当前位置:网站首页>CUDA C programming authoritative guide Grossman Chapter 4 global memory
CUDA C programming authoritative guide Grossman Chapter 4 global memory
2022-07-06 12:15:00 【Qi ang】
4.1 CUDA Memory Model Overview
Memory access and management is an important part of all programming languages .
Because most workloads are limited by the speed at which data is loaded and stored , So there are a lot of low latency 、 High bandwidth memory is very beneficial to performance .
The large capacity 、 Low latency memory is expensive and difficult to produce . Therefore, under the existing hardware storage subsystem , We must rely on the memory model to obtain the best delay and bandwidth .
CUDA The memory model combines the memory system of the host and the device , Shows the complete memory hierarchy , Enables you to explicitly control the data layout to optimize performance .
4.1.1 Advantages of memory hierarchy
Applications tend to follow the principle of locality , This means that they can access a relatively small local address space at any point in time . There are two different types of locality :
Temporal locality ;
Spatial locality ;
Temporal locality means that if a data location is referenced , Then the data is likely to be referenced again in a short time period , Over time , The possibility of this data being quoted gradually decreases .
Spatial locality holds that if a memory location is referenced , Then nearby locations may also be referenced .
Modern computers use continuously improved memory hierarchies with low latency and low capacity to optimize performance . This memory structure is only valid if locality is supported . A memory hierarchy consists of different delays 、 Multi level memory composition of bandwidth and capacity .
| register |
| cache |
| Memory |
| disk |
Go up and down , The characteristics are as follows ;
Lower average cost per bit ;
Higher capacity ;
Higher latency ;
Less processor access frequency ;
When data is frequently used by the processor , The data is saved at low latency 、 In low capacity memory .
When data is stored for later use , This data is saved in high latency 、 High capacity memory .
4.1.2 CUDA Memory model
For programmers , There are generally two types of memory :
programmable : You need to explicitly control which data is stored in programmable memory ;
Non programmable : You can't decide where to store the data , The program will automatically generate storage locations for good performance .
stay CPU Memory hierarchy , Both L1 cache and L2 cache are not programmable . On the other hand ,CUDA The memory model proposes many types of programmable memory :
register ;
Shared memory ;
Local memory ;
Constant memory ;
Texture memory ;
Global memory ;
The threads of a kernel function have their own private local memory .
A thread block has its own shared memory , Visible to all threads in the same thread block , Its content lasts for the entire life cycle of the thread block .
All threads can access global memory .
Read only memory space accessible to all threads : Constant memory and texture memory .
Texture memory provides different addressing modes and filtering modes for various data layouts .
For an application , Global memory 、 The contents of constant memory and texture memory have the same life cycle .
4.1.2.1 register
The register is GPU The fastest running memory space on . An argument declared by a kernel function without other modifiers , Usually stored in registers .
Registers are private to each thread , A kernel function usually uses registers to hold thread private variables that need to be accessed frequently .
The life cycle of the register variable is the same as that of the kernel function . Once the kernel function is executed , You can't access register variables .
A register is a register in SM Less resources delimited by the active thread bundle in . stay Fermi, Limit the maximum usage per thread 63 A register . stay Kepler in , Expand the limit to the maximum 255 A register .
Using fewer registers in the kernel function will make SM There are more resident thread blocks on the . Every SM The more concurrent thread blocks on the , The higher the utilization and performance .
The following command will output the number of registers 、 The number of bytes of shared memory and the number of bytes of constant memory used by each thread :
-Xptxas -v, -abi=no
If a kernel function uses more registers than the hardware limit , Then local memory will be used to replace the occupied registers . This register overflow can adversely affect performance .
nvcc The compiler uses heuristic strategies to minimize the use of registers , To avoid register overflow . You can also explicitly add additional information to each kernel function in the code to help optimize the register ;
__global__ void __launch_bounds__(maxThreadsPerBlock, minBlocksPerMultiprocessor)
kernel__name(...)
{
...
}maxThreadsPerBlock It indicates the maximum number of threads that each thread block can contain , This thread block is started by the kernel function .
minBlockPerMultiprocessor Points out in each SM The minimum number of resident thread blocks expected in .
You can also use maxrregcount Compilation options , To control the maximum number of registers used by all kernel functions in a compilation unit .
--maxrregcount=32;
4.1.2.2 Local memory
Variables in the kernel that are stored in registers but cannot enter the register space allocated by the kernel will overflow to local memory . The variables that the compiler may store in local memory are ;
Local array referenced with unknown index at compile time ;
Large local structures or arrays that may take up a lot of register space ;
Any variable that does not satisfy the kernel register qualification ;
The term local memory is ambiguous : Variables overflowing into local memory are essentially stored in the same storage area as the global memory space , Therefore, local memory access is characterized by high latency and low bandwidth .
For computing power 2.0 And above GPU, Local memory data is also stored in each SM And the L2 cache of each device .
4.1.2.3 Shared memory
Use in kernel functions __shared__ Modifier variables are stored in shared memory . Its life cycle is accompanied by the whole thread block . When the execution of a thread block ends , Its allocated shared memory will free and reallocate other thread blocks .
every last SM There is a certain amount of shared memory allocated by thread blocks . therefore , Care must be taken not to overuse shared memory , Otherwise, you will inadvertently limit the number of active thread bundles .
Shared memory is the basic way for threads to communicate with each other . Threads in a block cooperate with each other by using data in shared memory .
Access to shared memory must be synchronized using the following call :
__syncthreads();
This function sets up an execution roadblock , That is, all threads in the same thread block must arrive there before other threads are allowed to execute . Set obstacles for all threads in the thread block , This can avoid potential data conflicts .
