lab2提供了3个基本练习和2个扩展练习,要求完成实验报告。
对实验报告的要求:
- 基于markdown格式来完成,以文本方式为主
- 填写各个基本练习中要求完成的报告内容
- 完成实验后,请分析ucore_lab中提供的参考答案,并请在实验报告中说明你的实现与参考答案的区别
- 列出你认为本实验中重要的知识点,以及与对应的OS原理中的知识点,并简要说明你对二者的含义,关系,差异等方面的理解(也可能出现实验中的知识点没有对应的原理知识点)
- 列出你认为OS原理中很重要,但在实验中没有对应上的知识点
练习0:填写已有实验
本实验依赖实验1。请把你做的实验1的代码填入本实验中代码中有“LAB1”的注释相应部分。提示:可采用diff和patch工具进行半自动的合并(merge),也可用一些图形化的比较/merge工具来手动合并,比如meld,eclipse中的diff/merge工具,understand中的diff/merge工具等。
解:使用meld工具进行对比,可以得到如下结果:
经过对比,我们知道debug.c,trap.c,init.c文件不相同,这里可以直接使用meld来进行替换。一一合并之后就可以完成了。其余地方则无需修改,直接使用即可。
练习1:实现 first-fit 连续物理内存分配算法(需要编程)
在实现first fit 内存分配算法的回收函数时,要考虑地址连续的空闲块之间的合并操作。提示:在建立空闲页块链表时,需要按照空闲页块起始地址来排序,形成一个有序的链表。可能会修改default_pmm.c中的default_init,default_init_memmap,default_alloc_pages, default_free_pages等相关函数。请仔细查看和理解default_pmm.c中的注释。
请在实验报告中简要说明你的设计实现过程。请回答如下问题:
- 你的first fit算法是否有进一步的改进空间
解:首先根据提示查看default_pmm.c中的注释:
/* In the First Fit algorithm, the allocator keeps a list of free blocks * (known as the free list). Once receiving a allocation request for memory, * it scans along the list for the first block that is large enough to satisfy * the request. If the chosen block is significantly larger than requested, it * is usually splitted, and the remainder will be added into the list as * another free block. * Please refer to Page 196~198, Section 8.2 of Yan Wei Min's Chinese book * "Data Structure -- C programming language". */
// LAB2 EXERCISE 1: YOUR CODE
// you should rewrite functions: `default_init`, `default_init_memmap`,
// `default_alloc_pages`, `default_free_pages`.
/* * Details of FFMA * (1) Preparation: * In order to implement the First-Fit Memory Allocation (FFMA), we should * manage the free memory blocks using a list. The struct `free_area_t` is used * for the management of free memory blocks. * First, you should get familiar with the struct `list` in list.h. Struct * `list` is a simple doubly linked list implementation. You should know how to * USE `list_init`, `list_add`(`list_add_after`), `list_add_before`, `list_del`, * `list_next`, `list_prev`. * There's a tricky method that is to transform a general `list` struct to a * special struct (such as struct `page`), using the following MACROs: `le2page` * (in memlayout.h), (and in future labs: `le2vma` (in vmm.h), `le2proc` (in * proc.h), etc). * (2) `default_init`: * You can reuse the demo `default_init` function to initialize the `free_list` * and set `nr_free` to 0. `free_list` is used to record the free memory blocks. * `nr_free` is the total number of the free memory blocks. * (3) `default_init_memmap`: * CALL GRAPH: `kern_init` --> `pmm_init` --> `page_init` --> `init_memmap` --> * `pmm_manager` --> `init_memmap`. * This function is used to initialize a free block (with parameter `addr_base`, * `page_number`). In order to initialize a free block, firstly, you should * initialize each page (defined in memlayout.h) in this free block. This * procedure includes: * - Setting the bit `PG_property` of `p->flags`, which means this page is * valid. P.S. In function `pmm_init` (in pmm.c), the bit `PG_reserved` of * `p->flags` is already set. * - If this page is free and is not the first page of a free block, * `p->property` should be set to 0. * - If this page is free and is the first page of a free block, `p->property` * should be set to be the total number of pages in the block. * - `p->ref` should be 0, because now `p` is free and has no reference. * After that, We can use `p->page_link` to link this page into `free_list`. * (e.g.: `list_add_before(&free_list, &(p->page_link));` ) * Finally, we should update the sum of the free memory blocks: `nr_free += n`. * (4) `default_alloc_pages`: * Search for the first free block (block size >= n) in the free list and reszie * the block found, returning the address of this block as the address required by * `malloc`. * (4.1) * So you should search the free list like this: * list_entry_t le = &free_list; * while((le=list_next(le)) != &free_list) { * ... * (4.1.1) * In the while loop, get the struct `page` and check if `p->property` * (recording the num of free pages in this block) >= n. * struct Page *p = le2page(le, page_link); * if(p->property >= n){ ... * (4.1.2) * If we find this `p`, it means we've found a free block with its size * >= n, whose first `n` pages can be malloced. Some flag bits of this page * should be set as the following: `PG_reserved = 1`, `PG_property = 0`. * Then, unlink the pages from `free_list`. * (4.1.2.1) * If `p->property > n`, we should re-calculate number of the rest * pages of this free block. (e.g.: `le2page(le,page_link))->property * = p->property - n;`) * (4.1.3) * Re-caluclate `nr_free` (number of the the rest of all free block). * (4.1.4) * return `p`. * (4.2) * If we can not find a free block with its size >=n, then return NULL. * (5) `default_free_pages`: * re-link the pages into the free list, and may merge small free blocks into * the big ones. * (5.1) * According to the base address of the withdrawed blocks, search the free * list for its correct position (with address from low to high), and insert * the pages. (May use `list_next`, `le2page`, `list_add_before`) * (5.2) * Reset the fields of the pages, such as `p->ref` and `p->flags` (PageProperty) * (5.3) * Try to merge blocks at lower or higher addresses. Notice: This should * change some pages' `p->property` correctly. */
根据注释,我们可以知道First fit算法是一种思想比较简单,速度非常快的分配算法:
物理内存页管理器顺着双向链表进行搜索空闲内存区域,直到找到一个足够大的空闲区域,因为它尽可能少地搜索链表。如果空闲区域的大小和申请分配的大小正好一样,则把这个空闲区域分配出去,成功返回;否则将该空闲区分为两部分,一部分区域与申请分配的大小相等,把它分配出去,剩下的一部分区域形成新的空闲区。其释放内存的设计思路很简单,只需把这块区域重新放回双向链表中即可。
根据注释我们依次看到为了内存分配而设计的数据结构:
/* * * struct Page - Page descriptor structures. Each Page describes one * physical page. In kern/mm/pmm.h, you can find lots of useful functions * that convert Page to other data types, such as phyical address. * */
struct Page {
int ref; // page frame's reference counter
uint32_t flags; // array of flags that describe the status of the page frame
unsigned int property; // the num of free block, used in first fit pm manager
list_entry_t page_link; // free list link
};
接下来依次分析定义的每个变量的具体含义:
ref:注释中可以翻译为“引用的计数器”,这样可能比较抽象。具体的说ref表示的是,这个页被页表的引用记数,也就是映射此物理页的虚拟页个数。如果这个页被页表引用了即在某页表中有一个页表项设置了一个虚拟页到这个Page管理的物理页的映射关系,就会把Page的ref加一;反之,若页表项取消,即映射关系解除,就会把Page的ref减一。
flags:此物理页的状态标记,有两个标志位状态,为1的时候,代表这一页是free状态,可以被分配,但不能对它进行释放;如果为0,那么说明这个页已经分配了,不能被分配,但是可以被释放掉。简单地说,就是可不可以被分配的一个标志位。
propert:记录某连续空闲页的数量,这里需要注意的是用到此成员变量的这个Page一定是连续内存块的开始地址(第一页的地址)。
page_link:便于把多个连续内存空闲块链接在一起的双向链表指针,连续内存空闲块利用这个页的成员变量page_link来链接比它地址小和大的其他连续内存空闲块,释放的时候只要将这个空间通过指针放回到双向链表中。
接下来往后看可以看到下一个数据结构:
/* free_area_t - maintains a doubly linked list to record free (unused) pages */
typedef struct {
list_entry_t free_list; // the list header
unsigned int nr_free; // # of free pages in this free list
} free_area_t;
这里的数据结构定义让我觉得是个空闲列表,但是又有所不同。这里是由于随着内存的分配,导致出现了小的连续空闲内存即外部碎片。但是,我们应该利用这些小的连续空闲内存,但是每次的遍历带来的消耗不值得。所以这里定义了free_area_t的数据结构。
这里看一下里面的成员变量,首先就是一个list_entry结构的双向链表指针和记录当前空闲页的个数的无符号整型变量nr_free。其中的链表指针指向了空闲的物理页,也就是链表的头部。
在这里,通过上述两个数据结构,我们知道了为了使内存分配更加合理,我们设计了页以及管理空闲页的数据结构。
在需要写代码的文件的头文件中我们发现:
extern const struct pmm_manager default_pmm_manager;
顾名思义这里定义了管理实际分配当中的空闲空间的数据结构,接下来看一下pmm_manager的具体定义:
// pmm_manager is a physical memory management class. A special pmm manager - XXX_pmm_manager
// only needs to implement the methods in pmm_manager class, then XXX_pmm_manager can be used
// by ucore to manage the total physical memory space.
struct pmm_manager {
const char *name; // XXX_pmm_manager's name
void (*init)(void); // initialize internal description&management data structure
// (free block list, number of free block) of XXX_pmm_manager
void (*init_memmap)(struct Page *base, size_t n); // setup description&management data structcure according to
// the initial free physical memory space
struct Page *(*alloc_pages)(size_t n); // allocate >=n pages, depend on the allocation algorithm
void (*free_pages)(struct Page *base, size_t n); // free >=n pages with "base" addr of Page descriptor structures(memlayout.h)
size_t (*nr_free_pages)(void); // return the number of free pages
void (*check)(void); // check the correctness of XXX_pmm_manager
};
接下来对结构体中的各个部分的注释进行解释:
const char *name:某种物理内存管理器的名称(可根据算法等具体实现的不同自定义新的内存管理器)
*void (*init)(void):物理内存管理器初始化,包括生成内部描述和数据结构(空闲块链表和空闲页总数)
void (*init_memmap)(struct Page *base, size_t n):初始化空闲页,根据初始时的空闲物理内存区域将页映射到物理内存上
struct Page *(*alloc_pages)(size_t n):申请分配指定数量的物理页
void (*free_pages)(struct Page *base, size_t n):申请释放若干指定物理页
size_t (*nr_free_pages)(void):查询当前空闲页总数
void (*check)(void):检查物理内存管理器的正确性
接下来是上述定义的数据结构中会用到的宏定义:
/* Flags describing the status of a page frame */
#define PG_reserved 0 // if this bit=1: the Page is reserved for kernel, cannot be used in alloc/free_pages; otherwise, this bit=0
#define PG_property 1 // if this bit=1: the Page is the head page of a free memory block(contains some continuous_addrress pages), and can be used in alloc_pages; if this bit=0: if the Page is the the head page of a free memory block, then this Page and the memory block is alloced. Or this Page isn't the head page.
