当前位置:网站首页>Flink Yarn Per Job - 提交流程一
Flink Yarn Per Job - 提交流程一
2022-08-01 23:43:00 【hyunbar】

AbstractJobClusterExecutor.java
@Override
public CompletableFuture<JobClient> execute(@Nonnull final Pipeline pipeline, @Nonnull final Configuration configuration, @Nonnull final ClassLoader userCodeClassloader) throws Exception {
/*TODO 将 流图(StreamGraph) 转换成 作业图(JobGraph)*/
final JobGraph jobGraph = PipelineExecutorUtils.getJobGraph(pipeline, configuration);
/*TODO 集群描述器:创建、启动了 YarnClient, 包含了一些yarn、flink的配置和环境信息*/
try (final ClusterDescriptor<ClusterID> clusterDescriptor = clusterClientFactory.createClusterDescriptor(configuration)) {
final ExecutionConfigAccessor configAccessor = ExecutionConfigAccessor.fromConfiguration(configuration);
/*TODO 集群特有资源配置:JobManager内存、TaskManager内存、每个Tm的slot数*/
final ClusterSpecification clusterSpecification = clusterClientFactory.getClusterSpecification(configuration);
final ClusterClientProvider<ClusterID> clusterClientProvider = clusterDescriptor
.deployJobCluster(clusterSpecification, jobGraph, configAccessor.getDetachedMode());
LOG.info("Job has been submitted with JobID " + jobGraph.getJobID());
return CompletableFuture.completedFuture(
new ClusterClientJobClientAdapter<>(clusterClientProvider, jobGraph.getJobID(), userCodeClassloader));
}
将StreamGraph转换为JobGraph
**(1)找到createJobGraph方法
**
1)PipelineExecutorUtils
public static JobGraph getJobGraph(@Nonnull final Pipeline pipeline, @Nonnull final Configuration configuration) throws MalformedURLException {
checkNotNull(pipeline);
checkNotNull(configuration);
final ExecutionConfigAccessor executionConfigAccessor = ExecutionConfigAccessor.fromConfiguration(configuration);
// 往下看
final JobGraph jobGraph = FlinkPipelineTranslationUtil
.getJobGraph(pipeline, configuration, executionConfigAccessor.getParallelism());
configuration
.getOptional(PipelineOptionsInternal.PIPELINE_FIXED_JOB_ID)
.ifPresent(strJobID -> jobGraph.setJobID(JobID.fromHexString(strJobID)));
jobGraph.addJars(executionConfigAccessor.getJars());
jobGraph.setClasspaths(executionConfigAccessor.getClasspaths());
jobGraph.setSavepointRestoreSettings(executionConfigAccessor.getSavepointRestoreSettings());
return jobGraph;
}
2)FlinkPipelineTranslationUtil
public static JobGraph getJobGraph(
Pipeline pipeline,
Configuration optimizerConfiguration,
int defaultParallelism) {
FlinkPipelineTranslator pipelineTranslator = getPipelineTranslator(pipeline);
// 往下看
return pipelineTranslator.translateToJobGraph(pipeline,
optimizerConfiguration,
defaultParallelism);
}
3)StreamGraphTranslator implements FlinkPipelineTranslator
@Override
public JobGraph translateToJobGraph(
Pipeline pipeline,
Configuration optimizerConfiguration,
int defaultParallelism) {
…
StreamGraph streamGraph = (StreamGraph) pipeline;
// 重点
return streamGraph.getJobGraph(null);
}
4)StreamGraph
public JobGraph getJobGraph(@Nullable JobID jobID) {
return StreamingJobGraphGenerator.createJobGraph(this, jobID);
}
5)StreamingJobGraphGenerator
public static JobGraph createJobGraph(StreamGraph streamGraph, @Nullable JobID jobID) {
return new StreamingJobGraphGenerator(streamGraph, jobID).createJobGraph();
}
private JobGraph createJobGraph() {
preValidate();
// make sure that all vertices start immediately
/*TODO streaming 模式下,调度模式是所有节点(vertices)一起启动:Eager */
jobGraph.setScheduleMode(streamGraph.getScheduleMode());
jobGraph.enableApproximateLocalRecovery(streamGraph.getCheckpointConfig().isApproximateLocalRecoveryEnabled());
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn’t change.