__syncthreads() Also through frequent coercion SM To idle state to affect performance .
SM The L1 cache and shared memory in both use 64KB On chip memory , It is divided statically , However, the following instructions can be used for dynamic configuration at runtime :
cudaFuncSetCahceConfig() On chip memory partition is configured on the basis of each kernel function .
cudaFuncCachePreferNone/L1/Shared/Equal.
4.1.2.4 Constant memory
Constant memory resides in device memory , And in each SM Cache in a dedicated constant cache . Constant variables use __constant__ To embellish .
Constant variables must be declared in global space and outside all kernel functions . Constant memory is 64KB. Constant memory is actually statically declared , And visible to all kernel functions in the same compilation unit .
Kernel functions can only read data from constant memory . therefore , Constant memory must be initialized on the host side with the following function :cudaMemcpyToSymbol. The declared variables are stored in the global memory or constant memory of the device . in the majority of cases , This function is synchronous .
When all threads in the thread bundle read data from the same memory address , Constant memory performs best . Coefficients in mathematical formulas are a good example of using constant memory .
If each thread in the thread bundle reads data from a different address space , And read only once , Then constant memory is not the best choice , Because every time you read data from a constant memory , Will be broadcast to all threads in the thread bundle .
4.1.2.5 Texture memory
Texture memory resides in device memory , And in each SM Cache in the read-only cache of .
Texture memory is a global memory accessed through a specified read-only cache .
Read only cache includes filtering support , It can perform floating-point insertion as part of the read process .
Texture memory is the optimization of two-dimensional space locality , Therefore, threads that use texture memory to access two-dimensional data in the thread bundle can achieve optimal performance .
For applications that do not need to access 2D data and use filtering hardware , Compared with global memory , Using texture memory is slower .
4.1.2.6 Global memory
Global memory is GPU The largest of , Memory with the highest latency and often used .
global Refers to its scope and lifecycle . Its declaration can be made in any SM Accessed on the device , And throughout the entire life cycle of the application .
A global memory variable can be declared statically or dynamically .
You can use __device__ Modifier statically declares a variable in the device code .
When accessing global memory from multiple threads, you must pay attention to . Because the execution of threads cannot be synchronized across thread blocks , There may be problems when multiple threads in different thread blocks modify the same location of global memory concurrently , This will lead to an undefined program behavior .
Global memory resides in device memory , It can be done by 32 byte 、64 byte 、128 Bytes of memory transaction access . These memory transactions must be naturally aligned . in other words , The first address must be 32 byte 、64 Byte or 128 Multiple of bytes .
Optimizing memory transactions is critical for optimal performance .
When a thread bundle performs memory loading / When the storage , The number of transmissions that need to be met usually depends on two factors ;
Memory address distribution across threads ;
Alignment of memory addresses per transaction ;
In general , The more transactions used to satisfy memory requests , The more likely unused bytes are to be transferred back , This results in a reduction in data throughput . A bundle of memory requests for a given thread , The number of transactions and data throughput are determined by the computing power of the device .
4.1.2.7 GPU cache
GPU Cache is non programmable memory , There are four :
First level cache ;
Second level cache ;
Constant cache ;
Texture caching ;
Every SM There is a L1 cache , be-all SM Share a second level cache . Both L1 and L2 caches are used to store data in local memory and global memory , It also includes the part of register overflow .
stay CPU On , The loading and storage of memory can be cached . however , stay GPU Only memory loading operations can be cached on , Memory storage operations cannot be cached .
Every SM There is also a read-only constant cache and a texture cache , They are used in device memory to improve the reading performance from their own memory space .
4.1.2.8 CUDA Variable declaration summary
| Modifier | Variable name | Memory | Scope | Life cycle |
| float var | register | Threads | Threads | |
| float var[100] | Local | Threads | Threads | |
| __shared__ | float var/[100] | share | Thread block | block |
| __device__ | float var/[100] | overall situation | overall situation | Applications |
| _-constant__ | float var/[100] | Constant | overall situation | Applications |
Main features of various types of memory :
| Memory | On film / Off slice | cache | access | Range | Life cycle |
| register | On film | No | R/W | One thread | Threads |
| Local | Off slice | No | R/W | One thread | Threads |
| share | On film | No | R/W | All threads in the block | block |
| overall situation | Off slice | No | R/W | All threads + host | Host configuration |
| Constant | Off slice | Yes | R | All threads + host | Host configuration |
| texture | Off slice | Yes | R | All threads + host | Host configuration |
4.1.2.9 Static global memory
__device__ float devData;
int main()
{
float value = 3.4;
cudaMemcpyToSymbol(devData, &value, sizeof(float));
// ... Handle devDatakernel
cudaMemcpyFromSymbol(&value, devData, sizeof(float));
return 0;
}Although the host and device codes are stored in the same file in China , Their implementation is completely different . Even if it is visible in the same file , Host code cannot directly access device variables . Similarly , Nor can device code directly access host variables .
You may think that the host code can use the following code to access the global variables of the device ;cudaMemcpyToSymbol(). Yes , But pay attention to :
cudaMemcpyToSymbol Functions exist CUDA Runtime API in , It can be used secretly GPU Hardware to perform access ;
ad locum ,devData As an identifier , Not the variable address of the device's global memory ;
In kernel function ,devData It is treated as a variable in global memory .
cudaMemcpy A function cannot pass data to... Using the following variable address devData:
cudaMemcpy(&dataDev, &value, sizeof(float), cudaMemcpyHostToDevice).