#define SetPageReserved(page) set_bit(PG_reserved, &((page)->flags))
#define ClearPageReserved(page) clear_bit(PG_reserved, &((page)->flags))
#define PageReserved(page) test_bit(PG_reserved, &((page)->flags))
#define SetPageProperty(page) set_bit(PG_property, &((page)->flags))
#define ClearPageProperty(page) clear_bit(PG_property, &((page)->flags))
#define PageProperty(page) test_bit(PG_property, &((page)->flags))
同时,我们发现我们定义的数据结构里面的操作是和名字绑定在一起的,这里我们猜测我们定义的数据结构的名字是default_pmm_manager,接下来找到对应的定义:
const struct pmm_manager default_pmm_manager = {
.name = "default_pmm_manager",
.init = default_init,
.init_memmap = default_init_memmap,
.alloc_pages = default_alloc_pages,
.free_pages = default_free_pages,
.nr_free_pages = default_nr_free_pages,
.check = default_check,
};
发现这里把对应的函数和名字相绑定到了一起。
同时在上面的定义里面我们发现空闲块列表里面定义的类型并不是平日里面常见的数据类型,所以这里我们猜测任然是一个数据结构,接下来找到该类型的数据结构的定义:
struct list_entry {
struct list_entry *prev, *next;
};
/*list_entry_t是双链表结点的两个指针构成的集合,这个空闲块链表实际上是将各个块首页的指针集合(由prev和next构成)的指针(或者说指针集合所在地址)相连*/
typedef struct list_entry list_entry_t;
知道了我们定义的数据结构,接下来就应该实现First fit算法的相关函数:default_init,default_init_memmap,default_alloc_pages, default_free_pages。
defalut_init:
实现如下:
free_area_t free_area;
#define free_list (free_area.free_list)
#define nr_free (free_area.nr_free)
static void
default_init(void) {
list_init(&free_list);
nr_free = 0;
}
这部分是一个初始化的部分,就是将双向链表初始化,同时将空闲页总数nr_free初始化为0。
default_init_memmap:
在我们写这个函数之前,我们应该明白该函数是如何使用的以及它的功能是什么:
首先它的调用过程为:kern_init --> pmm_init–>page_init–>init_memmap。
接下来我们依次跟踪就可以知道里面的代码是在什么样的条件下执行的:
- 这个函数是进入ucore操作系统之后,第一个执行的函数,对于内核进行初始化。在其中,调用了初始化物理内存的函数pmm_init。
- 这个函数主要是完成对于整个物理内存的初始化,页初始化只是其中的一部分,调用位置偏前,函数之后的部分可以不管,直接进入page_init函数。
- page_init函数主要是完成了一个整体物理地址的初始化过程,包括设置标记位,探测物理内存布局等操作。
- 但是,其中最关键的部分,也是和实验相关的页初始化,交给了init_memmap函数处理。
//init_memmap - call pmm->init_memmap to build Page struct for free memory
static void
init_memmap(struct Page *base, size_t n) {
pmm_manager->init_memmap(base, n);
}
到这里,我们自然而然就应该观察到输入的这两个参数,我们大致可以知道这两个参数是为了初始化:
第一个参数的类型是Page *:
static inline struct Page *
pa2page(uintptr_t pa) {
if (PPN(pa) >= npage) {
panic("pa2page called with invalid pa");
}
return &pages[PPN(pa)];
}
这里的这个作用就是返回传入参数pa开始的第一个物理页,也就是基地址base。
第二个参数n:
这个参数就是代表物理页的个数。
综上,这个函数就是初始化一整个空闲物理内存块,将块内每一页对应的Page结构初始化,参数为基址和页数(因为相邻编号的页对应的Page结构在内存上是相邻的,所以可将第一个空闲物理页对应的Page结构地址作为基址,以基址+偏移量的方式访问所有空闲物理页的Page结构,根据指导书,这个空闲块链表正是将各个块首页的指针集合(由prev和next构成)的指针(或者说指针集合所在地址)相连,并以基址区分不同的连续内存物理块)。
代码的实现:
static void
default_init_memmap(struct Page *base, size_t n) {
assert(n > 0); //判断n是否大于0
struct Page *p = base;
for (; p != base + n; p ++) {
//初始化n块物理页
assert(PageReserved(p)); //检查此页是否为保留页
p->flags = p->property= 0; //标志位清0
SetPageProperty(p); //设置标志位为1
set_page_ref(p, 0); //清除引用此页的虚拟页的个数
//加入空闲链表
list_add_before(&free_list, &(p->page_link));
}
nr_free += n; //计算空闲页总数
base->property = n; //修改base的连续空页值为n
}
这里我们先根据注释说一下代码每一步是如何执行的:
首先,这里使用了一个页结构来存储传下来的base页面,之后使用循环判断后面n个页面是否为保留页(之前,因为防止初试化页面被分配或破坏,已经设置了保留页),如果该页不是保留页,那么就可以对它进行初始化,这里调用SetPageProperty设置标志位,表示当前页为空。同时这里将连续空页数量设置为0,即p->property。最后将映射到此物理页的虚拟页数量置为0,调用set_page_ref函数来清空引用。最后,将其插入到双向列表中,其中free_list指的是free_area_t中的list结构,并且基地址的连续空闲页数量加n,空闲页数量也加n。
综上,具体流程为:遍历块内所有空闲物理页的Page结构,将各个flags置为0以标记物理页帧有效,将property成员置零,使用 SetPageProperty宏置PG_Property标志位来标记各个页有效(具体而言,如果一页的该位为1,则对应页应是一个空闲块的块首页;若为0,则对应页要么是一个已分配块的块首页,要么不是块中首页;另一个标志位PG_Reserved在pmm_init函数里已被置位,这里用于确认对应页不是被OS内核占用的保留页,因而可用于用户程序的分配和回收),清空各物理页的引用计数ref;最后再将首页Page结构的property置为块内总页数,将全局总页数nr_free加上块内总页数,并用page_link这个双链表结点指针集合将块首页连接到空闲块链表里。
default_alloc_pages
代码的实现如下:
static struct Page *
default_alloc_pages(size_t n) {
assert(n > 0); //判断n是否大于0
if (n > nr_free) {
//需要分配页的个数大于空闲页的总数,直接返回
return NULL;
}
list_entry_t *le, *len; //空闲链表的头部和长度
le = &free_list; //空闲链表的头部
while((le=list_next(le)) != &free_list) {
//遍历整个空闲链表
struct Page *p = le2page(le, page_link); //转换为页结构
if(p->property >= n){
//找到合适的空闲页
int i;
for(i=0;i<n;i++){
len = list_next(le);
struct Page *pp = le2page(le, page_link); //转换页结构
SetPageReserved(pp); //设置每一页的标志位
ClearPageProperty(pp);
list_del(le); //将此页从free_list中清除
le = len;
}
if(p->property>n){
//如果页块大小大于所需大小,分割页块
(le2page(le,page_link))->property = p->property-n;
}
ClearPageProperty(p);
SetPageReserved(p);
nr_free -= n; //减去已经分配的页块大小
return p;
}
}
return NULL;
}
该函数分配指定页数的连续空闲物理内存空间,返回分配的空间中第一页的Page结构的指针。
首先说明一下该函数的代码过程:首先,判断空闲页的总数是否足够分配所需要的内存大小,若是足够则继续向下执行,否则则返回NULL指针。过了这一个检查之后,遍历整个空闲链表。如果找到合适的空闲页,即p->property >= n(从该页开始,连续的空闲页数量大于n),即可认为可分配,重新设置标志位。具体操作是调用ClearPageProperty(pp),将分配出去的内存页标记为非空闲。然后从空闲链表,即free_area_t中,删除此项。如果当前空闲页的大小大于所需大小。则分割页块。具体操作就是,刚刚分配了n个页,如果分配完了,还有连续的空间,则在最后分配的那个页的下一个页(未分配),更新它的连续空闲页值。如果正好合适,则不进行操作。最后计算剩余空闲页个数并返回分配的页块地址。
流程:从起始位置开始顺序搜索空闲块链表,找到第一个页数不小于所申请页数n的块(只需检查每个Page的property成员,在其值>=n的第一个页停下),如果这个块的页数正好等于申请的页数,则可直接分配;如果页数比申请的页数多,要将块分成两半,将起始地址较低的一半分配出去,将起始地址较高的一半作为链表内新的块,分配完成后重新计算块内空闲页数和全局空闲页数;若遍历整个空闲链表仍找不到足够大的块,则返回NULL表示分配失败。
default_free_pages
代码的实现如下:
static void
default_free_pages(struct Page *base, size_t n) {
assert(n > 0);
assert(PageReserved(base)); //检查需要释放的页块是否已经被分配
list_entry_t *le = &free_list;
struct Page * p;
while((le=list_next(le)) != &free_list) {
//寻找合适的位置
p = le2page(le, page_link); //获取链表对应的Page
if(p>base){
break;
}
}
