当前位置:网站首页>Build your own application based on Google's open source tensorflow object detection API video object recognition system (I)
Build your own application based on Google's open source tensorflow object detection API video object recognition system (I)
2022-07-06 14:53:00 【gmHappy】
Based on the first part Install and run Google open source TensorFlow Object Detection API Video object recognition system , Build your own application .
Replace the test image
Analysis of the source code :

The official test pictures are placed in test_images Under the table of contents , The name format is image{}.jpg(image+ Digital format ), Cycle two (image1.jpg、image2.jpg), To replace your own test image, just delete the original test_images Picture of catalog , Change your picture to image{}.jpg Format , If there are more than two pictures, modify range(1,?) that will do .
Model replacement
Analysis of the source code :
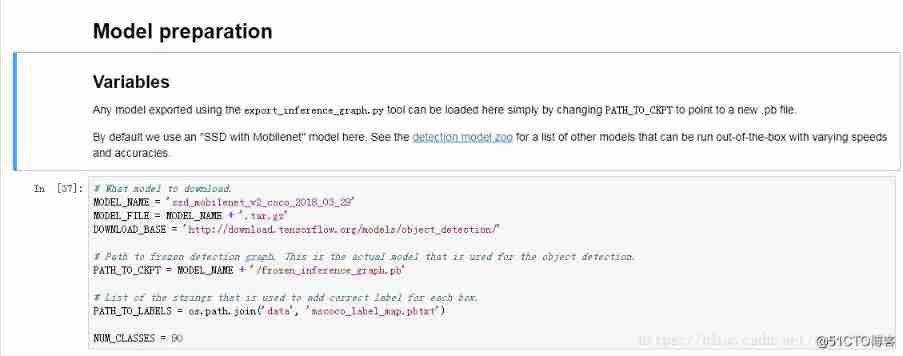
Model description address , As shown in the figure below, select the model you need to download :
The source code will be MODEL_NAME Replace it with the model you need , Pay attention to adding a timestamp

Integrate into your own PYTHON project
newly build PYTHON project , Any project name , The catalog results are as follows :
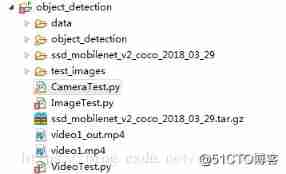
The whole compiled in the previous article object_detection Copy the directory to object_detection\object_detection\ Next ,
newly build test_images Store test pictures , The compiled object_detection/data Copy the directory to object_detection\ Next ,
Transfer the downloaded model ssd_mobilenet_v2_coco_2018_03_29.tar.gz copy to object_detection\ Next ,
newly build ImageTest.py.
So much nonsense , Start coding :
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
from object_detection.utils import ops as utils_ops
if tf.__version__ < '1.4.0':
raise ImportError('Please upgrade your tensorflow installation to v1.4.* or later!')
# This is needed to display the images.
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
##Model preparation##
# What model to download.
MODEL_NAME = 'ssd_mobilenet_v2_coco_2018_03_29'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
NUM_CLASSES = 90
## Download Model##
#opener = urllib.request.URLopener()
#opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
## Load a (frozen) Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
## Loading label map
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
# For the sake of simplicity we will use only 2 images:
# image1.jpg
# image2.jpg
# If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS.
PATH_TO_TEST_IMAGES_DIR = 'test_images'
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 3) ]
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
def run_inference_for_single_image(image, graph):
with graph.as_default():
with tf.Session() as sess:
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: np.expand_dims(image, 0)})
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
return output_dict
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
output_dict = run_inference_for_single_image(image_np, detection_graph)
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
instance_masks=output_dict.get('detection_masks'),
use_normalized_coordinates=True,
line_thickness=8)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_np)
plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
- 124.
- 125.
- 126.
- 127.
- 128.
- 129.
- 130.
- 131.
- 132.
- 133.
- 134.
- 135.
- 136.
- 137.
- 138.
- 139.
- 140.
- 141.
- 142.
- 143.
- 144.
- 145.
- 146.
- 147.
The above code will modify the source code :

Change it to


Change it to ( The model has been downloaded and put , No need to download again )


Change it to ( New addition plt.show(), You can't show it without pictures )