You cannot use... In the device variables on the host side & Operator , Because he is just a person who is GPU The symbol representing the physical location on the . however , You can use it explicitly cudaGetSymbolAddress() Call to get the address of a global variable .
float* dptr = nullptr;
cudaGetSymbolAddress((void**)&dptr, devData);
cudaMemcpy(dptr, &value, sizeof(float), cudaMemcpyHostToDevice);There is one exception , Reference directly from the host GPU Memory :CUDA Fixed memory . Both host code and device code can directly access fixed memory through short pointer references .
Variables in the file scope : Visibility and accessibility
In general , Device kernel cannot access host variables , And host functions cannot access device variables , Even if these variables are declared in the scope under the same file .
CUDA Runtime API Access to host and device variables , But it depends on whether you provide the correct parameters to the correct function .
4.2 memory management
Now? , The focus is on how to use CUDA Function to explicitly manage memory and data movement .
Allocate and free device memory ;
Transfer data between host and device ;
4.2.1 Memory allocation and release
The following functions can be used on the host side to allocate global memory :
cudaMalloc() Assigned on the device count Bytes of global memory . The allocated memory supports any variable type . If cudaMalloc Function execution failed , Put it back cudaErrorMemoryAllocation.
The value in the global memory allocated with will not be cleared . You need to fill the allocated global memory with the data transferred from the host , Or initialize with the following functions .cudaMemset().
Once an application no longer uses the allocated global memory , Then you can use it cudaFree Function to free the memory space .
The operation cost of allocating and releasing device memory is high , So applications should reuse device memory .
4.2.2 Memory transfer
cudaMemcpy() Function transfers data from the host to the device . If the pointer is inconsistent with the specified direction , that cudaMemcpy The behavior of is undefined .
size_t nbytes = 1 << 22 * sizeof(float);
float* h_a = (float*)malloc(sizeof(nbytes))
float* d_a;
cudaMalloc((void**)&d_a, nbytes);
cudaMemcpy(d_a, h_a, nbytes, cudaMemcpyHostToDevice);
free(h_a);
cudaFree(d_a);CUDA A basic principle of programming should be to minimize the transmission between the host and the device .
4.2.3 Fixed memory
The allocated host memory is pageable by default , It means the operation caused by page error , This operation moves the data on the host virtual memory to different physical locations according to the requirements of the operating system .
GPU Data cannot be safely accessed on pageable host memory , Because when the host operating system moves the data in a physical location , It can't control .
When transferring data from pageable host memory to device memory ,CUDA The driver first allocates temporary page locked or fixed host memory , Copy host source data to fixed memory , Then transfer data from fixed memory to device memory .
CUDA The runtime allows you to use cudaMallocHost() Function to allocate fixed host memory directly . This memory is page locked and accessible to the device . Because the fixed memory can be accessed directly by the device , So it can read and write with much higher bandwidth than pageable memory .
However , Allocating too much fixed memory may degrade the performance of the host system , Because it reduces the amount of pageable memory used to store virtual memory data , Pageable memory is available to the host system .
Fixed host memory must pass cudaFreeHost() Function to release .
Memory transfer between host and device :
Compared with pageable memory , The cost of allocating and freeing fixed memory is higher , However, it provides higher transmission throughput for large-scale data transmission ;
Relative to pageable memory , The acceleration achieved with fixed memory depends on the computing power of the device ;
Batching many small transfers into one larger transfer can provide performance , Because the unit transmission consumption is introduced ;
Data transmission between host and device can sometimes overlap with kernel execution .
4.2.4 Zero copy memory
Generally speaking , The host cannot directly access device variables , At the same time, the device cannot directly access host variables . When there is another , Zero copy memory . Hosts and devices can access zero copy memory .
GPU Threads can directly access zero copy memory . stay CUDA Using zero copy memory in kernel functions has the following advantages :
When the device is out of memory, the host memory can be used ;
Avoid explicit data transmission between host and device ;
Improve PCIe Transmission rate ;
When zero copy memory is used to share data between host and device , You must synchronize memory access between the host and the device , Changing the data in the zero copy memory of the host and device at the same time will lead to unpredictable consequences .
Zero copy memory is fixed memory ( Non pageable ), This memory is mapped to the device address space . You can go through cudaHostAlloc() Function to create a mapping to fixed memory . This memory is page locked and device accessible . Need to use cudaFreeHost() Function to release . Among them flags Parameters can further configure the special properties of allocated memory ;
cudaHostAllocDefault: bring cudaHostAlloc Function behavior and cudaMallocHost The functions are the same .
cudaHostAllocPortable: Can be returned by all CUDA Fixed memory used by context , It's not just the one that performs memory allocation .
cudaHostAllocWriteCombined Return write combined memory , This memory can be used on some system configurations PCIe Faster transmission on the bus , But it can't read effectively on most hosts . therefore , Write combined memory is a good choice for buffers , This memory is used by the device through mapped fixed memory or host to device transfer .
cudaHostAllocMapped Host write and device read can be realized and mapped to the host memory in the device address space .
have access to cudaHostGetDevicePointer() Get the device pointer mapped to fixed memory . This pointer can be referenced on the device to access the mapped fixed host memory .
When frequent read and write operations are performed , Using zero copy memory as a supplement to device memory will significantly reduce performance . Because every transfer mapped to memory must go through PCIe Bus . Compared with global memory , Delays also increased significantly .
In terms of the results , If you want to share a small amount of memory between the host and the device , Zero copy memory may be a good choice , Because it simplifies programming and has good performance .