for(p=base;p<base+n;p++){
list_add_before(le, &(p->page_link)); //将每一空闲块对应的链表插入空闲链表中
}
base->flags = 0; //修改标志位
set_page_ref(base, 0);
ClearPageProperty(base);
SetPageProperty(base);
base->property = n; //设置连续大小为n
//如果是高位,则向高地址合并
p = le2page(le,page_link) ;
if( base+n == p ){
base->property += p->property;
p->property = 0;
}
//如果是低位且在范围内,则向低地址合并
le = list_prev(&(base->page_link));
p = le2page(le, page_link);
if(le!=&free_list && p==base-1){
//满足条件,未分配则合并
while(le!=&free_list){
if(p->property){
//连续
p->property += base->property;
base->property = 0;
break;
}
le = list_prev(le);
p = le2page(le,page_link);
}
}
nr_free += n;
return ;
}
释放从指定的某一物理页开始的若干个被占用的连续物理页,将这些页放回空闲块链表,重置其中的标志信息,最后进行一些碎片整理性质的块合并操作。
首先根据参数提供的块基址,遍历链表找到待插入位置,插入这些页。然后将引用计数ref、flags标志位置位,最后调用merge_blocks函数迭代地进行块合并,以获取尽可能大的连续内存块。规则是从新插入的块开始,首先正序遍历链表,不断将链表内基址与新插入块物理地址较大一端相邻的空闲块合并到新插入块里(也是对应着分配内存块时将物理基址较大的块留在链表里);然后反序遍历链表,不断将链表内的基址与新插入块物理地址较小一端相邻的空闲块合并到新插入块里。
练习2:实现寻找虚拟地址对应的页表项(需要编程)
通过设置页表和对应的页表项,可建立虚拟内存地址和物理内存地址的对应关系。其中的get_pte函数是设置页表项环节中的一个重要步骤。此函数找到一个虚地址对应的二级页表项的内核虚地址,如果此二级页表项不存在,则分配一个包含此项的二级页表。本练习需要补全get_pte函数 in kern/mm/pmm.c,实现其功能。请仔细查看和理解get_pte函数中的注释。get_pte函数的调用关系图如下所示:
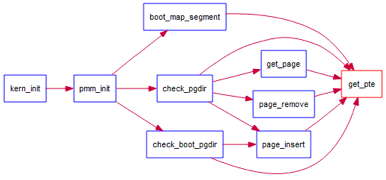 图1 get_pte函数的调用关系图
图1 get_pte函数的调用关系图
请在实验报告中简要说明你的设计实现过程。请回答如下问题:
- 请描述页目录项(Page Directory Entry)和页表项(Page Table Entry)中每个组成部分的含义以及对ucore而言的潜在用处。
- 如果ucore执行过程中访问内存,出现了页访问异常,请问硬件要做哪些事情?
提前先要弄清楚:PDT(页目录表),PDE(页目录项),PTT(页表),PTE(页表项)之间的关系:页表保存页表项,页表项被映射到物理内存地址;页目录表保存页目录项,页目录项映射到页表。
解:根据提示,我们首先查看get_pte函数中的注释:
//get_pte - get pte and return the kernel virtual address of this pte for la
// - if the PT contians this pte didn't exist, alloc a page for PT
// parameter:
// pgdir: the kernel virtual base address of PDT
// la: the linear address need to map
// create: a logical value to decide if alloc a page for PT
// return vaule: the kernel virtual address of this pte
pte_t *
get_pte(pde_t *pgdir, uintptr_t la, bool create) {
/* LAB2 EXERCISE 2: YOUR CODE * * If you need to visit a physical address, please use KADDR() * please read pmm.h for useful macros * * Maybe you want help comment, BELOW comments can help you finish the code * * Some Useful MACROs and DEFINEs, you can use them in below implementation. * MACROs or Functions: * PDX(la) = the index of page directory entry of VIRTUAL ADDRESS la. * KADDR(pa) : takes a physical address and returns the corresponding kernel virtual address. * set_page_ref(page,1) : means the page be referenced by one time * page2pa(page): get the physical address of memory which this (struct Page *) page manages * struct Page * alloc_page() : allocation a page * memset(void *s, char c, size_t n) : sets the first n bytes of the memory area pointed by s * to the specified value c. * DEFINEs: * PTE_P 0x001 // page table/directory entry flags bit : Present * PTE_W 0x002 // page table/directory entry flags bit : Writeable * PTE_U 0x004 // page table/directory entry flags bit : User can access */
#if 0
pde_t *pdep = NULL; // (1) find page directory entry
if (0) {
// (2) check if entry is not present
// (3) check if creating is needed, then alloc page for page table
// CAUTION: this page is used for page table, not for common data page
// (4) set page reference
uintptr_t pa = 0; // (5) get linear address of page
// (6) clear page content using memset
// (7) set page directory entry's permission
}
return NULL; // (8) return page table entry
#endif
}
上面的注释说明了一些接下来写函数可能会遇到的函数定义和宏定义:
PDX(la): 返回虚拟地址la的页目录索引
KADDR(pa): 返回物理地址pa相关的内核虚拟地址
set_page_ref(page,1): 设置此页被引用一次
page2pa(page): 得到page管理的那一页的物理地址
struct Page * alloc_page() : 分配一页出来
memset(void * s, char c, size_t n) : 设置s指向地址的前面n个字节为字节‘c’
PTE_P 0x001 表示物理内存页存在
PTE_W 0x002 表示物理内存页内容可写
PTE_U 0x004 表示可以读取对应地址的物理内存页内容
根据题目的描述,我们可以知道我们需要了解段页式管理的基本概念: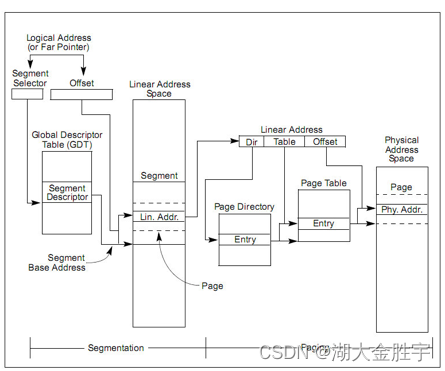
如图在保护模式中,x86 体系结构将内存地址分成三种:逻辑地址(也称虚地址)、线性地址和物理地址。逻辑地址即是程序指令中使用的地址,物理地址是实际访问内存的地址。逻辑地址通过段式管理的地址映射可以得到线性地址,线性地址通过页式管理的地址映射得到物理地址。
但是该实验将逻辑地址不加转换直接映射成线性地址,所以我们在下面的讨论中可以对这两个地址不加区分(目前的 OS 实现也是不加区分的)。
如图所示,页式管理将线性地址分成三部分(图中的 Linear Address 的 Directory 部分、 Table 部分和 Offset 部分)。ucore 的页式管理通过一个二级的页表实现。一级页表的起始物理地址存放在 cr3 寄存器中,这个地址必须是一个页对齐的地址,也就是低 12 位必须为 0。目前,ucore 用boot_cr3(mm/pmm.c)记录这个值。
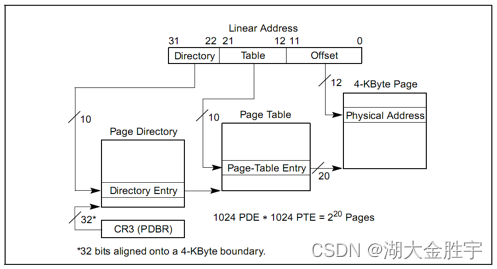
从图中我们可以看到一级页表存放在高10位中,二级页表存放于中间10位中,最后的12位表示偏移量,据此可以证明,页大小为4KB(2的12次方,4096)。
这里涉及到三个类型pte_t、pde_t和uintptr_t。通过查看定义:
typedef unsigned int uint32_t;
typedef uint32_t uintptr_t;
typedef uintptr_t pte_t;
typedef uintptr_t pde_t;
可知它们其实都是unsigned int类型。其中,pde_t 全称为page directory entry,也就是一级页表的表项,前10位;
pte_t 全称为page table entry,表示二级页表的表项,中10位。
从上述图中可以看到对于32位的线性地址,我们可以将它拆分成三部分,这里我们查看mmu.h来查看这些部分的定义:
// A linear address 'la' has a three-part structure as follows:
//
// +--------10------+-------10-------+---------12----------+
// | Page Directory | Page Table | Offset within Page |
// | Index | Index | |
// +----------------+----------------+---------------------+
// \--- PDX(la) --/ \--- PTX(la) --/ \---- PGOFF(la) ----/
// \----------- PPN(la) -----------/
//
// The PDX, PTX, PGOFF, and PPN macros decompose linear addresses as shown.
// To construct a linear address la from PDX(la), PTX(la), and PGOFF(la),
// use PGADDR(PDX(la), PTX(la), PGOFF(la)).