Since then , The TensorFlow Object Detection API Integrate into your own project .
边栏推荐
- MySQL中什么是索引?常用的索引有哪些种类?索引在什么情况下会失效?
- Four methods of exchanging the values of a and B
- 函数:用牛顿迭代法求方程的根
- Using flask_ Whooshalchemyplus Jieba realizes global search of flask
- Binary search tree concept
- Overview of LNMP architecture and construction of related services
- {1,2,3,2,5} duplicate checking problem
- 《统计学》第八版贾俊平第九章分类数据分析知识点总结及课后习题答案
- Statistics, 8th Edition, Jia Junping, Chapter 11 summary of knowledge points of univariate linear regression and answers to exercises after class
- Pointer -- eliminate all numbers in the string
猜你喜欢
Statistics, 8th Edition, Jia Junping, Chapter 6 Summary of knowledge points of statistics and sampling distribution and answers to exercises after class

Markdown font color editing teaching
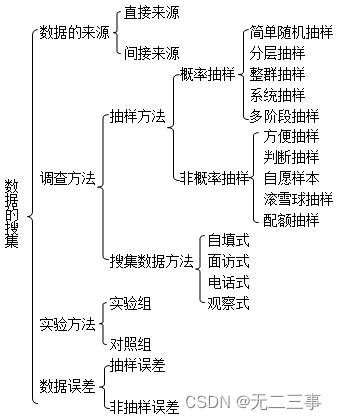
《统计学》第八版贾俊平第二章课后习题及答案总结
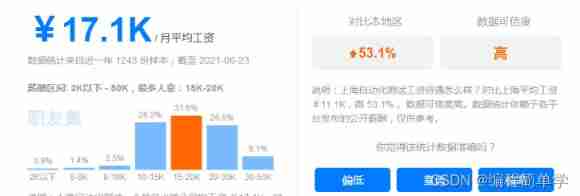
The salary of testers is polarized. How to become an automated test with a monthly salary of 20K?
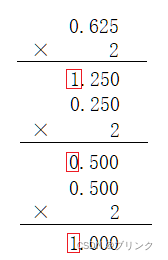
数字电路基础(一)数制与码制