For the PCIe Discrete bus connection GPU For larger datasets on , Zero copy memory is not a good choice , It will lead to significant performance degradation .
Zero copy memory :
There are two common heterogeneous computing system architectures : Integrated architecture and discrete architecture .
In the integrated architecture ,CPU and GPU Integrated on the same chip , And share memory on the physical address . At this time, there is no need to PCIe Backup on bus , Therefore, the performance and programmability of zero copy may be better .
For by PCIe The bus connects the device to the discrete system of the host , Zero copy memory has advantages only in special cases . Because the mapped fixed memory is shared between the host and the device , You must synchronize memory access to avoid any potential data conflicts , This data conflict is usually caused by multiple threads accessing the same memory asynchronously .
Be careful not to use too much zero copy memory , Because of its high latency .
4.2.5 Unified virtual addressing
Ability to calculate 2.0 And above devices support unified virtual addressing UVA. stay CUDA4.0 Introduced in . With UVA, Host memory and device memory can share the same virtual address space .
With UVA, The memory space pointed by the pointer is transparent to the application .
adopt UVA, Yes cudaHostAlloc The allocated fixed host memory has the same host and device pointers . therefore , You can pass the returned pointer directly to the kernel function .
With UVA, There is no need to obtain the device pointer or manage two pointers with identical physical data .
cudaHostAlloc((void**)&h_A, nBytesm,cudaHostAllocMapped);
initialData(h_A, nElem);
sumArraysZero<<<grid, blocks>>>(h_A, nElem);Be careful , from cudaHostAlloc The pointer returned by the function is passed directly to the kernel function .
4.2.6 Unified memory addressing
stay CUDA6.0 in , Introduced “ Unified memory addressing ” This new feature , It is used to simplify CUDA Memory management in programming model . A managed memory pool is created in unified memory , The allocated space in the memory pool can use the same memory address ( The pointer ) stay CPU and GPU On the Internet . The underlying system automatically transfers data between the host and the device in the same memory space . This transfer of data is transparent to the application , This greatly simplifies the code .
Unified memory addressing depends on UVA Support for , But they are completely different technologies .UVA A single virtual memory address is provided for all processors in the system . however ,UVA Data is not automatically transferred from one physical location to another , This is a unique function of unified memory addressing .
Unified memory addressing provides a “ Single pointer to data ” Model , Conceptually, it is similar to zero copy memory . However, zero copy exists in the host memory for allocation , therefore , Because of being PCIe Impact of accessing zero copy memory on the bus , The performance of kernel function will have high delay .; On the other hand , Unified memory addressing separates memory and execution space , Therefore, the data can be transparently transmitted to the host or device as needed , To improve locality and performance .
Managed memory refers to the unified memory automatically allocated by the underlying system , It can interoperate with the allocated memory of specific devices .
Managed memory can be allocated statically or dynamically , By adding __managed__ notes , Statically declare a device variable as a managed variable . But this operation can only be carried out in the file scope and the global scope . This variable can be referenced directly from the host or device code .
__device__ __managed__ int y;You can also use cudaMallocManaged Function dynamically allocates managed memory .
Programs that use managed memory can take advantage of automatic data transfer and pointer de duplication .
stay CUDA6.0 in , Device code cannot call cudaMallocManaged function . All managed memory must be declared dynamically on the host side or statically on a global scale .
4.3 Memory access mode
Maximizing the use of global memory bandwidth is the basic way to regulate the performance of kernel functions .
CUDA One of the remarkable features of the execution model is that instructions must be issued and executed in the unit of thread bundle . The same goes for storage . When executing memory instructions , Each thread in the thread bundle provides a memory address that is being loaded or stored . In the process harness 32 In threads , Each thread makes a single memory access request containing the requested address , It also has one or more device memory transfer services .
4.3.1 Align and merge access
All application data is initially stored in DRAM On , That is, in the memory of the physical device , The memory request of the kernel function is usually in DRAM Device and on-chip memory space in 128 Byte or 32 Byte memory transaction .
All accesses to global memory will pass through L2 cache , There are also many accesses through L1 cache , It depends on the type of access and GPU framework . If both levels of cache are used , So memory access is by a 128 Byte memory transaction implementation . If only L2 cache is used , So memory access is by a 32 Byte memory transaction implementation . You can enable or disable L1 cache at compile time .
One line one level cache is 128 byte , It maps to a 128 Byte alignment segment .
When optimizing applications , You need to pay attention to two features of device memory access :
Align memory access ;
Merge memory access ;
When the first address of a device memory transaction applies to an even number of times the cache granularity of the transaction service (32 Byte L2 cache or 128 Byte first level cache ), Aligned memory access... Will appear . Running misaligned loads can waste bandwidth .
When all in a thread bundle 32 When a thread accesses a contiguous block of memory , There will be merged memory access .
The ideal state of aligned merged memory access is that the thread bundle accesses the same continuous memory block starting from the aligned memory address .
Generally speaking , Need to optimize memory transaction efficiency : Use the least number of transactions to meet the most memory requests .
4.3.2 Global memory read
stay SM in , Pass the data 3 Kind of cache / Buffer path for transmission , The specific method depends on the type of device memory used :
Level 1 and level 2 caching ;
Constant memory ;
A read-only cache ;
Class A / L2 cache is the default path . To pass data through the other two paths requires the application to explicitly state . But to improve performance depends on the access mode used .