// 广度优先遍历 StreamGraph 并且为每个SteamNode生成hash id,
// 保证如果提交的拓扑没有改变,则每次生成的hash都是一样的
Map<Integer, byte[]> hashes = defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
/* TODO 最重要的函数,生成 JobVertex,JobEdge等,并尽可能地将多个节点chain在一起*/
setChaining(hashes, legacyHashes);
/TODO 将每个JobVertex的入边集合也序列化到该JobVertex的StreamConfig中 (出边集合已经在setChaining的时候写入了)/
setPhysicalEdges();
/TODO 根据group name,为每个 JobVertex 指定所属的 SlotSharingGroup 以及针对 Iteration的头尾设置 CoLocationGroup/
setSlotSharingAndCoLocation();
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getManagedMemoryOperatorScopeUseCaseWeights(),
id -> streamGraph.getStreamNode(id).getManagedMemorySlotScopeUseCases());
configureCheckpointing();
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
JobGraphUtils.addUserArtifactEntries(streamGraph.getUserArtifacts(), jobGraph);
// set the ExecutionConfig last when it has been finalized
try {
/TODO 将 StreamGraph 的 ExecutionConfig 序列化到 JobGraph 的配置中/
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
}
catch (IOException e) {
throw new IllegalConfigurationException(“Could not serialize the ExecutionConfig.” +
“This indicates that non-serializable types (like custom serializers) were registered”);
}
return jobGraph;
}
**(1)生成 JobVertex,JobEdge,并尽可能地将多个节点chain在一起**
1)StreamingJobGraphGenerator
operators start at position 1 because 0 is for chained source inputs
chain的开始位置是1,因为0是source input
/**
- Sets up task chains from the source {@link StreamNode} instances.
This will recursively create all {@link JobVertex} instances.
*/
private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes) {
// we separate out the sources that run as inputs to another operator (chained inputs)
// from the sources that needs to run as the main (head) operator.
final Map<Integer, OperatorChainInfo> chainEntryPoints = buildChainedInputsAndGetHeadInputs(hashes, legacyHashes);
final Collection initialEntryPoints = new ArrayList<>(chainEntryPoints.values());
// iterate over a copy of the values, because this map gets concurrently modified
// 从source开始建⽴ node chains
for (OperatorChainInfo info : initialEntryPoints) {
// 构建node chains,返回当前节点的物理出边;startNodeId != currentNodeId 时,说明currentNode是chain中的子节点
createChain(
info.getStartNodeId(),
1, // operators start at position 1 because 0 is for chained source inputs
info,
chainEntryPoints);
}
}
private List createChain(
final Integer currentNodeId,
final int chainIndex,
final OperatorChainInfo chainInfo,
final Map<Integer, OperatorChainInfo> chainEntryPoints) {
Integer startNodeId = chainInfo.getStartNodeId();
if (!builtVertices.contains(startNodeId)) {
/TODO 过渡用的出边集合, 用来生成最终的 JobEdge, 注意不包括 chain 内部的边/
List transitiveOutEdges = new ArrayList();
List<StreamEdge> chainableOutputs = new ArrayList<StreamEdge>();
List<StreamEdge> nonChainableOutputs = new ArrayList<StreamEdge>();
StreamNode currentNode = streamGraph.getStreamNode(currentNodeId);
/*TODO 将当前节点的出边分成 chainable 和 nonChainable 两类*/
for (StreamEdge outEdge : currentNode.getOutEdges()) {
if (isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}
for (StreamEdge chainable : chainableOutputs) {
transitiveOutEdges.addAll(
createChain(chainable.getTargetId(), chainIndex + 1, chainInfo, chainEntryPoints));
}
/*TODO 递归调用 createChain*/
for (StreamEdge nonChainable : nonChainableOutputs) {
transitiveOutEdges.add(nonChainable);
createChain(
nonChainable.getTargetId(),
1, // operators start at position 1 because 0 is for chained source inputs
chainEntryPoints.computeIfAbsent(
nonChainable.getTargetId(),
(k) -> chainInfo.newChain(nonChainable.getTargetId())),
chainEntryPoints);
}
/*TODO 生成当前节点的显示名,如:"Keyed Aggregation -> Sink: Unnamed"*/
chainedNames.put(currentNodeId, createChainedName(currentNodeId, chainableOutputs, Optional.ofNullable(chainEntryPoints.get(currentNodeId))));
chainedMinResources.put(currentNodeId, createChainedMinResources(currentNodeId, chainableOutputs));
chainedPreferredResources.put(currentNodeId, createChainedPreferredResources(currentNodeId, chainableOutputs));
OperatorID currentOperatorId = chainInfo.addNodeToChain(currentNodeId, chainedNames.get(currentNodeId));
if (currentNode.getInputFormat() != null) {
getOrCreateFormatContainer(startNodeId).addInputFormat(currentOperatorId, currentNode.getInputFormat());
}
if (currentNode.getOutputFormat() != null) {