// page directory index
#define PDX(la) ((((uintptr_t)(la)) >> PDXSHIFT) & 0x3FF)
// page table index
#define PTX(la) ((((uintptr_t)(la)) >> PTXSHIFT) & 0x3FF)
// page number field of address
#define PPN(la) (((uintptr_t)(la)) >> PTXSHIFT)
// offset in page
#define PGOFF(la) (((uintptr_t)(la)) & 0xFFF)
// construct linear address from indexes and offset
#define PGADDR(d, t, o) ((uintptr_t)((d) << PDXSHIFT | (t) << PTXSHIFT | (o)))
// address in page table or page directory entry
#define PTE_ADDR(pte) ((uintptr_t)(pte) & ~0xFFF)
#define PDE_ADDR(pde) PTE_ADDR(pde)
la是线性地址,32位,需要提取出该字段内容,才能获取页表内容。
其中,PDXSHIFT的值为22,右移22位,再与10个1与,就可以获取directory;PTXSHIFT的值为11,右移10位,再与11个1与,由于地址对齐的原因,0x3FF的11位之前都是0,这样就能提取table部分。同时也有偏移量的定义,还有知道了如何构造线性地址。
综上,页表保存页表项,页表项被映射到物理内存地址;页目录表保存页目录项,页目录项映射到页表。
接下来,让我们开始回答问题:
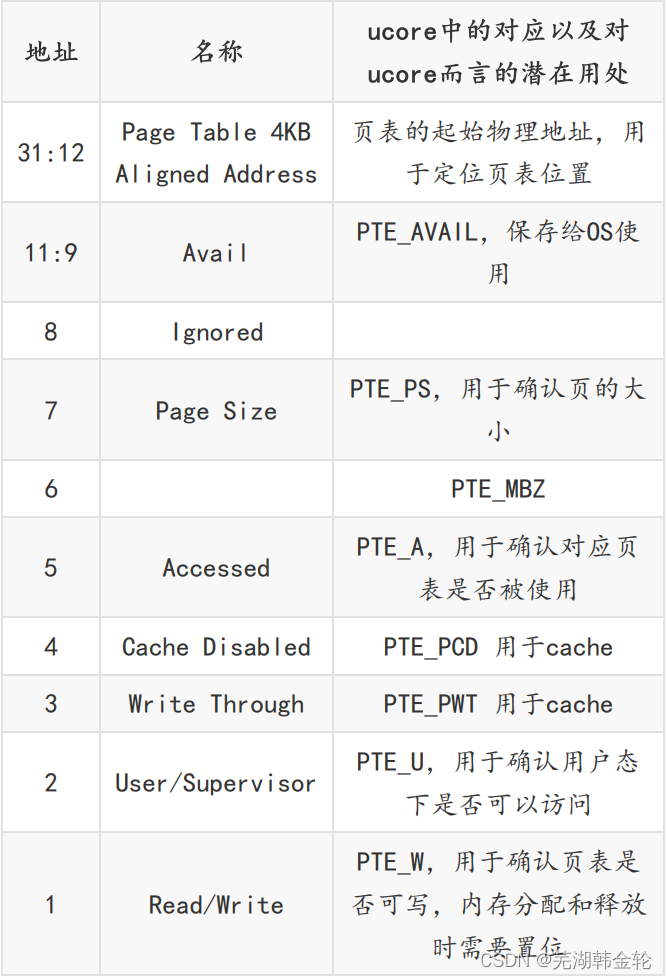
首先是PDE和PTE的各部分含义及用途:
PDE和PTE都是4B大小的一个元素,其高20bit被用于保存索引,低12bit用于保存属性,但是由于用处不同,内部具有细小差异,如图所示:
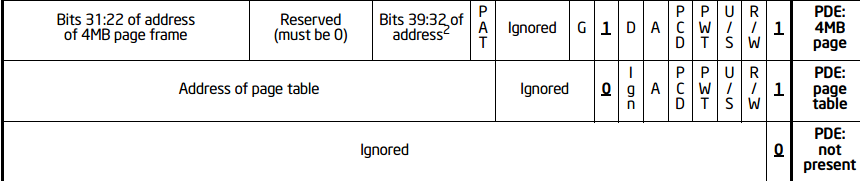
| bit | PDE | PTE |
|---|---|---|
| 0 | Present位,0不存在,1存在下级页表 | 同 |
| 1 | Read/Write位,0只读,1可写 | 同 |
| 2 | User/Supervisor位,0则其下页表/物理页用户无法访问,1可以访问 | 同 |
| 3 | Page level Write Through,1则开启页层次的写回机制,0不开启 | 同 |
| 4 | Page level Cache Disable, 1则禁止页层次缓存,0不禁止 | 同 |
| 5 | Accessed位,1代表在地址翻译过程中曾被访问,0没有 | 同 |
| 6 | 忽略 | 脏位,判断是否有写入 |
| 7 | PS,当且仅当PS=1且CR4.PSE=1,页大小为4M,否则为4K | 如果支持 PAT 分页,间接决定这项访问的页的内存类型,否则为0 |
| 8 | 忽略 | Global 位。当 CR4.PGE 位为 1 时,该位为1则全局翻译 |
| 9 | 忽略 | 忽略 |
| 10 | 忽略 | 忽略 |
| 11 | 忽略 | 忽略 |
出现页访问异常时,硬件执行的工作:
首先需要将发生错误的线性地址la保存在CR2寄存器中
- 这里说一下控制寄存器CR0-4的作用
- CR0的0位是PE位,如果为1则启动保护模式,其余位也有自己的作用
- CR1是未定义控制寄存器,留着以后用
- CR2是页故障线性地址寄存器,保存最后一次出现页故障的全32位线性地址
- CR3是页目录基址寄存器,保存PDT的物理地址
- CR4在Pentium系列处理器中才实现,它处理的事务包括诸如何时启用虚拟8086模式等
之后需要往中断时的栈中压入EFLAGS,CS,EIP,ERROR CODE,如果这页访问异常很不巧发生在用户态,还需要先压入SS,ESP并切换到内核态
最后根据IDT表查询到对应的也访问异常的ISR,跳转过去并将剩下的部分交给软件处理。
代码的实现:
pte_t *
get_pte(pde_t *pgdir, uintptr_t la, bool create) {
pde_t *pdep = &pgdir[PDX(la)]; //尝试获得页表
if (!(*pdep & PTE_P)) {
//如果获取不成功
struct Page *page;
//假如不需要分配或是分配失败
if (!create || (page = alloc_page()) == NULL) {
return NULL;
}
set_page_ref(page, 1); //引用次数加一
uintptr_t pa = page2pa(page); //得到该页物理地址
memset(KADDR(pa), 0, PGSIZE); //物理地址转虚拟地址,并初始化
*pdep = pa | PTE_U | PTE_W | PTE_P; //设置控制位
}
return &((pte_t *)KADDR(PDE_ADDR(*pdep)))[PTX(la)];
//KADDR(PDE_ADDR(*pdep)):这部分是由页目录项地址得到关联的页表物理地址, 再转成虚拟地址
//PTX(la):返回虚拟地址la的页表项索引
//最后返回的是虚拟地址la对应的页表项入口地址
}
首先尝试使用PDX函数,获取一级页表的位置,如果获取成功,可以直接返回一个东西。
如果获取不成功,那么需要根据create标记位来决定是否创建这一个二级页表(注意,一级页表中,存储的都是二级页表的起始地址)。如果create为0,那么不创建,否则创建。
既然需要查找这个页表,那么页表的引用次数就要加一。
之后,需要使用memset将新建的这个页表虚拟地址,全部设置为0,因为这个页所代表的虚拟地址都没有被映射。
接下来是设置控制位。这里应该设置同时设置上PTE_U、PTE_W和PTE_P,分别代表用户态的软件可以读取对应地址的物理内存页内容、物理内存页内容可写、物理内存页存在。

只有当一级二级页表的项都设置了用户写权限后,用户才能对对应的物理地址进行读写。所以我们可以在一级页表先给用户写权限,再在二级页表上面根据需要限制用户的权限,对物理页进行保护。由于一个物理页可能被映射到不同的虚拟地址上去(譬如一块内存在不同进程间共享),当这个页需要在一个地址上解除映射时,操作系统不能直接把这个页回收,而是要先看看它还有没有映射到别的虚拟地址上。这是通过查找管理该物理页的Page数据结构的成员变量ref(用来表示虚拟页到物理页的映射关系的个数)来实现的,如果ref为0了,表示没有虚拟页到物理页的映射关系了,就可以把这个物理页给回收了,从而这个物理页是free的了,可以再被分配。page_insert函数将物理页映射在了页表上。可参看page_insert函数的实现来了解ucore内核是如何维护这个变量的。当不需要再访问这块虚拟地址时,可以把这块物理页回收并在将来用在其他地方。取消映射由page_remove来做,这其实是page_insert的逆操作。
在这里,我们看到了KADDR函数,我们来看一下具体的声明:
/* * * KADDR - takes a physical address and returns the corresponding kernel virtual * address. It panics if you pass an invalid physical address. * */
#define KADDR(pa) ({
\ uintptr_t __m_pa = (pa); \ size_t __m_ppn = PPN(__m_pa); \ if (__m_ppn >= npage) {
\ panic("KADDR called with invalid pa %08lx", __m_pa); \ } \ (void *) (__m_pa + KERNBASE); \ })
最后用KADDR返回二级页表所对应的线性地址,因为这里不是要求物理地址,而是需要找对应的二级页表项,在查询完二级页表之前,都还是属于虚拟地址的范畴。
练习3:释放某虚地址所在的页并取消对应二级页表项的映射(需要编程)
当释放一个包含某虚地址的物理内存页时,需要让对应此物理内存页的管理数据结构Page做相关的清除处理,使得此物理内存页成为空闲;另外还需把表示虚拟地址与物理地址对应关系的二级页表项清除。请仔细查看和理解page_remove_pte函数中的注释。为此,需要补全在 kern/mm/pmm.c中的page_remove_pte函数。page_remove_pte函数的调用关系图如下所示:
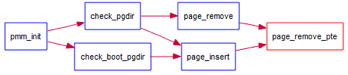
图2 page_remove_pte函数的调用关系图
请在实验报告中简要说明你的设计实现过程。请回答如下问题:
- 数据结构Page的全局变量(其实是一个数组)的每一项与页表中的页目录项和页表项有无对应关系?如果有,其对应关系是啥?