Whether the global memory load operation will pass through the L1 cache depends on two factors :
The computing power of the device ;
Compiler Options ;
By default , stay Fermi The device can use L1 cache for global memory loading , stay K40 And above GPU disable . The following flag tells the compiler to disable L1 caching :
-Xptxas -dlcm=cg
If L1 caching is disabled , All requests to load the global memory will go directly into the L2 cache ; If the L2 cache is missing , By DRAM Complete the request . Each memory transaction can be handled by a 、 Two or four parts , Each part 32 Bytes . L1 caching can also be enabled directly using the following identifiers :
-Xptxas -dlcm=ca
stay Kepler GPU in , The L1 cache is not used to cache the global memory load , Instead, it is specifically used to cache data that overflows registers into local memory .
Memory load access mode :
Loading can be divided into two modes :
Cache load ( Enable first level caching );
No cache load ( Disable L1 cache );
The memory load access mode has the following characteristics :
With cache and without cache : If L1 cache is enabled , The memory load is cached ;
Alignment and non alignment : If the first address of memory access is 32 Multiple of bytes , Then align and load ;
Merger and non merger : If the thread bundle accesses the same continuous data block , Then load the merge ;
4.3.2.1 Cache load
Align and merge memory access :

Access is aligned , The referenced address is not a continuous thread ID. Only if each thread requests in 128 There are... In the byte range 4 When a different byte , There is no unused data in this transaction .

Non aligned access , Merge access ; When L1 cache is enabled , from SM The physical address loading operation must be performed in 128 Align the boundaries of bytes , So there are two requirements 128 Byte transaction to perform this memory loading operation . Bus utilization 50%.

All threads in the thread bundle request the same address . Because the referenced bytes fall within a cache line range , So just request a memory transaction , But the bus utilization is very low .4/128 = 3.125%
Thread requests in the thread bundle are scattered in the global memory 32 individual 4 Byte address . Although the total number of bytes requested by the thread bundle is only 128 Bytes , But the address takes up N Cache lines .

CPU L1 cache and GPU Differences between L1 caches :
CPU L1 cache optimizes temporal and spatial locality .GPU L1 cache is designed for spatial locality rather than temporal locality . Frequent access to the memory location of a L1 cache does not increase the probability of data remaining in the cache .
4.3.2.2 Load without cache
Loading without cache does not go through L1 cache , It is in the granularity of memory segments (32 Bytes ) Rather than the granularity of the cache pool (128 byte ) perform . This is a finer grained loading , It can bring better bus utilization for non aligned or non merged memory access .
4.3.2.3 Examples of misaligned reads
Because the access mode is often determined by an algorithm implemented by the application , So merging memory loads is a challenge for some applications .
Using some offsets will cause memory access to be misaligned . Resulting in longer running time . By observing the result of taking the global loading efficiency as the index , It can be verified that these non aligned accesses are the cause of performance loss :
Global load efficiency = Requested global memory load throughput / Required global memory load throughput
have access to nvprof obtain gld_efficiency indicators . For non aligned reads , The global loading efficiency is reduced by at least half , This means that the global memory load throughput is doubled .
You can also use the global load transaction indicator to directly verify gld_transactions.
For misaligned cases , Disabling L1 cache improves loading efficiency . Because the loading granularity changes from 128 Bytes drop to 32 byte .
4.3.2.4 A read-only cache
Read only cache was originally used for texture memory loading . For computing power 3.5 And above GPU Come on , Read only caching also supports the use of global memory loading instead of L1 caching .
The loading granularity of read-only cache is 32 Bytes . Usually , For decentralized reading , These finer grained loads are better than the first level cache .
There are two ways to guide the memory to read through the read-only cache :
Using functions __lgd;
Use modifiers on indirectly referenced pointers ;
out[idx] = __lgd(&in[idx]);You can also put constants __restrict__ Modifier applied to pointer . These modifiers help nvcc The compiler recognizes aliasless pointers ( That is, the pointer specially used to access a specific array ).
__global__ void copyKernel(int* restrict__ out)
{...}4.3.3 Global memory write
Memory storage operation is relatively simple . L1 cache cannot be used in Fermi and Kepler GPU Perform storage operations on , Before sending to the device memory, the storage operation only passes through the L2 cache . The storage operation is in 32 Execute on the granularity of byte segments . Memory transactions can be divided into segments at the same time , Two or four paragraphs .
Align and merge .
4.3.4 Structure array and array structure
utilize AoS, It stores spatially adjacent data , stay CPU There will be good cache locality on .
utilize SoA, It can not only store adjacent data points closely , It can also store independent data points across arrays .
utilize SoA Schema storage data makes full use of GPU bandwidth . Because there is no cross access of the same field elements ,GPU Upper SoA The layout provides consolidated memory access , And it can make more efficient use of global memory .
In many parallel programming paradigms , In especial SIMD Type paradigm , Prefer to use SoA. stay CUDA C Programming is also generally more inclined to use SoA, Because data elements are pre prepared for effective merge access to global memory , The data elements of the same field referenced by the same memory operation are also adjacent when stored .
about AoS Data layout , The load request and memory storage request are repeated . therefore , Request to load and store 50% Bandwidth is unused .
4.3.5 Performance tuning
Two goals of optimizing the utilization of device memory bandwidth :
Align and merge memory access , To reduce the waste of bandwidth ;
Enough concurrent memory operations , To hide memory latency ;
The third chapter discusses the kernel function of optimizing instruction throughput , Maximizing concurrent memory access is achieved by :
Increase the number of independent memory operations performed in each thread ;
Test the execution configuration of kernel function startup , To fully reflect each SM The parallelism of ;
4.3.5.1 Deployment technology
Make each thread perform multiple independent memory operations , Then you can call more concurrent memory accesses .
however , Deployment technology does not affect the number of memory operations performed ( It only affects the number of concurrent executions ).