getOrCreateFormatContainer(startNodeId).addOutputFormat(currentOperatorId, currentNode.getOutputFormat());
}
/*TODO 如果当前节点是起始节点, 则直接创建 JobVertex 并返回 StreamConfig, 否则先创建一个空的 StreamConfig */
StreamConfig config = currentNodeId.equals(startNodeId)
? createJobVertex(startNodeId, chainInfo)
: new StreamConfig(new Configuration());
/*TODO 设置 JobVertex 的 StreamConfig, 基本上是序列化 StreamNode 中的配置到 StreamConfig中.*/
setVertexConfig(currentNodeId, config, chainableOutputs, nonChainableOutputs, chainInfo.getChainedSources());
if (currentNodeId.equals(startNodeId)) {
/*TODO 如果是chain的起始节点,标记成chain start(不是chain中的节点,也会被标记成 chain start)*/
config.setChainStart();
config.setChainIndex(chainIndex);
config.setOperatorName(streamGraph.getStreamNode(currentNodeId).getOperatorName());
/*TODO 将当前节点(headOfChain)与所有出边相连*/
for (StreamEdge edge : transitiveOutEdges) {
/*TODO 通过StreamEdge构建出JobEdge,创建 IntermediateDataSet,用来将JobVertex和JobEdge相连*/
connect(startNodeId, edge);
}
/*TODO 把物理出边写入配置, 部署时会用到*/
config.setOutEdgesInOrder(transitiveOutEdges);
/*TODO 将chain中所有子节点的StreamConfig写入到 headOfChain 节点的 CHAINED_TASK_CONFIG 配置中*/
config.setTransitiveChainedTaskConfigs(chainedConfigs.get(startNodeId));
} else {
/*TODO 如果是 chain 中的子节点*/
chainedConfigs.computeIfAbsent(startNodeId, k -> new HashMap<Integer, StreamConfig>());
config.setChainIndex(chainIndex);
StreamNode node = streamGraph.getStreamNode(currentNodeId);
config.setOperatorName(node.getOperatorName());
/*TODO 将当前节点的StreamConfig添加到该chain的config集合中*/
chainedConfigs.get(startNodeId).put(currentNodeId, config);
}
config.setOperatorID(currentOperatorId);
if (chainableOutputs.isEmpty()) {
config.setChainEnd();
}
/*TODO 返回连往chain外部的出边集合*/
return transitiveOutEdges;
} else {
return new ArrayList<>();
}
}
创建启动YarnClient
1)StandaloneClientFactory implements ClusterClientFactory
创建、启动了 YarnClient, 包含了一些yarn、flink的配置和环境信息
public StandaloneClusterDescriptor createClusterDescriptor(Configuration configuration) {
checkNotNull(configuration);
return new StandaloneClusterDescriptor(configuration);
}
2)YarnClusterClientFactory
private YarnClusterDescriptor getClusterDescriptor(Configuration configuration) {
/TODO 创建了YarnClient/
final YarnClient yarnClient = YarnClient.createYarnClient();
final YarnConfiguration yarnConfiguration = new YarnConfiguration();
/TODO 初始化、启动 YarnClient/
yarnClient.init(yarnConfiguration);
yarnClient.start();
return new YarnClusterDescriptor(
configuration,
yarnConfiguration,
yarnClient,
YarnClientYarnClusterInformationRetriever.create(yarnClient),
false);
}
集群资源配置
**(1) 配置内存**
JobManager内存 = jobmanager.memory.process.size
TaskManager内存 = taskmanager.memory.process.size
每个Tm的slot数 = taskmanager.numberOfTaskSlots
public ClusterSpecification getClusterSpecification(Configuration configuration) {
checkNotNull(configuration);
// jm 的内存 jobmanager.memory.process.size
final int jobManagerMemoryMB = JobManagerProcessUtils.processSpecFromConfigWithNewOptionToInterpretLegacyHeap(
configuration,
JobManagerOptions.TOTAL_PROCESS_MEMORY)
.getTotalProcessMemorySize()
.getMebiBytes();
// tm 的内存 taskmanager.memory.process.size
final int taskManagerMemoryMB = TaskExecutorProcessUtils
.processSpecFromConfig(TaskExecutorProcessUtils.getConfigurationMapLegacyTaskManagerHeapSizeToConfigOption(
configuration, TaskManagerOptions.TOTAL_PROCESS_MEMORY))
.getTotalProcessMemorySize()
.getMebiBytes();
// slot的个数 taskmanager.numberOfTaskSlots
int slotsPerTaskManager = configuration.getInteger(TaskManagerOptions.NUM_TASK_SLOTS);
return new ClusterSpecification.ClusterSpecificationBuilder()
.setMasterMemoryMB(jobManagerMemoryMB)
.setTaskManagerMemoryMB(taskManagerMemoryMB)
.setSlotsPerTaskManager(slotsPerTaskManager)
.createClusterSpecification();
}
集群部署
YarnClusterDescriptor
public ClusterClientProvider deployJobCluster(
ClusterSpecification clusterSpecification,
JobGraph jobGraph,
boolean detached) throws ClusterDeploymentException {
try {
// 1)
return deployInternal(
clusterSpecification,
“Flink per-job cluster”,
// 2)
getYarnJobClusterEntrypoint(),
jobGraph,
detached);
} catch (Exception e) {
throw new ClusterDeploymentException(“Could not deploy Yarn job cluster.”, e);
}
}
**(1) deployInternal方法**
/**
- This method will block until the ApplicationMaster/JobManager have been deployed on YARN.