- 如果希望虚拟地址与物理地址相等,则需要如何修改lab2,完成此事? 鼓励通过编程来具体完成这个问题
解:首先我们看到需要设计代码的注释:
//page_remove_pte - free an Page sturct which is related linear address la
// - and clean(invalidate) pte which is related linear address la
//note: PT is changed, so the TLB need to be invalidate
static inline void
page_remove_pte(pde_t *pgdir, uintptr_t la, pte_t *ptep) {
/* LAB2 EXERCISE 3: YOUR CODE * * Please check if ptep is valid, and tlb must be manually updated if mapping is updated * * Maybe you want help comment, BELOW comments can help you finish the code * * Some Useful MACROs and DEFINEs, you can use them in below implementation. * MACROs or Functions: * struct Page *page pte2page(*ptep): get the according page from the value of a ptep * free_page : free a page * page_ref_dec(page) : decrease page->ref. NOTICE: ff page->ref == 0 , then this page should be free. * tlb_invalidate(pde_t *pgdir, uintptr_t la) : Invalidate a TLB entry, but only if the page tables being * edited are the ones currently in use by the processor. * DEFINEs: * PTE_P 0x001 // page table/directory entry flags bit : Present */
#if 0
if (0) {
//(1) check if this page table entry is present
struct Page *page = NULL; //(2) find corresponding page to pte
//(3) decrease page reference
//(4) and free this page when page reference reachs 0
//(5) clear second page table entry
//(6) flush tlb
}
#endif
}
上述注释提到了一些宏定义,同时也说明了解题的思路。
接下来说明一下这些宏定义和函数的具体含义:
#define PTE_P 0x001 // Present
页表/目录条目标志位:存在位。
tlb_invalidate(pde_t *pgdir, uintptr_t la):
// invalidate a TLB entry, but only if the page tables being
// edited are the ones currently in use by the processor.
void
tlb_invalidate(pde_t *pgdir, uintptr_t la) {
if (rcr3() == PADDR(pgdir)) {
invlpg((void *)la);
}
}
当修改的页表是进程正在使用的那些页表,使之无效。
page_ref_dec(page):
static inline int
page_ref_dec(struct Page *page) {
page->ref -= 1; //引用数减一
return page->ref;
}
减少该页的引用次数,返回剩下引用次数。很明显看出来,这个函数试探一下当前这个页被引用的次数,如果只被上一级(二级页表)引用了一次,那么减一以后就是0,页和对应的二级页表都可以直接被释放(将二级页表置0是取消映射)。
如果还有更多的页表应用了它,那就不能释放掉这个页,但是取消对应二级页表项的映射,也就是把映射的入口(传入的二级页表)释放为0。
pte2page:
static inline struct Page *
pte2page(pte_t pte) {
//从ptep值中获取相应的页面
if (!(pte & PTE_P)) {
panic("pte2page called with invalid pte");
}
return pa2page(PTE_ADDR(pte));
}
代码的实现:
static inline void
page_remove_pte(pde_t *pgdir, uintptr_t la, pte_t *ptep) {
if (*ptep & PTE_P) {
//页表项存在
struct Page *page = pte2page(*ptep); //找到页表项
if (page_ref_dec(page) == 0) {
//只被当前进程引用
free_page(page); //释放页
}
*ptep = 0; //该页目录项清零
tlb_invalidate(pgdir, la);
//修改的页表是进程正在使用的那些页表,使之无效
}
}
可以看到根据注释可以很容易写出代码。
数据结构Page的全局变量(其实是一个数组)的每一项与页表中的页目录项和页表项有无对应关系?如果有,其对应关系是啥?
所有的物理页都有一个描述它的Page结构,所有的页表都是通过alloc_page()分配的,每个页表项都存放在一个Page结构描述的物理页中;如果 PTE 指向某物理页,同时也有一个Page结构描述这个物理页。所以有两种对应关系:
(1)可以通过 PTE 的地址计算其所在的页表的Page结构:
将虚拟地址向下对齐到页大小,换算成物理地址(减 KERNBASE), 再将其右移 PGSHIFT(12)位获得在pages数组中的索引PPN,&pages[PPN]就是所求的Page结构地址。
(2)可以通过 PTE 指向的物理地址计算出该物理页对应的Page结构:
PTE 按位与 0xFFF获得其指向页的物理地址,再右移 PGSHIFT(12)位获得在pages数组中的索引PPN,&pages[PPN]就 PTE 指向的地址对应的Page结构。
如果希望虚拟地址与物理地址相等,则需要如何修改lab2,完成此事? 鼓励通过编程来具体完成这个问题
ucore 设置虚拟地址到物理地址的映射分为两步:
- lab 2 中 ucore的入口点
kern_entry()(定义在 kern/init/entry.s)中,设置了一个临时页表,将虚拟地址 KERNBASE ~ KERNBASE + 4M 映射到物理地址 0 ~ 4M ,并将 eip 修改到对应的虚拟地址。ucore 所有代码和本实验操作的所有数据结构(Page数组)都在这个虚拟地址范围内。 - 在确保程序可以正常运行后,调用boot_map_segment(boot_pgdir, KERNBASE, KMEMSIZE, 0, PTE_W);将虚拟地址KERNBASE ~ KERNBASE + KMEMSIZE。
因为在编译链接时 ld 脚本 kern/tools/kernel.ld设置链接地址(虚拟地址),代码段基地址为0xC0100000(对应物理地址0x00100000),必须将该地址修改为0x00100000以确保内核加载正确。
/* Load the kernel at this address: "." means the current address */
/* . = 0xC0100000; */
. = 0x00100000;
.text : {
*(.text .stub .text.* .gnu.linkonce.t.*)
}
在第1步中,ucore 设置了虚拟地址 0 ~ 4M 到物理地址 0 ~ 4M 的映射以确保开启页表后kern_entry能够正常执行,在将 eip 修改为对应的虚拟地址(加KERNBASE)后就取消了这个临时映射。因为我们要让物理地址等于虚拟地址,所以保留这个映射不变(将清除映射的代码注释掉)。
next:
# unmap va 0 ~ 4M, it's temporary mapping
#xorl %eax, %eax
#movl %eax, __boot_pgdir
ucore的代码大量使用了KERNBASE+物理地址等于虚拟地址的映射,为了尽可能降低修改的代码数,仍使用宏KERNBASE和VPT(lab2中没有用到,为了避免bug仍然修改它),但是将他们减去0x38000000。
// #define KERNBASE 0xC0000000
#define KERNBASE 0x00000000
// #define VPT 0xFAC00000
#define VPT 0xC2C00000
修改了KERNBASE后,虚拟地址和物理地址的关系就变成了:
physical address + 0 == virtual address
在boot_map_segment()中,先清除boot_pgdir[1]的 present 位,再进行其他操作。这是get_pte会分配一个物理页作为boot_pgdir[1]指向的页表。
static void
boot_map_segment(pde_t *pgdir, uintptr_t la, size_t size, uintptr_t pa, uint32_t perm)
{
boot_pgdir[1] &= ~PTE_P;
...