4.3.5.2 Increase parallelism
In order to fully embody parallelism , You should test the grid and thread block size started by a kernel function . At this point, two hardware limitations need to be noted , Every SM How many concurrent thread blocks are there at most , And each SM How many concurrent thread bundles are there at most .
Maximize bandwidth utilization :
There are two main factors that affect the performance of device memory operation :
Make effective use of equipment DRAM and SM Byte movement between on-chip memories : In order to avoid the waste of device memory bandwidth , The memory access mode should be aligned and merged ;
Maximize the current memory operand :1) an , Each thread produces more independent memory access . 2) Modify the execution configuration of kernel function startup to make each SM There is more parallelism .
4.4 Bandwidth achievable by kernel function
When analyzing kernel function performance , Note the memory latency , That is, the time to complete an independent memory request .
Memory bandwidth , namely SM Speed of accessing device memory , It is measured in bytes per unit time .
In the last section , You have tried to use two methods to improve the performance of kernel functions :
Hide memory latency by maximizing the number of parallel execution thread bundles , Achieve better bus utilization by maintaining more executing memory accesses .
Maximize the efficiency of memory bandwidth by properly aligning and merging memory accesses .
4.4.1 Memory bandwidth
Most kernel functions are very sensitive to memory bandwidth , That is, they have memory bandwidth limitations . Therefore, special attention should be paid to the arrangement of data in global memory , And how the thread bundle accesses the data .
There are generally two types of bandwidth ;
Theoretical bandwidth : The absolute maximum bandwidth that current hardware can achieve .
Effective bandwidth : The bandwidth actually achieved by the kernel function , It measures bandwidth .
4.4.2 Matrix transposition
Observe the input and output layout , Will find :
read : Access through the rows of the original matrix , The result is merge access ;
Column : Access through the columns of the transpose matrix , The result is cross access ;
4.4.2.1 Set upper and lower performance limits for transpose kernels
Create two copy kernels to roughly calculate the upper and lower bounds of the performance of all transpose kernels :
Copy the matrix by loading and storing rows ( ceiling ). This will simulate performing the same number of memory operations as transpose , But you can only use merge access ;
Copy the matrix by loading and storing Columns ( Lower limit ). This will simulate performing the same number of memory operations as transpose , But you can only use merge access ;
__global__ void copyRow(float* out, float* in, const int nx, const int ny)
{
unsigned int ix = blockDim.x * blockIdx.x + threadIdx.x;
unsigned int iy = blockDim.y * blockIdx.y + threadIdx.y;
if (ix < nx && iy < ny)
out[iy * nx + ix] = in[iy * nx + ix];
}
__global__ void copyCol(float* out, float* in, const int nx, const int ny)
{
unsigned int ix = blockDim.x * blockIdx.x + threadIdx.x;
unsigned int iy = blockDim.y * blockIdx.y + threadIdx.y;
if (ix < nx && iy < ny)
out[ix * ny + iy] = in[ix * ny + iy];
}4.4.2.2 Simple transpose : Read rows and read Columns
__global__ void transposeNaiveRow(float* out, float* in, const int nx, const int ny)
{
unsigned int ix = blockDim.x * blockIdx.x + threadIdx.x;
unsigned int iy = blockDim.y * blockIdx.y + threadIdx.y;
if (ix < nx && iy < ny)
out[ix * ny + iy] = in[iy * nx + ix];
}
__global__ void transposeNaiveCol(float* out, float* in, const int nx, const int ny)
{
unsigned int ix = blockDim.x * blockIdx.x + threadIdx.x;
unsigned int iy = blockDim.y * blockIdx.y + threadIdx.y;
if (ix < nx && iy < ny)
out[iy * nx + ix] = in[ix * ny + iy];
}NaiveCol Performance ratio NaiveRow One of the reasons for better performance may be that cross reads are performed in the cache . Even if the data read into the L1 cache in some way is not used by this access , This data remains in the cache , Cache hits may occur during subsequent accesses .
After disabling L1 cache , The results show that cache cross reading can achieve the highest load throughput .
4.4.2.3 Expand transpose : Read rows and columns
The purpose of expansion is to assign more independent tasks to each thread , This maximizes the current memory request .
The following is based on the expansion factor 4 Line based implementation of .
__global__ void transposeUnroll4Row(float* out, float* in, const int nx, const int ny)
{
unsigned int ix = blockDim.x * blockIdx.x * 4 + threadIdx.x;
unsigned int iy = blockDim.y * blockIdx.y + threadIdx.y;
unsigned int ti = iy * nx + ix;
unsigned int to = ix * ny + iy;
if (ix + blockDim.x * 3 < nx && iy < ny)
{
out[to] = in[ti];
out[to + ny * blockDim.x] = in[ti + blockDim.x];
out[to + ny * blockDim.x * 2] = in[ti + blockDim.x * 2];
out[to + ny * blockDim.x * 3] = in[ti + blockDim.x * 3];
}
}4.4.2.4 Diagonal transpose : Read rows and columns
The programming model abstraction may represent the grid with a one-dimensional or two-dimensional layout , But from a hardware perspective , All blocks are one-dimensional .
When a kernel function is enabled , Thread blocks are allocated to SM The order of is determined by the block ID To make sure .
int bid = blockIdx.y * gridDim.x + blockIdx.x;Because the speed and order of thread block completion are uncertain , As the kernel process executes , At first, through the block ID It will become discontinuous .