Uibutton status exploration and customization

DVWA exercise 05 file upload file upload
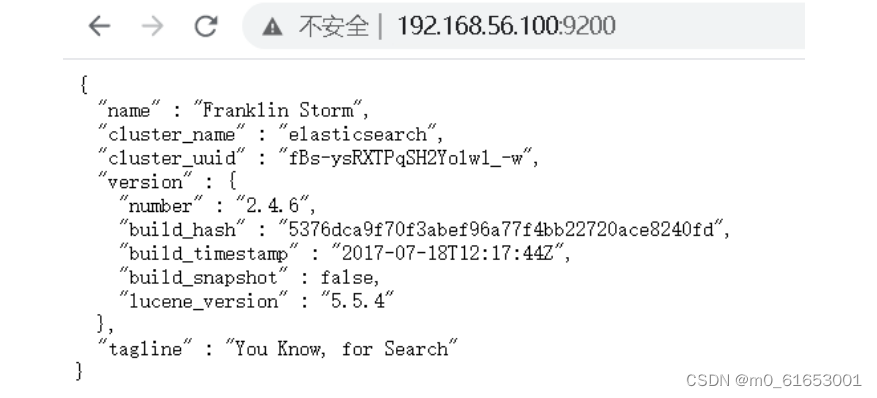
ES全文索引
How to learn automated testing in 2022? This article tells you
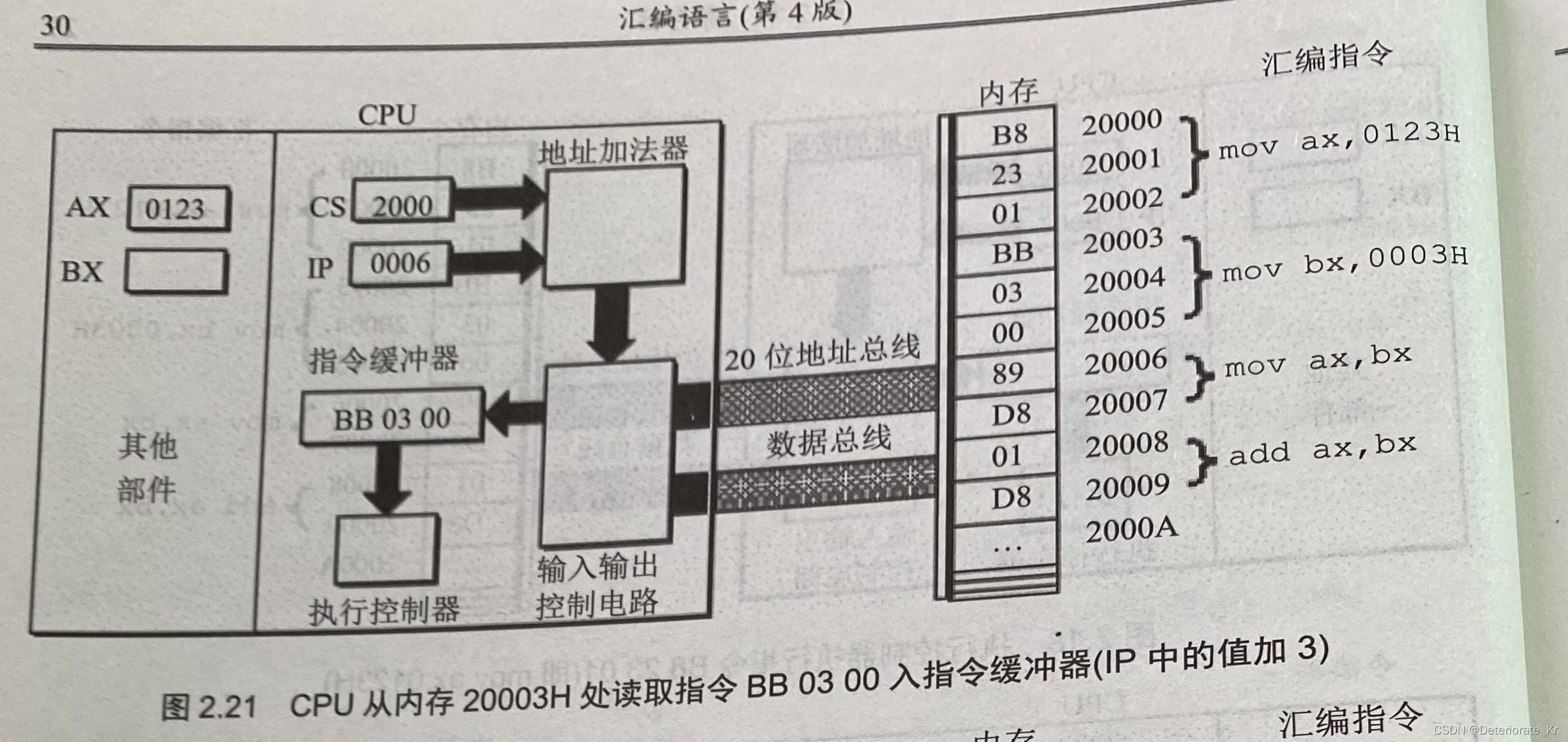
Wang Shuang's detailed learning notes of assembly language II: registers
随机推荐
Matplotlib绘图快速入门
Vysor uses WiFi wireless connection for screen projection_ Operate the mobile phone on the computer_ Wireless debugging -- uniapp native development 008
Fire! One day transferred to go engineer, not fire handstand sing Conquest (in serial)
What is an index in MySQL? What kinds of indexes are commonly used? Under what circumstances will the index fail?
数字电路基础(一)数制与码制
【指针】删除字符串s中的所有空格
MySQL中什么是索引?常用的索引有哪些种类?索引在什么情况下会失效?
Function: calculates the number of uppercase letters in a string
[oiclass] maximum formula
Wu Enda's latest interview! Data centric reasons
Bing Dwen Dwen official NFT blind box will be sold for about 626 yuan each; JD home programmer was sentenced for deleting the library and running away; Laravel 9 officially released | Sifu weekly
数字电路基础(三)编码器和译码器
Statistics 8th Edition Jia Junping Chapter 12 summary of knowledge points of multiple linear regression and answers to exercises after class
指针:最大值、最小值和平均值
浙大版《C语言程序设计实验与习题指导(第3版)》题目集
JDBC read this article is enough
【指针】求字符串的长度
What level do 18K test engineers want? Take a look at the interview experience of a 26 year old test engineer
Using flask_ Whooshalchemyplus Jieba realizes global search of flask
c语言学习总结(上)(更新中)