- @param clusterSpecification Initial cluster specification for the Flink cluster to be deployed
- @param applicationName name of the Yarn application to start
- @param yarnClusterEntrypoint Class name of the Yarn cluster entry point.
- @param jobGraph A job graph which is deployed with the Flink cluster, {@code null} if none
- @param detached True if the cluster should be started in detached mode
*/
private ClusterClientProvider deployInternal(
ClusterSpecification clusterSpecification,
String applicationName,
String yarnClusterEntrypoint,
@Nullable JobGraph jobGraph,
boolean detached) throws Exception {
final UserGroupInformation currentUser = UserGroupInformation.getCurrentUser();
if (HadoopUtils.isKerberosSecurityEnabled(currentUser)) {
boolean useTicketCache = flinkConfiguration.getBoolean(SecurityOptions.KERBEROS_LOGIN_USETICKETCACHE);
if (!HadoopUtils.areKerberosCredentialsValid(currentUser, useTicketCache)) {
throw new RuntimeException("Hadoop security with Kerberos is enabled but the login user " +
"does not have Kerberos credentials or delegation tokens!");
}
}
/TODO 部署前检查:jar包路径、conf路径、yarn最大核数…/
isReadyForDeployment(clusterSpecification);
// ------------------ Check if the specified queue exists --------------------
/TODO 检查指定的yarn队列是否存在/
checkYarnQueues(yarnClient);
// ------------------ Check if the YARN ClusterClient has the requested resources --------------
/TODO 检查yarn是否有足够的资源/
// Create application via yarnClient
final YarnClientApplication yarnApplication = yarnClient.createApplication();
final GetNewApplicationResponse appResponse = yarnApplication.getNewApplicationResponse();
Resource maxRes = appResponse.getMaximumResourceCapability();
final ClusterResourceDescription freeClusterMem;
try {
freeClusterMem = getCurrentFreeClusterResources(yarnClient);
} catch (YarnException | IOException e) {
failSessionDuringDeployment(yarnClient, yarnApplication);
throw new YarnDeploymentException(“Could not retrieve information about free cluster resources.”, e);
}
final int yarnMinAllocationMB = yarnConfiguration.getInt(
YarnConfiguration.RM_SCHEDULER_MINIMUM_ALLOCATION_MB,
YarnConfiguration.DEFAULT_RM_SCHEDULER_MINIMUM_ALLOCATION_MB);
if (yarnMinAllocationMB <= 0) {
throw new YarnDeploymentException(“The minimum allocation memory "
+ “(” + yarnMinAllocationMB + " MB) configured via '” + YarnConfiguration.RM_SCHEDULER_MINIMUM_ALLOCATION_MB
+ “’ should be greater than 0.”);
}
final ClusterSpecification validClusterSpecification;
try {
validClusterSpecification = validateClusterResources(
clusterSpecification,
yarnMinAllocationMB,
maxRes,
freeClusterMem);
} catch (YarnDeploymentException yde) {
failSessionDuringDeployment(yarnClient, yarnApplication);
throw yde;
}
LOG.info(“Cluster specification: {}”, validClusterSpecification);
final ClusterEntrypoint.ExecutionMode executionMode = detached ?