Although the order of thread blocks cannot be directly regulated , But you can use block coordinates flexibly blockIdx.x and blockIdx.y.
Diagonal coordinate system is used to determine the location of one-dimensional thread block ID, But for data access , You still need to use the Cartesian coordinate system .
When using diagonal coordinate system to represent blocks ID when , You need to map the diagonal coordinate system to the Cartesian coordinate system . For a square matrix , This mapping can be calculated by the following equation ;
block_x = (blockIdx.x + blockIdx.y) % gridDim.x;
block_y = blockIdx.x;__global__ void transposeDiagonalRow(float* out, float* in, const int nx, const int ny)
{
unsigned int blk_y = blockIdx.x;
unsigned int blk_x = (blockIdx.x + blockIdx.y) % gridDim.x;
unsigned int ix = blockDim.x * blk_x + threadIdx.x;
unsigned int iy = blockDim.y * blk_y + threadIdx.y;
if (ix < nx && iy < ny)
out[ix * ny + iy] = in[iy * nx + ix];
}Use the diagonal coordinate system to modify the execution order of the thread block , This greatly improves the performance of row based kernel functions . The implementation of diagonal kernel function can be greatly improved by expanding blocks , But this implementation is not as simple and direct as using the kernel function of Cartesian coordinate system .
The reason for this performance improvement is DRAM Parallel access to . When mapping a thread block to a data block using Cartesian coordinates , Global memory may not be evenly distributed throughout DRAM From partition , At this time, partition conflicts may occur . In case of partition conflict , Memory requests are queued in some partitions , Other partitions have not been called . Because the diagonal coordinate mapping results in a nonlinear mapping from the thread block to the data block to be processed , So cross access is unlikely to fall into a separate partition , And it will improve the performance .
4.4.2.5 Use thin blocks to increase parallelism
The easiest way to increase parallelism is to resize blocks . By increasing the number of consecutive elements stored in the process block , Thin blocks can improve the efficiency of storage operations .(8, 32), instead of (32, 8)
4.5 Matrix addition using the same memory
To simplify the management of host and device memory space , Improve this CUDA Readability and maintainability of the program , You can use unified memory to add the following solution to the main function of matrix addition :
Replace the allocation of host and device memory with managed memory allocation , To eliminate duplicate pointers ;
Delete all displayed memory copies ;
// Declaration and distribution 3 Managed arrays
float* A, * B, * gpuRef;
cudaMallocManaged((void**)&A, nbytes);
cudaMallocManaged((void**)&B, nbytes);
cudaMallocManaged((void**)&gpuRef, nbytes);
// Use a pointer to managed memory to initialize input data on the host
initial(A, nxy);
initial(B, nxy);
// Call the matrix addition kernel function through a pointer to managed memory
sumMatrixGPU<<<grid, block>>>(A, B, gpuRef, nx, ny);
cudaDeviceSynchronize();If it is in one more GPU Test on the system of the device , Hosting applications requires additional steps . Because managed memory allocation is visible to all devices in the system , All can limit which device is visible to the application , In this way, managed memory is allocated to only one device . Set the environment variable CUDA_VISIBLE_DEVICES.
Using managed memory causes CPU Longer initialization time .
By nvprof Flag enable unified memory related indicators :
nvprof --unified-memory-profiling per-process-device
When CPU Need to access the current resident GPU Managed memory in , Unified memory usage CPU Page failure triggers data transmission from the device to the host .
4.6 summary
Directly available to programmers GPU Enough memory for hierarchy , This allows more control over movement and layout , Optimized performance and higher peak performance .
Two ways to improve bandwidth utilization :
Maximize the current number of concurrent memory accesses ;
Maximize global memory and on the bus SM Utilization of bytes moved between on-chip memories ;
To keep enough memory operations in progress , You can use deployment technology to create more independent memory requests in each thread , Or adjust the execution configuration of the grid and thread block to reflect the full SM Parallelism .
To avoid unused data movement between device memory and on-chip memory , We should strive to achieve the ideal access mode : Align and merge memory access .
The key to improve merge access is the memory access mode in the thread bundle . On the other hand , The key to eliminate partition conflicts is the access mode of all active thread bundles . Diagonal coordinate mapping is a method to avoid partition conflict by adjusting the execution order of blocks .
The need to explicitly transfer data between the host and the device by eliminating duplicate pointers , Unified memory greatly simplifies CUDA Programming .