}
虚拟地址到物理地址的映射改变了,不可能通过check_pgdir()和check_boot_pgdir()的测试,所以要注释掉这两行调用。
最终运行结果如下:
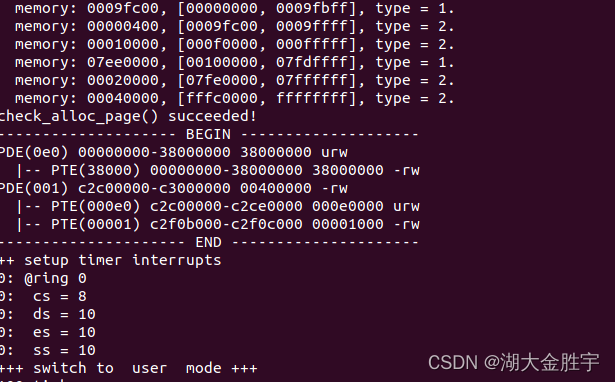
小结:
完成三个练习后,输入make qemu可以得到如下的结果:
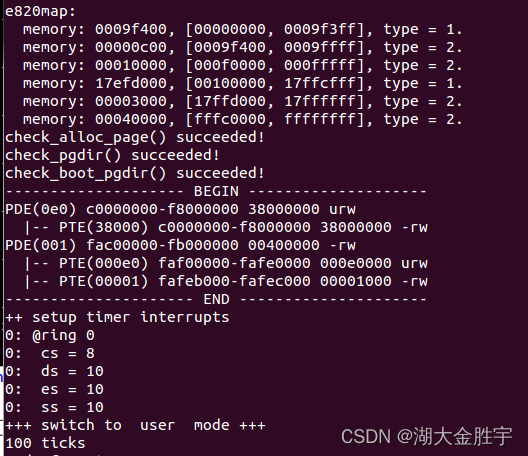
同时,怎么知道输出的结果是正确的呢?输入make grade,看到如下结果就可以知道是正确的:
至此,实验二已经初步完成了。
扩展练习Challenge:buddy system(伙伴系统)分配算法(需要编程)
Buddy System算法把系统中的可用存储空间划分为存储块(Block)来进行管理, 每个存储块的大小必须是2的n次幂(Pow(2, n)), 即1, 2, 4, 8, 16, 32, 64, 128…
- 参考伙伴分配器的一个极简实现, 在ucore中实现buddy system分配算法,要求有比较充分的测试用例说明实现的正确性,需要有设计文档。
解:首先,我们需要理解buddy system(伙伴系统)的定义:
分配内存:
1.寻找大小合适的内存块(大于等于所需大小并且最接近2的幂,比如需要27,实际分配32)
1.1 如果找到了,分配给应用程序。
1.2 如果没找到,分出合适的内存块。
1.2.1 对半分离出高于所需大小的空闲内存块
1.2.2 如果分到最低限度,分配这个大小。
1.2.3 回溯到步骤1(寻找合适大小的块)
1.2.4 重复该步骤直到一个合适的块
释放内存:
1.释放该内存块
1.1 寻找相邻的块,看其是否释放了。
1.2 如果相邻块也释放了,合并这两个块,重复上述步骤直到遇上未释放的相邻块,或者达到最高上限(即所有内存都释放了)。
在此定义之下,我们使用数组分配器来模拟构建这样完全二叉树结构而不是真的用指针建立树结构——树结构中向上或向下的指针索引都通过数组分配器里面的下标偏移来实现。在这个“完全二叉树”结构中,二叉树的节点用于标记相应内存块的使用状态,高层节点对应大的块,低层节点对应小的块,在分配和释放中我们就通过这些节点的标记属性来进行块的分离合并。
在分配阶段,首先要搜索大小适配的块——这个块所表示的内存大小刚好大于等于最接近所需内存的2次幂;通过对树深度遍历,从左右子树里面找到最合适的,将内存分配。
在释放阶段,我们将之前分配出去的内存占有情况还原,并考察能否和同一父节点下的另一节点合并,而后递归合并,直至不能合并为止。
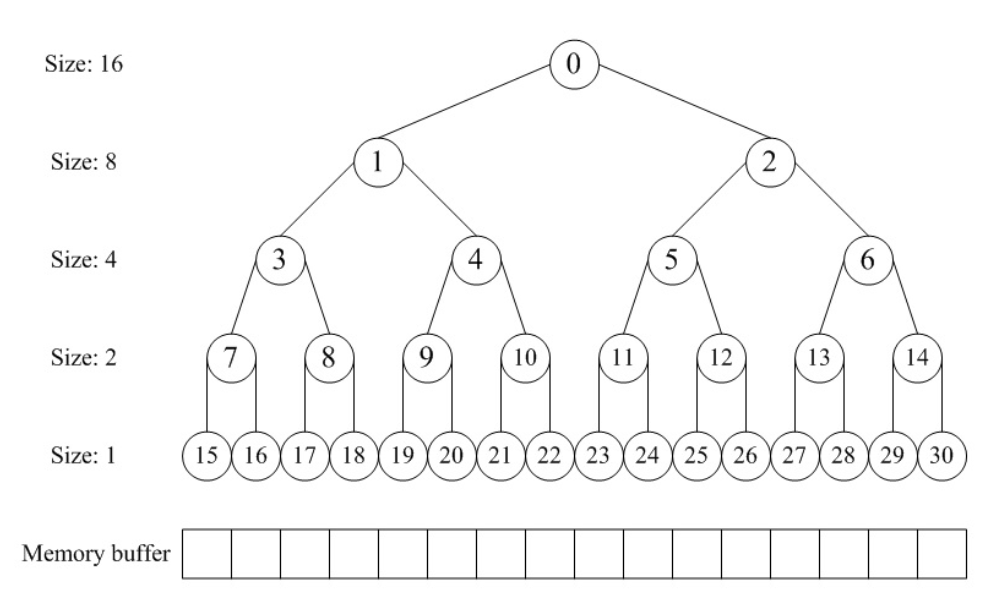
前置准备
伙伴系统中每个存储块的大小都必须是2的n次幂,所以其中必须有个可以将传入数转换为最接近该数的2的n次幂的函数,相关代码如下:
// 传入一个数,返回最接近该数的2的指数(包括该数为2的整数这种情况)
size_t getLessNearOfPower2(size_t x)
{
size_t _i;
for(_i = 0; _i < sizeof(size_t) * 8 - 1; _i++)
if((1 << (_i+1)) > x)
break;
return (size_t)(1 << _i);
}
初始化
初始时,程序会多次将一块尺寸很大的物理内存空间传入init_memmap函数,但该物理内存空间的大小却不一定是2的n次幂,所以需要对其进行分割。设定分割后的内存布局如下:
/* buddy system中的内存布局 某块较大的物理空间 低地址 高地址 +-+--+----+--------+-------------------+ | | | | | | +-+--+----+--------+-------------------+ 低地址的内存块较小 高地址的内存块较大 */
同时,在双向链表free_area.free_list中,令空间较小的内存块在双向链表中靠前,空间较大的内存块在双向链表中靠后;低地址在前,高地址在后。故以下是最终的链表布局:
/* free_area.free_list中的内存块顺序: 1. 一大块连续物理内存被切割后,free_area.free_list中的内存块顺序 addr: 0x34 0x38 0x40 +----+ +--------+ +---------------+ <-> | 0x4| <-> | 0x8 | <-> | 0x10 | <-> +----+ +--------+ +---------------+ 2. 几大块物理内存(这几块之间可能不连续)被切割后,free_area.free_list中的内存块顺序 addr: 0x34 0x104 0x38 0x108 0x40 0x110 +----+ +----+ +--------+ +--------+ +---------------+ +---------------+ <-> | 0x4| <-> | 0x4| <-> | 0x8 | <-> | 0x8 | <-> | 0x10 | <-> | 0x10 | <-> +----+ +----+ +--------+ +--------+ +---------------+ +---------------+ */
根据上面的内存规划,可以得到buddy_init_memmap的代码
static void
buddy_init_memmap(struct Page *base, size_t n) {
assert(n > 0);
// 设置当前页向后的curr_n个页
struct Page *p = base;
for (; p != base + n; p ++) {
assert(PageReserved(p));
p->flags = p->property = 0;
set_page_ref(p, 0);
}
// 设置总共的空闲内存页面
nr_free += n;
// 设置base指向尚未处理内存的end地址
base += n;
while(n != 0)
{
size_t curr_n = getLessNearOfPower2(n);
// 向前挪一块
base -= curr_n;
// 设置free pages的数量
base->property = curr_n;
// 设置当前页为可用
SetPageProperty(base);
// 按照块的大小来插入空闲块,从小到大排序
// @note 这里必须使用搜索的方式来插入块而不是直接list_add_after(&free_list),因为存在大的内存块不相邻的情况
list_entry_t* le;
for(le = list_next(&free_list); le != &free_list; le = list_next(le))
{
struct Page *p = le2page(le, page_link);
// 排序方式以内存块大小优先,地址其次。
if((p->property > base->property)
|| (p->property == base->property && p > base))
break;
}
list_add_before(le, &(base->page_link));
n -= curr_n;
}
}
空间分配
分配空间时,遍历双向链表,查找大小合适的内存块。
- 若链表中不存在合适大小的内存块,则对半切割遍历过程中遇到的第一块大小大于所需空间的内存块。
- 如果切割后的两块内存块的大小还是太大,则继续切割第一块内存块。
- 循环该操作,直至切割出合适大小的内存块。
最终buddy_alloc_pages代码如下:
static struct Page *
buddy_alloc_pages(size_t n) {
assert(n > 0);
// 向上取2的幂次方,如果当前数为2的幂次方则不变
size_t lessOfPower2 = getLessNearOfPower2(n);
if (lessOfPower2 < n)
n = 2 * lessOfPower2;
// 如果待分配的空闲页面数量小于所需的内存数量
if (n > nr_free) {
return NULL;
}
// 查找符合要求的连续页
struct Page *page = NULL;
list_entry_t *le = &free_list;
while ((le = list_next(le)) != &free_list) {
struct Page *p = le2page(le, page_link);
if (p->property >= n) {
page = p;
break;
}
}
// 如果需要切割内存块时,一定分配切割后的前面那块
if (page != NULL) {
// 如果内存块过大,则持续切割内存
while(page->property > n)
{
page->property /= 2;
// 切割出的右边那一半内存块不用于内存分配
struct Page *p = page + page->property;
p->property = page->property;
SetPageProperty(p);
list_add_after(&(page->page_link), &(p->page_link));
}
nr_free -= n;
ClearPageProperty(page);
assert(page->property == n);
list_del(&(page->page_link));
}
return page;
}
内存释放
释放内存时
先将该内存块按照内存块大小从小到大与内存块地址从小到大的顺序插入至双向链表(具体请看上面的链表布局)。
尝试向前合并,一次就够。如果向前合并成功,则一定不能再次向前合并。
之后循环向后合并,直至无法合并。
需要注意的是,在查找两块内存块能否合并时,若当前内存块合并过,则其大小会变为原来的2倍,此时需要遍历比原始大小(合并前内存块大小)更大的内存块。
判断当前内存块的位置是否正常,如果不正常,则需要断开链表并重新插入至新的位置。
如果当前内存块没有合并则肯定正常,如果合并过则不一定异常。
最终代码如下:
static void
buddy_free_pages(struct Page *base, size_t n) {
assert(n > 0);
// 向上取2的幂次方,如果当前数为2的幂次方则不变
size_t lessOfPower2 = getLessNearOfPower2(n);
if (lessOfPower2 < n)
n = 2 * lessOfPower2;
struct Page *p = base;
for (; p != base + n; p ++) {
assert(!PageReserved(p) && !PageProperty(p));
p->flags = 0;
set_page_ref(p, 0);
}
base->property = n;
SetPageProperty(base);
nr_free += n;
list_entry_t *le;
// 先插入至链表中
for(le = list_next(&free_list); le != &free_list; le = list_next(le))
{
p = le2page(le, page_link);
if ((base->property <= p->property)
|| (p->property == base->property && p > base))) {
break;
}
}
list_add_before(le, &(base->page_link));
// 先向左合并
if(base->property == p->property && p + p->property == base) {
p->property += base->property;
ClearPageProperty(base);
list_del(&(base->page_link));
base = p;
le = &(base->page_link);
}
// 之后循环向后合并
// 此时的le指向插入块的下一个块
while (le != &free_list) {
p = le2page(le, page_link);
// 如果可以合并(大小相等+地址相邻),则合并
// 如果两个块的大小相同,则它们不一定内存相邻。
// 也就是说,在一条链上,可能存在多个大小相等但却无法合并的块
if (base->property == p->property && base + base->property == p)
{
// 向右合并
base->property += p->property;
ClearPageProperty(p);
list_del(&(p->page_link));
le = &(base->page_link);
}
// 如果遍历到的内存块一定无法合并,则退出
else if(base->property < p->property)
{
// 如果合并不了,则需要修改base在链表中的位置,使大小相同的聚在一起
list_entry_t* targetLe = list_next(&base->page_link);
p = le2page(targetLe, page_link);
while(p->property < base->property)
|| (p->property == base->property && p > base))
targetLe = list_next(targetLe);
// 如果当前内存块的位置不正确,则重置位置
if(targetLe != list_next(&base->page_link))
{
list_del(&(base->page_link));
list_add_before(targetLe, &(base->page_link));
}
// 最后退出
break;
}
le = list_next(le);
}
}
总结
buddySystem在所分配的内存大小均为2的n次幂这种环境下,使用效果极佳。
由于buddySystem的特性,最好使用二叉树而非普通双向链表来管理内存块,这样就可以避免一系列的bug。
即便普通双向链表可以很好的实现buddySystem,但其中仍然存在一个较为麻烦的问题:
当某个物理块释放,将其插入至双向链表后,如果该物理块既可以和上一个物理块合并,又可以和下一个物理块合并,那么此时该合并哪一个物理块?