ClusterEntrypoint.ExecutionMode.DETACHED
: ClusterEntrypoint.ExecutionMode.NORMAL;
flinkConfiguration.setString(ClusterEntrypoint.EXECUTION_MODE, executionMode.toString());
/TODO 开始启动AM/
ApplicationReport report = startAppMaster(
flinkConfiguration,
applicationName,
yarnClusterEntrypoint,
jobGraph,
yarnClient,
yarnApplication,
validClusterSpecification);
// print the application id for user to cancel themselves.
if (detached) {
final ApplicationId yarnApplicationId = report.getApplicationId();
logDetachedClusterInformation(yarnApplicationId, LOG);
}
setClusterEntrypointInfoToConfig(report);
return () -> {
try {
return new RestClusterClient<>(flinkConfiguration, report.getApplicationId());
} catch (Exception e) {
throw new RuntimeException(“Error while creating RestClusterClient.”, e);
}
};
}
1)部署前检查:jar包路径、conf路径、yarn最大核数
private void isReadyForDeployment(ClusterSpecification clusterSpecification) throws Exception {
if (this.flinkJarPath == null) {
throw new YarnDeploymentException(“The Flink jar path is null”);
}
if (this.flinkConfiguration == null) {
throw new YarnDeploymentException(“Flink configuration object has not been set”);
}
// Check if we don’t exceed YARN’s maximum virtual cores.
final int numYarnMaxVcores = yarnClusterInformationRetriever.getMaxVcores();
int configuredAmVcores = flinkConfiguration.getInteger(YarnConfigOptions.APP_MASTER_VCORES);
if (configuredAmVcores > numYarnMaxVcores) {
throw new IllegalConfigurationException(
String.format(“The number of requested virtual cores for application master %d” +
" exceeds the maximum number of virtual cores %d available in the Yarn Cluster.",
configuredAmVcores, numYarnMaxVcores));
}
int configuredVcores = flinkConfiguration.getInteger(YarnConfigOptions.VCORES, clusterSpecification.getSlotsPerTaskManager());
// don’t configure more than the maximum configured number of vcores
if (configuredVcores > numYarnMaxVcores) {
throw new IllegalConfigurationException(
String.format(“The number of requested virtual cores per node %d” +
" exceeds the maximum number of virtual cores %d available in the Yarn Cluster." +
" Please note that the number of virtual cores is set to the number of task slots by default" +
" unless configured in the Flink config with ‘%s.’",
configuredVcores, numYarnMaxVcores, YarnConfigOptions.VCORES.key()));
}
// check if required Hadoop environment variables are set. If not, warn user
if (System.getenv(“HADOOP_CONF_DIR”) == null &&
System.getenv(“YARN_CONF_DIR”) == null) {
LOG.warn("Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set. " +
"The Flink YARN Client needs one of these to be set to properly load the Hadoop " +
“configuration for accessing YARN.”);
}
}
2)检查yarn资源是否够
private ClusterResourceDescription getCurrentFreeClusterResources(YarnClient yarnClient) throws YarnException, IOException {
List nodes = yarnClient.getNodeReports(NodeState.RUNNING);
int totalFreeMemory = 0;
int containerLimit = 0;
int[] nodeManagersFree = new int[nodes.size()];
for (int i = 0; i < nodes.size(); i++) {
NodeReport rep = nodes.get(i);
int free = rep.getCapability().getMemory() - (rep.getUsed() != null ? rep.getUsed().getMemory() : 0);
nodeManagersFree[i] = free;
totalFreeMemory += free;
if (free > containerLimit) {
containerLimit = free;
}
}
return new ClusterResourceDescription(totalFreeMemory, containerLimit, nodeManagersFree);
}
**找到最小资源配置**
RM\_SCHEDULER\_MINIMUM\_ALLOCATION\_MB=yarn.scheduler.minimum-allocation-mb
DEFAULT_RM_SCHEDULER_MINIMUM_ALLOCATION_MB=1024

边栏推荐
- Several interview questions about golang concurrency
- The third chapter of the imitation cattle network project: develop the core functions of the community (detailed steps and ideas)
- 斜堆、、、
- 企业防护墙管理,有什么防火墙管理工具?