边栏推荐
- Arm pc=pc+8 is the most understandable explanation
- RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
- Reno7 60W超级闪充充电架构
- Fashion Gen: the general fashion dataset and challenge paper interpretation & dataset introduction
- 选择法排序与冒泡法排序【C语言】
- Mp3mini playback module Arduino < dfrobotdfplayermini H> function explanation
- Arduino get random number
- Priority inversion and deadlock
- 小天才电话手表 Z3工作原理
- 2022.2.12 resumption
猜你喜欢
![[esp32 learning-1] construction of Arduino esp32 development environment](/img/31/dc16f776b7a95a08d177b1fd8856b8.png)
[esp32 learning-1] construction of Arduino esp32 development environment
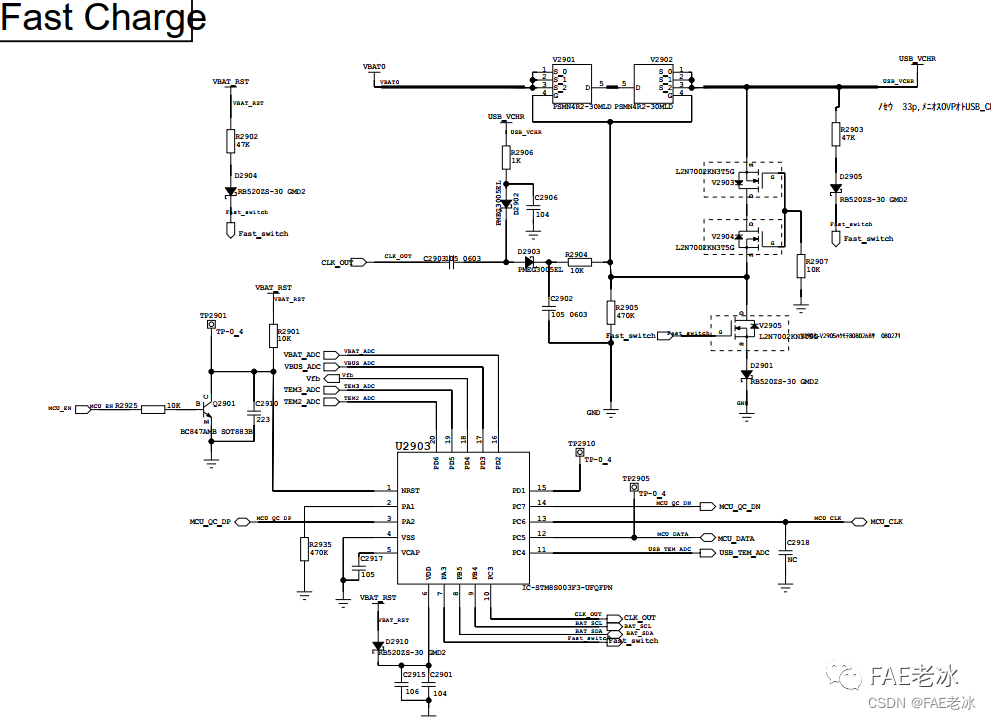
Oppo vooc fast charging circuit and protocol
Esp8266 uses Arduino to connect Alibaba cloud Internet of things
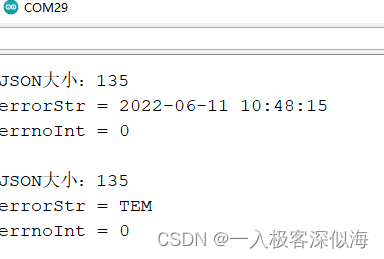
Arduino JSON data information parsing

ES6语法总结--下篇(进阶篇 ES6~ES11)

JS object and event learning notes
ESP learning problem record
Postman 中级使用教程【环境变量、测试脚本、断言、接口文档等】
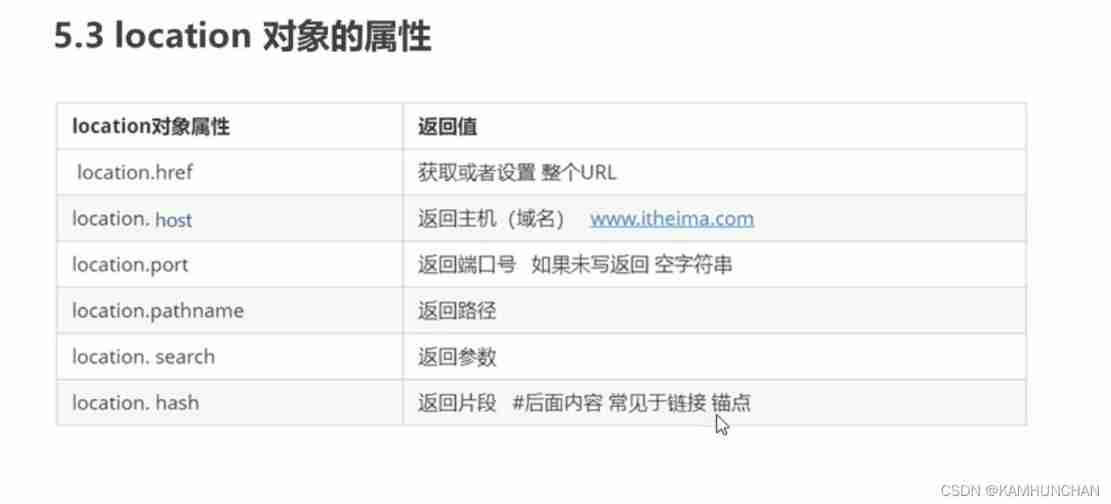
Common properties of location
Basic operations of databases and tables ----- modifying data tables
随机推荐
arduino UNO R3的寄存器写法(1)-----引脚电平状态变化
STM32 如何定位导致发生 hard fault 的代码段
关于Gateway中使用@Controller的问题
Esp8266 connects to bafayun (TCP maker cloud) through Arduino IED
OPPO VOOC快充电路和协议
基于Redis的分布式锁 以及 超详细的改进思路
Raspberry pie tap switch button to use
Togglebutton realizes the effect of switching lights
RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
C语言回调函数【C语言】
Custom view puzzle getcolor r.color The color obtained by colorprimary is incorrect
高通&MTK&麒麟 手機平臺USB3.0方案對比
选择法排序与冒泡法排序【C语言】
Navigator object (determine browser type)
E-commerce data analysis -- salary prediction (linear regression)
Inline detailed explanation [C language]
Kconfig Kbuild
RT-Thread 线程的时间片轮询调度
AMBA、AHB、APB、AXI的理解
Use of lists