结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zXL7EX3y-1654085660290)(C:\Users\zhaolv\AppData\Roaming\Typora\typora-user-images\image-20220430005630823.png)]
在这里,输出的结果是正确的,但是我发现我不能把自己写的算法在ucore里面实现。所以这里模仿前面的练习将buddy system算法插入到ucore中,最后才能成功。
扩展练习Challenge:任意大小的内存单元slub分配算法(需要编程)
slub算法,实现两层架构的高效内存单元分配,第一层是基于页大小的内存分配,第二层是在第一层基础上实现基于任意大小的内存分配。可简化实现,能够体现其主体思想即可。
- 参考linux的slub分配算法/,在ucore中实现slub分配算法。要求有比较充分的测试用例说明实现的正确性,需要有设计文档。
Challenges是选做,做一个就很好了。完成Challenge的同学可单独提交Challenge。完成得好的同学可获得最终考试成绩的加分。
解:首先,我们需要阅读一下需要的博客:
内核对象缓冲区管理
Linux 内核在运行过程中,常常会需要经常使用一些内核的数据结构(对象)。例如,当进程的某个线程第一次打开一个文件的时候,内核需要为该文件分配一个称为 file 的数据结构;当该文件被最终关闭的时候,内核必须释放此文件所关联的 file 数据结构。这些小块存储空间并不只在某个内核函数的内部使用,否则就可以使用当前线程的内核栈空间。同时,这些小块存储空间又是动态变化的,不可能像物理内存页面管理使用的 page 结构那样,有多大内存就有多少个 page 结构,形成一个静态长度的队列。而且由于内核无法预测运行中各种不同的内核对象对缓冲区的需求,因此不适合为每一种可能用到的对象建立一个“缓冲池”,因为那样的话很可能出现有些缓冲池已经耗尽而有些缓冲池中却又大量空闲缓冲区的现象。因此,内核只能采取更全局性的方法。
我们可以看出,内核对象的管理与用户进程中的堆管理比较相似,核心问题均是:如何高效地管理内存空间,使得可以快速地进行对象的分配和回收并减少内存碎片。但是内核不能简单地采用用户进程的基于堆的内存分配算法,这是因为内核对其对象的使用具有以下特殊性:
- 内核使用的对象种类繁多,应该采用一种统一的高效管理方法。
- 内核对某些对象(如 task_struct)的使用是非常频繁的,所以用户进程堆管理常用的基于搜索的分配算法比如First-Fit(在堆中搜索到的第一个满足请求的内存块)和 Best-Fit(使用堆中满足请求的最合适的内存块)并不直接适用,而应该采用某种缓冲区的机制。
- 内核对象中相当一部分成员需要某些特殊的初始化(例如队列头部)而并非简单地清成全 0。如果能充分重用已被释放的对象使得下次分配时无需初始化,那么可以提高内核的运行效率。
- 分配器对内核对象缓冲区的组织和管理必须充分考虑对硬件高速缓存的影响。
- 随着共享内存的多处理器系统的普及,多处理器同时分配某种类型对象的现象时常发生,因此分配器应该尽量避免处理器间同步的开销,应采用某种 Lock-Free 的算法。
如何有效地管理缓冲区空间,长期以来都是一个热门的研究课题。90 年代初期,在 Solaris 2.4 操作系统中,采用了一种称为“slab”(原意是大块的混凝土)的缓冲区分配和管理方法,在相当程度上满足了内核的特殊需求。
SLAB分配器介绍
SLAB 分配器为每种使用的内核对象建立单独的缓冲区。每种缓冲区由多个 slab 组成,每个 slab就是一组连续的物理内存页框,被划分成了固定数目的对象。根据对象大小的不同,缺省情况下一个 slab 最多可以由 1024 个物理内存页框构成。
内核使用 kmem_cache 数据结构管理缓冲区。由于 kmem_cache 自身也是一种内核对象,所以需要一个专门的缓冲区。所有缓冲区的 kmem_cache 控制结构被组织成以 cache_chain 为队列头的一个双向循环队列,同时 cache_cache 全局变量指向kmem_cache 对象缓冲区的 kmem_cache 对象。每个 slab 都需要一个类型为 struct slab 的描述符数据结构管理其状态,同时还需要一个 kmem_bufctl_t(被定义为无符号整数)的结构数组来管理空闲对象。如果对象不超过 1/8 个物理内存页框的大小,那么这些 slab 管理结构直接存放在 slab 的内部,位于分配给 slab 的第一个物理内存页框的起始位置;否则的话,存放在 slab 外部,位于由 kmalloc 分配的通用对象缓冲区中。
slab 中的对象有 2 种状态:已分配或空闲。为了有效地管理 slab,根据已分配对象的数目,slab 可以有 3 种状态,动态地处于缓冲区相应的队列中:
Full 队列,此时该 slab 中没有空闲对象。
Partial 队列,此时该 slab 中既有已分配的对象,也有空闲对象。
Empty 队列,此时该 slab 中全是空闲对象。
在 SLUB 分配器中,一个 slab 就是一组连续的物理内存页框,被划分成了固定数目的对象。slab 没有额外的空闲对象队列(这与 SLAB 不同),而是重用了空闲对象自身的空间。slab 也没有额外的描述结构,因为 SLUB 分配器在代表物理页框的 page 结构中加入 freelist,inuse 和 slab 的 union 字段,分别代表第一个空闲对象的指针,已分配对象的数目和缓冲区 kmem_cache 结构的指针,所以 slab 的第一个物理页框的 page 结构就可以描述自己。
每个处理器都有一个本地的活动 slab,由 kmem_cache_cpu 结构描述。
空间分配
slab_alloc函数:
static __always_inline void *slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node, void *addr)
{
void **object;
struct kmem_cache_cpu *c;
unsigned long flags;
local_irq_save(flags);
c = get_cpu_slab(s, smp_processor_id()); // (a)
if (unlikely(!c->freelist || !node_match(c, node)))
object = __slab_alloc(s, gfpflags, node, addr, c); // (b)
else {
object = c->freelist; // (c)
c->freelist = object[c->offset];
stat(c, ALLOC_FASTPATH);
}
local_irq_restore(flags);
if (unlikely((gfpflags & __GFP_ZERO) && object))
memset(object, 0, c->objsize);
return object; // (d)
}
- 获取本处理器的 kmem_cache_cpu 数据结构。
- 假如当前活动 slab 没有空闲对象,或本处理器所在节点与指定节点不一致,则调用 __slab_alloc 函数。
- 获得第一个空闲对象的指针,然后更新指针使其指向下一个空闲对象。
- 返回对象地址。
__slab_alloc函数:
static void *__slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node, void *addr, struct kmem_cache_cpu *c)
{
void **object;
struct page *new;
gfpflags &= ~__GFP_ZERO;
if (!c->page) // (a)
goto new_slab;
slab_lock(c->page);
if (unlikely(!node_match(c, node))) // (b)
goto another_slab;
stat(c, ALLOC_REFILL);
load_freelist:
object = c->page->freelist;
if (unlikely(!object)) // (c)
goto another_slab;
if (unlikely(SlabDebug(c->page)))
goto debug;
c->freelist = object[c->offset]; // (d)
c->page->inuse = s->objects;
c->page->freelist = NULL;
c->node = page_to_nid(c->page);
unlock_out:
slab_unlock(c->page);
stat(c, ALLOC_SLOWPATH);
return object;
another_slab:
deactivate_slab(s, c); // (e)
new_slab:
new = get_partial(s, gfpflags, node); // (f)
if (new) {
c->page = new;
stat(c, ALLOC_FROM_PARTIAL);
goto load_freelist;
}
if (gfpflags & __GFP_WAIT) // (g)
local_irq_enable();
new = new_slab(s, gfpflags, node); // (h)
if (gfpflags & __GFP_WAIT)
local_irq_disable();
if (new) {
c = get_cpu_slab(s, smp_processor_id());
stat(c, ALLOC_SLAB);
if (c->page)
flush_slab(s, c);
slab_lock(new);
SetSlabFrozen(new);
c->page = new;
goto load_freelist;
}
if (!(gfpflags & __GFP_NORETRY) && (s->flags & __PAGE_ALLOC_FALLBACK)) {
if (gfpflags & __GFP_WAIT)
local_irq_enable();
object = kmalloc_large(s->objsize, gfpflags); // (i)
if (gfpflags & __GFP_WAIT)
local_irq_disable();
return object;
}
return NULL;
debug:
if (!alloc_debug_processing(s, c->page, object, addr))
goto another_slab;
c->page->inuse++;
c->page->freelist = object[c->offset];
c->node = -1;
goto unlock_out;
}
- 如果没有本地活动 slab,转到 (f) 步骤获取 slab 。
- 如果本处理器所在节点与指定节点不一致,转到 (e) 步骤。
- 检查处理器活动 slab 没有空闲对象,转到 (e) 步骤。
- 此时活动 slab 尚有空闲对象,将 slab 的空闲对象队列指针复制到 kmem_cache_cpu 结构的 freelist 字段,把 slab 的空闲对象队列指针设置为空,从此以后只从 kmem_cache_cpu 结构的 freelist 字段获得空闲对象队列信息。
- 取消当前活动 slab,将其加入到所在 NUMA 节点的 Partial 队列中。
- 优先从指定 NUMA 节点上获得一个 Partial slab。
- 加入 gfpflags 标志置有 __GFP_WAIT,开启中断,故后续创建 slab 操作可以睡眠。
- 创建一个 slab,并初始化所有对象。
- 如果内存不足,无法创建 slab,调用 kmalloc_large(实际调用物理页框分配器)分配对象。
内存释放
slab_free函数:
static __always_inline void slab_free(struct kmem_cache *s, struct page *page, void *x, void *addr)
{
void **object = (void *)x;
struct kmem_cache_cpu *c;
unsigned long flags;
local_irq_save(flags);