- 工作5年,测试用例都设计不好?来看看大厂的用例设计总结
- 6133. Maximum number of packets
- 6133. 分组的最大数量
- FAST-LIO2 code analysis (2)
- Flink学习第五天——Flink可视化控制台依赖配置和界面介绍
- 架构基本概念和架构本质
猜你喜欢
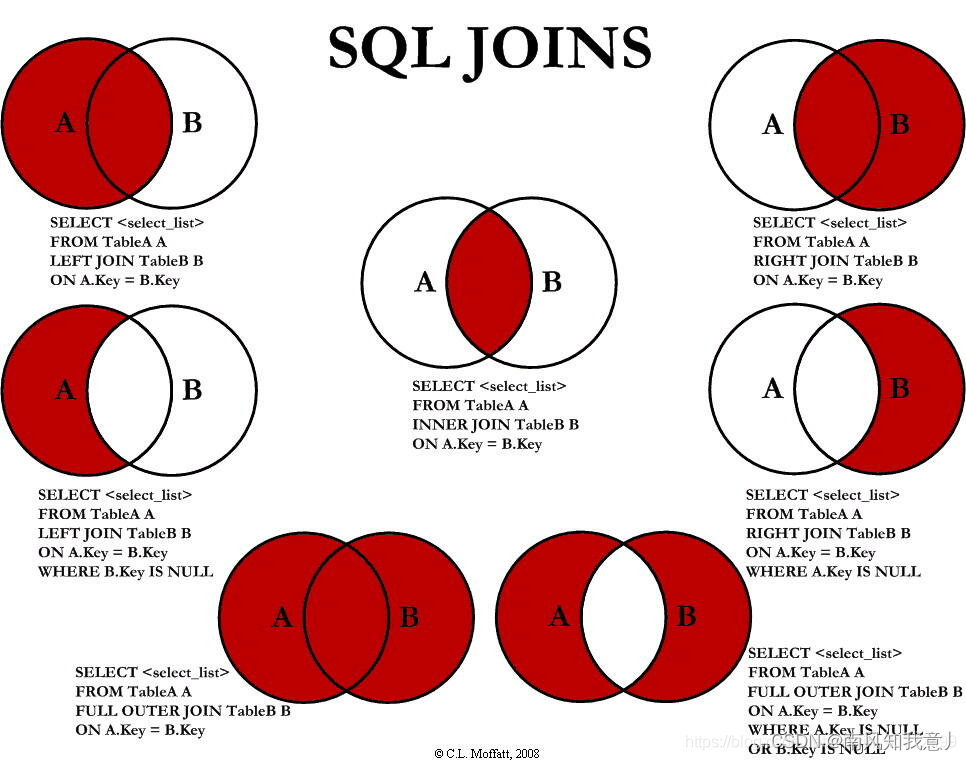
Various Joins of Sql

1个月写900多条用例,二线城市年薪33W+的测试经理能有多卷?
仿牛客网项目第三章:开发社区核心功能(详细步骤和思路)

cdh6 opens oozieWeb page, Oozie web console is disabled.
在CDH的hue上的oozie出现,提交 Coordinator My Schedule 时出错

How do programmers solve online problems gracefully?
![[LeetCode304 Weekly Competition] Two questions about the base ring tree 6134. Find the closest node to the given two nodes, 6135. The longest cycle in the graph](/img/63/16de443caf28644d79dc6e6889e5dd.png)
[LeetCode304 Weekly Competition] Two questions about the base ring tree 6134. Find the closest node to the given two nodes, 6135. The longest cycle in the graph
The monthly salary of the test post is 5-9k, how to increase the salary to 25k?

使用Jenkins做持续集成,这个知识点必须要掌握
伸展树的特性及实现
随机推荐
Making a Simple 3D Renderer
How to better understand and do a good job?
LocalDateTime转为Date类型
获取小猪民宿(短租)数据
Use Jenkins for continuous integration, this knowledge point must be mastered
Appears in oozie on CDH's hue, error submitting Coordinator My Schedule
Avoid , ,
, and tags基于JAX的激活函数、softmax函数和交叉熵函数
[LeetCode304周赛] 两道关于基环树的题 6134. 找到离给定两个节点最近的节点,6135. 图中的最长环
IDEA入门看这一篇就够了
邻接表与邻接矩阵
cdh6打开oozieWeb页面,Oozie web console is disabled.
FAST-LIO2 code analysis (2)
chrome复制一张图片的base64数据
Additional Features for Scripting
几道关于golang并发的面试题
C language - branch statement and loop statement
cmd指令
Share an interface test project (very worth practicing)
类型“FC<Props>”的参数不能赋给类型“ForwardRefRenderFunction<unknown, Props>”的参数。 属性“defaultProps”的类型不兼容。 不