c = get_cpu_slab(s, smp_processor_id());
debug_check_no_locks_freed(object, c->objsize);
if (likely(page == c->page && c->node >= 0)) {
// (a)
object[c->offset] = c->freelist;
c->freelist = object;
stat(c, FREE_FASTPATH);
} else
__slab_free(s, page, x, addr, c->offset); // (b)
local_irq_restore(flags);
}
- 如果对象属于处理器当前活动的 slab,或处理器所在 NUMA 节点号不为 -1(调试使用的值),将对象放回空闲对象队列。
- 否则调用 __slab_free 函数。
__slab_free函数:
static void __slab_free(struct kmem_cache *s, struct page *page,
void *x, void *addr, unsigned int offset)
{
void *prior;
void **object = (void *)x;
struct kmem_cache_cpu *c;
c = get_cpu_slab(s, raw_smp_processor_id());
stat(c, FREE_SLOWPATH);
slab_lock(page);
if (unlikely(SlabDebug(page)))
goto debug;
checks_ok:
prior = object = page->freelist; // (a)
page->freelist = object;
page->inuse--;
if (unlikely(SlabFrozen(page))) {
stat(c, FREE_FROZEN);
goto out_unlock;
}
if (unlikely(!page->inuse)) // (b)
goto slab_empty;
if (unlikely(!prior)) {
// (c)
add_partial(get_node(s, page_to_nid(page)), page, 1);
stat(c, FREE_ADD_PARTIAL);
}
out_unlock:
slab_unlock(page);
return;
slab_empty:
if (prior) {
// (d)
remove_partial(s, page);
stat(c, FREE_REMOVE_PARTIAL);
}
slab_unlock(page);
stat(c, FREE_SLAB);
discard_slab(s, page);
return;
debug:
if (!free_debug_processing(s, page, x, addr))
goto out_unlock;
goto checks_ok;
}
- 执行本函数表明对象所属 slab 并不是某个活动 slab。保存空闲对象队列的指针,将对象放回此队列,最后把已分配对象数目减一。
- 如果已分配对象数为 0,说明 slab 处于 Empty 状态,转到 (d) 步骤。
- 如果原空闲对象队列的指针为空,说明 slab 原来的状态为 Full,那么现在的状态应该是 Partial,将该 slab 加到所在节点的 Partial 队列中。
- 如果 slab 状态转为 Empty,且先前位于节点的 Partial 队列中,则将其剔出并释放所占内存空间。
总结
到这里,Challenge2已经完成了。同时,这里想要在ucore中实现,只需要像Challenge1中相同更改代码,就可以输出相应的结果。
参考答案分析
练习1
- 由于代码实现本身比较简单,本实验的在default_init, default_memmap的实现上与参考答案的思路基本一致,因此不进行赘述;
- 关于default_alloca_pages函数的实现,本实验与参考答案的实验的区别如下所示:
- 在实现遍历空闲块链表部分,本实验中的实现时先找到符合条件的块,然后退出遍历过程,对空闲块进行处理,而参考答案是直接在遍历过程中进行处理,然后再直接退出函数;
- 答案的实现中,空闲块链表上保存了所有的空闲的物理页对应的Page,而本实验的实现中,空闲块链表上仅存了所有连续空闲块的第一个物理页对应的Page,本人的实现减小了该链表的长度,有利于提高时间效率;
- 接下来讨论default_free_pages函数的实现区别:
- 同样,由于上述提及到的存储在空闲块链表上的内容的不同,本人的实现在删除只需要将某个物理空闲块的第一页从链表上摘下来即可,而参考答案的实现需要将整个空闲块的所有页都从链表上删除掉;
- 在完成空闲块的合并方便,本实验中的实现将合并操作抽出来形成单独的函数,使得代码思路更加清晰;
练习2
- 由于练习2中的代码思路较为简单,本实验中的实现与参考答案的区别仅仅体现在一些具体的代码描述上,比如说在获取页目录表的某一项的时候,参考答案使用
pgdir[PDX(la)]进行获取,而本实验中的实现使用呢了pgdir + PDX(la)进行获取;两者描述没有具体的优劣之分;
练习3
- 由于练习3的代码实现较为简单,本实验中的实现与参考答案基本没有区别,因此不再赘述;
实验中涉及的知识点列举
列举本次实验中涉及到的知识点如下:
- 80386 CPU的段页式内存管理机制,以及进入页机制的方法;
- 对物理内存的探测的方法;
- 具体的连续物理内存分配算法,包括first-fit,best-fit等一系列策略;
- ucore中链表的实现方法;
- 在C语言中使用面向对象思想实现物理内存管理器;
- 链接地址、虚拟地址、线性地址、物理地址以及ELF二进制可执行文件中各个段的含义;
对应到的OS中的知识点如下:
- 内存页管理机制;
- 连续物理内存管理;
两者之间的对应关系为:
- 前者为后者提供了具体完成某一个平台上的操作系统对应的内存管理功能的底层支持;
- 同时在实验中设计到的其他一些知识点,比如面向对象思想、链表的使用等,方便了具体的操作系统的实现编码;
实验中未涉及的知识点列举
实验中未涉及的知识点包括:
- 虚拟内存管理,包括在物理内存不足的情况下将暂时使用不到的物理页换出到外存中,从而实现大于物理内存空间的虚拟内存空间;
- PageFault的处理;
- OS中的进程、线程的创建、管理、调度过程,以及进程间的同步互斥;
- OS中用于访问外存的文件系统;
- OS对IO设备的管理;
lab 原来的状态为 Full,那么现在的状态应该是 Partial,将该 slab 加到所在节点的 Partial 队列中。
- 如果 slab 状态转为 Empty,且先前位于节点的 Partial 队列中,则将其剔出并释放所占内存空间。
边栏推荐
- What are the commonly used SQL statements in software testing?
- Want to change jobs? Do you know the seven skills you need to master in the interview software test
- Global and Chinese markets for GaN on diamond semiconductor substrates 2022-2028: Research Report on technology, participants, trends, market size and share
- Global and Chinese market of barrier thin film flexible electronics 2022-2028: Research Report on technology, participants, trends, market size and share
- Leetcode simple question: check whether two strings are almost equal
- The salary of testers is polarized. How to become an automated test with a monthly salary of 20K?
- MySQL development - advanced query - take a good look at how it suits you
- Install and run tensorflow object detection API video object recognition system of Google open source
- How to transform functional testing into automated testing?
- 线程及线程池
猜你喜欢

软件测试有哪些常用的SQL语句?

Want to learn how to get started and learn software testing? I'll give you a good chat today
Do you know the advantages and disadvantages of several open source automated testing frameworks?
Build your own application based on Google's open source tensorflow object detection API video object recognition system (II)
What is "test paper test" in software testing requirements analysis
软件测试需求分析之什么是“试纸测试”
UCORE lab2 physical memory management experiment report
遇到程序员不修改bug时怎么办?我教你
几款开源自动化测试框架优缺点对比你知道吗?
全网最详细的postman接口测试教程,一篇文章满足你


随机推荐
C language do while loop classic Level 2 questions
Thinking about three cups of tea
Oracle foundation and system table
软件测试方法有哪些?带你看点不一样的东西
Global and Chinese markets of cobalt 2022-2028: Research Report on technology, participants, trends, market size and share
Contest3145 - the 37th game of 2021 freshman individual training match_ A: Prizes
Cc36 different subsequences
Sleep quality today 81 points
Statistics 8th Edition Jia Junping Chapter 4 Summary and after class exercise answers
UCORE lab1 system software startup process experimental report
MySQL数据库(一)
Currently, mysql5.6 is used. Which version would you like to upgrade to?
The latest query tracks the express logistics and analyzes the method of delivery timeliness
Pedestrian re identification (Reid) - Overview
Rearrange spaces between words in leetcode simple questions
Emqtt distribution cluster and node bridge construction
ucore lab2 物理内存管理 实验报告
STC-B学习板蜂鸣器播放音乐2.0
Database monitoring SQL execution
Leetcode simple question: check whether two strings are almost equal